

AI 简报 20221014 期
原文:
https://app.myzaker.com/news/article.php?pk=63476be18e9f0903ac797c80
(全球 TMT2022 年 10 月 13 日讯)GTIC 2022 全球 AI 芯片峰会日前在深圳市南山区举行,2022 中国 AI 芯片企业 50 强榜单揭晓。本次榜单基于核心技术实力、团队建制情况、市场前景空间、商用落地进展、最新融资进度、国产替代价值六大维度进行综合评分判定,按照分值遴选出当下在 AI 芯片领域拥有突出成就和创新潜力的 50 家中国企业名单。
2022 中国 AI 芯片企业 50 强(排名不分先后,按公司名称首字母排序):
爱芯元智半导体 ( 上海 ) 有限公司
安徽聆思智能科技有限公司
北京玻色量子科技有限公司
北京地平线信息技术有限公司
北京嘉楠捷思信息技术有限公司
北京君正集成电路股份有限公司
北京灵汐科技有限公司
北京苹芯科技有限公司
北京清微智能科技有限公司
北京算能科技有限公司
北京探境科技有限公司
北京知存科技有限公司
成都启英泰伦科技有限公司
成都时识科技有限公司
光子算数 ( 北京 ) 科技有限责任公司
瀚博半导体 ( 上海 ) 有限公司
杭州国芯科技股份有限公司
杭州智芯科微电子科技有限公司
黑芝麻智能科技有限公司
昆仑芯 ( 北京 ) 科技有限公司
墨芯人工智能科技 ( 深圳 ) 有限公司
沐曦集成电路 ( 上海 ) 有限公司
南京后摩智能科技有限公司
南京芯驰半导体科技有限公司
平头哥半导体有限公司
千芯科技 ( 北京 ) 有限公司
瑞芯微电子股份有限公司
睿思芯科 ( 深圳 ) 技术有限公司
上海埃瓦智能科技有限公司
上海壁仞智能科技有限公司
上海登临科技有限公司
上海酷芯微电子有限公司
上海齐感电子信息科技有限公司
上海燧原科技有限公司
上海天数智芯半导体有限公司
上海曦智科技有限公司
上海依图网络科技有限公司
上海亿铸智能科技有限公司
上海肇观电子科技有限公司
深圳鲲云信息科技有限公司
深圳市海思半导体有限公司
深圳市九天睿芯科技有限公司
深圳云天励飞技术股份有限公司
时擎智能科技 ( 上海 ) 有限公司
思必驰科技股份有限公司
银牛微电子 ( 无锡 ) 有限责任公司
中科寒武纪科技股份有限公司
中科融合感知智能研究院 ( 苏州工业园区 ) 有限公司
珠海欧比特宇航科技股份有限公司
珠海亿智电子科技有限公司

原文:
https://view.inews.qq.com/a/20221014A00Q4500?tbkt=D&uid=&refer=wx_hot
10月13日,大众汽车集团宣布旗下软件公司CARIAD将与地平线成立合资企业,并持有合资企业60%股份。据悉,大众汽车计划为本次合作投资约24亿欧元(折合人民币约168亿元),该交易预计在明年上半年完成。
此次,CARIAD牵手地平线,主要将发力智能驾驶,开发领先的、高度优化的全栈式高级驾驶辅助系统和自动驾驶解决方案,在单颗芯片上集成多种功能,提高系统稳定性并节约成本降低能耗。

一直以来,合资品牌电动车在智能座舱、智能驾驶上与造车新势力们有一定的差价,大众汽车这次牵手地平线,无疑将补上了短板。并且以合资的方式进行合作,而不仅仅将地平线定义为供应商,无疑将加速推进大众旗下车型的智能化升级。向科技公司转型的路上,大众汽车又迈出了坚实的一步。
原文:
https://36kr.com/p/1931939259730306
在全世界的注视下,世界第二大虚拟货币以太坊(ETH)本月正式从PoW转为PoS机制,完成了业界革命的“The Merge”合并升级。
以太坊合并完成之前,大量持有以太坊的投资者就已经开始抛售,以太坊单币价格一路走低,从本周的高点1777美元,到合并时的1650美元左右,最终下跌至当前的1333美元,顺便还把老对手比特币也拖下水,目前比特币再次跌破19000美元关口。
这是区块链诞生以来,史无前例的一次升级,直接将之前的玩法全部推翻,宣告了曾经利用GPU(显卡)挖矿时代的全面终结,近1亿币圈玩家被影响。大量专职挖矿的矿工们,要开始考虑未来的何去何从。
从2008年开始的挖矿暴富梦,进入了落幕倒计时。
这次以太坊升级转型的PoS机制,是完全不同运算逻辑, 简单来说就是不再依赖于显卡, 而是凭借“币龄”和持有货币的数量来充当“算力”,从而杜绝能源高消耗的情况。
这样一来,影响最大的就是矿工们手头里囤积的显卡。
显卡作为挖矿的第一生产力工具,价格也在狂热的挖矿浪潮中一度疯涨。2021年底,英伟达发布RTX 30系显卡,原本是游戏玩家刚需的显卡设备,还没等玩家下单,矿工们就开始溢价疯抢,把市面上的RTX 30系显卡全部买下,再无一例外地投入到挖矿行列当中。
原本定位中端的RTX 3060Ti显卡,官方定价2999元,在最高峰时价格暴涨近乎破万,其它高端卡更不用说了,都是溢价三倍起步。最新的显卡买不到,矿工又盯上了“过时”的设备,上一代的RTX 20系显卡都迎来不同程度的疯涨。
甚至一些使用两三年的RTX 10系显卡,都能在二手市场以原价卖出,可见挖矿浪潮对显卡的影响。

原文:
https://mp.weixin.qq.com/s/qDwVdgPJCkArDOL4azvX1A
今日,Meta Connect 大会在线上举行。Meta CEO 马克 · 扎克伯格推出了一款全新的 Quest Pro 虚拟和混合现实头显设备,标志着 Meta 进入了扩展现实计算设备的高端市场。
在演讲中,扎克伯格部分以真人、部分以虚拟化身出现,他表示,「我希望物理世界和数字世界的融合能够为计算带来更多新的用途。」

在技术上,Meta Quest Pro 对现有 Quest 2 头显设备进行了全方位升级。
首先,Quest Pro 采用了全新的薄饼(Pancake)透镜,光学堆栈比 Quest 2 缩减 40%,视觉中心解析度每英寸像素提升 35%。设备瞳孔间距的调节范围为 55-75 毫米,为用户提供了更好的视觉体验并降低眼疲劳。

其次,Quest Pro 在硬件上采用了与高通联合设计并专为 VR 优化的骁龙 XR2 + 芯片,更好的散热系统使得续航提升了 50%,也大幅提升了性能。此外,Quest Pro 还附带 10 个先进的 VR/MR 传感器、空间音频、256GB 内存和 12GB RAM。
最后,Quest Pro 配备了重新设计的控制手柄,各自搭载一颗骁龙 662 处理器和三个摄像头。新的传感器使得不用头显也能在 3D 空间中追踪位置,用户可以享受 360 度全方位运动范围。新的 Trutouch Haptics 为用户提供了更宽和更精准的反馈效果范围。
原文:
https://mp.weixin.qq.com/s/MyUW7CELJOckFjmYNkQxuA
文章链接:
https://ai.googleblog.com/2022/09/quantization-for-fast-and.html
此前,由谷歌大脑团队科学家 Aleksandra Faust 和研究员 Srivatsan Krishnan 发布的深度强化学习模型在解决导航、核物理、机器人和游戏等现实世界的顺序决策问题方面取得巨大进步。它很有应用前景,但缺点之一是训练时间过长。
虽然可以使用分布式计算加快复杂困难任务的强化学习的训练,但是需要数百甚至数千个计算节点,且要使用大量硬件资源,这使得强化学习训练成本变得极其高昂,同时还要考虑对环境的影响。最近的研究表明,对现有硬件进行性能优化可以减少模型训练的碳足迹(即温室气体排放总量)。
借助系统优化,可以缩短强化学习训练时间、提高硬件利用率、减少二氧化碳(CO2)排放。其中一种技术是量化,将全精度浮点(FP32)数转换为低精度(int8)数,然后使用低精度数字进行计算。量化可以节省内存成本和带宽,实现更快、更节能的计算。量化已成功应用于监督学习,以实现机器学习(ML)模型的边缘部署并实现更快的训练。同样也可以将量化应用于强化学习训练。
近日,谷歌的研究者在《Transactions of Machine Learning Research》期刊上发表了《QuaRL:快速和环境可持续强化学习的量化》,介绍了一种称为「ActorQ」的新范式。该范式使用了量化,在保持性能的同时,将强化学习训练速度提高 1.5-5.4 倍。作者证明,与全精度训练相比,碳足迹也减少了 1.9-3.8 倍。
量化应用于强化学习训练
在传统的强化学习训练中,learner 策略会应用于 actor,actor 使用该策略探索环境并收集数据样本,actor 收集的样本随后被 learner 用于不断完善初始策略。定期地,针对 learner 的训练策略被用来更新 actor 的策略。为了将量化应用于强化学习训练,作者开创了 ActorQ 范式。ActorQ 执行上面描述的相同序列,其中关键区别是,从 learner 到 actor 的策略更新是量化的,actor 使用 int8 量化策略探索环境以收集样本。
以这种方式将量化应用于强化学习训练有两个关键好处。首先,它减少了策略的内存占用。对于相同的峰值带宽,learner 和 actor 之间传输的数据较少,这降低了 actor 与 learner 之间的策略更新通信成本。其次,actor 对量化策略进行推理,以生成给定环境状态的操作。与完全精确地执行推理相比,量化推理过程要快得多。
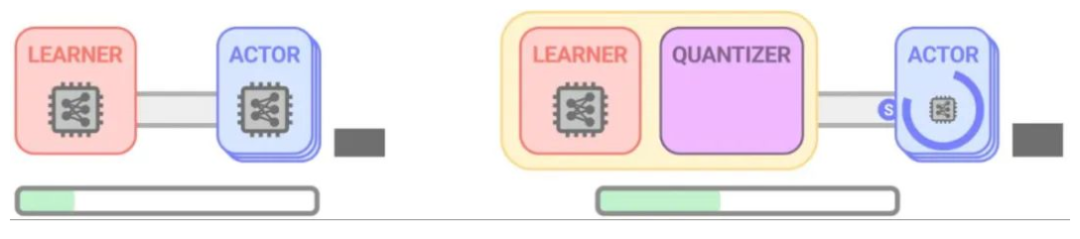
以量化提升强化学习训练效率
作者在实验中观察到训练强化学习策略的速度显著加快(1.5 倍至 5.41 倍之间)。更重要的是,即使 actor 进行了基于 int8 的量化推理,也可以保持性能。下图显示了用于 Deepmind Control Suite 和 OpenAI Gym 任务的 D4PG 和 DQN 智能体的这一点。
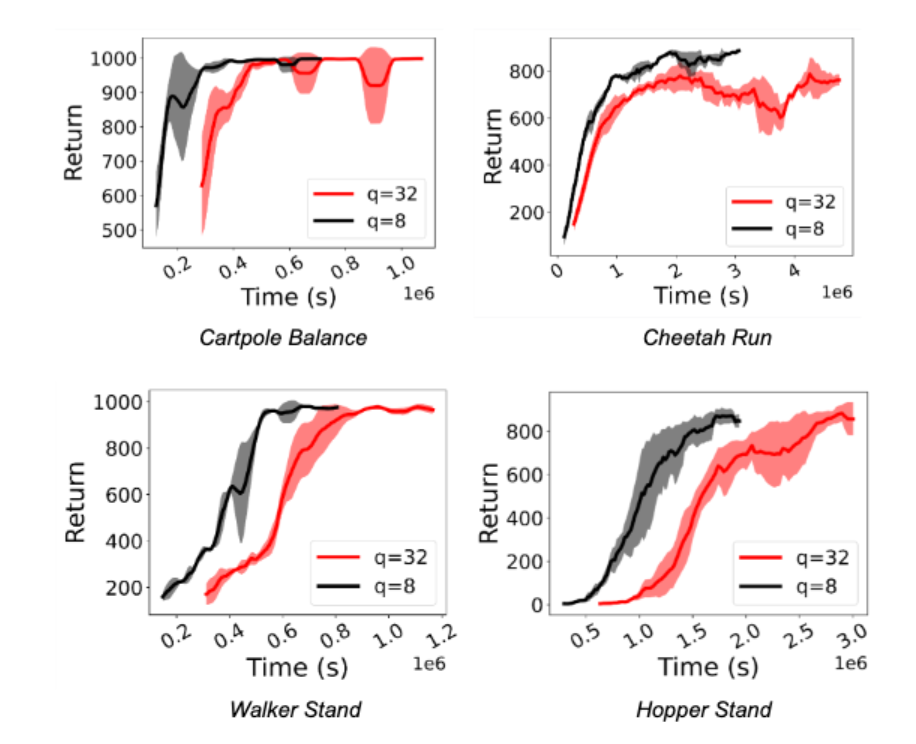
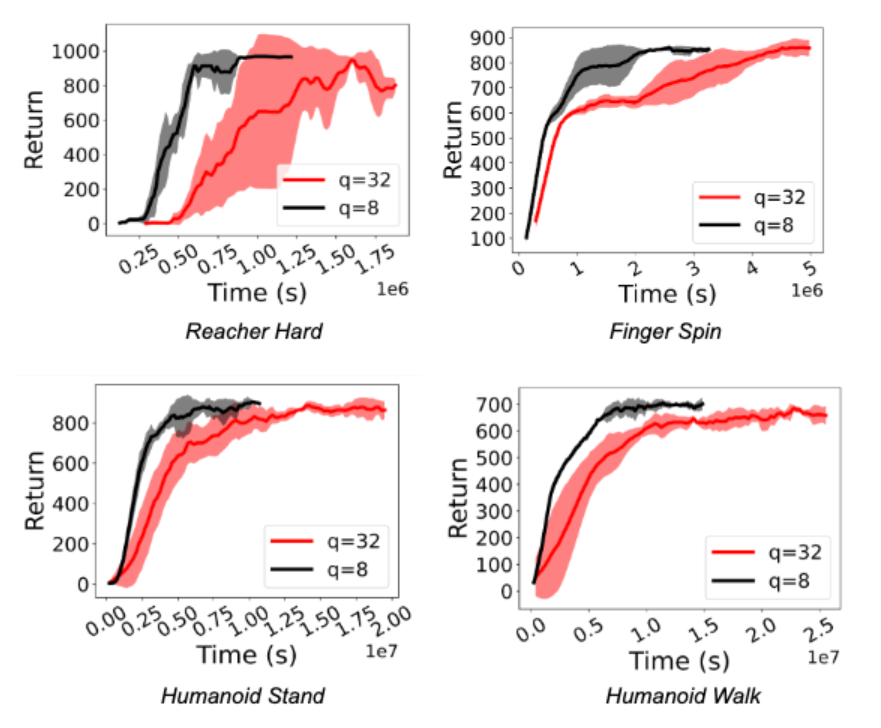
结论和未来方向
作者引入了 ActorQ,这是一种新的范式,将量化应用于强化学习训练,并在保持性能的同时实现了 1.5-5.4 倍的加速改进。与未应用量化的全精度训练相比,ActorQ 可以将强化学习训练的碳足迹减少 1.9-3.8 倍。
ActorQ 证明量化可以有效地应用于强化学习的许多方面,从获得高质量和高效的量化策略到减少训练时间和碳排放。随着强化学习在解决现实问题方面继续取得长足进步,我们有理由相信,使强化学习训练实现可持续发展将是关键。当将强化学习扩展到数千个 CPU 和 GPU 时,即使 50% 的改进也会在成本、能源和碳排放方面显著降低。作者的工作是将量化应用于强化学习训练以实现高效和环境可持续训练的第一步。
作者在 ActorQ 中的量化设计基于简单的均匀量化,但实际可以应用其他形式的量化、压缩和稀疏性(如蒸馏、稀疏化等)。未来的工作将考虑应用更积极的量化和压缩方法,这可能会为强化学习在训练性能和精度的权衡上带来更多的好处。
原文:
https://mp.weixin.qq.com/s/rc9AdGFige75ylfehfs-fQ
最近大火的生成式 AI 又有新动作了!
在 podcast.ai 推出的第一集播客节目里,已故的乔布斯竟然“死而复生”成为首位嘉宾,与美国知名播客主持人 Joe Rogan 进行了一场长达20分钟的对话,讨论了关于乔布斯的大学、对计算机的看法、工作状态以及信仰等等。
是不是听起来有些毛骨悚然?事实上,这段采访是由文本生成音频实现的,属于 AIGC 中的一个分支。
podcast.ai 是一个完全由 AI 生成的播客,每周都会深入探讨一个新话题。在第一期节目中,podcast.ai 通过乔布斯的传记和收集网络上关于他的所有录音,用 Play.ht 的语言模型大量训练,最终生成了这段假 Joe Rogan 采访乔布斯的播客内容。
此次 podcast.ai 推出的AI播客,是生成式AI在语音领域的一次新探索。从前段时间全网刷屏的 Stable Diffusion,后有国内平台掀起AI创作热,各类生成式AI模型给人们生活带来了更多的可能性。
Play.ht 表示,“我们相信在未来,所有内容创作都将由人工智能生成,但由人类指导,而最具创造性的工作将取决于人类将他们想要的创作表达到模型中的能力。”
原文:
https://mp.weixin.qq.com/s/Ke_vp6SWxWuygSNTFaO_bg
论文地址:
https://arxiv.org/pdf/2209.05442.pdf
我们知道,基于分数的模型和去噪扩散概率模型(DDPM)是两类强大的生成模型,它们通过反转扩散过程来产生样本。这两类模型已经在 Yang Song 等研究者的论文《Score-based generative modeling through stochastic differential equations》中统一到了单一的框架下,并被广泛地称为扩散模型。
目前,扩散模型在包括图像、音频、视频生成以及解决逆问题等一系列应用中取得了巨大的成功。Tero Karras 等研究者在论文《Elucidating the design space of diffusionbased generative models》中对扩散模型的设计空间进行了分析,并确定了 3 个阶段,分别为 i) 选择噪声水平的调度,ii) 选择网络参数化(每个参数化生成一个不同的损失函数),iii) 设计采样算法。
近日,在谷歌研究院和 UT-Austin 合作的一篇 arXiv 论文《Soft Diffusion: Score Matching for General Corruptions》中,几位研究者认为扩散模型仍有一个重要的步骤:损坏(corrupt)。一般来说,损坏是一个添加不同幅度噪声的过程,对于 DDMP 还需要重缩放。虽然有人尝试使用不同的分布来进行扩散,但仍缺乏一个通用的框架。因此,研究者提出了一个用于更通用损坏过程的扩散模型设计框架。
具体地,他们提出了一个名为 Soft Score Matching 的新训练目标和一种新颖的采样方法 Momentum Sampler。理论结果表明,对于满足正则条件的损坏过程,Soft Score MatchIng 能够学习它们的分数(即似然梯度),扩散必须将任何图像转换为具有非零似然的任何图像。
在实验部分,研究者在 CelebA 以及 CIFAR-10 上训练模型,其中在 CelebA 上训练的模型实现了线性扩散模型的 SOTA FID 分数——1.85。同时与使用原版高斯去噪扩散训练的模型相比,研究者训练的模型速度显著更快。

通常来说,扩散模型通过反转逐渐增加噪声的损坏过程来生成图像。研究者展示了如何学习对涉及线性确定性退化和随机加性噪声的扩散进行反转。

具体地,研究者展示了使用更通用损坏模型训练扩散模型的框架,包含有三个部分,分别为新的训练目标 Soft Score Matching、新颖采样方法 Momentum Sampler 和损坏机制的调度。
首先来看训练目标 Soft Score Matching,这个名字的灵感来自于软过滤,是一种摄影术语,指的是去除精细细节的过滤器。它以一种可证明的方式学习常规线性损坏过程的分数,还在网络中合并入了过滤过程,并训练模型来预测损坏后与扩散观察相匹配的图像。
只要扩散将非零概率指定为任何干净、损坏的图像对,则该训练目标可以证明学习到了分数。另外,当损坏中存在加性噪声时,这一条件总是可以得到满足。
在过程中,研究者发现噪声在实证(即更好的结果)和理论(即为了学习分数)这两方面都很重要。这也成为了其与反转确定性损坏的并发工作 Cold Diffusion 的关键区别。
其次是采样方法 Momentum Sampling。研究者证明,采样器的选择对生成样本质量具有显著影响。他们提出了 Momentum Sampler,用于反转通用线性损坏过程。该采样器使用了不同扩散水平的损坏的凸组合,并受到了优化中动量方法的启发。
这一采样方法受到了上文 Yang Song 等人论文提出的扩散模型连续公式化的启发。Momentum Sampler 的算法如下所示。

最后是调度。即使退化的类型是预定义的(如模糊),决定在每个扩散步骤中损坏多少并非易事。研究者提出一个原则性工具来指导损坏过程的设计。为了找到调度,他们将沿路径分布之间的 Wasserstein 距离最小化。直观地讲,研究者希望从完全损坏的分布平稳过渡到干净的分布。
原文:
https://mp.weixin.qq.com/s/ZpwlJbpQgvDqlmBX67phLw
论文地址:
https://arxiv.org/pdf/2210.03142.pdf
去噪扩散概率模型(DDPM)在图像生成、音频合成、分子生成和似然估计领域都已经实现了 SOTA 性能。同时无分类器(classifier-free)指导进一步提升了扩散模型的样本质量,并已被广泛应用在包括 GLIDE、DALL·E 2 和 Imagen 在内的大规模扩散模型框架中。
然而,无分类器指导的一大关键局限是它的采样效率低下,需要对两个扩散模型评估数百次才能生成一个样本。这一局限阻碍了无分类指导模型在真实世界设置中的应用。尽管已经针对扩散模型提出了蒸馏方法,但目前这些方法不适用无分类器指导扩散模型。
为了解决这一问题,近日斯坦福大学和谷歌大脑的研究者在论文《On Distillation of Guided Diffusion Models》中提出使用两步蒸馏(two-step distillation)方法来提升无分类器指导的采样效率。
在第一步中,他们引入单一学生模型来匹配两个教师扩散模型的组合输出;在第二步中,他们利用提出的方法逐渐地将从第一步学得的模型蒸馏为更少步骤的模型。
利用提出的方法,单个蒸馏模型能够处理各种不同的指导强度,从而高效地对样本质量和多样性进行权衡。此外为了从他们的模型中采样,研究者考虑了文献中已有的确定性采样器,并进一步提出了随机采样过程。

研究者在 ImageNet 64x64 和 CIFAR-10 上进行了实验,结果表明提出的蒸馏模型只需 4 步就能生成在视觉上与教师模型媲美的样本,并且在更广泛的指导强度上只需 8 到 16 步就能实现与教师模型媲美的 FID/IS 分数,具体如下图 1 所示。

此外,在 ImageNet 64x64 上的其他实验结果也表明了,研究者提出的框架在风格迁移应用中也表现良好。
原文:
https://mp.weixin.qq.com/s/DOqUWpoCIOE4RbH88vpgfg
归一化相关技术已经经过了几年的发展,目前针对不同的应用场合有相应的方法,在本文将这些方法做了一个总结,介绍了它们的思路,方法,应用场景。主要涉及到:LRN,BN,LN, IN, GN, FRN, WN, BRN, CBN, CmBN等。
本文又名“BN和它的后浪们”,是因为几乎在BN后出现的所有归一化方法都是针对BN的三个缺陷改进而来,在本文也介绍了BN的三个缺陷。相信读者会读完此文会对归一化方法有个较为全面的认识和理解。
LRN(2012)
局部响应归一化(Local Response Normalization, 即LRN)首次提出于AlexNet。自BN提出后,其基本被抛弃了,因此这里只介绍它的来源和主要思想。
LRN的创意来源于神经生物学的侧抑制,被激活的神经元会抑制相邻的神经元。用一句话来形容LRN:让响应值大的feature map变得更大,让响应值小的变得更小。
其主要思想在于让不同卷积核产生feature map之间的相关性更小,以实现不同通道上的feature map专注于不同的特征的作用,例如A特征在一通道上更显著,B特征在另一通道上更显著。
Batch Normalization(2015)
论文:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
论文中关于BN提出的解释:训练深度神经网络非常复杂,因为在训练过程中,随着先前各层的参数发生变化,各层输入的分布也会发生变化,图层输入分布的变化带来了一个问题,因为图层需要不断适应新的分布,因此训练变得复杂,随着网络变得更深,网络参数的细微变化也会放大。
由于要求较低的学习率和仔细的参数初始化,这减慢了训练速度,并且众所周知,训练具有饱和非线性的模型非常困难。我们将此现象称为内部协变量偏移,并通过归一化层输入来解决该问题。
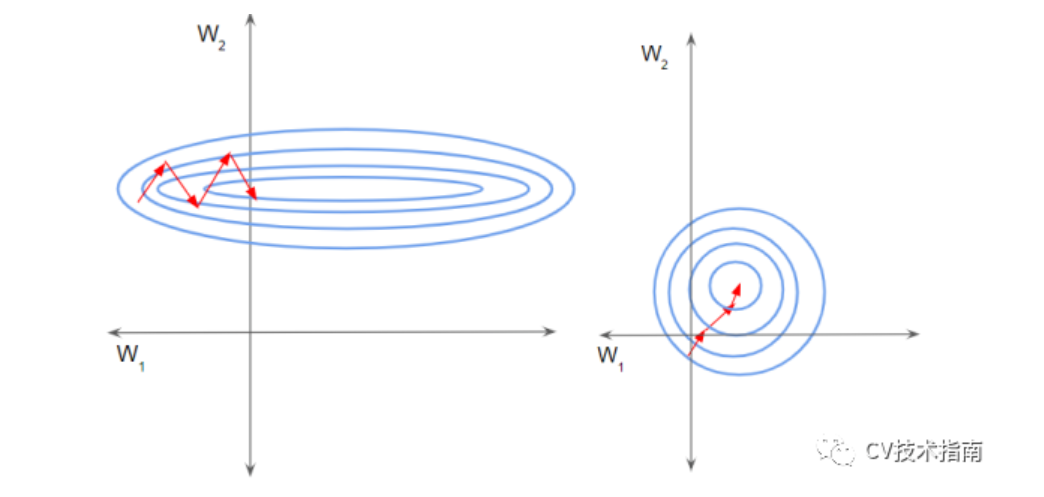
其它的解释:假设输入数据包含多个特征x1,x2,…xn。每个功能可能具有不同的值范围。例如,特征x1的值可能在1到5之间,而特征x2的值可能在1000到99999之间。
如下左图所示,由于两个数据不在同一范围,但它们是使用相同的学习率,导致梯度下降轨迹沿一维来回振荡,从而需要更多的步骤才能达到最小值。且此时学习率不容易设置,学习率过大则对于范围小的数据来说来回震荡,学习率过小则对范围大的数据来说基本没什么变化。
如下右图所示,当进行归一化后,特征都在同一个大小范围,则loss landscape像一个碗,学习率更容易设置,且梯度下降比较平稳。
实现算法:

在一个batch中,在每一BN层中,对每个样本的同一通道,计算它们的均值和方差,再对数据进行归一化,归一化的值具有零均值和单位方差的特点,最后使用两个可学习参数gamma和beta对归一化的数据进行缩放和移位。
此外,在训练过程中还保存了每个mini-batch每一BN层的均值和方差,最后求所有mini-batch均值和方差的期望值,以此来作为推理过程中该BN层的均值和方差。
注:BN放在激活函数后比放在激活函数前效果更好。
实际效果:1)与没有BN相比,可使用更大的学习率2)防止过拟合,可去除Dropout和Local Response Normalization3)由于dataloader打乱顺序,因此每个epoch中mini-batch都不一样,对不同mini-batch做归一化可以起到数据增强的效果。4)明显加快收敛速度5)避免梯度爆炸和梯度消失
注:BN存在一些问题,后续的大部分归一化论文,都是在围绕BN的这些缺陷来改进的。为了行文的方便,这些缺陷会在后面各篇论文中逐一提到。
BN、LN、IN和GN的区别与联系
下图比较明显地表示出了它们之间的区别。(N表示N个样本,C表示通道,这里为了表达方便,把HxW的二维用H*W的一维表示。)
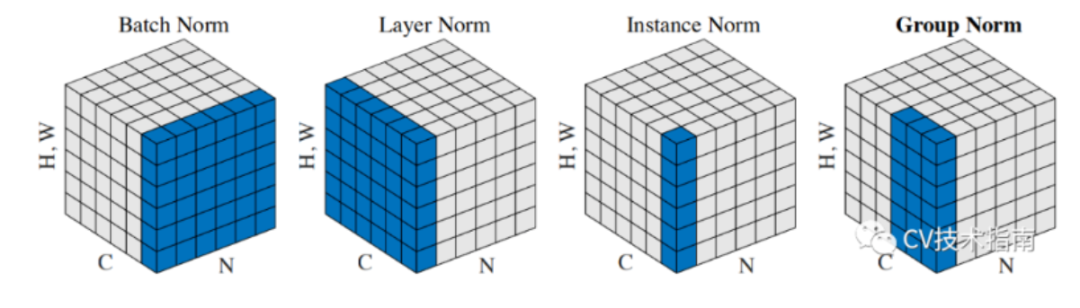
后面这三个解决的主要问题是BN的效果依赖于batch size,当batch size比较小时,性能退化严重。可以看到,IN,LN和GN都与batch size无关。
它们之间的区别在于计算均值和方差的数据范围不同,LN计算单个样本在所有通道上的均值和方差,IN值计算单个样本在每个通道上的均值和方差,GN将每个样本的通道分成g组,计算每组的均值和方差。
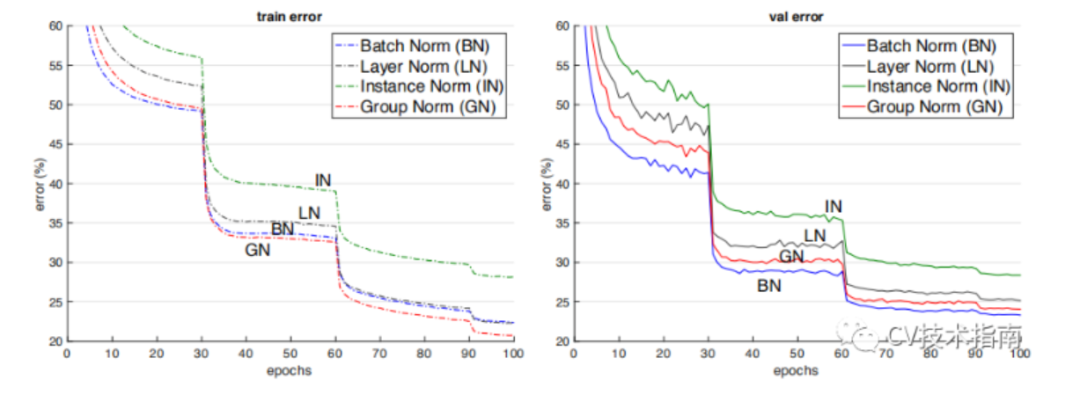
它们之间的效果对比。(注:这个效果是只在同一场合下的对比,实际上它们各有自己的应用场景,且后三者在各自的应用场合上都明显超过了BN)
论文:Instance Normalization: The Missing Ingredient for Fast Stylization
在图像视频等识别任务上,BN的效果是要优于IN的。但在GAN,style transfer和domain adaptation这类生成任务上,IN的效果明显比BN更好。
从BN与IN的区别来分析产生这种现象的原因:BN对多个样本统计均值和方差,而这多个样本的domain很可能是不一样的,相当于模型把不同domain的数据分布进行了归一化。
论文:Layer Normalization
BN的第一个缺陷是依赖Batch size,第二个缺陷是对于RNN这样的动态网络效果不明显,且当推理序列长度超过训练的所有序列长度时,容易出问题。为此,提出了Layer Normalization。
当我们以明显的方式将批归一化应用于RNN时,我们需要为序列中的每个时间步计算并存储单独的统计信息。如果测试序列比任何训练序列都长,这是有问题的。LN没有这样的问题,因为它的归一化项仅取决于当前时间步长对层的总输入。它还只有一组在所有时间步中共享的增益和偏置参数。(注:LN中的增益和偏置就相当于BN中的gamma 和beta)
LN的应用场合:RNN,transformer等。
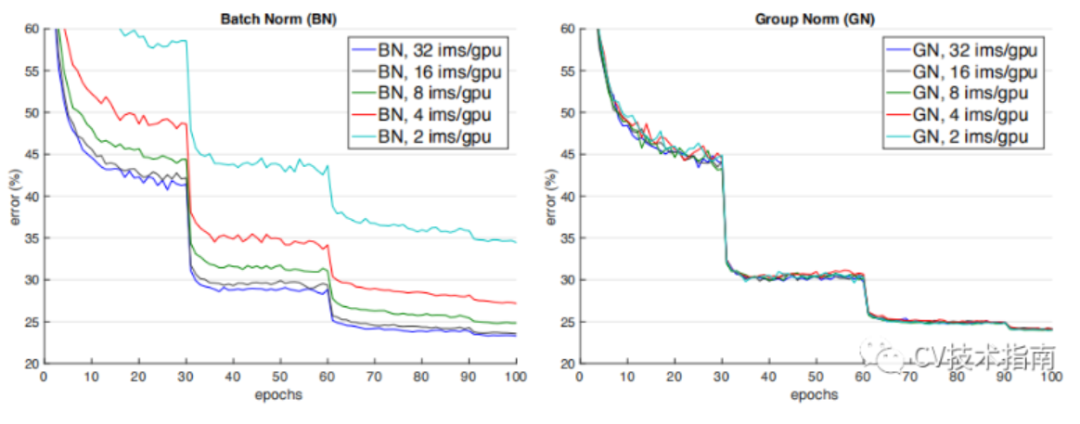
论文:Group Normalization
如下图所示,当batch size减少时,BN退化明显,而Group Normalization始终一致,在batch size比较大的时候,略低于BN,但当batch size比较小的时候,明显优于BN。
但GN有两个缺陷,其中一个是在batchsize大时略低于BN,另一个是由于它是在通道上分组,因此它要求通道数是分组数g的倍数。
GN应用场景:在目标检测,语义分割等要求尽可能大的分辨率的任务上,由于内存限制,为了更大的分辨率只能取比较小的batch size,可以选择GN这种不依赖于batchsize的归一化方法。
GN实现算法

Weights Normalization(2016)
论文:Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks
前面的方法都是基于feature map做归一化,这篇论文提出对Weights做归一化。
解释这个方法要费挺多笔墨,这里用一句话来解释其主要做法:将权重向量w分解为一个标量g和一个向量v,标量g表示权重向量w的长度,向量v表示权重向量的方向。
这种方式改善了优化问题的条件,并加速了随机梯度下降的收敛,不依赖于batch size的特点,适用于循环模型(如 LSTM)和噪声敏感应用(如深度强化学习或生成模型),而批量归一化不太适合这些应用。
Weight Normalization也有个明显的缺陷:WN不像BN有归一化特征尺度的作用,因此WN的初始化需要慎重,为此作者提出了对向量v和标量g的初始化方法。
Batch Renormalization(2017)
Cross-GPU BN(2018)
FRN(2019)
Cross-Iteration BN(2020)
本文介绍了目前比较经典的归一化方法,其中大部分都是针对BN改进而来,本文比较详尽地介绍了它们的主要思想,改进方式,以及应用场景,部分方法并没有详细介绍实现细节,对于感兴趣或有需要的读者请自行阅读论文原文。
除了以上方法外,还有很多归一化方法,例如Eval Norm,Normalization propagation,Normalizing the normalizers等。但这些方法并不常用,这里不作赘述。

 点击 “阅读原文”进入官网
点击 “阅读原文”进入官网
