(1) - 环境搭建
智能语音交互市场近年来发展迅速,其典型的应用之一智能音箱产品如今已走入千家万户,深受大家喜爱。智能音箱产品的核心就是语音处理,包括音频采集、语音识别(ASR)、自然语言处理(NLP)、文语合成(TTS)、音频播放五大部分。目前除了音频采集和播放必须在嵌入式端实现外,其余三部分一般都在云端处理(嵌入式端通过有线(USB)或无线(Wifi/BLE)将音频数据发送到云端)。痞子衡对语音处理一直比较感兴趣,最近在玩Python也注意到Python里有很多语音处理库,因此打算从零开始写一个基于Python的语音处理工具,这个语音处理工具我们暂且叫她pzh-speech,初步计划为pzh-speech设计4大功能:wav音频录制,语音识别,文语合成,音频播放。
在写pzh-py-speech时需要先搭好开发环境,下表列出了开发过程中会用到的所有软件/工具包:
| 工具 | 功能 | 下载地址 |
|---|---|---|
| Python 2.7.14 | Python官方包(解释器) | https://www.python.org/ |
| PyAudio 0.2.11 | 跨平台开源Audio I/O库 PortAudio 的Python封装 | http://people.csail.mit.edu/hubert/pyaudio/ |
| Matplotlib 2.2.3 | 一款非常强大的Python 2D绘图库 | https://matplotlib.org/ https://github.com/matplotlib/matplotlib |
| NumPy 1.15.0 | 基础Python科学计算包 | http://www.numpy.org/ https://www.scipy.org/ |
| SpeechRecognition 3.8.1 | 一款支持多引擎的Python语音识别(ASR)库 | https://github.com/Uberi/speech_recognition |
| PocketSphinx 0.1.15 | 卡内基-梅隆大学开源语音识别引擎 CMU Sphinx 的Python封装 | https://github.com/bambocher/pocketsphinx-python https://pypi.org/project/pocketsphinx/ |
| pyttsx3 2.7 | pyTTS, pyttsx项目的延续之作,一款轻量级的Python文语合成引擎 | https://github.com/nateshmbhat/pyttsx3 https://pypi.org/project/pyttsx3/ |
| eSpeak 1.48.04 | 一款开源的TTS,可将转换结果保存为wav | http://espeak.sourceforge.net/ |
| wxPython 4.0.3 | 跨平台开源GUI库 wxWidgets 的Python封装库 | https://www.wxpython.org/ https://pypi.org/project/wxPython/ |
| wxFormBuilder 3.8.0 | wxPython GUI界面构建工具 | https://github.com/wxFormBuilder/wxFormBuilder |
| PyCharm Community 2018.02 | 一款流行的Python集成开发环境 | http://www.jetbrains.com/pycharm/ |
pzh-py-speech工具是一个完全基于Python语言开发的应用软件,首先安装好Python 2.7.14,痞子衡的安装目录为C:\tools_mcu\Python27,安装完成后确保系统环境变量里包括该路径(C:\tools_mcu\Python27),因为该路径下包含python.exe,后续python命令需调用这个python.exe完成的。此外pip是Python的包管理工具,我们可以借助pip来安装PyAudio和Matplotlib包(NumPy含在Matplotlib里):
PS C:\tools_mcu\Python27\Scripts> .\pip.exe install pyaudio
Collecting pyaudio
...
Successfully installed pyaudio-0.2.11PS C:\tools_mcu\Python27\Scripts> .\pip.exe install matplotlib
Collecting matplotlib
...
Successfully installed backports.functools-lru-cache-1.5 cycler-0.10.0 kiwisolver-1.0.1 matplotlib-2.2.3 numpy-1.15.0 pyparsing-2.2.0 python-dateutil-2.7.3 pytz-2018.5
有了PyAudio便可以读写Audio,有了Matplotlib便可以将Audio以波形方式图形化显示出来。这两个工具安装完成,JaysPySPEECH工具开发的Python基础环境便搭好了。
Note: 关于GUI及调试等相关工具(wxPython、wxFormBuilder、PyCharm)的安装详见痞子衡另一个作品 pzh-py-com的环境搭建。
上一步主要安装了pzh-py-speech的基础开发环境,用于Audio的录播与显示,但是pzh-py-speech设计之初便考虑支持语音识别、文语转换功能,因为我们还需要进一步安装相关Python库。
首先安装语音识别库,SpeechRecognition是一款非常流行的支持多引擎的语音识别Python库,痞子衡为pzh-py-speech选用的就是SpeechRecognition,其中语音识别引擎选用的是可以离线工作的PocketSphinx,具体安装如下:
PS C:\tools_mcu\Python27\Scripts> .\pip.exe install SpeechRecognition
Collecting SpeechRecognition
...
Successfully installed SpeechRecognition-3.8.1PS C:\tools_mcu\Python27\Scripts> python -m pip install --upgrade pip setuptools wheel
Requirement already up-to-date: pip in c:\tools_mcu\python27\lib\site-packages (18.0)
Collecting setuptools
...
Successfully installed setuptools-40.2.0 wheel-0.31.1PS C:\tools_mcu\Python27\Scripts> .\pip.exe install --upgrade pocketsphinx
Collecting pocketsphinx
...
Successfully installed pocketsphinx-0.1.15
最后安装文语合成库,pyttsx3是一款超轻量级的文语合成Python库,其是经典的pyTTS、pyttsx项目的延续,其内核为Microsoft Speech API (SAPI5),可离线工作,具体安装如下:
PS C:\tools_mcu\Python27\Scripts> .\pip.exe install pyttsx3
Collecting pyttsx3
...
Successfully installed pyttsx3-2.7
pyttsx3仅能在线发声,无法保存到wav文件,因此我们还需要一个可以保存wav文件的TTS,痞子衡选择了eSpeak,其具体安装详见系列第六篇。到了这里,pzh-py-speech工具开发的Python环境便全部搭好了。
构建pzh-py-speech的界面过程与pzh-py-com构建步骤类似,也是分四步:界面设计简图、界面设计wxPython组件图、在wxFormBuilder里创作、使用生成的Python代码。为了突出重点,痞子衡只讲前两步,后面的过程不再赘述。
在真正进入代码设计pzh-py-speech界面前,首先应该在纸上画一个界面草图,确定pzh-py-speech界面应该有哪些元素构成,这些元素分别位于界面上什么位置。下面是痞子衡画的pzh-py-speech的界面简图,界面主要包括三大部分:接收区、配置区、发送区,接收区用于显示从串口接收到的数据;配置区用于配置串口参数;发送区用于编辑要从串口发送出去的数据。
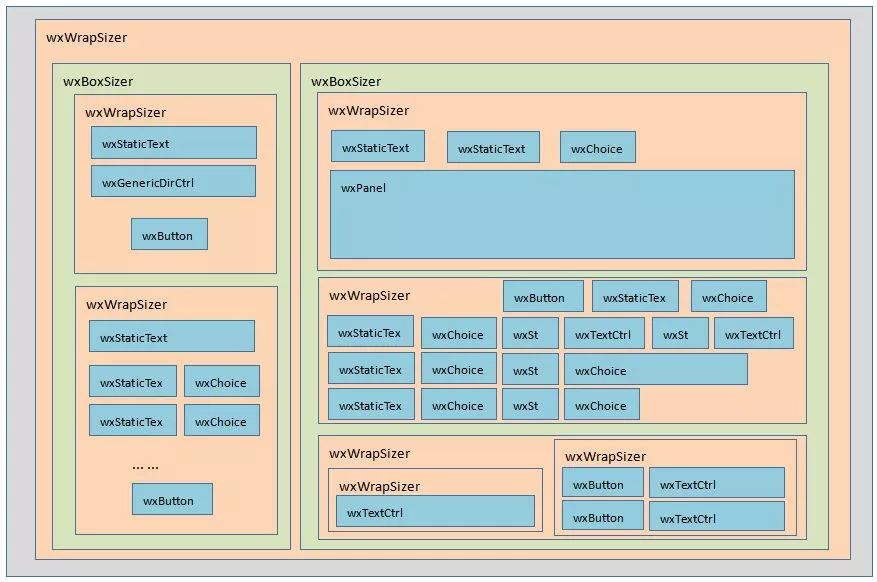
有了pzh-py-speech的界面设计简图指导,下一步需要将设计简图解析成如下的wxPython组件图,将简图里的元素转换成wxPython里的真实组件。这一步需要配合查阅wxPython相关手册,了解wxPython有哪些组件。
音频显示是pzh-py-speech的主要功能,pzh-py-speech借助的是Matplotlib以及NumPy来实现的音频显示功能,今天痞子衡为大家介绍音频显示在pzh-py-speech中是如何实现的。
SciPy是一套Python科学计算相关的工具集,其本身也是一个Python库,这个工具集主要包含以下6大Python库,pzh-py-speech所用到的Matplotlib以及NumPy均属于SciPy工具集。

NumPy是一套最基础的Python科学计算包,它主要用于数组与矩阵运算,它是一个开源项目,被收录进 NumFOCUS 组织维护的 Sponsored Project 里。pzh-py-speech使用的是NumPy 1.15.0。
NumPy库的官方主页如下:
NumPy官方主页: http://www.numpy.org/
NumPy安装方法: https://pypi.org/project/numpy/
NumPy的快速上手可参考这个网页 https://docs.scipy.org/doc/numpy/user/quickstart.html
Matplotlib是一套Python高质量2D绘图库,它的初始设计者为John Hunter,它也是一个开源项目,被同样收录进 NumFOCUS 组织维护的 Sponsored Project 里。pzh-py-speech使用的是Matplotlib 2.2.3。
Matplotlib库的官方主页如下:
Matplotlib官方主页: https://matplotlib.org/
Matplotlib安装方法: https://pypi.org/project/matplotlib/
Matplotlib绘图功能非常强大,但是作为一般使用,我们没有必要去通读其官方文档,其提供了非常多的example代码,这些example都在 https://matplotlib.org/gallery/index.html, 我们只要找到能满足我们需求的example,在其基础上简单修改即可。下面就是一个最简单的正弦波示例:

import matplotlib
import matplotlib.pyplot as plt
import numpy as np
# Data for plotting
t = np.arange(0.0, 2.0, 0.01)
s = 1 + np.sin(2 * np.pi * t)
fig, ax = plt.subplots()
ax.plot(t, s)
ax.set(xlabel='time (s)', ylabel='voltage (mV)',
title='About as simple as it gets, folks')
ax.grid()
fig.savefig("test.png")
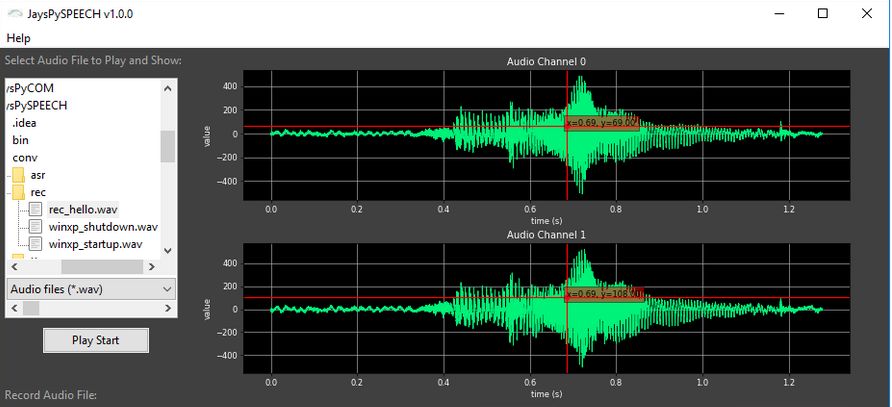
plt.show()pzh-py-speech关于音频显示功能实现主要有四点:选择.wav文件、读取.wav文件、绘制.wav波形、添加光标功能,最终pzh-py-speech效果如下图所示,痞子衡为逐一为大家介绍实现细节。
选择wav文件主要借助的是wxPython里的genericDirCtrl控件提供的功能实现的,我们使用genericDirCtrl控件创建了一个名为m_genericDirCtrl_audioDir的对象,借助其SetFilter()方法实现了仅显示.wav文件格式的过滤,并且我们为m_genericDirCtrl_audioDir还创建了一个event,即viewAudio(),这个event的触发条件是选中m_genericDirCtrl_audioDir里列出的.wav文件,当viewAudio()被触发时,我们通过GetFilePath()方法即可获得选中的.wav文件路径。
class mainWin(win.speech_win):
def __init__(self, parent):
win.speech_win.__init__(self, parent)
# ...
self.m_genericDirCtrl_audioDir.SetFilter("Audio files (*.wav)|*.wav")
def viewAudio( self, event ):
self.wavPath = self.m_genericDirCtrl_audioDir.GetFilePath() 读取.wav文件主要借助的是python自带的标准库wave,以及第三方的NumPy库。痞子衡创建了一个名为wavCanvasPanel的类,在这个类中定义了readWave(self, wavPath, wavInfo)方法,其中参数wavPath即是要读取的.wav文件路径,参数wavInfo是GUI状态栏对象,用于直观显示读取到的.wav文件信息。
在wavCanvasPanel.readWave()方法中,痞子衡首先使用了wave库里的功能获取到.wav文件的所有信息以及所有PCM数据,然后借助NumPy库将PCM数据按channel重新组织,便于后续图形显示。关于数据重新组织,有一个地方需要特别说明,即int24类型(3-byte)是不被NumPy中的fromstring()原生支持,因此痞子衡自己实现了一个非标准类型数据的fromstring()。
import numpy
import wave
class wavCanvasPanel(wx.Panel):
def fromstring(self, wavData, alignedByte):
if alignedByte <= 8:
src = numpy.ndarray(len(wavData), numpy.dtype('>i1'), wavData)
dest = numpy.zeros(len(wavData) / alignedByte, numpy.dtype('>i8'))
for i in range(alignedByte):
dest.view(dtype='>i1')[alignedByte-1-i::8] = src.view(dtype='>i1')[i::alignedByte]
[hex(x) for x in dest]
return True, dest
else:
return False, wavData
def readWave(self, wavPath, wavInfo):
if os.path.isfile(wavPath):
# Open the wav file to get wave data and parameters
wavFile = wave.open(wavPath, "rb")
wavParams = wavFile.getparams()
wavChannels = wavParams[0]
wavSampwidth = wavParams[1]
wavFramerate = wavParams[2]
wavFrames = wavParams[3]
wavInfo.SetStatusText('Opened Audio Info = ' +
'Channels:' + str(wavChannels) +
', SampWidth:' + str(wavSampwidth) + 'Byte' +
', SampRate:' + str(wavFramerate) + 'kHz' +
', FormatTag:' + wavParams[4])
wavData = wavFile.readframes(wavFrames)
wavFile.close()
# Transpose the wav data if wave has multiple channels
if wavSampwidth == 1:
dtype = numpy.int8
elif wavSampwidth == 2:
dtype = numpy.int16
elif wavSampwidth == 3:
dtype = None
elif wavSampwidth == 4:
dtype = numpy.float32
else:
return 0, 0, 0
if dtype != None:
retData = numpy.fromstring(wavData, dtype = dtype)
else:
# Implement int24 manually
status, retData = self.fromstring(wavData, 3)
if not status:
return 0, 0, 0
if wavChannels != 1:
retData.shape = -1, wavChannels
retData = retData.T
# Calculate and arange wave time
retTime = numpy.arange(0, wavFrames) * (1.0 / wavFramerate)
retChannels = wavChannels
return retChannels, retData, retTime
else:
return 0, 0, 0 绘制.wav波形是最主要的功能。痞子衡在wavCanvasPanel类中实现了showWave(self, wavPath, wavInfo)方法,这个方法会在GUI控件m_genericDirCtrl_audioDir的事件函数viewAudio()中被调用。
在wavCanvasPanel.showWave()方法中,痞子衡首先使用了readWave()获取.wav文件中经过重新组织的PCM数据,然后借助Matplotlib中的figure类中的add_axes()方法逐一将各channel的PCM数据绘制出来,并辅以各种信息(x、y轴精度、标签等)一同显示出来。由于GUI控件里专门用于显示波形的Panel对象尺寸为720*360 inch,痞子衡限制了最多显示.wav的前8通道。
import matplotlib
from matplotlib.backends.backend_wxagg import FigureCanvasWxAgg as FigureCanvas
from matplotlib.figure import Figure
MAX_AUDIO_CHANNEL = 8
#unit: inch
PLOT_PANEL_WIDTH = 720
PLOT_PANEL_HEIGHT = 360
#unit: percent
PLOT_AXES_WIDTH_TITLE = 0.05
PLOT_AXES_HEIGHT_LABEL = 0.075
class wavCanvasPanel(wx.Panel):
def __init__(self, parent):
wx.Panel.__init__(self, parent)
dpi = 60
width = PLOT_PANEL_WIDTH / dpi
height = PLOT_PANEL_HEIGHT / dpi
self.wavFigure = Figure(figsize=[width,height], dpi=dpi, facecolor='#404040')
self.wavCanvas = FigureCanvas(self, -1, self.wavFigure)
self.wavSizer = wx.BoxSizer(wx.VERTICAL)
self.wavSizer.Add(self.wavCanvas, 1, wx.EXPAND|wx.ALL)
self.SetSizerAndFit(self.wavSizer)
self.wavAxes = [None] * MAX_AUDIO_CHANNEL
def readWave(self, wavPath, wavInfo):
# ...
def showWave(self, wavPath, wavInfo):
self.wavFigure.clear()
waveChannels, waveData, waveTime = self.readWave(wavPath, wavInfo)
if waveChannels != 0:
# Note: only show max supported channel if actual channel > max supported channel
if waveChannels > MAX_AUDIO_CHANNEL:
waveChannels = MAX_AUDIO_CHANNEL
# Polt the waveform of each channel in sequence
for i in range(waveChannels):
left = PLOT_AXES_HEIGHT_LABEL
bottom = (1.0 / waveChannels) * (waveChannels - 1 - i) + PLOT_AXES_HEIGHT_LABEL
height = 1.0 / waveChannels - (PLOT_AXES_WIDTH_TITLE + PLOT_AXES_HEIGHT_LABEL)
width = 1 - left - 0.05
self.wavAxes[i] = self.wavFigure.add_axes([left, bottom, width, height], facecolor='k')
self.wavAxes[i].set_prop_cycle(color='#00F279', lw=[1])
self.wavAxes[i].set_xlabel('time (s)', color='w')
self.wavAxes[i].set_ylabel('value', color='w')
if waveChannels == 1:
data = waveData
else:
data = waveData[i]
self.wavAxes[i].plot(waveTime, data)
self.wavAxes[i].grid()
self.wavAxes[i].tick_params(labelcolor='w')
self.wavAxes[i].set_title('Audio Channel ' + str(i), color='w')
# Note!!!: draw() must be called if figure has been cleared once
self.wavCanvas.draw()
class mainWin(win.speech_win):
def __init__(self, parent):
win.speech_win.__init__(self, parent)
self.wavPanel = wavCanvasPanel(self.m_panel_plot)
# ...
def viewAudio( self, event ):
self.wavPath = self.m_genericDirCtrl_audioDir.GetFilePath()
self.wavPanel.showWave(self.wavPath, self.statusBar)光标定位功能不是必要功能,但其可以让软件看起来高大上,痞子衡创建了一个名为wavCursor类来实现它,主要在这个类中实现了moveMouse方法,这个方法将会被FigureCanvasWxAgg类中的mpl_connect()方法添加到各通道axes中。
MAX_AUDIO_CHANNEL = 8
class wavCursor(object):
def __init__(self, ax, x, y):
self.ax = ax
self.vline = ax.axvline(color='r', alpha=1)
self.hline = ax.axhline(color='r', alpha=1)
self.marker, = ax.plot([0],[0], marker="o", color="crimson", zorder=3)
self.x = x
self.y = y
self.xlim = self.x[len(self.x)-1]
self.text = ax.text(0.7, 0.9, '', bbox=dict(facecolor='red', alpha=0.5))
def moveMouse(self, event):
if not event.inaxes:
return
x, y = event.xdata, event.ydata
if x > self.xlim:
x = self.xlim
index = numpy.searchsorted(self.x, [x])[0]
x = self.x[index]
y = self.y[index]
self.vline.set_xdata(x)
self.hline.set_ydata(y)
self.marker.set_data([x],[y])
self.text.set_text('x=%1.2f, y=%1.2f' % (x, y))
self.text.set_position((x,y))
self.ax.figure.canvas.draw_idle()
class wavCanvasPanel(wx.Panel):
def __init__(self, parent):
# ...
self.wavAxes = [None] * MAX_AUDIO_CHANNEL
# 定义光标对象
self.wavCursor = [None] * MAX_AUDIO_CHANNEL
def showWave(self, wavPath, wavInfo):
# ...
if waveChannels != 0:
# ...
for i in range(waveChannels):
# ...
self.wavAxes[i].set_title('Audio Channel ' + str(i), color='w')
# 实例化光标对象,并使用mpl_connect()将moveMouse()动作加入光标对象
self.wavCursor[i] = wavCursor(self.wavAxes[i], waveTime, data)
self.wavCanvas.mpl_connect('motion_notify_event', self.wavCursor[i].moveMouse)
# ...音频录播是pzh-py-speech的主要功能,pzh-py-speech借助的是Python自带wave库以及第三方PyAudio库来实现的音频播放和录制功能,今天痞子衡为大家介绍音频录播在pzh-py-speech中是如何实现的。
wave是python标准库,其可以实现wav音频文件的读写,并且能解析wav音频的参数。pzh-py-speech借助wave库来读写wav文件,播放音频时借助wave库来读取wav文件并获取音频参数(通道,采样宽度,采样率),录制音频时借助wave库来设置音频参数并保存成wav文件。下面列举了pzh-py-speech所用到的全部API:
wave用法: https://docs.python.org/2/library/wave.html
wave.open()
# wav音频读API
Wave_read.getnchannels() # 获取音频通道数
Wave_read.getsampwidth() # 获取音频采样宽度
Wave_read.getframerate() # 获取音频采样率
Wave_read.getnframes() # 获取音频总帧数
Wave_read.readframes(n) # 读取音频帧数据
Wave_read.tell() # 获取已读取的音频帧数
Wave_read.close()
# wav音频写API
Wave_write.setnchannels(n) # 设置音频通道数
Wave_write.setsampwidth(n) # 设置音频采样宽度
Wave_write.setframerate(n) # 设置音频采样率
Wave_write.writeframes(data) # 写入音频帧数据
Wave_write.close() PyAudio是开源跨平台音频库PortAudio的python封装,PyAudio库的维护者是Hubert Pham,该库从2006年开始推出,一直持续更新至今,pzh-py-speech使用的是PyAudio 0.2.11。
pzh-py-speech借助PyAudio库来实现音频数据流控制(包括从PC麦克风获取音频流,将音频流输出给PC扬声器),如果说wave库实现的是对wav文件的单纯操作,那么PyAudio库则实现的是音频相关硬件设备的交互。
PyAudio项目的官方主页如下:
PortAudio官方主页: http://www.portaudio.com/
PyAudio官方主页: http://people.csail.mit.edu/hubert/pyaudio/
PyAudio安装方法: https://pypi.org/project/PyAudio/
PyAudio对音频流的控制有两种,一种是阻塞式的,另一种是非阻塞式的(callback),前者一般用于确定的音频控制(比如单纯播放一个本地音频文件,并且中途不会有暂停/继续等操作),后者一般用于灵活的音频控制(比如录制一段音频,但是要等待一个事件响应才会结束)。pzh-py-speech用的是后者。下面是两种方式的音频播放使用示例:
import pyaudio
import wave
CHUNK = 1024
wf = wave.open(“test.wav”, 'rb')
p = pyaudio.PyAudio()
##########################################################
# 此为阻塞式,循环读取1024个byte音频数据去播放,直到test.wav文件数据被全部读出
stream = p.open(format=p.get_format_from_width(wf.getsampwidth()),
channels=wf.getnchannels(),
rate=wf.getframerate(),
output=True)
data = wf.readframes(CHUNK)
while data != '':
stream.write(data)
data = wf.readframes(CHUNK)
##########################################################
# 此为非阻塞式的(callback),系统会自动读取test.wav文件里的音频帧,直到播放完毕
def callback(in_data, frame_count, time_info, status):
data = wf.readframes(frame_count)
return (data, pyaudio.paContinue)
stream = p.open(format=p.get_format_from_width(wf.getsampwidth()),
channels=wf.getnchannels(),
rate=wf.getframerate(),
output=True,
stream_callback=callback)
stream.start_stream()
while stream.is_active():
time.sleep(0.1)
##########################################################
stream.stop_stream()
stream.close()
p.terminate()播放功能本身实现不算复杂,但pzh-py-speech里实现的是播放按钮的五种状态Start -> Play -> Pause -> Resume -> End控制,即播放中途实现了暂停和恢复,因此代码要稍微复杂一些。此处的重点是playAudioCallback()函数里的else分支,如果在暂停状态下,必须还是要给PyAudio返回一段空数据:
import wave
import pyaudio
AUDIO_PLAY_STATE_START = 0
AUDIO_PLAY_STATE_PLAY = 1
AUDIO_PLAY_STATE_PAUSE = 2
AUDIO_PLAY_STATE_RESUME = 3
AUDIO_PLAY_STATE_END = 4
class mainWin(win.speech_win):
def __init__(self, parent):
# ...
# Start -> Play -> Pause -> Resume -> End
self.playState = AUDIO_PLAY_STATE_START
def viewAudio( self, event ):
self.wavPath = self.m_genericDirCtrl_audioDir.GetFilePath()
if self.playState != AUDIO_PLAY_STATE_START:
self.playState = AUDIO_PLAY_STATE_END
self.m_button_play.SetLabel('Play Start')
def playAudioCallback(self, in_data, frame_count, time_info, status):
if self.playState == AUDIO_PLAY_STATE_PLAY or self.playState == AUDIO_PLAY_STATE_RESUME:
data = self.wavFile.readframes(frame_count)
if self.wavFile.getnframes() == self.wavFile.tell():
status = pyaudio.paComplete
self.playState = AUDIO_PLAY_STATE_END
self.m_button_play.SetLabel('Play Start')
else:
status = pyaudio.paContinue
return (data, status)
else:
# Note!!!:
data = numpy.zeros(frame_count*self.wavFile.getnchannels()).tostring()
return (data, pyaudio.paContinue)
def playAudio( self, event ):
if os.path.isfile(self.wavPath):
if self.playState == AUDIO_PLAY_STATE_END:
self.playState = AUDIO_PLAY_STATE_START
self.wavStream.stop_stream()
self.wavStream.close()
self.wavPyaudio.terminate()
self.wavFile.close()
if self.playState == AUDIO_PLAY_STATE_START:
self.playState = AUDIO_PLAY_STATE_PLAY
self.m_button_play.SetLabel('Play Pause')
self.wavFile = wave.open(self.wavPath, "rb")
self.wavPyaudio = pyaudio.PyAudio()
self.wavStream = self.wavPyaudio.open(format=self.wavPyaudio.get_format_from_width(self.wavFile.getsampwidth()),
channels=self.wavFile.getnchannels(),
rate=self.wavFile.getframerate(),
output=True,
stream_callback=self.playAudioCallback)
self.wavStream.start_stream()
elif self.playState == AUDIO_PLAY_STATE_PLAY or self.playState == AUDIO_PLAY_STATE_RESUME:
self.playState = AUDIO_PLAY_STATE_PAUSE
self.m_button_play.SetLabel('Play Resume')
elif self.playState == AUDIO_PLAY_STATE_PAUSE:
self.playState = AUDIO_PLAY_STATE_RESUME
self.m_button_play.SetLabel('Play Pause')
else:
pass相比播放功能,录制功能就简单了些,因为录制按钮状态就两种Start -> End,暂不支持中断后继续录制。这里的重点主要是音频三大参数(采样宽度,采样率,通道数)设置的支持:
import wave
import pyaudio
class mainWin(win.speech_win):
def recordAudioCallback(self, in_data, frame_count, time_info, status):
if not self.isRecording:
status = pyaudio.paComplete
else:
self.wavFrames.append(in_data)
status = pyaudio.paContinue
return (in_data, status)
def recordAudio( self, event ):
if not self.isRecording:
self.isRecording = True
self.m_button_record.SetLabel('Record Stop')
# Get the wave parameter from user settings
fileName = self.m_textCtrl_recFileName.GetLineText(0)
if fileName == '':
fileName = 'rec_untitled1.wav'
self.wavPath = os.path.join(os.path.dirname(os.path.abspath(os.path.dirname(__file__))), 'conv', 'rec', fileName)
self.wavSampRate = int(self.m_choice_sampRate.GetString(self.m_choice_sampRate.GetSelection()))
channels = self.m_choice_channels.GetString(self.m_choice_channels.GetSelection())
if channels == 'Mono':
self.wavChannels = 1
else: #if channels == 'Stereo':
self.wavChannels = 2
bitDepth = int(self.m_choice_bitDepth.GetString(self.m_choice_bitDepth.GetSelection()))
if bitDepth == 8:
self.wavBitFormat = pyaudio.paInt8
elif bitDepth == 24:
self.wavBitFormat = pyaudio.paInt24
elif bitDepth == 32:
self.wavBitFormat = pyaudio.paFloat32
else:
self.wavBitFormat = pyaudio.paInt16
# Record audio according to wave parameters
self.wavFrames = []
self.wavPyaudio = pyaudio.PyAudio()
self.wavStream = self.wavPyaudio.open(format=self.wavBitFormat,
channels=self.wavChannels,
rate=self.wavSampRate,
input=True,
frames_per_buffer=AUDIO_CHUNK_SIZE,
stream_callback=self.recordAudioCallback)
self.wavStream.start_stream()
else:
self.isRecording = False
self.m_button_record.SetLabel('Record Start')
self.wavStream.stop_stream()
self.wavStream.close()
self.wavPyaudio.terminate()
# Save the wave data into file
wavFile = wave.open(self.wavPath, 'wb')
wavFile.setnchannels(self.wavChannels)
wavFile.setsampwidth(self.wavPyaudio.get_sample_size(self.wavBitFormat))
wavFile.setframerate(self.wavSampRate)
wavFile.writeframes(b''.join(self.wavFrames))
wavFile.close()语音识别是pzh-py-speech的核心功能,pzh-py-speech利用的是SpeechRecognition系统以及CMU Sphinx引擎来实现的语音识别功能,今天痞子衡为大家介绍了语音识别在pzh-py-speech中是如何实现的。
SpeechRecognition是一套基于python实现的语音识别的系统,该系统的设计者为Anthony Zhang(Uberi),该库从2014年开始推出,一直持续更新至今,pzh-py-speech使用的是SpeechRecognition 3.8.1。
SpeechRecognition系统的官方主页如下:
SpeechRecognition官方主页:https : //github.com/Uberi/speech_recognition
SpeechRecognition安装方法:https : //pypi.org/project/SpeechRecognition/
SpeechRecognition系统本身并没有语音识别功能,其主要是调用第三方语音识别引擎来实现语音识别,SpeechRecognition支持的语音识别引擎非常多,有如下8种:
CMU Sphinx(离线工作)
Google语音识别
Google Cloud Speech API
威特
Microsoft Bing语音识别
Houndify API
IBM语音转文字
Snowboy Hotword检测(可离线使用)
不管是替代哪一种语音识别引擎,在SpeechRecognition里调用接口都是一致的,我们以实现音频文件转文字的示例代码audio_transcribe.py来了解SpeechRecognition的用法,截取audio_transcribe.py部分内容如下:
import speech_recognition as sr
# 指定要转换的音频源文件(english.wav)
from os import path
AUDIO_FILE = path.join(path.dirname(path.realpath(__file__)), "english.wav")
# 定义SpeechRecognition对象并获取音频源文件(english.wav)中的数据
r = sr.Recognizer()
with sr.AudioFile(AUDIO_FILE) as source:
audio = r.record(source) # read the entire audio file
# 使用CMU Sphinx引擎去识别音频
try:
print("Sphinx thinks you said " + r.recognize_sphinx(audio))
except sr.UnknownValueError:
print("Sphinx could not understand audio")
except sr.RequestError as e:
print("Sphinx error; {0}".format(e))
# 使用Microsoft Bing Voice Recognition引擎去识别音频
BING_KEY = "INSERT BING API KEY HERE" # Microsoft Bing Voice Recognition API keys 32-character lowercase hexadecimal strings
try:
print("Microsoft Bing Voice Recognition thinks you said " + r.recognize_bing(audio, key=BING_KEY))
except sr.UnknownValueError:
print("Microsoft Bing Voice Recognition could not understand audio")
except sr.RequestError as e:
print("Could not request results from Microsoft Bing Voice Recognition service; {0}".format(e))
# 使用其他引擎去识别音频
# ... ...有木有觉得SpeechRecognition使用起来特别简单?是的,这正是SpeechRecognition系统强大之处,更多示例可见https://github.com/Uberi/speech_recognition/tree/master/examples。
前面痞子衡讲了SpeechRecognition系统本身并没有语音识别功能,因此我们需要为SpeechRecognition安装一个语音识别引擎,痞子衡为JaysPySPEECH的是可离线工作的CMU
Sphinx。CMU Sphinx是卡内基梅隆大学开发的一种开源语音识别引擎,该引擎可以离线工作,并支持多语种(英语,中文,法语等)。CMUSphinx引擎的官方主页如下:
CMU Sphinx官方主页:https : //cmusphinx.github.io/
CMU Sphinx官方下载:https : //sourceforge.net/projects/cmusphinx/
由于JaysPySPEECH是基于Python环境开发的,因此我们不能直接使用CMU Sphinx,那该怎么办?别着急,Dmitry Prazdnichnov大牛为CMU Sphinx写了Python封装接口,即PocketSphinx,其官方主页如下:
PocketSphinx官方主页:https : //github.com/bambocher/pocketsphinx-python
PocketSphinx安装方法:https ://pypi.org/project/pocketsphinx/
我们在JaysPySPEECH生成系列文章第一篇环境构建里已经安装了语音识别和PocketSphinx,痞子衡的安装路径为C:\ tools_mcu \ Python27 \ Lib \ site-packages下的\ speech_recognition与\ pocketsphinx,安装好这两个包,引擎便选好了。
默认情况下,PocketSphinx仅支持美国英语语言的识别,在C:\ tools_mcu \ Python27 \ Lib \ site-packages \ speech_recognition \ pocketsphinx-data目录下仅能看到美国文件夹,先来看一下这个文件夹里有什么:
\pocketsphinx-data\en-US
\acoustic-model --声学模型
\feat.params --HMM模型的特征参数
\mdef --模型定义文件
\means --混合高斯模型的均值
\mixture_weights --混合权重
\noisedict --噪声也就是非语音字典
\sendump --从声学模型中获取混合权重
\transition_matrices --HMM模型的状态转移矩阵
\variances --混合高斯模型的方差
\language-model.lm.bin --语言模型
\pronounciation-dictionary.dict --拼音字典 其实看到了这一堆文件是不是觉得有点难懂?这其实跟CMU Sphinx引擎的语音识别原理有关,此处我们暂且不深入了解,对我们调用API的应用来说只需要关于如何为CMU Sphinx增加其他语言包(某种中文包)。
要想增加其他语言,首先得要有语言包数据,CMU Sphinx主页提供了12种主流语言包的下载https://sourceforge.net/projects/cmusphinx/files/Acoustic_and_Language_Models/ ,因为JaysPySPEECH需要支持中文识别,因此我们需要下载\ Mandarin下面的三个文件:
\Mandarin
\zh_broadcastnews_16k_ptm256_8000.tar.bz2 --声学模型
\zh_broadcastnews_64000_utf8.DMP --语言模型
\zh_broadcastnews_utf8.dic --拼音字典有了中文语言包数据,然后我们需要根据关于使用PocketSphinx的说明里指示的步骤操作,痞子衡整理如下:
\ speech_recognition \ pocketsphinx-data目录下创建zh-CN文件夹
将zh_broadcastnews_16k_ptm256_8000.tar.bz2解压缩并里面所有文件放入\ zh-CN \ acoustic-model文件夹下
将zh_broadcastnews_utf8.dic重命名为发音-dictionary.dict并加入\ zh-CN文件夹下
通过SphinxBase工具将zh_broadcastnews_64000_utf8.DMP转换成language-model.lm.bin并加入\ zh-CN文件夹下
关于第4步里提到的SphinxBase工具,我们需要从https://github.com/cmusphinx/sphinxbase里下载源码,然后使用Visual Studio 2010(或更高版本)打开\ sphinxbase \ sphinxbase.sln工程全部重建后会在\ sphinxbase \ bin \ Release \ x64下看到生成了如下6个工具:
\\sphinxbase\bin\Release\x64
\sphinx_cepview.exe
\sphinx_fe.exe
\sphinx_jsgf2fsg.exe
\sphinx_lm_convert.exe
\sphinx_pitch.exe
\sphinx_seg.exe我们主要使用sphinx_lm_convert.exe工具完成转换工作生成language-model.lm.bin,具体命令如下:
PS C:\ tools_mcu \ sphinxbase \ bin \ Release \ x64> 。\ sphinx_lm_convert.exe -i。\ zh_broadcastnews_64000_utf8.DMP -o language-model.lm-ofmt arpa
Current configuration:
[NAME] [DEFLT] [VALUE]
-case
-help no no
-i .\zh_broadcastnews_64000_utf8.DMP
-ifmt
-logbase 1.0001 1.000100e+00
-mmap no no
-o language-model.lm
-ofmt arpa
INFO: ngram_model_trie.c(354): Trying to read LM in trie binary format
INFO: ngram_model_trie.c(365): Header doesn't match
INFO: ngram_model_trie.c(177): Trying to read LM in arpa format
INFO: ngram_model_trie.c(70): No \data\ mark in LM file
INFO: ngram_model_trie.c(445): Trying to read LM in dmp format
INFO: ngram_model_trie.c(527): ngrams 1=63944, 2=16600781, 3=20708460
INFO: lm_trie.c(474): Training quantizer
INFO: lm_trie.c(482): Building LM triePS C:\ tools_mcu \ sphinxbase \ bin \ Release \ x64> 。\ sphinx_lm_convert.exe -i。\ language-model.lm -o语言模型.lm.bin
Current configuration:
[NAME] [DEFLT] [VALUE]
-case
-help no no
-i .\language-model.lm
-ifmt
-logbase 1.0001 1.000100e+00
-mmap no no
-o language-model.lm.bin
-ofmt
INFO: ngram_model_trie.c(354): Trying to read LM in trie binary format
INFO: ngram_model_trie.c(365): Header doesn't match
INFO: ngram_model_trie.c(177): Trying to read LM in arpa format
INFO: ngram_model_trie.c(193): LM of order 3
INFO: ngram_model_trie.c(195): #1-grams: 63944
INFO: ngram_model_trie.c(195): #2-grams: 16600781
INFO: ngram_model_trie.c(195): #3-grams: 20708460
INFO: lm_trie.c(474): Training quantizer
INFO: lm_trie.c(482): Building LM trie
语音识别代码实现实际上很简单,直接调用speech_recognition里的API即可,目前仅实现了CMU Sphinx引擎,并且仅支持中英双语识别。具体到pzh-py-speech上主要是实现GUI界面上的“ ASR”按钮的相应函数,即audioSpeechRecognition(),如果用户更改了配置参数(语言类型,ASR引擎类型),并单击“ ASR”按钮,此时便会触发audioSpeechRecognition()的执行。代码如下:
import speech_recognition
class mainWin(win.speech_win):
def getLanguageSelection(self):
languageType = self.m_choice_lang.GetString(self.m_choice_lang.GetSelection())
if languageType == 'Mandarin Chinese':
languageType = 'zh-CN'
languageName = 'Chinese'
else: # languageType == 'US English':
languageType = 'en-US'
languageName = 'English'
return languageType, languageName
def audioSpeechRecognition( self, event ):
if os.path.isfile(self.wavPath):
# 创建speech_recognition语音识别对象asrObj
asrObj = speech_recognition.Recognizer()
# 获取wav文件里的语音内容
with speech_recognition.AudioFile(self.wavPath) as source:
speechAudio = asrObj.record(source)
self.m_textCtrl_asrttsText.Clear()
# 获取语音语言类型(English/Chinese)
languageType, languageName = self.getLanguageSelection()
engineType = self.m_choice_asrEngine.GetString(self.m_choice_asrEngine.GetSelection())
if engineType == 'CMU Sphinx':
try:
# 调用recognize_sphinx完成语音识别
speechText = asrObj.recognize_sphinx(speechAudio, language=languageType)
# 语音识别结果显示在asrttsText文本框内
self.m_textCtrl_asrttsText.write(speechText)
self.statusBar.SetStatusText("ASR Conversation Info: Successfully")
# 语音识别结果写入指定文件
fileName = self.m_textCtrl_asrFileName.GetLineText(0)
if fileName == '':
fileName = 'asr_untitled1.txt'
asrFilePath = os.path.join(os.path.dirname(os.path.abspath(os.path.dirname(__file__))), 'conv', 'asr', fileName)
asrFileObj = open(asrFilePath, 'wb')
asrFileObj.write(speechText)
asrFileObj.close()
except speech_recognition.UnknownValueError:
self.statusBar.SetStatusText("ASR Conversation Info: Sphinx could not understand audio")
except speech_recognition.RequestError as e:
self.statusBar.SetStatusText("ASR Conversation Info: Sphinx error; {0}".format(e))
else:
self.statusBar.SetStatusText("ASR Conversation Info: Unavailable ASR Engine")
大家好,我是痞子衡,是正经搞技术的痞子。今天痞子衡给大家介绍的是语音处理工具pzh-py-speech诞生之文语合成实现。
文语合成是pzh-py-speech的核心功能,pzh-py-speech借助的是pyttsx3以及eSpeak引擎来实现的文语合成功能,今天痞子衡为大家介绍文语合成在pzh-py-speech中是如何实现的。
pyttsx3是一套基于实现SAPI5文语合成引擎的Python封装库,该库的设计者为Natesh M Bhat,该库其实是 pyTTS 和 pyttsx 项目的延续,pyttsx3主要是为Python3版本设计的,但同时也兼容Python2。JaysPySPEECH使用的是pyttsx3 2.7。
pyttsx3系统的官方主页如下:
pyttsx3官方主页: https://github.com/nateshmbhat/pyttsx3
pyttsx3安装方法: https://pypi.org/project/pyttsx3/
pyttsx3的使用足够简单,其官方文档 https://pyttsx3.readthedocs.io/en/latest/engine.html 半小时即可读完,下面是最简单的一个示例代码:
import pyttsx3;
engine = pyttsx3.init();
engine.say("I will speak this text");
engine.runAndWait() ;前面痞子衡讲了pyttsx3基于的文语合成内核是SAPI5引擎,这是微软公司开发的TTS引擎,其官方主页如下:
SAPI5官方文档: https://docs.microsoft.com/en-us/previous-versions/windows/desktop/ms723627(v%3dvs.85)
由于pyttsx3已经将SAPI5封装好,所有我们没有必要关注SAPI5本身的TTS实现原理。
在使用pyttsx3进行文语合成时,依赖的是当前PC的语音环境,打开控制面板(Control Panel)->语言识别(Speech Recognition),可见到如下页面:
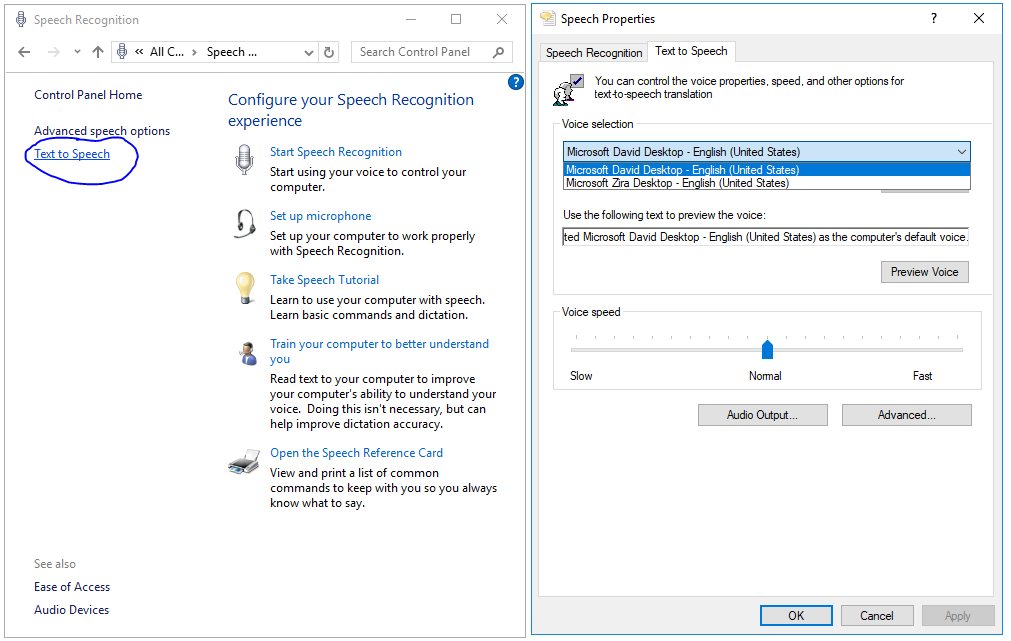
痞子衡使用的PC是Win10英文版,故默认仅有英文语音包(David是男声,Zira是女声),这点也可以使用如下pyttsx3调用代码来确认:
import pyttsx3;
ttsObj = pyttsx3.init()
voices = ttsObj.getProperty('voices')
for voice in voices:
print ('id = {} \nname = {} \n'.format(voice.id, voice.name))代码运行结果如下:
id = HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Speech\Voices\Tokens\TTS_MS_EN-US_DAVID_11.0
name = Microsoft David Desktop - English (United States)
id = HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Speech\Voices\Tokens\TTS_MS_EN-US_ZIRA_11.0
name = Microsoft Zira Desktop - English (United States)
要想在使用pzh-py-speech时可以实现中英双语合成,要确保PC上既有英文语音包也有中文语音包,痞子衡PC上当前仅有英文语音包,故需要安装中文语音包(安装其他语言语音包的方法类似)。
Windows系统下中文语音包有很多,可以使用第三方公司提供的语音包(比如 NeoSpeech公司 ),也可以使用微软提供的语音包,痞子衡选用的是经典的慧慧语音包(zh-CN_HuiHui)。
进入 Microsoft Speech Platform - Runtime (Version 11) 和 Microsoft Speech Platform - Runtime Languages (Version 11) 下载页面将选中文件下载(亲测仅能用Google Chrome浏览器才能正常访问,IE竟然也无法打开):

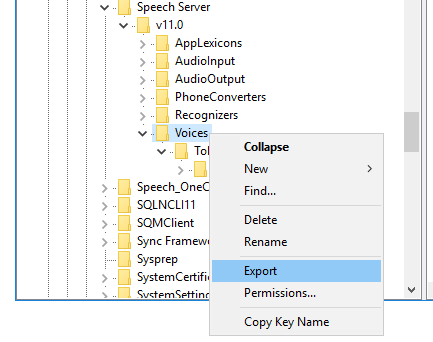
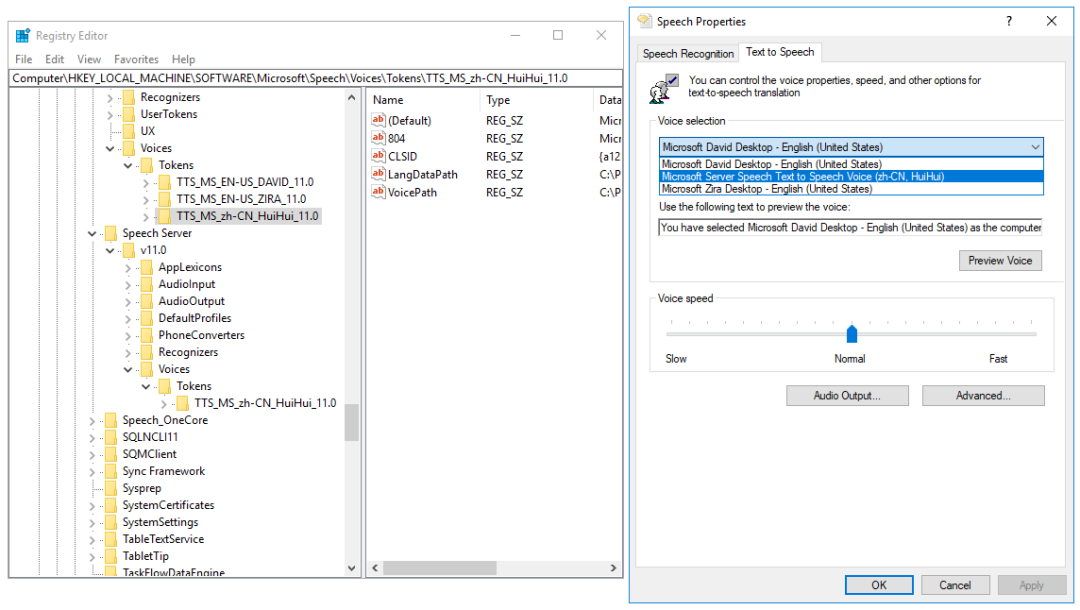
先安装SpeechPlatformRuntime.msi(双击安装即可),安装完成之后重启电脑,再安装MSSpeech_TTS_zh-CN_HuiHui.msi,安装结束之后需要修改注册表,打开Run(Win键+R键)输入"regedit"即可看到如下registry编辑界面,HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Speech\Voices路径下可以看到默认语音包(DAVID, ZIRA),HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Speech Server\v11.0\Voices路径下可看到新安装的语音包(HuiHui):
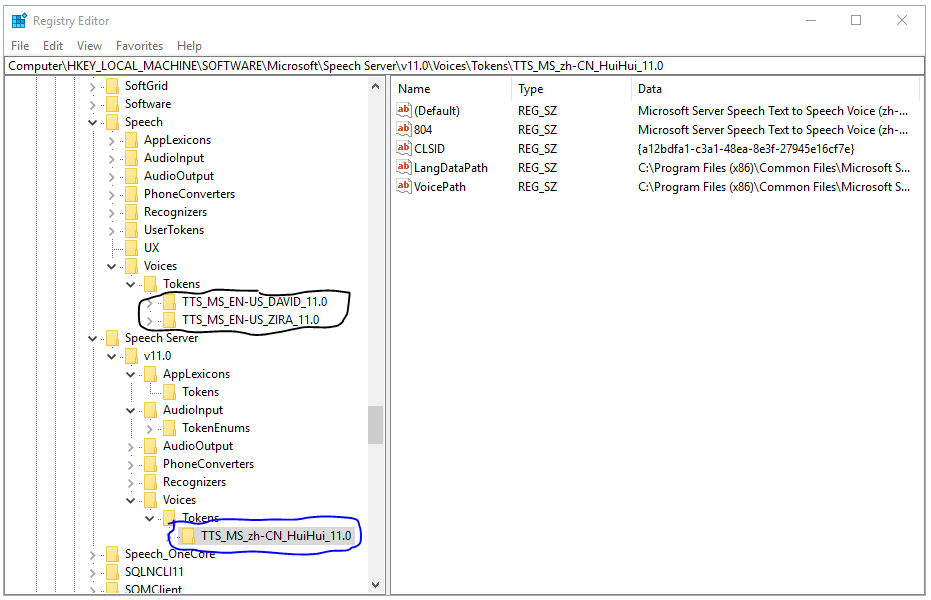
右键HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Speech Server\v11.0\Voices,将其导出成.reg文件,使用文本编辑器打开这个.reg文件将其中"\Speech Server\v11.0"全部替换成"\Speech"并保存,然后将这个修改后的.reg文件再导入注册表。
导入成功后,便可在注册表和语音识别选项里看到Huihui身影:
Note: 上述修改仅针对32bit操作系统,如果是64bit系统,需要同时将HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\Microsoft\Speech Server\v11.0\Voices路径的注册表按同样方法也操作一遍。
由于pyttsx3仅能在线发声,无法将合成后的语音保存为wav文件,因此痞子衡需要为JaysPySPEECH再寻一款可以保存为wav的TTS引擎。痞子衡选中的是eSpeak,eSpeak是一个简洁的开源语音合成软件,用C语言写成,支持英语和其他很多语言,同时也支持SAPI5接口,合成的语音可以导出为wav文件。
eSpeak的官方主页如下:
eSpeak官方主页: http://espeak.sourceforge.net/
eSpeak下载安装: http://espeak.sourceforge.net/download.html
eSpeak补充语言包: http://espeak.sourceforge.net/data/index.html
eSpeak从标准输入或者输入文件中读取文本,虽然语音输出与真人声音相去甚远,但是在项目需要的时候,eSpeak仍不失为一个简便快捷的工具。
痞子衡将eSpeak 1.48.04安装在了C:\tools_mcu\eSpeak路径下,进入这个路径可以找到\eSpeak\command_line\espeak.exe,这便是我们需要调用的工具,为了方便调用,你需要将"C:\tools_mcu\eSpeak\command_line"路径加入系统环境变量Path中。
关于中文支持,在\eSpeak\espeak-data\zh_dict文件里已经包含了基本的中文字符,但是如要想要完整的中文支持,还需要下载zh_listx.zip中文语音包,解压后将里面的zh_listx文件放到\eSpeak\dictsource目录下,并且在\eSpeak\dictsource路径下执行命令"espeak --compile=zh",执行成功后可以看到\eSpeak\espeak-data\zh_dict文件明显变大了。
eSpeak对于python来说是个外部程序,我们需要借助subprocess来调用espeak.exe,下面是示例代码:
import subprocess
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
enText = "Hello world"
zhText = u"你好世界"
txtFile = "C:/test.txt" #文件内为中文
wavFile = "C:/test.wav"
# 在线发音(-v是设置voice,en是英文,m3男声,zh是中文,f3是女声)
subprocess.call(["espeak", "-ven+m3", enText])
subprocess.call(["espeak", "-vzh+f3", zhText])
# 保存为wav文件(第一种方法仅能保存英文wav,如果想保存其他语言wav需要使用第二种方法)
subprocess.call(["espeak","-w"+wavFile, enText])
subprocess.call(["espeak","-vzh+f3", "-f"+txtFile, "-w"+wavFile])如果想直接体验eSpeak的发音质量,可以直接打开\eSpeak\TTSApp.exe应用程序,软件使用非常简单:
文语合成实现主要分为两部分:TTS, TTW。实现TTS需要import pyttsx3,实现TTW需要借助subprocess调用eSpeak,下面 痞子衡分别介绍这两部分的实现:
TTS代码实现其实很简单,目前仅实现了pyttsx3引擎,并且仅支持中英双语识别。具体到pzh-py-speech上主要是实现GUI界面上"TTS"按钮的回调函数,即textToSpeech(),如果用户选定了配置参数(语言类型、发音人类型、TTS引擎类型),并点击了"TTS"按钮,此时便会触发textToSpeech()的执行。代码如下:
reload(sys)
sys.setdefaultencoding('utf-8')
import pyttsx3
class mainWin(win.speech_win):
def __init__(self, parent):
# ...
self.ttsObj = None
def refreshVoice( self, event ):
languageType, languageName = self.getLanguageSelection()
engineType = self.m_choice_ttsEngine.GetString(self.m_choice_ttsEngine.GetSelection())
if engineType == 'pyttsx3 - SAPI5':
if self.ttsObj == None:
self.ttsObj = pyttsx3.init()
voices = self.ttsObj.getProperty('voices')
voiceItems = [None] * len(voices)
itemIndex = 0
for voice in voices:
voiceId = voice.id.lower()
voiceName = voice.name.lower()
if (voiceId.find(languageType.lower()) != -1) or (voiceName.find(languageName.lower()) != -1):
voiceItems[itemIndex] = voice.name
itemIndex += 1
voiceItems = voiceItems[0:itemIndex]
self.m_choice_voice.Clear()
self.m_choice_voice.SetItems(voiceItems)
else:
voiceItem = ['N/A']
self.m_choice_voice.Clear()
self.m_choice_voice.SetItems(voiceItem)
def textToSpeech( self, event ):
# 获取语音语言类型(English/Chinese)
languageType, languageName = self.getLanguageSelection()
# 从asrttsText文本框获取要转换的文本
lines = self.m_textCtrl_asrttsText.GetNumberOfLines()
if lines != 0:
data = ''
for i in range(0, lines):
data += self.m_textCtrl_asrttsText.GetLineText(i)
else:
return
ttsEngineType = self.m_choice_ttsEngine.GetString(self.m_choice_ttsEngine.GetSelection())
if ttsEngineType == 'pyttsx3 - SAPI5':
# 尝试创建pyttsx3文语合成对象ttsObj
if self.ttsObj == None:
self.ttsObj = pyttsx3.init()
# 搜索当前PC是否存在指定语言类型的发声人
hasVoice = False
voices = self.ttsObj.getProperty('voices')
voiceSel = self.m_choice_voice.GetString(self.m_choice_voice.GetSelection())
for voice in voices:
#print ('id = {} \nname = {} \nlanguages = {} \n'.format(voice.id, voice.name, voice.languages))
voiceId = voice.id.lower()
voiceName = voice.name.lower()
if (voiceId.find(languageType.lower()) != -1) or (voiceName.find(languageName.lower()) != -1):
if (voiceSel == '') or (voiceSel == voice.name):
hasVoice = True
break
if hasVoice:
# 调用pyttsx3里的say()和runAndWait()完成文语合成,直接在线发音
self.ttsObj.setProperty('voice', voice.id)
self.ttsObj.say(data)
self.statusBar.SetStatusText("TTS Conversation Info: Run and Wait")
self.ttsObj.runAndWait()
self.statusBar.SetStatusText("TTS Conversation Info: Successfully")
else:
self.statusBar.SetStatusText("TTS Conversation Info: Language is not supported by current PC")
self.textToWav(data, languageType)
else:
self.statusBar.SetStatusText("TTS Conversation Info: Unavailable TTS Engine")TTW代码实现也很简单,目前仅实现了eSpeak引擎,并且仅支持中英双语识别。具体到pzh-py-speech上主要是实现GUI界面上"TTW"按钮的回调函数,即textToWav(),如果用户选定了配置参数(发音人性别类型、TTW引擎类型),并点击了"TTW"按钮,此时便会触发textToWav()的执行。代码如下:
import subprocess
class mainWin(win.speech_win):
def textToWav(self, text, language):
fileName = self.m_textCtrl_ttsFileName.GetLineText(0)
if fileName == '':
fileName = 'tts_untitled1.wav'
ttsFilePath = os.path.join(os.path.dirname(os.path.abspath(os.path.dirname(__file__))), 'conv', 'tts', fileName)
ttwEngineType = self.m_choice_ttwEngine.GetString(self.m_choice_ttwEngine.GetSelection())
if ttwEngineType == 'eSpeak TTS':
ttsTextFile = os.path.join(os.path.abspath(os.path.dirname(__file__)), 'ttsTextTemp.txt')
ttsTextFileObj = open(ttsTextFile, 'wb')
ttsTextFileObj.write(text)
ttsTextFileObj.close()
try:
#espeak_path = "C:/tools_mcu/eSpeak/command_line/espeak.exe"
#subprocess.call([espeak_path, "-v"+languageType[0:2], text])
gender = self.m_choice_gender.GetString(self.m_choice_gender.GetSelection())
gender = gender.lower()[0] + '3'
# 调用espeak.exe完成文字到wav文件的转换
subprocess.call(["espeak", "-v"+language[0:2]+'+'+gender, "-f"+ttsTextFile, "-w"+ttsFilePath])
except:
self.statusBar.SetStatusText("TTW Conversation Info: eSpeak is not installed or its path is not added into system environment")
os.remove(ttsTextFile)
else:
self.statusBar.SetStatusText("TTW Conversation Info: Unavailable TTW Engine")至此,语音处理工具pzh-py-speech诞生之文语合成实现痞子衡便介绍完毕了,掌声在哪里~~~
本文授权转载自公众号“痞子衡嵌入式”,作者痞子衡
