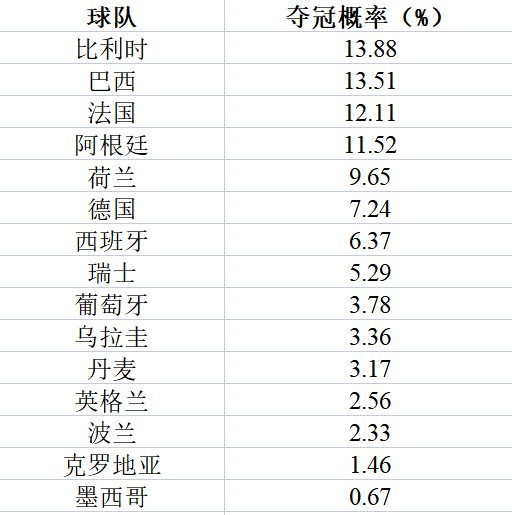
进攻与防守指数确定泊松概率2022 年 5 月 19 日,发表在 PLoS One 上的一篇论文,曾对“双柏松”统计模型做出过详细的分析,论文题为《预测 2020 年欧洲杯比赛结果的双泊松模型分析》(Analysis of a double Poisson model for predicting football results in Euro 2020)为题。 (来源:PLoS One)论文中指出,在该模型中,每个球队的进球数都可以被换算成泊松概率分布。并且,通过该模型可以统计出球队在比赛过程中的进球个数,其均值取决于球队的进攻和防守能力。实际比赛的过程中,除了双方的综合实力,还受运气等外在因素影响,因此结果具有不确定性。考虑到这点,在用“双泊松”模型描述球队水平时,会提前设置“进攻”与“防守脆弱性”指数。其中,“进攻”指数越高表示球队进球越容易,“防守脆弱性”指数则相反,越高表示进球越难。在获得“进攻”与“防御脆弱性”指数后就能算出“泊松概率分布”平均值。“双泊松”模型中设定不同的球队可以根据各自不同的“双泊松”过程得分,并将 A 和 B 球队的预期进球得分设定为 μ(A,B)。需要注意的是,统计模型在计算的过程中会将进球速度看做是恒定的,也不考虑进球的具体时间,只需要考虑进球数。此外,“泊松概率分布”的计算过程使用了“无记忆”假设,即一个进球不会影响比赛其余的进球数。这些通常是模型的潜在错误来源。图 | 各国赢球概率预测(来源:Matthew Penn)同样值得注意的是,在这个模型中,没有对主客场比赛进行区分。也就是说,无论比赛在哪里进行,A 队对 B 队的预期进球数都将等于 μ(A,B)。这是一个简化的假设,不仅减少了参数的数量,而且避免了小数据集的过度拟合。事实上,由于不同球队之间的相关联结果数量很少(其中许多球队根本没有进行过比赛),会根据情况减少模型中的参数数量。预估球队分数接下来,在计算不同球队预计进球数的过程中,模型默认球员都按照最理想的情况发挥。“预计进球数”等于 A 球队的进攻指数乘以 B 球队的防守脆弱性指数,在计算 B 球队的进球数过程中也是如此。例如,A 球队的进攻指数是 8,防守脆弱性指数是 0.4;B 球队进攻指数是 10,防守脆弱性指数是 0.6,双方的得分为 4.8:4(模型默认为 5:4)。但是,由于比赛过程中充满不确定因素,A 队 4.8 的进球数与 B 队 0.6 的进球数都被当做平均泊松概率分布。所有比分的概率大小取决于两个进球数概率值的乘积。A 和 B 球队攻击力和防守脆弱性指数都是根据球队过去的表现与分数综合地确定,需要不断更新与调整,将预测的柏松概率分布数值与比赛中实际获得的分数匹配。(来源:Pixabay)因此,在实际预测过程中,球队可能出现的分数都会被预测出来,最后可以预估出夺冠的球队。马修·佩恩在牛津大学官网上表示:“双柏松统计模型预测了一百万次球赛,得出世界杯十六强晋级走势及冠军归属。根据预测结果,荷兰、伊朗、阿根廷、丹麦、西班牙、克罗地亚、巴西等球队会进入十六强。阿根廷进入四强,巴西将在四分之一决赛时淘汰西班牙。”