

首先还是给大会做个广告,ISSCC 2023是ISSCC的70年周年,Keynote由AMD苏妈领衔,将在明年2/19-23在旧金山市召开。

“存算一体”的正确翻译是啥?
先放一个小彩蛋。小编日常都是用Computing-in-Memory描述存算一体的,但是这是正确的翻译么?但纵观全program,即使在题目里你就会看到好几个说法,如清华、东南的论文就都采用了Computation-in-Memory的说法,


当然,也有Computing-in-Memory的称呼:

 还有 Compute-in-Memory:
还有 Compute-in-Memory:


那官方称呼什么呢?ISSCC全部34个session中,有两个session的title都直接用到了存算一体,而他们的官方称呼都是——Compute-in-Memory. 从英语语法的角度讲,这是对的。Compute本来就可以做名词的,Computing/tation都画蛇添足了。值得注意的是这两个session都是长session(即session跨度覆盖整个半天,包含7-9篇文章),也就是说光这两个session就有16篇文章是存算一体相关的。


除了这两个session外,存算一体还出没在 session 29(3篇)和session 33 (2篇),粗略的算一算ISSCC 2023至少有21篇存算一体相关的论文,占了整个ISSCC录用论文的10%,堪比一个track了,当然也导致很多老师吐槽这个存算一体是不是“溢出”了呀。
数字化、浮点化“存算一体”的大趋势
作为一个数字化存算一体的布道者,小编这两年经常会被问一个问题是:你这还是存算一体么?和近存计算数字加速器有啥区别?
我作过很多很techinical的回答。比如,数字存算采用了定制逻辑门取代标准单元库逻辑门提高功耗,规则化的版图取代自动布局布线下模拟随机生成的版图降低寄生。再比如数字存算可以100%享受到scaling down的优势,而模拟存算能效几乎不随工艺节点变化,导致先进工艺下数字存算较模拟存算的劣势越来越小等等。
但看完这个program,我觉得这些都没答到点上,可能一个六神磊磊式的回答,更接近这个问题的本质。《神雕侠侣》里独孤求败的剑冢前有一句话“草木竹石均可为剑,渐入无剑胜有剑之境”。所谓,无剑胜有剑,或许就是存算一体追求的意境。“模拟”存算是砍出这条路的第一个剑式,但对于存算电路,最终要的探索是“不囿于任何设计规则的定制化高能效、高精度电路”的新招式。你的模拟课本上未必有招,你的Verilog课本上也没有这些招。模拟、数字甚或者任何手段都应该是你的“心中之剑”胜过手中的剑招。
让我们来看看ISSCC 2023的存算之剑。纯模拟的存算一体在session 7 (SRAM存算一体Macro)中只有2篇,其余均是数字。特别指出的是,台湾清华提出了数模混合的浮点存算一体,以及东南大学的纯数字的浮点存算一体Macro实现。浮点能效也都上看了20-30 TOPS/W。支持浮点精度的数字存算芯片,从一开始的2年前KAIST的一篇VLSI到今天大规模占领存算session,可以说是“换了人间”的大趋势。

再看Session 16,基于存算一体的AI处理器部分。7篇中题目中写明数字存算就有5篇,另外两篇中目测也有一篇是大概率是数字。而数字存算可以实现的SoC场景,可以涵盖各类需求,如高精度的Transformer,甚至浮点精度的AI训练等。

和Session 22(异构的机器学习加速器,基本就是纯数字的AI芯片)相比,存算路径的芯片大致覆盖了各类主流、非主流的应用场景,已丝毫不显劣势。
“存算一体”何时能大规模商业落地?
小编短短的芯片科研道路上,见证过两个一开始并没有被工业界认为很靠谱的新技术,最终落地成为行业标准——ADPLL(全数字锁相环)、Asynchronous SAR ADC(异步逐次比较模数转换器)。它俩从以第一篇ISSCC到大规模量产,大致都用了快十年的时间。存算一体是否也能步着这样的节奏(甚至更快),变成人工智能芯片的标准件呢?
然而,产业对“存算一体”的态度却没有那么乐观。北美模拟存算一体的明星初创Mythic在几周前宣布了由于缺乏现金流“out of runway”(偏离了跑道)。在国内,头部芯片设计公司对存算的态度大抵也是如此。
究其原因,目前的“存算一体”芯片并没有本质上解决所谓的“存储墙”问题。从各类paper不断在show能效的题目里就可以看出,目前的存算一体更多是在探索矩阵计算单元的高能效实现方法。然而,产业界在提高矩阵计算单元的能效有一条最粗暴的路径——摩尔定律尺寸微缩。以ISSCC 2023的某篇28nm的存算一体transformer为例,各种跨层次协同技术的共同作用下,性能才能和VLSI 2022上Nvidia 5nm的transformer比一比肩膀(实际上还有点落后)。
那业界关注什么呢?可以先来看下处理器巨头们在ISSCC 2023上发布的论文。(这些论文一般认为有广告的嫌疑)Program 主session第一篇的论文是AMD 的Zen4 处理器核:

大致也是上周,AMD开了新一年的发布会,苏妈介绍了Zen 4架构的Eypc服务器和PC处理器。他们解决存储墙的方式就是:是第二代3D V-Cache(ISSCC 2022上是第一代)+IO Hub Die(ISSCC 2020)+ 数量可扩展的CPU Die,暴力美学的典范。

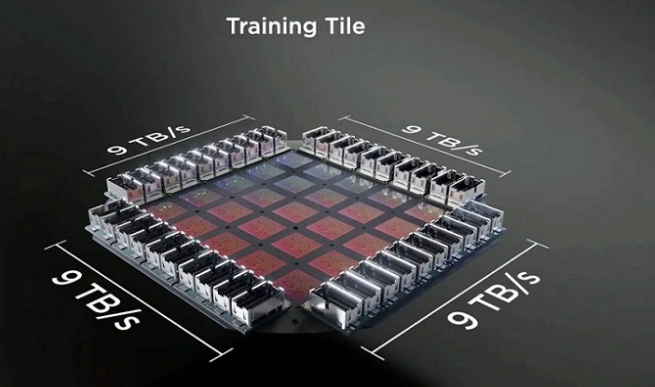
再来看Session 9,邀请工业界的大芯片论文。第一篇是Tesla的7nm的训练芯片(应该是今年发表的Dojo),它一个完整的软件定义晶上系统(小广告:12月即将Software-Define System on Wafer大会),每个core含有1.25MB的SRAM buffer,每个D1 Die含有354个core,一个晶圆上有25个D1。目测整个晶圆的Cache上10GB了(每个Die 428MB SRAM Cache,乘以25)。

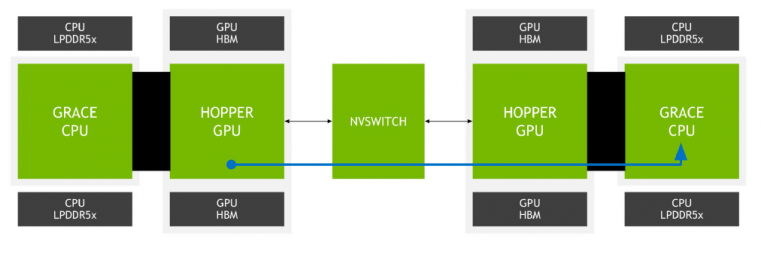
同样的,Nvidia的邀请论文也在讨论连接各类in-house 处理器芯片的连接协议与电路——NVlink-C2C。

显然,和这些芯片相比,学术界存算一体相关论文的芯片规模还不足以进入产业的法眼,至少并不能解决一个100MB以上中等规模网络的存储墙问题(现在的大网络都太疯狂了)。真正具有可扩展性、对存储墙友好的存算一体能力还未完全展现。而仅仅能解决的INT4/8的高能效存算电路目前还不是高性能处理器的主要矛盾。不过,随着浮点型存算的发展,借鉴存算一体技术的超大规模浮点型Tensor Core或许并不太久远。
过去两年的ISSCC的前瞻或者技术总结,其实都会提到存算一体,有兴趣的读者可以对比着来看看,这些年存算一体的发展历程。
来源:矽说

