之前和大家聊过Waymo的自动驾驶训练数据集WOD(相关阅读:一文解析Waymo的自动驾驶训练数据集WOD),百度在2019年也发表了自己的自动驾驶训练测试数据集ApolloScape,论文为《The ApolloScape Open Dataset for Autonomous Driving and its Application》。这个数据集最大特色是使用了高精度地图采集车,激光雷达点云密度极高,达到光学成像级的密度。因此它是唯一具备稠密环境语义分割的3D点云数据集,包含超过20个地点。
因为是地图级采集车,所以相机方位姿态准确度极高,6自由度下,translation ≤ 50 mm, rotation ≤ 0.015°。相机917万像素,在所有数据采集系统中稳居第一。地图自然离不开道路标识,百度的数据集包含最丰富的道路标识,像素级道路标识包含多达35个分类,160K以上图像。地图需要高精度定位,百度数据集的定位也是所有数据集中最强的。
百度数据集包含多种视觉化信息
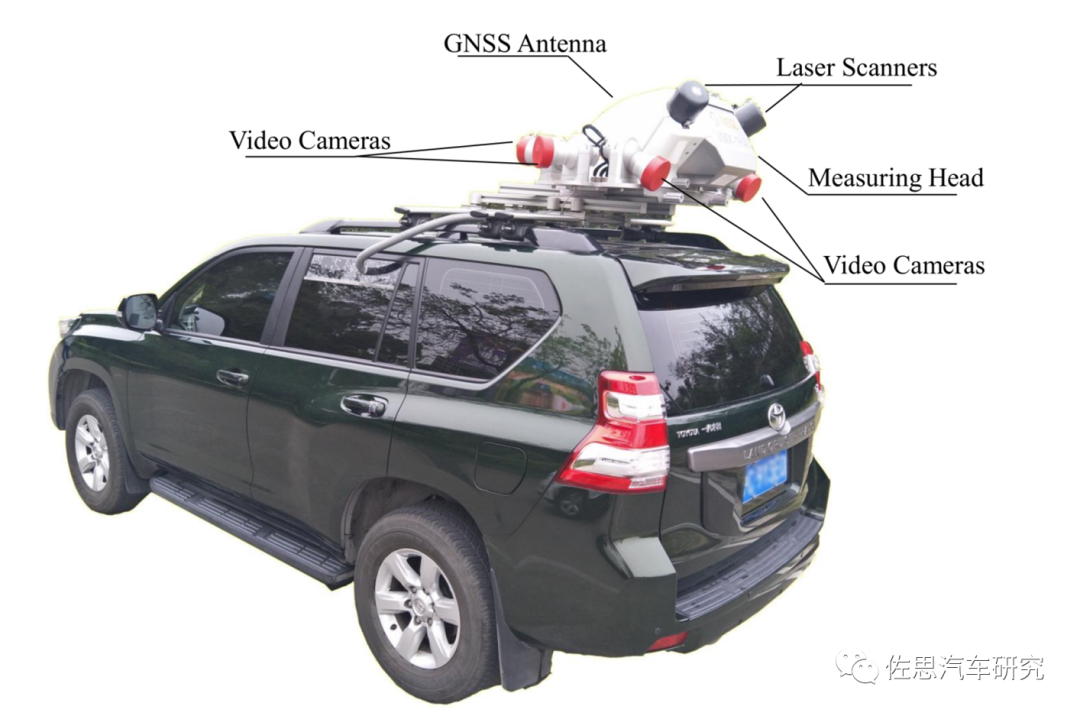
百度的数据采集车就是百度地图的数据采集车,车辆本身是百万元级的丰田陆地巡洋舰,车顶的采集系统是Rigel的VMX-1HA。
VMX-1HA系统构成
VMX-1HA是2017年老产品,目前已被VMX-2HA取代。VMX-1HA最重要的部件是两个测绘级激光雷达VUX-1HA。
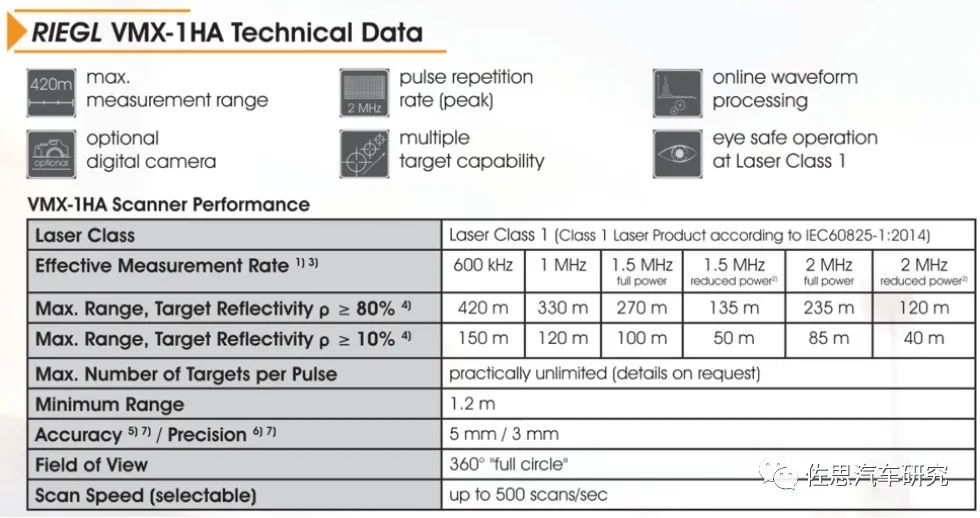
VMX-1HA的性能参数,精度达到惊人的3毫米级,扫描线为500线,有效距离超400米,每秒200万点发射频率,双回波整体系统就是800万点密度。效果可以达到光学相机水准,特别是道路标识可以和相机互补,相机会有光线干扰,夜间或天气不佳时不够清晰,激光雷达没有这个问题。

这种级别的激光雷达可以做城市建筑模型,文物数字化,交通基础设施地图。
VMX-1HA检测头
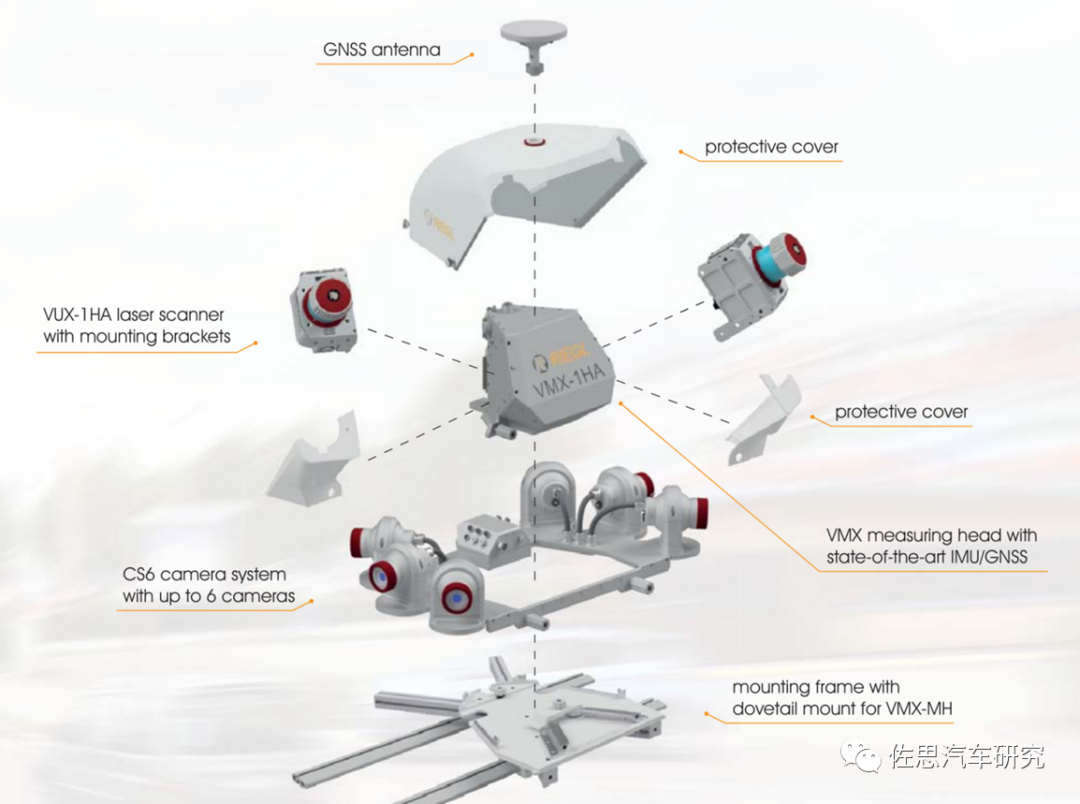
VMX-1HA配备6个摄像头,2HA是7个摄像头。6个摄像头覆盖360°全景,这6个不是鱼眼镜头(鱼眼镜头畸变要做矫正), 而是普通镜头,因此无需矫正。前两个摄像头像素达3384*2710,也就是917万像素,是目前所有采集系统中最高的像素。其余四个是500万像素。
做为地图,定位自然要求极高,绝对定位精度达到20毫米。

VMX-1HA还可以选配FLIR的Ladybug5热成像系统,10米内可达4K级别清晰度,价格很高。
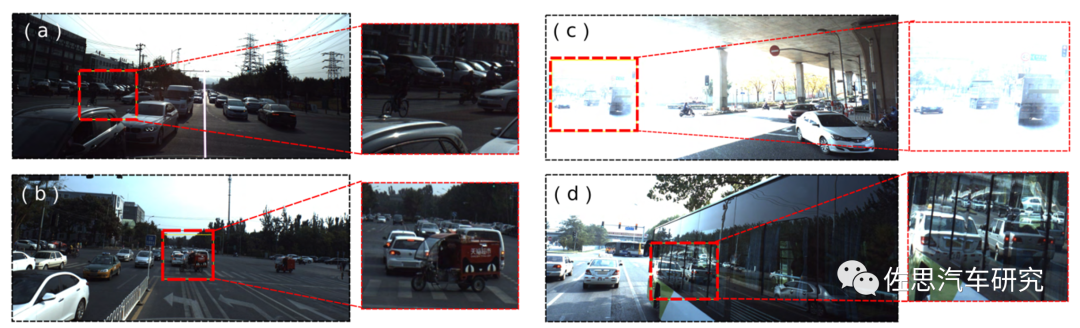
激光雷达可以避免摄像头的缺陷,如这种被遮挡的、对比度极高的、镜面反射的情形。
分割种类和同步像素标注的数量
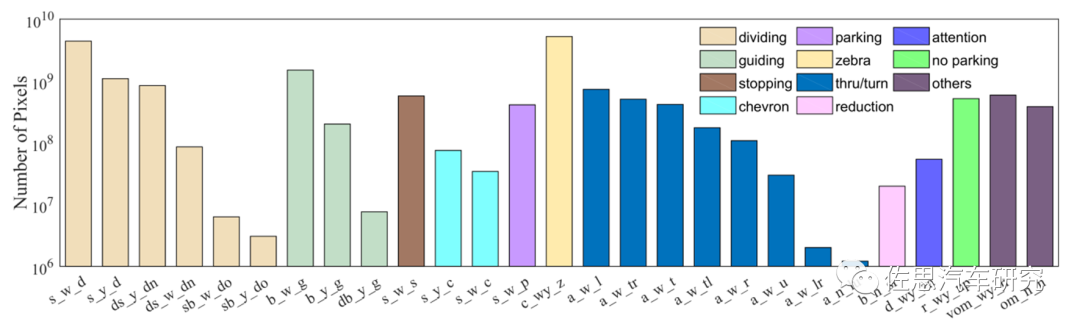
道路标识Landmark分类和同步像素标注数量,道路标识分11大类,28小类,非常细致。
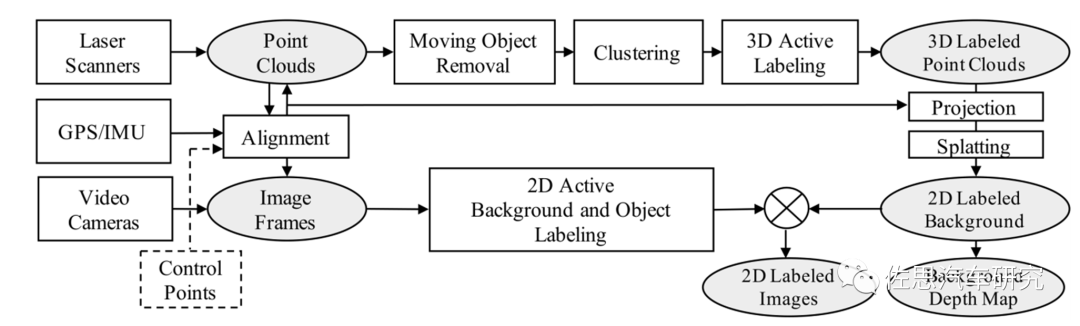
百度数据集标注管线
百度数据集人工标注工具界面
百度数据集的标注管线,a为原始图像,b为激光雷达投影图像,c去掉移动目标,d和e为深度投影与分类,f填补e的天空和移动目标去除后的空洞,这与高精度地图的制作流程颇为类似。
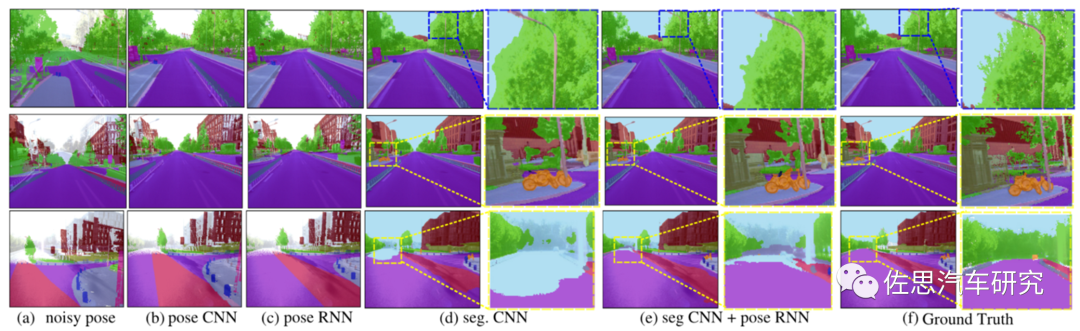
语义分割框架如上图,使用DeLS 3D,这是百度的一种算法,论文为《DeLS-3D: Deep Localization and Segmentation with a 3D Semantic Map》。黑箭头代表测试过程,红箭头为训练和评估过程,黄色的锥体代表相机的定位,输入包含一连串的图像和与之同步的GPS IMU信息。
Segment CNN架构
SegmentCNN又称SegNet,是剑桥大学2015年11月发表的论文《SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image》是最早做语义分割比较成功的模型,直到今天效果还不错,确实很厉害。
SegNet网络结构如图所示,Input为输入图片,Output为输出分割的图像,不同颜色代表不同的分类。语义分割的重要性就在于不仅告诉你图片中某个东西是什么,而且告知你它在图片的位置。我们可以看到是一个对称网络,由中间绿色pooling池化层与红色upsampling上取样层作为分割,左边是卷积提取高维特征,并通过pooling使图片变小,SegNet作者称为Encoder,右边是反卷积(在这里反卷积与卷积没有区别)与upsampling,通过反卷积使得图像分类后特征得以重现,upsampling使图像变大,SegNet作者称为Decoder,最后通过Softmax,输出不同分类的最大值。这就是大致的SegNet过程。
百度ApolloScape的基线,SegCNN效果最佳。
几种算法对比
最后说一下语义分割的指标之一MIoU (Mean Intersection over Union),即交并比。
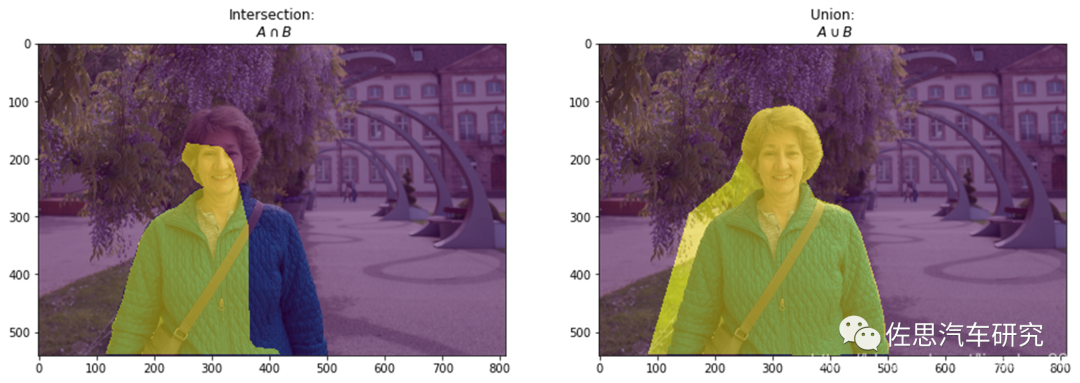
在进行语义分割结果评价的时候,常常将预测出来的结果分为四个部分:true positive、false positive、true negative和false negative, 其中negative就是指非物体标签的部分(可以直接理解为背景),那么显而易见的,positive就是指有标签的部分。
基于类进行计算的IoU就是将每一类的IoU计算之后累加,再进行平均,得到的就是基于全局的评价,所以我们求的IoU其实是取了均值的IoU,也就是均交并比(mean IoU)。
数据集系列到此完毕,还有值得一提的是大众与福特合资的Argo公司的Argoverse,不过之前的文章已经有详细描述。综合来看,自动驾驶研究的热点一个是从2D Bounding Box向语义分割,3D方向,单目立体重建,另一个是动作行为预测,光流追踪和路径规划。不过目前业内还是以2D Bounding Box为主。
转载自佐思汽车研究,文中观点仅供分享交流,不代表本公众号立场,如涉及版权等问题,请您告知,我们将及时处理。
-- END --