本篇文章遇到排版混乱的地方,可点击文末阅读原文或前往该地址:https://orangey.blog.csdn.net/article/details/123002359
更多关于Android安全的知识,可前往:https://blog.csdn.net/ananas_orangey/category_11955914.html
关于正则表达式,很多人认为,使用的时候查询下就行,没必要深入学习,但是知识与应用永远都是螺旋辩证的关系,有需要查询也无可厚非,但是先掌握知识,可以让应用更创新,更深入,超越他人,必须要先掌握大量的深刻的知识。
但是学习正则并非易事:知识点琐碎、记忆点多、符号乱,难记忆、难描述、广而深且,说了那么多,开始正文吧
正则表达式又称规则表达式,计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本,是对字符串操作的一种逻辑公式,是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
正则表达式使用一种符号系统,允许以最小的努力匹配复杂的文本模式。虽然对于正则表达式的语法没有正式的标准化,但是对于语法的基本元素有一个普遍的共识
正则表达式是处理字符串的强大工具,它有自己特定的语法结构,有了它,实现字符串的检索、替换、匹配验证、在HTML里提取想要的信息都是简简单单的事
例如,Windows下用于文件查找的通配符(wildcard),也就是*和?。如果想查找某个目录下的所有的Word文档的话,搜索*.doc。在Windows这里,*会被解释成任意的字符串。和通配符类似,正则表达式也是用来进行文本匹配的工具,只不过比起通配符,它能更精确地描述你的需求
例1:匹配以数字开头,并以 abc 结尾的字符串
^ [0-9] + abc $
定位符 字符集 限定符 普通字符 限定符
例2:
[a-zA-z]+://[^\s]*
PS:上面是正则表达式的特定语法规则组合,通过这些组合,就可以得到想要的字符,例如,\s表示匹配任意的空白字符,*代表匹配前面的字符任意多个等等。常用的匹配字符规则如下表:
| 模式 | 描述 |
|---|---|
\l | 把下一个字符转换为小写 |
\L | 把\L到\E之间的字符全部转换为小写 |
\u | 把下一个字符转换为大写 |
\U | 把\U到\E之间的字符全部转换为大写 |
\w | 匹配字母、数字及下划线 |
\W | 匹配不是字母、数字及下划线的字符;匹配任意不是字母,数字,下划线,汉字的字符 |
\s | 匹配任意空白字符,相当于{\t\n\r\f} |
\s*$ | 匹配一个字符串的结尾位置零个或多个空白字符 |
\S | 匹配任意非空白字符;匹配任意不是空白符的字符 |
\d | 匹配任意数字,等价于[0-9] |
\D | 匹配任意非数字字符 |
\A | 匹配字符串开头 |
\Z | 匹配字符串的结尾,如果存在换行,只匹配到换行前的字符串 |
\z | 匹配字符串的结尾,如果存在换行,同时还会匹配换行符 |
\G | 匹配最后完成匹配的位置 |
\B | 匹配不是单词开头或结束的位置 |
\b | 指定单词的边界,用来匹配一个单词的开头和结尾;匹配且只匹配一个位置,不匹配任何字符 |
\f | 换页符 |
\n | 匹配换行符 |
\t | 匹配制表符 |
\r | 回车符 |
\v | 垂直制表符 |
\v | 垂直制表符 |
\1…\9 | 匹配第n个分组的内容 |
\10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式 |
\E | 结束\L或\U转换 |
\p | 匹配CR/LF (等同于 \r\n),用来匹配 DOS 行终止符 |
\ | 转移字符,将后一个字符标记为一个特殊字符 |
^ | 匹配一行字符串的开头;匹配输入字串的开始位置 |
^\s* | 匹配一个字符串的开头位置和随后的零个或多个空白字符 |
$ | 匹配一行字符串的结尾;匹配输入字串的结束位置 |
$1、$2、...、$99 | 与 regexp 中的第 1 到第 99 个子表达式相匹配的文本 |
$& | 与 regexp 相匹配的子串 |
$` | 位于匹配子串左侧的文本 |
$' | 位于匹配子串右侧的文本 |
$$ | 直接量符号 |
. | 匹配除换行符外的任意字符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符;匹配到除"\n"之外的所有单个字符 |
[…] | 用来表示一组字符单独列出,比如[amk]匹配a,m,k;表示一个字符集,可以单个列出,如[amk$];也可以加一个"-"表示一个字符范围,如[a-z];匹配任意一个字符即可;也可以用补集来匹配不在区间范围内的字符。其做法是把""作为类别的首个字符;其它地方的""只会简单匹配""字符本身,例如[5] 将匹配除"5"之外的任意字符;代表多选一,比如[abc]可以匹配到字母a,也可以匹配到字母b或c |
[a-z] | 匹配a到z之间的任意元素,\w这个通配符就可以用【a-zA-Z0-9_】来表示 |
[^a-n] | 补集,匹配除 "a" 到 "n" 的其他字符 |
[^…] | 否定的字符种类. 匹配除了方括号里的任意字符;不在[]中的字符,比如^abc,表示匹配除了a,b,c之外的字符;取反,不能是括号内的任意单个元素 |
[^x] | 匹配除了x以外的任意字符 |
[^aeiou] | 匹配除了aeiou这几个字母以外的任意字符 |
* | 匹配0个或多个表达式;匹配前面的子表达式0次或多次 |
*? | 重复任意次,但尽可能少重复 |
+ | 匹配1个或多个表达式;匹配前面的子表达式1次或多次 |
+? | 重复1次或更多次,但尽可能少重复 |
? | 匹配0个或1个前面正则表达式定义的片段(非贪婪匹配);匹配前面的子表达式0次或1次;如果打算同时使用[] 和 ?,千万记得应该把?放在字符集合的外面 |
?= | 正先行断言-存在 |
?! | 负先行断言-排除 |
?<= | 正后发断言-存在 |
? | 负后发断言-排除 |
?? | 重复0次或1次,但尽可能少重复 |
{n} | 精确匹配n个前面的表达式 |
{n,} | 重复n次或更多次 |
{n,}? | 重复n次以上,但尽可能少重复 |
{n,m} | 匹配n到m次,由前面正则表达式匹配的片段(贪婪匹配);匹配至少n次,至多m次 |
{n,m}? | 重复n到m次,但尽可能少重复 |
a\|b | 匹配a或b |
( ) | 匹配括号内的表达式,也表示一个组;代表把子表达式当做一个独立元素,子表达式允许多重嵌套,但在实际工作中一个遵循适可而止的原则 |
(?=) | 正向前查找 |
(?!) | 负向前查找 |
(?<=) | 正向后查找 |
(? | 匹配exp,并捕获文本到名称为name的组里,也可以写成(?'name'exp) |
(? | 负向后查找 |
(?m) | 分行模式匹配 |
(?imx) | 正则表达式包含三种可选标志:i, m, 或 x。只影响括号中的区域 |
(?-imx) | 正则表达式关闭i, m, 或 x可选标志。只影响括号中的区域 |
(?: re) | 类似(…),但是不表示一个组;匹配re,不捕获匹配的文本,也不给此分组分配组号 |
(?imx: re) | 在括号中使用i, m, 或 x可选标志 |
(?-imx: re) | 在括号中不使用i, m, 或 x可选标志 |
(?#comment) | 这种类型的分组不对正则表达式的处理产生任何影响,用于提供注释让人阅读 |
(?= re) | 前向肯定界定符。如果所含正则表达式,以…表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边 |
(?! re) | 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功 |
(?> re) | 匹配的独立模式,省去回溯 |
\r\n | Windows 所使用的文本行结束标签 |
\n\n | 在 Linux 上匹配空白行使用 |
\r\n | 同时适用于 Windows 和 Linux 的正则表达式应该包含一个可选的 \r 和一个必须被匹配的 \n |
\x | 十六进制(逢16进1)数值要用前缀\x来给出 |
\0 | 八进制(逢8进1)数值要用前缀\0来给出 |
| | 替换字符,匹配|前或后的表达式;表示逻辑 或 操作符 |
x\|y | 匹配 x 或 y。例如,'z|food'匹配"z"或"food"。'(z|f)ood'匹配"zood"或"food" |
标志
标志也叫模式修正符,因为它可以用来修改表达式的搜索结果。这些标志可以任意的组合使用,它也是整个正则表达式的一部分
| 标志 | 描述 |
|---|---|
| i | 忽略大小写 |
| g | 全局搜索 |
| m | 多行的:锚点元字符^ $工作范围在每行的起始 |
运算符优先级:
优先级为从上到下,依次降低:
| 运算符 | 说明 | 优先级 |
|---|---|---|
\ | 转义符 | 最高 |
()、(?:)、(?=)、[] | 括号和中括号 | 高 |
*、+ 、? 、{n} 、{n,} 、{n,m} | 限定符 | 中 |
^、$ 、\任何元字符 | 定位点和序列 | 低 |
| | 选择 | 最低 |
正则表达式的工作机制
写的任何一个正则直接量或者 RegExp 都会被浏览器编译为一个原生代码程序。第一次匹配是从头个字符开始,匹配成功时,他会查看是否还有其他的路径没有匹配到,如果有的话,回退到上一次成功匹配的位置,然后重复第二步操作,不过此时开始匹配的位置(lastIndex)是上次成功位置加 1
| 编译 |
+--------+
|
↓
+----------------+
| 设置开始位置 |←---------+
+----------------+ ↑
| |
↓ 其 |
+----------------+ 他 |
| 匹配 & 回溯 | 路 |
+----------------+ 径 |
| |
↓ |
+----------------+ |
| 成功
or
失败 |---------→+
+----------------+
在爬虫以及处理数据包中,用得最多的匹配字符,如下:
.:匹配除换行符外的任意字符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符;匹配到除"\n"之外的所有单个字符
*:匹配0个或多个表达式;匹配前面的子表达式0次或多次
?:匹配0个或1个前面正则表达式定义的片段(非贪婪匹配);匹配前面的子表达式0次或1次
():匹配括号内的表达式,也表示一个组
\d:匹配任意数字,等价于[0-9]
{n}:精确匹配n个前面的表达式
$:匹配一行字符串的结尾;匹配输入字串的结束位置
^:匹配一行字符串的开头;匹配输入字串的开始位置
\b回退(删除)一个字符
代表着单词的开头或结尾,也就是单词的分界处
例1:匹配orangey
\borangey\b
虽然通常英文的单词是由空格,标点符号或者换行来分隔的,但是\b并不匹配这些单词分隔字符中的任何一个,它只匹配一个位置
例2:匹配orangey后面的blog
\borangey\b.*\bblog\b
PS:上面正则中.是另一个元字符,匹配除了换行符以外的任意字符。*同样是元字符,不过它代表的不是字符,也不是位置,而是数量——它指定*前边的内容可以连续重复使用任意次以使整个表达式得到匹配。因此,.*连在一起就意味着任意数量的不包含换行的字符。现在\borangey\b.*\bblog\b的意思:先是一个单词orangey,然后是任意个任意字符(但不能是换行),最后是blog这个单词
PS:如果需要更精确的说法,\b匹配这样的位置:它的前一个字符和后一个字符不全是(一个是,一个不是或不存在)\w
正则表达式的语法很令人头疼,即使对经常使用它的人来说也是如此。由于难与读和写,容易出错,利用工具对正则表达式进行测试是否正确,是很需要的,如下是正则表达式在线校验工具:
https://c.runoob.com/front-end/854
https://tool.oschina.net/regex#
https://regex101.com 能可视化展示正则匹配结果
https://regexper.com 能够直观展示正则表达式的状态机图
正则表达式在线编写教程文档
https://ihateregex.io
https://github.com/geongeorge/i-hate-regex
https://deerchao.cn/tutorials/regex/regex.htm
https://blog.csdn.net/lxcnn
https://github.com/ziishaned/learn-regex/blob/master/translations/README-cn.md
Python正则表达HOWTO 学习教程
https://docs.python.org/zh-cn/3.7/howto/regex.html#regex-howto
正则表达式最初的想法来自两位神经学家:沃尔特·皮茨与麦卡洛克,他们研究出了一种用数学方式来描述神经网络的模型
一位名叫Stephen Kleene的数学科学家发表了一篇题目是《神经网事件的表示法》的论文,利用称之为正则集合的数学符号来描述此模型,引入了正则表达式的概念。正则表达式被作为用来描述其称之为“正则集的代数”的一种表达式,因而采用了“正则表达式”这个术语
C语言之父、UNIX之父肯·汤普森把这个“正则表达式”的理论成果用于做一些搜索算法的研究,他描述了一种正则表达式的编译器,于是出现了应该算是最早的正则表达式的编译器qed(这也就成为后来的grep编辑器)。
Unix使用正则之后,正则表达式不断的发展壮大,然后大规模应用于各种领域,根据这些领域各自的条件需要,又发展出了许多版本的正则表达式,出现了许多的分支。我们把这些分支叫做“流派”。
Perl语言诞生了,它综合了其他的语言,用正则表达式作为基础,开创了一个新的流派,Perl流派。
注:Perl语言是一种擅长处理文本的语言,Larry在1987年创建,Practical Extraction and Report Language,实用报表提取语言,但因晦涩语法和古怪符号不利于理解和记忆导致很多开发人员并不喜欢
在实际使用中,我们常常需要匹配同一类型的字符多次,比如匹配11位的手机号,我们不可能将 [0-9] 写11遍,此时我们可以使用Quantifiers来实现重复匹配
{n}:匹配 n 次
{n,m}:匹配 n-m 次
{n,}:匹配 >=n 次
?:匹配 0 || 1 次
*:匹配 >=0 次,等价于 {0,}
+:匹配 >=1 次,等价于 {1,}
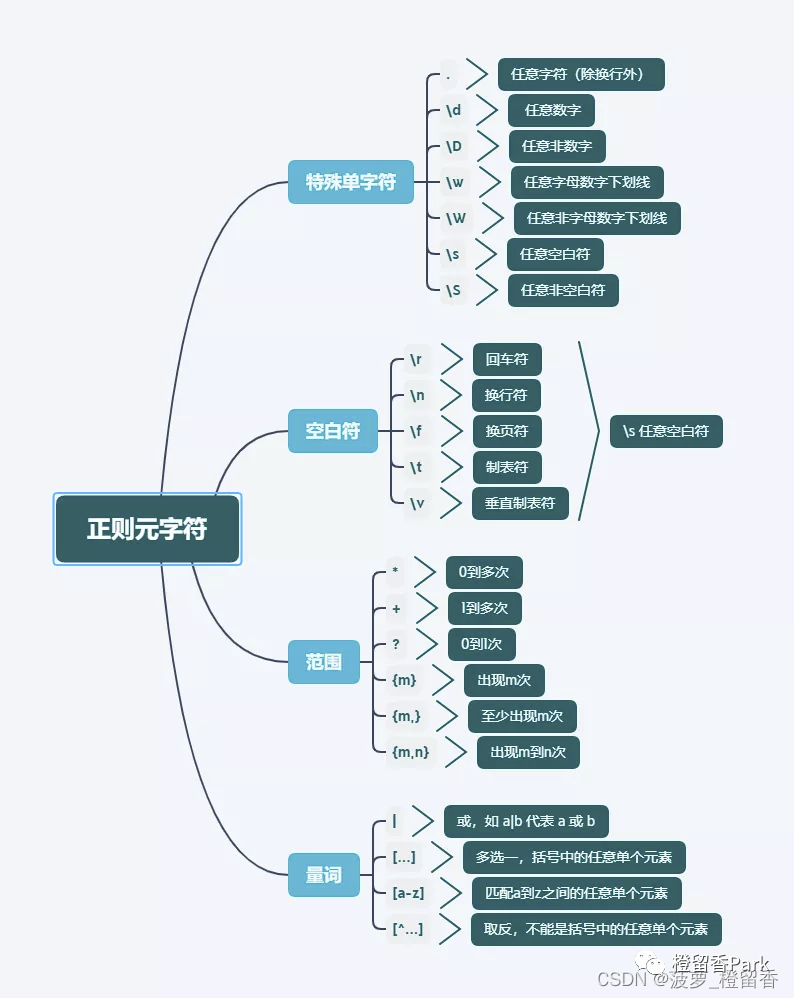
完整的正则表达式由两种字符构成:特殊字符(元字符)和普通字符。元字符表示正则表达式功能的最小单位,如* ^ $ \d等。正则表达式里还有更多的元字符,比如\s匹配任意的空白符,包括空格,制表符(Tab),换行符,中文全角空格等。\w匹配字母或数字或下划线或汉字等
元字符:
基本元字符
数量元字符
位置元字符
特殊元字符
在默认模式,匹配除了换行的任意字符。
\:转义特殊字符(允许你匹配'*','?',或者此类其他特殊字符)
[]:用于表示一个字符集合
|:A|B,A和B可以是任意正则表达式,创建一个正则表达式,匹配A或者B,任意个正则表达式可以用'|'连接。它也可以在组合内使用
-:可以表示字符范围,通过用'-'将两个字符连起来。比如[a-z]将匹配任何小写ASCII字符,[0-5][0-9]将匹配从00到59的两位数字,[0-9A-Fa-f]将匹配任何十六进制数位
():匹配器整体为一个原子,即模式单元可以理解为多个原子组成的大原子
\转义特殊字符(允许你匹配'*','?', 或者此类其他特殊字符),或者表示一个特殊序列;要牢记使用反斜杠\作为转义序列
例如,查找.或者*,得使用\来取消这些字符的特殊意义,使用\.和\*。当然,要查找\本身,你也得用\\.
例如:
baidu\.com匹配baidu.cn
C:\\Windows匹配C:\Windows
[]用于匹配字符集合中的任意一个字符,常见的字符集有:
[xyz]:匹配 "x"或"y"`"z"`
[^xyz]:补集,匹配除"x" "y" "z"的其他字符
[a-z]:匹配从"a" 到 "z"的任意字符
[^a-n]:补集,匹配除"a" 到 "n"的其他字符
[A-Z]:匹配从"A" 到 "Z"的任意字符
[0-9]:匹配从"0" 到 "9"的任意数字
比如匹配所有的字母和数字可以写成:/[a-zA-Z0-9]/或者/[a-z0-9]/i
字符可以单独列出,如下:
文本:awbwi
正则:[bai]
运行结果:匹配'a','b',或者'i'
特殊字符在集合中,失去它的特殊含义。如[(+*)]只会匹配这几个文法字符'(', '+', '*', 或')'
因为已有了对应数字、字母、数字,空白这些字符集合的元字符,所以查找起来会很简单,但如果想匹配没有预定义元字符的字符集合(比如元音字母b,a,i,d,u),应该怎么办?
很简单,你只需要在方括号里列出它们就行了,像[aeiou]就匹配任何一个英文元音字母,[.?!]匹配标点符号(.或?或!)。
例1:匹配任何一个英文元音字母或
[baidu]
例2:匹配标点符号(.或?或!)
[.?!]
也可指定一个字符范围,像[0-9]代表的含意与\d是等价的:一位数字;同理[a-z0-9A-Z_]也完全等同于\w(如果只考虑英文的话)
更复杂的字符类表达式
\(?0\d{2}[) -]?\d{8}
PS:首先是一个转义字符\(,它能出现0次或1次(?),然后是一个0,后面跟着2个数字(\d{2}),然后是)或-或空格中的一个,它出现1次或不出现(?),最后是8个数字(\d{8})。这个表达式可匹配几种格式的电话号码,像(010)77779999,或022-44556677,或02912345678等
例3:匹配从00到59的两位数字
文本:012234456789
正则:[0-5][0-9]
运行结果:匹配'01','22','34',或者'45'
PS:可以表示字符范围,通过用'-'将两个字符连起来。比如[a-z]将匹配任何小写ASCII字符,[0-5][0-9]将匹配从00到59的两位数字,[0-9A-Fa-f]将匹配任何十六进制数位。如果-进行了转义(比如[a\-z])或者它的位置在首位或者末尾(如[-a]或[a-]),它就只表示普通字符'-'
字符类如\w或者\S在集合内可以接受,它们可以匹配的字符由ASCII或LOCALE模式决定
例1:
匹配以字母a开头的单词——先是某个单词开始处(\b),然后是字母a,然后是任意数量的字母或数字(\w*),最后是单词结束处(\b)
\ba\w*\b
例2:
匹配1个或更多连续的数字。这里的+是和*类似的元字符,不同的是*匹配重复任意次(可能是0次),而+则匹配重复1次或更多次
\d+
例3:
匹配刚好9个字符的单词
\b\w{9}\b
不在集合范围内的字符可以通过取反来进行匹配。如果集合首字符是'^',所有不在集合内的字符将会被匹配,比如[^5]将匹配所有字符,除了'5',[^^]将匹配所有字符,除了'^'.^如果不在集合首位,就没有特殊含义
例4:
验证填写账号必须为3位到10位数字时
^\d{3,10}$
PS:元字符^(和数字6在同一个键位上的符号)和$都匹配一个位置,这和\b有点类似。^匹配你要用来查找的字符串的开头,$匹配结尾
{3,10}的意思是重复的次数不能少于3次,不能多于10次,否则都不匹配
因为使用了
^和$,所以输入的整个字符串都要用来和\d{3,10}来匹配,也就是说整个输入必须是3到10个数字,如果输入的账号能匹配这个正则表达式的话,既满足要求;对于\d{3,10}而言,使用这样的方法就只能保证字符串里包含3到10连续位数字,而不是整个字符串就是3到10位数字。和忽略大小写的选项类似,有些正则表达式处理工具还有一个处理多行的选项。如果选中了这个选项,
^和$的意义就变成了匹配行的开始处和结束处
例5:
文本:TM1
正则:[^TM]
运行结果:1
|A|B,A和B可以是任意正则表达式,创建一个正则表达式,匹配A或者B,任意个正则表达式可以用'|'连接。
它也可以在组合内使用。
扫描目标字符串时,'|'分隔开的正则样式从左到右进行匹配。当一个样式完全匹配时,这个分支就被接受。意思就是,一旦A匹配成功,B就不再进行匹配,即便它能产生一个更好的匹配。或者说'|'操作符绝不贪婪。如果要匹配'|'字符,使用|,或者把它包含在字符集里,比如[|]。
例5:
文本:awe
正则:[a|w]
运行结果:匹配a或w
文本:wpdmw
正则:p|m
运行结果:匹配p或m
--可以表示字符范围,通过用'-'将两个字符连起来。比如[a-z]将匹配任何小写ASCII字符,[0-5][0-9]将匹配从00到59的两位数字,[0-9A-Fa-f]将匹配任何十六进制数位。
例如:查找所有1-5之间的自然数
文本:012234456789
正则:[1-5]
运行结果:匹配'1','2','2','3','4','4',或者'5'
<p data-line="468" class="sync-line" style="margin:0;">
PS:可以表示字符范围,通过用'-'将两个字符连起来。比如[a-z]将匹配任何小写ASCII字符,[0-5][0-9]将匹配从00到59的两位数字,[0-9A-Fa-f]将匹配任何十六进制数位。如果-进行了转义(比如[a\-z])或者它的位置在首位或者末尾(如[-a]或[a-]),它就只表示普通字符'-'
()匹配器整体为一个原子,即模式单元可以理解为多个原子组成的大原子
例如:查找所有1-5之间的自然数
文本:012234456789
正则:([1-5])
运行结果:匹配'1','2','2','3','4','4',或者'5'
<p data-line="483" class="sync-line" style="margin:0;">
数量元字符:
*
+
?
*?, +?, ??
{m}
{m,n}
{m,n}?
*,+,{5},{7,13}这几个匹配重复的方式了。下面表格是正则表达式中常用的限定符(指定数量的代码,例如*,{7,13}等
常用的限定符
| 模式 | 描述 |
|---|---|
* | 匹配0个或多个表达式;匹配前面的子表达式0次或多次;代表出现0到多次,可以出现,也可以不出现,出现的话,不限制次数 |
+ | 匹配1个或多个表达式;匹配前面的子表达式1次或多次;代表出现1到多次,也就是至少出现一次的意思 |
? | 匹配0个或1个前面正则表达式定义的片段(非贪婪匹配);匹配前面的子表达式0次或1次;代表出现0到1次,比如Http协议的正则就可以用 Https? 表示 |
{n} | 精确匹配n个前面的表达式;代表出现n次,比如 a{1} 就表示匹配的规则中,字母a只能出现1次 |
{n,} | 重复n次或更多次;至少出现n次,{0,} 相当于星号,{1,} 相当于加号 |
{n,m} | 匹配n到m次,由前面正则表达式匹配的片段(贪婪匹配);匹配至少n次,至多m次;代表出现n到m次,{0,1} 相当于问号 |
*对它前面的正则式匹配0到任意次重复,例1:
文本:121122
正则:12*
运行结果:匹配'12','1',或者'122'
# 只重复2,尽量多的匹配字符串
例2:重复.0到任意次,.有代表任意字符,所有d.*c能匹配dc之间包含任意字符
文本:d123456cwel
正则:d.*c
运行结果:d123456c
+对它前面的正则式匹配1到任意次重复。ab+会匹配'a'后面跟随1个以上到任意个'b',它不会匹配'a'
文本:ababbbbaabbcaacb
正则:ab+
运行结果:匹配'ab','abbbb',或者'abb'
?对它前面的正则式匹配0到1次重复。ab?会匹配'a'或者'ab
文本:ababbbbaabbcaacb
正则:ab?
运行结果:匹配'ab','ab','a','ab','a',或者'a'
*?, +?, ??'*','+',和'?'的懒惰模式,'*','+','?'修饰符都是贪婪的,它们在字符串进行尽可能多的匹配。有时候并不需要这种行为。在修饰符之后添加'?'将使样式以非贪婪方式或者dfn最小方式进行匹配,尽量少的字符将会被匹配
文本:ababbbbaabbcaacb
正则:ab*?
运行结果:匹配'a','a','a','a','a',或者'a'
<p data-line="558" class="sync-line" style="margin:0;">
{m}对其之前的正则式指定匹配m个重复,少于m的话就会导致匹配失败。比如,a{6}将匹配6个'a',但是不能是5个
文本:ababbbbaabbcaacb
正则:ab{2}
运行结果:匹配'abb',或者'abb'
<p data-line="568" class="sync-line" style="margin:0;">
{m,n}对正则式进行m到n次匹配,在m和n之间取尽量多,比如a{3,5}将匹配3到5个'a'。忽略m意为指定下界为0,忽略n指定上界为无限次。比如a{4,}b将匹配'aaaab'或者10000000个'a'尾随一个'b',但不能匹配'aaab'。逗号不能省略,否则无法辨别修饰符应该忽略哪个边界
文本:ababbbbaabbcaacb
正则:ab{2,}
运行结果:匹配'abbbb',或者'abb'
<p data-line="580" class="sync-line" style="margin:0;">
文本:ababbbbaabbcaacb
正则:a{2}b{2,4}
运行结果:匹配'aabb'
<p data-line="588" class="sync-line" style="margin:0;">
文本:ababbbbaabbcaacb
正则:ab{2,4}
运行结果:匹配'abbbb',或者'abb'
<p data-line="594" class="sync-line" style="margin:0;">
# 匹配前一个字符(或者子表达式至少m次)
<p class="mume-header " id="匹配前一个字符或者子表达式至少m次">
<p data-line="595" class="sync-line" style="margin:0;">
{m,n}?非贪婪模式{m,n}?修饰符的非贪婪模式,只匹配尽量少的字符次数。比如对于'aaaaaa',a{3,5}匹配5个'a',而a{3,5}?只匹配3个'a'
文本:ababbbbaabbcaacb
正则:ab{2,4}?
运行结果:匹配'abb',或者'abb'
文本:aaaaaa
正则:a{3,5}
运行结果:匹配'aaaaa'
文本:ababbbbaabbcaacb
正则:a{3,5}?
运行结果:匹配'aaa',或者'aaa'
位置元字符:
^
$
\A
\Z
\b
\B
^匹配字符串的开头是否包含正则表达式, 并且在MULTILINE模式也匹配换行后的首个符号
例1:匹配字符串开头是否包含weY
文本:Hello Baidu
正则:^[weY]
运行结果:未匹配成功
例2:匹配开头是否包含weH
文本:Hello Baidu
正则:^[weH]
运行结果:H
例3:匹配开头是否包含2个以上的a
文本:bbaidu
正则:^b{2,}
运行结果:bb
$匹配字符串尾或者在字符串尾的换行符的前一个字符,在MULTILINE模式下也会匹配换行符之前的文本。foo匹配 'foo' 和 'foobar',但正则表达式foo$只匹配 'foo'。在'foo1\nfoo2\n'中搜索foo.$,通常匹配'foo2',但在MULTILINE模式下可以匹配到'foo1';在'foo\n'中搜索$会找到两个(空的)匹配:一个在换行符之前,一个在字符串的末尾
例1:
文本:baidu
正则:baidu
运行结果:baidu
例2:
文本:baidudd
正则:baidu
运行结果:baidu
例3:
文本:baidu
正则:baidu$
运行结果:baidu
例4:
文本:bai du
正则:[iu]
运行结果:匹配'i',或者'u'
例5:
文本:bai du
正则:[iu]$
运行结果:u
\b匹配空字符串,但只在单词开始或结尾的位置。一个单词被定义为一个单词字符的序列。注意,通常\b定义为\w和\W字符之间,或者\w和字符串开始/结尾的边界,意思就是'\bfoo\b'匹配'foo','foo.','(foo)','bar foo baz'但不匹配'foobar'或者'foo3'。
文本:baidu
正则:\bbaidu\b
运行结果:baidu
文本:aaa baidu bb
正则:baidu.
运行结果:baidu
默认情况下,Unicode字母和数字是在Unicode样式中使用的,但是可以用ASCII标记来更改。如果 LOCALE 标记被设置的话,词的边界是由当前语言区域设置决定的,\b表示退格字符
\B匹配空字符串,但不能在词的开头或者结尾。意思就是'ba\B'匹配'baidu','bai','bai2',但不匹配'ba','ba.',或者'ba!' ``````.\B是\b的取非,所以Unicode样式的词语是由Unicode字母,数字或下划线构成的,虽然可以用ASCII标志来改变。如果使用了LOCALE标志,则词的边界由当前语言区域设置
文本:baidu
正则:ba\B
运行结果:ba
文本:ba
正则:ba\B
运行结果:未匹配
在正则表达式中,普通字符表示的还是原来的意思,比如表达式 1 可以匹配到数字 1,表达式 a 可以匹配到字母 a。
但是如果想要匹配到更多字符的时候,不可能把所有的字符都列一遍,这样就太浪费时间了,那有什么更好的办法呢?特殊元字符能帮到我们的忙
特殊元字符:
\d
\D
\s
\S
\w
\W
[\b]
.
\d数字通配符,可以匹配到数字0-9
对于Unicode (str) 样式:匹配任何Unicode十进制数(就是在Unicode字符目录[Nd]里的字符)。这包括了[0-9],和很多其他的数字字符。如果设置了ASCII标志,就只匹配[0-9]
对于8位(bytes)样式:匹配任何十进制数,就是[0-9]
文本:aa1bb2ccc3dddd4e5ee
正则:\d
运行结果:匹配'1','2','3','4',或者'5'
\D如果将D大写,则匹配到的是任意非数字,相当于 \d 的反义
匹配任何非十进制数字的字符。就是\d取非。如果设置了ASCII标志,就相当于[^0-9]
文本:aa1bb2ccc3dddd4e5ee
正则:\d
运行结果:
a
a
b
b
c
c
c
d
d
d
d
e
e
e
\s空白符通配符,可以配到任意空白符,包括回车、换行、换页、制表符等
对于 Unicode (str) 样式:匹配任何Unicode空白字符(包括[ \t\n\r\f\v],还有很多其他字符,比如不同语言排版规则约定的不换行空格)。如果ASCII被设置,就只匹配[ \t\n\r\f\v]
对于8位(bytes)样式:匹配ASCII中的空白字符,就是[ \t\n\r\f\v]
文本:aa1bb2c cc3 dddd4e5ee
正则:\s
运行结果:匹配到两处
空白符分为下图中的几类,一般用 \s表示:
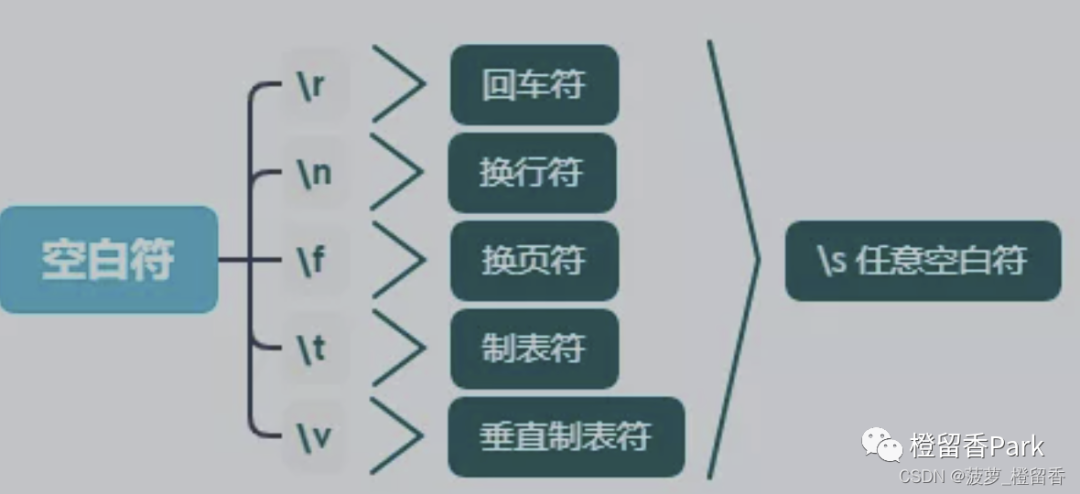
空白符:
\r:回车符
\n:换行符
\f:换页符
\t:制表符
\v:垂直制表符
\S如果将S大写,则匹配到的是任意非空白符
匹配任何非空白字符。就是\s取非。如果设置了ASCII标志,就相当于[^ \t\n\r\f\v]
文本:aa1bb2c cc3 dddd4e5ee
正则:\S+
运行结果:匹配'aa1bb2c','cc3',或者'dddd4e5ee'
\w字母数字下划线通配符,可以匹配到任意的字母数字下划线
对于Unicode (str) 样式:匹配Unicode词语的字符,包含了可以构成词语的绝大部分字符,也包括数字和下划线。
对于8位(bytes)样式:匹配ASCII字符中的数字和字母和下划线,就是[a-zA-Z0-9_]。如果设置了LOCALE标记,就匹配当前语言区域的数字和字母和下划线
文本:aa1Baidubb2c cc3 dddd4e5ee
正则:\w+
运行结果:匹配'aa1Baidubb2c','cc3',或者'dddd4e5ee'
\W如果将W大写,则匹配到的是任意非字母数字下划线
匹配任何不是单词字符的字符。这与\w正相反。如果使用了ASCII旗标,这就等价于[^a-zA-Z0-9_]。如果使用了LOCALE旗标,则会匹配在当前区域设置中不是字母数字又不是下划线的字符
文本:aa1Baidubb无2ccc3dddd4e5ee
正则:\W+
运行结果:匹配'无'
[\b]它只在字符集合内表示退格,比如[\b]
例1:匹配Baidu后面跟1个或更多数字
Baidu\d+
例2:匹配一行的第一个单词(或整个字符串的第一个单词,具体匹配哪个意思得看选项设置)
^\B+
..点号通配符,可以匹配到除换行外的任意字符:
文本:Baidu_*&N<S.x/
正则:.
运行结果:
B
a
i
d
u
_
*
&
N
<
S
.
x
/
<p data-line="896" class="sync-line" style="margin:0;">
... ...
更多内容请前往原文地址
参考链接:
https://deerchao.cn/tutorials/regex/regex.htm
https://docs.microsoft.com/zh-cn/dotnet/standard/base-types/regular-expressions
https://docs.microsoft.com/zh-cn/dotnet/api/system.text.regularexpressions.regex?view=net-6.0
https://www.regular-expressions.info/
https://weblogs.asp.net/whaggard/377025
https://mp.weixin.qq.com/s/lX0-GjqYBUo4KncrpngcTw
https://mp.weixin.qq.com/s/tfzsPRiEjDGfO1BoPNu2RA
https://mp.weixin.qq.com/s/7rflGRsMioF3S2TX8TP_1Q
https://mp.weixin.qq.com/s/0sVMQDstgIZEpYZUvRNadg
https://mp.weixin.qq.com/s/JnmjFVg9IuLMgOKV8Z918g
https://mp.weixin.qq.com/s?__biz=MzI3NjY1OTA0NQ==&mid=2247484108&idx=1&sn=66ee027ffe1bbdf08ea0616f9d648277&chksm=eb736cc6dc04e5d0be33c3c9756b6dc37379f0e27f6982ec214fa85f70a42b303cf455f13766&scene=178&cur_album_id=2245264853273903105#rd
