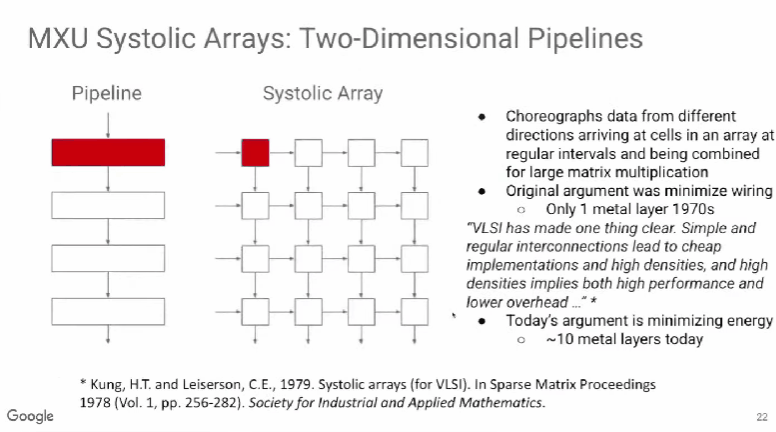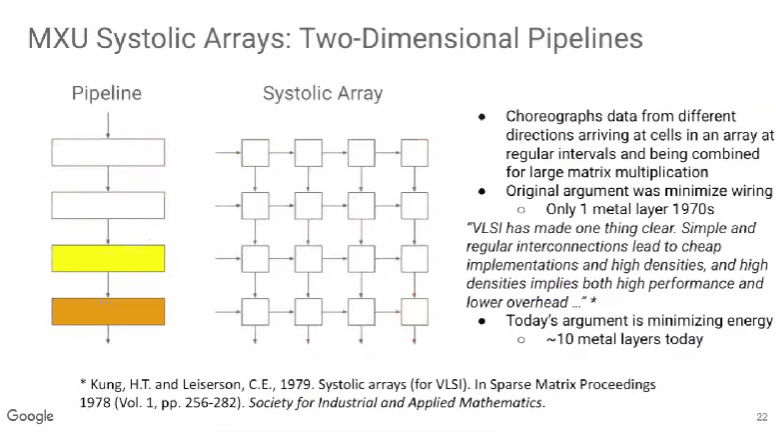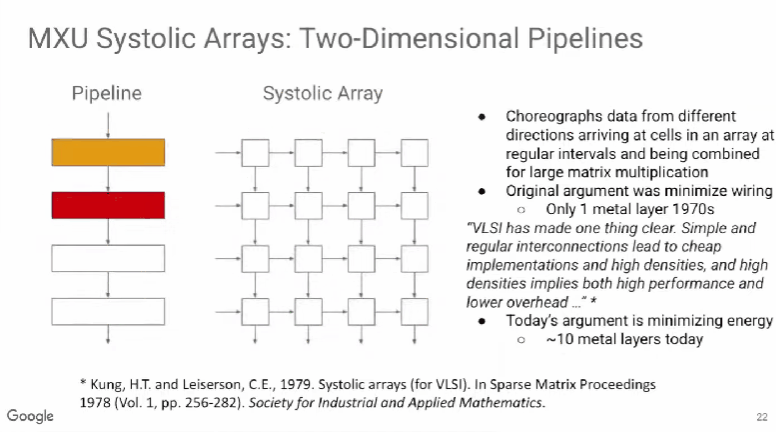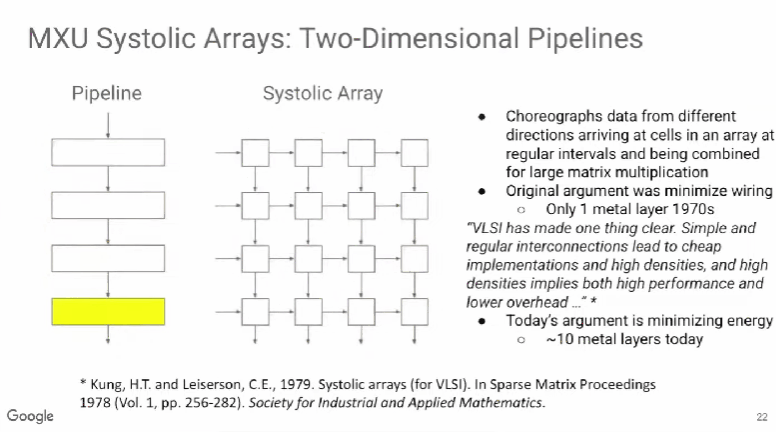
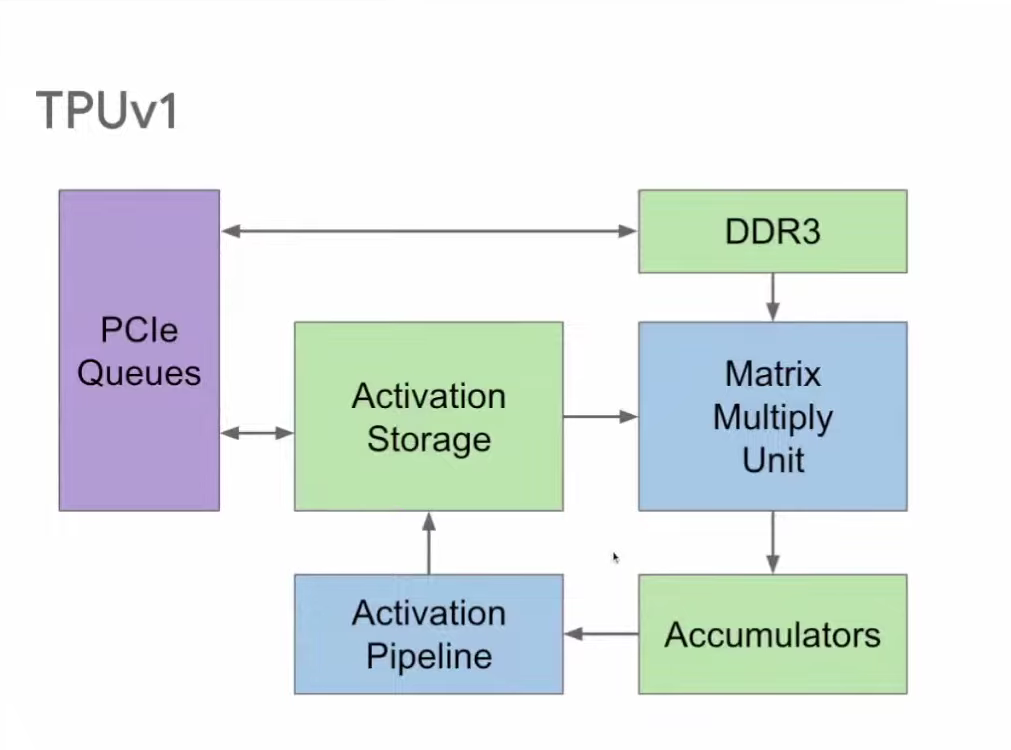
随着工业自动化和智能化的发展,电机控制系统正向更高精度、更快响应和更高稳定性的方向发展。高速光耦作为一种电气隔离与信号传输的核心器件,在现代电机控制中扮演着至关重要的角色。本文将详细介绍高速光耦在电机控制中的应用优势及其在实际工控系统中的重要性。高速光耦的基本原理及优势高速光耦是一种光电耦合器件,通过光信号传递电信号,实现输入输出端的电气隔离。这种隔离可以有效保护电路免受高压、电流浪涌等干扰。相比传统的光耦,高速光耦具备更快的响应速度,通常可以达到几百纳秒到几微秒级别的传输延迟。电气隔离:高速光
晶台光耦
2024-12-20 10:18
146浏览