随着我国近几年人工智能新基建与大规模计算系统的逐步落地,为了使大规模人工智能计算系统健康持续发展,需要一个能够有效地评价计算系统的人工智能算力的评价指标,而现有的测试方法无法满足这一需求。本文来自“AIPerf:大规模人工智能算力基准测试程序”。
目前,已有一些大规模计算系统的评测程序,例如Linpack是一个目前被广泛使用的高性能计算机双精度浮点运算性能基准评测程序,国际超算Top500榜单依据Linpack值来进行排名。
然而典型的人工智能应用并不需要双精度浮点数运算,大部分人工智能训练任务以单精度浮点数 或16 位浮点数为主,推 理以Int8为主。各大企业、高校和相关组织也相继开发了各类人工智能算力基准评测程序,如MLPerf、Mobile AI Bench、DeepBench、AIIA DNN Benchmark,以及在双精度的Linpack基础上改成混合精度的HPL-AI等基准评测程序,但是这些程序并不适用于大规模和可变规模人工智能计算系统的评测。
为了填补大规模计算系统人工智能算力评测这一领域的空白,清华大学与鹏城实验室联合研制并开发了人 工智能算力基准测试程序——AIPerf Benchmark(以下简称AIPerf)。
AIPerf基于微软NNI(neural network intelligence)开源框架实现,以自动化机器学习(AutoML)为负载,使用网络态射(network morphism)网络结构搜索和树状结构Parzen估计(tree-structured Parzen estimator,TPE)方法超参搜索来寻找精度更高的神经网络结构和(或)超参数。用户可以通过配置文件指定AutoML的相关参数,如训练使用的批大小(batch size)、最大epoch数、学习率、最大搜索模型总个数、最长搜索总时间、最大同时搜索模型个数(并发数)等多个参数。
AIPerf的设计达到了以下4个关键的设计目标。
(1)一个统一的分数:
AIPerf能够报告一个分数,该分数可以作为被评测计算集群系统的评价指标。AIPerf目前的评价指标是Tops,即平均每秒处理的混合精度AI浮点操作数。使用一个而不是多个分数能方便进行不同机器的横向比较,且方便公众宣传。
(2)可变的问题规模:
人工智能计算集群往往有不同的系统规模,差异性体现在节点数量、加速器数量、加速器类型、内存大小等指标上。因此,为了适应各种规模的高性能计算集群,AIPerf能够使用AutoML调整问题规模来适应集群规模的变化,从而充分利用人工智能计算集群的计算资源来体现其算力。
(3)具有实际的人工智能意义:
具有人工智能意义的计算(如神经网络运算)是 人 工智能 基 准 测试 程 序相较于传统高性能计算机基准测试程序的重要区别,也是 其能 够检测集 群人 工智能算力的 核心所在。目前,A I Perf 通 过 在ImageNet数据集上训练神经网络来运行 计 算 机 视 觉 应 用程 序;将 来,计 划 将自然语言处理等其他人工智能任务加入AIPerf的评测范围。
(4)包含必要的多机通信:
网络通信是人工智能计算集群设计的主要指标之一,也是其庞大计算能力的重要组成部分。作为面向高性能计算集群的人工智能基准测试程序,AIPerf包括必要的多机通信(如任务的分发、结果的收集与多机训练),从而将网络通信性能作为最终性能的影响因素之一。
在第二届中国超级算力大会(ChinaSC2020)上,基于AIPerf大规模人工智能算力基准评测程序的国际人工智能性能算力排行榜首次发布。鹏城实验室研制的基于ARM架构和华为加速处理器的鹏城云脑二主机以194 527 Tops的AIPerf算力荣登榜首,其性能是排名第二的联泰集群NVIDIA系统性能的12倍以上。
AIPerf基准评测程序还处于积极的开发和完善阶段,目前AIPerf正在应用负载、硬件适应性以及国际推广等方面大力推进。
AIPerf目前只支持面向计算机视觉的人工智能应用程序。为了更好地评估大规模智能系统在各个典型应用领域的性能,研究团队计划之后支持更多种网络搜索与训练算法以及评测数据集,同时支持更多类型的人工智能计算集群系统;此外,将积极推动AIPerf在国际上的影响力,将其打造成有国际影响力和公信力的大规模人工智能系统基准评测程序。
实际上,AI是HPC技术发展的一个衍生领域, 在HPC行业,TOP500排名基于Linpack BenchMark性能(最新版HPL 2.0规范从2008年一直用到现在),不过随着时间的推移,应用程序对更复杂计算的需求已变得原来越普遍,TOP500创始人之一的田纳西大学教授Jack Dongarra认为Linpack性能已经过时,大家也意识到单看CPU性能的弊端,开始使用HPCG(The High Performance Conjugate Gradients)性能来全面衡量超算性能。
HPCG使用更复杂的微分方程计算方式。Linpack衡量的是线性方程计算的速度和效率,无法测量这些更加复杂的计算程序。由于越来越多的应用程序采用微分方程计算方式,所以每一轮全球超级计算机500强排行榜的Linpack性能数据与真实的数据之间的差距将越来越大。
简单来说,Linpack更考验超算的处理器理论性能,而HPCG更看重实际性能,对内存系统、网络延迟要求也更高,所以任何HPC超算测出来的HPCG性能要比Linpack性能低得多,基本报中告有个HPCG/HPL比率可衡量计算效率,大部分超算的比例都在5%以内,1-3%的比比皆是。
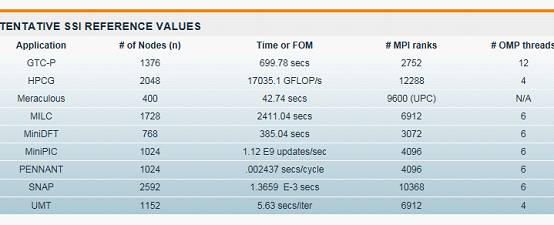
上图展现的是常见的HPC应用基准测试实例,除了HPCG外,主要包括GTC-P 、Meraculous、MILC、MiniDFT 、MiniPIC和PENNANT等。
GTC-P(Gyrokinetic Toroidal Code)通过使用粒子单元算法求解Vlassov-Poisson方程来模拟离子通过托卡马克的运动。在每个PIC(particle-in-cell)时间步长期间,粒子的电荷分布被内插到网格上,泊松方程在网格上求解,电场从网格内插到粒子,并且根据电场更新粒子的相空间坐标。
Meraculous是一种大规模并行基因组组装基准,构造并遍历存在于冗余短序列输入数据集中的长度为k(k-mers)的所有重叠子串的de Bruijn图。通过遍历de Bruijn图,并发现所有(可能断开的)线性子图,Meraculous能够构建基因组数据的高质量连续序列。
MILC基准代码表示由用于研究量子色力学(Quantum Chromodynamics)的MIMD晶格计算(MILC)协作的一组代码,属于亚原子物理学强相互作用的理论,通过并联机器进行四维格子规格理论的仿真。属于物理研究和模拟场景下的基准。
MiniDFT是用于建模材料的平面波密度泛函理论(Density Functional Theory)的模拟应用程序。MiniDFT使用LDA或PBE交换相关函数计算Kohn-Sham方程的自相一致解。对于自相一致的场循环的每次迭代,构建Fock矩阵,然后对角化。为了构建Fock矩阵,使用快速傅立叶变换将平面波基(其中最容易计算的动能)转换为实际空间(其中电位被评估)和返回的轨道。
MiniPIC是解决具有反射壁的任意域中的静电场中的离散Boltzman方程。MiniPIC基准测试使用非结构化的基于hex或tet的网格以及用于粒子网格的静态分区。粒子被跟踪到每个单元格交叉区,打包后并使用MPI传递到相邻的处理器。主要代码库使用了Trilinos数学库中的Tpetra对象进行矩阵/向量操作。
PENNANT是一款用于高级架构研究的应用程序。它具有用于操纵包含任意多边形的二维非结构化有限元网格的数据结构。PENNANT使用几何域分解支持MPI并行性,对使用MPI调用的处理器上实现的点数据进行采集和散射操作,还支持使用OpenMP或CUDA的线程并行。
SNAP作为代理应用程序来建模现代离散坐标中性粒子传输应用程序的性能。SNAP被认为是Sweep3D的更新,旨在用于混合计算架构。它是由洛斯阿拉莫斯国家实验室代码PARTISN建模的。
UMT是建立在多个核分布式存储,多节点并行计算机系统上,执行三维非结构化空间网格上的时间依赖性,能量依赖性,离散坐标和非线性辐射问题的解决方案。为了实现极大的可扩展性,应用程序利用节点之间的消息传递和在节点内角度的线程算法进行空间分解。
下面我们介绍下微观基准,微观基准则更具普适性,经常在项目中客户RFP中出现,更加偏向于纯粹的工具性能测试
Crossroads/N9 DGEMM基准测试是一种简单,多线程,密集矩阵乘法测试。该代码旨在测量单个节点的持续浮点计算速率。
IOR是最常见的BenchMark基准,旨在测量POSIX和MPI-IO级别的并行I/O性能。
Mdtest是一个MPI协调的元数据基准测试,可以对文件和目录执行文件操作,基于不同操作报告性能。
STREAM 基准用来测试持续的计算内存带宽。Crossroads/N9内存带宽基准测试是John D. McCalpin最初编写的STREAM基准测试版本的升级版。
至此我们对TOP500、HPCG、Graph500和Green Graph 500业界知名HPC系统排行榜,以及IOR、Mdtest和STREAM等HPC场景中的基准测试方法有了比较全面了解。