CPU、IO、磁盘、内存,可以说是影响计算机性能的几大关键因素。今天,我们就来探究一下内存的那些事儿。
提示:本文内容较长,阅读大约需要35分钟,建议收藏起来慢慢看。
内存为进程的运行提供物理空间,同时作为快速CPU和慢速磁盘之间的适配器,可以说是个非常重要的角色。
通过本文你将了解到以下内容:
本文均围绕Linux操作系统展开,话不多说,我们开始吧!
当要学习一个新知识点时,比较好的过程是先理解出现这个技术点的背景原因,同期其他解决方案,新技术点解决了什么问题以及它存在哪些不足和改进之处,这样整个学习过程是闭环的。
老子的著名观点是无为而治,简单说就是不过多干预而充分依靠自觉就可以有条不紊地运作,理想是美好的,现实是残酷的。
Linux系统如果以一种原始简单的方式管理内存是存在一些问题:
假如现在有ABC三个进程运行在Linux的内存空间,设定OS给进程A分配的地址空间是0-20M,进程B地址空间30-80M,进程C地址空间90-120M。
虽然分配给每个进程的空间是无交集的,但仍然无法避免进程在某些情况下出现访问异常的情况,如下图所示:
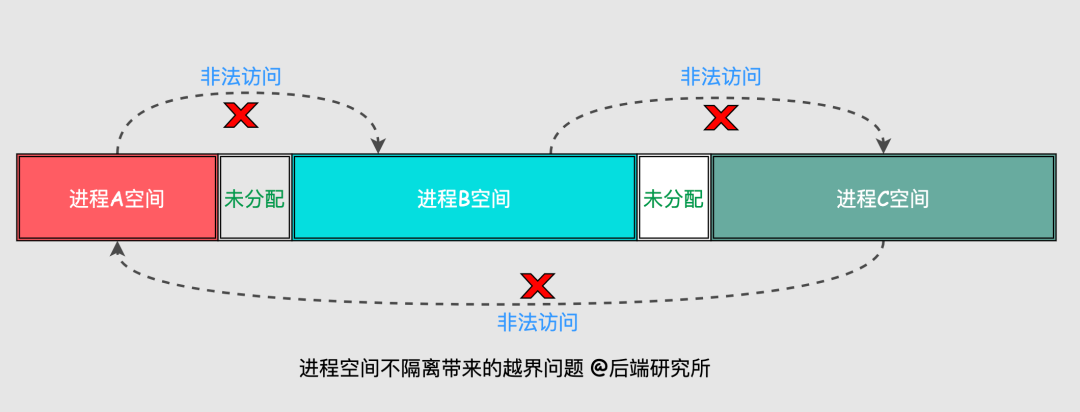
比如,进程A访问了属于进程B的空间,进程B访问了属于进程C的空间,甚至修改了空间的值,这样就会造成混乱和错误,实际中是不允许发生的。
所以,我们需要的是每个进程有独立且隔离的安全空间。
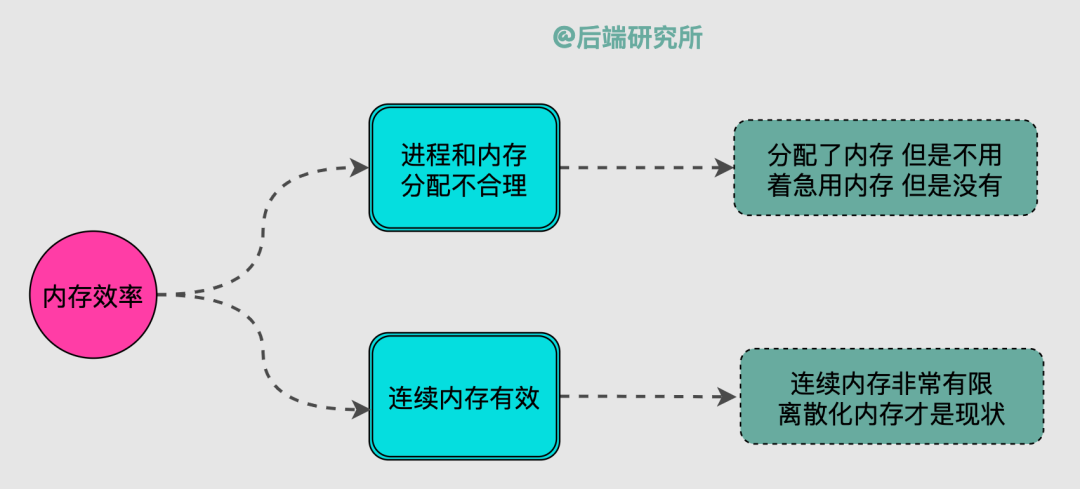
机器的内存是有限资源,而进程数量是动态且无法确定的,这样就会出现几个必须要考虑的问题:
如果已经启动的进程们占据了几乎所有内存空间,没有新内存可分配了,此时新进程将无法启动。
已经启动的进程有时候是在睡大觉,也就是给了内存也不用,占着茅坑不拉屎。
连续内存实在是很珍贵,大部分时候我们都无法给进程分配它想要的连续内存,离散化内存才是我们需要面对的现实。
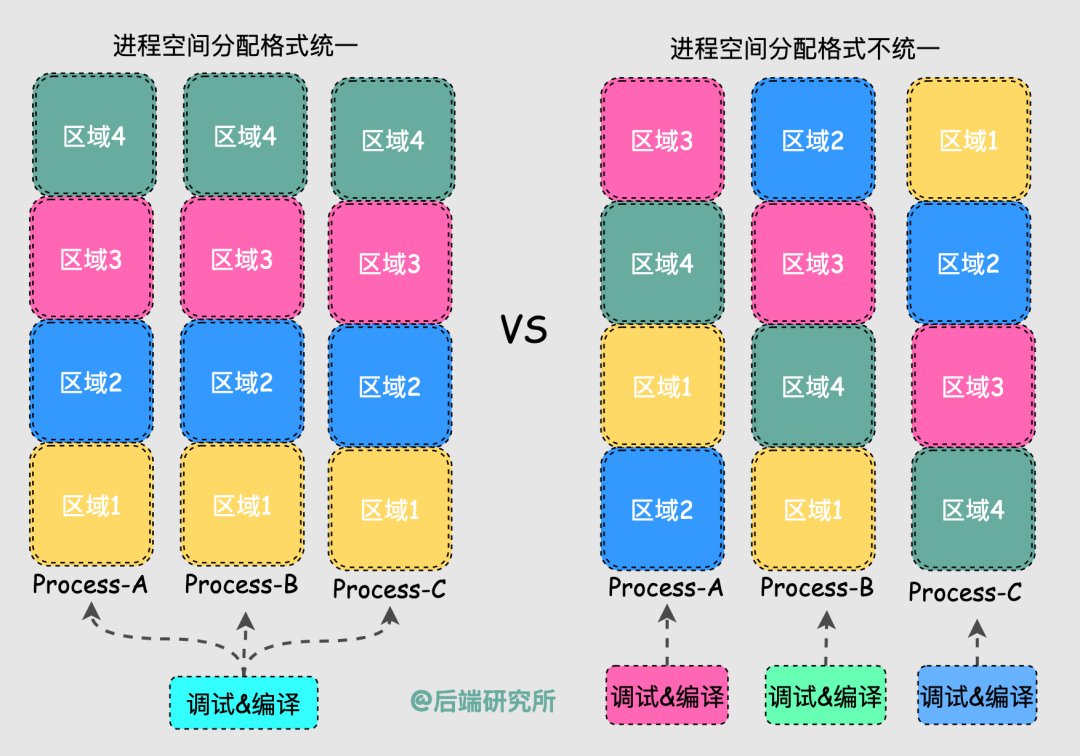
由于程序运行时的位置是不确定的,我们在定位问题、调试代码、编译执行时都会存在很多问题。
我们希望每个进程有一致且完整的地址空间,同样的起始位置放置了堆、栈以及代码段等,从而简化编译和执行过程中的链接器、加载器的使用。
换句话说,如果所有进程的空间地址分配都是一样的,那么Linux在设计编译和调试工具时就非常简单了,否则每个进程都可能是定制化的。
综上,面对众多问题,我们需要一套内存管理机制。
大家一定听过这句计算机谚语:
Any problem in computer science can be solved by another layer of indirection.
计算机科学领域的任何问题都可以通过增加一个中间层来解决,解决内存问题也不例外。
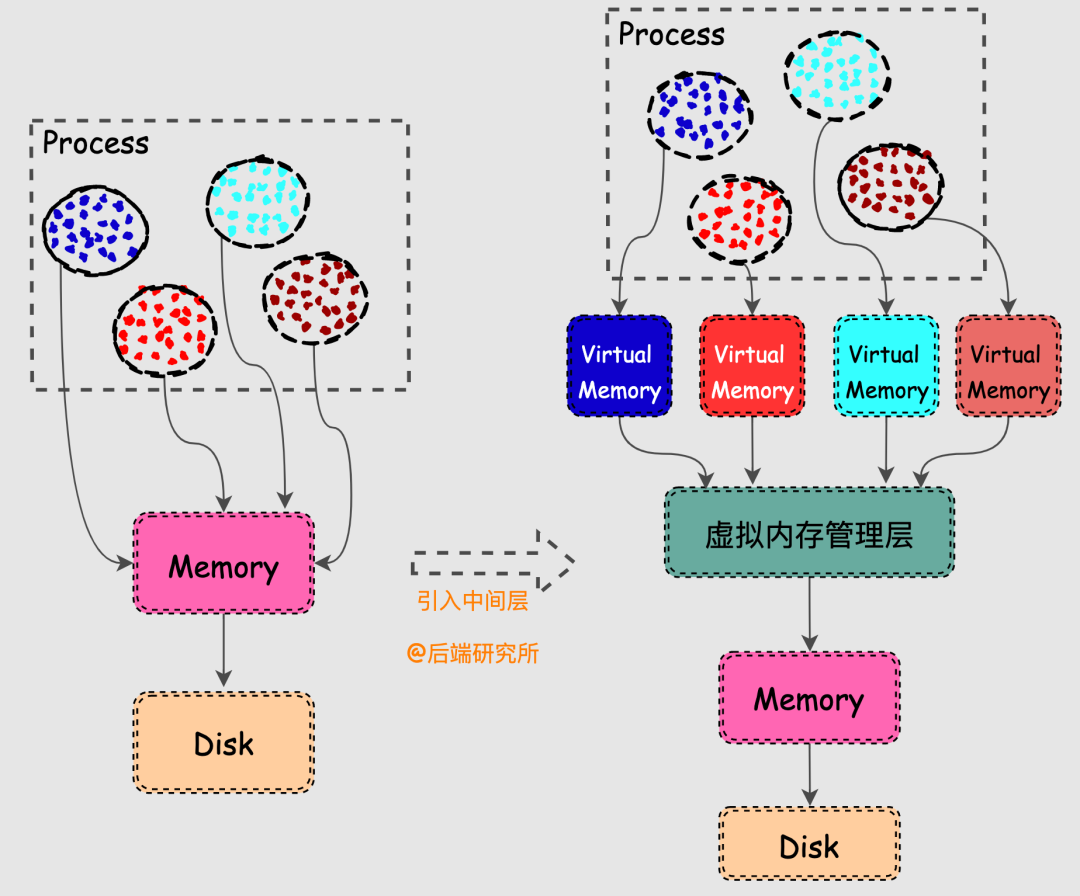
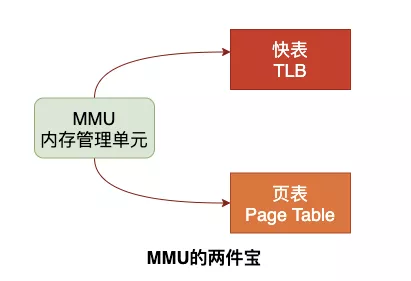
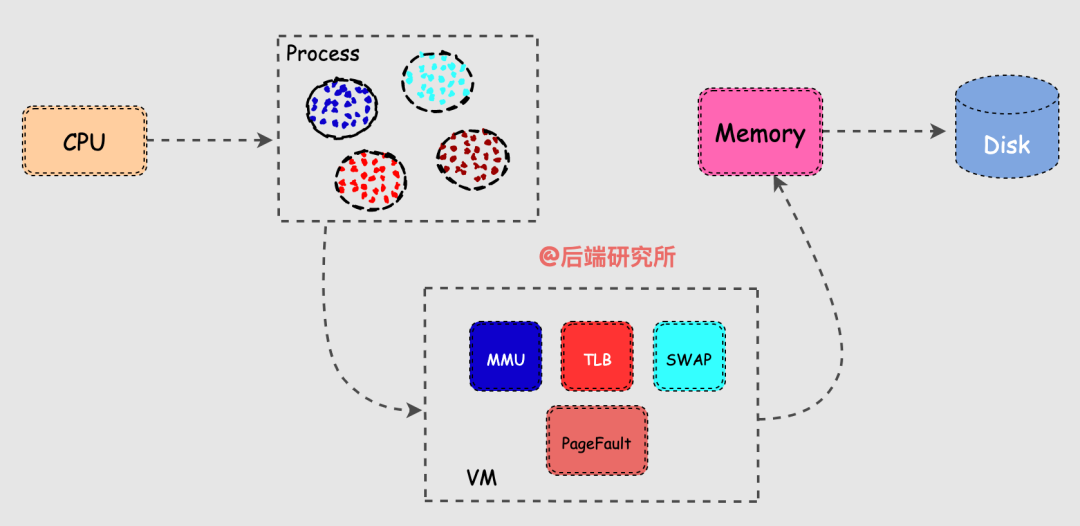
Linux的虚拟内存机制简单来说就是在物理内存和进程之间请了个管家,内存管家上任之后做了以下几件事情:
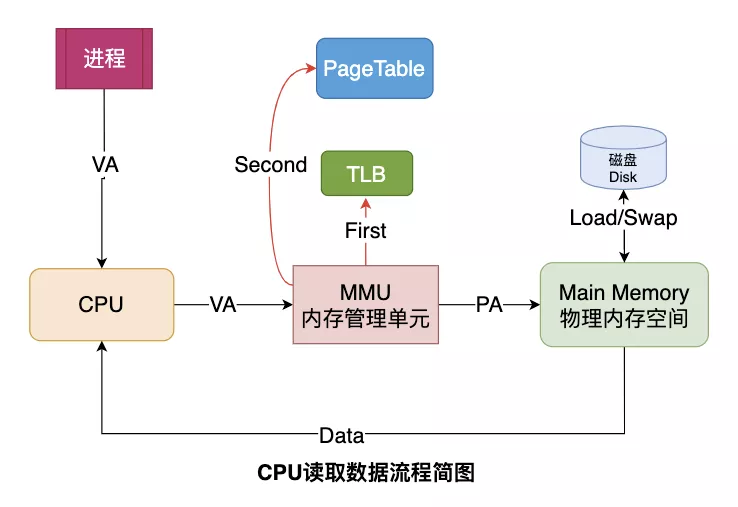
引入虚拟机制后,进程在获取CPU资源读取数据时的流程也发生了一些变化。
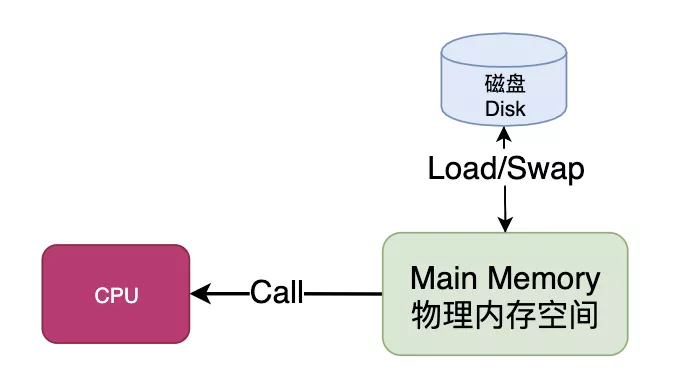
CPU并不再直接和物理内存打交道,而是把地址转换的活外包给了MMU,MMU是一种硬件电路,其速度很快,主要工作是进行内存管理,地址转换只是它承接的业务之一。
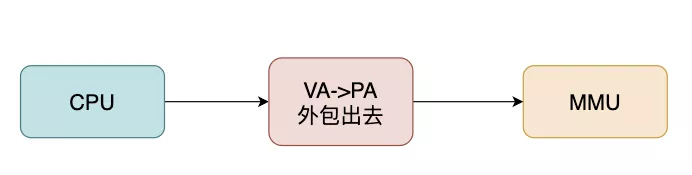
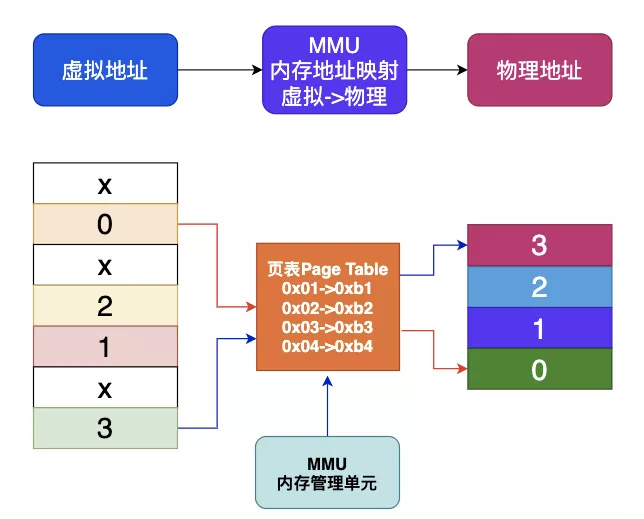
每个进程都会有自己的页表Page Table,页表存储了进程中虚拟地址到物理地址的映射关系,所以就相当于一张地图,MMU收到CPU的虚拟地址之后开始查询页表,确定是否存在映射以及读写权限是否正常,如下图所示:
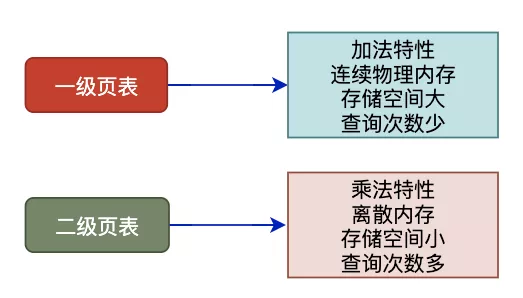
当机器的物理内存越来越大,页表这个地图也将非常大,于是问题出现了:
我们以2级页表为例,MMU要先进行两次页表查询确定物理地址,在确认了权限等问题后,MMU再将这个物理地址发送到总线,内存收到之后开始读取对应地址的数据并返回。
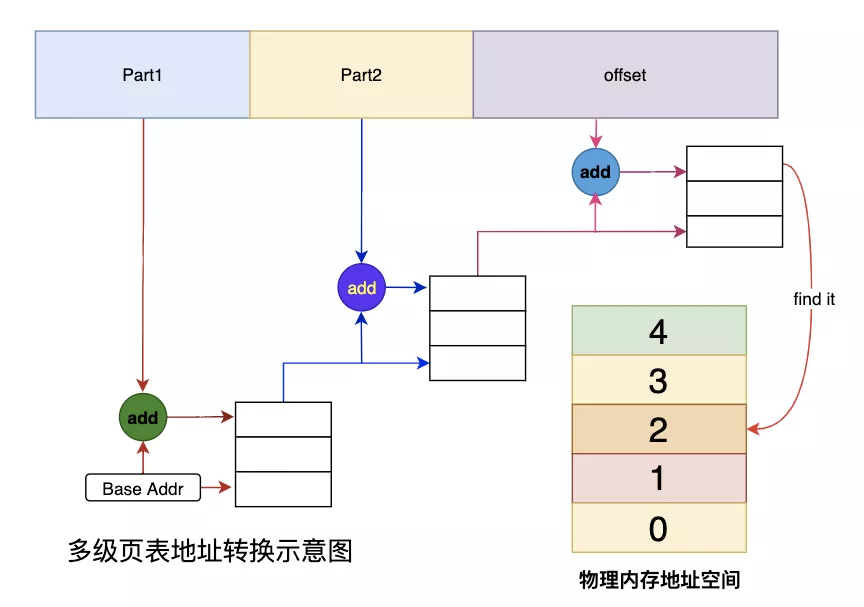
MMU在2级页表的情况下进行了2次检索和1次读写,那么当页表变为N级时,就变成了N次检索+1次读写。
可见,页表级数越多查询的步骤越多,对于CPU来说等待时间越长,效率越低,这个问题还需要优化才行。
本段小结 敲黑板 划重点
页表存在于进程的内存之中,MMU收到虚拟地址之后查询Page Table来获取物理地址。
单级页表对连续内存要求高,于是引入了多级页表。
多级页表也是一把双刃剑,在减少连续存储要求且减少存储空间的同时降低了查询效率。
CPU觉得MMU干活虽然卖力气,但是效率有点低,不太想继续外包给它了,这一下子把MMU急坏了。
MMU于是找来了一些精通统计的朋友,经过一番研究之后发现CPU用的数据经常是一小搓,但是每次MMU都还要重复之前的步骤来检索,害,就知道埋头干活了,也得讲究方式方法呀!
找到瓶颈之后,MMU引入了新武器,江湖人称快表的TLB,别看TLB容量小,但是正式上岗之后干活还真是不含糊。
当CPU给MMU传新虚拟地址之后,MMU先去问TLB那边有没有,如果有就直接拿到物理地址发到总线给内存,齐活。
TLB容量比较小,难免发生Cache Miss,这时候MMU还有保底的老武器页表 Page Table,在页表中找到之后MMU除了把地址发到总线传给内存,还把这条映射关系给到TLB,让它记录一下刷新缓存。
TLB容量不满的时候就直接把新记录存储了,当满了的时候就开启了淘汰大法把旧记录清除掉,来保存新记录,仿佛完美解决了问题。
本段小结 敲黑板 划重点
MMU也是个聪明的家伙,集成了TLB来存储CPU最近常用的页表项来加速寻址,TLB找不到再去全量页表寻址,可以认为TLB是MMU的缓存。
假如目标内存页在物理内存中没有对应的页帧,或者存在但无对应权限,CPU 就无法获取数据,这种情况下CPU就会报告一个缺页错误。
由于CPU没有数据就无法进行计算,CPU罢工了用户进程也就出现了缺页中断,进程会从用户态切换到内核态,并将缺页中断交给内核的 Page Fault Handler 处理。
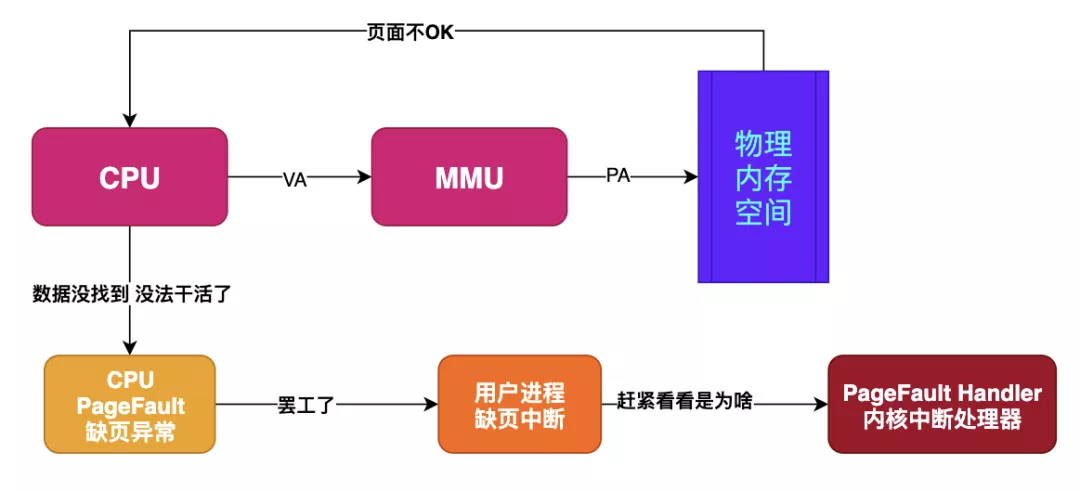
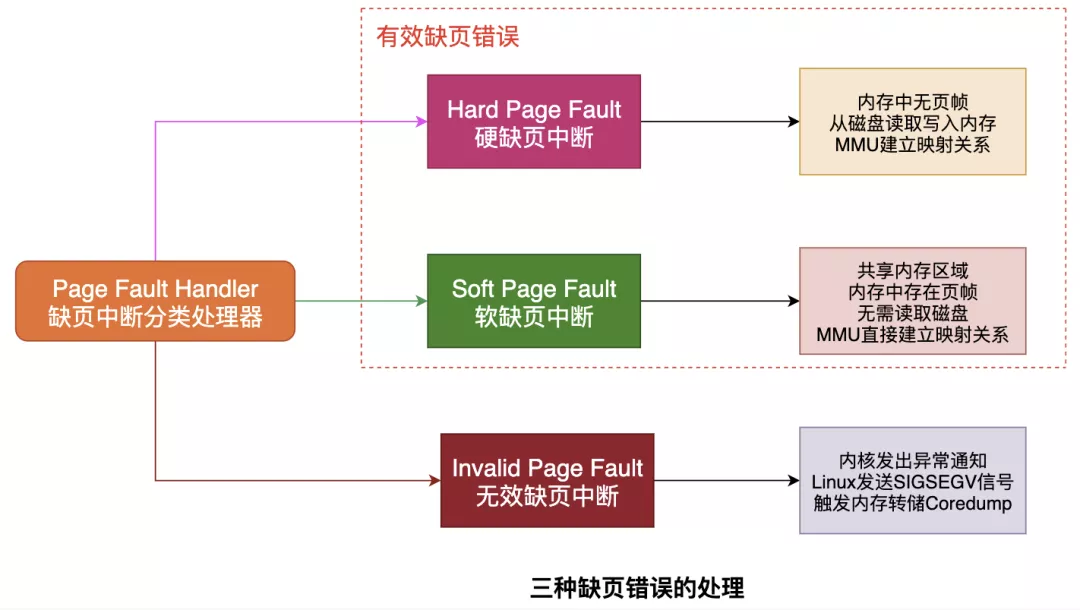
缺页中断会交给PageFaultHandler处理,其根据缺页中断的不同类型会进行不同的处理:
Hard Page Fault
也被称为Major Page Fault,翻译为硬缺页错误/主要缺页错误,这时物理内存中没有对应的页帧,需要CPU打开磁盘设备读取到物理内存中,再让MMU建立VA和PA的映射。
Soft Page Fault
也被称为Minor Page Fault,翻译为软缺页错误/次要缺页错误,这时物理内存中是存在对应页帧的,只不过可能是其他进程调入的,发出缺页异常的进程不知道而已,此时MMU只需要建立映射即可,无需从磁盘读取写入内存,一般出现在多进程共享内存区域。
Invalid Page Fault
翻译为无效缺页错误,比如进程访问的内存地址越界访问,又比如对空指针解引用内核就会报segment fault错误中断进程直接挂掉。
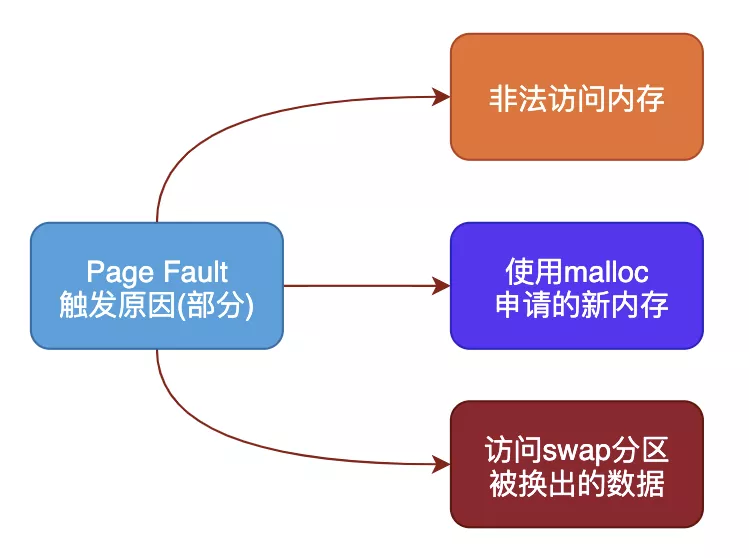
不同类型的Page Fault出现的原因也不一样,常见的几种原因包括:
非法操作访问越界
这种情况产生的影响也是最大的,也是Coredump的重要来源,比如空指针解引用或者权限问题等都会出现缺页错误。
使用malloc新申请内存
malloc机制是延时分配内存,当使用malloc申请内存时并未真实分配物理内存,等到真正开始使用malloc申请的物理内存时发现没有才会启动申请,期间就会出现Page Fault。
访问数据被swap换出
物理内存是有限资源,当运行很多进程时并不是每个进程都活跃,对此OS会启动内存页面置换将长时间未使用的物理内存页帧放到swap分区来腾空资源给其他进程,当存在于swap分区的页面被访问时就会触发Page Fault从而再置换回物理内存。
本段小结 敲黑板 划重点
缺页异常在虚拟机制下是必然会出现的,原因非常多,没什么大不了的,在缺页异常的配合下合法的内存访问才能得到响应。
我们基本弄清楚了为什么需要内存管理、虚拟内存机制主要做什么、虚拟机制下数据的读写流程等等。
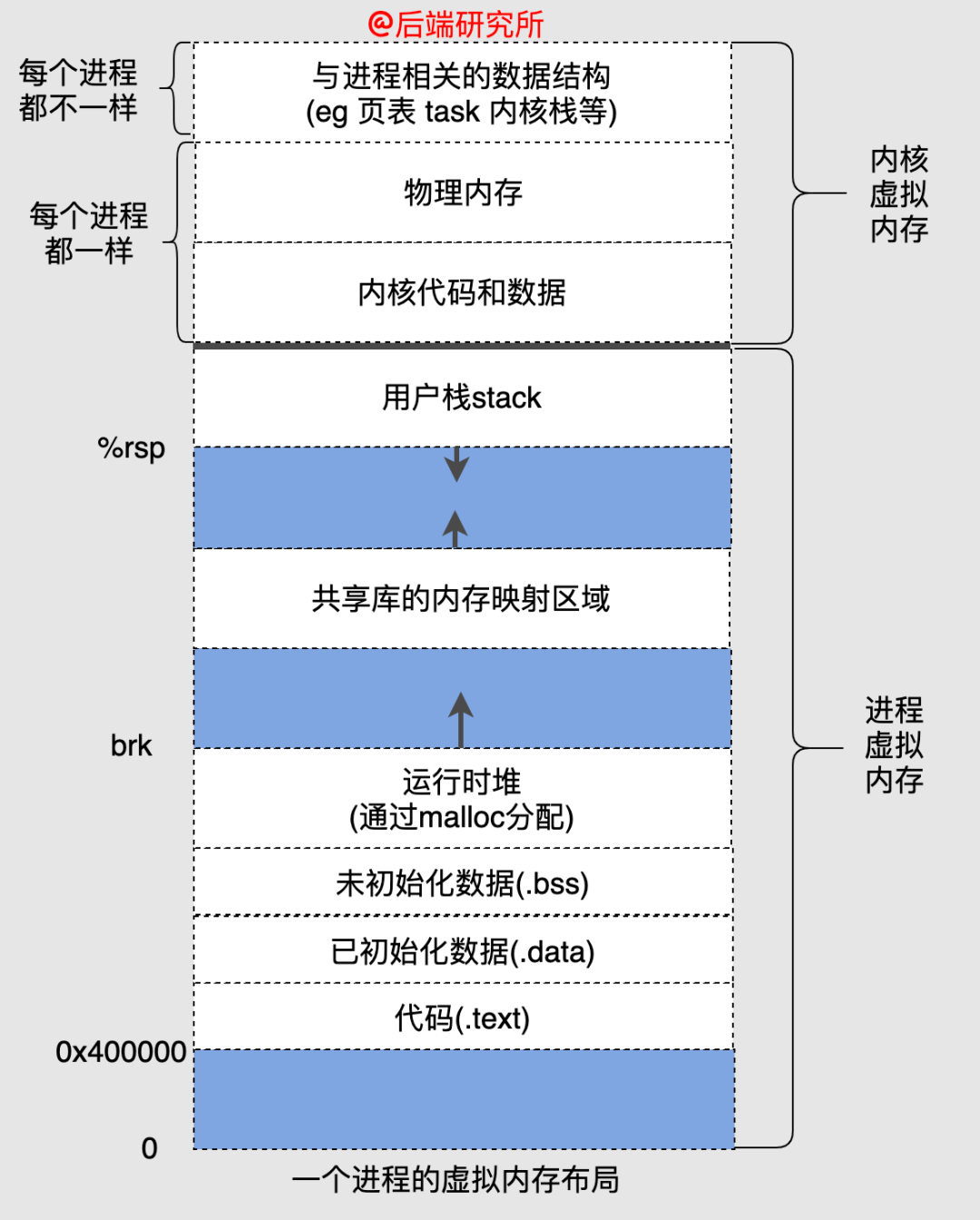
虚拟机制下每个进程都有独立的地址空间,并且地址空间被划分为了很多部分,如图为32位系统中虚拟地址空间分配:
64位系统也是类似的,只不过对应的空间都扩大为128TB。
下面来看看各个段各自特点和相互联系:
text段包含了当前运行进程的二进制代码,所以又被称为代码段,在32位和64位系统中代码段的起始地址都是确定的,并且大小也是确定的。
data段存储已初始化的全局变量,和text段紧挨着,中间没有空隙,因此起始地址也是固定的,大小也是确定的。
bss段存储未初始化的全局变量,和data段紧挨着,中间没有空隙,因此起始地址也是固定的,大小也是确定的。
heap段和bss段并不是紧挨着的,中间会有一个随机的偏移量,heap段的起始地址也被称为start_brk,由于heap段是动态的,顶部位置称为program break brk。
在heap段上方是内存映射段,该段是mmap系统调用映射出来的,该段的大小也是不确定的,并且夹在heap段和stack段中间,该段的起始地址也是不确定的。
stack段算是用户空间地址最高的一部分了,它也并没有和内核地址空间紧挨着,中间有随机偏移量,同时一般stack段会设置最大值RLIMIT_STACK(比如8MB),在之下再加上一个随机偏移量就是内存映射段的起始地址了。
看到这里,大家可能晕了我们抓住几点:
我把heap段、stack段、mmap段再细化一张图:
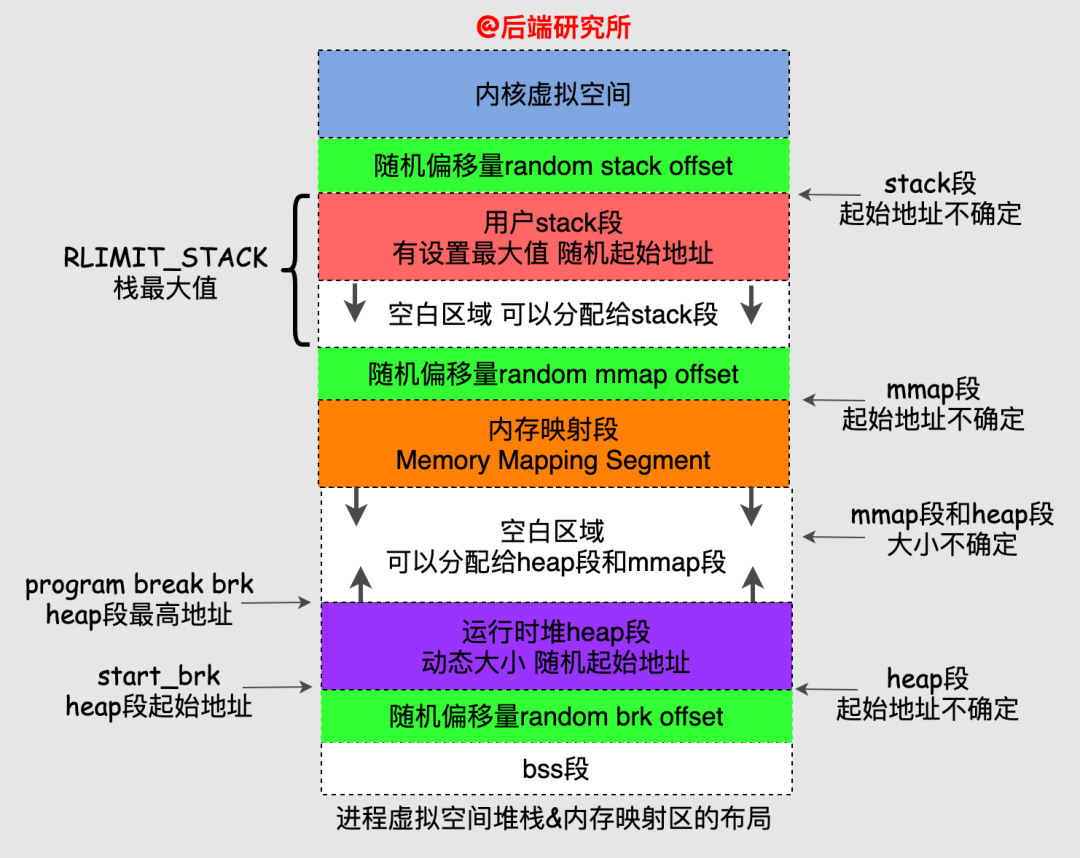
从图上我们可以看到各个段的布局关系和随机偏移量的使用,多看几遍就清楚啦!
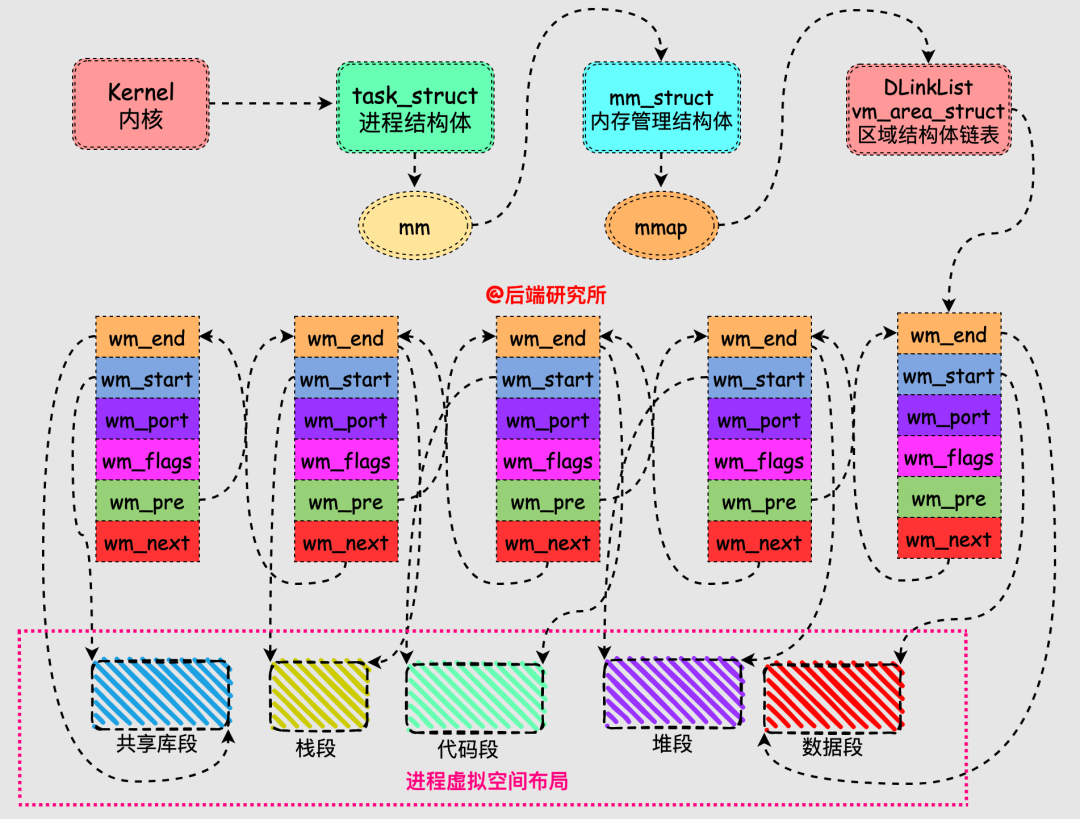
从前面可以看到进程虚拟空间就是一块块不同区域的集合,这些区域就是我们上面的段,每个区域在Linux系统中使用vm_area_struct这个数据结构来表示的。
内核为每个进程维护了一个单独的任务结构task_strcut,该结构中包含了进程运行时所需的全部信息,其中有一个内存管理(memory manage)相关的成员结构mm_struct:
struct mm_struct *mm;
struct mm_struct *active_mm;
结构mm_strcut的成员非常多,其中gpd和mmap是我们需要关注的:
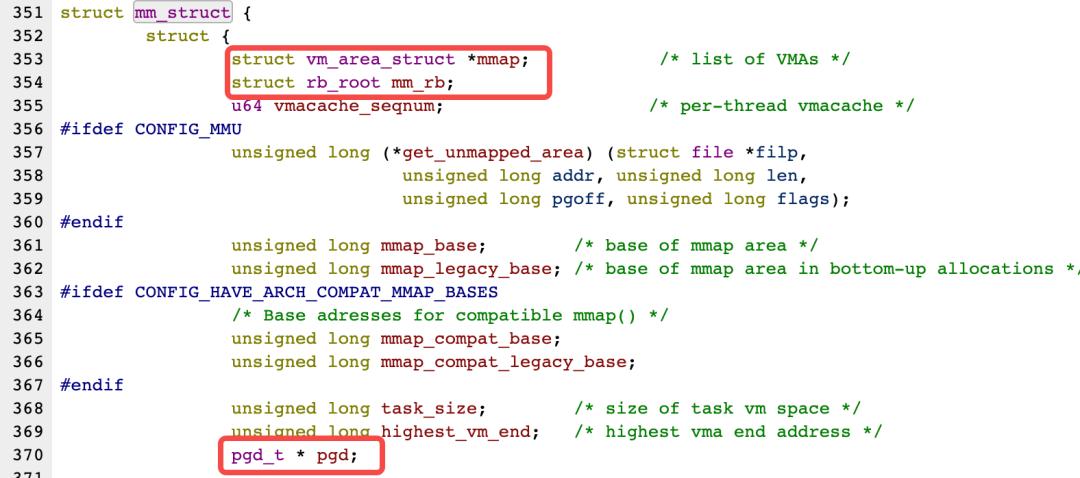
我们看下vm_area_struct的结构体定义,后面要用到,注意看哈:

vm_area_start作为链表节点串联在一起,每个vm_area_struct表示一个虚拟内存区域,由其中的vm_start和vm_end指向了该区域的起始地址和结束地址,这样多个vm_area_struct就将进程的多个段组合在一起了。
我们同时注意到vm_area_struct的结构体定义中有rb_node的相关成员,不过有的版本内核是AVL-Tree,这样就和mm_struct对应起来了:
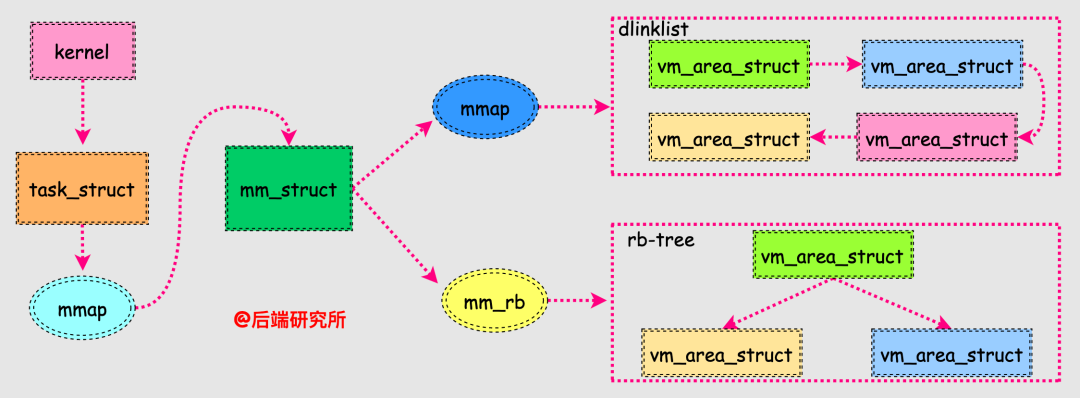
这样vm_area_struct通过双向链表和红黑树两种数据结构串联起来,实现了两种不同效率的查找,双向链表用于遍历vm_area_struct,红黑树用于快速查找符合条件的vm_area_struct。
有内存分配和回收的地方就可能有内存分配器。
以glibc为例,我们先捋一下:
从而就引出了,今天的主线图:
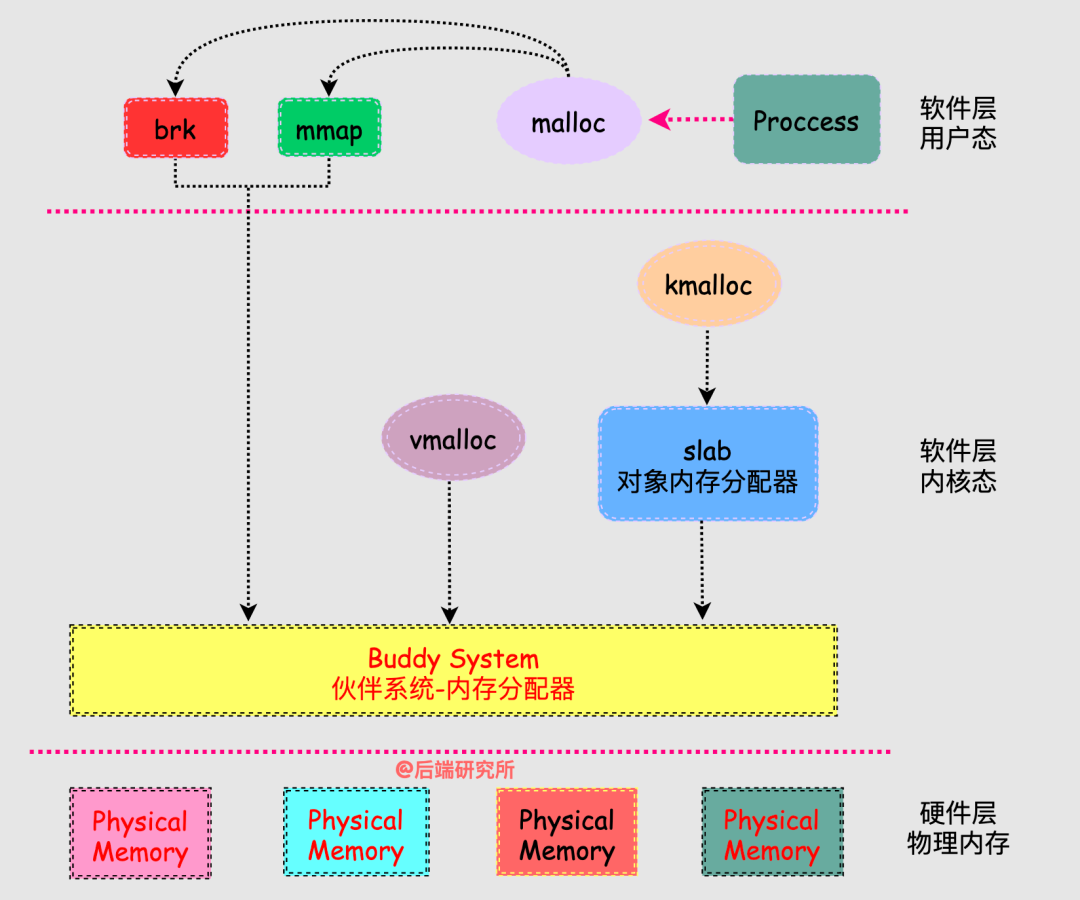
从图中我们来阐述几个重点:
进程的内存分配器工作于内核和用户程序之间,主要是为了实现用户态的内存管理。
分配器响应进程的内存分配请求,向操作系统申请内存,找到合适的内存后返回给用户程序,当进程非常多或者频繁内存分配释放时,每次都找内核老大哥要内存/归还内存,可以说十分麻烦。
总麻烦大哥,也不是个事儿,于是分配器决定自己搞管理!
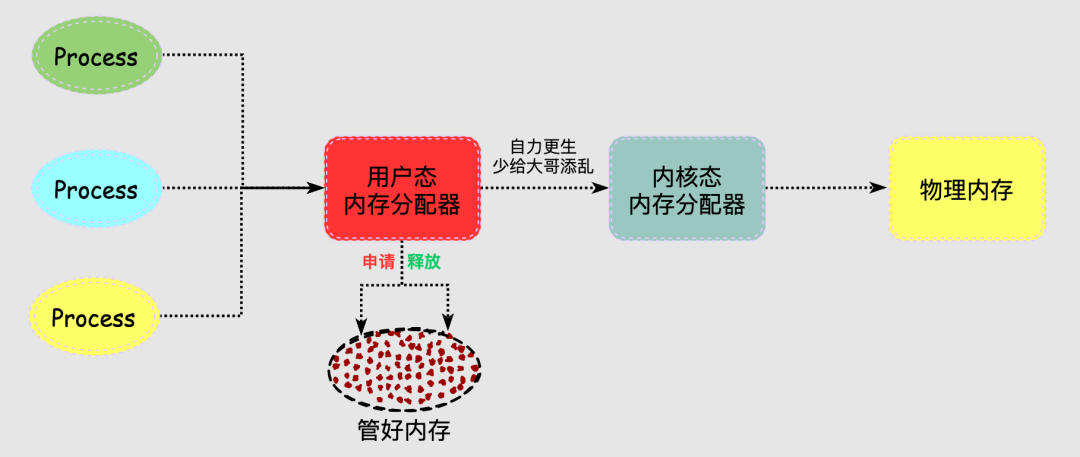
说到管理能力,每个人每个国家都有很大差别,分配器也不例外,要想管好这块内存也挺难的,场景很多要求很多,于是就出现了很多分配器:
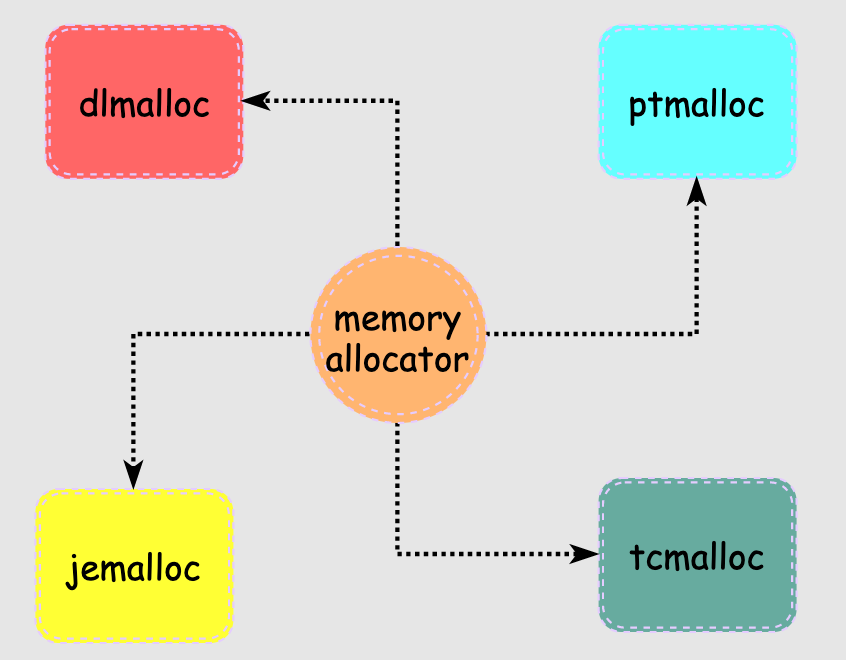
dlmalloc是一个著名的内存分配器,最早由Doug Lea在1980s年代编写,由于早期C库的内置分配器在某种程度上的缺陷,dlmalloc出现后立即获得了广泛应用,后面很多优秀分配器中都能看到dlmalloc的影子,可以说是鼻祖了。
http://gee.cs.oswego.edu/dl/html/malloc.html
ptmalloc是在dlmalloc的基础上进行了多线程改造,认为是dlmalloc的扩展版本,它也是目前glibc中使用的默认分配器,不过后续各自都有不同的修改。因此,ptmalloc2和glibc中默认分配器也并非完全一样。
tcmalloc 出身于 Google,全称是 thread-caching malloc,所以 tcmalloc 最大的特点是带有线程缓存,tcmalloc 非常出名,目前在 Chrome、Safari 等知名产品中都有所应有。
tcmalloc 为每个线程分配了一个局部缓存,对于小对象的分配,可以直接由线程局部缓存来完成,对于大对象的分配场景,tcmalloc 尝试采用自旋锁来减少多线程的锁竞争问题。
jemalloc 是由 Jason Evans 在 FreeBSD 项目中引入的新一代内存分配器。
它是一个通用的 malloc 实现,侧重于减少内存碎片和提升高并发场景下内存的分配效率,其目标是能够替代 malloc。
jemalloc 应用十分广泛,在 Firefox、Redis、Rust、Netty 等出名的产品或者编程语言中都有大量使用。
具体细节可以参考 Jason Evans 发表的论文 《A Scalable Concurrent malloc Implementation for FreeBSD》
论文链接:https://www.bsdcan.org/2006/papers/jemalloc.pdf
我们在使用malloc进行内存分配,malloc只是glibc提供的库函数,它仍然会调用其他函数从而最终触达到物理内存,所以是个很长的链路。
我们先来看下malloc的特点:
/* malloc example */
#include
#include
int main ()
{
int i,n;
char * buffer;
scanf ("%d", &i);
buffer = (char*) malloc (i+1);
if (buffer==NULL) exit (1);
for (n=0; n buffer[n]=rand()%26+'a';
buffer[i]='\0';
free (buffer);
return 0;
}
上面是malloc作为库函数和用户交互的部分,如果不深究原理,掌握上面这些就可以使用malloc了,但是对于我们这些追求极致的人来说,还远远不够。
继续看下 malloc是如何触达到物理内存的:
#include
int brk(void *addr);
void *sbrk(intptr_t increment);
画外音:我原来以为sbrk是brk的什么safe版本,还真是无知了
#include
void *mmap(void *addr, size\_t length, int prot, int flags, int fd, off\_t offset);
int munmap(void *addr, size_t length);
malloc的核心工作就是组织管理内存,高效响应进程的内存使用需求,同时保证内存的使用率,降低内存碎片化。
那么,malloc是如何解决这些问题的?
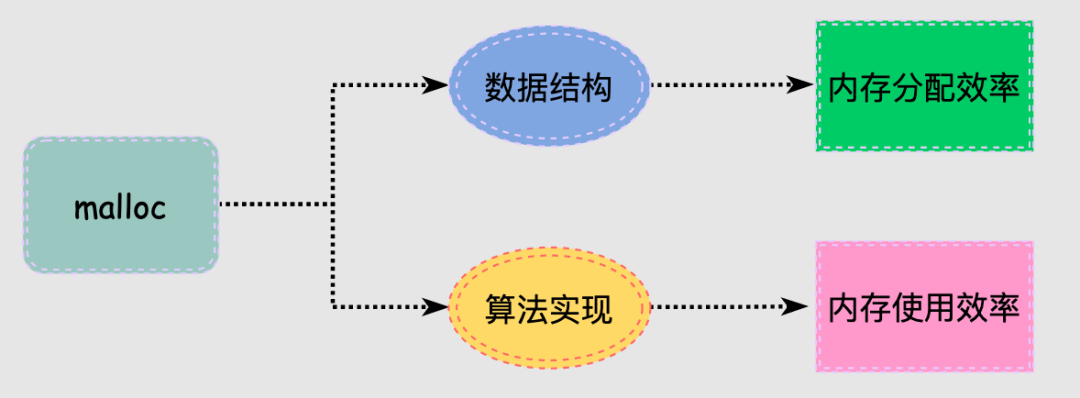
malloc为了解决这些问题,采用了多种数据结构和策略来实现内存分配,这就是我们接下来研究的事情:
事情没有一蹴而就,我们很难理解内存分配器设计者面临的复杂问题,因此当我们看到malloc底层复杂的设计逻辑时难免没有头绪,所以要忽略细节抓住主线多看几遍。
malloc将内存分成了大小不同的chunk,malloc将相似大小的chunk用双向链表链接起来,这样一个链表被称为一个bin。
这些空闲的不同大小的内存块chunk通过bin来组织起来,换句话说bin是空闲内存块chunk的容器。
malloc一共维护了128个bin,并使用一个数组来存储这些bin。
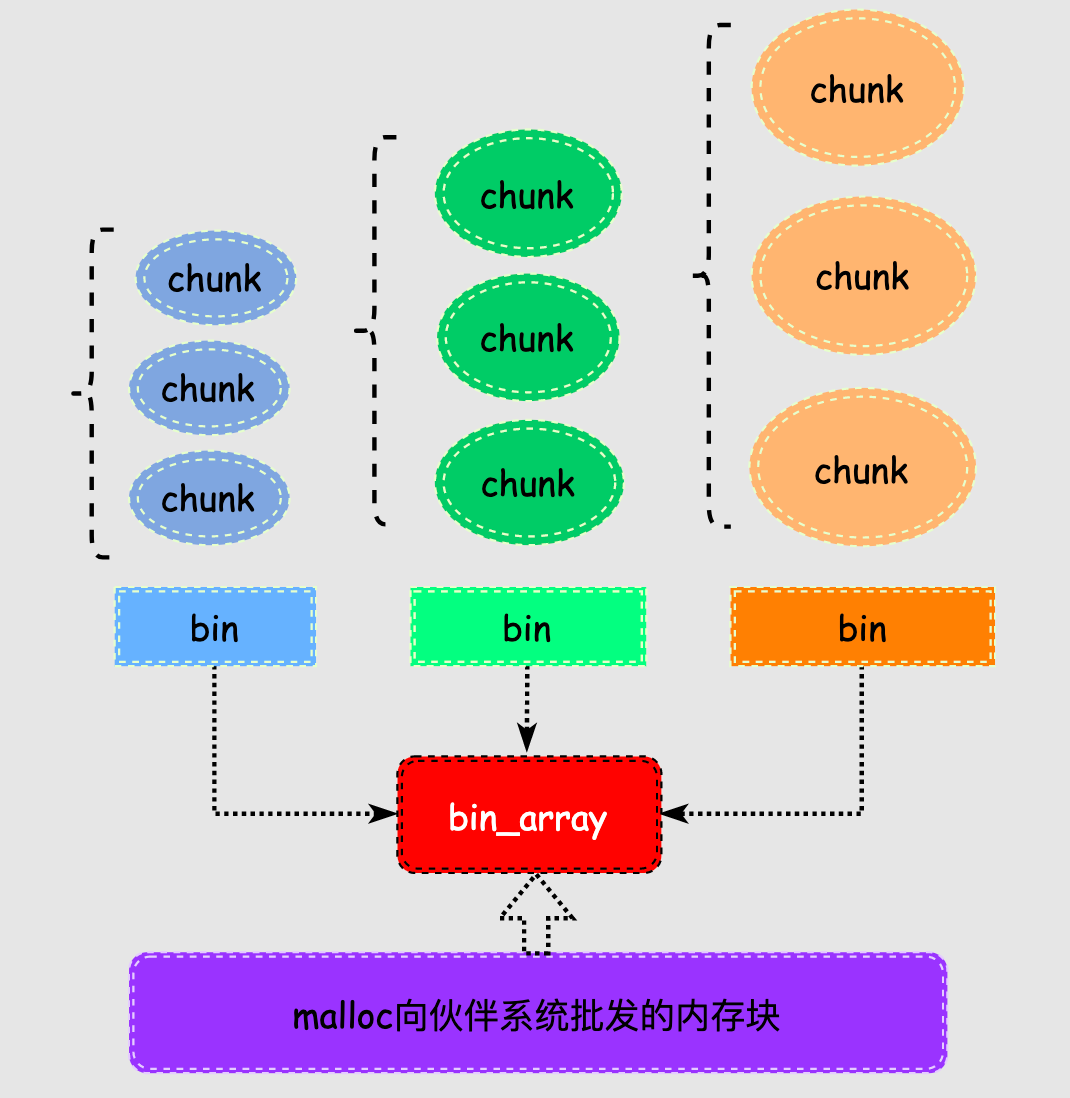
malloc中128个bin的bins数组存储的chunk情况如下:
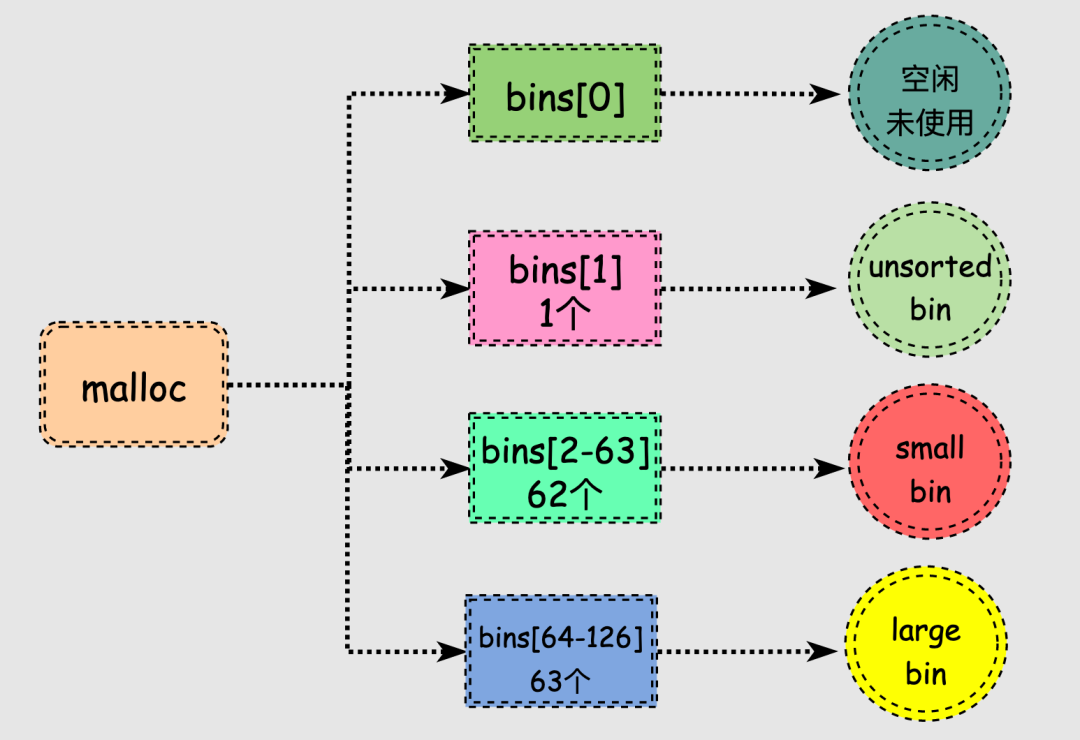
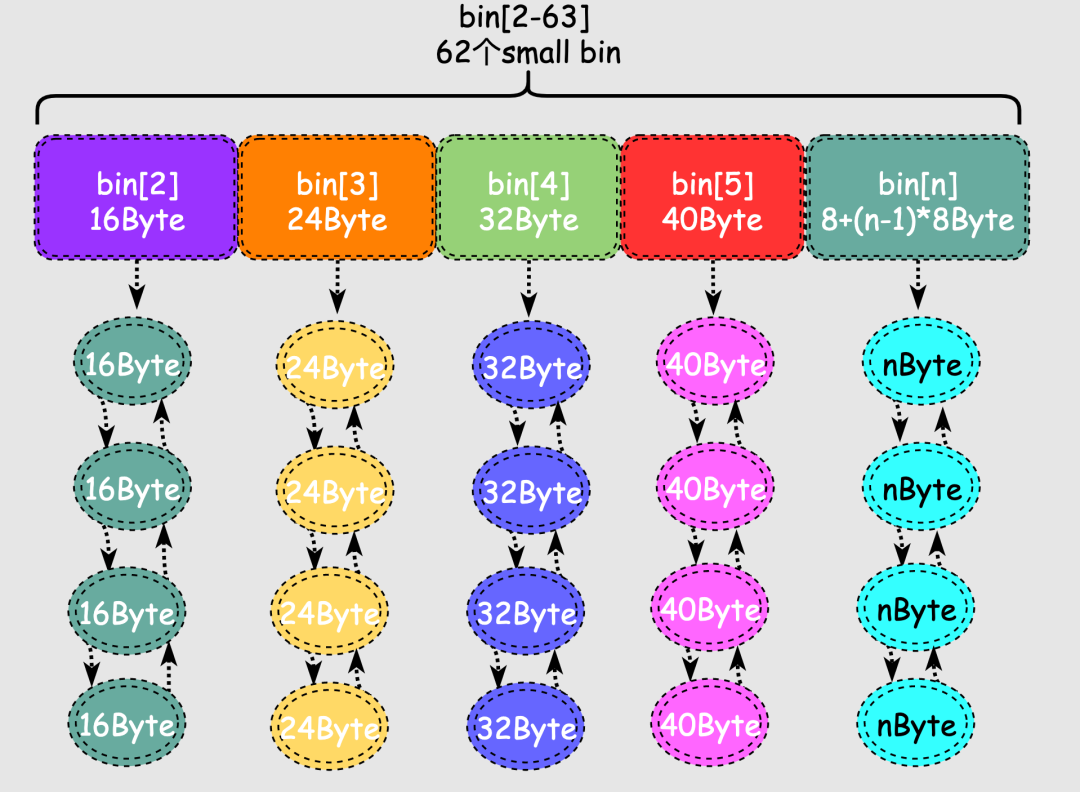
malloc有两种特殊类型的bin:
malloc对于释放的内存并不会立刻进行合并,如何将刚释放的两个相邻小chunk合并为1个大chunk,此时进程分配仍然是小chunk则可能还需要分割大chunk,来来回回确实很低效,于是出现了fast bin。
fast bin存储在fastbinY数组中,一共有10个,每个fast bin都是一个单链表,每个单链表中的chunk大小是一样的,多个链表的chunk大小不同,这样在找特定大小的chunk的时候就不用挨个找,只需要计算出对应链表的索引即可,提高了效率。
// http://gee.cs.oswego.edu/pub/misc/malloc-2.7.2.c
/* The maximum fastbin request size we support */
#define MAX_FAST_SIZE 80
#define NFASTBINS (fastbin_index(request2size(MAX_FAST_SIZE))+1)
多个fast bin链表存储的chunk大小有16, 24, 32, 40, 48, 56, 64, 72, 80, 88字节总计10种大小。
fast bin是除tcache外优先级最高的,如果fastbin中有满足需求的chunk就不需要再到small bin和large bin中寻找。当在fast bin中找到需要的chunk后还将与该chunk大小相同的所有chunk放入tcache,目的就是利用局部性原理提高下一次内存分配的效率。
对于不超过max_fast的chunk被释放后,首先会被放到 fast bin中,当给用户分配的 chunk 小于或等于 max_fast 时,malloc 首先会在 fast bin 中查找相应的空闲块,找不到再去找别的bin。
当小块或大块内存被释放时,它们会被添加到 unsorted bin 里,相当于malloc给了最近被释放的内存被快速二次利用的机会,在内存分配的速度上有所提升。
当用户释放的内存大于max_fast或者fast bins合并后的chunk都会首先进入unsorted bin上,unsorted bin中的chunk大小没有限制。
在进行 malloc 操作的时候,如果在 fast bins 中没有找到合适的 chunk,则malloc 会先在 unsorted bin 中查找合适的空闲 chunk。
unsorted bin里面的chunk是最近回收的,但是并不能全部再被快速利用,因此在遍历unsorted bins的过程中会把不同大小的chunk再分配到small bins或者large bins。
malloc在chunk和bin的结构之上,还有两种特殊的chunk:
top chunk不属于任何bin,它是始终位于堆内存的顶部。
当所有的bin里的chunk都无法满足分配要求时,malloc会从top chunk分配内存,如果大小不合适会进行分割,剩余部分形成新的top chunk。
如果top chunk也无法满足用户的请求,malloc只能向系统申请更多的堆空间,所以top chunk可以认为是各种bin的后备力量,尤其在分配大内存时,large bins也无法满足时大哥就得顶上了。
当unsorted bin只有1个chunk,并且这个chunk是上次刚刚被使用过的内存块,那么它就是last remainder chunk。
当进程分配一个small chunk,在small bins中找不到合适的chunk,这时last remainder chunk就上场了。
这种特殊chunk主要用于分配内存非常小的情况下,当fast bin和small bin都无法满足时,还会再次从last remainder chunk进行分配,这样就很好地利用了程序局部性原理。
前面我们了解到malloc为了实现内存的分配,采用了一些数据结构和组织策略。接着,我们再来看看实际的内存分配流程以及这些数据结构之间的关系。
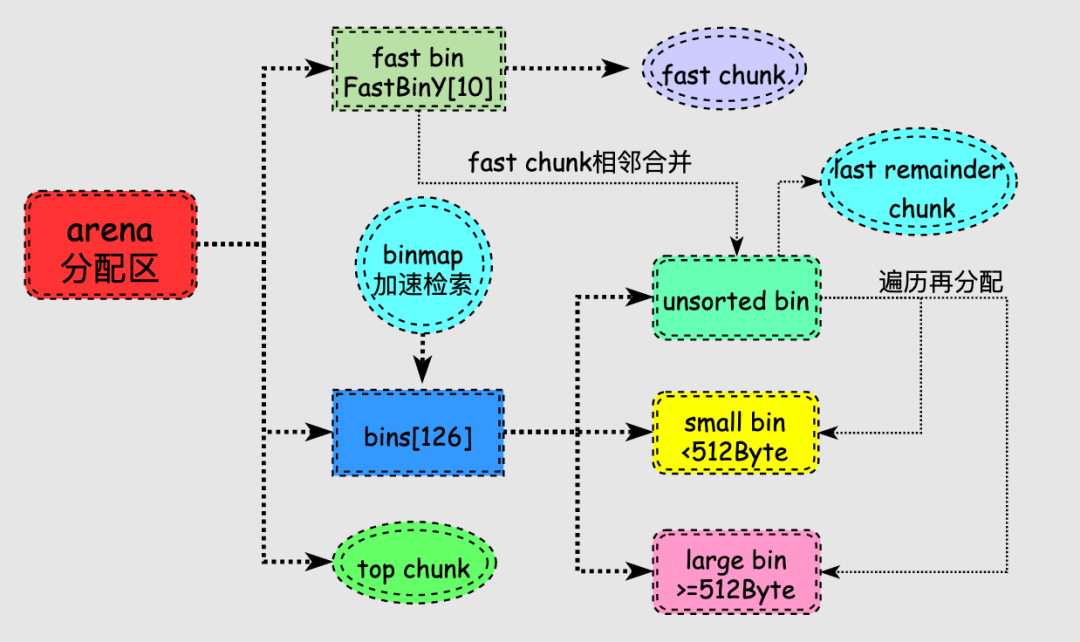
在上图中有几个点需要说明:
内存释放后,size小于max_fast则放到fast bin中,size大于max_fast则放到unsorted bin中,fast bin和unsorted bin可以看作是刚释放内存的容器,目的是给这些释放内存二次被利用的机会。
fast bin中的fast chunk被设置为不可合并,但是如果一直不合并也就爆了,因此会定期合并fast chunk到unsorted bin中。
unsorted bin很特殊,可以认为是个中间过渡bin,在large bin分割chunk时也会将下脚料chunk放到unsorted bin中等待后续合并以及再分配到small bin和large bin中。
由于small bin和large bin链表很多并且大小各不相同,遍历查找合适chunk过程是很耗时的,为此引入binmap结构来加速查找,binmap记录了bins的是否为空等情况,可以提高效率。
当用户申请的内存比较小时,分配过程会比较复杂,我们再尝试梳理下该情况下的分配流程:
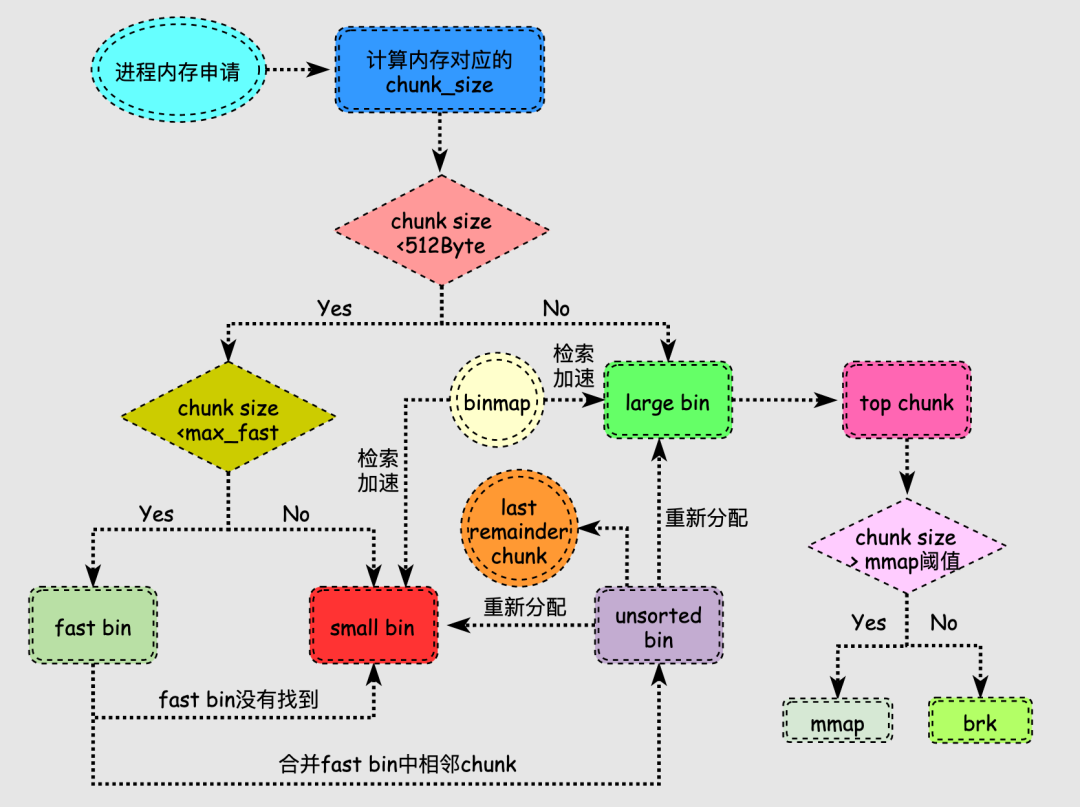
查找合适空闲内存块的过程涉及循环过程,因此把各个步骤标记顺序来表述过程。
特别地,搜索合适chunk的过程中,fast bins 和small bins需要大小精确匹配,而在large bins中遵循“smallest-first,best-fit”的原则,不需要精确匹配,因此也会出现较多的碎片。
内存回收的必要性显而易见,试想一直分配不回收,当进程们需要新大块内存时,肯定就没内存可用了。为此,内存回收必须要搞起来。
内存回收就是释放掉比如缓存和缓冲区的内存,通常他们被称为文件页page cache,对于通过mmap生成的用于存放程序数据而非文件数据的内存页称为匿名页。
这两种物理页面在某些情况下是可以回收的,但是处理方式并不同。
page cache常被用于缓冲磁盘文件的数据,让磁盘数据放到内存中来实现CPU的快速访问。
page cache中有非常多page frame,要回收这些page frame需要确定这些物理页是否还在用,为了解决这个问题出现了反向映射技术。
正向映射是通过虚拟地址根据页表找到物理内存,反向映射就是通过物理地址找到哪些虚拟地址使用它,也就是当我们在决定page frame是否可以回收时,需要使用反向映射来查看哪些进程被映射到这块物理页了,进一步判断是否可以回收。
反向映射技术最早并没有在内核中出现,从诞生到被广泛推广也经历了很多波折,并且细节很多,要展开说估计还得万八千字,所以我找了一篇关于反向映射很棒的文章:
https://cclinuxer.github.io/2020/11/Linux%E5%8F%8D%E5%90%91%E6%98%A0%E5%B0%84%E6%9C%BA%E5%88%B6/
找到可以回收的page frame之后内核使用LRU算法进行回收,Linux采用的方法是维护2个双向链表,一个是包含了最近使用页面的active list,另一个是包含了最近不使用页面的inactive list。
匿名页没有对应的文件形成映射,因此也就没有像磁盘那样的低速备份。
在回收匿名页的时候,需要先保存匿名页上的内容到特定区域,这样才能避免数据丢失保证后续的访问。
匿名页在进程中是非常普遍的,动态分配的堆内存都可以说是匿名页,Linux为回收匿名页,特地开辟了swap space来存储内存上的数据,关于swap机制的文章太多了,这算是个常识的东西了,所以本文不啰嗦啦!
内核倾向于回收page cache中的物理页面,只有当内存很紧张并且内核配置允许swap机制时,才会选择回收匿名页。
回收匿名页意味着将数据放到了低速设备,一旦被访问性能损耗也很大,因此现在大内存的物理机器经常关闭swap来提高性能。
NUMA架构下每个CPU都有自己的本地内存来加速访问避免总线拥挤,在本地内存不足时又可以访问其他Node的内存,但是访问速度会下降。
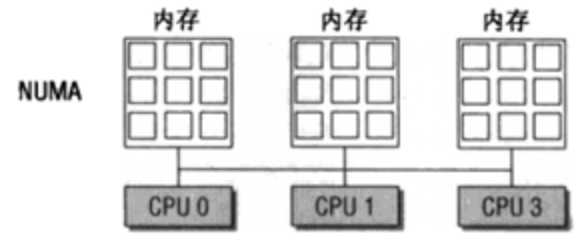
每个CPU加本地内存被称作Node,一个node又被划分为多个zone,每个zone有自己一套内存水位标记,来记录本zone的内存水平,同时每个node有一个kswapd内核线程来回收内存。
Linux内核中有一个非常重要的内核线程kswapd,负责在内存不足的情况下回收页面,系统初始化时,会为每一个NUMA内存节点创建一个名为kswapd的内核线程。
在内存不足时内核通过wakeup_kswapd()函数唤醒kswapd内核线程来回收页面,以便释放一些内存,kswapd的回收方式又被称为background reclaim。
Linux内核使用水位标记(watermark)的概念来描述这个压力情况。
Linux为内存的使用设置了三种内存水位标记,high、low、min,当内存处于不同阶段会触发不同的内存回收机制,来保证内存的供应,如下图所示:
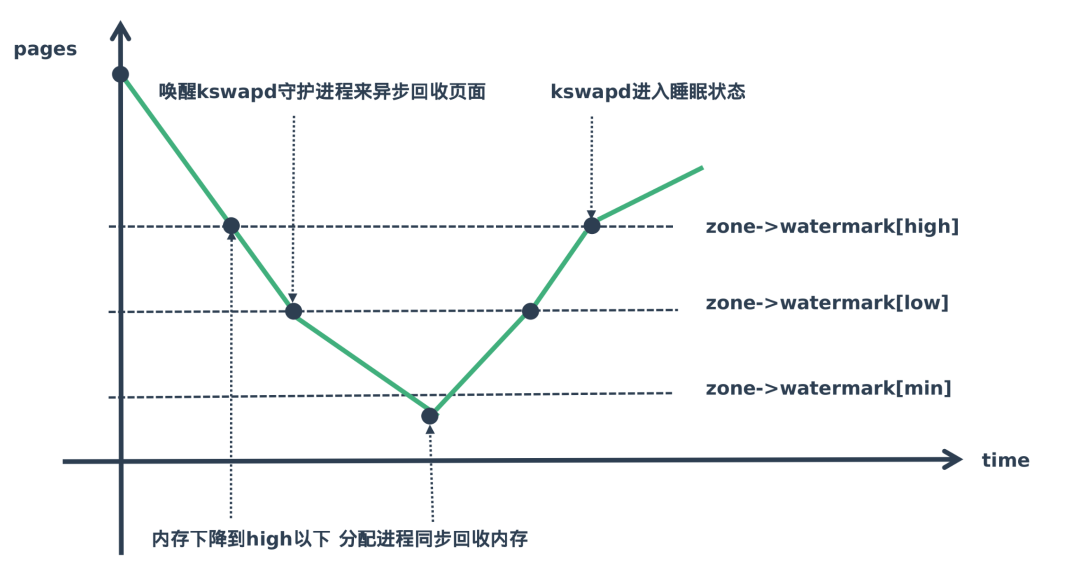
他们所标记的分别含义为:
水位线在high以上表示内存剩余较多,目前内存使用压力不大,kswapd处于休眠状态
水位线在high-low的范围表示目前虽然还有剩余内存但是有点紧张,kswapd开始工作进行内存回收
水位线在low-min表示剩余可用内存不多了压力山大,min是最小的水位标记,当剩余内存达到这个状态时,就说明内存面临很大压力。
水位线低于min这部分内存,就会触发直接回收内存。
OOM(Out Of Memory)是Linux内核在可用内存较少或者某个进程瞬间申请并使用超额的内存,此时空闲的物理内存是远远不够的,此时就会触发OOM。
为了保证其他进程兄弟们能正常跑,内核会让OOM Killer根据设置参数和策略选择认为最值得被杀死的进程,杀掉它然后释放内存来保证大盘的稳定。
OOM Killer这个杀手很多时候不够智慧,经常会遇到进程A是个重要程序,正在欢快稳定的跑着,此时杀出来个进程B,瞬间要申请大量内存,Linux发现满足不了这个程咬金,于是就祭出大招OOM Killer,但是结果却是把进程A给杀了。
在oom的源码中可以看到,作者关于如何选择最优进程的一些说明:

https://github.com/torvalds/linux/blob/master/mm/oom_kill.c
oom_killer在选择最优进程时决策并不完美,只是做到了"还行",根据策略对进程打分,选择分数最高的进程杀掉。
具体的计算在oom_badness函数中进行的,如下为分数的计算:

其中涉及进程正在使用的物理内存RSS+swap分区+页面缓冲,再对比总内存大小,同时还有一些配置来避免杀死最重要的进程。
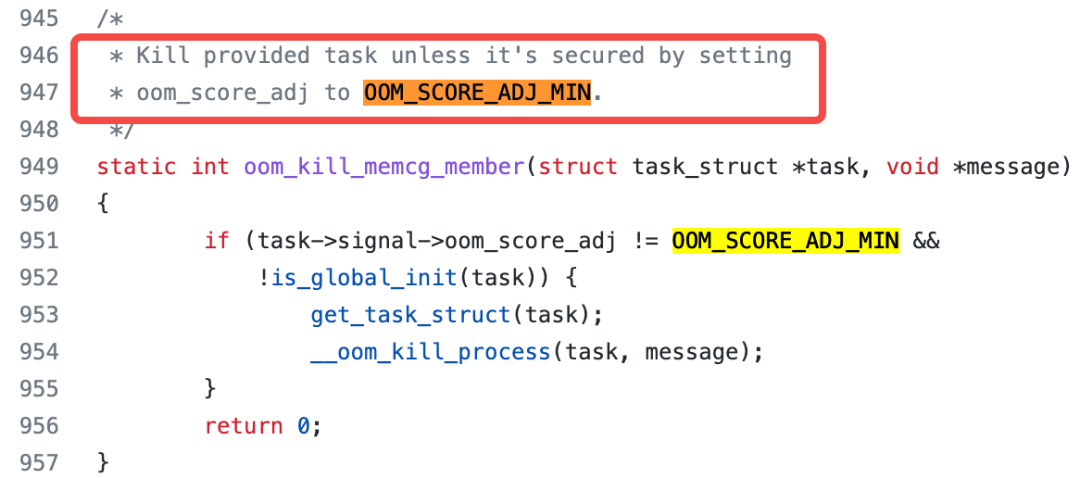
进程设置OOM_SCORE_ADJ_MIN时,说明该进程为不可被杀死,返回的得分就非常低,从而被oom killer豁免。
本文首先介绍虚拟内存机制产生的原因,以及Linux虚拟内存机制的基本原理、同时引入了实现的数据结构和段页机制。
其次重点介绍了内存分配器、并以glibc的malloc为蓝本讲述该内存分配器采用何种数据结构来实现空闲内存管理。
最后阐述内存回收的原理,介绍了匿名页和文件页的回收差异性,同时介绍了kswapd内核线程和内存watermark机制。
由于篇幅和能力所限,本文只能给出一条主线来展示内存如何被组织、使用、回收等。如果不是内核开发人员,单纯的业务开发人员足以应付面试和日常工作。
最后,感谢大家的耐心阅读!如果觉得文章有用,麻烦帮忙点个赞
