--关注回复“SOA”--
↓↓领取:面向智能车辆开发的开放性SOA方案↓↓
之前和大家聊过Waymo的自动驾驶训练数据集WOD(相关阅读:一文解析Waymo的自动驾驶训练数据集WOD)和百度自动驾驶训练测试数据集ApolloScape(相关阅读:一文解析百度自动驾驶训练测试数据集ApolloScape)对于以深度学习为主要方法的自动驾驶来说,训练数据集是最关键的,因为算法都大同小异,且开源的很多,算法上无法区分高下,并且深度学习是个黑盒子,因此也有人戏称深度学习是炼丹。
虽然深度学习不具备可解释性,但是深度学习数据集与最终结果具备关联性,能区分高下的关键就是训练数据集,这就像炼丹的材料。训练数据集覆盖面越广,标注越精细,分类的越准确、类型越多,最终的自动驾驶性能就越好。
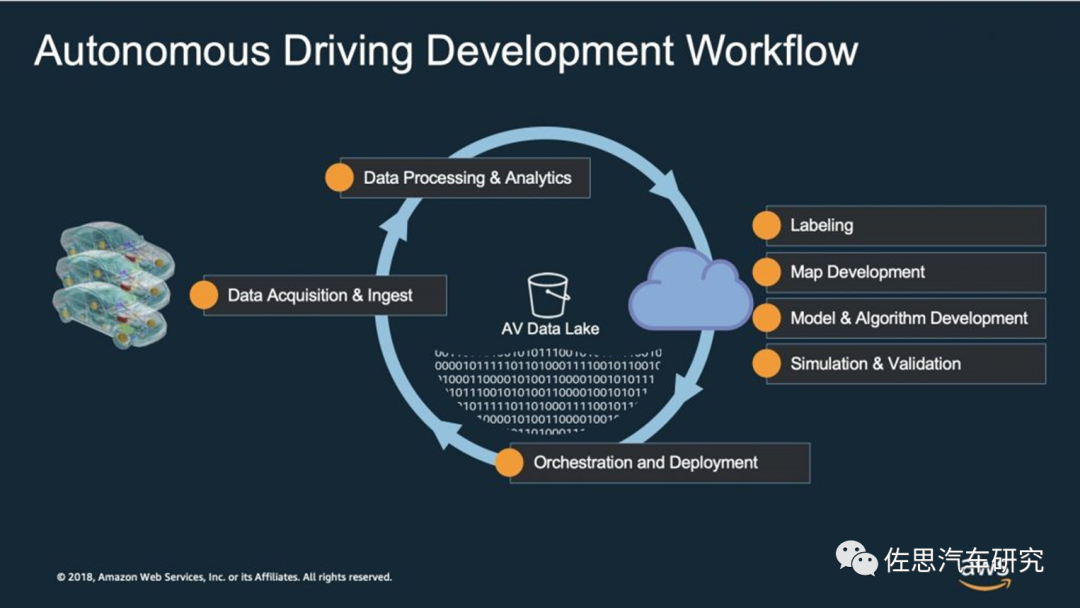
图片来源:互联网
因为训练数据集非常重要,大多数车企都是围绕训练数据集工作的,数据集是源动力,上图是亚马逊Web服务公司(AWS)的自动驾驶开发工作流,关键的环节就是数据的搜集与处理。大型车企都有自己单独组建的训练数据集,硬件方面的投入主要是价格昂贵的数据中心,可能要上亿美元,同时这个数据中心的维护成本和运营成本也不低。
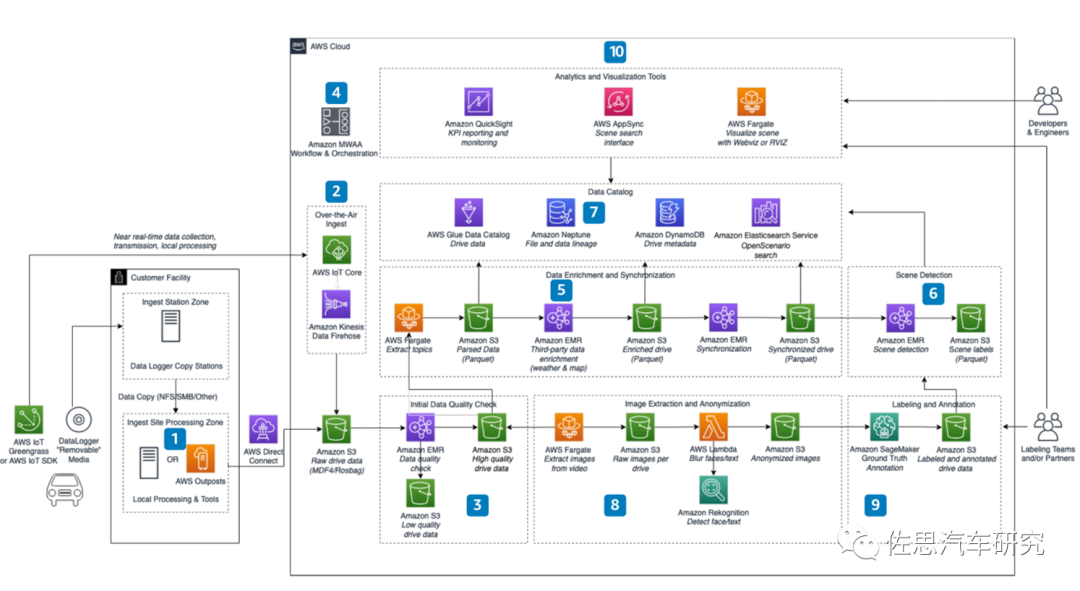
图片来源:互联网
如果不想自建数据中心,亚马逊、微软和戴尔之类的公司也提供云端数据中心的服务,上图为亚马逊的自动驾驶数据集云端解决方案。
全球第一个训练数据集KITTI由德国卡尔斯鲁厄理工学院和丰田美国技术研究院联合开发,是目前全球公认的自动驾驶领域最权威的测试数据集,也是最早的。该数据集用于评测立体图像(stereo)、光流(optical flow)、视觉测距(visual odometry)、3D物体检测(object detection)和3D跟踪(tracking)等计算机视觉技术在车载环境下的性能。KITTI包含市区、乡村和高速公路等场景采集的真实图像数据,每张图像中最多达15辆车和30个行人,还有各种程度的遮挡与截断。整个数据集由389对立体图像和光流图,39.2km视觉测距序列以及超过200k 3D标注物体的图像组成,以10Hz的频率采样及同步。
总体上看,原始数据集被分类为Road、City、Residential、Campus和Person。对于3D物体检测,label细分为car、van、truck、pedestrian、pedestrian(sitting)、cyclist、tram以及miscellaneous组成。采集车的双目摄像头基线长54厘米,车载电脑为英特尔至强的X5650 CPU,RAID 5 4TB硬盘。采集时间是2011年的9月底和10月初,总共大约5天。
很多自动驾驶公司包括大众与福特合资公司Argo的Argoverse,Waymo的Open、百度的ApolloScape、奥迪的A2D2、奔驰(Cityscape)、英伟达(PilotNet)、本田(H3D)、安波福(nuScense)、Lyft的L5、Uber都公开了其部分训练验证数据集,还有一些知名大学也公开了其训练验证数据集,包括MIT、剑桥、牛津、巴克利、加州理工大学(Caltech)、CMU、悉尼大学、密歇根、德国鲁尔(交通灯)、加拿大约克(JAAD)、斯坦福、西安交通大学的5D。这当中最具影响力的当属Kitti、Waymo的Open和安波福的nuScense。
这些数据集严格地说应该叫Benchmark,不是真正用于商业用途的企业自用训练数据集,那些数据集是企业的最核心资产,不会公开。这些Benchmark通常分为3部分,大约70%是做训练用,20%做测试,10%做验证,训练数据就像课本,测试就如同期末考试,验证类似于自我摸底。虽然不是企业自用训练数据集,但主要差别主要是规模,企业自用的规模要大得多,企业之所以公开这些数据集,让第三方使用,主要用意一是找出更高性能的深度学习模型,二是改进或修正企业自用的训练数据集。
今天要介绍的是华为的ONCE,即ONCE(One millioN sCenEs)。论文地址:arXiv:2106.11037v3,数据集地址:http://www.once-for-auto-driving.com或https://github.com/once-for-auto-driving/。ONCE由香港中文大学、华为诺亚方舟实验室、华为智能汽车解决方案事业部车辆云服务部门、中山大学和瑞士理工学院联合打造。
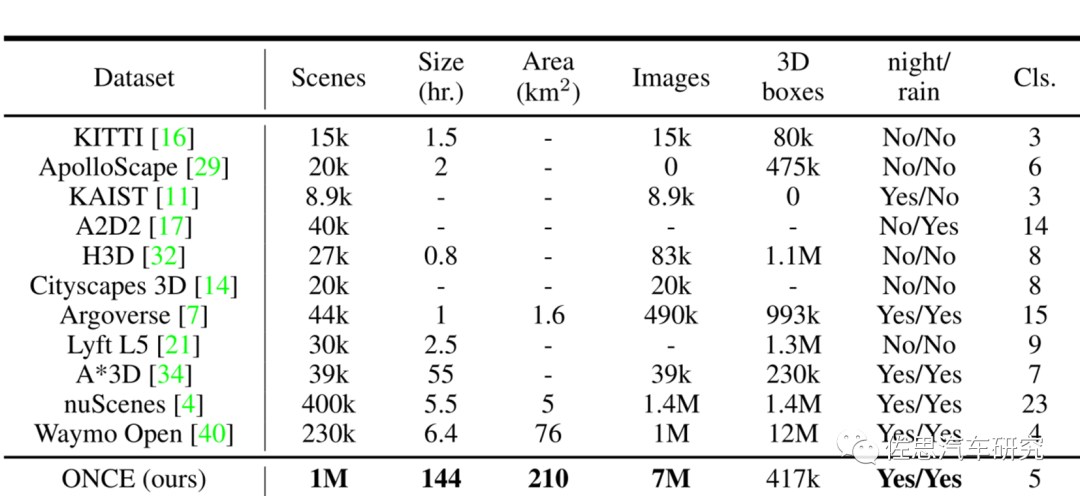
图片来源:互联网
ONCE拥有最多场景,多达100万个,行驶时间高达144小时,覆盖210平方公里,700万张同步图像,3D Box有417k个。不过Waymo的3D Box高达1200万个,确实有独到之处。ONCE之所以这么少是因为华为认为非标签数据的训练也有价值,还有一个原因是标注越多,成本越高。在这里对标注和标签需要多说几句:
标注是Annotations,即给样品提供真值(Ground Truth)注解,只能由人工和激光雷达/立体双目完成,因为激光雷达和立体双目的测距是基于物理测量而非概率算法推测,因此可以算真值,激光雷达的3维坐标信息也是基于物理的测量,而非概率算法推测,可算Ground Truth。机器如果能达到真值的预测程度那就无需再训练了。
标签是Label,有些时候和标注混用,标签或许是标注的内容之一,比如某张图片是只猫,标签为猫,但是Bounding Box没有,不能算真值。
很多地方都提到机器标签或自动标注,实际上那只是Labelme这样的标注工具,还需要人工标注,据说标注一张图片的价格是八毛或一元钱。因为是人工标注,那么难免会出错,因此通常会多次标注,即多人标注同样的样品,尽量降低错误。典型例子,多伦多大学的Boreas数据集,128线激光雷达5Hz频率,7111帧点云图像会有326180个3D标准Box。
图片来源:互联网
ONCE使用华为自己开发的标注软件,界面如上图。
典型的ONCE 3D标注。图片来源:互联网
图片来源:互联网
上图为Kitti数据集标注文件的readme.txt文件。该文件存储于object development kit(1 MB)文件中,readme详细介绍了子数据集的样本容量、label类别数目、文件组织格式、标注格式、评价方式等内容。从中可以看出IMU主要是为了保证数据的时间戳一致,建立统一的坐标系,包括全部坐标系和局部坐标系。ONCE应该也采用了类似的布局,单独有TXT文件存储标注。
图片来源:互联网
ONCE数据集,包括和激光雷达同步的RGB图像,包括了各种天气。
主要传感器的对比。图片来源:互联网
任何自动驾驶训练数据采集车都必备激光雷达,通常激光雷达是作为距离Ground Truth真值出现的,同时3D Box的3维坐标和3维尺寸也都离不开激光雷达。除了复杂的传感器与定位系统配置外,采集车还有昂贵的数据采集和处理系统,一辆采集车的设备一般都在100万人民币以上,每天上传的数据可能都是TB级的,以特斯拉为例,先不要说没有5G模块的特斯拉如何上传海量数据,也不说车牌的隐私问题,单激光雷达一项即可否决,特斯拉的影子模式纯属无稽之谈。ONCE数据集特别声明数据采集在可允许范围,主动删除任何个人信息和定位信息,特别是车牌照和人脸。在中国任何用于商业用途的数据采集都要经过国家批准,并且数据不准发往国外。
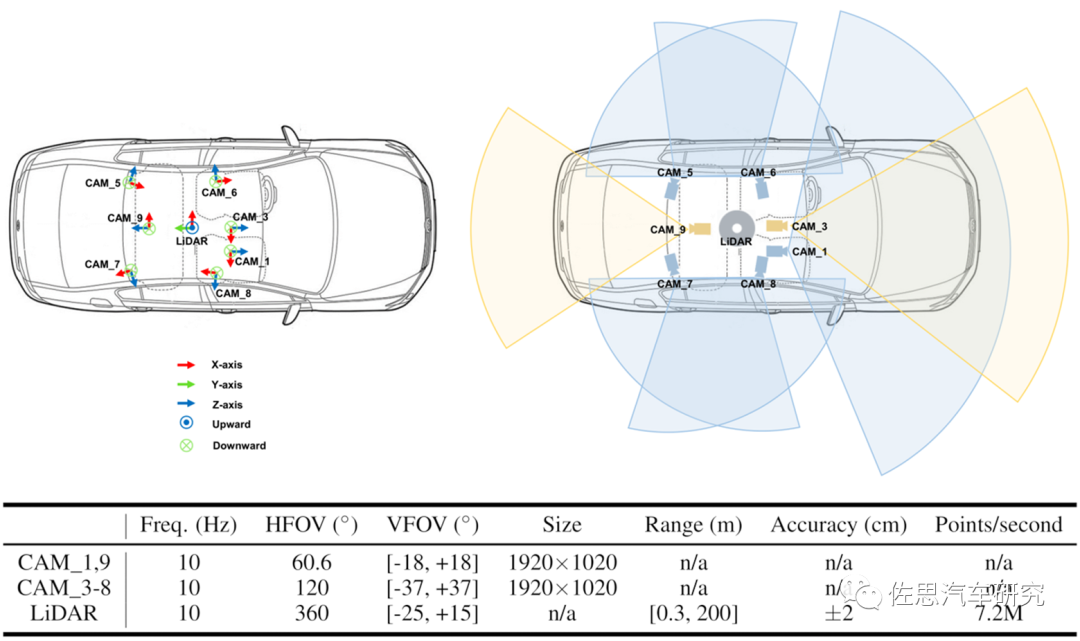
图片来源:互联网
华为数据采集车传感器配置,从出点数推测似乎应该是Velodyne的128线激光雷达,采用三回波模式,从测距范围和精度看似乎是禾赛的Pandar 128线,其双回波是691万点。华为的ONCE是所有自动驾驶训练数据集中激光雷达点密度最高的,不过华为的摄像头分辨率不高。
图片来源:互联网
几个数据集的天气覆盖维度,Waymo主要在凤凰城采集数据,凤凰城位于沙漠边缘,几乎常年不下雨,所以Waymo的数据集都是晴天。凤凰城还有个特点,虽有156万人口,但只有20多栋高楼,大多数人都是住别墅的,因此做自动驾驶很方便,没有高楼大厦的GPS遮挡,也没有大面积阴影遮挡阳光。顺便说一句,英特尔总部在凤凰城。BDD 100K做得很好,它是UC巴克利大学和康纳尔大学合作的成果,缺点是很小,只有100k场景,它是唯一覆盖雪景的数据集,对BDD 100k感兴趣的可以搜索BDD100K:A Diverse Driving Dataset for Heterogeneous Multitask Learning这篇论文。ONCE的时间段分得开,早晨最多,其次是午后和夜间。
图片来源:互联网
数据集平均精度对比,每个模型的好坏是通过评价它在某个数据集上的性能来判断的,这个数据集通常被叫做“验证/测试”数据集。这个性能由不同的统计量来度量,包括准确率(accuracy)、精确率(precision)、召回率(recall)等等。目标检测问题中最常用的度量标准---平均精度均值(Mean Average Precision,mAP),要理解mAP首先要理解IoU,给定的边界框的正确性的度量标准是“交并比”(Intersection over Union, IoU),这是一个非常简单的可视量。现在对于每个类别,预测边界框和参考边界框的重叠部分叫做交集,而两个边界框跨越的所有区域叫做并集。我们现在要分辨检测结果是否正确,最常用的阈值是0.5:如果 IoU>0.5,那么认为这是一个正确检测,否则认为这是一个错误检测。假设在整个数据集中有20个类别。对每一个类别,我们都会进行相同的操作:计算IoU->精确率(Precision)->平均精度(Average Precision)。所以我们会有20个不同的平均精度值。利用这些平均精度值,可以很轻松地判断我们的模型对任何给定的类别的性能。
ONCE最大特色是对自监督学习self-supervised learning、半监督学习Semi-supervised Learning和无监督领域自适应(Unsupervised Domain Adaptation)做了对应,ONCE的3D盒标注只有417k,远低于Waymo,这是因为标注成本较高,通常都是人工标注,虽然特斯拉有机器自动标注,但精度太低,主流还是人工标注,因此也有了个戏称,那就是有多少智能就需要多少人工,指的就是所谓人工智能特别依赖人工标注,华为这个标注花了3个月时间以上。
我们知道一般机器学习分为监督学习(supervised learning)、非监督学习和强化学习。
自动驾驶领域的基本都是监督学习,即已知数据和其一一对应的标注(标签),也就是说训练数据集需要全部标注。
无监督学习(unsupervised learning):已知数据没有任何标注,按照一定的偏好,训练一个智能算法,将所有的数据映射到多个不同标签的过程。
强化学习(reinforcement learning):智能算法在没有人为指导的情况下,通过不断的试错来提升任务性能的过程。
弱监督学习(weakly supervised learning):已知数据和其一一对应的弱标签,训练一个智能算法,将输入数据映射到一组更强的标签的过程。标签的强弱指的是标签蕴含的信息量的多少,比如相对于分割的标签来说,分类的标签就是弱标签。
半监督学习(semi supervised learning):已知数据和部分数据一一对应的标签,有一部分数据的标签未知,训练一个智能算法,学习已知标签和未知标签的数据,将输入数据映射到标签的过程。半监督通常是数据的标注非常困难,比如说医院的X光片子检查结果,医生也需要一段时间来判断健康与否,可能只有几组数据知道是健康还是非健康。
图片来源:互联网
华为ONCE提供6种3D检测模型的Benchmark,除了PointPainting都是基于激光雷达的。图中的SECOND就是Sparsely Embedded Convolutional Detection,实际就是VoxelNet(2017)论文的升级版。PV-RCNN在2021年名列Kitti 3D检测第一名,与pointRCNN同作者。PV-RCNN把point-based和voxel-based两种方法的优势结合起来,提高了3D目标检测的表现。基于体素的操作可以高效的编码多尺度特征表示并生成高质量3D提案框,基于点操作有可变的感受野(Field),故可以保留更精确的位置信息。PointPillars具备最高效率,是目前量产车常用的3D检测算法。
图片来源:互联网
6种模型在ONCE上的性能对比,CenterPoints性能最好,但是耗费运算资源最多。CenterPoints模型在Waymo的数据集上使用英伟达130TensorFLOPS的Titan RTX的帧率只有11帧。
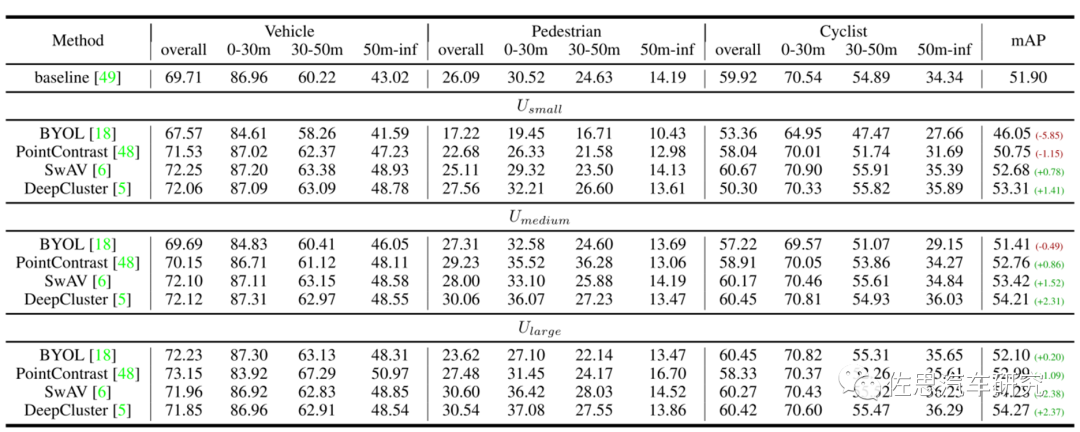
自监督学习结果。图片来源:互联网
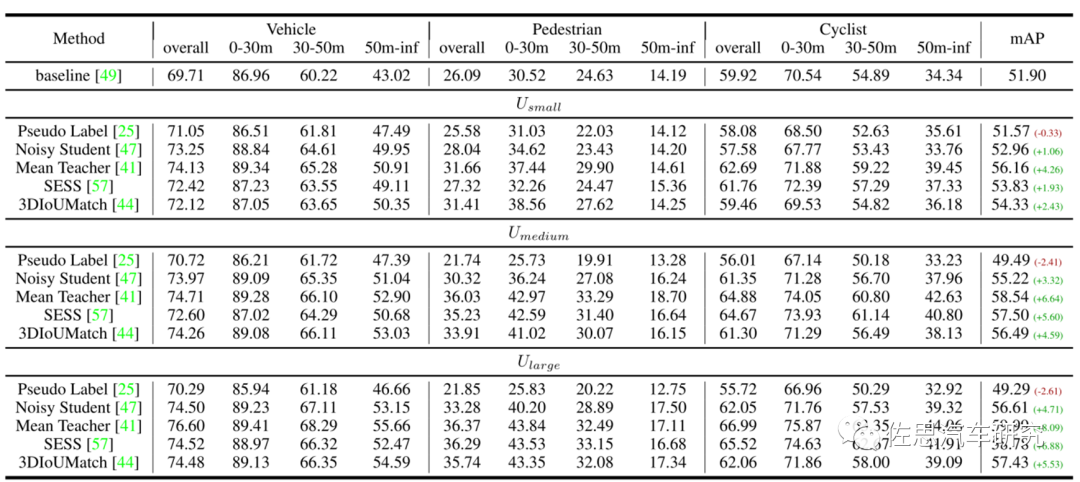
半监督学习结果,显然比自监督学习要好。图片来源:互联网
从中不难看出华为自动驾驶的方向是半监督学习到无监督学习。
转载自佐思汽车研究,文中观点仅供分享交流,不代表本公众号立场,如涉及版权等问题,请您告知,我们将及时处理。
-- END --