

《内存的故事》主要是三年前写的。趁这个假期写一个短续,枯燥地鸟瞰一下这几年内存行业的一些近况。
一、内存领域的现阶段问题是什么
内存是个不太好的俗称,其主要用途是两个:作为程序运行的空间(DRAM等)和存储数据的空间(NAND等)。
NAND进入3D时代以后,基本上容量就没有天花板了,所以这个我们放到最后再说。
现阶段的主要问题是DRAM:单位价格的容量增长缓慢和速度跟不上CPU。这个问题在商用领域特别明显,比如数据中心、高性能计算和运营商网络等。
此外DRAM能耗过高,因为它要在每个时钟周期给小电容们重新充电。
电费是商业用户的成本大头。在移动设备上,DRAM也是电池的死敌。
历史上DRAM为了增加带宽只能不断增加延时,那么把缓存加大如何呢?问题是,SRAM和CPU你中有我一样贵,而且六个晶体管才能存一个比特。Intel至强处理器的Cache,也只有DRAM的千分之一。
宇宙无敌的IBM Power 9 CPU配24个核也就120MB L3,代价是它的die size近700mm2,是苹果A13处理器的七倍!
(Power9中L2/L3占这么大面积才100多M)
内存行业的主要核心问题是日益增长的容量速度功耗需求和DRAM的技术瓶颈无法匹配。
二、DDR5
由于DRAM本身的局限性,它的技术进步一直很痛苦。DDR3到DDR4的小进步花了五年;DDR4从2012年发布第一版到今天DDR5还没有发布(注:显存GDDR5只是DDR3的变种)。
DRAM标准由JEDEC JC-42工作组制订。虽然有投票机制,但DRAM的节奏其实一直由英特尔主导。
原因很简单,英特尔确定PC路线图:CPU或北桥芯片决定什么时间支持新标准内存。
得益于半导体工艺的进步,DDR5的核心电压从DDR4的1.2V下降到1.1V,这有望节省20%的功耗。
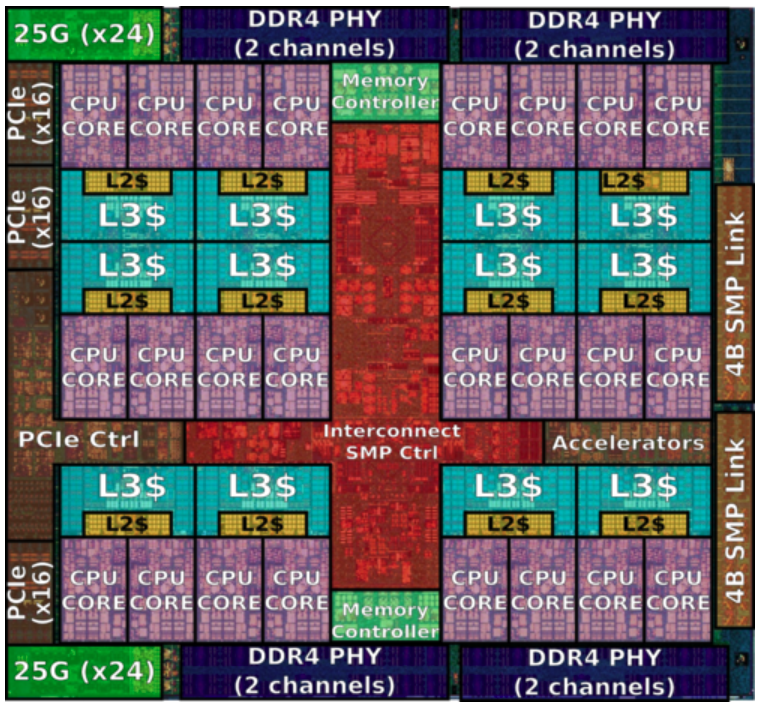
(DDR5可以使系统通道数再翻倍。图:Mircon)
DDR5的Burst Length和Prefetch (预读取)从DDR4的8n增加到16n,这样在时钟频率不变的情况下带宽翻倍。为了控制高速带来的各种信号干扰和抖动问题,DDR5还引入了核心时钟的各种优化调整。新的On-die ECC功能也是对服务器的大利好。
但这些这也将带来更多的设计、测试和兼容挑战,需要CPU(含内存控制器)的很大改动,从目前看大概要等到2022年。
三、LPDDR5
低功耗LPDDR5单独拿出来因为从LPDDR4开始已经和标准DDR分道扬镳了。
虽然LPDDR5和DDR5使用的新技术很多是共通的,但着眼点有很大不同。LPDDR5是功耗第一速度第二,而DDR5追求速度第一功耗第二。
因为LPDDR4已经是16n预读取,LPDDR5主要靠Bank group访问实现速度提升。它追求的是超低功耗,所以供电电压和核心电压比DDR5都更低。
x86领域的技术进步被英特尔带慢了节奏,但在手机领域则不同。
激烈的竞争和每年一次的旗舰产品发布使得各家不断比拼最新的技术。
LPDDR5就是个例子。
小米10率先使用LPDDR5确实是个big thing,这显示了高通激进的产品策略。一加8和三星S20的跟进基本上定了今年高端的调子。
华为则面临比较尴尬的处境,因为美商Micron是目前LPDDR5的主要供应商。三星估计优先供应自己,而Hynix似乎在标准DDR5更用心。在LPDDR5供应困难的情况下,华为要不要在下一代麒麟提供支持,从产品规划上是个两难。
三、HBM
对于迫切需要高带宽的应用,比如游戏和高性能计算,高带宽内存(HBM)则是绕过DRAM传统IO增强模式演进的优秀方案。
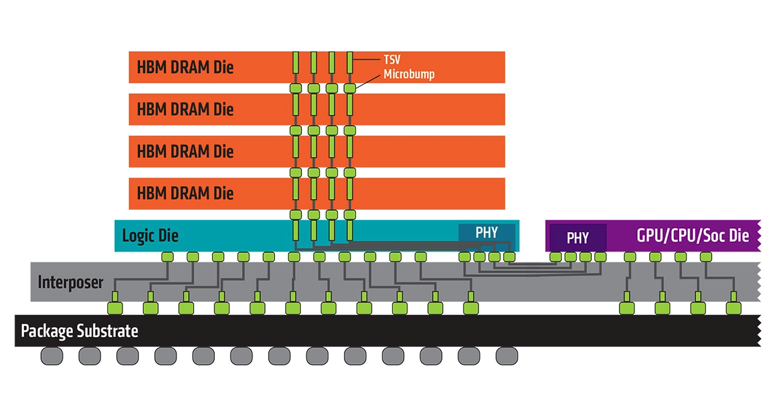 (图:AMD)
(图:AMD)
HBM直接和处理器封装的方式不再受限于芯片引脚,突破了IO带宽的瓶颈。另外DRAM和CPU/GPU物理位置的接近使得速度进一步提升。
在尺寸上,HBM也使整个系统的设计大大缩小成为可能。
在目前,HBM2在很大程度上是GDDR6的竞争对手。不过根据最新消息,Xbox Series X和索尼PS5仍旧选择了GDDR6,也许因为HBM2高昂的成本吧。
不过从长远看,DRAM仍有很强的3D化需求。因为2D在制造上(昂贵的10nm瓶颈)接近天花板。
四、NVDIMM
现在云计算虚拟机和各种内存数据库大行其道,服务器对大容量内存非常饥渴。但是由于DRAM成本很难进一步降低,如何低成本配置高容量内存变成一个难题。
混搭的NVDIMM被提了出来。
NVDIMM-F是直接用NAND颗粒替代DRAM做成内存条,好处是极其便宜,但它速度太慢而且并不能突破系统对DRAM总容量的访问限制。
NVDIMM-N是在内存条上加上NAND做DRAM的镜像存储,防止服务器意外断电丢失内存数据。但NAND并不能扩容内存而且占了一些通道带宽。
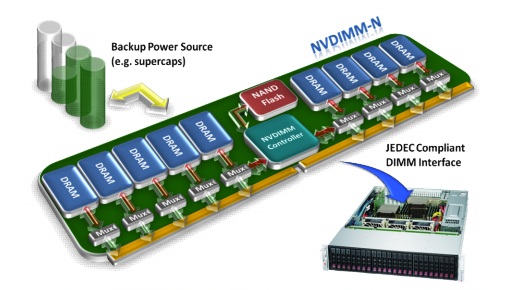
JEDEC NVDIMM-N示意图
最终的方案是NVDIMM-P,它允许巨大的容量比如1T内存,并允许用各种新式芯片比如NAND、RRAM、MRAM等替代DRAM。
目前还没有看到JEDEC NVDIMM-P的标准出来。但英特尔已经发布了3D-Xpoint为基础的Optane DIMM,自己平台支持自己是个巨大的优势,也是给竞争对手的一个大门槛。
五、3D-Xpoint和其它NV内存
3D-Xpoint是很有意思一个话题,号称速度比NAND快1000倍。
英特尔和Micron对3D-Xpoint的技术原理一直讳莫如深,甚至一丁点都不透露。开始有人猜它是3D NOR,后来大家认为它是相变内存(PCM)或RRAM。
市面上也没有看到有人剥开这颗芯片分析内部。
直到一个案卷中,让我们看到当代爱迪生Stanford Ovshinsky是其发明人。清算公司认为英特尔和Micron在Ovshinsky去世后公司破产处理中隐瞒了关键信息。
和Micron分家后,英特尔的3D-Xpoint将转到大连厂独家生产,不知道未来是否能有更多的小道消息。
3D-Xpoint技术在服务器领域增长潜力很大,但如何降低制造成本是关键。
MRAM、FRAM等其它NV类内存则在物联网、汽车和工业等领域寻找机会。
MRAM的工艺和传统MOS半导体工艺类似,这有助于其扩大生产而降低成本,最终有机会在一些嵌入式应用取代部分NOR、SRAM或DRAM。
那么速度更快的PCM和RRAM是否能取代NAND呢?似乎短期不会实现,因为存储数据的速度要求一般没那么高,而3D NAND的低成本容量暴增实在是太成功了。
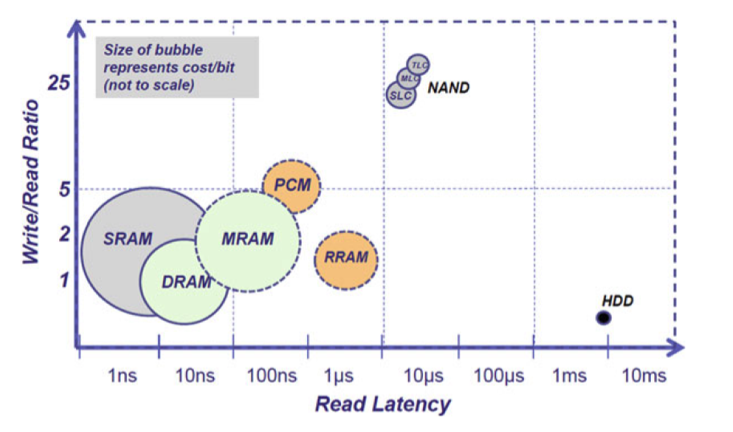
(旧图:对比不同内存的成本和速度)
五、3D NAND
对于3D NAND来讲,单个cell缩小变得没有意义,因此不再需要最尖端的半导体制程技术。Hynix最近说,3D NAND未来可以叠800层。
盖楼过程光刻环节减少了,而沉积和蚀刻等工序大大增加,蚀刻之王泛林成为最大赢家。
这导致的另一个影响是DRAM和NAND的产线和产能不再能灵活互补。
蚀刻下图这种楼梯达百层和以及蚀刻长孔是有挑战性的。楼梯是连接位线的,长孔则是著名的充电陷阱(Charge Trap)。
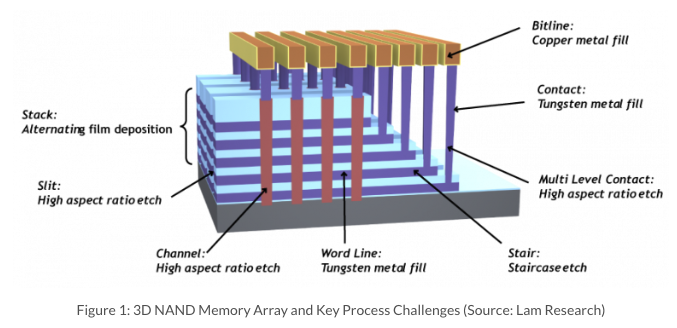
记得英飞凌/奇梦达是最早用以色列Saifun公司技术量产Charge Trap闪存的。但当时技术不成熟,擦写寿命只有Floating Gate的1/10。Jim Handy说Charge Trap蚀刻孔的工艺来源自Trench技术。
在《内存的故事》里提到过当初IBM、英飞凌、东芝和AMD是早期半导体技术结盟的,后来奇梦达用Trench独战群雄最后败北。但Charge Trap蚀刻技术倒是延续了下来:AMD的后代Spansion把它用在了NOR Flash上,而东芝则做出领先的BiCS 3D NAND。
现在坚守Floating Gate的只剩英特尔一家了。我的理解是FG每层都需要光刻,这样的工艺复杂度会导致其失去竞争力,退出市场可能是难以避免的。
前些天看长江存储发布的128层Xtacking技术很有意思,它把存储阵列和控制电路分开。这样可以大大降低开发和革新周期,但对量产挑战不小。看到的具体技术细节不多,如果是wafer-to-wafer bonding,即使不考虑bonding良率,成品良率是两片晶圆良率相乘的关系。
3D NAND的延续和DDR5标准的难产则对于目前正在起步的中国内存业则是个非常好的追赶良机。
很高兴看到长鑫存储已经开始量产主流的DDR4,而其在知识产权和专利上的远见布局也令人赞叹。
脚踏实地和志存高远大概是内存行业的不二法门吧。
参考阅读:
《内存的故事》
《内存的故事》-Rambus
《内存的故事》-金士顿
