
都说Python简单易学,这不就来凑凑热闹。一直对爬虫挺好奇了,于是搜到了C语言中文网的一篇文章。其中有一个例子是爬取有道翻译的。根据输入的内容获取翻译结果,一共不到50行的代码,看着确实挺简单的,思路也非常清晰。于是手残也跟着写了一份代码。
爬取有道翻译的数据,首先需要安装requests库,这些数据都可以在浏览器开发者工具(F12)中找到。
需要知道请求的url,如下图:
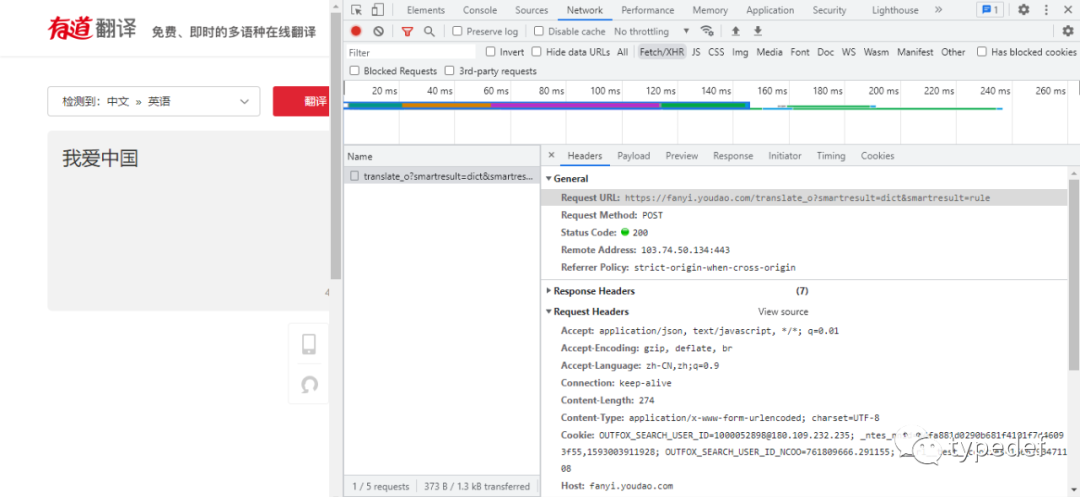
需要知道标头(Request Headers),如下图:
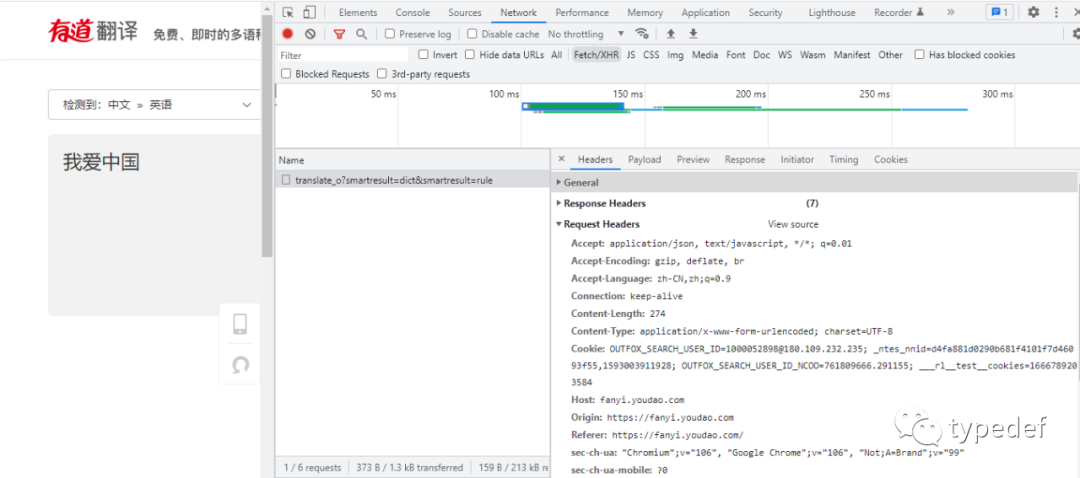
需要知道表单(Form Data),如下图:
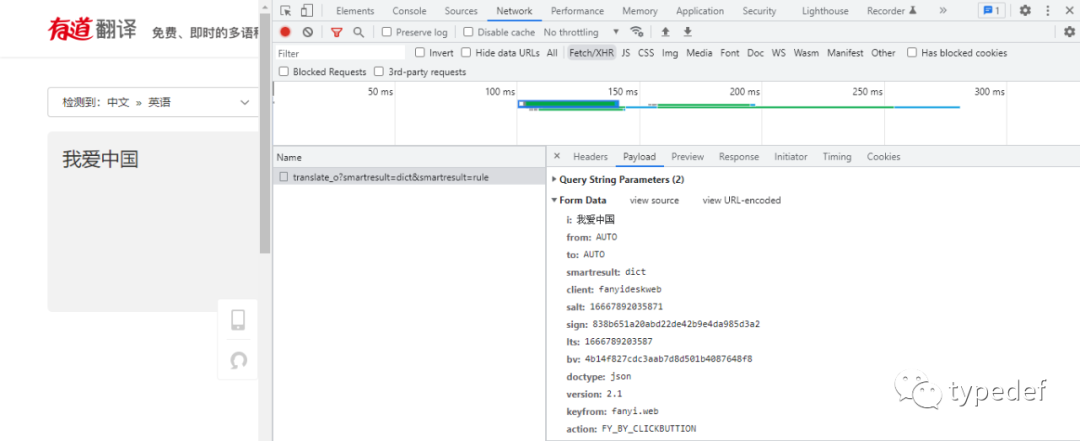
翻译的结果可以在Preview中查看,结果保存在字典中。所以只要从字典中能取出数据展示即可,如下图:
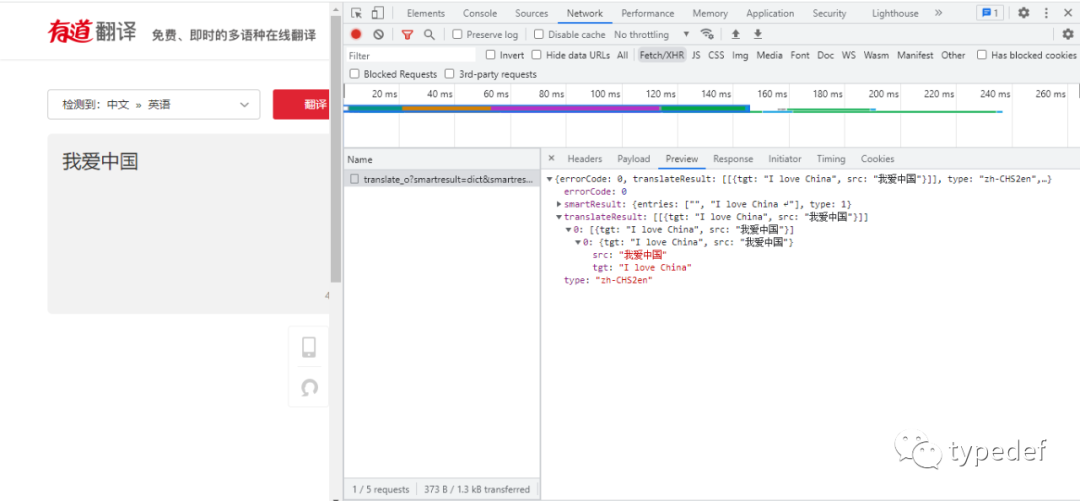
不写不知道,一写吓一跳,如果不出意外的情况下意外还是发生了,服务器响应{"errorCode":50},内容翻译不出来。
这种程序可不能惯着,代码写出来了不能工作,势必要拿下。
于是去网上找大神求助,爬取有道翻译已经成为学习爬虫的入门案例了,结果有道翻译急了,后来就针对爬虫做了反爬机制。其实就是对表单中salt和sign参数验证,只有验证正确才能返回翻译结果。
可能网上的这篇文章比较久远了,那个时候还没有反爬机制,这样就说得通了。
那么只要搞明白这两个参数是如何加密的,就能正常翻译了。
首先,在有道翻译网页源文件中,有一个fanyi.min.js文件,这个文件中记录了这两个参数加密的方式,如下所示:
当打开这个链接时,网页显示是这样子的,比较乱。

我们直接把网页的内容复制一份,找个在线格式化js代码的(链接放在源码中),然后把格式化之后内容保存下来,再用编辑器查看。其中有一段是这样子的,如下:
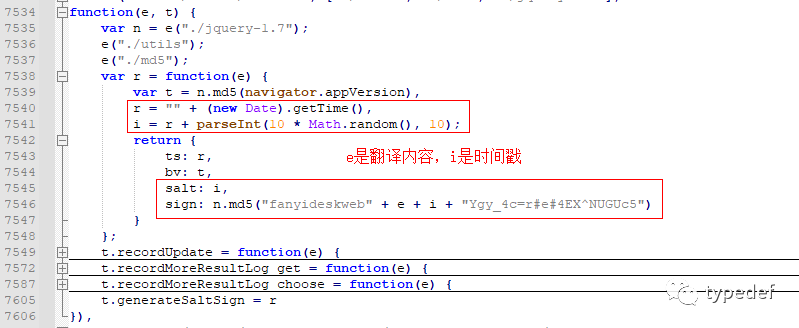
solt就是时间戳加上一个随机值,sign是对拼接的字符串经过MD5加密。e就是我们待翻译的文字。
# -*- coding: utf-8 -*-
import requests
import json
import random
import time
import hashlib
"""
破解有道反爬虫solt,sign, {"errorCode":50}
有道云在线翻译:https://fanyi.youdao.com/,
有道云fanyi.min.js网址:https://shared.ydstatic.com/fanyi/newweb/v1.1.10/scripts/newweb/fanyi.min.js
js代码格式化工具:https://tool.oschina.net/codeformat/js,把fanyi.min.js内容复制到这个网站上
"""
def FormDataGetSign(text, salt):
str = "fanyideskweb" + text + salt + "Ygy_4c=r#e#4EX^NUGUc5"
m = hashlib.md5()
m.update(str.encode('utf-8'))
return m.hexdigest()
translate = input("Please enter what you want to translate:\r\n")
salt = str(int(time.time() * 1000) + random.randint(0, 10))
url = "https://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule"
# url="https://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule"
# 将原地址中的'_o'去掉就不会对salt和sing验证了
Form_data={'i':translate,
'from':'AUTO',
'to':'AUTO',
'smartresult':'dict',
'client':'fanyideskweb',
'salt': salt,
'sign':FormDataGetSign(translate, salt),
'lts':'1666619583365',
'bv':'4b14f827cdc3aab7d8d501b4087648f8',
'doctype':'json',
'version':'2.1',
'keyfrom':'fanyi.web',
'action':'FY_BY_REALTlME'}
headers = {'Cookie':'OUTFOX_SEARCH_USER_ID=1000052898@180.109.232.235;',
'Referer': 'http://fanyi.youdao.com/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'}
content = json.loads(requests.post(url, data=Form_data, headers=headers).text)
if 'translateResult' in content:
try:
print('The result of translation:\r\n'+content['translateResult'][0][0]['tgt'])
except:
pass
else:
print("翻译出错")
可以直接将url地址中的_o删除,反爬虫机制就不会生效了。solt和sign可以直接用浏览器中的固定值。
参考链接:https://tendcode.com/article/youdao-spider/
END
往期推荐
Python中字符串格式化三种方法


