

1. 什么是缓存
2. 缓存的定义
3. 计算机中的高速缓存
3.1 高速缓存相关名词
3.2 计算机中的高速缓存存储器模型
3.3 计算机中有哪些缓存
3.4 硬件读取高速缓存的过程
4. 直接映射高速缓存
4.1 组选择
4.2 行匹配
4.3 字选择
4.4 模拟直接映射缓存
4.5 直接映射高速缓存的缺陷
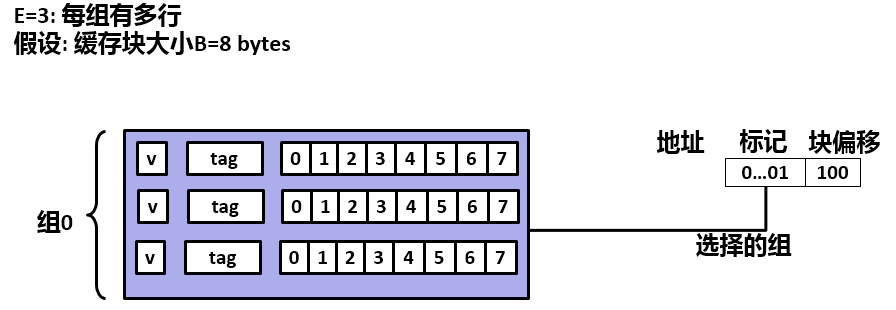
5. 两路相联高速缓存
5.1 组选择
5.2 行匹配
5.3 字选择
5.4 模拟两路相联高速缓存
6. 全相联高速缓存
7. 真实计算机系统中的缓存
8. 缓存的评价指标
8.1 不命中率
8.2 命中率
8.3 命中时间
8.4 未命中惩罚
9. 总结
缓存又叫高速缓存,是计算机存储器中的一种,本质上和硬盘是一样的,都是用来存储数据和指令的 。它们最大的区别在于读取速度的不同。程序一般是放在内存中的,当CPU执行程序的时候,执行完一条指令需要从内存中读取下一条指令,读取内存中的指令要花费100000个时钟周期(缓存读取速度为200个时钟周期,相差500倍),如果每次都从内存中取指令,CPU运行时将花费大量的时间在读取指令上。这显然是一种资源浪费。
如何解决这个问题呢?有人肯定会问,直接把程序存储在缓存中不行吗?
答案是可以的。但是,缓存的造价太贵了。具体如下图所示。以2015年的售价为例,1GB SRAM的价格大约为327680美元,而1GB 普通硬盘的价格仅仅为0.03美元。用缓存来存储程序成本太高了,得不偿失。

于是,有人就提出了这样一种方法,在CPU和内存之间添加一个高速内存, 这个高速内存容量小,只用来存储CPU执行时常用的指令。既保证了硬件成本,又提高了CPU的访问速度。这个高速内存就是缓存(高速缓存)。
高速缓存是一个小而快速的存储设备 ,它作为存储在更大更慢的设 备中的数据对象的缓冲区域。使用高速缓存的过程称为缓存 。
具体如下图所示,主存可以作为一个存储设备,L3是主存的缓冲区域,从L3存取数据的过程就叫做缓存。
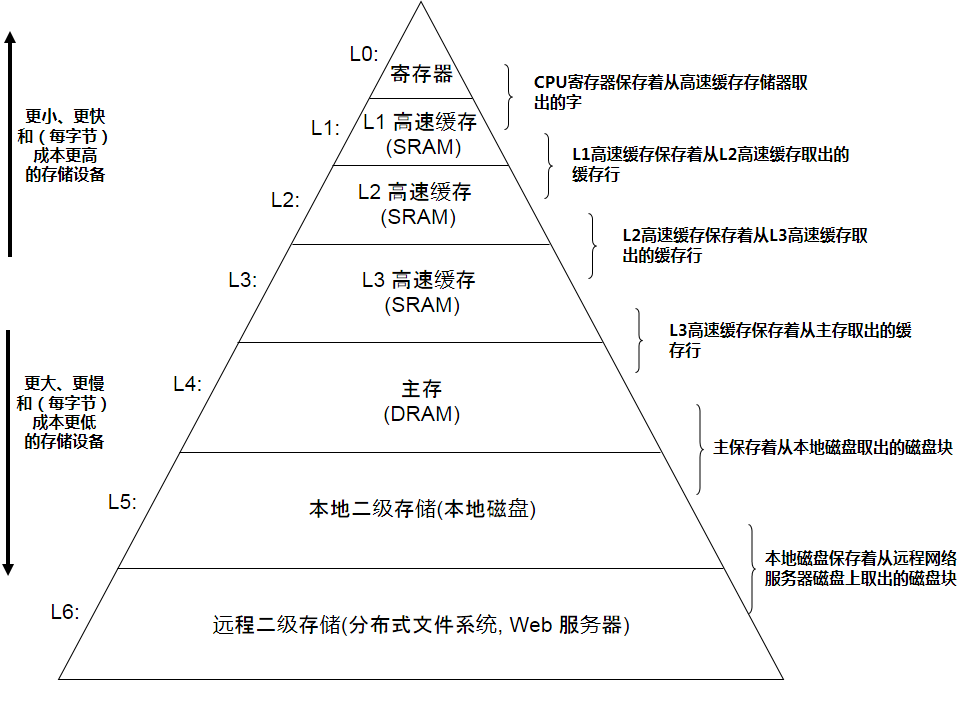
如下图所示,数据总是以块为单位 在高速缓存和主存之间来回复制。
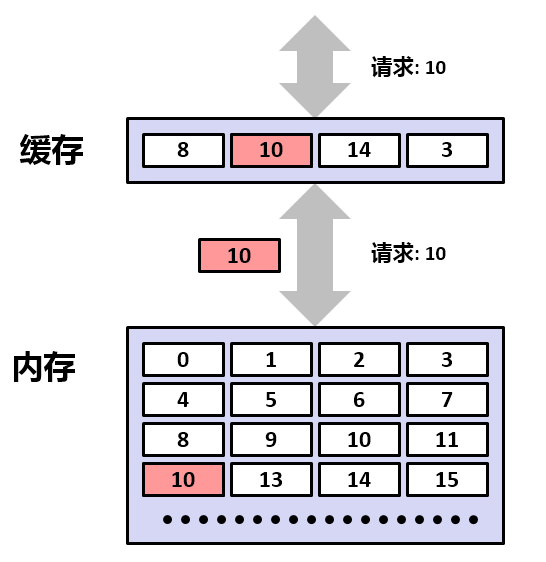
如果我们的程序请求一个数据字,这个数据字存储在编号为10的块中。将分以下几种情况考虑:
1. 高速缓存行中为空,这叫做冷不命中 。
2.高速缓存中有数据块,但没有数据块10,这叫做缓存不命中 。接下来缓存请求主存将该块复制到高速缓存,高速缓存接收到之后将替换一个现有的数据块,从而存储新的数据块在高速缓存中。最后,高速缓存将数据块10返回给CPU。
3. 高速缓存中有数据,将内存中的数据块放置到高速缓存中时,发生了冲突,这叫做冲突不命中 。
放置策略中最常用的是:第k+1层的块i必须放在第k层的块(i mod 4)中。比如,第k+1层的0,4,8,12会映射到第k层的块0。块1,5,9,13会映射到块1。
4. 缓存中有数据块10,则直接返回给CPU。这叫做缓存命中 。
高速缓存完全由硬件管理,硬件逻辑必须要知道,如何查找缓存中的块,并确定是否包含特定块。因此,必须以非常严格且简单的方式去构建高速缓存。在计算机中,高速缓存模型如下图所示。
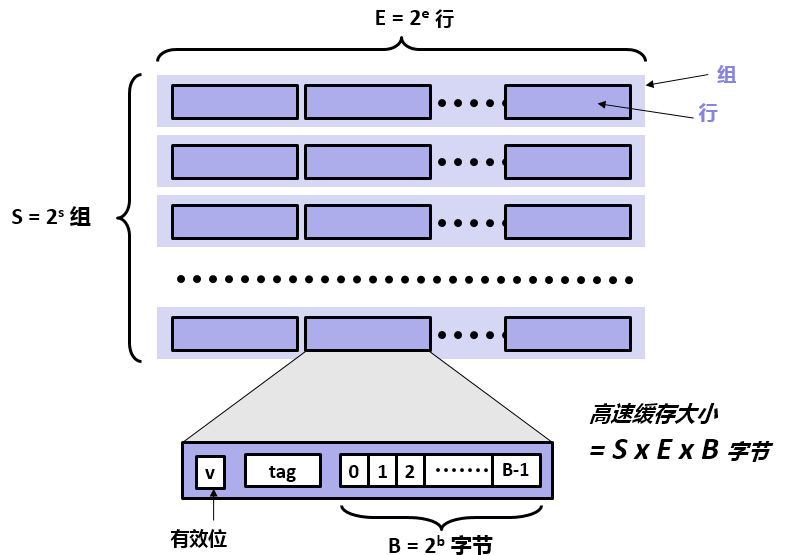
我们可以将高速缓存存储器视为有个高速缓存组的数组 。每个组包含个高速缓存行 。每个行是由一个字节的数据块组成的。
一般而言,高速缓存的结构可以用元组(S,E,B,m)来描述。高速缓存的大小(或容量)C指的是所有块的大小的和。标记位和有效位不包括在内 。因此,C=S×E×B。
每个高速缓存存储器有m位,可以组成个不同的地址,。每个数据块由以下三部分构成。
有效位:有效位为t位,t一般为1,指明这个行是否包含有效信息。
标记位:标记位为s位。唯一的标识了存储在高速缓存中的块(数组索引)。
块偏移:数据块为字节。指明CPU请求的内容在数据块中的偏移。
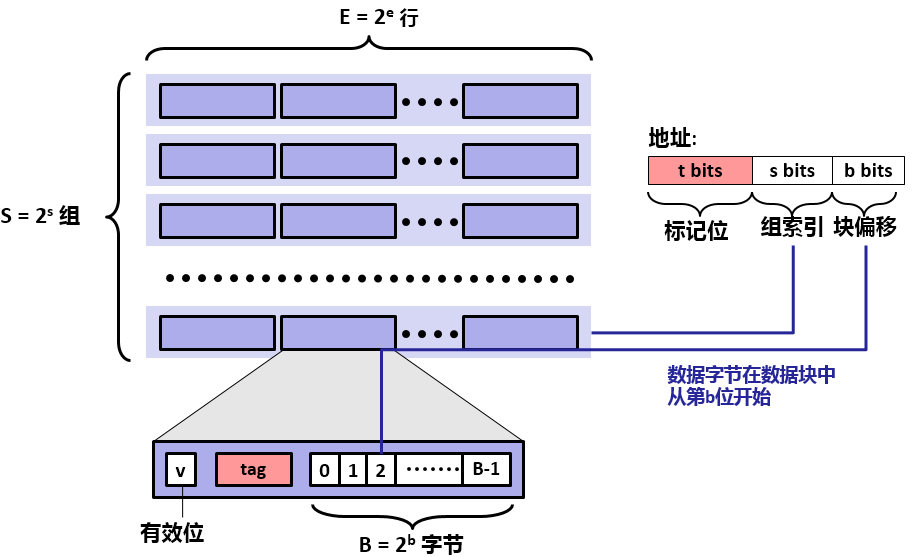
下面对以上内容出现的参数做个总结:
| 参数 | 描述 |
|---|---|
| S=2^s | 组数 |
| E | 每个组的行数 |
| B=2^b | 块大小(字节) |
| m=log2(M) | 物理地址位数 |
| M=2^m | 内存地址的最大数量 |
| s=log2(S) | 组索引位数量 |
| b=log2(B) | 块偏移位数量 |
| t=m-(s+b) | 标记位数量 |
| C=B*E*S | 不包括像有效位和标记位这样开销的高速缓存大小(字节) |
下表为现代计算机中用到的各种缓存。
| 类型 | 缓存什么 | 被缓存在何处 | 延迟(周期数) | 由谁管理 |
|---|---|---|---|---|
| CPU寄存器 | 4字节或8字节 | 芯片上的CPU寄存器 | 0 | 编译器 |
| TLB | 地址翻译 | 芯片上的TLB | 0 | 硬件MMU |
| L1高速缓存 | 64字节块 | 芯片上的L1高速缓存 | 4 | 硬件 |
| L2高速缓存 | 64字节块 | 芯片上的L2高速缓存 | 10 | 硬件 |
| L3高速缓存 | 64字节块 | 芯片上的L3高速缓存 | 50 | 硬件 |
| 虚拟内存 | 4KB页 | 主存 | 200 | 硬件 |
| 缓冲区缓存 | 部分文件 | 主存 | 200 | OS |
| 磁盘缓存 | 磁盘扇区 | 磁盘控制器 | 100000 | 控制器固件 |
| 网络缓存 | 部分文件 | 本地磁盘 | 10000000 | NFS客户 |
| 浏览器缓存 | Web页 | 本地磁盘 | 10000000 | Web浏览器 |
| Web缓存 | Web页 | 远程服务器磁盘 | 1000000000 | Web代理服务器 |
当一条加载指令指示CPU从主存地址A中读取一个字w时,会将该主存地址A发送到高速缓存中,则高速缓存会根据以下步骤判断地址A是否命中:
组选择:根据地址划分,将中间的s位表示为无符号数作为组的索引 ,可得到该地址对应的组。
行匹配:根据地址划分,可得到t位的标志位,由于组内的任意一行都可以包含任意映射到该组的数据块,所以就要线性搜索组中的每一行,判断是否有和标志位匹配且设置了有效位的行 ,如果存在,则缓存命中,否则缓冲不命中。
字抽取:如果找到了对应的高速缓存行,则可以将b位表示为无符号数作为块偏移量 ,得到对应位置的字。
当高速缓存命中时,会很快抽取出字w,并将其返回给CPU。如果缓存不命中,CPU会进行等待,高速缓存会向主存请求包含字w的数据块,当请求的块从主存到达时,高速缓存会将这个块保存到它的一个高速缓存行中,然后从被存储的块中抽取出字w,将其返回给CPU。
上面我们介绍了计算机中的高速缓存模型,我们可以根据每个组的高速缓存行数E,将高速缓存分成不同的类型。下面我们看下直接映射高速缓存(E=1)的具体例子。
组选择示意图如下所示。假设有 S 组,每组由一行组成,缓存块为8字节。CPU发出地址要取数据字,高速缓存将该地址分解为三部分,对于图中的地址来说,块偏移量为4。组索引是 1 ,粉红色的为t位标记位。因此,高速缓存提取的组索引为 1,即图中第二行。
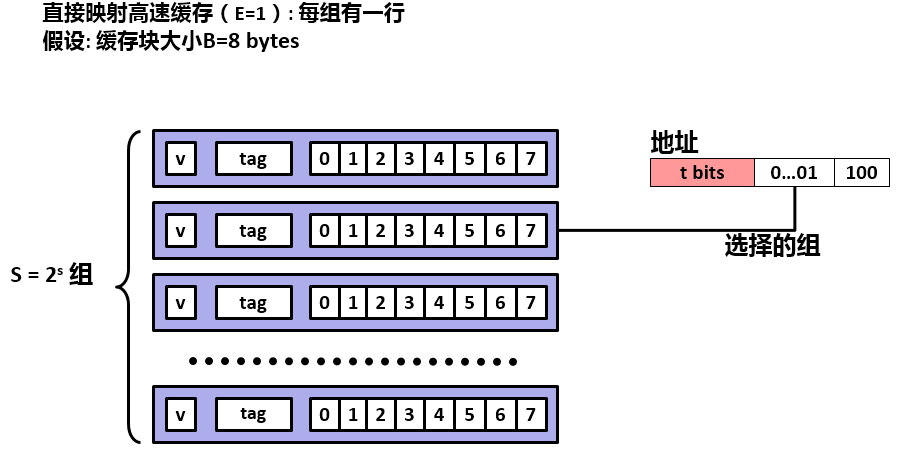
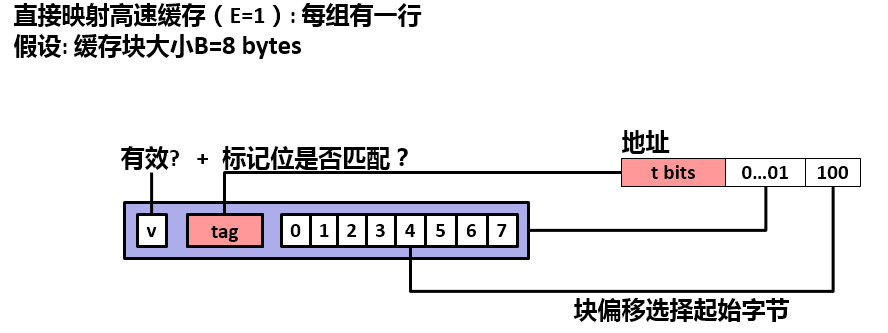
然后,检查地址中的标记位与缓存行中的标记位是否匹配。如果匹配,将进行下一步字选择。如果不匹配,则表示未命中。在未命中时,高速缓存必须从内存中重新取数据块, 在行中覆盖此块。
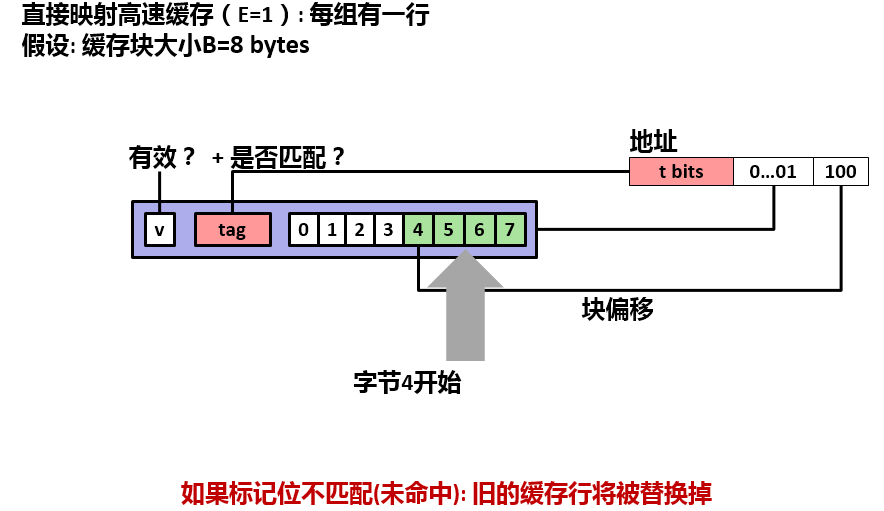
当标记位匹配时,表示命中,接着检查地址中的块偏移为4,即要从缓存行数据块的第5位开始取值,并返回给CPU。
下面,我们模拟下直接映射高速缓存的过程,以便加深理解高速缓存是如何工作的。假设,内存地址为4字节,S=4组,E=1行/组,B=2字节/块。其结构图如下所示。
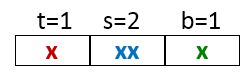
我们模拟CPU要从高速缓存中读取地址为0,1,7,8,0的数据。下面是具体的过程。
| 地址 | 二进制 | 是否命中 |
|---|---|---|
| 0 | [](t=0,s=00,b=0) | |
| 1 | [](t=0,s=00,b=1) | |
| 7 | [](t=0,s=11,b=1) | |
| 8 | [](t=1,s=00,b=0) | |
| 0 | [](t=00,s=0,b=0) |
1. 读地址0的数据。标记位为0,索引位为00,偏移位为0,块号为0。缓存行中没有数据,组0的有效位为0,地址的标记位和组0的标记位不匹配,因此,未命中。然后,高速缓存从内存中取出块0,块1, 共2字节,并存储在组0中。具体如下图所示。
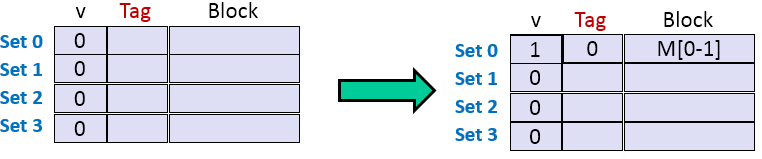
2. 读地址1的数据。标记位为0,索引位为00,偏移位为1,块号1。缓存行中已有数据数据,组0的有效位为1,地址1的标记位和组0的标记位匹配,因此,命中。具体如下图所示。

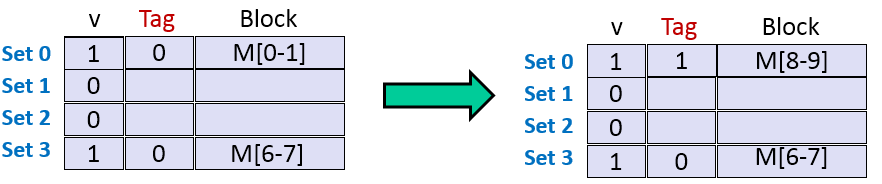
3. 读地址7的数据。标记位为0,索引位为11(3),偏移位为1,块号为3。缓存行中有数据,组3的有效位为0,地址的标记位和组0的标记位不匹配,因此,未命中。然后,高速缓存从内存中取出块6,块7, 共2字节,并存储在组3中。具体如下图所示。

4. 读地址8的数据。标记位为1,索引位为00,偏移位为0,块号为4。缓存行中有数据,组0的有效位为1,地址的标记位和组0的标记位不匹配,因此,未命中。然后,高速缓存从内存中取出块8,块9, 共2字节,并存储在组0中。具体如下图所示。
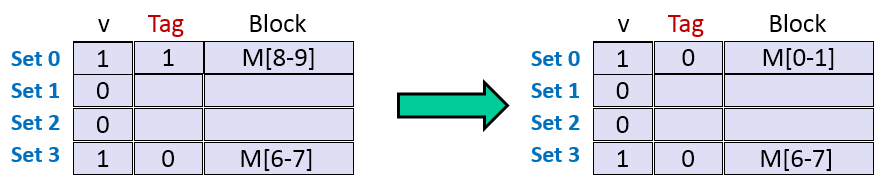
5. 读地址0的数据。标记位为0,索引位为00,偏移位为0,块号为0。缓存行中有数据,组0的有效位为1,地址的标记位和组0的标记位不匹配,因此,未命中。然后,高速缓存从内存中取出块0,块1, 共2字节,并存储在组0中。具体如下图所示。
最终结果如下:缓存命中率为20%。
| 地址 | 二进制 | 是否命中 |
|---|---|---|
| 0 | [](t=0,s=00,b=0) | 否 |
| 1 | [](t=0,s=00,b=1) | 是 |
| 7 | [](t=0,s=11,b=1) | 否 |
| 8 | [](t=1,s=00,b=0) | 否 |
| 0 | [](t=00,s=0,b=0) | 否 |
注意:块大小为2字节,所以从内存中取数据总是以偶数倍开始的,所以会看到M[8-9],而不是M[7-8]。
如果你看懂了上述高速缓存的整个过程,考虑下如何编程来模拟高速缓存呢?后面的文章我会详细讲解如何用C语言模拟高速缓存,欢迎关注我的公众号【嵌入式与Linux那些事】,第一时间获取更新。
观察以上过程其实可以发现,在第5步,读地址0的数据的时候,我们又得重新从内存中取数据到缓存行中。在读地址8的数据的时候,M[8-9]替换了缓存行中的M[0-1]。
最主要的原因是每一个组中只允许存放一行缓存。假设,E = 2,每组中有2个缓存行,M[8-9]和M[0-1]就有很大可能同时存在于组0中。我们在第5步访问时,就不需要重新从内存中取数据了。因此,就有了E = 2的两路相联高速缓存。
直接映射高速缓存中冲突不命中造成的问题源于每个组只有一行这个限制。组相联高速存放松了这条限制,所以每个组都保存有多于一个的高速缓存行。如下图所示为两路相联的高速缓存。
它的组选择与直接映射高速缓存的组选择一样,组索引位标识组。具体如下图所示,这里不再赘述。
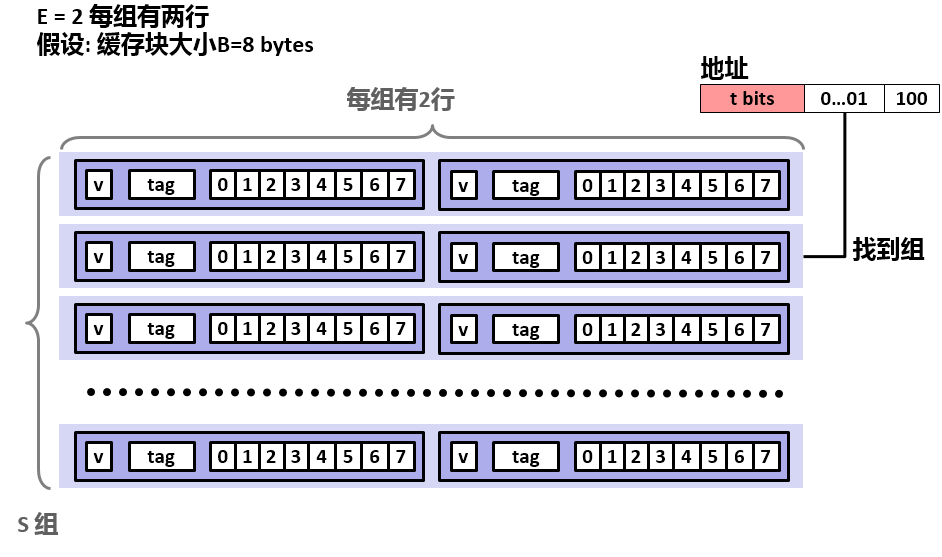
组相联高速缓存中的行匹配比直接映射高速缓存中的更复杂,因为它必须每次检查多个行 的标记位和有效位,以确定所请求的字是否在集合中。具体如下图所示。
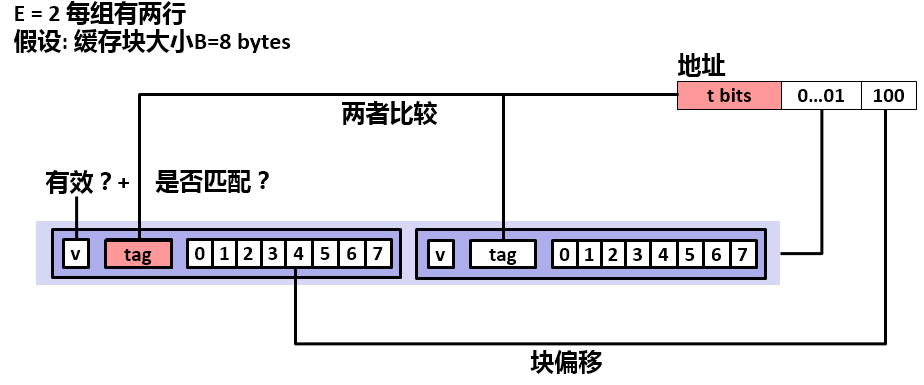
字选择的过程和直接映射高速缓存中的方式一样,这里就不再赘述。

下面,我们模拟下两路相联高速缓存的过程,以便加深理解高速缓存是如何工作的。假设,内存地址为4字节,S=2组,E=2行/组,B=2字节/块。其结构图如下所示。
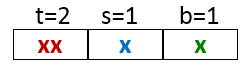
我们模拟CPU要从高速缓存中读取地址为0,1,7,8,0的数据。下面是具体的过程。
| 地址 | 二进制 | 是否命中 |
|---|---|---|
| 0 | [] (t=00,s=0,b=0) | |
| 1 | [](t=00,s=0,b=1) | |
| 7 | [](t=01,s=1,b=1) | |
| 8 | [](t=10,s=0,b=0) | |
| 0 | [](t=00,s=0,b=0) |
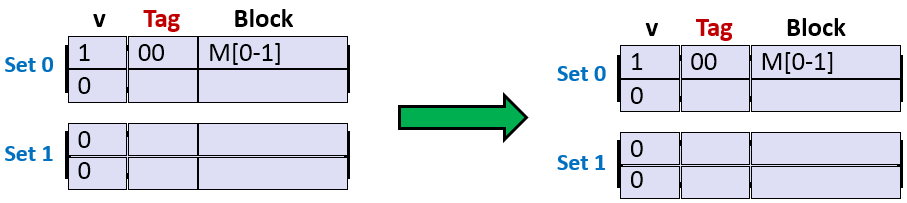
1. 读地址0的数据。标记位为00,索引位为0,偏移位为0,块号为0。缓存行中没有数据,组0的有效位为0,地址的标记位和组0的第一行和第二行的标记位都不匹配,因此,未命中。然后,高速缓存从内存中取出块0,块1, 共2字节,并存储在组0第一行中。具体如下图所示。

2. 读地址1的数据。标记位为00,索引位为0,偏移位为1,块号为1。缓存行中已有数据数据,组0的第一行有效位为1,地址1的标记位和组0的第一行标记位匹配,因此,命中。具体如下图所示。
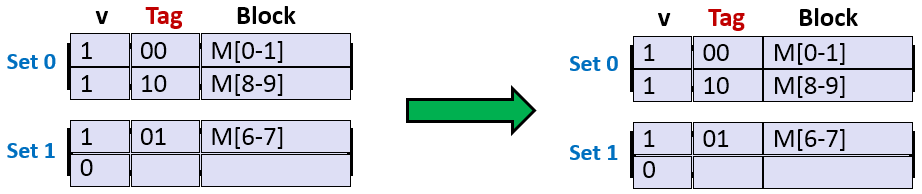
3. 读地址7的数据。标记位为01,索引位为1,偏移位为1,块号为1。缓存行中有数据,组1的有效位为0,地址的标记位和组1中的第一行和第二行的标记位不匹配,因此,未命中。然后,高速缓存从内存中取出块6,块7, 共2字节,并存储在组1中。具体如下图所示。

4. 读地址8的数据。标记位为10,索引位为0,偏移位为0,块号为0。缓存行中有数据,组0的第一行有效位为1,第二行有效位为0,地址的标记位和组0的第一行和第二行的标记位不匹配,因此,未命中。然后,高速缓存从内存中取出块8,块9, 共2字节,并存储在组0的第二行中。具体如下图所示。

5. 读地址0的数据。标记位为00,索引位为0,偏移位为0,块号为0。缓存行中有数据,组0的第一行有效位为1,地址的标记位和组0的第一行的标记位匹配,因此,命中。具体如下图所示。
| 地址 | 二进制 | 是否命中 |
|---|---|---|
| 0 | [] (t=00,s=0,b=0) | 否 |
| 1 | [](t=00,s=0,b=1) | 是 |
| 7 | [](t=01,s=1,b=1) | 否 |
| 8 | [](t=10,s=0,b=0) | 否 |
| 0 | [](t=00,s=0,b=0) | 是 |
两路相联高速缓存与直接映射高速缓存相比,在每组中增加了一行,缓存命中率提升了15%。避免了缓存频繁从内存中存取数据的情况,提高了程序运行速度。
全相联高速缓存中的行匹配和字选择与组相联高速缓存中的是一样的,过程就不再赘述,其结构图如下所示。
相联度越高越好吗?
答案是否定的。较高的相联度会造成较高的成本。实现难度大,价格昂贵,而且很难使之速度变快。较高的相联度会增加命中时间,因为复杂性增加了,另外,还会增加不命中处罚,因为选择牺牲行的复杂性也增加了。
相联度的选择最终变成了命中时间和不命中处罚之问的折中。一般来讲,高性能系统会为L1高速缓存选择较低的相联度(这里的不命中处罚只是几个周期),而在不命中处罚比较高的较低层上使用比较小的相联度。例如, Intel Core i7系统中,L和L2高速缓存是8路组相联的,而L3高速缓存是16路组相联的。
在此之前,我们一直假设高速缓存只保存数据。不过,实际上,高速缓存既保存数据,也保存指令。只保存指令的高速缓存称为 i-cache 。只保存程序数据的高速缓存称为 d-cache 。既保存指令又包括数据的高速缓存称为 统一的高速缓存 。
如下图所示为 Intel Core i7处理器的高速缓存层次结构。每个CPU芯片有四个核。每个核有自己的L1 i-cache, L1 d-cache和L2统一的高速缓存。所有的核共享片上L3统一的高速缓存。其具体参数如下表所示。
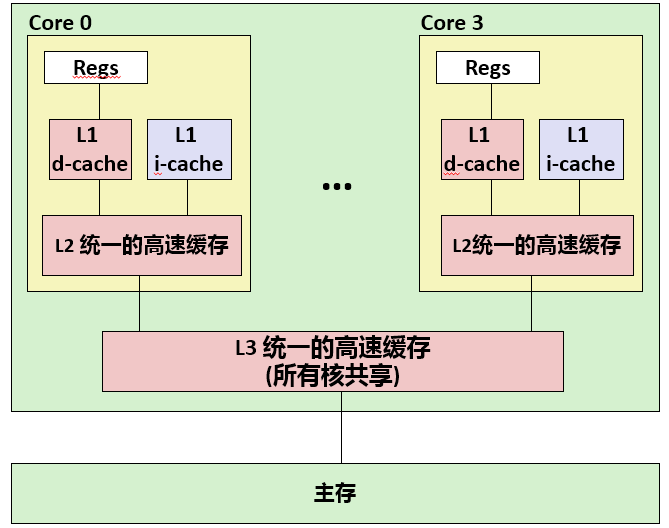
| 缓存 | 大小 | 内部结构 | 访问时间 |
|---|---|---|---|
| L1 | 32KB | 8路相联 | 4时钟 |
| L2 | 256KB | 8路相联 | 10时钟 |
| L3 | 8M | 16路相联 | 40-75时钟 |
最后介绍下衡量高速缓存性能的一些指标:
在一个程序执行或程序的一部分执行期间,内存引用不命中的比率,它等于: 不命中数量/引用数量。
命中的内存引用比率。它等于: 1-不命中率。
从高速缓存传送一个字到CPU所需的时间,包括组选择、行确认和字选择的时间。一般来讲,L1缓存的命中时间为:4个时钟。L2缓存的命中时间为:10个时钟。
未命中需要的额外时间。对于主存来说,一般为 50 ~ 200个时钟周期。
举个例子:
假设缓存命中时间为1个时钟周期,缓存未命中惩罚为100个时钟周期。
下面计算下97%缓存命中率和99%的缓存命中率的平均访问时间为多少?计算公式为命中时间加上未命中处罚乘以百分系数。
97%的命中率:时钟。
99%的命中率:时钟。
结论:命中率增加2%,平均访问时间减少了50%。
计算机中存在着各种各样的缓存,比如, 文件缓存 把一些需要高速存取的变量缓存在内存中,每次访问直接读出即可。 浏览器缓存 根据一套与服务器约定的规则进行工作,如果在浏览过程中前进或后退时访问到同一个图片,这些图片可以从浏览器缓存中调出而即时显示。数据库缓存 经常需要从数据库查询的数据、或经常更新的数据放入到缓存中,这样下次查询时,直接从缓存直接返回,减轻数据库压力。
我们了解这么多基本概念有什么用呢?如果我们理解了计算机系统是如何将数据在内存中组织和移动的,那么在写程序时就可以把数据项存储在合适的位置,CPU能更快地访问到它们,提高程序的执行效率。
END
来源:嵌入式与Linux那些事
