

AI 简报 20220916 期
原文:
摒弃了卷积之后,我反而更强了?商汤等开源无卷积的轻量级ViT架构LightViT
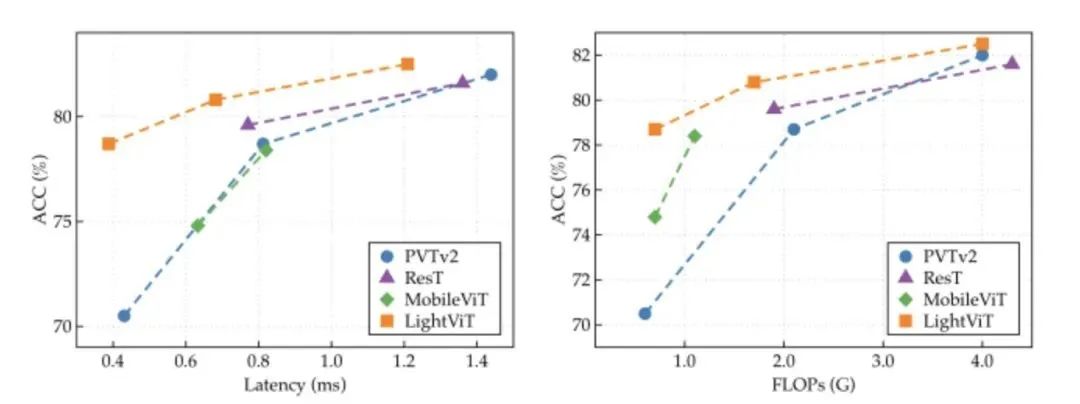
一些轻量级的ViTs工作为增强架构性能,常将卷积操作集成于Transformer模块中。本文为探讨卷积对轻量级ViTs的必要性,设计了一种无卷积的轻量级ViTs架构LightViT,提出一种全局而高效的信息聚合方案。除了在局部窗口内执行自注意计算之外,还在self-attention中引入额外的可学习标记来捕捉全局依赖性,在FFN中引入双维注意机制。LightViT-T在ImageNet上仅用0.7G FLOPs就实现了78.7%的准确率,比PVTv2-B0高出8.2%。代码已开源。

论文地址:https://arxiv.org/abs/2207.05557
代码地址:https://github.com/hunto/LightViT
ViTs模型DeiT-Ti和PVTv2-B0在ImageNet上可以达到72.2%和70.5%的准确率,而经典CNN模型RegNetY-800M在类似的FLOPs下达到了76.3%的准确率。这一现象表明某些轻量级的ViTs性能反而不如同级别CNNs。
作者等人将这一现象的原因归咎于CNNs固有的归纳偏置(inductive bias),同时现有很多工作试图将卷积集成于ViTs中来提高模型性能。然而不管是宏观上直接将卷积与self-attention集成/混合,还是微观上将卷积计算纳入self-attention计算之中,都说明了卷积对于轻量级ViTs的性能提升是至关重要的存在。
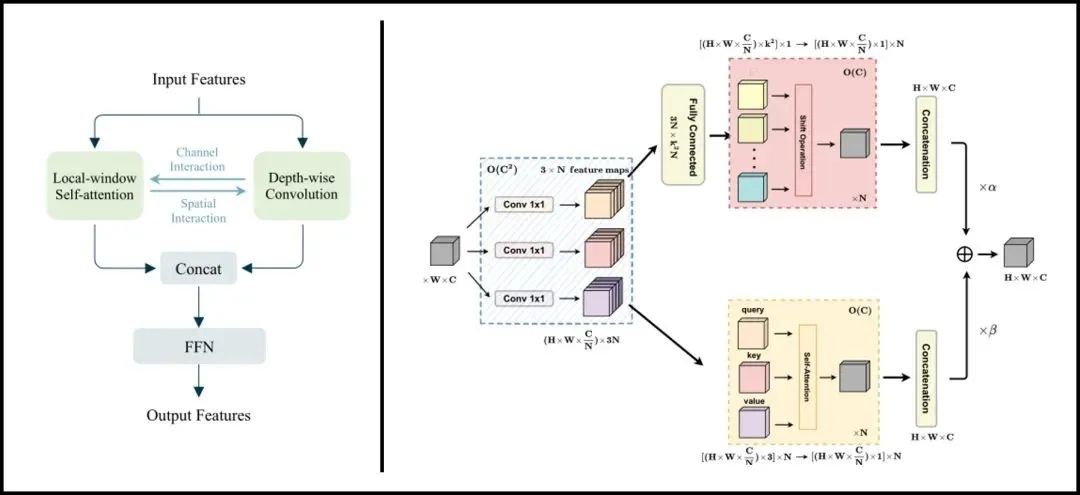
作者等人认为,在ViTs中混合卷积操作,是一种信息聚合的方式,卷积通过共享内核建立了所作用token之间的明确联系。基于这一点,作者等人提出“如果这种明确的聚合能以更均匀的方式发挥作用,那么它们对于轻量级的ViTs来说实际上是不必要的”。
至此LightViT油然而生,除了继续在局部窗口内执行自注意计算之外,对架构的主要修改针对self-attention和FFN部分。在self-attention中引入可学习的全局标记来对全局依赖关系进行建模,并被广播到局部token中,因此每一个token除了拥有局部窗口注意计算带来的局部依赖关系外,还获得了全局依赖关系。在FFN中,作者等人注意到轻量级模型的通道尺寸较小,因此设计一种双维注意模块来提升模型性能。其性能对比简图如下所示:
原文:PyTorch 转入 Linux 基金会,对 AI 研究将产生重大影响

近日,PyTorch 创始人 Soumith Chintala 在PyTorch官网宣布称,PyTorch 作为一个顶级项目,将正式转移到 Linux 基金会(LF),名称为 PyTorch 基金会。
PyTorch 诞生于 2017 年 1 月,由 Facebook 人工智能研究院(FAIR)推出,是一个基于 Torch 的 Python 开源机器学习库,可用于自然语言处理等应用程序。作为最受欢迎的机器学习框架之一,PyTorch 目前已拥有超过 2400 名贡献者,以 PyTorch 为基础构建项目近达 15.4 万个。
而 Linux 基金会的核心使命正是协作开发开源软件,基金会的管理委员会人员,均来自AMD、亚马逊网络服务(AWS)、谷歌云、Meta、微软Azure和英伟达等企业,这种模式与 PyTorch 当前状况及发展方向相一致。PyTorch 基金会的成立,可确保在未来几年内由不同的成员群体,以透明公开的方式做出商业决策。
对此 Soumith Chintala 表示,“随着 PyTorch 继续成长为一个多利益相关者项目,是时候转向更广泛的开源基础了”,“很高兴 Linux 基金会将成为我们的新家,因为他们在支持像我们这样的大型开源项目(例如 Kubernetes 和 NodeJS)方面拥有丰富的经验。”
扎克伯格也在Facebook 帖子中写道,“新的 PyTorch 基金会董事会将包括许多帮助社区发展到今天的人工智能领导者,包括 Meta 和我们在 AMD、亚马逊、谷歌、微软和英伟达的合作伙伴。我很高兴能够继续建立 PyTorch 社区并推进 AI 研究。”
原文:
单目3D检测新SOTA!旷视提出PersDet在透视BEV中进行3D目标检测
arXiv论文“PersDet: Monocular 3D Detection in Perspective Bird’s-Eye-View“,2022年8月19日, 旷视科技的工作。

目前,在BEV中检测3D目标,优于用于自动驾驶和机器人的其他3D检测方法。然而,将图像特征转换为BEV需要特殊的算子来进行特征采样。许多边缘设备不支持这些操作,在部署检测器时会带来额外的障碍。为了解决这个问题,重新讨论BEV表示的生成,并提出在透视BEV中检测目标一种不需要特征采样的新的BEV表示。
透视BEV特征同样可以享受BEV范式的好处。此外,透视BEV通过解决特征采样引起的问题,提高了检测性能。基于这一发现,提出透视BEV空间中高性能目标检测的方法-PersDet。
在实现简单且内存高效的结构的同时,PersDet在nuScenes基准上优于现有最先进的单目方法,当使用ResNet-50作为主干时,达到34.6%的mAP和40.8%的NDS。
基于摄像机的3-D目标检测器可分为两大类:摄像机视图(CV)检测器和BEV检测器。
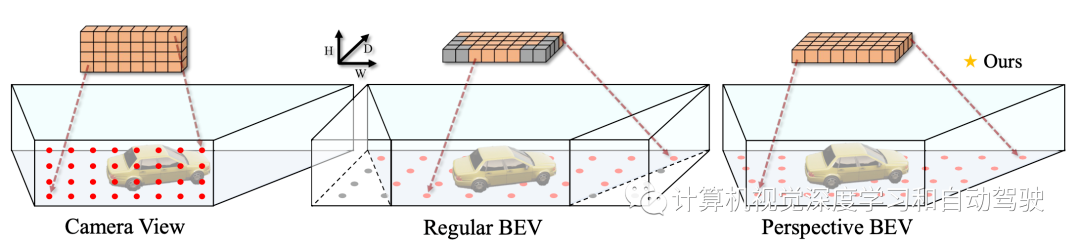
如图所示,CV检测器沿着高度和宽度轴在图像平面中放置锚点。这些锚点自然地与从图像中提取的下采样特征图对齐。相反,BEV检测器的锚点分布在宽度轴和深度轴之间,因为BEV特征的语义对应于水平参考平面的目标。
由于Lift-Splat方法最初设计用于分割任务,因此这些锚点通常均匀分布在参考平面上。这种分布带来了特征采样的要求-透视效果在投影特征中进行,但不在锚点中进行。
本文建议将透视效应引入锚点,而不是将其从特征中移除。在这种情况下,语义信息可以与真实世界的锚点对齐,无需特征采样。此外,由于现有方法中的特征采样操作通常伴随着由过采样和欠采样现象引起的信息丢失和结构失真,因此去除特征采样会带来额外的性能增益。
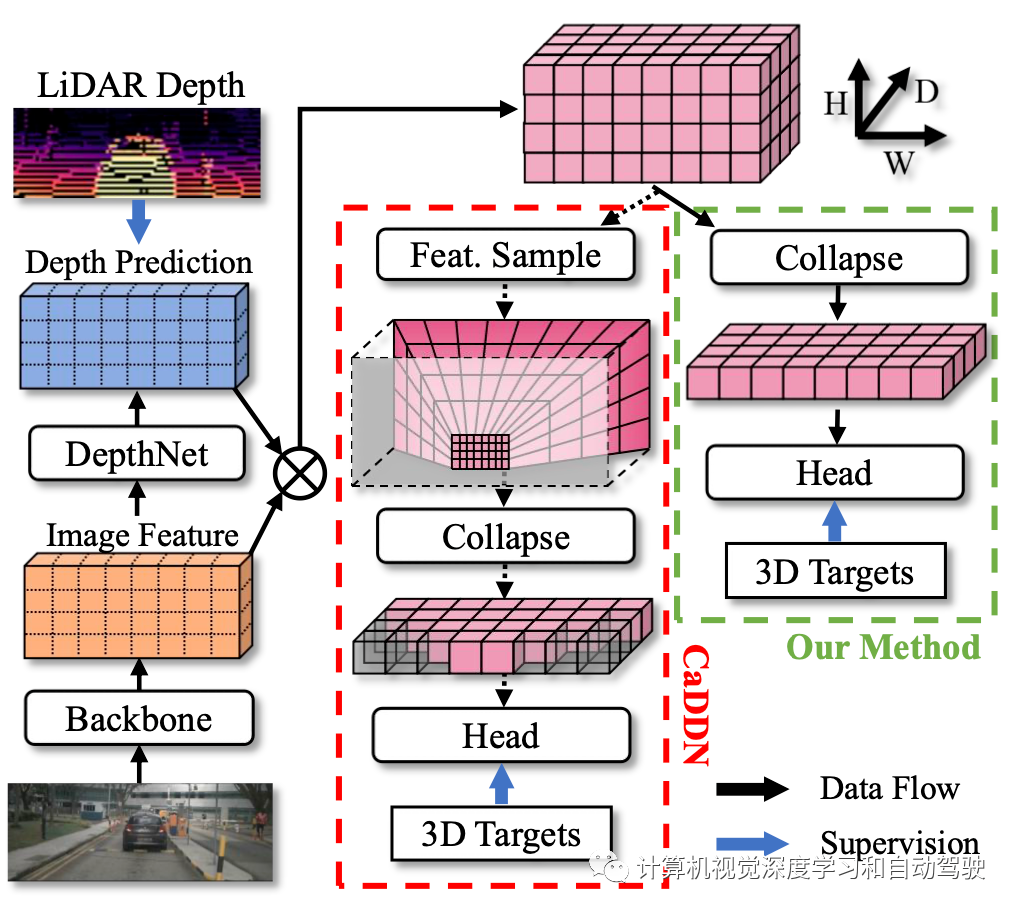
以CaDDN为代表的现有BEV检测器遵循Lift-splat的模式,其中采用特征提取器和DepthNet进行特征提取和深度预测。深度预测由激光雷达获得的真值深度单独监督。注意,激光雷达深度仅在训练期间使用;检测器仅拍摄图像进行测试和验证。如图所示,BEV检测框架使用3D边框和深度监督执行统一训练。
原文:
小姐姐,哎呦,你干嘛~
最近小姐姐 ikun 跳舞又火了,你干嘛~

今天讲解一个让 ikun 们狂喜的算法。单张图片人体 3D 重建算法 ICON,它来了!
给一张彩色图片,将二维纸片人,还原成拥有丰富几何细节的三维数字人。
这个算法今年上半年就发布了,最近开源了训练代码,又发布了Hugging Face的网页体验版,不用部署环境就能玩,所以我就把这个压箱底的算法发出来,再跟大家聊聊。

按照作者的话说,ICON 的贡献就是:
对于小内行——ICON把PIFu/PaMIR的姿态鲁棒性提升到了可直接给SCANimate做训练数据的水准;
对于更广泛的同行——ICON显著提高了从单张图片中做三维穿衣人重建的姿势水平;
对于吃瓜群众——元宇宙基建(开个小玩笑)。
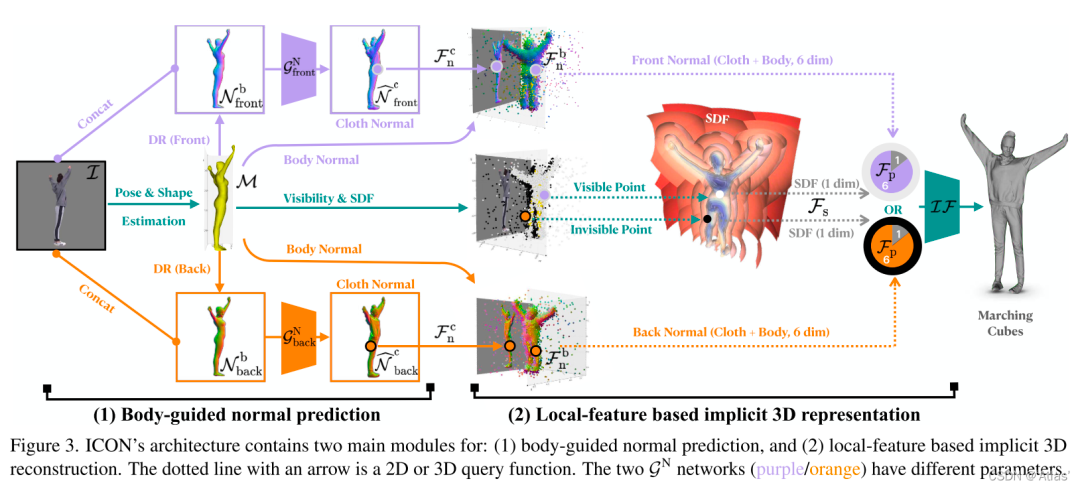
mesh-based方法具有很好的正则化,而深层隐式函数具有更强的表现力;ICON将两者结合。ICON输入穿衣的人体RGB图及SMPL人体估计,输出穿衣的像素级3D重构结果。
原文:不盲追大模型与堆算力!沈向洋、曹颖与马毅提出理解 AI 的两个基本原理:简约性与自一致性
近两年,“大力(算力)出奇迹”的大模型成为人工智能领域多数研究者的追求趋势。然而,其背后巨大的计算成本与资源耗费问题也弊端渐显,一部分科学家开始对大模型投以严肃的目光,并积极寻求解决之道。新的研究表明,要实现 AI 模型的优秀性能,并不一定要依靠堆算力与堆规模。
深度学习火热十年,不得不说,其机遇与瓶颈在这十年的研究与实践中已吸引了大量的目光与讨论。
其中,瓶颈维度,最引人注意的莫过于深度学习的黑盒子特性(缺乏可解释性)与“大力出奇迹”(模型参数越来越大,算力需求越来越大,计算成本也越来越高)。此外,还有模型的稳定性不足、安全漏洞等等问题。
而本质上,这些问题部分是由深度神经网络的“开环”系统性质所引起。要破除深度学习的 B 面“魔咒”,单靠扩大模型规模与堆算力或许远远不够,而是要追根溯源,从构成人工智能系统的基本原理,从一个新的视角(如闭环)理解“智能”。
7月12日,人工智能领域的三位知名华人科学家马毅、曹颖与沈向洋便联名在arXiv上发表了一篇文章,“On the Principles of Parsimony and Self-Consistency for the Emergence of Intelligence”,提出了一个理解深度网络的新框架:压缩闭环转录(compressive closed-loop transcription)。
这个框架包含两个原理:简约性(parsimony)与自洽性/自一致性(self-consistency),分别对应 AI 模型学习过程中的“学习什么”与“如何学习”,被认为是构成人工/自然智能的两大基础,在国内外的人工智能研究领域引起了广泛关注。

三位科学家认为,真正的智能必须具备两个特征,一是可解释性,二是可计算性。
然而,在过去十年,人工智能的进步主要基于使用“蛮力”训练模型的深度学习方法,在这种情况下,虽然 AI 模型也能获得功能模块来进行感知与决策,但学习到的特征表示往往是隐式的,难以解释。
此外,单靠堆算力来训练模型,也使得 AI 模型的规模不断增大,计算成本不断增加,且在落地应用中出现了许多问题,如神经崩溃导致学习到的表征缺少多样性,模式崩溃导致训练缺乏稳定性,模型对适应性和对灾难性遗忘的敏感性不佳等等。
三位科学家认为,之所以出现上述问题,是因为当前的深度网络中,用于分类的判别模型和用于采样或重放的生成模型的训练在大部分情况下是分开的。此类模型通常是开环系统,需要通过监督或自监督进行端到端的训练。而维纳等人早就发现,这样的开环系统不能自动纠正预测中的错误,也不能适应环境的变化。
因此,他们主张在控制系统中引入“闭环反馈”,让系统能够学习自行纠正错误。在这次的研究中,他们也发现:用判别模型和生成模型组成一个完整的闭环系统,系统就可以自主学习(无需外部监督),并且更高效,稳定,适应性也强。

END

爱我就给我点在看
 点击 “阅读原文”进入官网
点击 “阅读原文”进入官网

