CUDA作为一个并行数据计算设备的图形处理器单元,仅仅几年的时间,可编程的图形处理器单元演变成为了一匹绝对的计算悍马,当极高的内存带宽驱动多核处理器时,当今的GPU 为图型和非图型处理提供了难以置信的资源。本文参考自“NVIDIA CUDA编程指南”。GPU编程技术可参考基于GPU统一内存优化的图计算框架设计、GPU技术专题下载链接、(OpenACC基本介绍、CUDA CC 编程介绍、CUDA Fortr基本介绍)、深度报告:GPU研究框架、CPU和GPU研究框架合集。
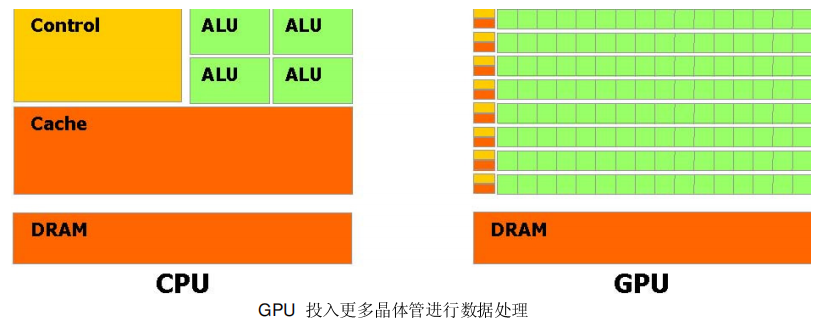
这个演变背后的主要原因是由于GPU 被设计用于高密度和并行计算,更确切地说是用于图形渲染。因此更多的晶体管被投入到数据处理而不是数据缓存和流量控制。GPU 是特别适合于并行数据运算的问题-同一个程序在许多并行数据元素,并带有高运算密度(算术运算与内存操作的比例)。由于同一个程序要执行每个数据元素,降低了对复杂的流量控制要求; 并且,因为它执行许多数据元素并且据有高运算密度,内存访问的延迟可以被忽略。并行数据处理,意味着数据元素以并行线程处理。许多处理大量数据集,例如数组的应用程序可以使用一个并行数据的编程模型来加速计算。在3D 渲染上,大的像素集和顶点被映射到并行线程。同样,图像和媒体处理的应用程序例如着色的图像后处理,录像编码和解码,图像缩放比例,立体视觉,以及图像识别也可以映射图像块和像素到并行处理线程。实际上,在图像着色和处理领域外的许多算法同样可以通过并行数据处理得到加速,从一般信号处理或物理模拟到金融计算或者生物计算。然而直到今天,尽管强大的计算能力包装进了GPU,而它对非图形应用的有效支持依然有限:- GPU 只能通过图型API 来编程,导致新手很难学习和非图形API 上很不充分的应用。
- GPU DRAM 可以用一般方式下读取,GPU 程序可以从任何DRAM 部分收集数据元素。但不可写,在一般方式下的GPU 程序不能写入信息到DRAM 的任何部分,相比CPU 丧失了很多编程的灵活性。
- 有些应用是由于DRAM 内存带宽而形成的瓶颈,未能充分利用GPU 的计算能力。
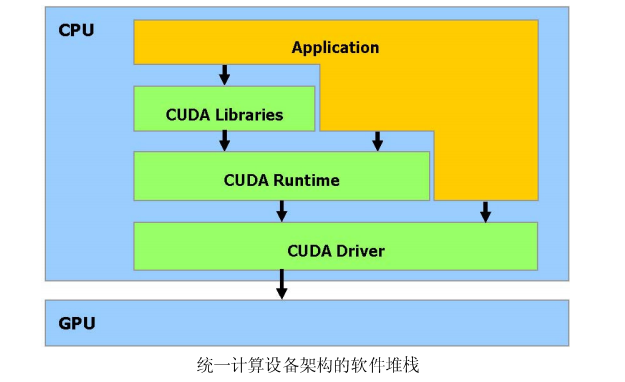
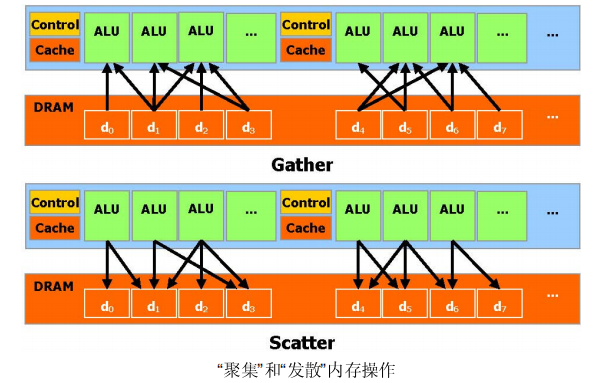
CUDA是一个在GPU 上计算的新架构CUDA(Compute Unified Device Architecture) 统一计算设备架构,在GPU 上发布的一个新的硬件和软件架构,它不需要映射到一个图型API 便可在GPU 上管理和进行并行数据计算。从G80 系列和以后的型号都可以支持。操作系统的多任务机制通过几个CUDA 和图型应用程序协调运行来管理访问GPU。CUDA 软件堆栈由几层组成,如图所示:一个硬件驱动程序,一个应用程序编程接口(API)和它的Runtime, 还有二个高级的通用数学库,CUFFT 和CUBLAS。硬件被设计成支持轻量级的驱动和Runtime 层面,因而提高性能。 CUDA API 更像是C 语言的扩展,以便最小化学习的时间。CUDA 提供一般DRAM 内存寻址方式:“发散” 和“聚集”内存操作,如图所示。从而提供最大的编程灵活性。从编程的观点来看,它可以在DRAM的任何区域进行读写数据的操作,就像在CPU 上一样。
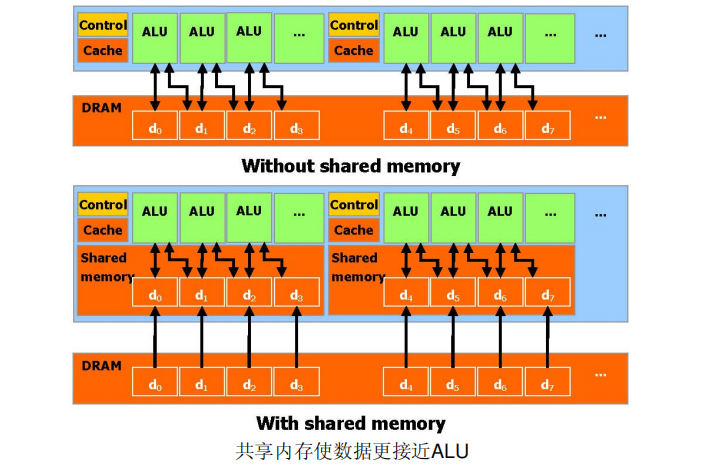
CUDA 允许并行数据缓冲或者在On-chip 内存共享,可以进行快速的常规读写存取,在线程之间共享数据。如图所示,应用程序可以最小化数据到DRAM 的overfetch 和round-trips ,从而减少对DRAM 内存带宽的依赖。
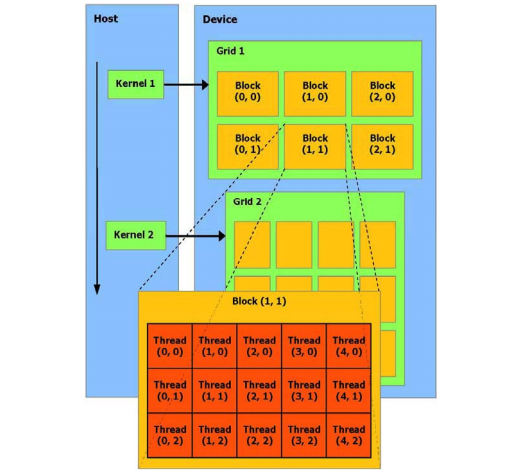
当通过CUDA 编译时,GPU 可以被视为能执行非常高数量并行线程的计算设备。它作为主CPU 的一个协处理器。换句话说,运行在主机上的并行数据和高密度计算应用程序部分,被卸载到这个设备上。更准确地讲,一个被执行许多次不同数据的应用程序部分,可以被分离成为一个有很多不同线程在设备上执行的函数。达到这个效果,这个函数被编译成设备的指令集(kernel 程序),被下载到设备上。主机和设备使用它们自己的DRAM,主机内存和设备内存。并可以通过利用设备高性能直接内存存取(DMA)的引擎(API)从一个DRAM 复制数据到其他DRAM。线程批处理就是执行一个被组织成许多线程块的kernel,如图所示。主机发送一个连续的kernel 调用到设备。每个kernel 作为一个由线程块组成的批处理线程来执行。一个线程块是一个线程的批处理,它通过一些快速的共享内存有效地分享数据并且在制定的内存访问中同步它们的执行。更准确地说,它可以在Kernel 中指定同步点,一个块里的线程被挂起直到它们所有都到达同步点。为一个应用程序使用多GPU 作为CUDA 设备,必须保证这些GPU 是一样的类型。如果系统工作在SLI 模式下,那么只有一个GPU 可以作为CUDA 设备,由于所有的GPU 在驱动堆栈中被底层的融合了。SLI 模式需要在控制面板中关闭,这样才能事多个GPU 作为CUDA设备。本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
电子书<服务器基础知识全解(终极版)>更新完毕。
获取方式:点击“阅读原文”即可查看182页 PPT可编辑版本和PDF阅读版本详情。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。