简 介: 本文测试了将AZure的文本生成的语音信号分割成不同的片段,适合进行视频的后期配音。分割利用了每一段语音之间的 0.5 秒中的间隔,这样可以将每一段的语音对应的分割出来。
**关键词**: AZure
如下是Azure网站提供的文字转换成语音的界面。文本转语音[1]

TEASOFT语音配音的转换布置:
利用BSIRFORM上的 “Action” 按钮生成视频配音文字。具体操作:alt+点击Action 。

TEASOFT 生成文字时,每一个Action中的文字形成一行。并对每一行进行如下的处理:
下面是转化后的文字样本。
今天在Youtube上,
看到一位Up主介绍了波形折叠电路,
并展示了它应用在电子音乐信号处理方面,
那么什么是波形折叠?
如何利用电路来实现呢?
首先讨论一下什么是波形折叠?
以这三个波形为例进行说明,
对于三角信号波形,
如果它的幅值超过一个阈值,
上面的波形则镜像折叠到阈值下面,
这就是波形折叠,
对于锯齿信号波形,
同样,
进行折叠之后,它变成了三角波,
对于方波信号,
信号折叠之后,
波形仍然是方波,
只是幅值下降,
波形没有变化,
下面,
如何利用电路来实现呢?
视频中给出了从简单到复杂的实现方法,
下面对此进行测试一下,
下面搭建单管折叠电路,
总共有三个器件,
这是电路原理图,NPN三极管使用8050.
从MSO24的信号源输出500Hz,
峰峰值为5V的三角波,
蓝色波形是输出的波形,
这是读入内存后的波形数据,
下面测量PNP折叠电路,
这是电路输出波形,
从MSO24读取的波形数据,
将上面两个电路并联在一起,形成双边这点电路,
这对峰峰值为1V的三角波处理结果,
调整不同幅值,
可以看到折叠信号始终维持在正负0.25V之内,
本文讨论了波形折叠电路,
根据Youtube上的UP主介绍的简单点路,
搭建了基于三极管的波形折叠电路,
验证了相关电路的工作原理,
进入 AZure 文本转语音界面。文本转语音[2] : https://azure.microsoft.com/zh-cn/products/cognitive-services/text-to-speech/#overview
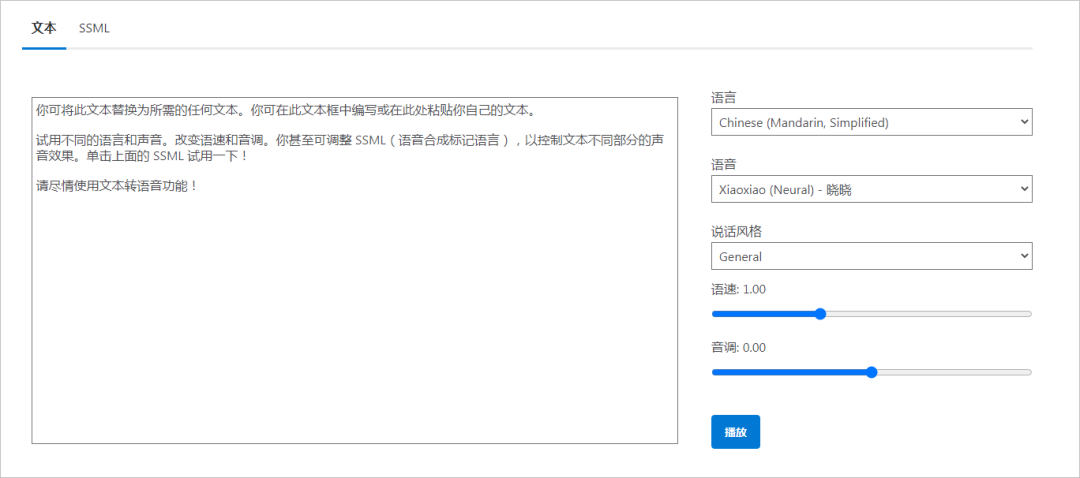
将上述文字拷贝到界面中的对话框内。选择合适的语言,语音,说话风格以及角色扮演等。
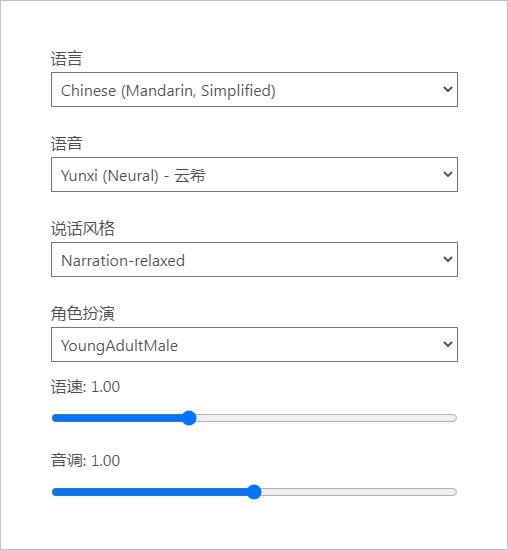
使用 Audacity软件进行录制语音合成结果,并存储到 .WAV 文件。
三、语音分割
分割每个语音利用了每一段之间存在 0.5秒的时间间隔。搜寻语音文件中所有长度大于等于 0.5 秒的时间间隔,将对应的数据存储在各自的语音文件中。
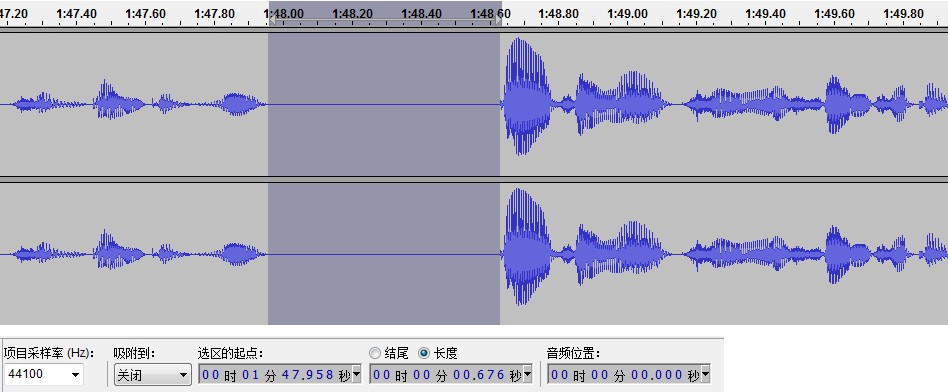
根据 电话双音频拨码信号采集[2] 所采用的 Python 对于语音处理的相关算法,进行上述合成语音的分割。
读取语音波形文件,获得相应的参数和数据。
from headm import *
from scipy.io import wavfile
wavefile = r'D:\Temp\11.wav'
sample_rate, sig = wavfile.read(wavefile)
printf(sample_rate, shape(sig))
保存的语音文件的采样率为 44100Hz,通过数量长度除以采样率,可以知道语音文件时间长度为 115.8s 。
44100 (5107840, 2)
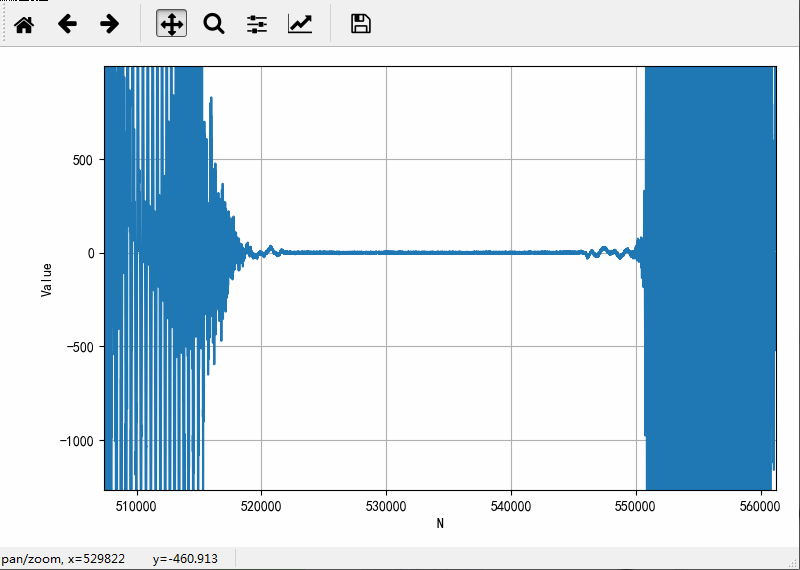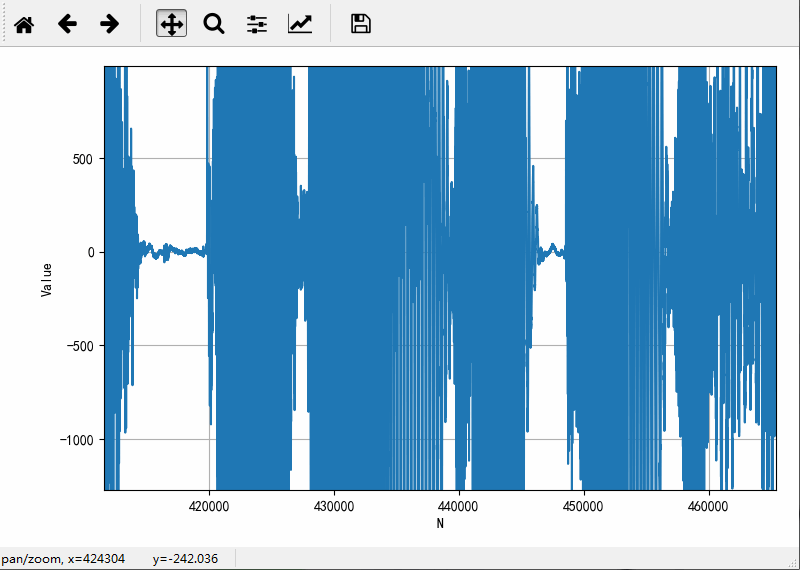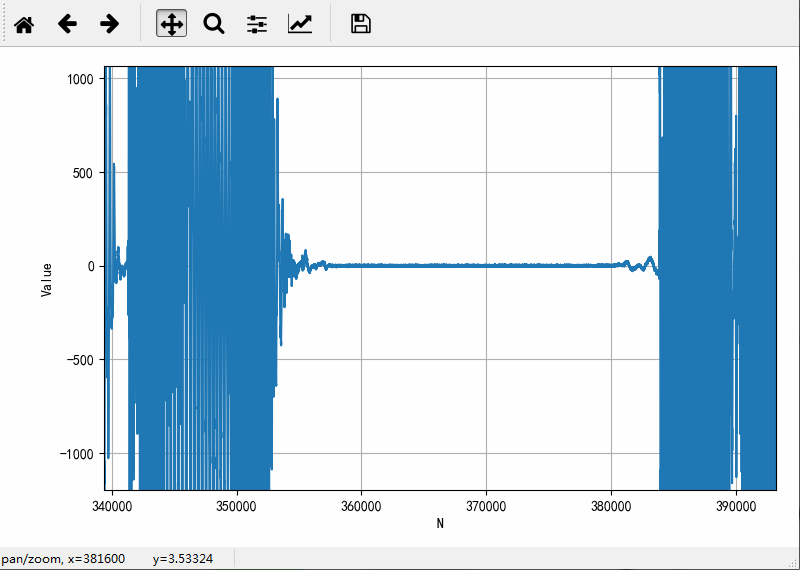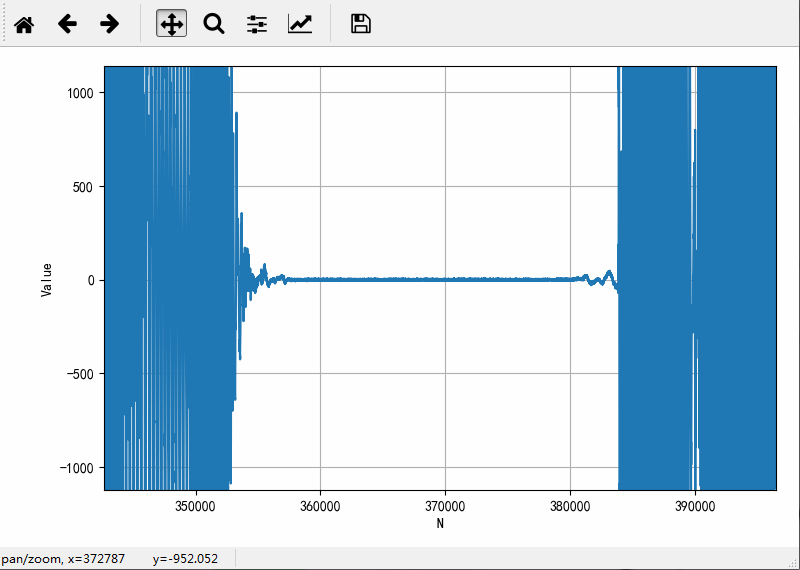
绘制其中一个声道的数据波形如下:
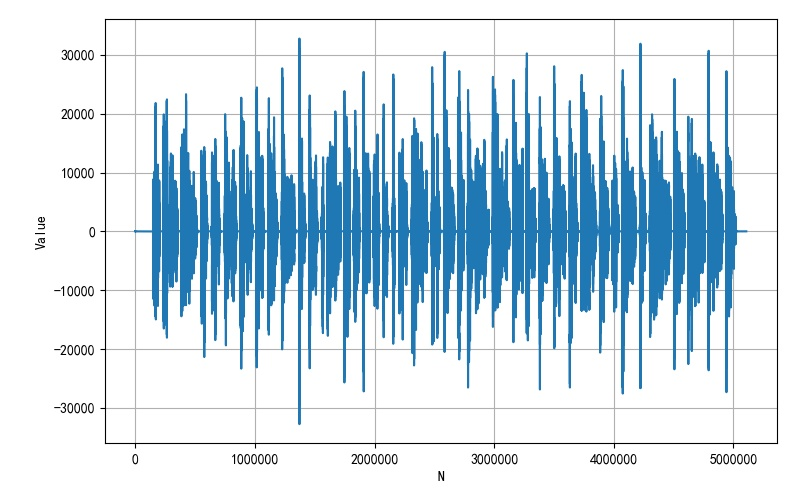
对于上述录制的音频文件波形进行分析,获得语音分割参数:
● 语音分割参数:
静音幅值:±25,这个数值最终定位50
静音时间长度:0.5s
#!/usr/local/bin/python
# -*- coding: gbk -*-
#******************************
# SPS.PY -- by Dr. ZhuoQing 2022-10-03
# Seperate speak signal into segment.
# Usage: sps wavefile silencevalue(int) silencetime(float)
#
# Before using sps, copy all voice string into clipboard.
#
# Note:
#******************************
from headm import *
from scipy.io import wavfile
from pydub import AudioSegment
wavefile = r'D:\Temp\11.wav'
#------------------------------------------------------------
try:
if not os.path.exists(r'd:\temp'):
os.makedirs(r'd:\temp')
if not os.path.exists(r'd:\temp\VOICE'):
os.makedirs(r'd:\temp\VOICE')
except OSError:
printf("Error :Creating directory of data.")
#------------------------------------------------------------
silencevalue = 25 # Silence max value
silencetime = 0.5 #
mp3flag = 0
#------------------------------------------------------------
strall = [s.strip('\r') for s in clipboard.paste().split('\n') if len(s) > 0]
for s in sys.argv:
fname = os.path.join(r'd:\temp', '%s.WAV'%s)
if os.path.isfile(fname):
wavefile = fname
continue
fname = os.path.join(r'd:\temp', '%s.MP3'%s)
if os.path.isfile(fname):
wavefile = fname
mp3flag = 1
continue
if s.isdigit():
silcencevalue = int(s)
if silencevalue > 1000:
silencevalue = 1000
continue
if s.replace('.', '').isdigit():
silcentime = float(s)
printff(wavefile, silencevalue, silencetime)
#------------------------------------------------------------
if mp3flag == 0:
sample_rate, sig = wavfile.read(wavefile)
sigdata = array(sig[:,0])
else:
sample_rate = 44100
sound = AudioSegment.from_file(file=wavefile)
left = sound.split_to_mono()[0]
sig = frombuffer(left._data, int16)
sigdata = array(sig)
#------------------------------------------------------------
sigdata[(sigdata > -silencevalue) & (sigdata < silencevalue)] = 0
sigdata[(sigdata <= -silencevalue) | (sigdata >= silencevalue)] = 1
sigone = where(sigdata == 1)[0]
sigdelta = array([x2-x1 for x1,x2 in zip(sigone[0:-1], sigone[1:])])
deltamin = int(sample_rate*silencetime)
sigmax = where(sigdelta > deltamin)[0]
sigsegment =[sigone[0]]
for sm in sigmax:
sigsegment.append(sigone[sm+1])
sigsegment.append(sigone[-1])
#------------------------------------------------------------
printff('Voice Segment:%d'%len(sigsegment), 'Voice String:%d'%len(strall))
printf('\a')
if len(sigsegment) - len(strall) != 1:
printf("Voice String Number error !\a")
exit()
#------------------------------------------------------------
for i in range(len(sigsegment) - 1):
startid = sigsegment[i]
endid = sigsegment[i+1] - sample_rate*3//4
wavefilename = '%04d.wav'%i
if i < len(strall):
sa = strall[i].replace(',', '').replace(',','').replace('.','').replace('。', '').replace(';','')
wavefilename = '%s.wav'%sa
outfile = os.path.join(r'd:\temp\VOICE', wavefilename)
if mp3flag == 0:
wavfile.write(outfile, sample_rate, sig[startid:endid, :])
else: wavfile.write(outfile, sample_rate, sig[startid:endid])
printf(outfile)
tspbeep(1800, 100)
#------------------------------------------------------------
# END OF FILE : SPS.PY
#******************************
在 sps 命令后面可以添加 wave 文件, 静音幅度, 静音时间等参数。需要注意的是, 在使用 sps 之前,需要将声音的文本拷贝到剪切板中。
分割后的文件存储在 d:\temp\VOICE 目录中。
对于上述程序进行了测试,它准确的将所有的语音进行了分割。
本文测试了将AZure的文本生成的语音信号分割成不同的片段,适合进行视频的后期配音。分割利用了每一段语音之间的 0.5 秒中的间隔,这样可以将每一段的语音对应的分割出来。
下面是利用AZure配音的短片:
文本转语音: https://azure.microsoft.com/zh-cn/products/cognitive-services/text-to-speech/#overview
[2]电话双音频拨码信号采集: https://blog.csdn.net/zhuoqingjoking97298/article/details/122606221?spm=1001.2014.3001.5501
