本文一共4981字,阅读大约需要12分钟。
芯片越做越“大”,又越做越“小”。大小之间,不变的是设计师对系统整体表现的极致追求。
本文首发于电子行业综合学术期刊《电子产品世界》
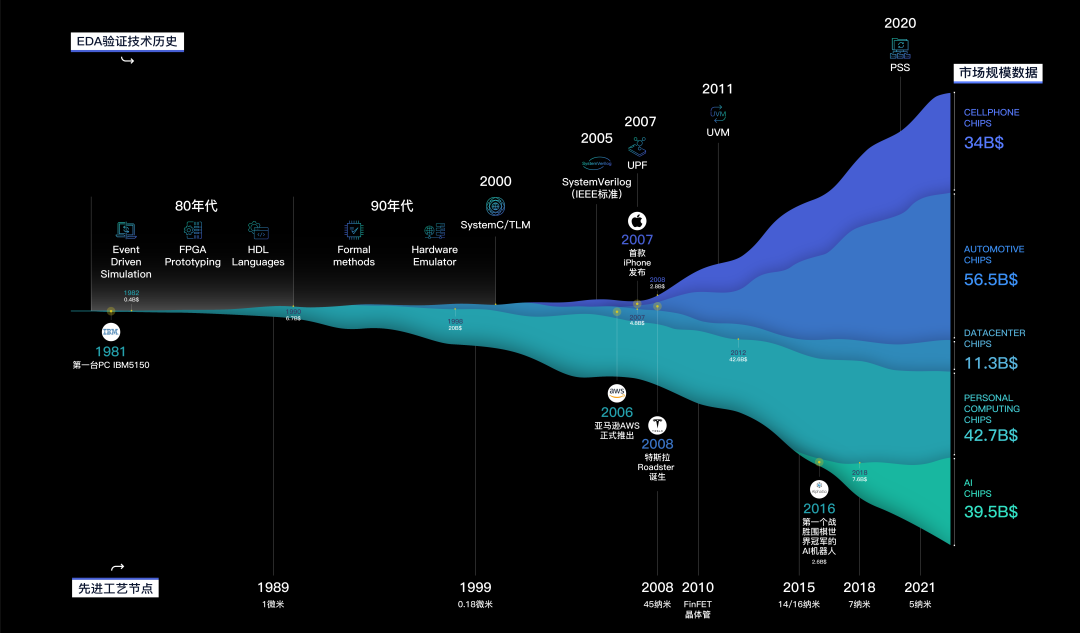
近年来,随着大规模集成电路制造工艺发展速度减缓,相对于线性提升的芯片规模,芯片的制造成本呈现指数级上升,下图可以很清晰地看到两种趋势变化。

图1 芯片晶体管规模与制造成本提升趋势
(数据来源:美国DARPA)
这些数字表明,我们正在为越来越复杂的芯片付出得越来越多。但是从1990年代到2000年代的经验好像并不是这样:每一代电脑手机价格涨得并不多,但是性能总是有大幅增长,甚至性价比都是在提高的,更好的电子产品甚至越来越便宜。为什么现在我们的感觉变化了?
这里有两方面的原因:第一,过去很长时间里消费电子的用户数量在指数级增长,这样的增长摊薄了指数级增长的成本;第二个原因就是摩尔定律,随着工艺改进,芯片上的晶体管数量每隔一段时间就会“无成本”翻倍,从而带来性能的飞速增长,所以我们感觉芯片的性价比总是在提高。摩尔定律会永远持续吗?最近这10年里,我们反复听到这个说法:摩尔定律已经结束。
关于摩尔定律的发展历史,从下图可以看得比较清楚,纵坐标是处理器性能,横坐标是不同的工艺和架构发展阶段。
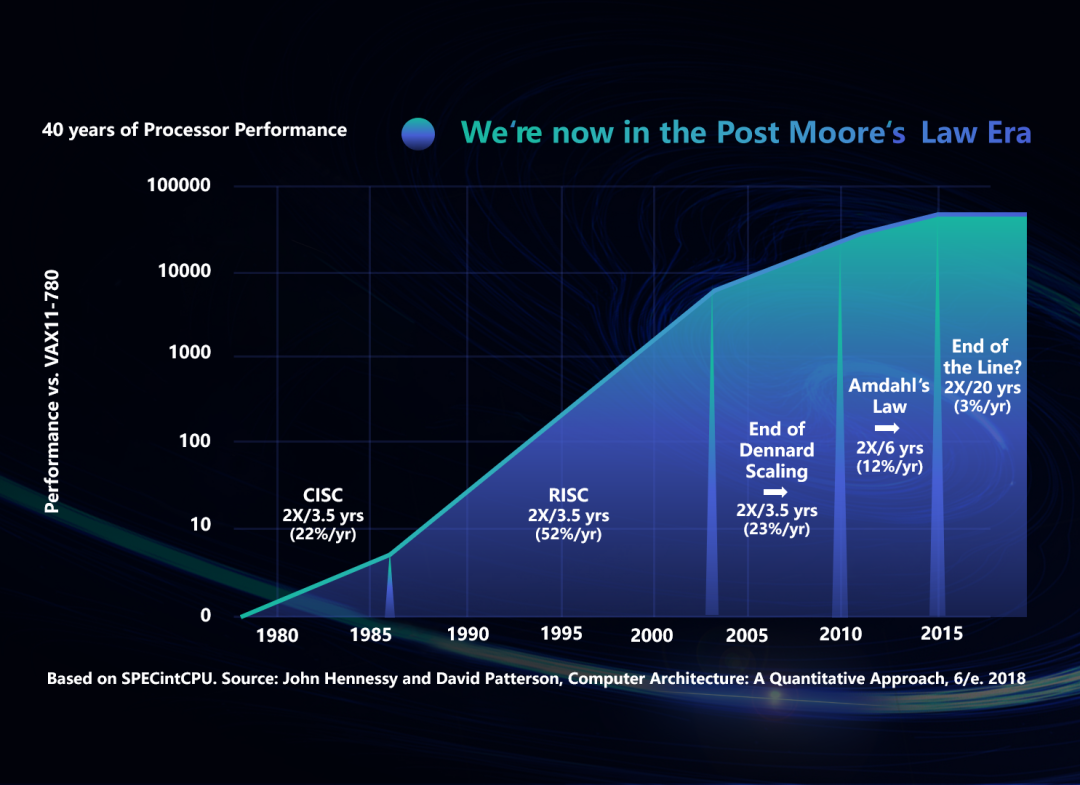
从70年代中期开始,基于CISC复杂指令集的处理器,经历了10年的快速发展,每3.5年性能就翻一倍。然后精简指令集RISC由于它流水线比较好设计,容易利用工艺的发展,所以能继续推动性能的快速发展,差不多1年半就提高一倍,当然这个时期也出现了制造工艺大发展,所以芯片性能提高比较快。
到2005年左右有一个重要的规律Dennard Scaling,或者叫MOSFET scaling差不多发展到头了,它的含义就是说工艺发展了,晶体管变小驱动电压就会变小,会自然带来芯片功耗的降低,所以你只管增加芯片复杂度,下一代工艺出来了自然会帮你把功耗压住。但是到这个阶段不行了,漏电压不住了,单位功耗无法再降,那么单核频率就没办法再提高了,那怎么办呢?我们都知道答案,就是转向多核处理器,多核又带来一个高速发展期,还是三五年就能提高一倍的性能。
但是,多核也存在一些问题,无论是手机上还是高性能计算上,都不是有多少核就总是能用多少核的,Amdahl定律就是描述这个规律,即算法里面的串行部分总会卡住最高的性能。同时,并行化也有额外开销,即使像图像深度学习这么极端的并行数据算法,也存在一些偏向串行化或者全局的算子会变成性能瓶颈。所以我们看到过去10年里面,处理器的实际应用性能提高远没有前30年那么快了。
总结来说,过去的四十年里面,不断发展的工艺和架构设计共同推动着摩尔定律持续前进,即使是今天也还有3nm、2nm、1nm先进工艺在地平线上遥遥可及。但是现实趋势来看,更高工艺、更多核、更大的芯片面积已经不能带来过去那种成本、性能、功耗的全面优势,摩尔定律确实是在进入一个发展平台期,也意味着我们进入了“后摩尔时代”。
如今,摩尔定律已经到了一个部分失效的阶段,即晶体管密度虽然还在继续增加,但功耗密度和性能密度已经很难进一步提高,也就是没有那种随着工艺改进自动发生的进步了。后摩尔时代,我们也观察到几个趋势正在给验证EDA带来更高的要求:
01
02
从更多维度构造自主芯片,满足应用领域需求
03
压力巨大的应用创新周期
过去几十年里,通用电子设备如个人电脑、手机、汽车、云计算等新兴应用领域正快速推动着芯片和EDA产业的发展。曾经围绕这些设备里芯片的一个关键词是“快”,更快的芯片就是更好的芯片,因为功耗、成本和物理限制都不是问题,那是一个美好的年代。但是,后摩尔时代没有那么容易设计出“更快”的芯片了,或者说更快的芯片一定更贵了,是不是芯片不会再变化了呢?答案是否定的,未来芯片的变化反而会更大,不同的指令集、内存类型、内存大小、外部接口、专用指令或加速器、软硬件分工模式、封装模式等等,都没有绝对的好坏,甚至一味追求更高工艺都不一定正确了,因为单颗芯片继续简单增加功能或者提高工艺,必然带来成本的增加,对用户不一定是好事。这种情况下,设计就不一定是做加法了,很多时候我们可能还要做减法。任何改变都是取舍权衡,那么权衡由什么来决定呢?由应用系统的需求决定。未来,如何发挥一颗芯片的设计,也需要应用系统和软件做相应的变化。过去那种软件不需要太多变化,隔几年用同样的钱换新一代的芯片就能看到系统性能提升,这样的经验已经不再适用了。所以,后摩尔时代的芯片创新空间是变大了,而不是变小了。但是设计的约束和目的变了,从设计更快的芯片转变为设计更符合系统应用创新需求的芯片。我们也确实看到了业界在发生这样的变化:苹果、特斯拉、华为、谷歌、阿里巴巴等手机、汽车、服务器、AI、云服务等高科技系统公司,都在从“采购和使用通用芯片”,转向“定制自己的芯片”,在内部不断加强芯片团队方面的投资,通过SoC芯片和ASIC芯片的创新来实现系统创新。同时,新兴高科技的发展也反过来促进芯片设计和EDA的发展,比如人工智能、机器学习、云计算等技术对芯片设计和 EDA工具本身的影响也越来越大。对于国内公司来说,在高工艺发展受限的大背景下,就更没有必要完全把注意力放在先进工艺上,应该看到即使是在14nm、16nm、28nm甚至更低工艺上,国内很多芯片产品整体来看还是跟国际巨头有差距,这种差距恰恰是架构、软件、编译器以及应用需求匹配等因素造成的。后摩尔时代的芯片创新,会有更多不同的维度。后摩尔时代的第二个趋势是,芯片设计约束变得更多维。过去在工艺发展驱动下,一般都以围绕着工艺的PPA(性能、功耗、面积)指标作为核心维度实现芯片设计,其中面积也约等于芯片成本。但是发展到后摩尔时代,PPA三者之间的矛盾互斥已经大到很难平衡,而成本也不再简单取决于芯片面积,因此我们可以观察到芯片设计的约束维度已经开始发生明显的变化,其中包括:越来越定制化的芯片,必然也越来越依赖针对性的软件去利用这些创新的芯片功能。苹果手机在自主设计芯片之前,曾经长期CPU工艺落后于高通,但是基于iOS软件系统的苹果手机流畅程度、用户体验都优于大部分竞争对手。这个例子充分说明了系统级软硬件集成优化的重要性,而单个芯片的PPA指标并不必然能给整个应用系统带来提升。而软件的优化,不能等到芯片开发生产完成再做,必需要从项目规划阶段就能根据应用需求做好软硬件划分,并把“特定软件”和“特定芯片”结合到一起,去实际评估最终能否达到性能需求。这样就出现了“先有鸡还是先有蛋”的问题,因此新一代EDA工具需要对软件提前定制和优化需求进行支持。过去,处理器指令集以从CISC发展来的x86指令集为典型代表,在发展过程中不断增加新的指令,越来越庞大。但RISC-V为代表的新型ISA和架构反其道而行之,从一个非常简单的指令集出发,只为特定应用增加特定指令和加速器。基于这种思路,诞生了大量的DSA(领域特定)芯片,在AI监控、自动驾驶、IoT等领域取得了比通用处理器更好的效果。另一个更激进的架构演进方向代表是存内计算,让存储和计算能够在同一个器件内完成,这打破了冯诺依曼架构的固定模式,在很多机器学习应用上都能带来与工艺发展无关的效率提升。同时,在多核、多计算单元、多芯粒(die)并行的复杂芯片中,SoC体系结构的优化也还存在很大的空间。举例来说,我们可以在某些ARM架构服务器芯片,或者在某国产x86 CPU芯片上,都观察到单核频率和特定计算性能高于同档次Intel Xeon处理器的情况,这说明单纯从处理器核的设计和生产工艺上,后来者们都已经达到一定的水准。但是在运行多核、多socket的数据库等复杂系统软件时,性能还是有一定差距,这也反向证明了在一个复杂的多核、多芯片、多级存储体系里,架构优化的重要性。随着多芯粒(die)封装从2D逐渐过渡到3D,高带宽高密度互连的Chiplet封装成了最近很火的一个技术方向。它把不同工艺的模块化芯片,像拼接乐高积木一样用封装技术整合在一起,实现更高的性能。Chiplet可以更容易地赋能系统公司自定义创新芯片,也可以帮助中小型的芯片公司和团队降低创新门槛,把资源投入在核心创新点上。比如国产GPU公司壁仞科技最近发布的7nm GPU产品,通过CoWoS Chiplet技术集成了计算芯粒和高带宽HBM2内存芯粒,实现了媲美竞争对手4nm高端GPU的同等算力,并且在不同产品线之间共享计算芯粒,有效降低了成本和提高了良率。但是Chiplet包含了很多EDA相关的新技术,比如说跟制造相关的包括封装里面功耗分析、散热分析等,Chiplet芯片的设计验证也对传统EDA提出了新的要求。特别是在验证技术和工具方面,实际上已经成为Chiplet发展的瓶颈。因为Chiplet目前还以单一公司完成全系统为主,但未来多厂商合作的新型Chiplet模式会把传统SoC流程打破,这就要求在IP建模、互连架构分析、系统功能验证、功耗验证等方面提出新的模式,而不仅仅是解决了制造问题就能实现全新的Chiplet产业结构。从应用系统出发的新趋势,也决定了单颗芯片无法达成系统设计目的,因此芯片的定义、设计和验证也必须考虑多颗芯片之间的协同。比如Nvidia公司的NVLink GPU片间通信接口协议,给GPU处理器增加了高性能数据交换接口,绕过了原来的PCIe瓶颈,有效提高了多GPU协同训练大型AI模型的效率。目前复杂处理器的规模在几亿到上百亿等效逻辑门,但未来一个电子应用系统的总逻辑门数量会在几千亿、几万亿,这不可能用单颗芯片或单颗封装去完成,必须充分考虑几十到几百颗芯片的扩展,并有效处理子系统之间的连接和分工。这种通过异构、多芯粒、多模块系统集成的方式,也体现了从系统设计角度出发去定义和设计芯片的理念。半导体设计产业开始不仅是通过工艺的提升,而是更多考虑系统、架构、软硬件协同等,从系统应用来导向、从应用来导向去驱动芯片设计,让用户得到更好的体验。再来说项目周期,自定义芯片驱动的系统创新周期是从应用需求创新开始,对系统和芯片提出新的需求,因此推导出需要一颗或多颗在功能、功耗、性能上权衡的芯片,然后开始芯片的设计和生产,芯片被制造出来之后投入使用,与软件一起形成新的系统。但是这个周期当中的芯片设计验证环节,对系统公司来说是一个全新的领域,不管是外包还是自研,在当前的EDA工具和方法学流程中,都存在1-2年的创新间隔。由于系统级软硬件和传统芯片设计思路之间的隔阂,这样的创新性项目周期,往往从一开始就会耗费比预计更长的时间,从系统的功能性能指标到具体的芯片定义是一个非常复杂的过程,需要跨领域的架构工程师团队紧密合作,基于多种工具平台分解需求和向下映射。鉴于系统级应用的复杂性和技术挑战,这些步骤往往需要比预期中更多的时间,这会迫使项目通过验证和测试等下游步骤去弥补损失的时间,进一步压缩本就很紧张的时间表。但是复杂SoC芯片和高级工艺的超高成本,又决定了芯片的验证要求很高,需要保证功能和性能验证的覆盖率,于是我们往往会看到芯片设计项目在仿真、调试、原型验证等环节碰到资源、人员、验证平台实现等各种瓶颈,引入更多的时间延误。即使芯片成功流片,进入生产阶段,系统级应用带来的复杂测试环境,对传统ATE测试方法又带来速度、资源上的各种限制,影响项目真正实现“进入市场”的时间点。因此,这里的第三个趋势,是前两个发展趋势所必然带来的挑战。如果不能直面这些挑战,那么系统创新驱动的多维芯片创新就会受到影响。后摩尔时代,针对以上三大趋势,芯华章贯彻“终局思维”,以终为始,致力于打造更智能的EDA 2.0,其核心目标是:- 建立起能够覆盖从芯片级别到最终系统级别的验证和测试方法学,提升芯片及电子系统的性能表现。
- 让系统工程师和软件工程师都参与到芯片设计中来,用智能化的工具和服务化的平台来缩短从芯片需求到系统应用创新的周期,降低复杂芯片的设计和验证难度,赋能电子系统创新。
未来,系统应用将是芯片设计的核心驱动力。芯华章所提出的EDA 2.0并不是一个0和1的状态变化,而是要在当前的基础上进一步增强各环节的开放程度。在开放和标准化的前提下,将过去的设计经验和数据吸收到全流程EDA工具及模型中,形成智能化的EDA设计,形成从系统需求到芯片设计、验证的全自动流程。同时,为了满足算力和平台化的要求,EDA 2.0应该与云平台和及云上多样化的硬件结合,充分利用成熟的云端软硬件生态。要支持应用厂商快速得到需要的芯片,EDA 2.0还应该是产品和服务的结合,最终实现电子设计服务——EDaaS(Electronic Design as a Service)。2022年7月,芯华章成立研究院,汇集了沈昌祥、毛军发等中国两院院士,更有数十位来自集成电路设计、电子设计自动化与信息算法系统领域的顶级专家学者,以研究下一代EDA 2.0方法学与技术为目标,面向工业应用的核心基础技术做长期、持续地研发投入与技术攻关,推动从EDA 1.0往2.0发展,满足数字世界中系统应用对芯片多样化的需求,打造自主可信赖的电子系统创新基石。