点击蓝字 关注我们
SUBSCRIBE to US
IEEE x ATEC
IEEE x ATEC科技思享会是由专业技术学会IEEE与前沿科技探索社区ATEC联合主办的技术沙龙。邀请行业专家学者分享前沿探索和技术实践,助力数字化发展。
随AI技术的不断深入发展,医学人工智能应用如雨后春笋般迅速涌现,在医疗领域遍地开花。AI具有智能化、自动化的特点,能够通过强大算力解锁复杂数据、处理海量数据,在医学变革过程中发挥着无与伦比的重要作用。IEEE x ATEC科技思享会第三期会议特邀四位嘉宾围绕“AI驱动下的医学变革—从生命科学到医疗管理”独立TALK。
以下是香港科技大学(广州)教授/博导、ATEC科技精英赛高级咨询委员会专家褚晓文教授的演讲《AutoML 在基于胸部 CT 影像的 Covid-19 辅助诊断中的应用》。
演讲嘉宾 | 褚晓文
香港科技大学(广州)教授/博导
ATEC科技精英赛高级咨询委员会专家
《AutoML 在基于胸部 CT 影像的
Covid-19 辅助诊断中的应用》
大家好,感谢IEEE x ATEC科技思享会邀请我参与本场“AI驱动下的医学变革”的分享。我是来自香港科技大学(广州)数据科学与分析学域的褚晓文教授,在加入港科大(广州)之前,我一直在香港浸会大学计算机科学系工作。
今天我要跟大家分享的内容是《AutoML 在基于胸部 CT 影像的 Covid-19 辅助诊断中的应用》。首先我要感谢本项目的合作者,主要包括我在香港浸会大学的博士生贺鑫等人,杭州电子科技大学张继勇教授团队以及美国南加州大学的Ying Guohao。
今天的报告主要分四个部分:首先是对AutoML的一个简单介绍,其次是可微搜索在CT影像分类中的应用,第三是基于进化算法的神经结构搜索的一点尝试。最后再简单介绍一下我们如何结合自动数据增强和神经结构搜索。
今天的报告内容主要基于以下四篇学术论文:第一篇是我们关于AutoML的一个综述论文,适合对AutoML技术感兴趣的初学者。第二篇是发表在AAAI2021的一篇论文,主要展示了如何用AutoML技术有效针对3D CT影像去寻找一个3D的CNN模型。第三篇是发表在今年MICCAI的论文,主要是介绍了一种基于多目标优化和进化算法的AutoML设计。最后一篇论文是我们近期对自动数据增强和神经结构搜索的一个结合。大家如果对其中的技术细节感兴趣,可以参考一下。
Introduction to AutoML
首先,我们对AutoML做一个简单介绍。
在过去的十几年里,我们见证了基于深度学习,即深度神经网络的蓬勃发展。深度学习在各种AI任务中都取得了令人振奋的成绩,并广泛应用到我们实际生活的方方面面。熟悉神经网络的朋友们可以看出,在上图中我们展示了五种不同的神经网络结构。从单链的线性结构一直发展到今天有诸多分支和跨层结构的复杂网络。这些网络的设计大部分都是基于Trial and Error,是靠成千上万的科研工作人员不断通过人工试错而发现的。
而基于数据驱动,机器学习方法一般都包括数据预处理、特征工程模型评估、模型选择等若干阶段。在传统的机器学习领域,如何自动化的进行数据预处理、超参调优、模型选择,都是非常经典的问题。
随着深度神经网络技术的繁荣和不断突破,如何自动化的进行神经网络结构的设计,也成为自动机器学习中一个非常重要且具有挑战性的课题。这个问题我们通常称之为神经结构搜索,即Neural Architecture Search。神经结构搜索主要有三个构件,分别是搜索空间(Search Space)、搜索策略(Search Strategy)和性能评估策略(Performance Estimation Strategy)。
搜索空间一般是基于一定的先验知识和对具体问题的理解,大概制定一下神经网络的拓扑结构。搜索策略则是要求在给定的搜索空间中如何去探索未知的网络结构,希望能够不断找到一个更好的网络。而性能评估策略就是如何对搜索到的网络结构进行快速打分,即如何从一组结构中判断出来哪一个结构是最好的。
接下来我们逐一对这三个构件做进一步介绍。
搜索空间(Search Space),它定义了NAS算法可以搜索的神经网络的类型和拓扑结构。一般可以把一个网络描述成一个有向无环图DAG,图中的每个节点代表了一个网络层,而图中的边代表网络之间的数据流向。除了输入和输出层,中间层可以有不同的类型,比如全连接层,各种的卷积、池化、激活函数层等等。而每种网络层的类型又有其独特的超参数需要考虑,在此就不一一赘述。
如果我们要对整个网络结构进行端对端的搜索,那这个搜索空间会非常庞大。比如一个简单的链条结构,如果我们要设计一个100层的网络,而每一层有4种不同的算子选择,那么整个搜索空间的大小就是4的100次方。
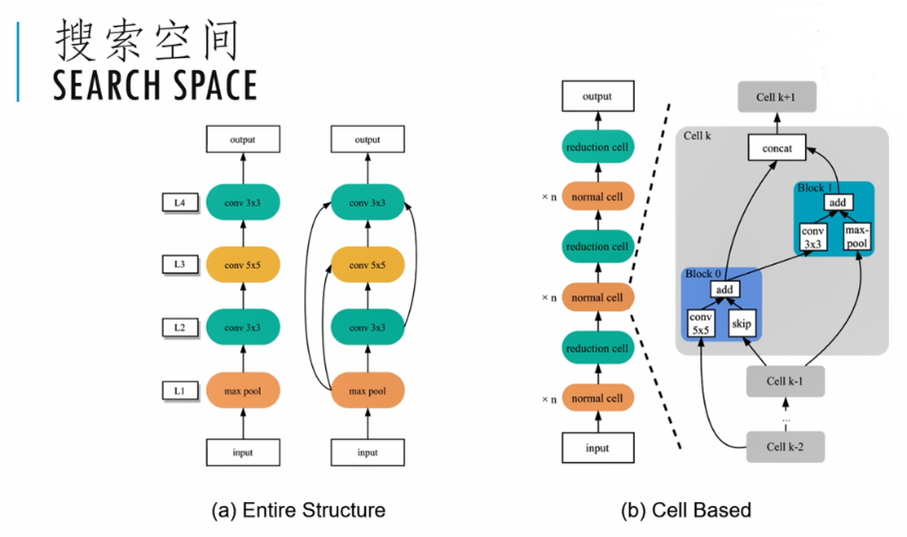
为了提高搜索效率,我们可以基于经验对搜索空间进行一定的限定或者简化。比如最流行的Resnet和Transformer模型等等,都是通过设计一个复杂的子模块,然后将其堆叠而成。因此我们也可以把要搜索的网络切分成基本的单元cell。然后每个单元里面又进一步分成若干个操作块block。通过这些单元的堆叠形成更复杂的网络。这样我们就把搜索一个网络的问题简化为搜索一个单元的问题。在图(b)的示例中,normal cell主要是进行一些常规的卷积操作,而reduction cell主要是用于下采样的操作。
性能评估策略在NAS中有着举足轻重的地位。如果能够提高性能评估的速度,就可以在同样的时间预算里面搜索一个更大的网络空间,有利于我们找到一个更好的网络结构。
然而如何把神经网络的性能评估做到又快又准,是一个非常困难的问题。最早期大家都是基于Brute-Force的方法,把一个搜索到的模型训练到收敛来判断其性能。这个方法虽然比较准确,但是非常消耗资源。比如在cell这种小型的数据集上进行网络搜索,一般都需要几千个GPU hours。为了降低NAS对算力的需求,我们可以通过对数据降维或者对模型进行压缩来大概估算这样一个模型的性能。中国有句俗话叫三岁看老,所以也有学者提出来用Early stopping的策略来预判一个网络模型的性能。
近年来,AutoML领域一个比较大的突破就是采用了这种Weight sharing权重共享的思路来加速性能评估。它的核心思想是训练一个supernet的结构。这个supernet里的任何一个子图都是一个潜在的subnet网络结构。所以在这种方法里面,supernet的权重会被它所有的subnet共享。我们只需要训练一个supernet就可以得到所有subnet的权重,从而对这个subnet做性能的评估。经验表明,通过权重共享,通常可以把搜索的计算消耗从几千个GPU hours降到几十个甚至几个GPU hours。因此这个方法也成为了目前AutoML一个主流的方法。
性能评估的手段。最后一个问题就是如何在庞大的搜索空间中有效的进行搜索。由于描述神经网络的参数含有大量的离散数据,因此网络搜索是一个离散且高维度的优化问题。很难去找最优解。通常我们都是使用一些迭代优化的思路,去尝试提高搜索效果。具体而言,我们可以分为网格和随机搜索、进化算法、贝叶斯优化、强化学习和基于梯度的算法等等。
这里我们大概介绍一下进化算法的思路。首先我们要制定一个把网络结构编码成二进制串的方案,然后我们会随机初始化一组网格作为初始解。经过了一系列的选择、交叉、变异和更新等步骤,进行不断进化迭代,希望最终找到一组更好的网格结构,再从中进行重新训练,得到一个最好的选择。
这里我们再介绍另外一种非常流行的基于梯度优化的思路。它也是一个把离散优化的问题松弛到连续空间,这样就可以利用梯度下降算法进行有效的搜索。我们这里提一下DARTS这个非常有影响力的工作,发表在ICLR2019年。
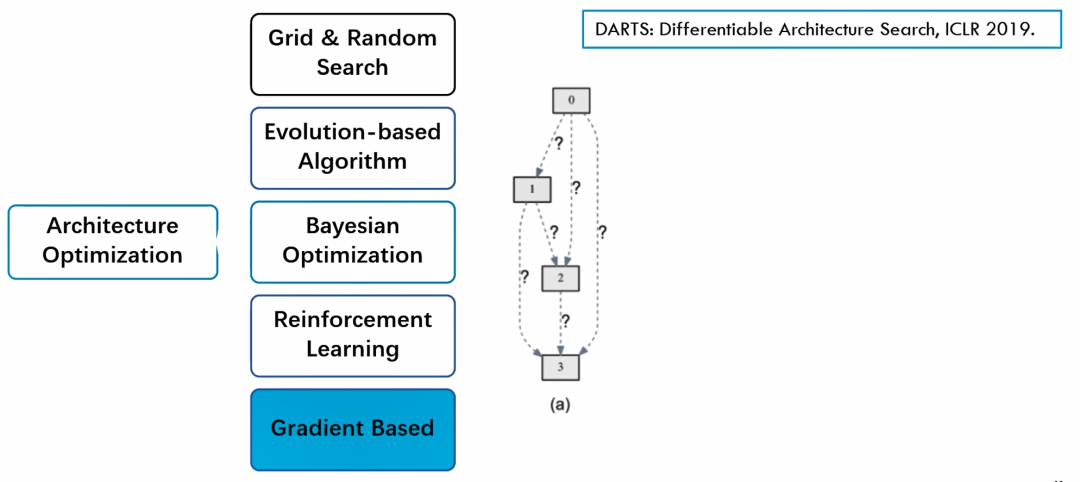
图(a)代表了一个supernet的一个结构,每条边代表着一些潜在的数据运算。这里每个问号代表它可能是五种或者十种不同的运算模式。当我有很多很多问号时,这就是一个非常复杂的组合优化问题。
而DARTS的思路就是同时考虑所有可能的运算。比如说我们每条边有三种可能,分别用三种颜色来代表,我们这个supernet就包含了所有可能的运算,让它们同时进行。但是每一条边或者说每一个运算给它们赋一个概率值。比如说初始化的时候都是三分之一的概率,然后就可以对这个网络进行训练,包括这些权重值也是可以进行训练的。最终可以得到一个不同值的一个权重。最后我们就选择权重值最大的那条边作为最终选择的操作。
以上就是我们对AutoML的一个简要介绍。接下来我们来讨论如何把AutoML用于基于胸部 CT 影像的Covid-19辅助诊断当中。
Differential Neural Architecture Search (AAAI 2021)
在2019到2020年间,快速检测新冠肺炎的手段还不是太成熟,一种是基于RT-PCR的病毒测试,一般需要四个多小时以上的时间才能够得到测试结果。而另一方面,医疗影像学家通过对X光胸片和CT胸部影像的分析,也可以做新冠肺炎的诊断。在2020年的一个跟踪研究中发现,通过对一千多例病人的分析表明,胸部CT影像对新冠肺炎的诊断有非常高的识别率和敏感度,是病毒检测的一个有效补充手段。
因此很多计算机科学家开始研究如何利用深度学习的方法来协助新冠肺炎的智能检测。
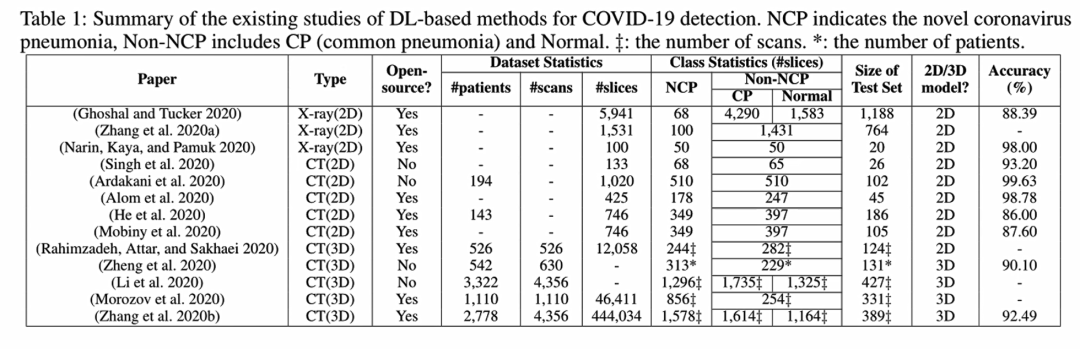
上面这张表总结了2020年的一些相关的工作,主要是一些相关的数据集。从早期2D的X-ray数据集到2D的CT数据集,到最后比较大规模的3D CT数据集。在这些数据集里面,NCP代表新冠肺炎,CP代表普通的肺炎,Normal代表正常的影像。但是由于大家使用的数据集都不太一样,很难去对一个具体的深度学习方法做出一个公平又公正的判断。
因此我们首先选取了三个比较大型的CT数据集作为我们的研究基础,而且我们在这三个公开数据集上做了一些benchmark工作。第一个数据集是来自伊朗的Covid-CTset,这个数据集大概有526个样本。第二个数据集是来自俄罗斯的MosMedData ,有1110个样本。而第三个数据集是来自我们中国的CC-CCII数据,有4300多个CT样本,是目前最大的一个公开数据集。
由于原始的数据集有不同的数据格式,也有不少的噪音和错误的数据。因此我们对数据集做了统一的预处理,并人工对数据做了一些清理工作,提高了数据质量。我们进一步以病人为单位,把数据集分割为训练集和测试集。
我们这项工作的研究动机有三点。首先传统的检测方法比较耗时,因此我们希望利用深度学习技术来实现快速的新冠诊断。第二,已有的深度学习方法大部分都是基于二维的X-ray或者CT影像,无法充分利用3D CT影像信息,所以在性能上还有提升空间。第三,针对新冠检测的3D卷积模型还比较少,因此我们希望利用自动机器学习技术来自动发现一些比较好的3D模型。为了验证自动机器学习的性能,我们需要选取一些传统的方法作为比对基准。
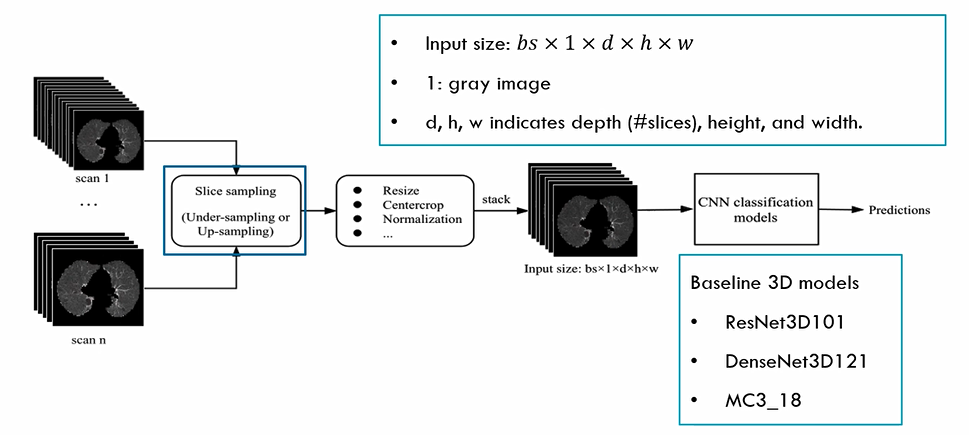
上图是一个3D的深度神经网络的工作流程,输入是一个3D的CT数据集,包括N个CT scan。每一个scan都包含若干张二维CT影像。所以我们要先对每个scan进行采样,保证每个scan的图像数量是一样的,然后进行数据预处理,得到一些批量的3D数据影像。再送到设计好的3D卷积网络里面进行训练。我们选了三个流行的3D卷积网络作为我们的Baseline,包括ResNet3D101,DenseNet3D121以及MC3_18。
要使用AutoML,首先要清楚自己的目标和任务特征。比如我们做CT影像的分类任务,就需要我们的网络具备3D空间数据的特征提取能力。同时考虑到新冠检测对速度的要求,我们希望这个模型不要太庞大,训练和推理的时间都要比较合理。
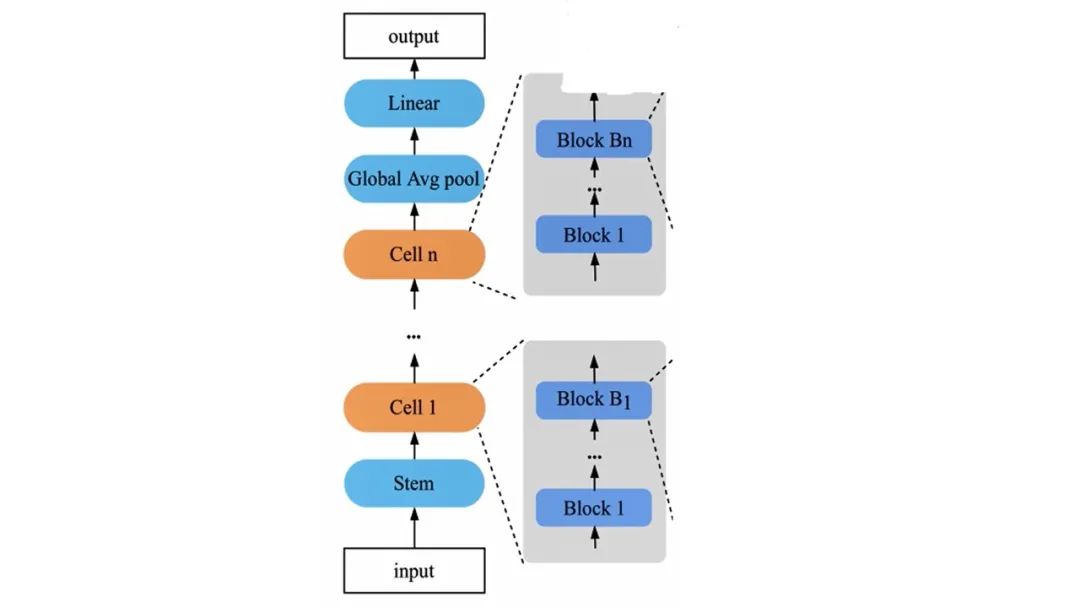
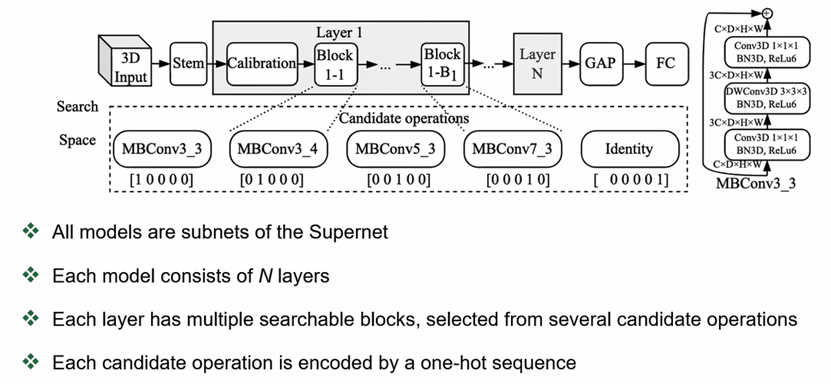
我们使用了supernet的设计来共享权重。我们的模型包括两个部分,上图中蓝色部分是不需要搜索的,包括Stem层、全局平均池化层和最后的全连接层。中间有N个cells,即N个单元,这些是需要进行搜索的。每一个单元又包含若干个块(blocks),每个block是依靠经验设计出来的一组候选操作集,我们需要从中搜索不同的操作组合。
目前我们这个AutoML的方法涉及到一些额外的超参数,包括整个单元的数量N以及每个单元里block的数量Bi。这些参数都是依靠人工经验进行设置的,希望以后有机会也能够把这些参数自动化。通过控制每个block的candidate的数量,我们可以控制整个网络参数的参数集的大小。
supernet设计里最重要的一个环节就是块算子的设计对于网络轻量化的追求。我们参考了2018年CVPR的文章《Mobilenetv2:Inverted residuals and linear bottlenecks》以mobile bottleneck convolution为核心框架,这个卷积MBConv属于一种可分离的卷积设计,其特点就是计算量比较小。它分为三组操作。第一组是一个主点的1*1*1的卷积,外接一个3D BN操作,再加上一个ReLU6。第二组,最重要的就是一个3D的K*K*K的深度卷积。同样后面要跟一个3D的BN操作和一个ReLU6操作。第三组又是一个主点的卷积,再接一个3D BN操作。最后这个模块也包含一个跳连接的操作。
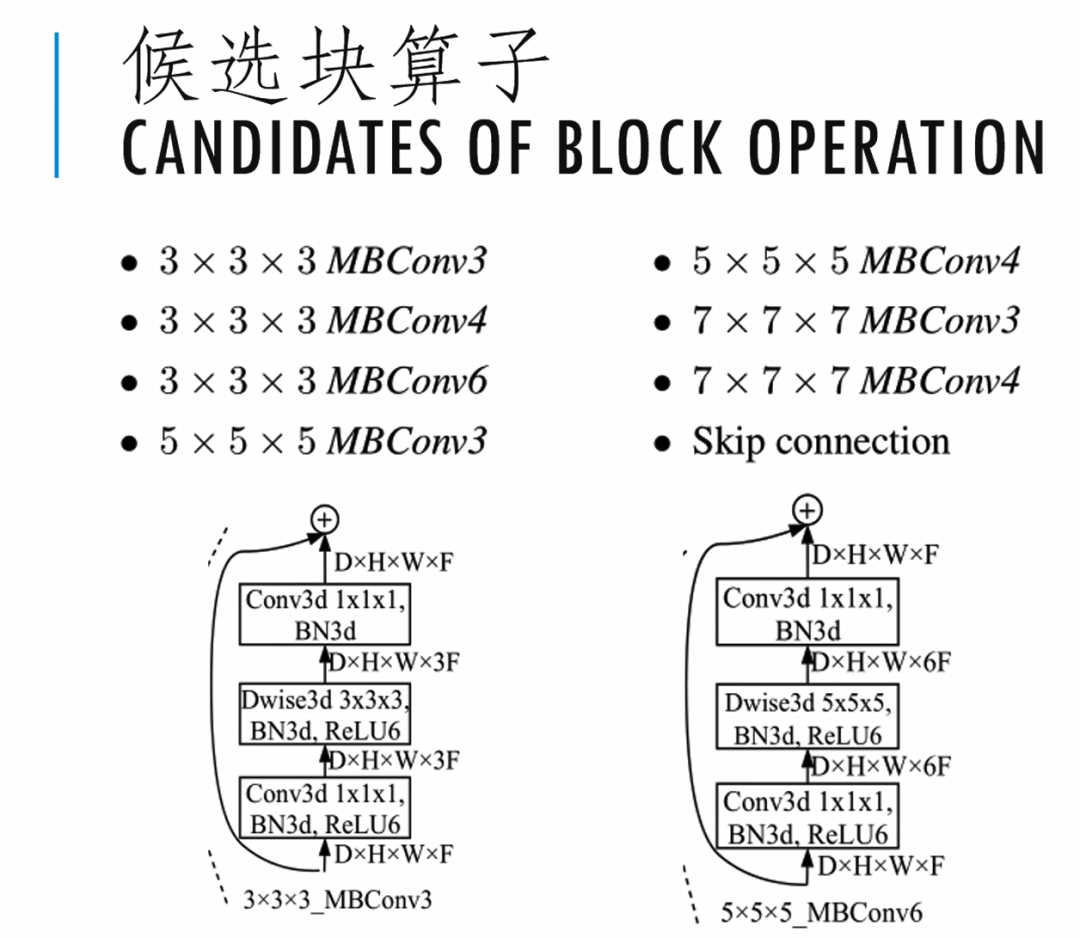
最终我们选取了8种不同的块算子作为候选的运算集。这些candidate的大小从3*3*3到7*7*7,最后的3、4、6代表了从第一个卷积到第二个卷积之间一个扩散因子。整个搜索空间的大小还是非常大的。比如说我们有6个单元,一共有21个blocks,每个block有8个候选设计,那搜索空间的大小就是8的21次方。如果用传统暴力训练的方法是不太可能的。因此我们这个工作就采用了基于梯度的可微分搜索的策略。
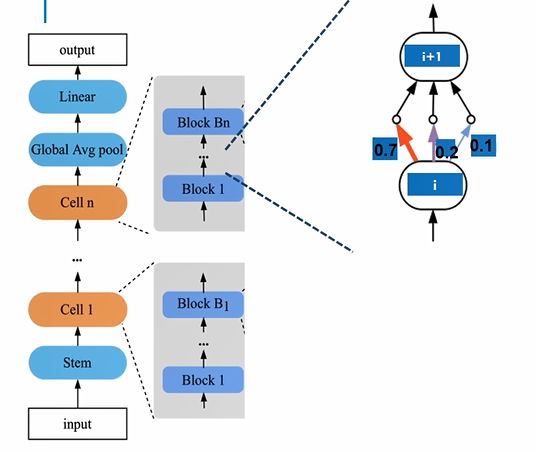
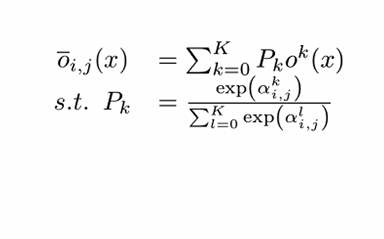
下面简单介绍一下可微分搜索的思路。我们搜索的目标是一个包含若干块的单元,每个块都要从事先制定好的操作里面选择一种操作。这里我们用节点i和节点i+1代表两个特征张量,它们对应着公式里的输入X, i和i+1这两个张量之间有若干条边,每条边对应了一个可能的操作。每条边又有一个权重值Pk,通过SOFTMAX函数计算而来。因此这三个权重的和为一。最后张量i+1的操作,它的值是这三个操作的加权平均。
前面介绍的可微分搜索策略在训练过程中的每次的前向和后向,都需要对所有的算子进行操作。因此它的复杂度随着算子候选集的增大而增加。为了降低计算压力,我们采用了一种采样的思路,每次前向运算并不需要对所有的候选运算进行操作。而是从其中按照概率分布来选取一种算子进行操作。这里就用到了深度学习近年来一个非常流行的重参数的技巧叫做GUMBEL SOFTMAX,它使用了GUMBEL SOFTMAX函数来近似一个离散的GUMBEL MAX函数,使得一个离散的采样技术和梯度下降算法能够得以结合。

介绍完搜索策略,接下来介绍一下整体的训练策略。我们把NAS定义为一个双层优化问题,它有两套未知的参数:第一个是神经网络结构,用α来表示。第二个是一个具体网络α自身的网络参数,用Wα来表示。我们的优化目标就是希望最小化在一个给定的验证集上的损失函数值,而其约束条件是这个参数Wα﹡,它是能够最小化这个网络α在给定的训练集上的一个损失函数。
通常这种双层的优化问题是使用一个交叉迭代的方法去解的。我们先固定一个网络结构α,然后用训练集来求解Wα﹡。我们又固定了这个Wα,通过验证集来对网络结构α进行调优。一直迭代下去,直到收敛。
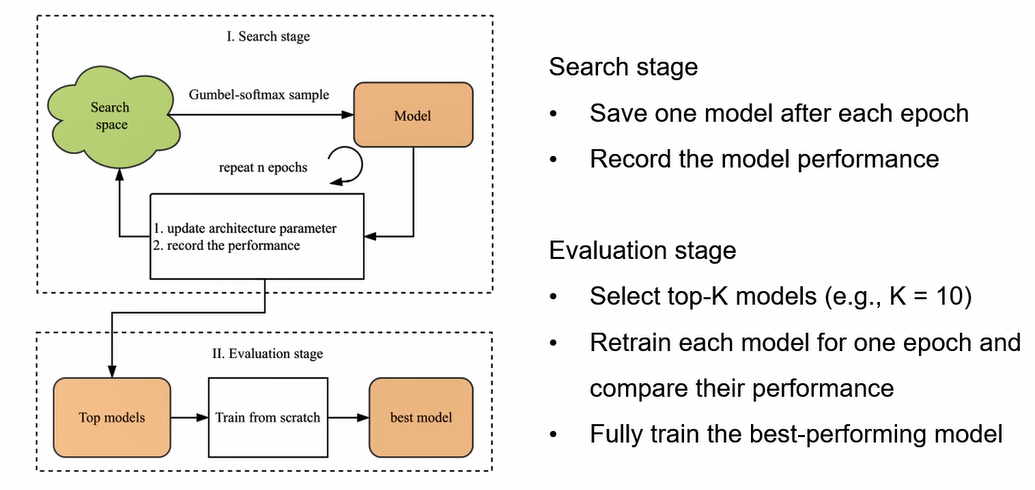
在此,我们对整体的搜索和训练过程再做一个总结。在搜索阶段我们从搜索空间进行采样,得到一个模型,然后训练一个epoch记录该模型以及它的性能。重复N次,最终得到N个不同的模型。进入到评估阶段后,我们从N个模型中选出表现最好的K个模型,对这K个模型重新进行一个比较短期的训练,再从中选取表现最好的一个,最后对我们选出来的模型进行一次完整的训练。
我们在三个数据集上进行了测试。每个数据集我们得到了两种不同大小的3D卷积网络,分别称之为3D-S和3D-L。每一组AutoML的实验,我们大概需要花8个GPU hours,实际上我们是用了四张Nvidia V100的卡进行搜索,两个小时就能完成一个搜索任务。
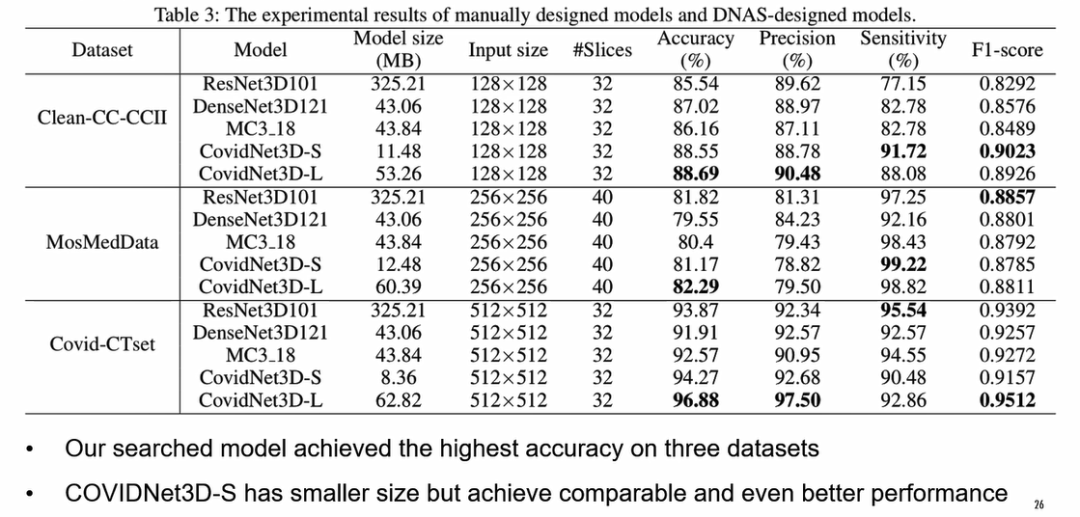
从上图的实验结果看,AutoML搜索到的模型,在Accuracy这个指标上是全面超过了三个手工设计的baseline了。另外我们发现我们轻量化的模型CovidNet3D-S,它的模型大小大概只有10MB左右,性能表现也非常不错。
Evolutionary Multi-objective Architectures Search (MICCAI 2022)
接下来我们再简单介绍另外一种基于进化算法的AutoML技术。这个工作的创新点是结合了多目标优化来缓解在AutoML中的稳定性问题。
近期很多学者发现权重共享虽然能够降低AutoML对计算资源的需求,但是它本身牺牲了模型性能评估的准确度。由于一个supernet的权重被其所覆盖的所有subnets所共享,因此很多subnets之间如果有一些共享的边,这些subnet之间就会互相影响。比如说你想优化这个subnet,那么就调整了它的参数,这样就会对跟它有重叠的subnet带来一些参数的变化。这些对subnets的影响是未知的。因此,我们会观察到同一个subnet在训练过程中的性能是不稳定的。比如它的loss值,有时上升有时下降,这样可能会导致一些比较好的模型在早期就被淘汰掉。为了解决这个问题,我们引入了一个新的优化目标,叫做potential,希望这个优化目标能够帮助去保持一些比较好的模型。
我们在搜索空间上的设计并没有太多变化,主要还是基于MobileNetV2的结构。由于我们这回使用了进化算法,我们需要把网络结构进行编码。这个例子里面每个块有五个不同的候选操作,因此每个块的编码就是一个五维的one-hot编码,而整个网络的二进制编码就由这些五维的向量拼接而成。例如你有N个layer,那每个layer都是一个很短的code,N个layer就是由N个这样的code拼接而成。
基于进化算法的神经结构搜索,主要包含以下几个步骤:
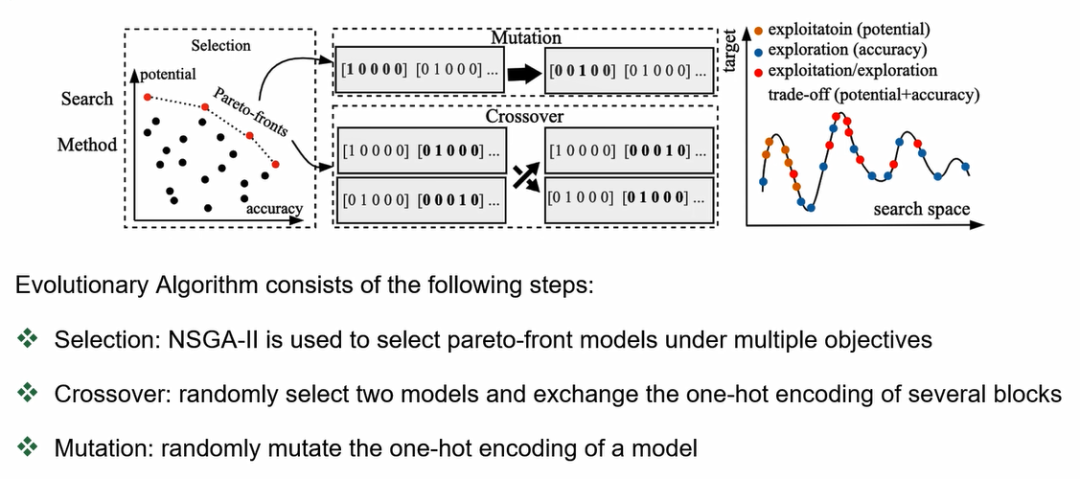
首先我们有一个预热的训练阶段,从中选取一组最好的初始模型来构建一个群体population,然后才可以进入进化的迭代。在每一次的进化周期,我们先从整个群体里面按照帕累托最优来选取一组模型subset,这个是作为我们的种子。然后再从中随机选取一些模型队进行交叉Crossover。希望这样能够引入一些新的进化,同时会对随机选取的一些模型进行变异操作。
整体而言,我们进化算法是要在探索新的模型(exploration)跟充分利用已有模型(exploitation)之间取得一定的平衡。和已有的AutoML算法不同,我们采用了一个多目标的优化设计。已有的AutoML算法一般都是用subnet的性能来作为选择条件。但是由于在漫长的训练过程中,一个subnet的性能时好时坏,因此具有一定的随机性和不稳定性。我们就把训练过程中的每一个子网的性能都做一个记录,记在F 向量里面。而E向量,就是他们对应的训练的索引。
最后我们对收敛的曲线做了一个拟合,把它的线性拟合的斜率定义为它的potential。斜率比较高的时候,就代表它的收敛潜力比较大。所以我们就在我们的多目标设计里面,除了考虑一个模型在某一时刻的accuracy,同时也考虑它的历史发展轨迹。
我们的实验结果表明,经过多目标优化和进化算法结合以后,它能够大幅提升搜索效率,尤其是和我们之前的CovidNet3D比较,在三个数据集上都有了较大的提升。
Joint Search of Data Augmentation Policy and Neural Architecture
最后我们再介绍一下,近期我们如何把自动数据增强Data augmentation和神经结构搜索结合起来。在3D医疗影像的分类问题上有两个常见的挑战,包括模型设计的复杂性以及一般数据集比较小的问题。
我们知道医疗领域如果要对数据做高质量的标注,成本是非常高的。解决小数据集的问题,首选手段就是数据增强Data augmentation。但研究表明最优的数据增强策略往往依赖于数据集本身。所以近年来如何做自动的数据增强,也吸引了很多学者的注意。它的目的主要是对一个给定的数据集和学习任务来自动去寻找一个合适的数据增强策略。
我们提出了一个MEDPIPE(联合流水线)的方案。我们利用自动机器学习的思路,把自动数据增强策略和自动的网络结构搜索统一起来,主要是构建了一个统一的流水线。我们把数据增强策略DAP和NA做一个统一的网络编码,这样就可以在同一个搜索空间下面对DAP和NA同时进行优化。
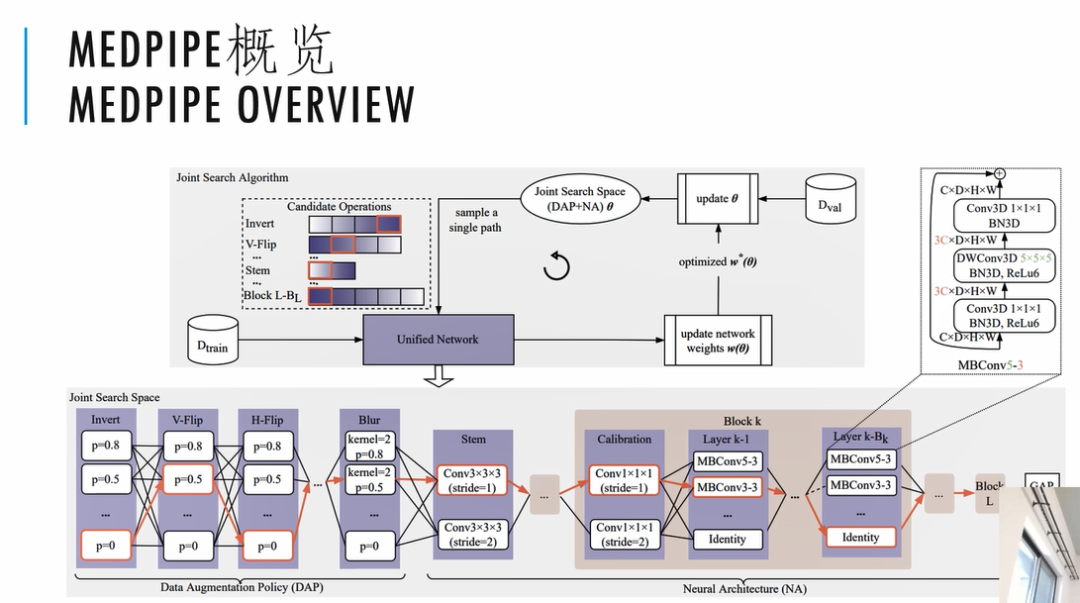
上面是MEDPIPE的一个概览图。
我们把数据增强策略,也用一个DAG图来描述,这样它就成为了整个网络结构的一部分。后面跟前面介绍的一样,后面网络搜索的DAG图是没有变化的。
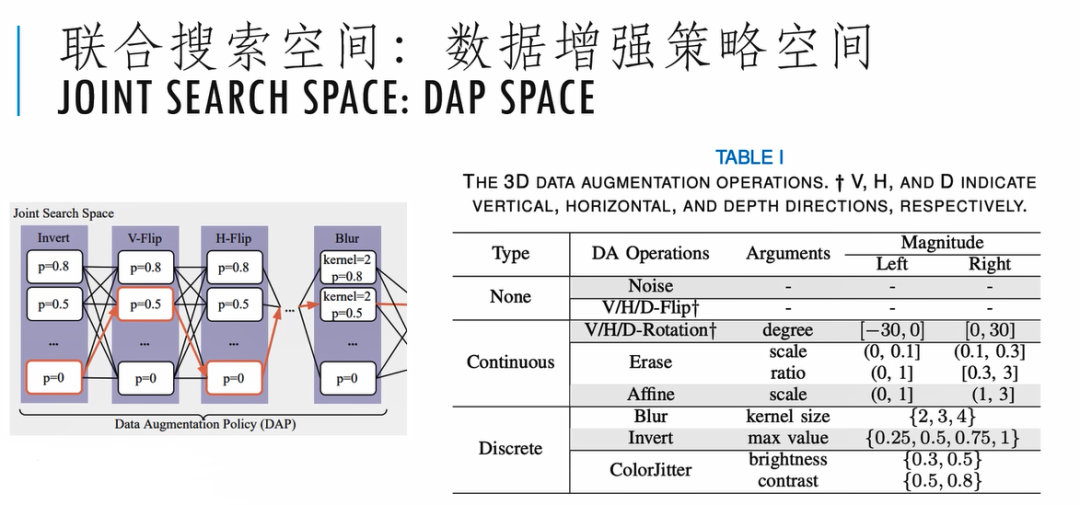
上图是我们具体的一个设计,对数据增强策略,考虑到了不同的操作,包括Invert、V-Flip、H-Flip、Blur,还有Erase、Affine等。
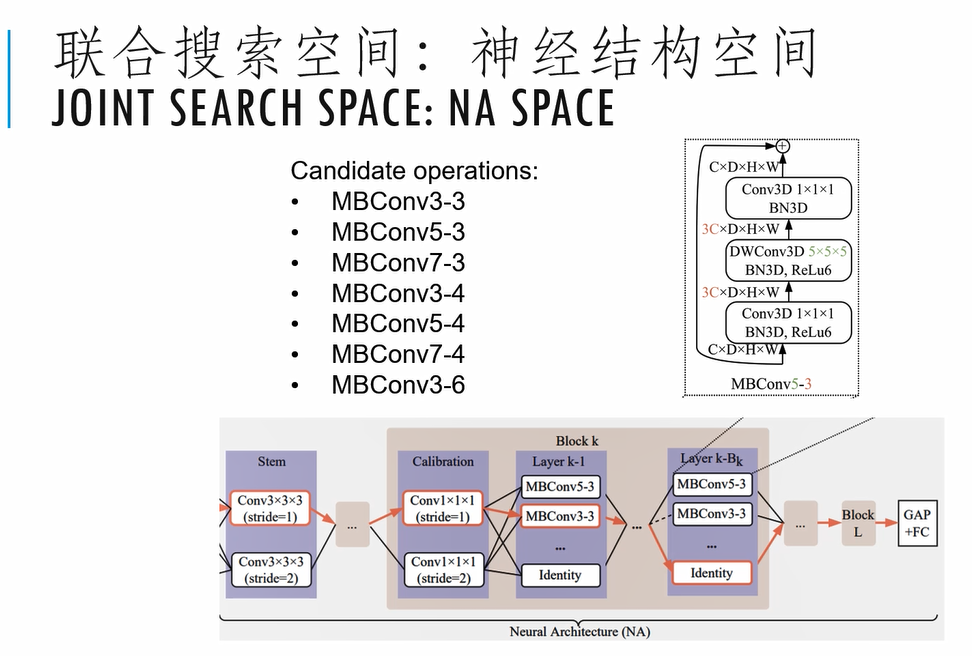
上图是我们对神经结构的一个搜索空间的设计,主要还是沿用了我们之前MBConv的一个设计。
有了搜索空间以后,我们要解决的搜索问题,被定义为一个双层优化问题,在此不再赘述了。但是由于层数比较多,引入了数据增强以后,它的搜索空间大小变得更加复杂。因此我们有必要对这个训练做进一步的优化。
我们采用的还是采样的思路,叫单路径采样。从一个比较大的DAG图里面,在前项和后项运算时,我们并不需要尝试所有的运算。我们通过Gumbel Softmax来进行一个采样的操作,通过Gumbel Softmax来把它的操作变成是可微分的。

上图是我们实验结果。我们看到在三种不同的数据集上,我们搜索到的数据增强的策略是非常不一样的。这说明在不同的数据集上,的确需要设计不同的数据增强的方法。
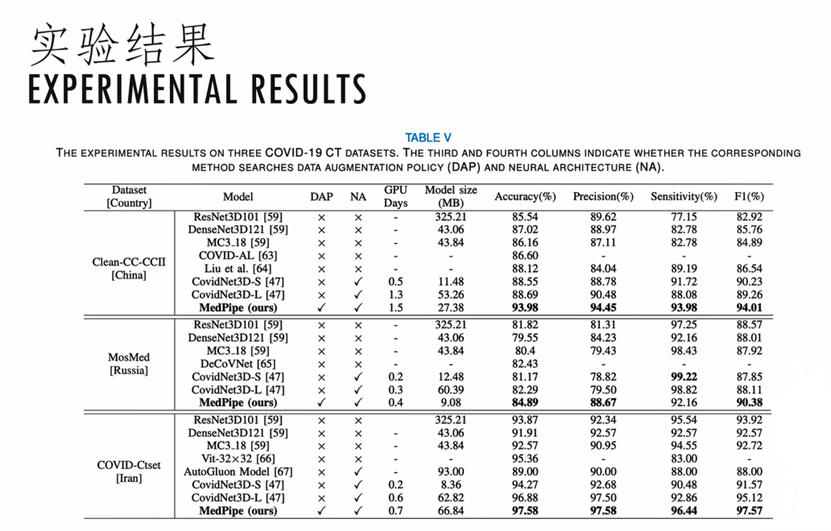
上图是我们结合数据增强和神经结构搜索得到的一些网络模型,我们就称之为MEDPIPE模型。和之前的没有采用自动数据增强的网络搜索方法相比,性能都有一个非常大的提升。
Conclusion
最后,我对今天的报告做一个总结,通过我们近两年的研究表明,AutoML是一种非常有效的手段,可以在任意给定的数据集上搜索出比较高效的神经网络模型。而以可微搜索算法为代表的权重共享等技术可以大幅降低AutoML对算力的需求。基于进化的搜索方法,可以帮我们搜索到一些更好的网络结构。最后数据增强和网络结构搜索相结合,可以进一步提高AutoML的效能。
然而,目前AutoML技术还依赖于一定的人工设计经验,如何突破人工设计的约束来创造出有效的网络结构,将是一个非常重要的发展方向。另外,如何快速而准确的评估一个网络结构的性能,还需要更深入的研究。

今天我的报告就到这里,感谢大家的聆听。如果有任何的问题,欢迎邮件联系我或者我的博士生贺鑫,我们的项目都是开源的,大家可以去上面两个网址下载相关的代码。谢谢。
ABOUT US
IEEE
作为全球最大的专业技术组织,IEEE在全球160多个国家和地区共有超40万名会员,其中学生会员超12万。
在电气及电子工程、计算机等其他技术领域中,IEEE出版了近三分之一的技术文献,其中包括每年出版的200本期刊和杂志,IEEE Xplore数字图书馆文献已超过500万篇。IEEE每年在全球举办超过1900个会议,会议成为了IEEE会员参与活动的重要形式,丰富和满足了会员的生活。IEEE 标准协会是世界领先的标准制定机构,并日益成为新兴技术领域标准的核心来源,其标准制定内容涵盖信息技术、通信、电力和能源等多个领域。如众所周知的IEEE 802有线与无线的网络通信标准和人工智能系统–IEEE 7000 标准解决了人工智能系统中的个人数据保护和安全保证的问题。
IEEE积极搭建开放共享的国际合作舞台,开展学术及科技交流活动,发展不同的科技和学术平台,希望可以充分发挥学会会员的协同效应,建立活跃的学术和技术创新生态,助力下一代专业技术人员的发展与壮大。
ATEC
ATEC (Advanced Technology Exploration Community)前沿科技探索社区是由中关村实验室指导创立的信息领域前沿技术实践发展社区。社区致力于搭建面向新一代互联网相关技术的产学研合作平台,推动创新技术的产业应用研究,支持应用型技术人才培养,传播积极奋进的程序员/工程师文化。社区的发起单位包括清华大学、上海交通大学、浙江大学、西安交通大学和蚂蚁集团等。
借助与多所知名高校专家学者的深度合作,ATEC科技社区创立并持续运营“ATEC科技精英赛”项目。与业内常规的大赛不同,ATEC科技精英赛通过紧扣社会价值的命题设计、贴近真实环境比赛环境搭建,目标考察选手及其团队成员间的综合性命题解决能力。而基于大赛真实过程录制的业内首档代码竞技真人秀《燃烧吧!天才程序员》,则将全景呈现比赛过程中青年科技选手间的竞争与合作、隐忍与反击,真实展现中国年轻一代科技从业者奋发向上的精神和动力。
除ATEC科技精英赛外,ATEC科技社区积极推动着ATEC沙龙、ATEC实训平台等多个产研合作项目,践行“助力数字化发展”、“科技服务社会”的发展理念。

微信号|IEEE电气电子工程师
新浪微博|IEEE中国
· IEEE电气电子工程师学会 ·
往
期
推
荐
合成孔径雷达技术 描绘救灾的未来
自动驾驶checklist:我们现在处于什么阶段呢?
什么是数字孪生?
为什么人工智能需要同理心?

