点击上方↑↑↑“OpenCV学堂”关注我
来源:公众号 新智元 授权
基于文本的图像生成模型效果惊艳,可以说是时下讨论最火热的AI研究领域了,内行外行都能看个热闹。最近Google投稿ICLR 2023的一篇论文在生成模型界又掀起波澜,除了让照片动起来,文中提出的Phenaki模型还可以在文本描述中添加剧情,让视频内容更丰富。论文链接:https://openreview.net/forum?id=vOEXS39nOFA photorealistic teddy bear is swimming in the ocean at San Francisco.The teddy bear goes under water.The teddy bear keeps swimming under the water with colorful fishes.A panda bear is swimming under water.
如果说前面还算合理,看到最后泰迪熊变身大熊猫,实在绷不住了。这反转放短视频平台上不得几百万点赞,豆瓣评分都得9.9,扣0.1分怕你骄傲。Side view of an astronaut is walking through a puddle on marsThe astronaut is dancing on marsThe astronaut walks his dog on marsThe astronaut and his dog watch fireworks
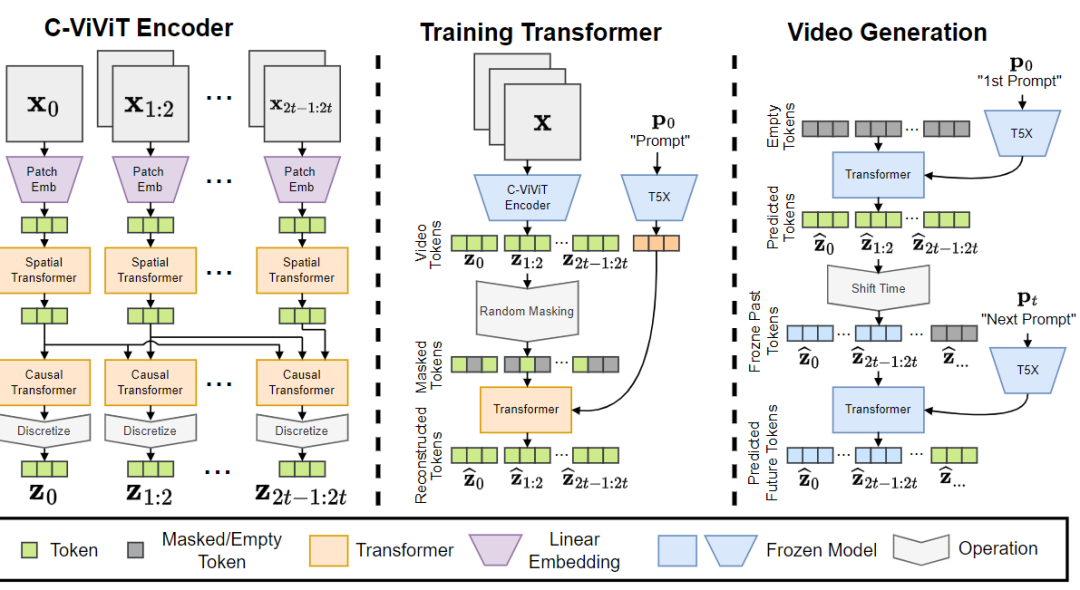
相比文本引导的图像生成模型来说,生成视频的计算成本更高,高质量的文本-视频训练数据也要少的多,并且输入的视频长度参差不齐等问题,从文本中直接生成视频更困难。为了解决这些问题,Phenaki引入了一个学习视频表示的新模型,将视频压缩后用离散tokens进行表征,tokenizer在时间维度上使用因果注意力(causal attention)来处理不同长度的视频,然后使用一个预训练的双向掩码Transformer模型对文本进行编码直接生成视频。
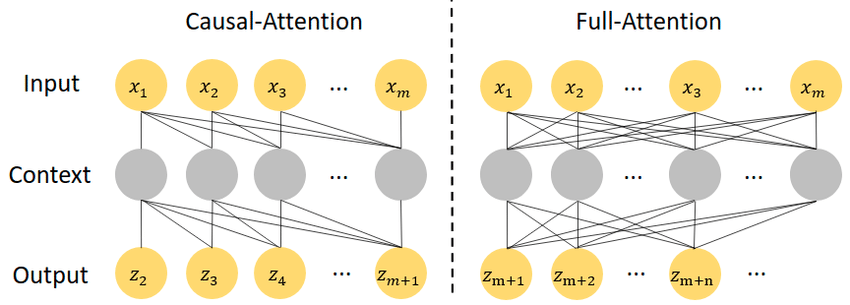
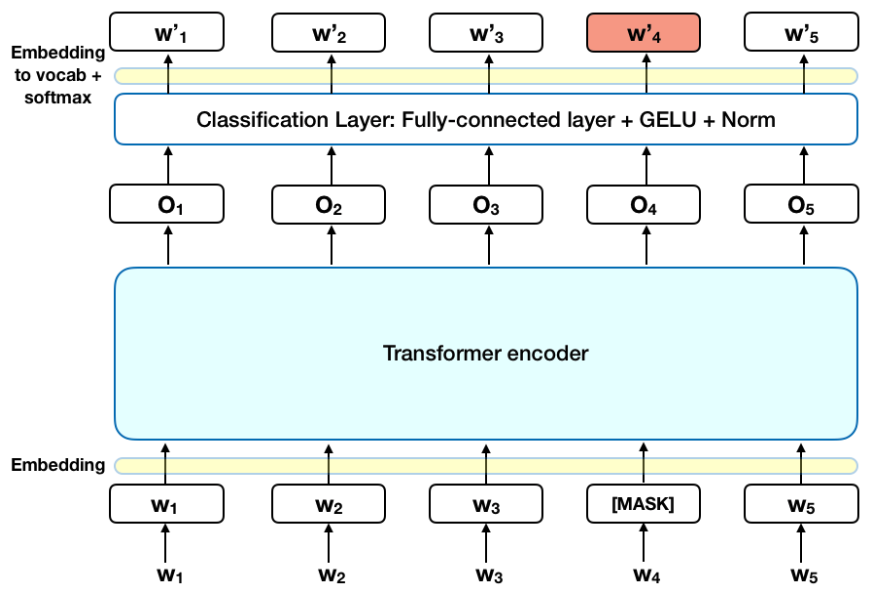
为了解决数据问题,研究人员提出一种联合训练方法,使用大量的文本-图像语料以及少量的文本-视频语料实现更好的泛化性能。与之前的视频生成方法相比,Phenaki支持任意领域的文本故事,剧情可以随时间变化且能够生成任意长度的视频。这也是第一次有论文研究从时间可变的文本提示中生成视频,并且文中提出的视频编码器/解码器在空间和时间上的质量均优于其他模型。从本质上讲,虽然视频就是一个图像序列,但生成一个长且连贯的视频却并不容易。图像领域不缺训练数据,比如LAION-5B, FFT4B等数据集都包括数十亿的文本-图像数据对,而文本-视频数据集如WebVid则只有大约一千万个视频,远远不够支撑开放领域的视频生成。从计算力上来看,训练和推理图像生成模型已经快把GPU的性能榨干了,是否能挤出计算空间留给视频生成解码器也是一个要解决的问题。文本引导的视频生成任务还有一个难点,一小段文本对于图片生成来说可能足够描述细节,但对于一个长视频来说远远不够,并且视频包括上下文,即下一个片段的生成需要以当前片段作为条件,随着时间的推移,故事逐渐展开。理想情况下,视频生成模型必须能够生成任意长度的视频,同时有能力将某一时刻的生成帧以当前时刻的文本提示作为条件,这些文本提示会随时间步变化。这种能力可以将视频与会动的图像明确区分开来,并为艺术、设计和内容创作等现实世界创造性应用开辟道路。在此之前,基于故事的有条件视频生成(story based conditional video generation)是一块从未被探索过的领域,这就是第一篇朝该目标迈出的论文。想要用传统的深度学习方法,即直接从数据中学习视频生成是不可能的,因为没有基于故事的数据集可以学习。为了实现这一目标,研究人员为Phenaki模型设计了两个组件,一个编码器-解码器模型用来把视频压缩成离散的embeddings,以及一个Transformer模型,把文本embeddings翻译成视频tokens,其中文本向量由预训练模型T5X进行编码。这个模块要解决的主要问题是如何获得视频的压缩表征,之前关于文本转视频的工作要么对每帧图像进行编码,但对视频长度有限制;要么使用固定长度的视频编码器,无法生成可变长度的视频。C-ViViT是ViViT的因果变体,专门为视频生成任务调整了模型架构,可以在时间和空间维度上压缩视频,同时在时间维度上保持自回归,从而允许自回归地生成任意长度的视频。首先在空间和时间Transformer中删除[CLS]标记,然后对所有由空间编码器计算的空间token使用时间Transfomrer,与ViViT中对[CLS]标记的单一时间Transformer的运行不同。最重要的是,ViViT编码器需要一个固定长度的视频输入,因为它在时间上采用的是all-to-all注意力。将其替换为因果注意力之后,C-ViViT编码器就会变成自回归,并允许输入帧的数量可变。2、使用双向Transformers从文本中生成视频可以把文本到视频的任务看作是sequence-to-sequence的问题,以预测输入的文本向量对应的视频tokens大部分的seq-to-seq模型都使用自回归Transformer,根据编码的文本特征按照顺序预测图像或视频tokens,即采样时间与序列长度成线性关系,对于长视频的生成来说是不可接受的。Phenaki采用掩码双向Transformer,通过一个小且固定的采样步骤来减少采样时间,而无需考虑不同的视频序列长度,双向Transfomrer可以同时预测不同的视频tokens在每个训练步骤,首先从0到1中随机选择一个掩码比率,并根据视频长度随机地用特殊标记[MASK]替换一部分token然后根据给定的文本向量和未掩码的视频tokens,通过最小化掩码token的交叉熵损失来学习模型参数。在推理过程中,首先将所有的视频tokens标记为特殊词[MASK],然后在每个推理步骤中,根据文本向量和未掩码的(要预测的)视频tokens,平行地预测所有被掩码(未知)的视频token在每个采样步骤中,选择一个预测token的比例,其余的tokens在下一步中将被重新掩码和重新预测。对于长视频的推理和自回归生成,使用事前训练(classifier-free)的引导来控制生成和文本条件之间的一致性。一旦生成了第一个视频,就可以通过使用C-ViViT对最后一个视频中的最后K个生成的帧进行编码,自动递归地推理出其他帧。用C-ViViT编码器计算出的token初始化MaskGIT,并继续生成以文本输入为条件的剩余视频标记。在视频推理过程中,文本条件可以是相同的,也可以是不同的,这也使得该模型能够在之前和当前文本条件的视觉内容之间动态地创建视觉过渡,有效地生成一个由输入文本描述的视觉故事。最终,研究人员在1500万8FPS的文本-视频对,5000万个文本-图像对,以及4亿混合语料库LAION-400M上进行训练,最终Phenaki模型参数量为18亿。batch size为512的情况下训练了100万步,用时不到5天,其中80%的训练数据来自视频数据集。在视觉的定性评价上,可以看到模型对视频中的人物和背景动态的控制程度都很高,并且外观和视频的风格也可以通过文本提示来调整(例如,普通视频、卡通或铅笔画)在定量比较上,Phenaki在zero-shot设置下实现了和其他模型相当的生成质量。在考虑训练数据的影响时,可以发现在只用视频训练的模型和用更多的图像数据训练的模型之间存在着性能上的权衡。