
当以太网接口的速率提升到100G以上后,用传统FPGA来实现对应的数据处理时,一定会遇到总线效率的问题。本文就分享团队对大位宽高速数据处理时采用的分段总线方法的一些心得,希望大家可以批评指正。
01
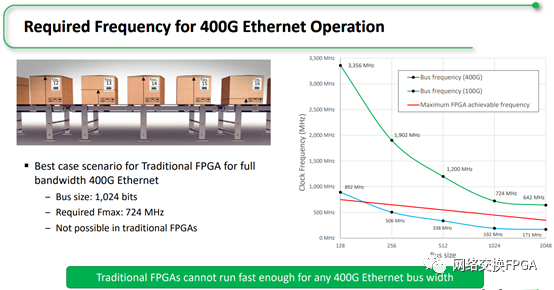
主要原因在于更宽的数据总线带来了总线效率的问题,针对变长数据输入的情景,当芯片内部总线位宽变大时,若每个总线字在数据传输过程中不能被有效利用,则可能导致总线效率降低。
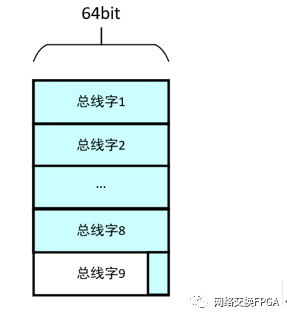
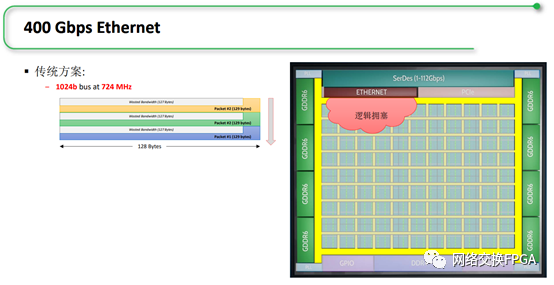
例如,在位宽为64bit的总线上传输65字节的数据帧,其在总线上的传输格式如下图所示,第9个总线字仅用来传输1字节,导致总线效率降低,约为90.3%。
若总线位宽再进一步提升至512bit后,如下图所示,总线效率只有50.8%。
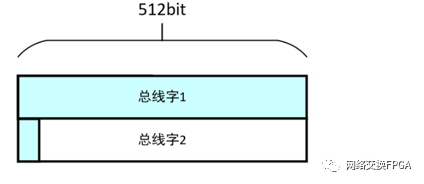
可见,在传统总线中,当传输数据量未对齐边界到总线位宽时,总线效率随位宽的拓宽而降低。
【以下内容来源于刘欢博士的论文】
为解决上述总线效率问题,需要引入分段总线格式。非分段总线每个 总线字内仅可以容纳一个数据帧的内容,当总线字不能被充分利用时(如长度为 64 字节的数据总线承载 65 字节的帧),未利用部分使用特定值(如全 0)做填充处理, 在某些帧长下,填充字段所占比例过高,导致总线效率低下。分段总线将数据总线字分为多个总线段,每个总线段可以容纳一个数据帧的内容,换言之,一个总线字由多个总线段组成,此时一个总线字可以承载多个数据帧的内容,从而降低了填充字段的影响。
分段总线在工业界与学术界均获得了关注与研究,在工业界,Xilinx 与 Intel 的 400G 和600G以太网 IP 核、PCIe IP核等的片内总线均采用了简单分段总线格式,以实现更高的总线效率;在学术界,涌现了一种新的分段总线架构:Multi Buses[1],下文分别对两种分段总 线格式进行介绍,并分析其总线效率与实现开销。
(1)Xilinx/Intel 分段总线格式
Xilinx 在其最新一代 Versal ACAP 中采用了 600G 以太网 IP 硬核[316],该 IP 核可以支持一个 400G 以太网端口+2个100G 以太网端口,对于 400G 以太网端口,用户侧采用1024比特数据总线,该数据总线分为 8 段,每段 128 比特;Intel 在其最新一代Agilex FPGA中采用Chiplet技术集成了400G 以太网[2-4],其面向用户侧接口 也采用了 1024 比特数据总线,该总线分为 16 段,每段 64 比特。Xilinx/Intel分段总线格式如图所示。
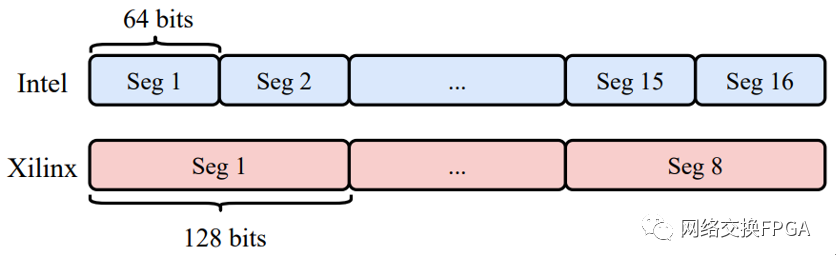
Xilinx/Intel 分段总线运行频率均为 390MHz 左右,在频率受限的前提下,通过使 用宽总线,可以实现更高的最高吞吐量;通过使用分段总线,可以在一个总线数据字中承载多个数据帧的数据,减小填充的影响,从而提升总线效率,增强对短数据帧的支持。
(2)Multi Buses 分段总线格式
最近,学术界涌现出了一种名为 Multi Buses 的新型分段总线,该总线格式如图所示,数据总线采用了 Word、Region、Block 和 Item 四个度量标准,下图仅为示意图,四种度量标准之间的数量关系可以任意定义。图中 Word 代表了总线字, 其长度与总线宽度相等;Block 与 Xilinx/Intel 分段总线格式中的总线段起到相同的 作用,即单个 Block 内仅可以承载一个数据帧的内容,未使用部分采用特定值填充;Item 即总线传输的最小单位,例如,以太网/PCIe等传输总线,其用户侧数据总线的 最小传输单位为 1 字节;Region 是 Multi Buses 引入的新概念,也是该总线的重要创新点,下面对 Region 的概念与优势进行详细介绍。
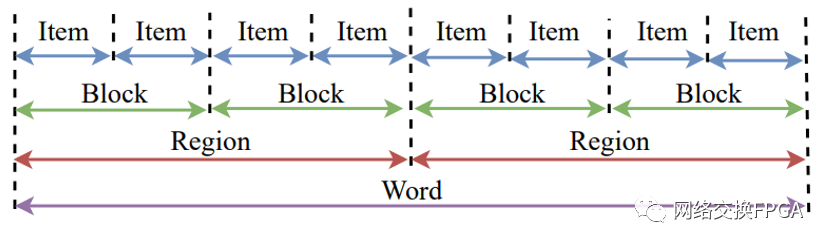
数据总线用于传输数据,而处理模块用于处理总线承载的数据,在设计总线格式时,除需要考虑总线的传输效率外,还需要顾及处理模块的实现复杂度。对于 Xilinx/Intel 分段总线,总线段的长度越小,填充字段造成的影响越小,因此可以实现更高的总线效率,但由于数据帧的结束可能发生在任意一个总线段,因此每个总线段都需要预留一个处理模块,换言之,总线效率提高的同时,设计的面积复杂度也线性提高了。
但是,需要注意的是,数据帧在传输时需要满足最小长度要求,例如,以太网帧的最小传输长度为 64 字节,数据帧的最小传输长度可能远大于总线段的长度,而处理模块处理数据时,一般以数据帧为单位。因此,如果可以把各个总线段的处理结果聚合为数据帧的处理结果,然后交由处理模块做进一步处理,如此可以有效减少处理模块的数量,进而减小面积开销。根据该思想,Multi Buses 提出了 Region 的概 念,Region 的大小与传输数据帧的最小长度紧密相关,在一个 Region 中,允许承载两个数据帧的内容,因此在一个 Region 中仅会出现一个数据帧结束,该结束数据帧的后续处理,将交由本 Region 对应的处理模块进行。
举例说明 Region 的概念与设计优势。使用 4096 比特/512 字节数据总线传输以太 网数据帧,当总线段长度为 8 字节时,总线段数量为 64,此时如果不引入 Region 的 概念,则需要 64个处理模块以完成数据帧的处理;以太网数据帧的最小长度为 64 字节,因此一个总线字中最多承载 9个数据帧的数据,并出现 8个数据帧结束,此时 56个处理模块都是空闲的。引入 Region 的概念,并将 Region 大小设置为 64 字节,此 时一个总线数据字可以分为 8个 Region,每个 Region 对应一个处理模块,数据处理模块的数量降低了 87.5%,当传输最短帧时,数据处理模块的利用率可以达到 100%。
(3)分段总线效率与面积开销分析
总线效率 𝑒𝑓𝑓𝑖𝑐𝑖𝑒𝑛𝑐𝑦 与总线段长度 𝑠𝑒𝑔𝑤𝑖𝑑𝑡ℎ、数据帧长度f𝐿𝑒𝑛的关系如下面公式所示,该公式含义为,分段总线的总线效率等于数据帧长度与所用总线段总长 度的比值,换言之,总线效率仅取决于数据帧长度与总线段长度,与 Region 的大小无关。
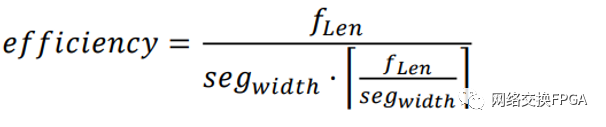
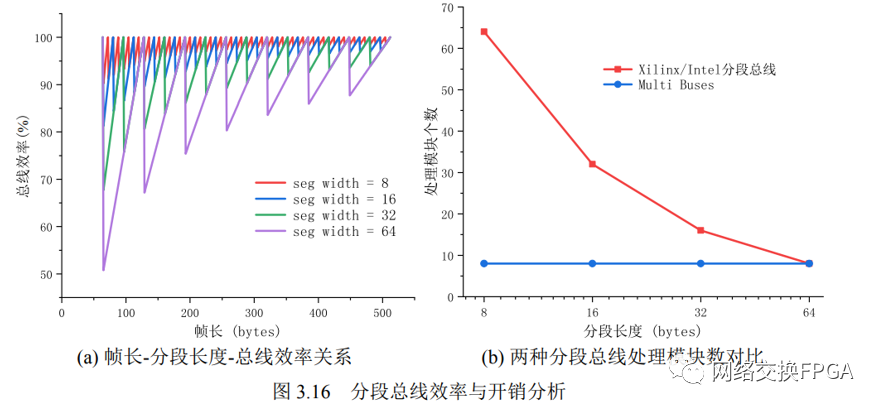
根据上面公式,考虑总线段长度为 8、16、32、64 字节的场景,当数据帧长度 范围为 64∼512 字节时,数据帧长、总线段长度与总线效率的关系如下图3.16a所示, 总线段长度为 8、16、32、64 字节时,对应的总线效率范围分别是 90.28%∼100%、 81.25%∼100%、67.71%∼100%、50.78%∼100%,可以发现,减小总线段长度可以保证最坏情况下的总线效率。
对于宽度为 4096 比特/512 字节的数据总线,当传输以太网帧(最小帧长 64 字节)时,对于 Multi Buses 分段总线,处理模块的数量仅与 Region 的数量有关,因此 无论分段长度如何,所需处理模块个数始终为 512/64 = 8;而对于 Xilinx/Intel 分段总线,所需处理模块数量等于总线段的数量,因此减小分段长度虽然可以提高最坏情况下的总线效率,但同时也会导致更高的面积开销。两种分段总线所需处理模块的对 比如图3.16b 所示。
【以上内容来源于刘欢博士的论文】
02
以Xilinx的PCIe2.0 IP核为例,该IP支持64bit和128bit两种总线位宽。
在64bit位宽的模式下,该IP与传统总线无异,因为64bit模式的位宽较小,且TLP报文均以32bit对界,所以不会对总线效率产生太大影响。
而在128bit位宽的模式下,该IP采用了类似分段的思想来处理接收方向的数据总线,即在一个时钟周期内,128bit的总线上可以同时允许有两个TLP帧在传输,Xilinx称其为Receiving Straddled(跨接),产生跨接的时序图如下所示:
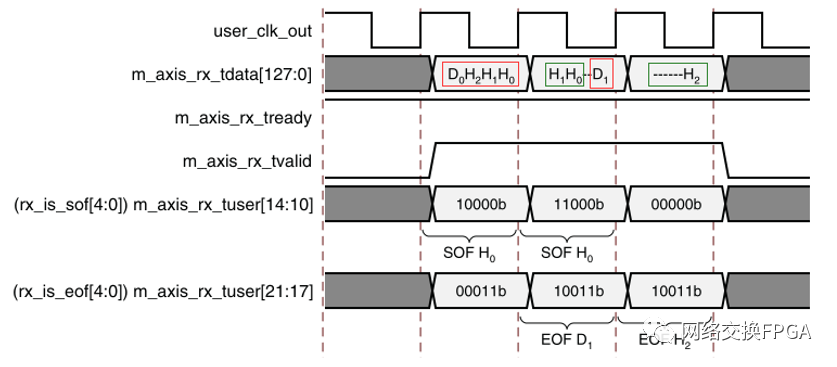
这种模式下AXIS的tlast信号不起作用,由边带信号tuser携带sof和eof信息来标识一帧的开始及结束。红框标出的是第一帧TLP,绿框是第二帧TLP,可见在跨接情况下,128bit总线允许一个周期中传输两帧的信息,在上图表示为第二个周期传输了帧1的尾数据和帧2的TLP Head,而在帧1的尾数据D1和帧2的TLP Head(H0、H1)间隔了一个DW,所以该总线可视为两段的分段总线,在一定程度上提高了总线的利用率。
若在上图的数据传输情况中,不对128bit总线采用2 seg分段,其效率为62.5%,需要3个时钟周期;而采用2 seg分段后效率提升至了87.5%,只需2个时钟周期。
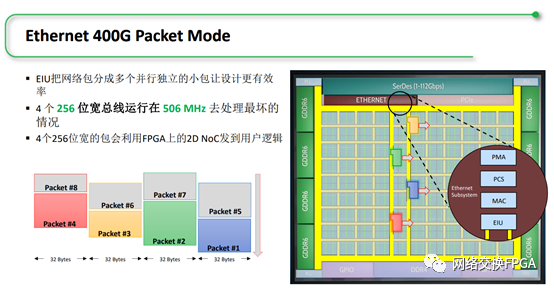
DCMAC是Xilinx最新一代自适应异构计算平台Versal ACAP中采用的600G以太网IP核,支持多种速率以太网的组合,总带宽可达600Gb/s,其用户端使用1536bit位宽的AXIS总线,频率为390.625MHz。
在这种超高位宽的总线中就不能像上述的PCIe2.0 IP一样还可以选择传统总线模式了,DCMAC对AXIS总线进行了12段的分段管理,每段为128bit。如下图所示:
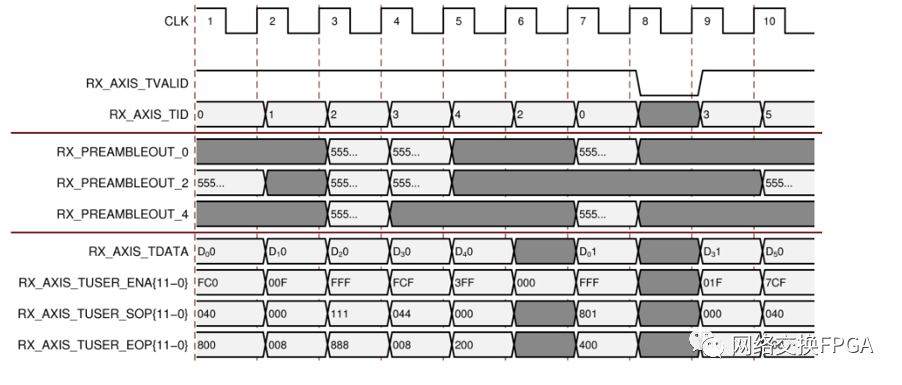
第一个时钟周期,信道0在段6上启动了一次传输,RX_PREAMBLEOUT0是本次传输的前导码,该传输在段11上结束,帧长最多为96字节。
第二个时钟周期,信道1在段3上结束了该信道在前面启动的传输。
第三个时钟周期,信道2在段0、段4和段8上分别启动了一次传输,且帧长都为64字节,也就是DCMAC的1536bit-12 seg分段总线可在一个时钟周期内同时接收处理三个以太网最短帧,这尤其在频繁传输小包的情况下能提高总线的传输效率。
个人理解:在分段总线中,越宽的总线需要更多的段数,因为一帧的传输都启动在一段的开头,段数少了,能够浪费的位宽就多了,效率就随之降低。但段数多了,相关处理逻辑的面积就会增加,功耗也会提高,需在效率(总线中表现为速度)、面积和功耗(PPA)中寻找平衡。
Corundum针对DMA的特点,采用一种分段存储器来存储DMA引擎接收的数据包或要发送给DMA引擎的数据包。
Corundum支持的MTU默认为9014字节,标准页面下MTU超过4KB的网络设备若想保证Host侧效率就不能进行socket缓冲区与DMA缓冲区间的数据复制,这就表示Host必须支持Scatter/Gather IO,而使用Scatter/Gather就意味着可能多笔DMA传输对应同一个网络数据包,Corundum使用tag号标识一个网络数据包并对outstanding提供支持,若使用普通存储器(FIFO或RAM),其存储格式可能如下图所示,不仅每一帧都会浪费一定的存储空间,还会在读取存储器时使同一帧的数据产生割裂,使后续处理成连续帧变得麻烦。
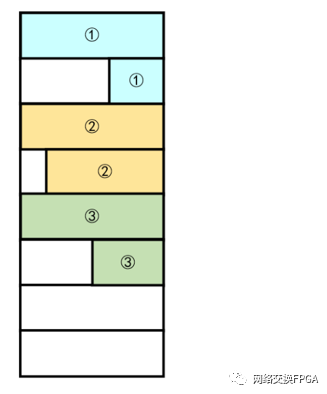
而Corundum的分段存储器可以将上图中片段①和片段②间的气泡进行消除和对齐,使一个数据包在存储和读取时都是完整连续的一帧,提高了存储效率,缩减了存储和读取的时钟周期,从而提高了存储器访问的带宽。
如下图所示,Corundum分段存储器的每个段都是一个独立的RAM,所以可以在同一个时钟周期索引存储器的不同行,这为跨行排气泡提供了可能。分段存储器的位宽是DMA总线位宽的2倍,在存储时将待存储的数据复制成三份拼接起来,根据字节首地址和长度信息进行滑动窗口操作来截取该数据在分段存储器的一行或两个相邻行中的放置位置,操作粒度为1字节,用字节掩码和段使能信号标识。
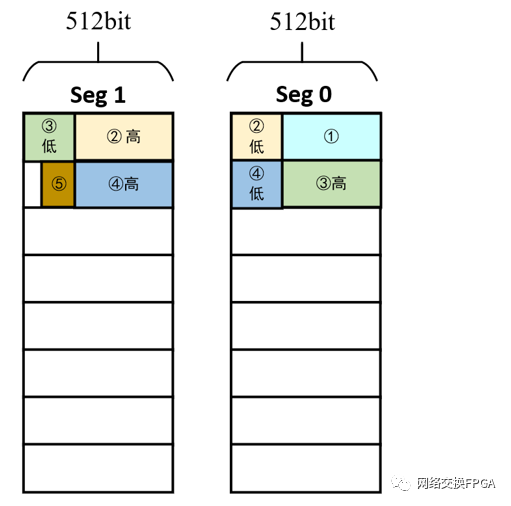
个人理解:与2.1和2.2的对总线的分段不同,Corundum对存储器的分段存储的目标是使一个网络数据包连续存储,提高其存储器读写的带宽。但是其下一个数据包不是从相邻段开始存储,而是从下一行的开头开始存储,由于后面要转换成AXIS总线进行传输,这样下一个网络数据包从分段存储器的下一行开始存储会减少转换电路的开销,更重要的是,即使从分段存储器的相邻段开始存储,在非跨行的情况下,也会对该行进行至少2次读取,这和读两行是一样的,都是两个时钟周期,并没有提高大帧之间的效率。
而对总线分段的目标是提高总线本身的传输效率,不涉及到存储器与其他总线间的转换关系,也不涉及到像DMA一样存在多个小帧组成一个大帧的情况,所以需要能在同一个总线周期传输多帧的能力,而不能像Corundum一样,没有在相邻段启动下一个大帧传输,因为这个大帧内部还有小帧,而小帧之间是排气泡的;它还不涉及到“读取”这种行为,读取的结果是没有字节掩码的,只有读取者自己知道哪些数据是有效的,这就产生了上述Corundum分段存储器如果对两个大帧进行非跨行的跨段存储,则在读取时需要对同一行读两次的情景,而总线则可通过边带信号直接携带位置信息,这样就可以在相邻两段存储两帧而不会对总线效率没有提升。

参考文献:
[1] KEKELY L, CABAL J, PUŠ V, et al. Multi buses: theory and practical considerations of data bus width scaling in fpgas[C]//2020 23rd Euromicro Conference on Digital System Design (DSD). IEEE, 2020: 49-56.
[2] XILINX. Versal ACAP 600G Channelized Multirate Ethernet Subsystem (DCMAC) v1.2 LogiCORE IP Product Guide[EB/OL]. [2022-4-20]. https://docs.xilinx.com/r/en-US/pg369-dcmac.
[3] INTEL. F-Tile Ethernet Intel® FPGA Hard IP User Guide[EB/OL]. [2022-4-20]. https://www. intel.com/content/www/us/en/docs/programmable/683023/21-4/overview-16832.html.
[4] INTEL. F-tile Architecture and PMA and FEC Direct PHY IP User Guide[EB/OL]. [2022-4-20]. https://www.intel.com/content/www/us/en/docs/programmable/683872/21-2/introduction.html.
作者:徐铭伟、刘欢 图文排版:潘伟涛
责任编辑:潘伟涛

