

第二节介绍了关于多模态对话分析的文献回顾。在第三节中,详细介绍了记录我们自己的数据集及其规格的协议。第四节详细介绍了多模态方法,以进行级别交互分类。
在驾驶舱乘客互动分析的背景下,这种调查是边缘化的,因此,仍然是一个科学挑战。
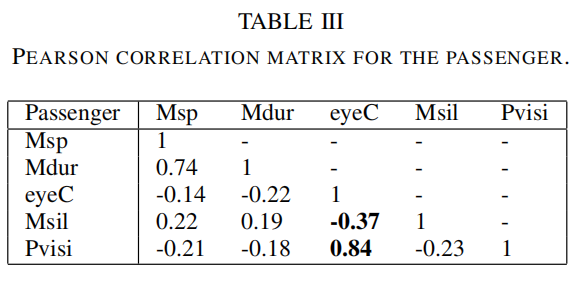
III.车辆中的多模态对话语料库


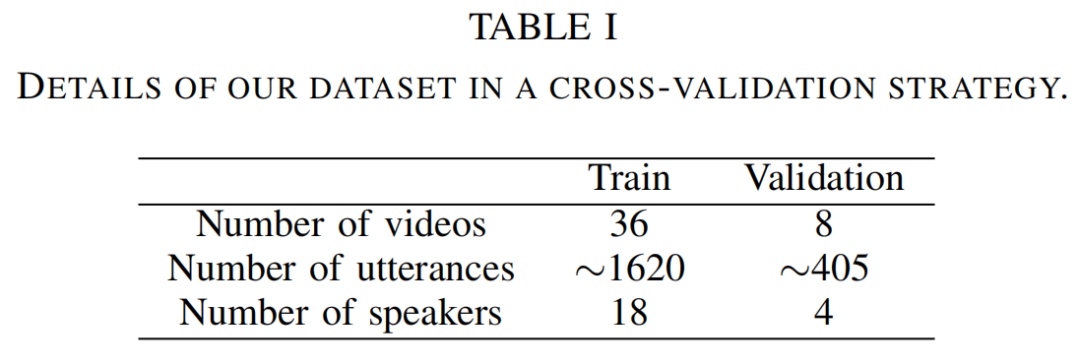
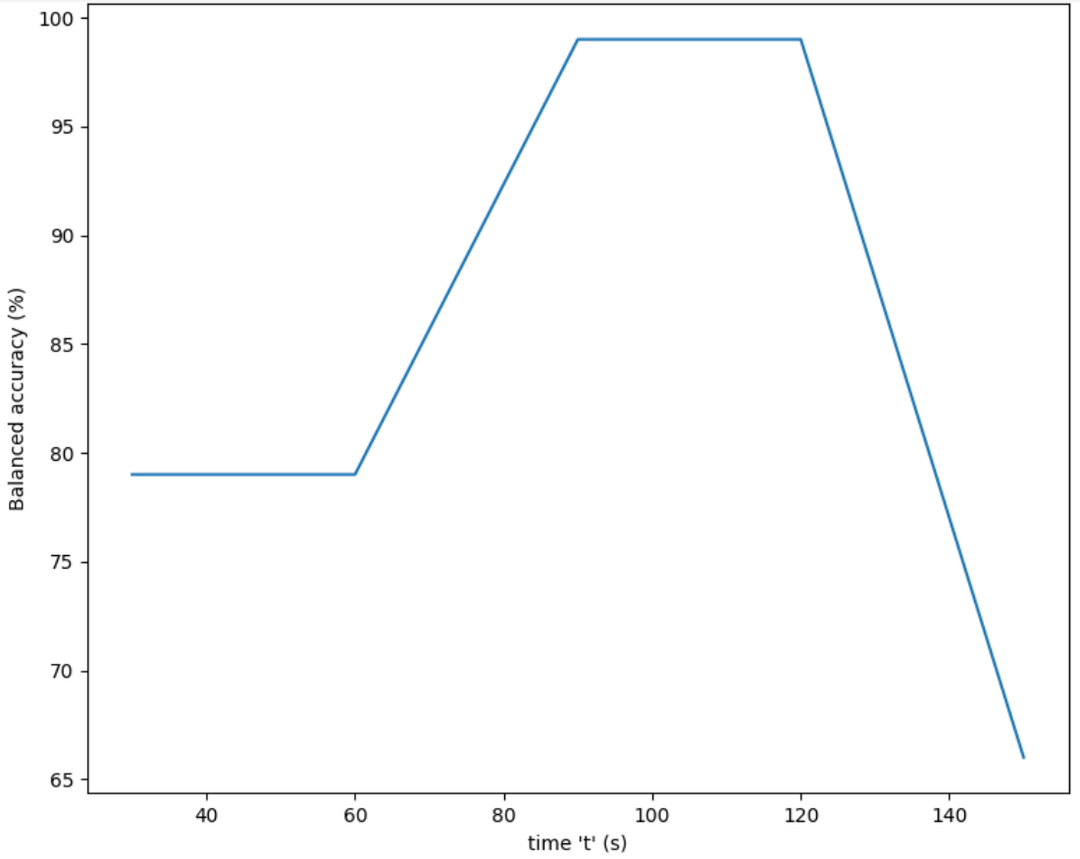
由于受试者不是真正的演员,我们观察到两个阶段的过渡。第一阶段是设置阶段:在每个场景的前30秒,受试者不能坚持或断然拒绝导致 "糟糕的演技"。第二个是在最后:受试者的灵感耗尽,在每个场景的最后20秒内造成呼吸短促。
IV.多模态分析
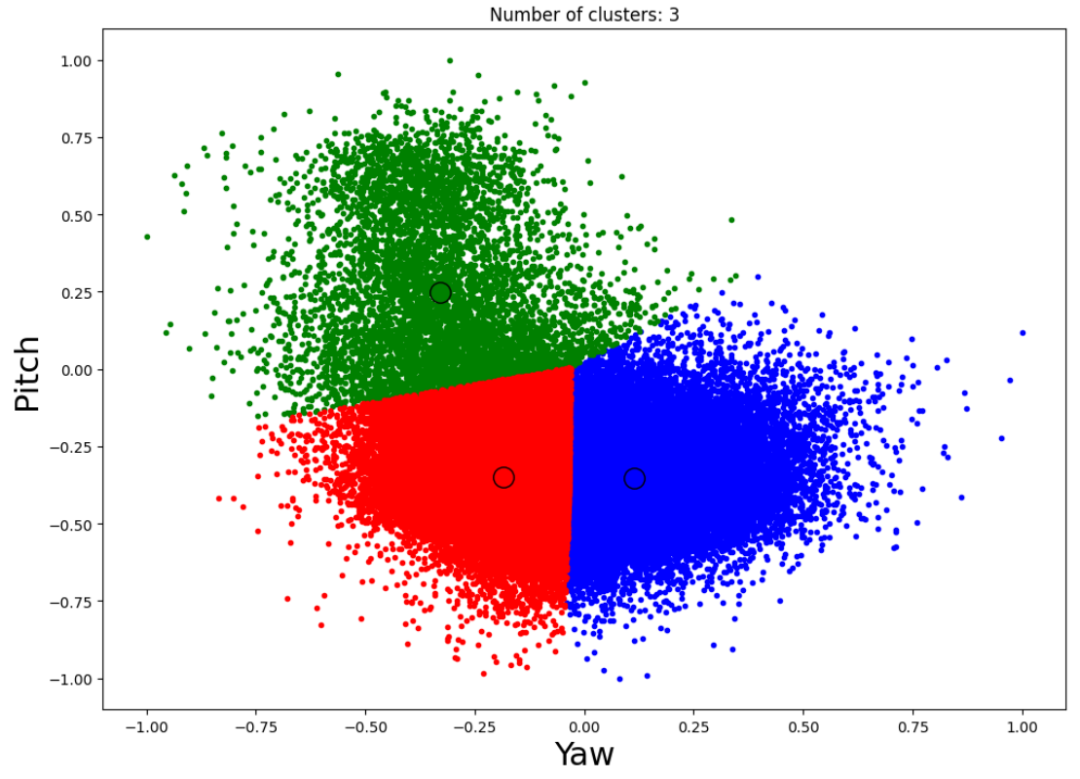
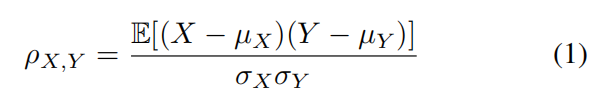
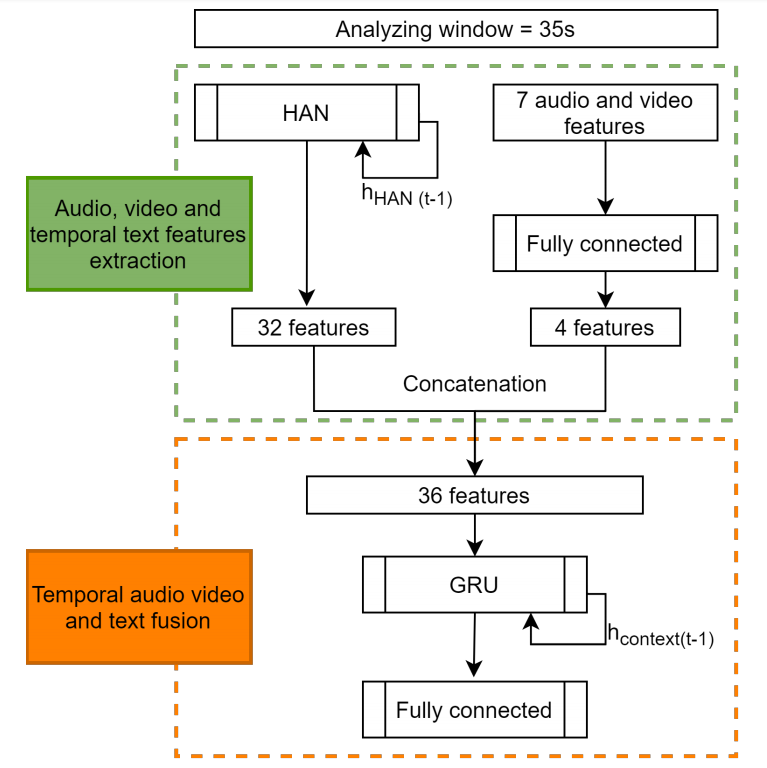
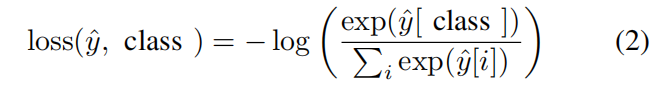
其中yˆ是模型对C类的输出分数。
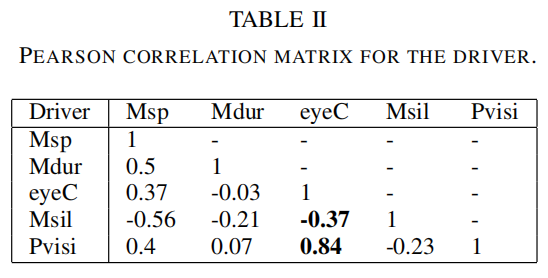
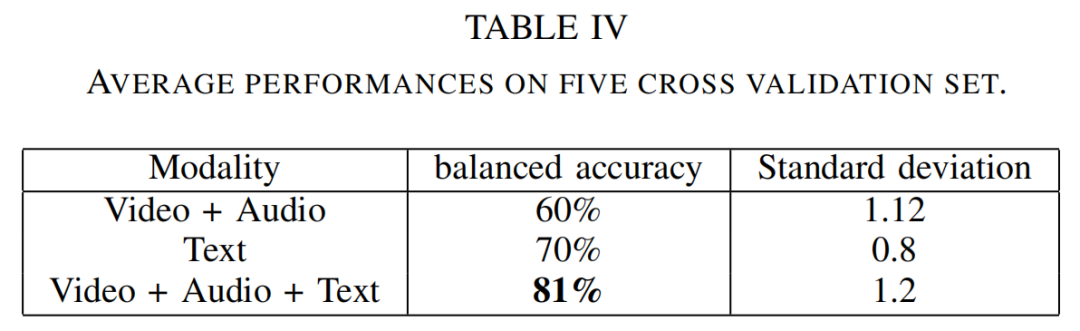
V.评估和相关分析
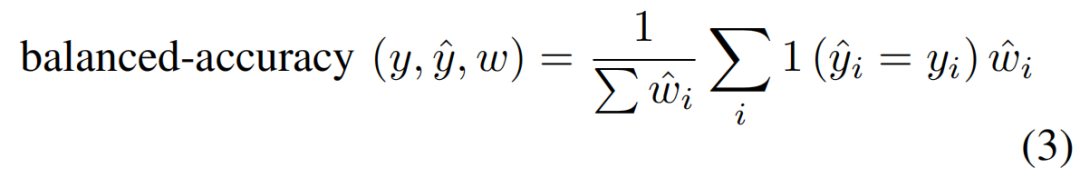
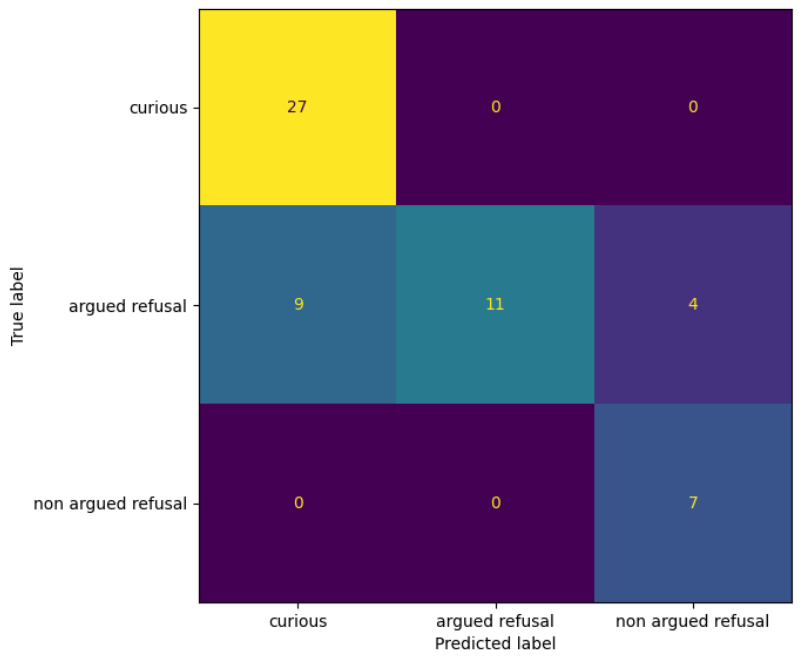
另一个导致错误分类的问题是一些受试者的糟糕演技。例如,一些受试者在拒绝场景中的表演阶段中笑场。或者一个受试者在回头看后排乘客时表现得很反常。
VI.结论和未来工作
参考文献:
[1]J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understand- ing,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Min- neapolis, Minnesota: Association for Computational Linguistics, June 2019, pp. 4171–4186.
[2]L. Martin, B. Muller, P. J. Ortiz Surez, Y. Dupont, L. Romary, E. de la Clergerie, D. Seddah, and B. Sagot, “CamemBERT: a Tasty French Language Model,” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics.Online: Association for Computational Linguistics, July 2020, pp. 7203–7219.
[3] B. Santra, P. Anusha, and P. Goyal, “Hierarchical Transformer for Task Oriented Dialog Systems,” arXiv:2011.08067 [cs], Mar. 2021.
[4] D. Chen, H. Chen, Y. Yang, A. Lin, and Z. Yu, “Action-Based
Conversations Dataset: A Corpus for Building More In-Depth Task- Oriented Dialogue Systems,” arXiv:2104.00783 [cs], Apr. 2021.
[5] D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, “Learning
spatiotemporal features with 3d convolutional networks,” in The IEEE
International Conference on Computer Vision (ICCV), Dec. 2015.
[6] K. Hara, H. Kataoka, and Y. Satoh, “Learning spatio-temporal features
with 3d residual networks for action recognition,” arXiv:1708.07632 [cs], 2017.
[7] F. Eyben, M. Wllmer, and B. Schuller, “opensmile – the munich
versatile and fast open-source audio feature extractor,” in ACM Mul- timedia, 01 2010, pp. 1459– 1462.
[8] Y. Yu, X. Si, C. Hu, and J. Zhang, “A Review of Recurrent Neural
Networks: LSTM Cells and Network Architectures,” Neural Compu- tation, vol. 31, no. 7, pp. 1235– 1270, July 2019.
[9] S. Poria, E. Cambria, D. Hazarika, N. Majumder, A. Zadeh, and L.-P.
Morency, “Context-dependent sentiment analysis in user-generated videos,” in Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2017, pp. 873–883. [Online]. Available: http://aclweb.org/anthology/P17-1081
[10] M. G. Huddar, S. S. Sannakki, and V. S. Rajpurohit, “An ensemble
approach to utterance level multimodal sentiment analysis,” in 2018 International Conference on Computational Techniques, Electronics and Mechanical Systems (CTEMS), 2018, pp. 145– 150.
[11] A. Agarwal, A. Yadav, and D. K. Vishwakarma, “Multimodal senti-
ment analysis via rnn variants,” in 2019 IEEE International Conference on Big Data, Cloud Computing, Data Science Engineering (BCD),
2019, pp. 19–23.
[12] R. Li, C. Lin, M. Collinson, X. Li, and G. Chen, “A dual-attention
hierarchical recurrent neural network for dialogue act classification,” in Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL). Hong Kong, China: Association for Computational Linguistics, Nov. 2019, pp. 383–392.
[13] Y. Luan, Y. Ji, and M. Ostendorf, “Lstm based conversation models,”2016.
[14] E. Cambria, D. Hazarika, S. Poria, A. Hussain, and R. B. V. Subramaanyam, “Benchmarking multimodal sentiment analysis,” arXiv:1707.09538 [cs], 2017.
[15] W. Li, W. Shao, S. Ji, and E. Cambria, “BiERU: Bidirectional Emotional Recurrent Unit for Conversational Sentiment Analysis,” arXiv:2006.00492 [cs], Feb. 2021.
[16] N. Majumder, S. Poria, D. Hazarika, R. Mihalcea, A. Gelbukh, and E. Cambria, “Dialoguernn: An attentive rnn for emotion detection in conversations,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, pp. 6818–6825, July 2019.
[17] A. Zadeh, R. Zellers, E. Pincus, and L.-P. Morency, “Mosi: Multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos,” 2016.
[18] Z. Yang, D. Yang, C. Dyer, X. He, A. Smola, and E. Hovy, “Hierarchi-cal attention networks for document classification,” in Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. San Diego, California: Association for Computational Linguistics, June 2016, pp. 1480– 1489.
[19] Q. Portes., J. Carvalho., J. Pinquier., and F. Lerasle., “Multimodal
neural network for sentiment analysis in embedded systems,” in Proceedings of the 16th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications-Volume 5: VISAPP,, INSTICC. SciTePress, 2021, pp. 387–398.
[20] B. Bigot, J. Pinquier, I. Ferran´e,and R. Andr-Obrecht, “Looking for relevant features for speaker role recognition (regular paper),” in IN- TERSPEECH, Makuhari, Japan, 26/09/10-30/09/10. http://www.isca- speech.org/: International Speech Communication Association (ISCA), 2010, pp. 1057– 1060.
[21] K. S. Jones, “A statistical interpretation of term specificity and its application in retrieval,” Journal of Documentation, vol. 28, pp. 11– 21, 1972.
[22] R. Ranjan, V. M. Patel, and R. Chellappa, “Hyperface: A deep multi-task learning framework for face detection, landmark localization, pose estimation, and gender recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 41, no. 1, pp. 121– 135, 2019.
