

我们提出了一个具有挑战性的新数据集,用于自动驾驶:牛津RobotCar数据集。在2014年5月至2015年12月期间,我们使用牛津RobotCar平台,即一辆自主的日产LEAF,平均每周两次遍历牛津市中心的路线。这形成了超过1000公里的驾驶记录,从安装在车辆上的6个摄像头收集了近2000万张图像,以及激光雷达、GPS和INS的地面实况。数据是在所有天气条件下收集的,包括大雨、夜晚、阳光直射和下雪。在一年的时间里,道路和建筑工程大大改变了从数据收集开始到结束的部分路线。通过在一年的时间里频繁遍历同一路线,我们能够研究在真实世界的动态城市环境中对自动驾驶车辆的长期定位和测绘。完整的数据集可在以下网站下载:http://robotcar-dataset.robots.ox.ac.uk。
这些数据集主要关注自动驾驶的算法能力的发展:如[8]、[9]中的运动估计,[10]、[11]中的立体重建,[12]、[13]中的行人和车辆检测以及[14]、[15]中的语义分类。然而,这些数据集并没有解决长期自动驾驶带来的许多挑战:主要是像[16]、[17]那样,在同一环境中,在明显不同的条件下进行定位,以及像[18]、[19]那样,在存在结构变化的情况下进行制图。
在本文中,我们提出了一个专注于长期自动驾驶的大规模数据集。我们通过在一年内反复遍历英国牛津市中心的一条路线,收集了超过20TB的图像、激光雷达和GPS数据,形成了超过1000公里的驾驶记录。收集到的数据的三维可视化样本显示在图1中。
通过在长时间内不同条件下驾驶同一条路线,我们可以捕捉到由于光照、天气、动态物体、季节性影响和建筑等因素造成的场景外观和结构的大范围变化。与所有传感器的原始记录一起,我们提供了一整套内在和外在的传感器校准,以及用于访问和操作原始传感器数据的MATLAB开发工具。

图1. 牛津RobotCar数据集用于长期的道路车辆自动驾驶。Data 在一年多的时间里,使用RobotCar平台在英国牛津市中心反复穿越约10公里的路线,收集了大量的数据。这导致了对同一路线的100多次遍历,捕捉到了一个动态城市环境在很长一段时间内的外观和结构的巨大变化。收集到的图像、激光雷达和GPS数据使人们能够对自动驾驶车辆的长期制图和定位进行研究,这里显示的数据集中的不同区域建立的3D地图样本。
通过向研究人员提供这一大规模数据集,我们希望能够加速未来移动机器人和自动驾驶汽车的长期自主研究。
RobotCar安装了以下传感器:
•1 x Point Grey Bumblebee XB3 (BBX3-13S2C-38)三视立体相机,1280 × 960 × 3,16Hz,1/3" Sony ICX445 CCD,全局快门,3.8mm镜头,66◦ HFoV,12/24厘米基线
• 3 x Point Grey Grasshopper2 (GS2-FW-14S5C-C) 单眼相机, 1024 × 1024, 11.1Hz,2/3” Sony
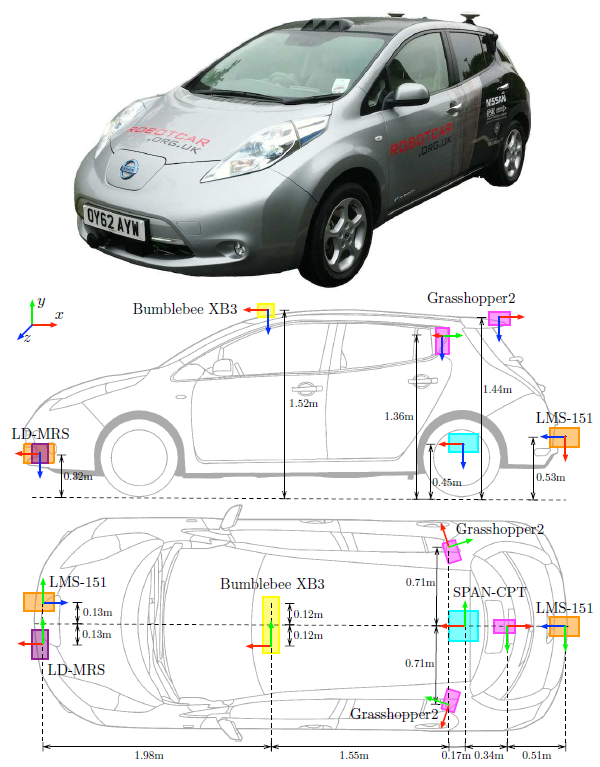
图2. RobotCar平台(顶部)和传感器位置图。坐标框架显示了安装在车辆上的每个传感器的原点和方向,惯例是:X-前(红色),Y-右(绿色),Z-下(蓝色)。所列的测量值以厘米为近似值;开发工具包括所有传感器的精确SE(3)外校准。
ICX285 CCD, 全局快门, 2.67mm 鱼眼镜头 (Sunex DSL315B-650-F2.3), 180◦ HFoV
• 2 x SICK LMS-151 2D 激光雷达,270◦ 视场角, 50Hz, 50m 范围, 0.5◦分辨率
• 1 x SICK LD-MRS 3D 激光雷达,85◦ HFoV, 3.2◦ VFoV, 4平面, 12.5Hz, 50m 范围, 0.125◦ 分辨率
• 1 x NovAtel SPAN-CPT ALIGN 惯性和GPS导航系统, 6轴, 50Hz, GPS/GLONASS,双天线
车辆上的传感器的位置如图2所示。车辆上的所有传感器都是用一台运行Ubuntu Linux的电脑记录的,该电脑有两个八核英特尔至强E5-2670处理器,96GB四通道DDR3内存和一个由八个512GB固态硬盘组成的RAID 0(条带)阵列,总容量为4TB。所有的传感器驱动和记录过程都是内部开发的,以提供准确的同步和记录数据的时间戳。
两个LMS-151二维激光雷达传感器都以 "推扫式 "配置安装,以便在车辆前进过程中提供对周围环境的扫描。通过将这些扫描与全局或局部姿态源相结合,形成一个精确的环境三维重建,如图1所示;
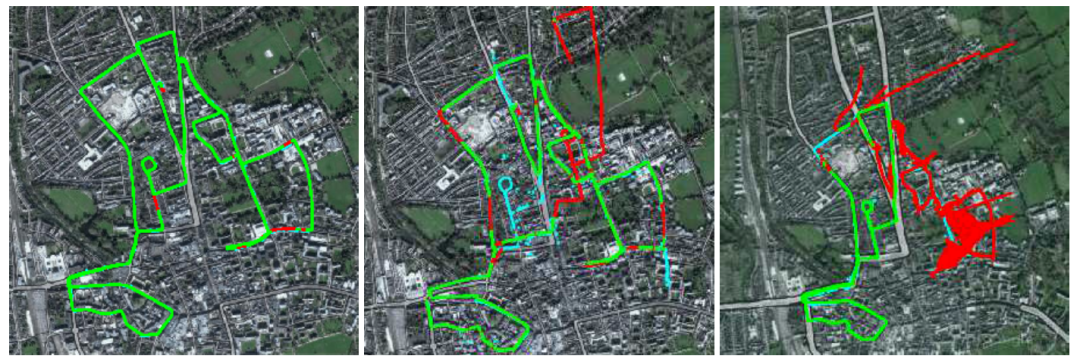
图3. 10公里的主要数据收集路线显示了GPS接收和INS质量的变化。大多数数据集表现出良好的GPS接收(左边),以绿色显示。在一些地方,GPS接收不良导致INS解决方案的漂移(中间,红色),尽管原始GPS测量(青色)仍然可用。偶尔,接收的缺失会在很大一部分路线上造成明显的定位误差(右图)。
通过将这些扫描与全局或局部姿态源相结合,形成一个精确的环境三维重建,如图1所示;
MATLAB开发工具中提供了生成三维点云的软件。LD-MRS传感器被安装在朝前的配置中,以探测车辆前方的障碍物。
Bumblebee XB3和三个Grasshopper2相机的组合提供了车辆周围场景的360度视觉监控。三台Grasshopper2相机使用Point Grey为共享火线800总线1的相机提供的自动方法进行同步,产生11.1Hz的平均帧率。BumblebeeXB3相机是以16Hz的最大帧率记录的。
为BumblebeeXB3开发了一个定制的自动曝光控制器,以提供地面和周围建筑物的良好曝光图像,而不对天空或车辆的前面进行正确曝光。然而,由于软件自动曝光控制的反应较慢,这偶尔会导致帧的过度曝光。Grasshopper2使用了相关的硬件区域自动曝光控制器来提供良好曝光的图像。
III.数据采集

图4. 2014年5月至2015年12月期间对同一地点进行的100多次遍历的蒙太奇,说明了在各种条件下外观的巨大变化。除了短期的照明和天气变化外,由于季节性变化造成的长期变化也很明显。注意蓝色标志在道路左肩的排列。
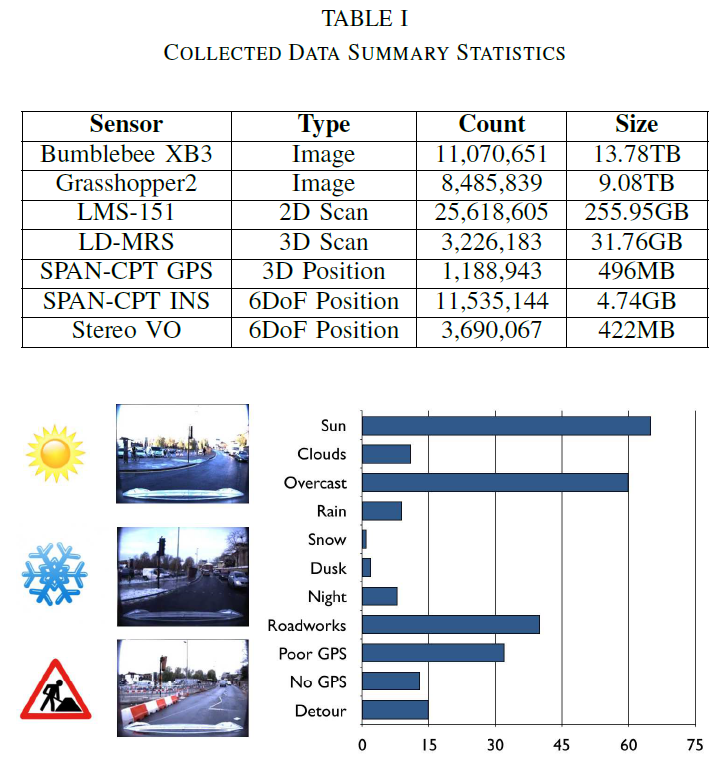
图5. 不同条件标签下的遍历次数。一些环境因素影响了路线,包括光照和外观的变化,道路工程和施工造成的绕行,以及影响GPS接收的大气条件。可以按标签对穿越进行分类,以方便下载和调查特定的环境条件。

图6. 数据收集过程中捕捉到的驾驶条件的变化说明。由于照明(阳光直射、阴天、夜晚)、天气(雨、雪)和其他道路使用者(车辆、行人、自行车)的遮挡,场景的外观发生了明显的变化。
1.内在:对于BumblebeeXB3图像,开发套件中提供了两套校准查询表:一个是12厘米窄基线配置,由中间和右边的图像组成,另一个是24厘米宽基线配置,由左边和右边的图像组成。
如果只下载数据集的一部分,必须注意为窄基线或宽基线立体图选择正确的图像配置。Bumblebee XB3查询表中的数值是由Point Grey提供的,作为工厂校准的一部分。
对于Grasshopper2图像,为每个相机提供了一个未失真查找表,使用[21]的OCamCalib工具箱获得的校准模型生成。然而,鱼眼图像的透视不失真往往导致高度不均匀的图像,不同的鱼眼失真模型往往更适合于不同的应用。
因此,我们还提供了一个棋盘式序列的原始图像,作为OCamCalib工具箱校准的输入。
2.外在:对于每个激光雷达扫描仪,初始的校准估计是由[22]中描述的相机-激光雷达校准过程提供的。对于二维激光雷达扫描仪,校准估计值采用[23]中描述的在线校准方法进行完善,使用从Bumblebee XB3获得的视觉测距作为相对姿势源。
从GPS+惯性传感器到BumblebeeXB3的校准是使用[23]的修改版计算的,使用来自惯性传感器的轨迹作为相对姿势源来构建三维激光雷达网格。

图7. 环境的结构变化随时间推移。原来的十字路口(左上)经过几个月的重新开发,导致施工期间的交通改道(右上,左下)。最终的十字路口(右下)有一个完全不同的道路布局,用一个环形交叉口代替了交通灯。
使用二维激光雷达扫描建立的点云对LD-MRS进行校准,使用的方法见文献[24]。所有的外部因素都是由MATLAB开发工具提供的。
传感器的终身校准是一个具有挑战性的问题,涉及到长期定位和测绘。虽然我们用上述方法提供了我们对外在因素的最佳估计,但我们不能保证它们对特定的遍历是准确的。我们鼓励研究在线校准的人员使用我们的外部参数作为传感器校准参数长期估计的初始猜测。
B.数据格式
为了便于分配,我们将数据集划分为单独的路线,每条路线对应于一个单一的遍历。为了减少下载文件的大小,我们将每个遍历进一步划分为几块,每块对应于路线的大约6分钟的片段。在一个遍历中,来自不同传感器的数据块会在时间上重叠(例如,左侧立体声数据块2与LD-MRS数据块2覆盖同一时间段);然而,不同遍历之间的数据块并不对应。
每个块都被打包成一个tar档案,以便向下加载;档案中的文件夹结构如图8所示。任何tar文件的大小都不应该超过5GB。希望所有的tar档案都在同一个目录下解压:这将在下载多个块和/或遍历时保留图8中的文件夹结构。
每块档案还包含
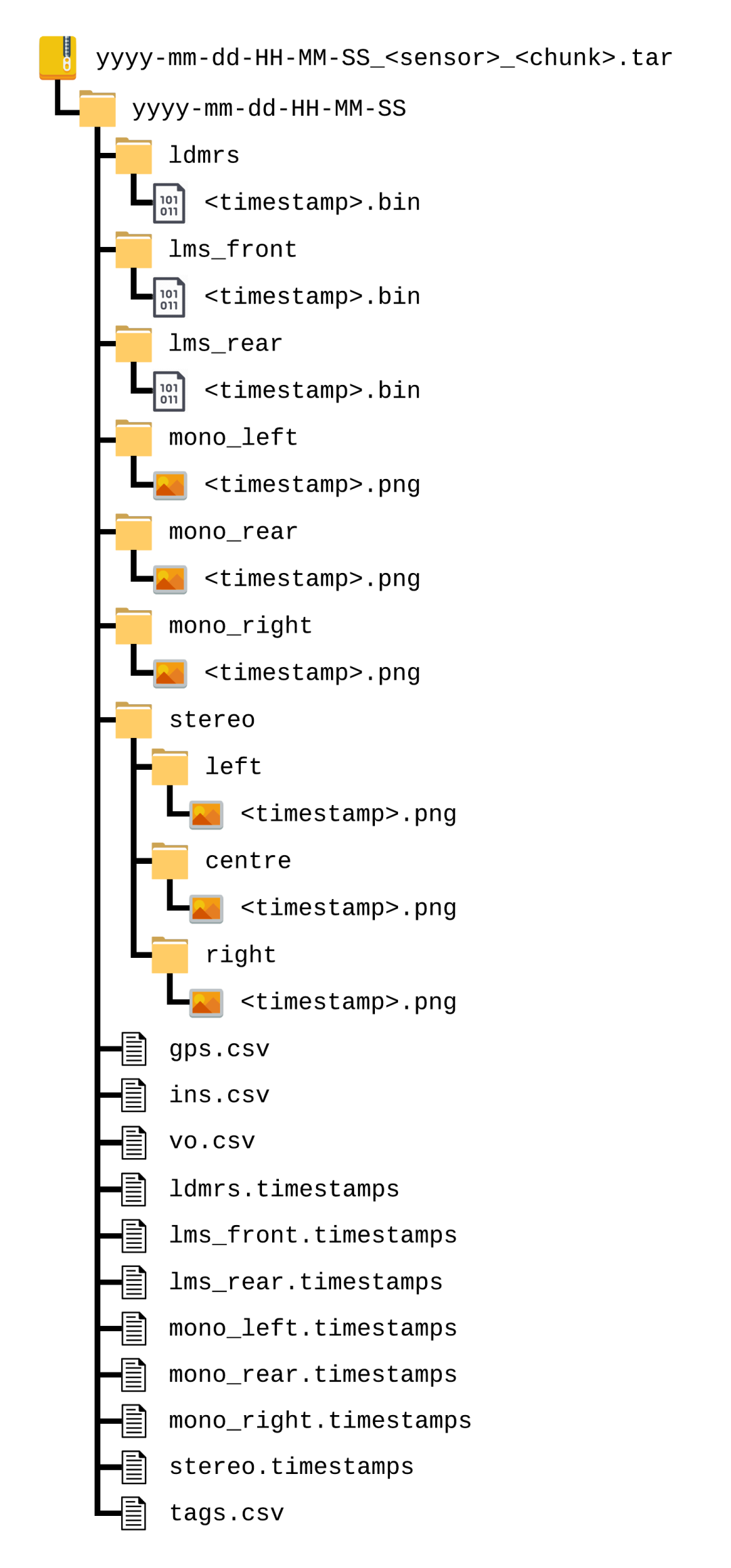
图8. 单个数据集的目录布局。当从多个遍历中下载多个tar档案时,将它们全部解压在同一个目录中,将保留文件夹结构。
我们已经将内部记录格式的传感器数据转换为标准的数据格式,以便于携带。每个数据类型的格式如下:
1.图像:所有的图像都以无损压缩的PNG文件2形式存储,采用未校正的8位原始Bayer格式。这些文件的结构为
2.二维激光雷达扫描:每次扫描的二维激光雷达返回值都以双精度浮点值的形式存储在一个二进制文件中,类似于[6]中的Velodyne扫描格式。

图9. 从左到右:原始Bayer图像(以PNG格式提供),去马赛克的彩色图像,以及来自(顶部)Bumblebee XB3和(底部)Grasshopper2相机的矫正透视图像。开发工具中提供了用于解马赛克和校正扭曲的MATLAB函数。
类似于[6]中的Velodyne扫描格式。 文件结构为
在将点投射到直角坐标中时,没有对车辆的运动进行修正;这可以通过根据激光的15ms旋转周期为每个点插入一个时间戳来选择性地执行。 对于一个文件名为
3.3D激光雷达扫描: 来自LD-MRS的三维激光雷达返回值以与二维激光雷达扫描相同的打包双精度浮点二进制格式存储。这些文件的结构为ldmrs/
4.GPS+惯性: SPAN-CPT的GPS和惯性传感器数据以ASCII格式的csv文件提供。提供了两个单独的文件:gps.csv和ins.csv。GPS .csv包含5Hz时GPS的纬度(度)、经度(度)、高度(m)和不确定度(m)的解决方案,ins.csv包含融合的GPS+惯性解决方案,包括3D UTM位置(m)、速度(m/s)、姿态(度)和50Hz时的解决方案状态。
5.视觉定位法(VO): GPS+惯性解决方案中的局部误差(由于卫星信号的丢失或重新获取)会导致使用该传感器作为姿势源构建的局部地图的不连续性。对一些应用来说,一个平滑的局部姿势源,不一定是全局精确的,是比较好的,例如图10所示的局部三维点云构建。
我们使用我们在[25]中描述的视觉测绘系统处理了全套Bumblebee XB3宽基线立体图像,并提供相关姿态估计作为参考的局部姿态源。 文件vo.csv包含相对姿态解决方案,由源帧和目的帧的时间戳,以及与两帧相关的SE(3)相对姿态的六向量欧拉参数化(x, y, z, α, β, γ)组成。
我们的视觉测绘解决方案在数百米范围内是准确的(适合于建立本地的三维点云),但在更大的范围内会有漂移,而且也会受到场景和曝光水平的影响;我们只把它作为一个参考,而不是作为一个地面真实的相对姿势系统。

 图10.
使用(上)INS姿势和(下)本地VO姿势产生的本地三维点云,由所包含的开发工具产生。在GPS接收不佳的地方,INS的姿势解决方案存在不连续,导致本地三维点云被破坏。视觉测距法提供了一个平滑的本地姿势估计,但在较大的距离上会有漂移。
图10.
使用(上)INS姿势和(下)本地VO姿势产生的本地三维点云,由所包含的开发工具产生。在GPS接收不佳的地方,INS的姿势解决方案存在不连续,导致本地三维点云被破坏。视觉测距法提供了一个平滑的本地姿势估计,但在较大的距离上会有漂移。
IV.开发工具
我们提供了一套简单的MATLAB开发工具,以便对数据集的访问和操作。提供的MATLAB工具包括加载和显示图像和LIDAR扫描的简单功能,以及更高级的功能,包括从推扫2D扫描生成3D点云,以及将3D点云投影到相机图像。图11展示了开发工具的使用示例。
函数LoadImage.m从指定的目录和指定的时间戳读取原始Bayer图像,并返回一个MATLAB格式的RGB彩色图像。该函数还可以接受一个可选的查找表参数(由函数ReadCameraModel.m提供),然后将使用不失真查找表对图像进行校正。图9显示了原始Bayer、RGB和校正图像的例子。函数PlayImages.m将产生一个来自指定目录的可用图像的动画,如图11(a)所示。
函数ProjectLaserIntoCamera.m将上述两个工具结合在一起,如下所示:LoadImage.m用于从指定的方向和指定的时间戳检索和解构原始图像,然后BuildPointcloud.m用于在图像捕获时在车辆周围生成本地三维点云。然后,三维点云利用相机的内在因素被探测到二维相机图像,产生如图11(c)所示的结果。
V.经验教训
在收集、存储和处理从RobotCar收集到的数据的过程中,我们学到了很多宝贵的经验,我们在这里总结一下,以供其他尝试类似大规模数据收集的人员参考:
1.仅记录原始数据:对于每个传感器,我们确保只有通过电线收到的原始数据包和准确的主机时间戳被记录到磁盘上;我们不进行任何解析、压缩或过滤(例如 Bayer解马赛克)。
我们还启用了所有传感器的所有可选的日志信息(如状态信息)。这可以最大限度地提高数据的效用,这可能只有在收集后的几个月或几年才会显现出来,并最大限度地减少预处理的 "自营销 "决定。
例如,像[26]那样依赖于测光误差的方法或像[27]那样依赖于精确测色的方法受到图像压缩和Bayer解嵌的强烈影响;通过直接从相机中记录原始数据包,我们最大限度地减少了对未来研究的限制。
2.使用向前兼容的格式:在收集多年的数据时,不可避免地会出现软件错误并被修复,而操作数据的工具的功能也会随着时间的推移而改进。因此,重要的是,数据是以向前兼容的二进制格式记录的,不与特定的软件版本相联系。
在内部,我们使用谷歌Protocol Buffers3来管理我们的数据格式;这使我们能够改变或扩展消息定义,使用代码生成器访问多种语言的消息数据,并保持与旧软件版本的二进制兼容。
3.分开记录的数据和处理的数据:在处理和操作数据时,产生相关的元数据(如索引文件、激光雷达点云、视觉测距结果)往往是有用的。
然而,产生这种元数据的工具会在很长一段时间内发生变化和改进,重要的是,经过处理的日志与原始记录保持区别。在实践中,我们在数据服务器上维护两个日志目录;一个只读目录,只有安装了RobotCar的计算机可以上传到该目录,还有一个读写目录,镜像记录的数据并允许用户添加元数据。
因此,如果其中一个元数据工具被升级,在删除或替换所有以前由该工具生成的元数据时,不会有丢失记录的原始数据的风险。
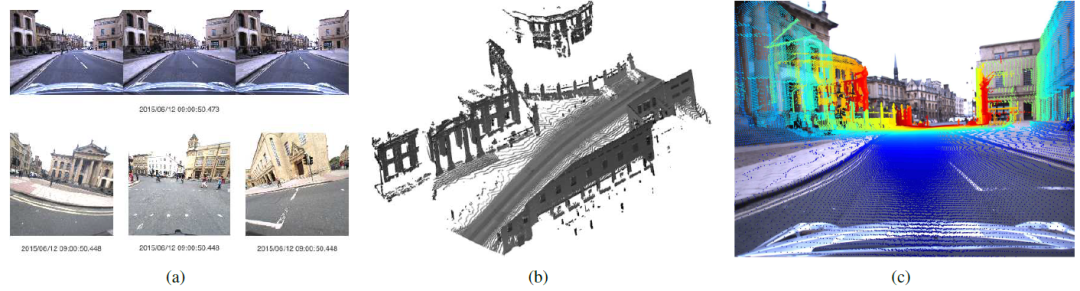
图11. MATLAB开发工具的样本。(a)所有车载摄像机的图像解压缩和回放,(b)从推扫式激光雷达和INS姿态生成三维点云,(c)利用已知的外在因素和内在因素将三维点云投影到二维摄像机图像中。
VI.总结和未来工作
我们提出了牛津RobotCar数据集,这是一个新的大规模数据集,专注于车辆的长期自动驾驶。随着这个数据集的发布,我们打算挑战目前的长期定位和测绘方法,并促成研究自动驾驶车辆和移动机器人的终身学习。
在不久的将来,我们希望提供类似于KITTI基准套件4的基准服务,为研究人员提供机会,使用共同的地面实况和评价标准公开比较长期的定位和测绘方法。
我们也鼓励研究人员从本文提出的数据中开发他们自己的特定应用基准,例如使用[28]的开放源码结构自运动或[29]的优化包,我们将努力支持这些基准。
参考文献:
[1]P. Dolla´r, C. Wojek, B. Schiele, and P. Perona, “Pedestrian detection: A benchmark,” in Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conferenceon. IEEE, 2009, pp. 304–311.
[2]G. J. Brostow, J. Fauqueur, and R. Cipolla, “Semantic object classes in video: A high-definition ground truth database,” Pattern Recognition Letters, vol. 30, no. 2, pp. 88–97, 2009.
[3]G. Pandey,J. R. McBride, and R. M. Eustice, “Ford campus vision and LIDAR data set,” The International Journal of Robotics Research, vol. 30, no. 13, pp. 1543–1552, 2011.
[4]D. Pfeiffer, S. Gehrig, and N. Schneider, “Exploiting the power of stereo confidences,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2013, pp. 297–304.
[5] J.-L. Blanco-Claraco, F.-A´ . Moreno-Duen˜as, and J. Gonza´lez-Jime´nez, “The Ma´laga urban dataset: High-rate stereo and LiDAR in a realistic urban scenario,” The International Journal of Robotics Research, vol. 33, no. 2, pp. 207–214,2014.
[6]A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets robotics: The KITTI dataset,” International Journal of Robotics Research (IJRR), 2013.
[7]M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benen- son, U. Franke, S. Roth, and B. Schiele, “The Cityscapes dataset for semantic urban scene understanding,” in Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
[8]D. Niste´r, O. Naroditsky, and J. Bergen, “Visual odometry for ground vehicle applications,” Journal of Field Robotics, vol. 23, no. 1, pp. 3–20, 2006.
[9]A. Geiger, J. Ziegler, and C. Stiller, “Stereoscan: Dense 3D recon- struction in real-time,” in Intelligent Vehicles Symposium (IV), 2011IEEE. IEEE, 2011, pp. 963–968.
[10] H. Hirschmuller, “Accurate and efficient stereo processing by semi- global matching and mutual information,” in 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), vol. 2. IEEE, 2005, pp. 807–814.
[11] A. Geiger, M. Roser, and R. Urtasun, “Efficient large-scale stereo matching,” in Asian conference on computer vision. Springer, 2010, pp. 25–38.
[12] P. Viola, M. J. Jones, and D. Snow, “Detecting pedestrians using patterns of motion and appearance,” International Journalof Computer Vision, vol. 63, no. 2, pp. 153–161, 2005.
[13] R. Benenson, M. Omran, J. Hosang, and B. Schiele, “Ten years of pedestrian detection, what have we learned?” in European Conference on Computer Vision. Springer, 2014, pp. 613–627.
[14] I. Posner, M. Cummins, and P. Newman, “Fast probabilistic labeling of city maps,” in Proceedings of Robotics: Science and Systems IV, Zurich, Switzerland, June 2008.
[15] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 3431–3440.
[16] C. McManus, B. Upcroft, and P. Newman, “Learning place-dependant features for long-term vision-based localisation,” Autonomous Robots,Special issue on Robotics Science and Systems 2014, pp. 1–25, 2015.
[17] C. Linegar, W. Churchill, and P. Newman, “Made to measure:Bespoke
landmarks for 24-hour, all-weather localisation with a camera,” in Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, May 2016.
[18]G. D. Tipaldi, D. Meyer-Delius, and W. Burgard, “Lifelong localiza- tion in changing environments,” The International Journal of Robotics Research, vol. 32, no. 14, pp. 1662–1678,2013.
[19]W. Maddern, G. Pascoe, and P. Newman, “Leveraging experience for large-scale LIDAR localisation in changing cities,” in Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, May 2015.
[20]A. Harrison and P. Newman, “TICSync: Knowing when things hap- pened,” in Robotics and Automation (ICRA), 2011 IEEE International Conference on. IEEE, 2011, pp. 356–363.
[21]D. Scaramuzza, A. Martinelli, and R. Siegwart, “A toolbox for easily calibrating omnidirectional cameras,” in 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2006, pp. 5695– 5701.
[22]A.Kassir and T. Peynot,“Reliable automatic camera-laser calibration,” in Proceedings of the 2010 Australasian Conference on Robotics & Automation. ARAA, 2010.
[23]G. Pascoe, W. Maddern, and P. Newman, “Direct visual localisation and calibration for road vehicles in changing city environments,” in IEEE International Conference on Computer Vision: Workshop on Computer Vision for Road Scene Understanding and AutonomousDriving, Santiago, Chile, December2015.
[24]W. Maddern, A. Harrison, and P. Newman, “Lost in translation (and rotation): Fast extrinsic calibration for 2D and 3D LIDARs,”in Proc. IEEE International Conference on Robotics and Automation (ICRA), Minnesota, USA, May 2012.
[25]W. Churchill, “Experience based navigation: Theory, practice and implementation,” Ph.D. dissertation, University of Oxford, Oxford, United Kingdom, 2012.
[26]J. Engel, T. Scho¨ps, and D. Cremers, “LSD-SLAM: Large-scale direct monocular SLAM,” in European Conference on ComputerVision. Springer, 2014, pp. 834–849.
[27] W. Maddern, A. Stewart, C. McManus, B. Upcroft, W. Churchill, and
P. Newman, “Illumination invariant imaging: Applications in robust vision-based localisation, mapping and classification for autonomous vehicles,” in Proceedings of the Visual Place Recognition in Changing Environments Workshop, IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, vol. 2, 2014, p. 3.
[28] J. L. Scho¨nberger and J.-M. Frahm, “Structure-from-motion revisited,”in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
[29]S. Agarwal, K. Mierle, and Others, “Ceres solver,” http://ceres-solver. org, 2012.
分享不易,恳请点个【👍】和【在看】
