

点击上方↑↑↑“OpenCV学堂”关注我
来源:公众号 机器之心 授权
本文将从一个 cuda 初学者的角度来阐述如何优化一个形状较大的正方形乘正方形的 FP32 矩阵乘。
矩阵乘作为目前神经网络计算中占比最大的一个部分,其快慢会显著影响神经网络的训练与推断所消耗的时间。虽然现在市面上已经有非常多的矩阵乘的高效实现——如基于 cpu 的 mkl、基于 arm 设备的 ncnn 与 emll、基于 cuda 的 cublas ——掌握了矩阵乘优化的思路不仅能帮助你更好的理解编写高性能代码的一些基本原则,而且许多神经网络加速领域进阶的技巧如算子融合都是与矩阵乘交互从而达到更高的性能。
由于矩阵乘的性能优化与两个矩阵的形状有着非常密切的联系,因此,为了降低本文的撰写难度(以及辅助读者更好的理解矩阵乘优化),本文将从一个 cuda 初学者的角度来阐述如何优化一个形状较大的正方形乘正方形的 FP32 矩阵乘。同时本文按如下顺序讲解:
Goals:本文的目标是什么?
Performance:我们达到了多少性能?
朴素 GEMM 与前置知识:简单介绍一下我们的任务是什么,我们需要提前了解什么。
Tiling:如何做矩阵分块?即如何将一个巨大的矩阵乘任务合理的分配到 GPU 的不同线程上。
Thread 级优化:在 Thread 这个维度,我们能做什么优化?
Warp 级优化:在 Warp 这个维度,我们能做什么优化?
Block 级优化:在 Block 这个维度,我们能做什么优化?
Epilogue:尾声。
Goals
首先明确一下本文的目标是:
• 实现一个比 cublas 更快的形状较大的正方形乘正方形的 FP32 矩阵乘。
• 从理论角度与硬件规格能够简单的推导矩阵分块与排布的方法。
• 可以大致清楚各个优化技术效果的阶段性的 benchmark。
• 如何使用 Nsight Compute 等性能分析工具分析潜在的性能瓶颈。
本文不含:
• 使用 Tensor Core 加速矩阵乘。(这也是为什么这篇文章叫传统 CUDA GEMM)
• 使用安培架构新提出的 async memcpy。
• CUDA 语法知识。
• 汇编。(主要是现在并没有官方支持汇编的操作,目前的汇编器几乎都是逆向的产物,不是很稳定。同时汇编带来的好处如消除寄存器的 bank conflict nvcc 也在不断的做相应的改进,因此就不介绍了)
开源地址:https://github.com/AyakaGEMM/Hands-on-GEMM
同时本文在相当程度上参考了李少侠的 GEMM 优化指南(写得非常!非常!非常!不错),本文的优势在于补了阶段性代码和在某些少侠一笔带过的地方做了一些扩展。
Performance
为了让大家更有动力阅读下去,这里先放出来性能效果!
测试平台
• 系统:Arch Linux
• 驱动:520.56.06
•CUDA:11.8
•GPU:Nvidia RTX 2080
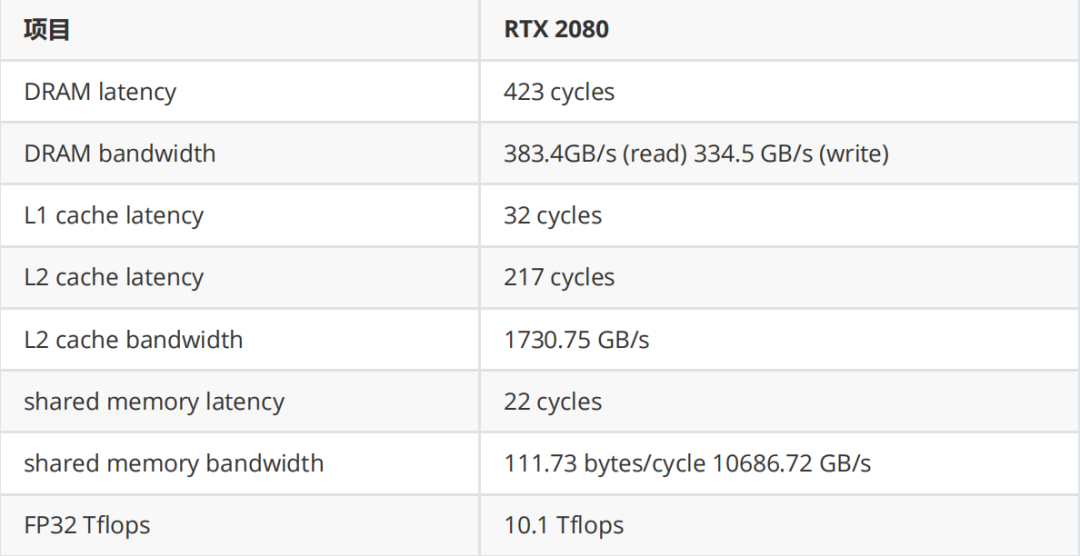
测试结果
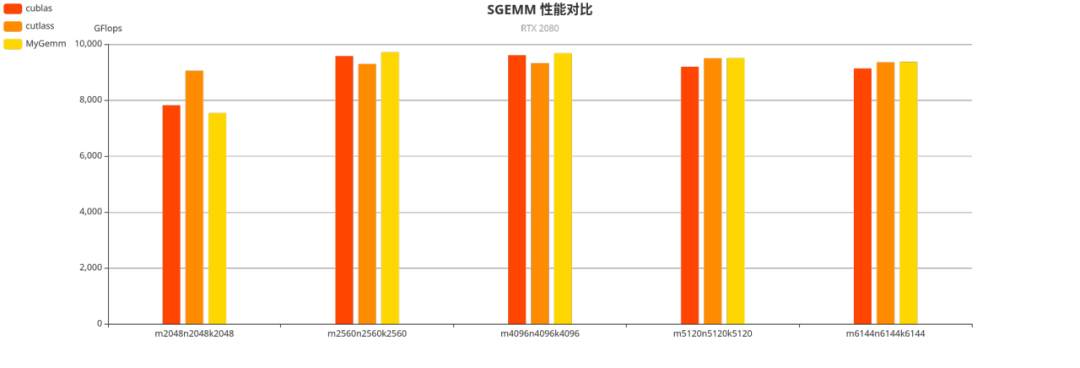
我们也可以注意到,在较大形状上手写的矩阵乘有着与 cublas 相近,甚至更优的性能。
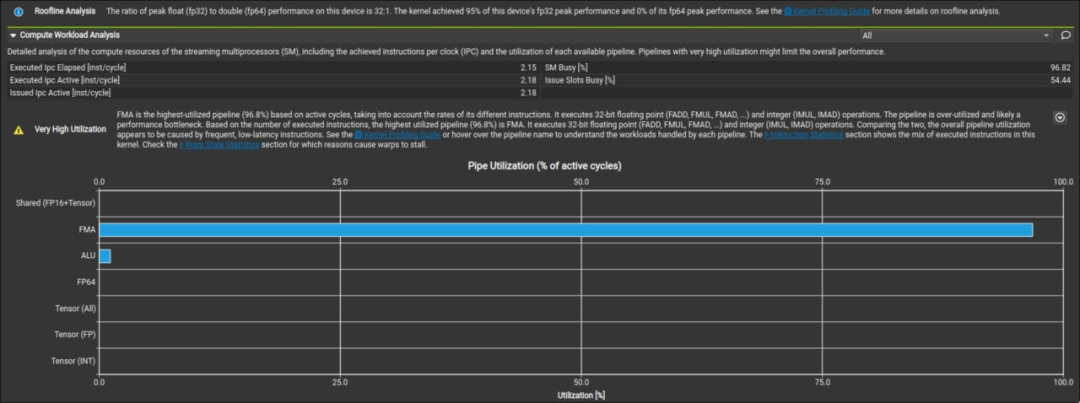
从这张图我们可以看出,手写的矩阵乘能够达到硬件 95% 的峰值性能,效果还是很不错的。
朴素 GEMM 与前置知识
首先写一个朴素矩阵乘。
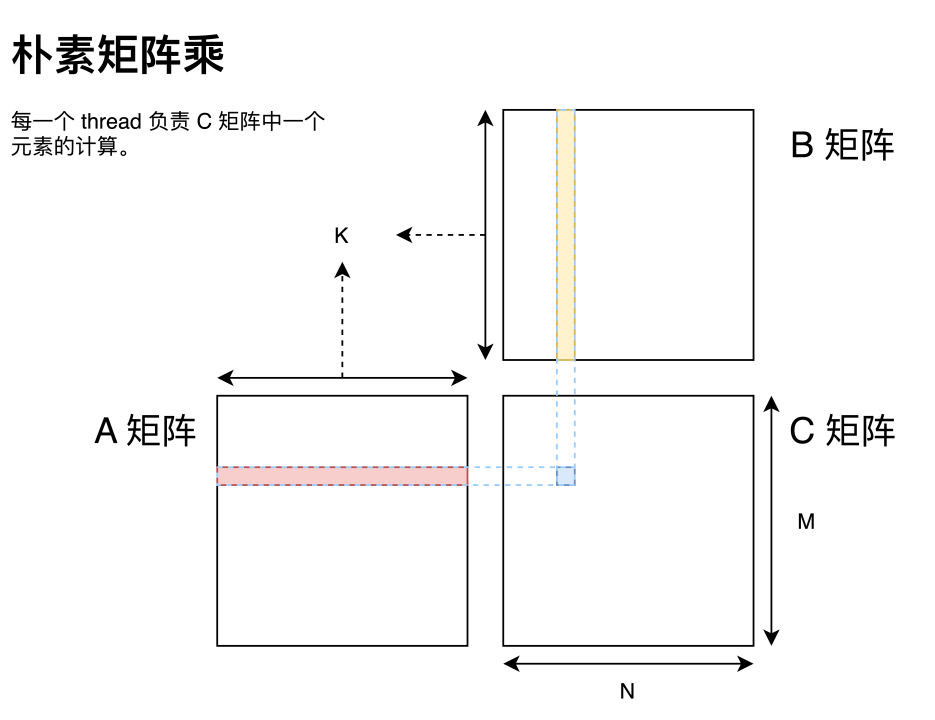
# 数组 A:M 行 K 列的行主序矩阵# 数组 B:K 行 N 列的行主序矩阵# 数组 C:M 行 N 列的行主序矩阵# alpha:一个标量# beta:一个标量# 计算方法:# c=alpha*A*B+beta*C;__global__ void matrixMul(const float *A, const float *B, float *C,int M, int N, int K, float alpha, float beta){int tx = blockIdx.x * blockDim.x + threadIdx.x;int ty = blockIdx.y * blockDim.y + threadIdx.y;int baseX = blockIdx.x * blockDim.x;int baseY = blockIdx.y * blockDim.y;float c = 0;if (tx < M && ty < N){for (int i = 0; i < K; i++){c += A[tx * K + i] * B[i * N + ty];}C[tx * N + ty] = beta * C[tx * N + ty] + alpha * c; // we multiply alpha here to reduce the alpha cal num.}}
这里 GPU 矩阵乘与 CPU 矩阵乘最大的区别就在于 GPU 可以为目标矩阵 C 中每一个元素分配一个 thread 进行计算。这也是可以切实的感知到 GPU 多线程编程的一点。但这个矩阵乘的朴素实现会非常慢,而分析性能瓶颈中最常见的两个指标即是带宽和延迟。这里借用 Nvidia 在 GTC 2018 上的分享来做说明。

这里以一个自动扶梯作为例子来讲解。
带宽:指这个自动扶梯每秒能够运送多少个人,以这张图为例子,这个扶梯每秒能运 0.5 个人,这就是这个自动扶梯的带宽。
延迟:指一个人踏上这个扶梯直到他被运到顶所需要的时间。同样以这张图为例,这个扶梯需要 40s 的延迟。
那么回到指令上来,每一个指令都有对应的延迟和带宽,而以朴素矩阵乘为例,每一个乘法运算需要读两次内存和一次 FFMA,假如没有其他额外的优化(如循环展开与指令重排),相当于是两个级联的自动扶梯,一个负责运送数据,一个负责做数学运算。假设数据运送扶梯的带宽与延迟与图中一致而不考虑 FFMA 的带宽与延迟,那么一次 FFMA 需要等待 40s(扶梯延迟)+ (1/0.5)s(第一个数据到达后第二个数据到达的时间)才能拿到所需的数据,这与扶梯的带宽 0.5s / 人的峰值性能相去甚远。那么此时这个 kernel 就完全被延迟卡住了,而无法发挥出应有的性能。
而对于带宽部分,这里我们引用李少侠的带宽分析:
对于 FP32 数据,如上图所示,一个 warp 一次做 32 次 FFMA,对应 64 OP,需读取 A 矩阵 1 个元素和 B 矩阵 32 个元素,共 132byte。 通过寄存器累加,且忽略 C 矩阵写回开销,那么计算访存比为 64OP / 132byte = 0.48。虽然 dram 最小访问单位为一个 memory transaction,但考虑到 L1 cache 的存在也不会影响实际的计算访存比。
通过 repo 中提供的 l2cache_bandwidth.cu 可测得 Titan V L2 cache 带宽约 1.9TB/s,那么最乐观的结果即使 L2 cache 100% 命中,此方案的理论上限也只有 1.9T * 0.48 = 0.912 tflops,远低于 14.9 tflops 的硬件算力。
由此我们可以看出,朴素的矩阵乘实现方法无论从延迟和带宽上都无法满足需要。
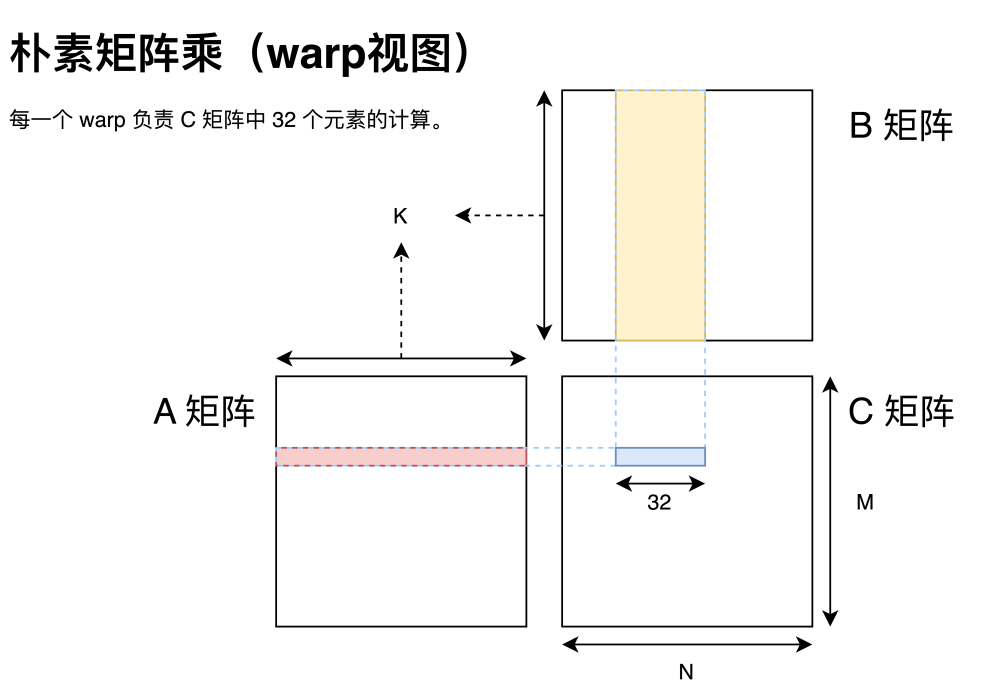
这里一个 warp(即 32 个线程)是指 GPU 调度线程的粒度,可以简单的理解为同一个 warp 内的线程总是同时运行、同时休眠的。当然这种说法并不完全准确,毕竟还有 warp divergent 问题,感兴趣的同学可以自行了解。但总之,思考 GPU 执行时总是从 warp 的角度思考是非常合理的。那么对于一个 warp 而言,我们可以根据李少侠的分析看出,就算我们假设延迟能够被完全覆盖,这种分配方案也并不能达到硬件的峰值性能。
这里我用自己的话总结一遍就是:在每个线程执行指令设计时,需要尽可能的覆盖掉每个指令的延迟;在性能分析时,则从带宽角度分析矩阵分块是否合理。
而在于延迟部分还有一顿免费的午餐。在实际应用中,编译器会自动的做一些优化,如循环展开与指令重排等。例如展开循环后可以将多个读取 A 矩阵的元素和读取 B 矩阵的元素排在一起,使得取数据的自动扶梯能够一次多上几个人,从而去覆盖掉扶梯的延迟。而且 GPU 与 CPU 还有一个非常不同的地方在于,GPU 的线程切换代价非常低,因此可以在等待延迟的时候转而去运行其他线程从而达到延迟覆盖的目的。还是以扶梯为例子,GPU 上有很多个扶梯,在等待第一个人到达扶梯末尾时,GPU 可以转到第二个扶梯送几个人上扶梯。理想情况下,在 GPU 送完第 N 个扶梯的人时,第一个扶梯的人刚好达到扶梯顶部,那么这个运送的延迟就被覆盖掉了。
Tiling
矩阵乘分块是为了将一个大问题化解为小问题求解,这里 CPU 与 GPU 分块的需求也不尽相同。CPU 是希望保持计算的局部性,可以充分利用 L1、L2 高速缓存来避免缓慢的内存访问。而 GPU 在此基础之上还需要将一个大问题合理拆分到不同的 thread 上,使得其能够充分利用 GPU 上的硬件资源。下面我将从局部性和合理拆分两个方面讲解如何做矩阵分块。
局部性原理
局部性原理,在我的理解中便是为了能够尽可能的使用高速缓存器内的数据进行运算所提出的一个程序设计理念。由于高速缓存器往往十分昂贵(或者需要很高的功耗),因此空间都不大。由此我们需要尽可能的将一些重复访存聚合起来,放到高速缓存器里面来加速数据访问,或者在进行访存的时候尽可能连续访存来使用 cache 加速访存。我们先还是让每一个 thread 负责一个目标矩阵元素的计算。虽然这种分配方式十分朴素、十分直接,同时各个 thread 之间也没有数据依赖关系,不需要做额外的同步之类的操作,但这种分配方式却是十分访存不友好的,因为每一个 thread 都是直接与内存做交互,而 GPU 的全局内存访问带宽完全不足以匹配上它的计算速度。
同时我们注意到处于同一行的 thread 总是会同样的读取 A 矩阵的同一行数据;同一列的 thread 总是会读取 B 矩阵的同一列数据。那么一个非常自然的想法则是对于每一个 Block,我们将数据移动到这个 Block 共享的一块高速存储区 shared memory 上,从而减少与全局内存交互的次数。同时我们考虑到 shared memory 的容量有限,因此可以一次只取一部分 k,然后通过循环迭代的方式完成这个 Block 所负责的矩阵乘区域。
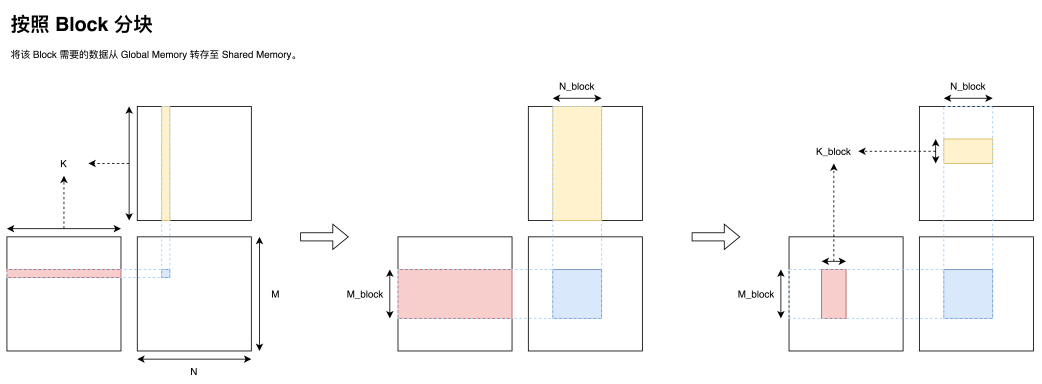
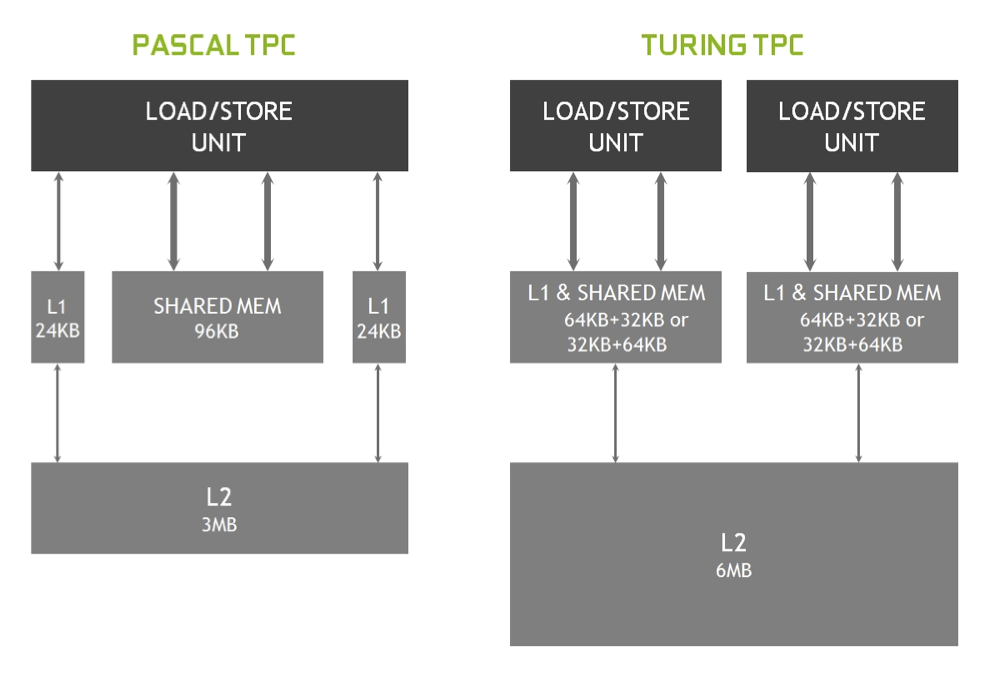
值得一提的事,shared memory 虽然叫做 memory,但他却有着非常高的访存速度与极低的延迟。实际上,shared memory 可以被看作是一块可以显式控制的 L1 cache。从图灵架构开始,在硬件上 shared memory 与 GPU 上的 L1 cache 共享同一块区域,同时 shared memory 与 Load/Store 单元交互也是直连的(没有中间商赚差价)。
在将一个大型矩阵乘划分为一个个由 Block 负责的小型矩阵乘之后,我们接下来还需要把一个 Block 负责的矩阵乘分配给 Block 内部的 warp;分配到 warp 之后我们还需要把一个 warp 负责的矩阵乘分配给 warp 内部的 thread。经过这么一步一步的划分,我们便可以把一个巨大的矩阵乘任务高效的分配到各级速度不一的存储器上,最终尽可能打满硬件峰值性能,实现高效矩阵乘。有了前面划分 Block 的经验,我们也就可以依葫芦画瓢,实现大矩阵的拆分(Tiling),在此就不过多赘述了,最终整体流程图如下。
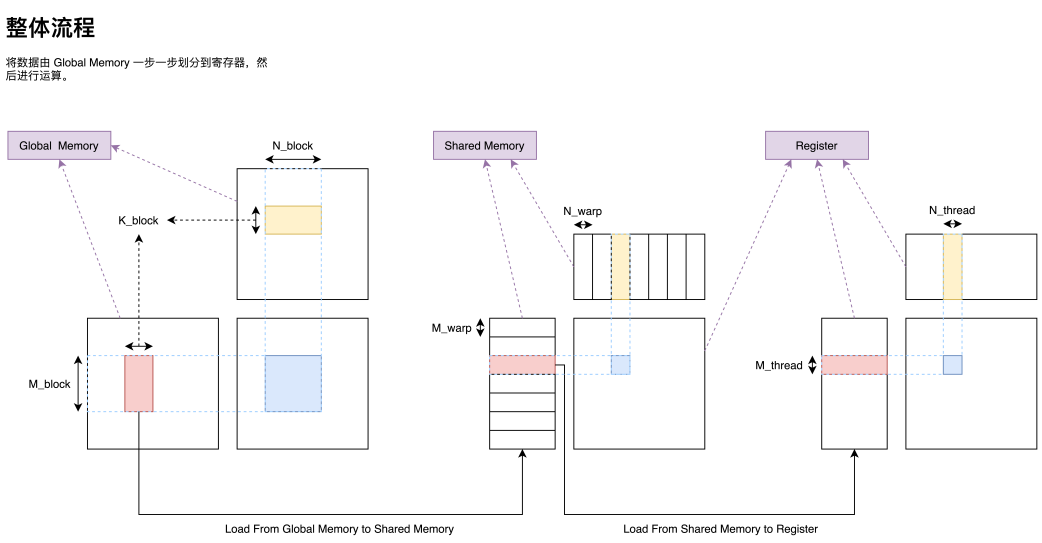
当然这只是一个较为粗糙的流程图,例如每一个 thread 负责的分块也并不是图中所示的连续一块矩阵乘,我们也将在后续一步一步完善细节,但这种分解的框架却是一种非常经典的思路。
如何确定分块大小?
在拥有分块的基本理念之后,我们还有一个问题没有解决。那便是每一个 Block 该负责多大的矩阵乘?每一个 thread 又应该负责多大的矩阵乘?为了让文字变得清晰起来,我们定义每一个 Block 负责的矩阵大小为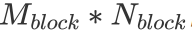 ,每次迭代
,每次迭代 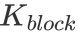 的 k 维数据,每一个 warp 负责的矩阵大小为
的 k 维数据,每一个 warp 负责的矩阵大小为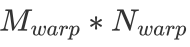 ,每一个 thread 负责的大小为
,每一个 thread 负责的大小为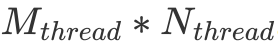 。其中这些符号都在上图出现过,可以自行对照一下。
。其中这些符号都在上图出现过,可以自行对照一下。
这里我们同样引用李少侠的计算访存分析:
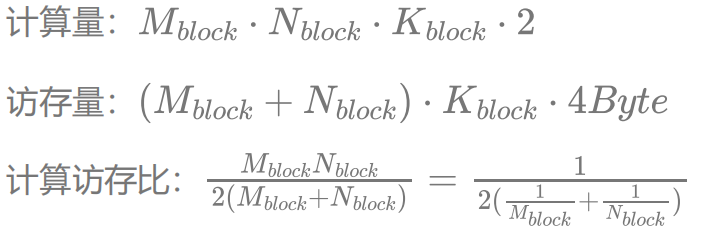
假设我们不考虑 shared memory 的访存代价(因为可以做到覆盖掉shared memory 的访存延迟,而且其带宽能够满足 FFMA 单元的计算速度),只考虑全局内存的访问,可以看到选择在 K 上缩水(即不把整个 K 维度都放到 shared memory 里)还是比较合理的,因为 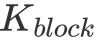 的大小其实并不影响计算访存比。而对计算访存比有决定性影响的是每一个 Block 计算的大小。如果取
的大小其实并不影响计算访存比。而对计算访存比有决定性影响的是每一个 Block 计算的大小。如果取  为 64,带入 RTX 2080 的数据,可以得到 10.1 Tflops / 16 = 631.25 GB/s。即内存访问带宽达到 631.25 GB/s 就能避免内存访问瓶颈了。同样,我们取 L2 命中率为 20%(还是比较好达到的),加权内存访问带宽为:
为 64,带入 RTX 2080 的数据,可以得到 10.1 Tflops / 16 = 631.25 GB/s。即内存访问带宽达到 631.25 GB/s 就能避免内存访问瓶颈了。同样,我们取 L2 命中率为 20%(还是比较好达到的),加权内存访问带宽为: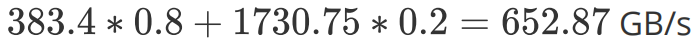 ,即可避免内存访问瓶颈。
,即可避免内存访问瓶颈。
那是否我们只要取分块大小为 64x64 就万事大吉了呢?也不尽然。我们前面只分析了带宽,而在延迟无法被覆盖的情况下,整个 kernel 性能也不会太好。而更大的分块意味着每一个 thread 会计算更多的数据,可以使用一些手段实现更优的延迟覆盖。这一点会在后面讨论如何具体实现,大致思想也是局部性的原理,只不过这次是将数据从 shared memory 保存到寄存器,从而实现使用更高速的缓存计算的目的。
那是否我们取分块越大越好呢?那也不一定。更大的分块使用了更多的寄存器,从而使得同一个 SM 能够同时承载的线程数变少,这里 Nvidia 将之称为 Occupancy。如前文所述,当一个 warp 被卡住时,GPU 可以切换到另一个 warp 执行指令,Occupancy 越低,可供 GPU 切换的线程就越少。
而 Occupancy 也是和硬件强相关的。一个 GPU 由多个 SM 构成,每一个 SM 拥有有限的寄存器数量、 shared memory 和最大可调度线程数量。而 Occupancy 是指每个 SM 能够同时调度的线程数量除以一个 SM 的最大可调度线程数量。关于 Occupancy 的计算我们可以通过在编译时添加 --ptxas-options=-v 参数,使编译器在编译时输出每个 kernel 所花费的寄存器数量和 shared memory,然后通过随 cuda 提供的一个 excel 表格进行计算。(尽管这个 Excel 已经 deprecated 了,但他用起来确实挺方便的。)
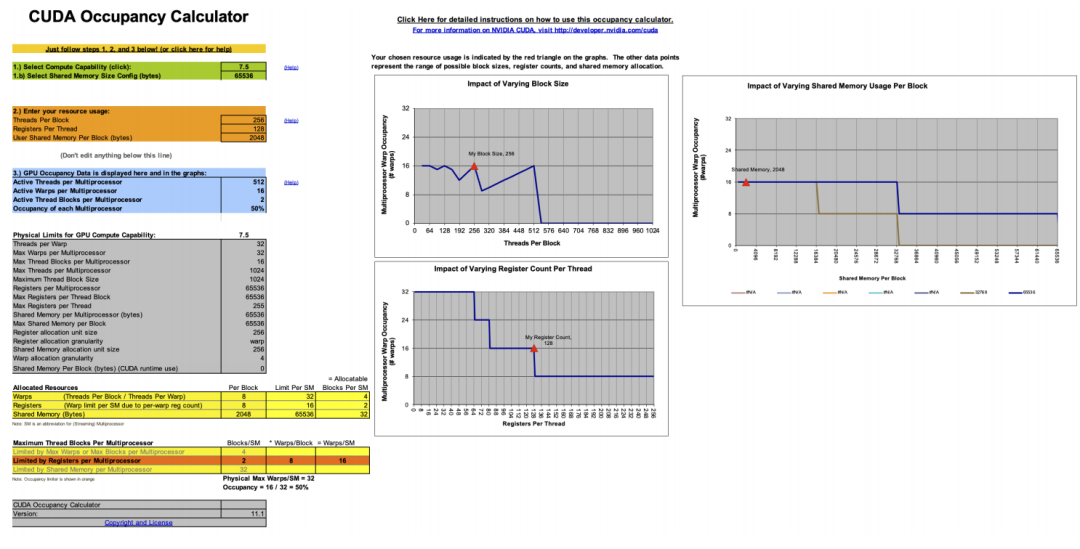
例如我们每个 thread 需要 128 个寄存器,2048 bytes 的 shared memory,那么由于 RTX 2080 每个 SM 只有 65536 个寄存器,因此每个 SM 最多只能同时跑 512 个 threads。又因为每个 SM 最多能够承载 1024 个 threads,所以此时 Occupancy 为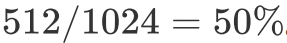 。
。
值得一提的是,虽然较高的 Occupancy 使得在一个线程卡住时,SM 能够马上切换到别的线程,通过将其他线程需要执行的指令填充到流水线中从而达到覆盖延迟的目的,但这并不代表高性能。例如,如果每一个线程本身就能够通过更多的寄存器占用从而达到延迟覆盖的目的,自然也就不需要 SM 来做这件事了,反倒是如果无脑的去提高 Occupancy 使得一些 thread 内的延迟甚至都无法被 SM 通过切换执行线程的方式覆盖,那属实是得不偿失了。
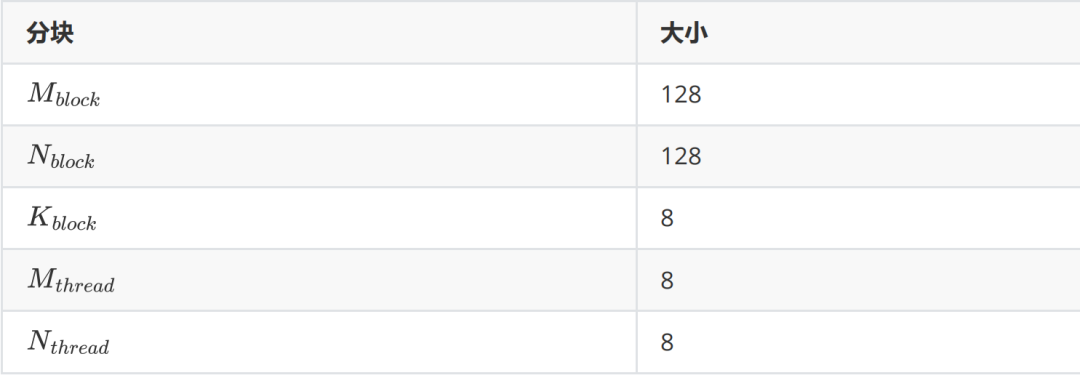
因此,我们能够做的就是在有一定理论分析的情况下确定好一些矩阵的分块大小的方案,然后要不就是经验性的去选择最终用哪个分块,要不就是跑一个 profile 来直接得到最快的分块。这里由于已经有非常多的先例证明了 128x128x8 是一个较优的选择,因此本文则遵从这个分块方案。那么,目前我们能够确定的分块如下表。
当然有些同学可能会问,既然最终还是需要用跑 profile 的方式来确定最优分块,那理论分析还有什么意义呢?答案就是如果提前通过理论分析,那么就能够在一定程度上缩小需要跑 profile 的分块数量。用算法上的语言来讲就是如果我们将需要搜索的所有分块作为搜索空间,那么理论分析便是搜索算法中的 A* 算法,你掌握了越多的理论分析知识那么这个搜索过程就会越高效。同时对 CUDA 底层越了解,在同一个分块策略下,你更容易写出能达到理论性能的 kernel。
Thread 级优化
对于一个 thread 能做的优化其实并不多,因为 GPU 是以一个 warp(即 32 个 thread)进行调度的,所以许多基于单线程的优化,如访存优化,其实并不能直接套到 GPU 上。而为数不多值得一提的优化手段便是单个线程在计算时应该采用向量内积还是向量外积以及 double buffer。但实质上向量外积严格意义上也不能算作是一个优化,因为这一步编译器就能在编译阶段帮忙做了。之所以提一句是还是为了给 double buffer 做铺垫,即我们应该怎么预取数据。
首先我们取了 128x128 的分块策略,一个 Block 有 256 个线程,那么每个线程需要负责一个 8x8 的矩阵乘运算。而一个线程完成一个小型矩阵乘有两种实现方法。
向量内积
向量内积的实现方法如图所示,即将 A 矩阵拆分为多个行向量、B 矩阵拆分为多个列向量,这些向量通过向量内积的方法求得最终答案。
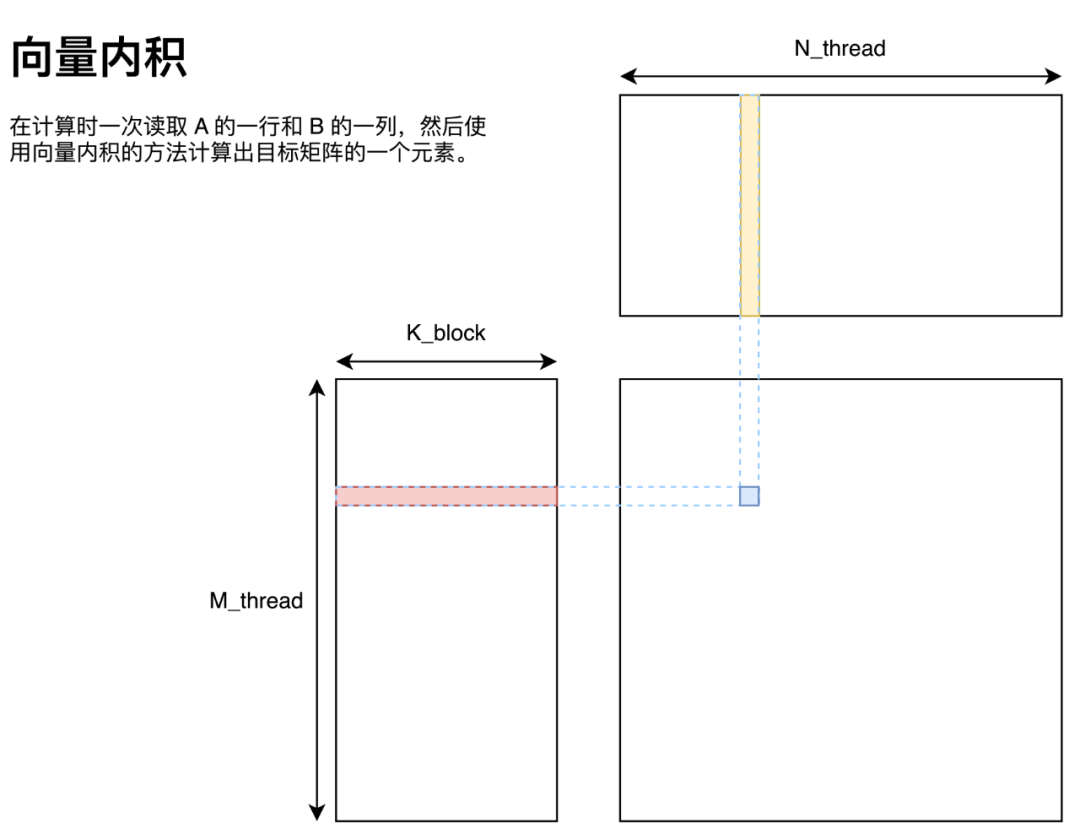
用代码描述如下:
M=N=K=8;float a[M*N];float b[N*K];float c[M*N];for i in range(M):for j in range(N):for k in range(K):c[i*N+j]+=a[i*K+k]*b[k*N+j];
向量外积
向量外积的实现方法如图所示,即将 A 矩阵拆分为多个列向量、B 矩阵拆分为多个行向量,这些向量通过向量外积的方法求得最终答案。
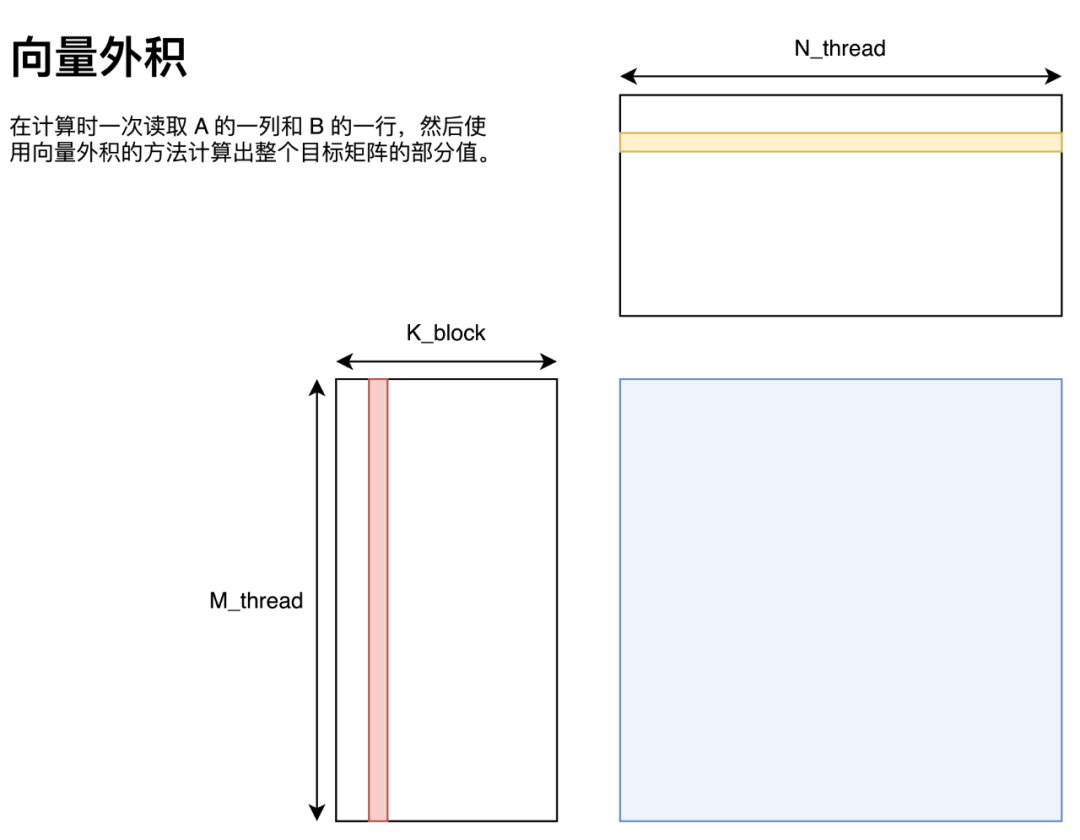
用代码描述如下:
M=N=K=8;float a[M*N];float b[N*K];float c[M*N];for k in range(K):for i in range(M):for j in range(N):c[i*N+j]+=a[i*K+k]*b[k*N+j];
可以看到,向量内积和向量外积的区别在代码上仅仅体现在循环方式上。
为何我们需要关心这个?
有做过 CPU 矩阵乘优化的同学可能知道,仅仅调整循环顺序就已经能够带来显著的性能差异了。有许多分析都是从局部性的角度进行分析的。即使用向量外积的方案可以利用到循环遍历的局部性,将一些重复访存使用寄存器缓存而避免无意义访存。例如我们补充一下采用向量外积方案关于寄存器的细节。
float a[M*N];float b[N*K];float c[M*N];for k in range(K):regB[0:N] = b[k*N:(k+1)*N]for i in range(M):regA = a[i*K+k];for j in range(N):c[i*N+j]+=regA*regB[j];
其中 regA 和 regB 均为寄存器。其中我们不难发现,对于每一次循环 j ,使用的都是完全相同的 A 矩阵里的元素,因此可以用一个寄存器来缓存该值;对于每一次循环 k,使用的都是完全相同的一行 B 矩阵中的值,因此我们可以用 N 个寄存器缓存该值。于是将原本 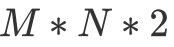 次访存(底下两层循环需要访问一次 A 矩阵和一次 B 矩阵),通过使用
次访存(底下两层循环需要访问一次 A 矩阵和一次 B 矩阵),通过使用 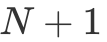 个寄存器缓存(B 使用 N 个,A 使用一个),优化为 N+M 次访存。同时我们也注意到, M 和 N 越大的情况下,提升效果越发显著,这也是为什么我们希望每一个线程负责的分块大一点比较好。但同时 M 和 N 越大,每一个线程多使用的寄存器就越多,而在 GPU 的语境下,更高的寄存器占用意味着更低的 Occupancy。因此当 M 和 N 大到 shared memory 带宽不是性能瓶颈即可。更详细的分析可以看李少侠的分析。
个寄存器缓存(B 使用 N 个,A 使用一个),优化为 N+M 次访存。同时我们也注意到, M 和 N 越大的情况下,提升效果越发显著,这也是为什么我们希望每一个线程负责的分块大一点比较好。但同时 M 和 N 越大,每一个线程多使用的寄存器就越多,而在 GPU 的语境下,更高的寄存器占用意味着更低的 Occupancy。因此当 M 和 N 大到 shared memory 带宽不是性能瓶颈即可。更详细的分析可以看李少侠的分析。
而我则从循环展开的角度解释一下为什么我们需要了解这个优化方案,同时解释一下为什么该优化方案在 GPU 上并不如 CPU 上那么有效。从循环展开的角度来看,第二种循环体构造与第一种循环最大的区别就在于它能在不展开 k 的情况下通过展开 m 和 n 处的循环就能自动的识别到重复访存,并使用相应的寄存器来避免重复访存。例如我们假定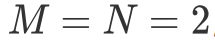 ,那么展开 m 和 n 处循环的结果如下。
,那么展开 m 和 n 处循环的结果如下。
M=N=2;float a[M*N];float b[N*K];float c[M*N];for k in range(K):c[0*N+0]+=a[0*K+k]*b[k*N+0]c[0*N+1]+=a[0*K+k]*b[k*N+1]c[1*N+0]+=a[1*K+k]*b[k*N+0]c[1*N+1]+=a[1*K+k]*b[k*N+1]
只要是稍微现代一点的编译器,都能一眼看出这四条指令的 8 次访存,有 4 次是可以合并的。同时现代一点的编译器也能在一定程度上根据生成的汇编交叉排列计算和访存达到延迟覆盖的目的。而向量内积的方案需要把整个 k 维度展开才能看到这些潜在的访存合并机会。在 CPU 矩阵乘的语境下,一般计算 kernel 的 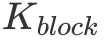 都比较大(好几百),而
都比较大(好几百),而  都很小(一般取 6x16,根据架构来做具体确定),寄存器数量又非常少,因此基本上无法在 K 维上将循环完全展开并做优化。因为展开一个超长的循环不仅会带来额外的寄存器占用、优化难度,还会带来更多的汇编指令,使得最终的二进制文件臃肿不堪。但在 GPU 上,情况却恰恰相反。对于已知循环次数的小循环,即便你没有指定 #pragma unroll,nvcc 也会自动的展开这些循环。而对于一个 thread 所负责的小型矩阵乘,这三层循环的值均为 8,符合 nvcc 自动展开循环的条件。而在展开完成后,nvcc 会对所有的访存以及计算指令重排得到一个不错的汇编指令排列。
都很小(一般取 6x16,根据架构来做具体确定),寄存器数量又非常少,因此基本上无法在 K 维上将循环完全展开并做优化。因为展开一个超长的循环不仅会带来额外的寄存器占用、优化难度,还会带来更多的汇编指令,使得最终的二进制文件臃肿不堪。但在 GPU 上,情况却恰恰相反。对于已知循环次数的小循环,即便你没有指定 #pragma unroll,nvcc 也会自动的展开这些循环。而对于一个 thread 所负责的小型矩阵乘,这三层循环的值均为 8,符合 nvcc 自动展开循环的条件。而在展开完成后,nvcc 会对所有的访存以及计算指令重排得到一个不错的汇编指令排列。
那么这就引出了下一个问题,我们为何还需要关心他究竟是向量内积还是向量外积?
答案就是 double buffer。如果我们能够提前知道一个循环需要什么数据,我们就能提前预取该循环第一次所需的数据,同时在该循环进行运算的时候预取下一次计算所需的数据。而显然这在向量内积的情况下是无法做到的。同时由于 double buffer 需要额外的寄存器保存从 global memory 转移到 shared memory 的数据,所以当一开始循环展开使用的寄存器过多时,尽管后续能优化到较少的寄存器,但编译器依然无法正确的在限定寄存器数量下实现 double buffer。这一点在优化 sgemm 的时候并不是那么重要(因为多使用一点寄存器也就从每个 SM 跑两个 block 变为一个 block),但是在优化 int8 矩阵乘时需要额外的关注(因为本身它就只能在一个 SM 上跑一个 block,如果实现不得当将会完全失去 double buffer)。
那么此时朴素的利用到向量外积和 shared memory 的代码:https://github.com/AyakaGEMM/Hands-on-GEMM/blob/main/src/cuda/shared_mem_gemm.cu
Double Buffer
由于 GPU 没有 prefetch 这种指令,同时我们又有 shared memory 这种可编程的 L1 cache,因此需要手动实现 prefetch 功能,而在 GPU 语境下一般被称作 double buffer。double buffer 的好处自不必多说,即它可以实现数据读取与计算在时间上重叠,利用 FFMA 单元与 Load/Store 单元可以并行执行指令的特点,达到覆盖延迟的目的。而尽管 GPU 可以在一个 warp 有延迟的情况下,通过切换去运行另一个 warp 达到延迟覆盖到目的,但由于可供 warp 调度器能切换到线程数量的限制,过于长的延迟并不能通过这种方式覆盖掉。这里引用一下李少侠更详细的分析:
若每 SM 有 4 个调度器,若每个调度器只有 4 个可调度 warp,当指令平均间隔超过 4 cycle 后就无法靠 warp 调度掩盖延迟了。考虑到 GEMM 中涉及 smem 读写的过程需要同步 thread block,进一步限制了 warp 调度空间,所以很难靠 warp 并行掩盖延迟。
而本文最终实现的 kernel occupancy 只有 50%,即每个 SM 只能调度 512 个 threads(16 warps),加上图灵架构每 SM 有 4 个 warp 调度器,最终结果与李少侠分析的一致。因此 double buffer 从指令角度提供的延迟覆盖方法最终还是会有效的。
但值得一提的是,在你自己动手实践时,尽可能的考虑在其他优化已经加无可加的情况下再加入这个优化。这是由于这个优化会大幅修改数据读取部分的代码,而且还会产生重复代码,不利于代码维护。同时在我自己的实践中发现,如果在一开始 kernel 写的比较垃圾,加了 double buffer 也没有什么卵用,还会让后续的优化不太好加上去。当然,这只是我的个人建议,如果你想实际看看 double buffer 的效果也可以一开始就加上去。
首先我们看一下每个 thread 的运行流程。

那么能实现 double buffer 的机会有两个地方:Global Memory to Shared Memory 与 Shared Memory to Register。即在每一次 FFMA 开始之前我们读取 Global Memory 的数据到寄存器中,在 FFMA 之后将该寄存器中的值写到 shared memory 中。由于在读取数据后 load from shared memory 以及 FFMA 两个流程中我们并不依赖于该寄存器中的数据,因此可以覆盖 Global Memory 的读取延迟。而同时在计算每一次 FFMA 之前,我们可以用寄存器提前取下一次 FFMA 需要的数据,也就能做到覆盖 shared memory 的延迟。
大概就是这样!我们在每一次运算之前提前将第一次循环所需的数据移动到寄存器中,这样我们就可以实现数据运算和数据存取指令级并行的功能了。
Warp 级优化
在做了不少铺垫之后,接下来的优化终于是可以带来一些看得见的性能提升的了。首先回顾我们之前的代码,可以看到每个 thread 负责的部分完全没有考虑到它们之间可能的协作关系,即同一个 warp 内的 thread 此时在同一块硬件上同时执行——它们共享同一个 register file,这表明它们可以通过寄存器快速共享数据(即 shared memory 的 broadcast 机制);它们会同时访存,这表明如何安排每一个 warp 内的 thread 访存是至关重要的。
Warp Tiling
已知我们指定一个 Block 计算 128x128 的矩阵,一个 Block 有 8 个 warp,一个 warp 有 32 个 thread,每个 thread 需要负责 8x8 的小型矩阵乘,那么我们沿用李少侠的定义:
一个 warp 由 个线程组成,可以是
,我们把这些线程对应的 thread tile 拼在一起的区域称为 warp tile,尺寸为
,如下图所示。
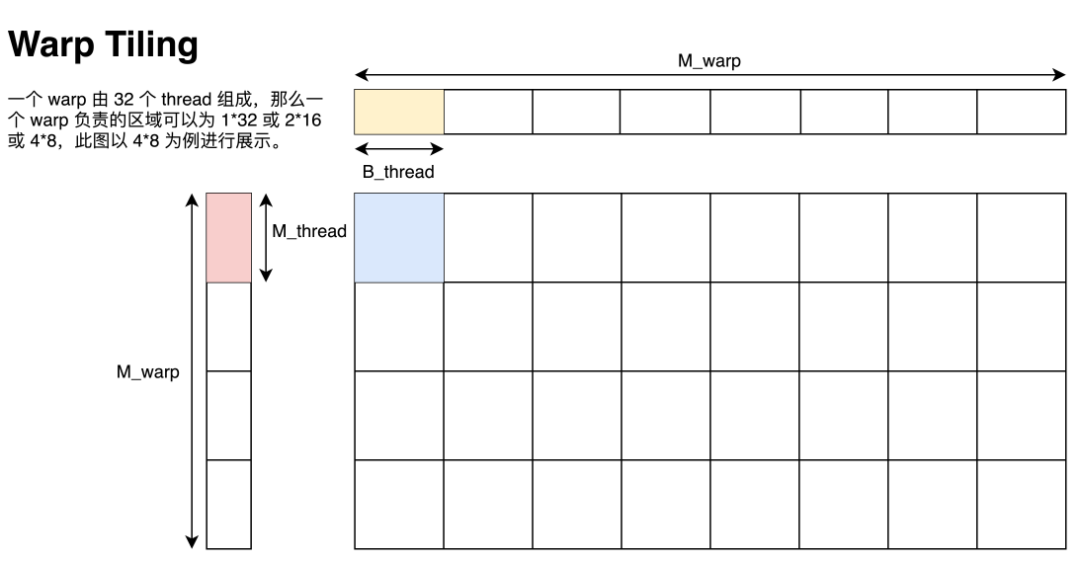
这里的图给的是  的排列方式。由于同一个 warp 在访问 shared memory 时有 broadcast 机制(即同一个 warp 在访问同一个内存地址内的值时只会实质发生一次数据读取),因此这一个 warp 计算时只会实际读取
的排列方式。由于同一个 warp 在访问 shared memory 时有 broadcast 机制(即同一个 warp 在访问同一个内存地址内的值时只会实质发生一次数据读取),因此这一个 warp 计算时只会实际读取 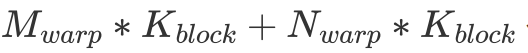 个 float。与之相对的,这个 warp 会进行
个 float。与之相对的,这个 warp 会进行 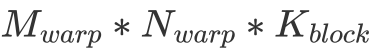 次 FFMA。不难看出,在
次 FFMA。不难看出,在  固定为 32 的情况下,
固定为 32 的情况下,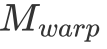 与
与 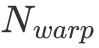 越相近,计算访存比就越大,因此取
越相近,计算访存比就越大,因此取  最为合适。
最为合适。
而在确定了 warp tiling 后,如何读取和存储数据的细节还需要细扣,接下来我将会按照 GPU 的硬件特性讲解读写数据的细节。但这一部分的大致思路基本已经介绍完毕了,动手能力强的同学现在就可以自己试试如何写一个高效矩阵乘了!
向量化访存
向量化访存即是一条指令同时请求多个 float 数据,目前 CUDA 最高支持 128 bit 的向量化访存,即一条指令请求 4 个 float 数据。向量化访问主要的好处在于可以用更少的指令读取更多的数据。由于在访问全局内存时是以 32 Byte 为粒度进行访问的,因此如果同一个 warp 内的 thread 请求了一段连续内存的数据,每一个 thread 都请求两次 4 Byte 的数据(小于 GPU 全局访存的最小单位),那么 GPU 会在硬件处将 64 次数据请求按照 32 Byte 进行合并,最终形成 8 次 32 Byte 内存访问。
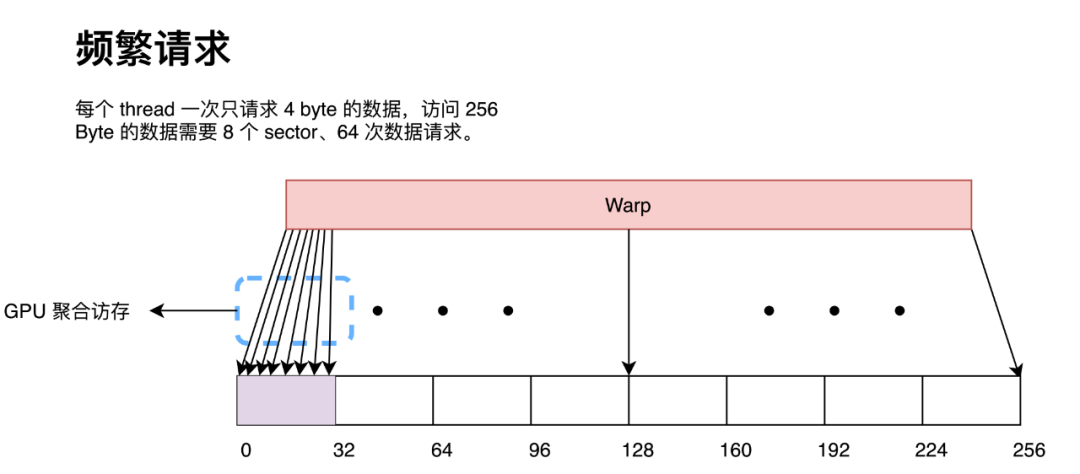
而如果每一个 thread 请求 8 Byte 数据,那么 GPU 会在硬件处同样将 32 次数据请求按照 32 Byte 进行合并,最终形成也形成 8 次 32 Byte 内存访问。
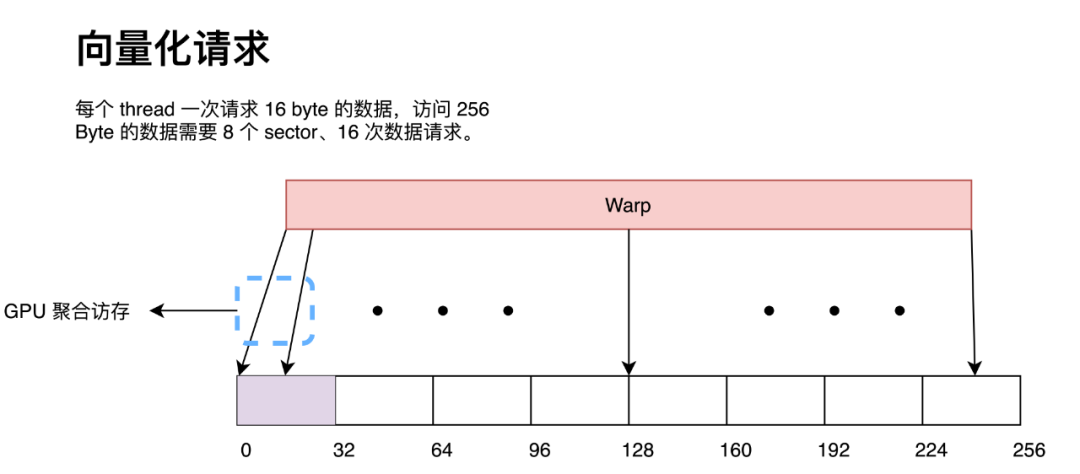
那么我们可以看出,对于访问同一数据量的数据,请求的指令越多,GPU 的聚合访问的压力就会越大。在极端情况下,尽管带宽足够,但大量的访存请求会塞满访问队列导致 stall。这在 Nsight Compute 中显示为 MIO Throttle 和 LG Throttle,即对应 shared memory 和 global memory。因此采用向量化访存能在一定程度上缓解 GPU 硬件层面的聚合访存压力(因为我们显式的用指令告诉 GPU 某些数据请求不需要聚合,直接用一个 sector 来处理就好了)。
但使用向量化访存——即用 float4 读写数据——也不是完美的。它的一个严重缺陷在于使用 float4 访存要求请求的数据地址要按照 float4 对齐,因此当 M、N、K 不为 4 的倍数时将会报 missaligned address 错误(因为第二行开始就不能按照 float4 对齐了)。
这么干对输入矩阵形状有一定要求,写出来的矩阵乘没有特别好的通用性。同时 sgemm 受聚合访存的影响也并不是那么大,因此在实操中往往并不会选择使用 float4 读写全局内存,而只会使用 float4 读写 shared memory。但由于我一开始学 CUDA 的时候对这一块理解也不深,然后发现许多人(李少侠除外)都很暴力的直接用 float4 读写全局内存,于是我也用了 float4 读写全局内存。
而我们这里对比李少侠的 kernel profile 和我们最终的成品发现,在 global memory 读取处是否使用向量化读取其实并不会对性能有多少影响。可以看到最终 profile 出来的 Stall LG Throttle 和 Stall MIO Throttle 占比都不高。
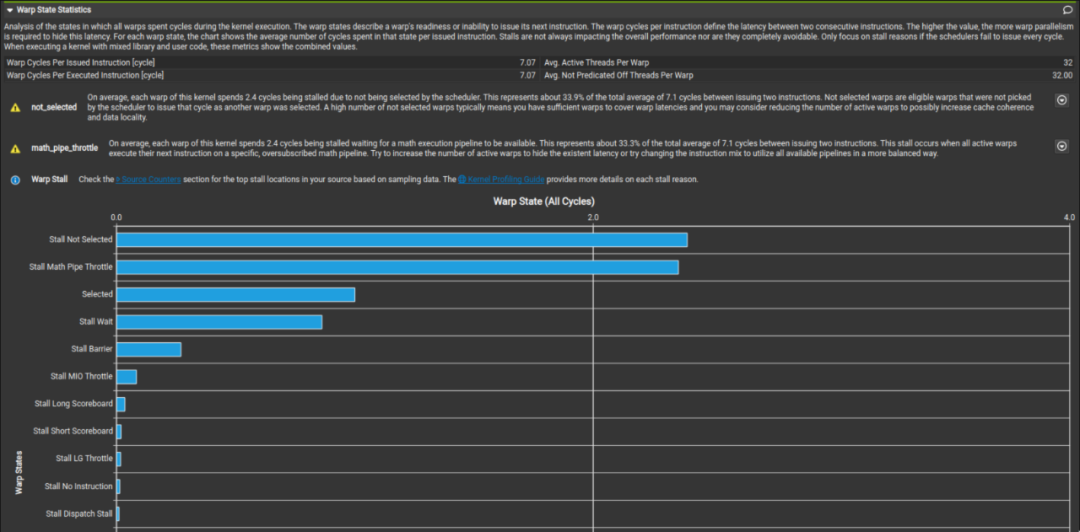

上图为李少侠的 kernel 下图为我最终写的 kernel。这两个 kernel 在数据读取方面的区别就是李少侠是以 4B 为单位访存的,而我是以 16B 为单位做访存的。这进一步印证了 sgemm 其实并不是非常关心读取 global memory 时是以怎样的粒度读取的。而向量化访存对于 shared memory 的影响就留给读者自行验证了。同时值得注意的是,在把数据读取方式从向量化访存修改为一个一个访存时需要注意 bank conflict 的问题。因为一个 warp 在执行 128-bit load 和 32-bit load 时的调度并不相同(这点会在后面提到)。
还有一个值得注意的是在 Global Memory 访存时,并不能直接将原先的向量化存取代码直接改成一个一个的读取。因为这样访存从原来一个 warp 并行访问一段连续的内存变成一个 warp 分成四次访问不连续的内存。虽然有 L2 cache 来平滑这种不规则的访存,但最终会带来 10% 左右的性能下降。代码如下:
// Original CodepreA = *reinterpret_cast<const float4 *>(baseA + i + rowA * K + colA);// Modified CodepreA.x = baseA[rowA * K + i + colA];preA.y = baseA[rowA * K + i + colA + 1];preA.z = baseA[rowA * K + i + colA + 2];preA.w = baseA[rowA * K + i + colA + 3];
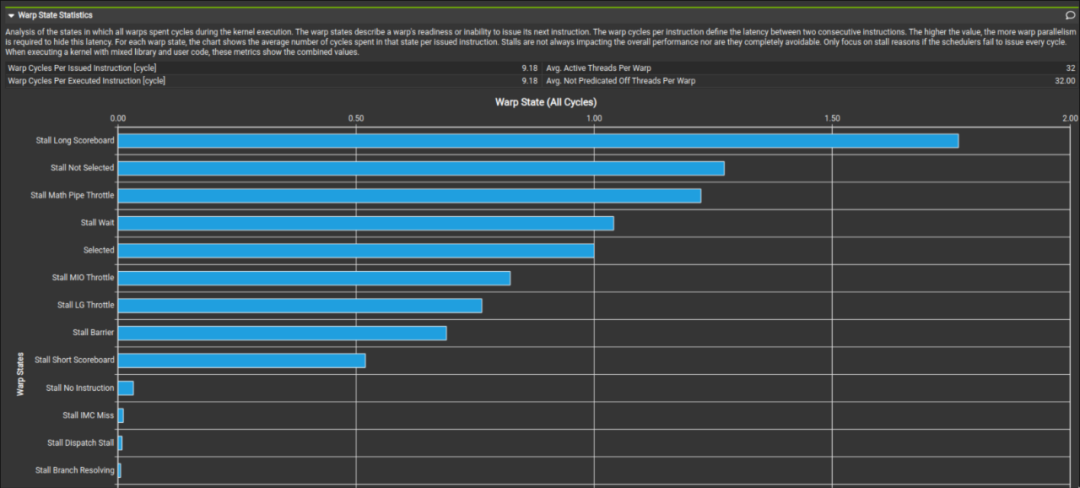
可以看到这种简单的更改其实并不可取,更优的写法是每一条指令都是在 warp 视图下的连续访存。
Global Memory
前面提到 GPU 访存时以 32 Byte 为粒度进行访问的,那么一个 32 Byte 访问被称为一个 sector。那么值得注意的就是在搬运数据时,尽可能的让同一个 warp 搬运同一行的数据来避免使用额外的 sector(本文采用现代的行主序来存储矩阵)。
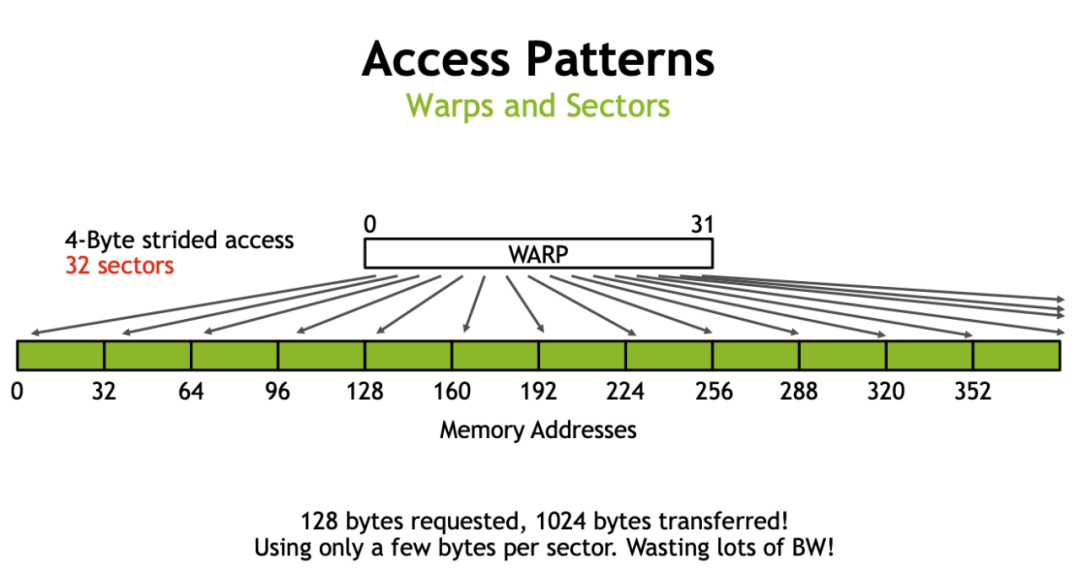
这里借用一下 Nvidia 的图。如果同一个 warp 内的 thread 都访问每一行的开头,那么如果一行超过 8 个 float,那么每一个 thread 都需要一个 sector 去请求它们需要的数据,这就造成了 sector 浪费。而实际中每一行的元素往往都会大于 8 个 float,因此会有非常大的性能损失。下图为一个 warp 在拷贝时,每个 thread 之间间隔的大小,单位为 float。可以看到在间隔为 2 时就已经有一半的性能损失了,这很不好。
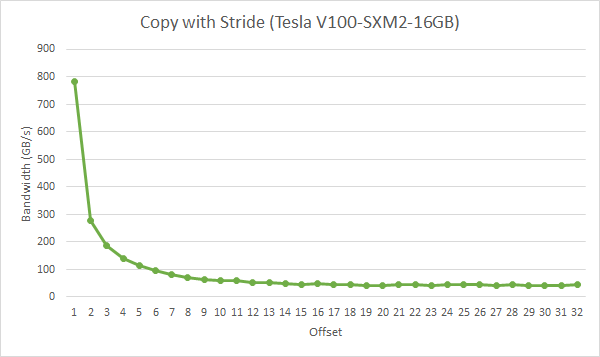
因此我们采用下图所示的访问方式。即尽可能的让一个 warp 中的 thread 连续的读取 Global Memory 中的元素。
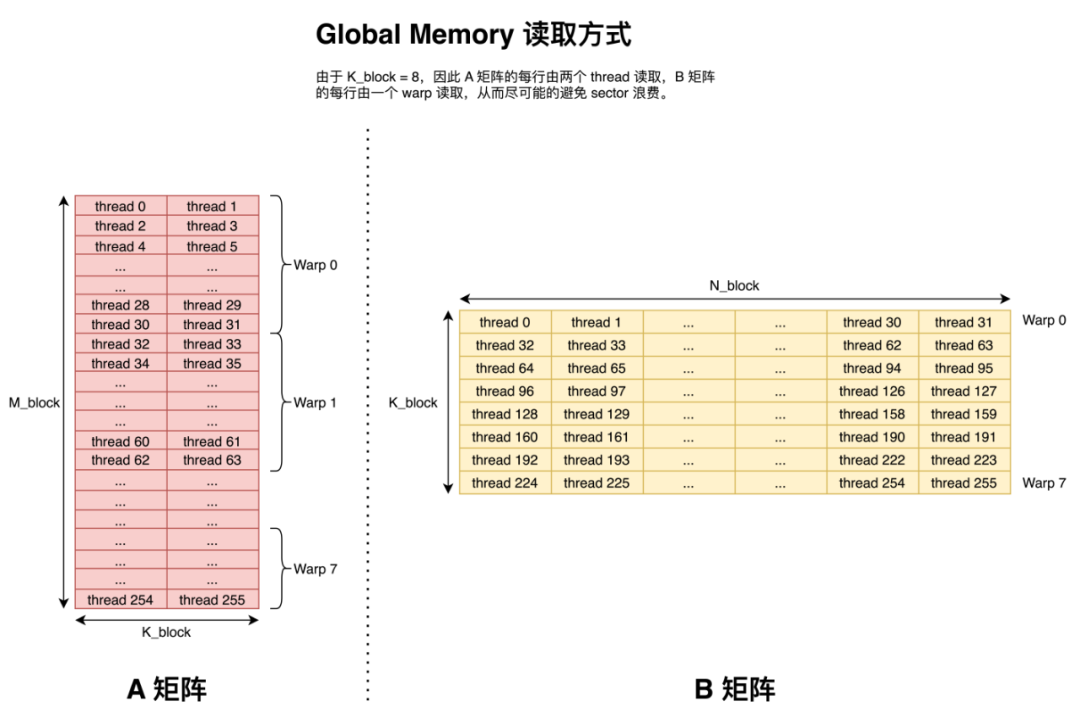
Shared Memory
前文已经讲过,shared memory 在图灵架构之后可以完全被看作是 L1 cache。而在此基础之上,shared memory 的访问粒度是 32 bit 也就是 4 Byte,刚好是一个 float 数据的大小。而后 shared memory 按照 4 Byte 连续的划分为一个个 bank。对于 bank 可以简单的理解为双通道内存中通道的概念,即在不同的 bank 中的数据可以并行访问,同一个 bank 内不同地址的数据只能串行访问。在 Compute Capability 5.x 及之后的卡上,shared memory 具有 32 个 bank,刚好是一个 warp 中线程的数量。而如果同一个 warp 中不同 thread 均只访问 4 Byte 数据且希望同时访问同一个 bank 的数据将会有两种结果。(对于每一个 thread 访问更多数据的行为将在后面提到)
1. 两个或多个 thread 访问的刚好是同一个地址内的数据,那么此时将会触发 broadcast 机制,即实际只读取一次数据,而后广播到这些 thread 中。
2. 两个或多个 thread 访问的是同一个 bank 内的数据,那么此时这些 thread 的访问将会被强制安排为串行执行。这种访问情况被称为 bank conflict。
这里给出 cuda programming guide 的两张图来直观的体现 broadcast 和 bank conflict。
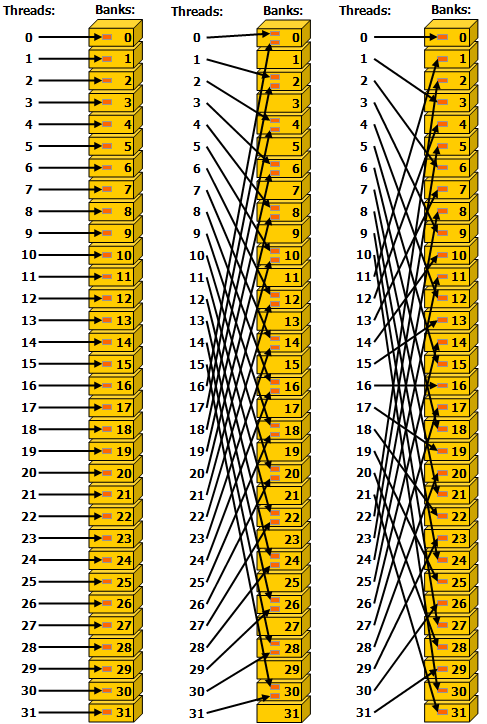
这张图表示同一个 warp 中的 thread 按不间隔、隔一个、隔两个 bank 对 shared memory 访问。中间的访问每两个 thread 都会发生一次 bank conflict,而其他两种访问都不会发生 bank conflict。值得注意的一点是这张图最右侧的图的访问方式刚好可以达到每一个 thread 都访问了不同的 bank 的效果。
同时考虑到 shared memory 是按照 bank 来访问的,且与 Load/Store 单元直连,并没有中间商赚差价,所以对于 shared memory 的访存并不讲究连续访存,而只需要考虑是否有 bank conflict 就足够了。因此理论上最左和最右两列图的访问性能是一样的,这与访问全局内存有一点区别。同理,每一个 warp 连续的多次访存也并不要求连续访存,而在拷贝数据到 shared memory 时对 A 矩阵做矩阵转置的目的是为了向量化访存,而不是为了连续访存。
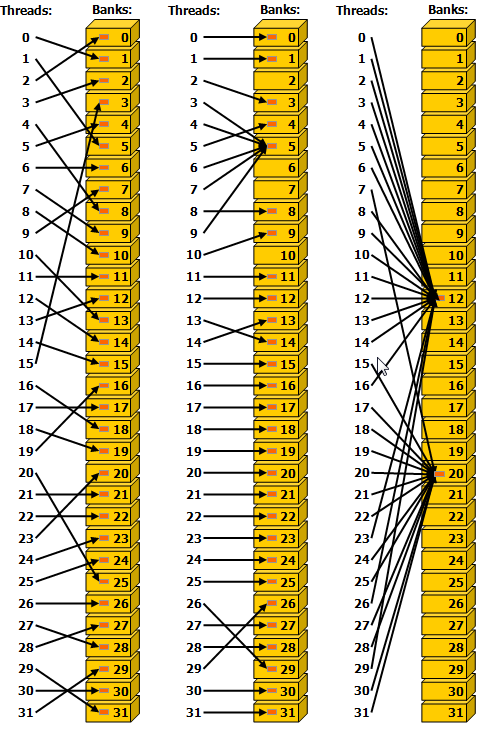
这张图则展示了 broadcast 机制,没啥好说的。
128-bit conflict-free store
而前文中提到,我们使用 float4 来做数据传输来缓解 GPU 聚合访问的压力,使得每一个指令都更加高效。而又因为前文所述,每个线程需要使用向量外积的方法计算矩阵乘,因此我们需要在 A 矩阵转存到 shared memory 时做一次转置。
但细心的同学可能注意到,如果就这么平铺直叙的做转置那么将会发生非常严重的 bank conflict,因为一个 warp 内的奇数 thread 和偶数 thread 使用同一个 bank。那么此时解决 bank conflict 的方法有两种,第一种便是将 shared memory 的 k 维度缩小,然后直接把奇数 thread 所取的数据直接并到 M 维上,就不会有 bank conflict 的问题了。这种方法通过 index 变换,直接就能避免 bank conflict,非常巧妙,而我当时没有想到,就没有用这种方法。值得注意的是,尽管图是按行隔开的,但那只是为了表示数据是如何在一个 thread 里保存的,实际写到 shared memory 中是以一个 float 为单位,按列主序存储到 shared memory 中。
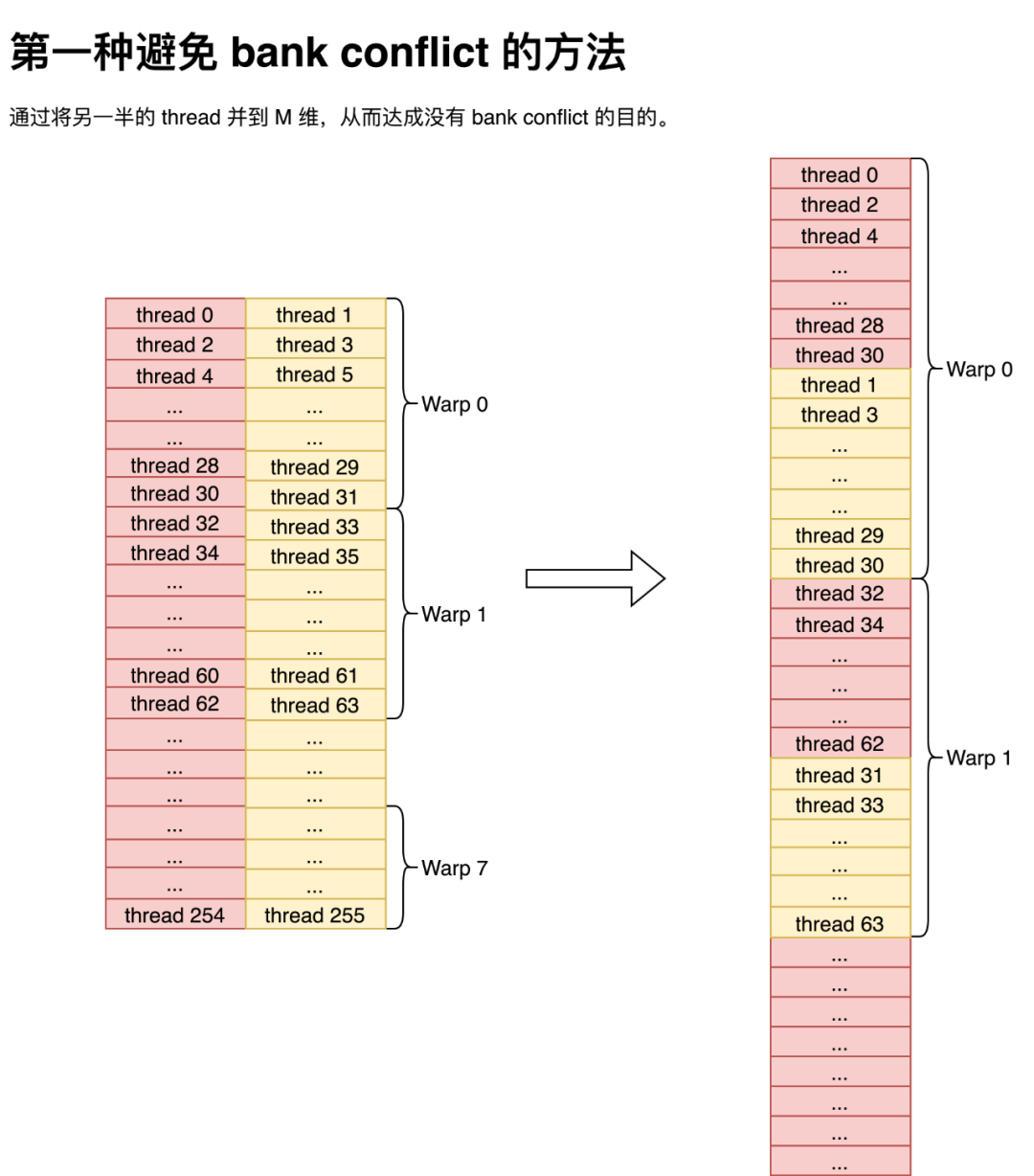
而第二种方法就非常简单粗暴了,直接往 lda 上加 4,然后就不会有 bank conflict 了。当然这种方法的弊端也是有的,那就是会造成一部分 shared memory 的浪费。但对 sgemm 来说倒也还好, shared memory 的占用也不是导致 Occupancy 降低的原因,所以我就用了这个方法。
128-bit conflict-free load
而我们把数据存储到 shared memory 之后,下一步便是考虑如何在没有 bank conflict 的情况下将数据读取出来。在本文中,我们取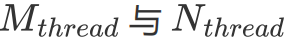 为 8,在采用向量化存取时,直接按照 Warp Tiling 采用朴素的存取方法就能在没有 bank conflict 的情况下把数据读出来了。
为 8,在采用向量化存取时,直接按照 Warp Tiling 采用朴素的存取方法就能在没有 bank conflict 的情况下把数据读出来了。
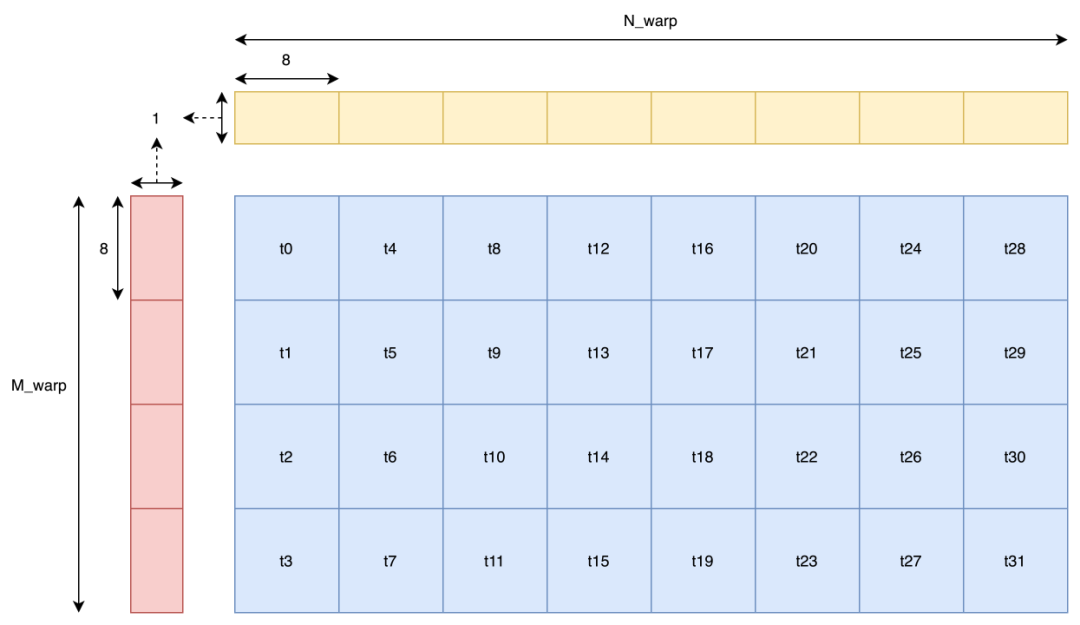
当然有的同学可能会问:既然访存是按照一个 warp 为单位进行的,而图中明显读取 B 矩阵时,t16 会和 t0 发生 bank conflict,那为什么又说不会有 bank conflict 呢?那么答案就是在做 128-bit 访存时,warp 并不是同时读取数据的。这里还是借用 Nvidia 在 GTC 2018 上的分享来做说明。

当 warp 中每个 thread 只读取 4B 或更小数据时,warp 才是同时读取的。而本文中采用 128-bit 也就是 16B 读取,那么一个 warp 会分成 4 次操作读取,每次操作只有 1/4 warp 工作。那么只要同一次操作内的 thread 没有发生 bank conflict,那么就没有 bank conflict。而上图中 t0-t7 同时操作,它们之间并没有 bank conflict,后面的 thread 依此类推,那么也就不会有 bank conflict。那么朴素的 warp tiling 实现代码在这:https://github.com/AyakaGEMM/Hands-on-GEMM/blob/main/src/cuda/warp_tile_gemm.cu
而李少侠在代码中采用了一种更高级的排布方式,即 z 字排布。与之相对应的,他将一个 thread 负责的小型矩阵乘拆分成四个更小的矩阵乘。同时这个拆分虽然是在地址上做的拆分,但在运算中依然可以看作是一个整体,即运算部分不用更改任何代码而只需要在 index 上做一些变换即可。而他这么做的理由是为了更快的 broadcast。但说实话,我不是很理解,也没搜到为什么这样能有更快的 broadcast 性能。(而且我这么试了一下,发现确实是快了,这实在是太神奇了,欢迎大家提供一些看法。)
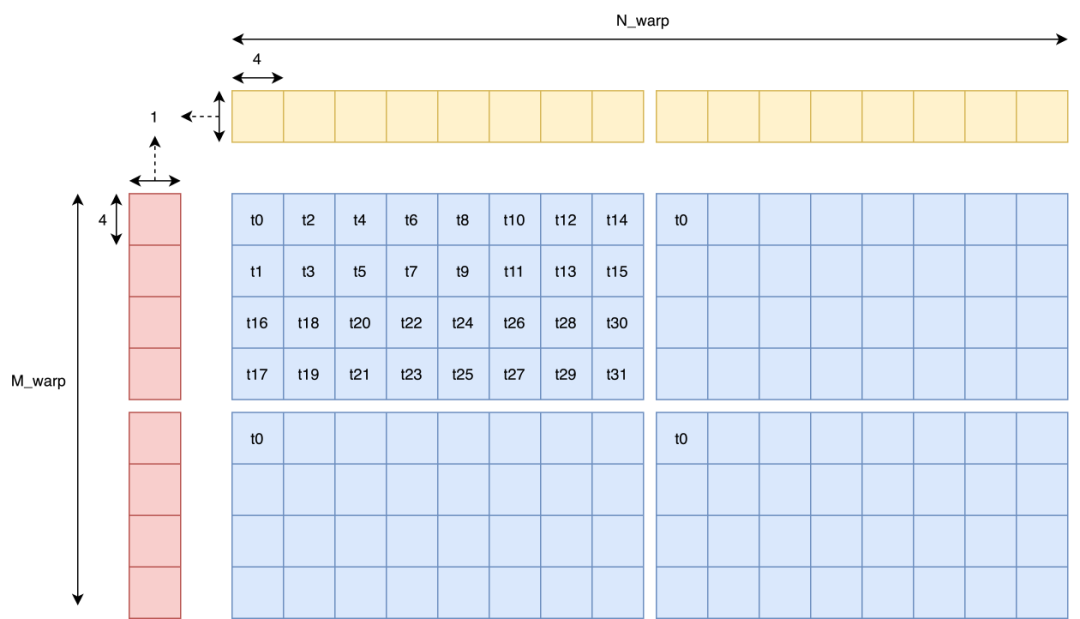
这里我们跑一个 profile 发现,确实是没有 bank conflict 的,挺好。代码在这:
https://github.com/AyakaGEMM/Hands-on-GEMM/blob/main/src/cuda/z_thread_map_gemm.cu

Block 级优化
Block 在 GPU 上基本等同于不同的 kernel 在 GPU 上运行了,所以它们之间的联系并不是特别强烈。而它们之间的相互关系在 GEMM 语境下基本就只有 wave 和 L2 cache(一个 wave 里的 Block 共享这一块 cache)了,良好的 Block Tiling 能提升相当可观的 L2 cache 命中率。
但这一部分属于 sgemm 并不是特别关心的部分,因为本身 FFMA 单元算的就不是很快,所以 Block Tiling 随便搞搞就能够满足 FFMA 单元的带宽和延迟需求了。因此,这一节的内容主要是为了有些有用到 tensor core 的同学提一个需要注意的性能提升点,其次就是有些同学可能会发现自己写的 kernel 可能会比本文中的示例慢一点(大约 10% 左右),因此在此提一下在 sgemm 中应该怎么随便搞搞 Block Tiling。
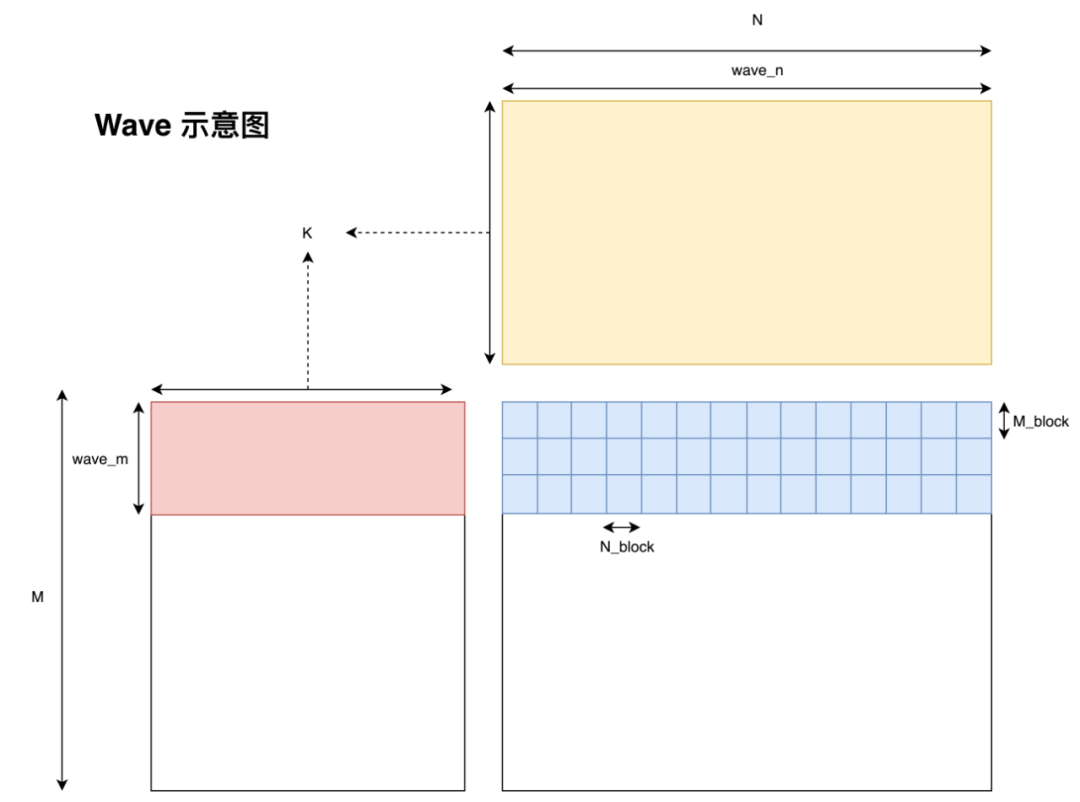
Wave & L2 cache Hit Rate
首先明确一下 wave 的概念,即一个 GPU 上能够同时运行的 Block 数量。关于 GPU 是如何决定一个 wave 由哪些 Block 组成的我并没有找到非常明确的文档说明,但我一拍脑袋想,说不定就是朴素的按顺序决定的,即 index 处于 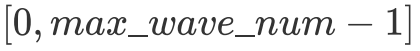 范围内的 Block 处在第一个 wave 中,后面的 Block 依此类推。后面试了试好像的确是这样划分的。
范围内的 Block 处在第一个 wave 中,后面的 Block 依此类推。后面试了试好像的确是这样划分的。
在明确了 wave 的概念后,我们便可以对 L2 cache 命中率做一个简单的分析了。我们指定 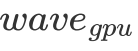 代表一个 wave 同时运行的 Block 数量,假设一个 wave 刚好能计算 C 矩阵的整数行,那么我们不难发现对于一个 wave 而言,它需要从 Global Memory 中读取
代表一个 wave 同时运行的 Block 数量,假设一个 wave 刚好能计算 C 矩阵的整数行,那么我们不难发现对于一个 wave 而言,它需要从 Global Memory 中读取 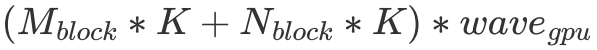 个 float。但由于有 L2 cache 的存在,假设一个 wave 读取的数据全能被 L2 cache 装下,那么实际只读取了
个 float。但由于有 L2 cache 的存在,假设一个 wave 读取的数据全能被 L2 cache 装下,那么实际只读取了 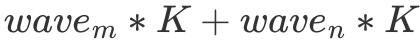 的数据。最终 L2 cache 的命中率为:
的数据。最终 L2 cache 的命中率为:
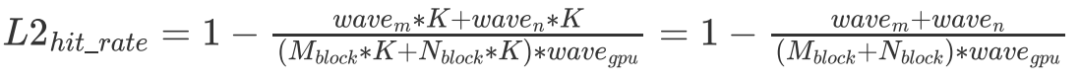
即  差距越大,L2 cache 的命中就越低。那么如果想要去优化 L2 cache 命中,一个比较直接的想法就是尽可能把一个 wave 的 Block 变成方的。但就算不搞,sgemm 也不在乎,因为其实对性能来讲并没有什么区别,所以就没搞。
差距越大,L2 cache 的命中就越低。那么如果想要去优化 L2 cache 命中,一个比较直接的想法就是尽可能把一个 wave 的 Block 变成方的。但就算不搞,sgemm 也不在乎,因为其实对性能来讲并没有什么区别,所以就没搞。
SGEMM Block Tiling
而在 sgemm 的语境下,假设最坏的情况即一个 wave 都不能覆盖目标矩阵 C 的一行,且 RTX 2080 有 46 个 SM,一个 SM 能跑两个 Block,此时
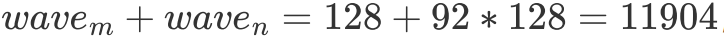
 ,
,
带入上式可得,此时 L2 cache 命中率大概是 49.4%。这里我们并没有考虑访问 C 矩阵的影响,在实践中会把 L2 cache 的命中率拉低一点。但即便是如此,前文我们分析过只要 L2 cache 命中达到 20%,在带宽上就不会造成性能瓶颈了。因此发现,就算我们采用朴素的 Block Tiling,Global Memory 访问也不会成为访存瓶颈。
但事实真的是这样吗?
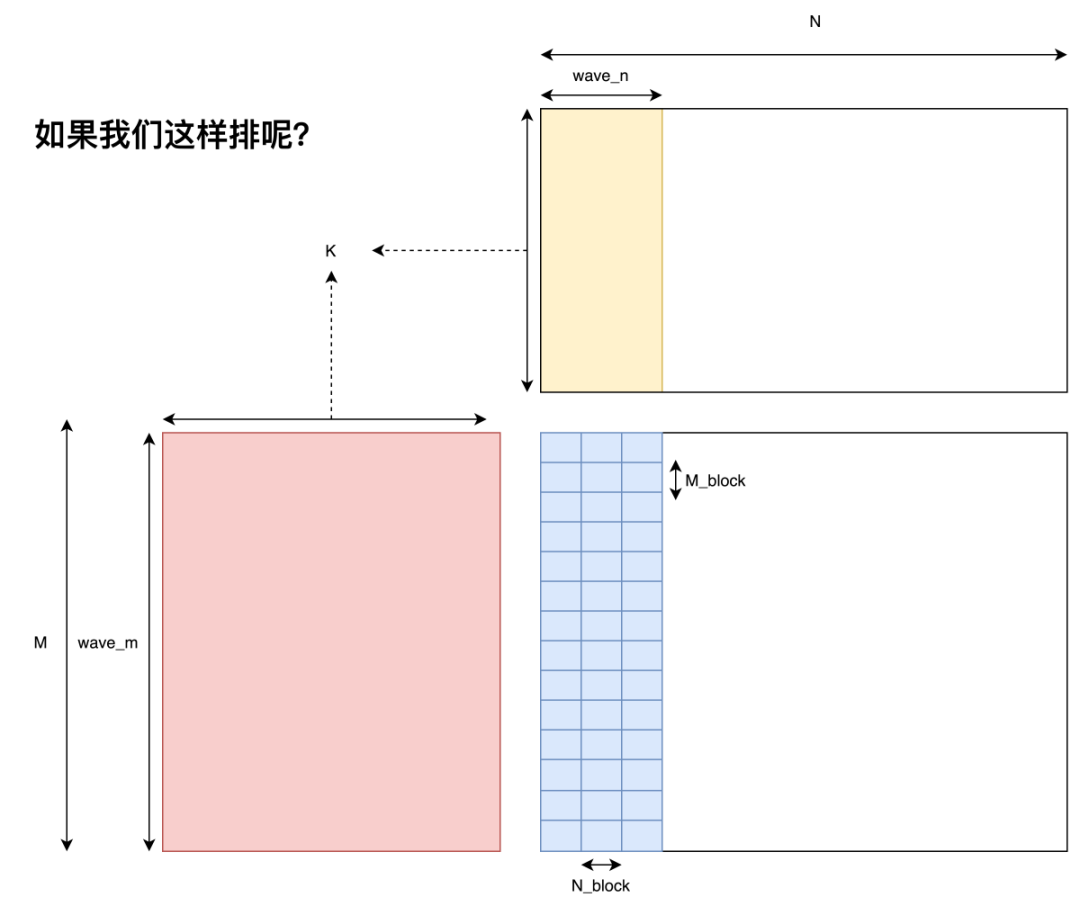
细心的同学可能会发现,上图所采用的 tiling 方式并不是直觉上的用 blockIdx.x 表示 Block 在 M 维上的位置,而是用 blockIdx.y 表示 Block 在 M 上的位置。而我们简单调换一下代码中 blockIdx.x 与 blockIdx.y 的顺序,瞬间就有了 10% 左右的性能差距。目前网上并没有针对这个现象的分析(因为几乎所有人都是用的 col major 的 data layout,而且李少侠直接就在代码里使用了更优的 tiling 方式,所以没有人遇到这个问题),因此我这里提出一点个人的猜想,如果猜的不对还请指正。
L2 cache
首先我们看一下这两种 tiling 方式的区别在哪。最为直观的区别就是当 N 或 M 足够大时,采用上图中的 tiling 方式的 wave 形状是横着的,而另一种 tiling 方式的 wave 形状是竖着的,而这种竖着的形状看起来就不是 cache 友好的访存方式。
为什么这么说呢?因为我采用的是行主序的方式存储的矩阵,因此如果一个 wave 的形状是扁平的,那么每个 Block 在每一次循环遍历 B 矩阵时只会有 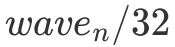 次 cache miss。这是由于 L2 cache 的 cache line 大小为 128 bytes,因此当数据从 Global Memory 中移动到 L2 cache 后,许多 Block 就能直接从 L2 cache 中读取数据了。然而如果一个 wave 的形状是狭长的。那么每个 Block 在第一次访问 A 矩阵的每一行时都会有 cache miss 的情况出现,即产生
次 cache miss。这是由于 L2 cache 的 cache line 大小为 128 bytes,因此当数据从 Global Memory 中移动到 L2 cache 后,许多 Block 就能直接从 L2 cache 中读取数据了。然而如果一个 wave 的形状是狭长的。那么每个 Block 在第一次访问 A 矩阵的每一行时都会有 cache miss 的情况出现,即产生 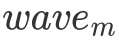 次 cache miss,而后 31 次的遍历都不会有 cache miss。虽然两种 tiling 方式最终 cache miss 的次数是一样的,但这种短时间爆发的 cache miss 所带来的延迟是非常难被各种优化手段覆盖的,因为这种延迟不仅短时间内有很多次,同时每一次的延迟都很长,所以会造成性能损失。因此以后高性能代码的开发中,也要注意合理的把 cache miss 分配到 kernel 运行的各个阶段。
次 cache miss,而后 31 次的遍历都不会有 cache miss。虽然两种 tiling 方式最终 cache miss 的次数是一样的,但这种短时间爆发的 cache miss 所带来的延迟是非常难被各种优化手段覆盖的,因为这种延迟不仅短时间内有很多次,同时每一次的延迟都很长,所以会造成性能损失。因此以后高性能代码的开发中,也要注意合理的把 cache miss 分配到 kernel 运行的各个阶段。
Bank Conflict
在查看两种 Tiling 方式的 profile 我发现,采用横着 Tiling 方式的 kernel bank conflict 更低一些。


等等,既然我们之前已经处理过 bank conflict 了,那么为什么这里还会有 bank conflict 呢?这个现象其实我也不是很清楚。但目前已知的是,在没有加 double buffer 情况下是没有 bank conflict 的,但加了 double buffer 之后或多或少会出现一些 bank conflict。那么至于为什么横着 Tiling 方式的 bank conflict 更低,我就更不知道了,因此这里还请各位 dalao 赐教。
最终版本的代码在这:https://github.com/AyakaGEMM/Hands-on-GEMM/blob/main/src/cuda/double_buffer_yhs_refine_gemm.cu
Epilogue
回顾本文,也基本达成了文章开头所立的各种 flag。当然现在还是有很多问题没有解决的,如 split K、长尾问题、分块细调等等,这些权当是一些未来展望了。近期也在尝试写一下 int8 tensor core 的矩阵乘,在较小形状上(M、N、K<=2048)能有比 cublas 更高的性能,但在更大形状上就只有 80% 左右了(这还是 L2 cache 命中率为 90% 的结果,可能还有啥别的没做好),所以就没有写 int8 tensor core 的部分。不过好歹是写完了!

