
在上一篇自动驾驶定位深度学习概述中,我们分析了业界基于信号+航迹推算+环境特征匹配的融合方案,并讨论了深度学习在定位和地图构建未来可能的应用以及深度学习的优缺点。在这一篇,我们将对深度学习在里程计方面的应用进行更细节的探讨,并对不同解决方案进行性能对比。
⾥程计属于航迹推算方案,它持续跟踪汽车的⾃我运动并估算相对姿势,在给定初始状态的情况下,通过整合这些相对姿势来重建全局轨迹,保持对运动变换估算的⾜够准确,以实现全局范围内的⾼精度定位。本文讨论主要集中在惯性里程计算和视觉⾥程计以及融合的深度学习⽅法,因为它们是移动感知模式的常⻅选择。
惯性⾥程计是⼀种普遍的⾥程计方案。与视觉⽅法相⽐,惯性传感器成本相对较低、体积⼩、节能且保护隐私。它相对不受环境因素的影响,例如照明条件或移动物体。然⽽,惯性测量单元 (IMU) 会因传感器偏差和噪声,导致惯性导航系统 (SINS) 中的误差漂移。纯惯性解决⽅案通常作为在视觉信息不可⽤或⾼度失真的极端环境中提供姿势信息的备⽤计划。
纯惯性解决⽅案深度学习方面的研究并不多,通常将惯性⾥程计公式化成为⼀个顺序学习问题,利用递归神经网络(RNN)从惯性测量序列中端到端学习相对姿势,譬如IONnet。值得一提的是 DeepMind 提出的 MotionTransformer。它结合深度⽣成模型(GAN)和域适应技术来提⾼惯性⾥程计的泛化能⼒,提出一个包括源域序列编码器(提取常见的跨不同域的特征),目标域序列生成器(在目标域中生成感知流),序列重构解码器(重构序列以学习更好的表示)和极向量预测器(为惯性导航产生一致的轨迹)的架构。他们的研究证明深度学习可以从嘈杂的 IMU 数据中学习有⽤的特征,并补偿传统算法难以解决的惯性航位推算的误差漂移。
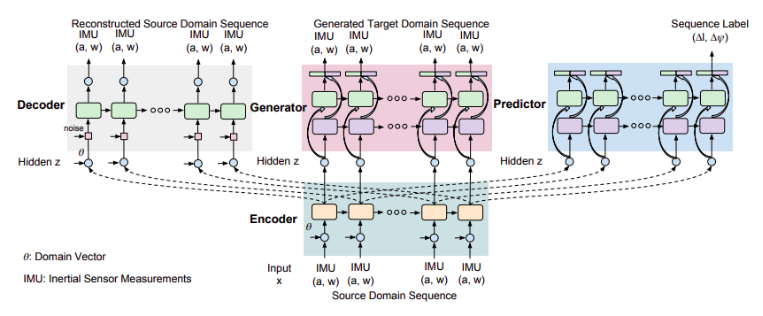
( C. Chen, Y. Miao, C. X. Lu, L. Xie, P. Blunsom, A. Markham, and N. Trigoni, 2019)
监督学习的 VO 是基于学习的⾥程计的最主要⽅法之⼀。它通过在标记数据集上训练深度神经⽹络模型来构建从连续图像到运动的映射函数直接转换,⽽不是像传统的 VO 系统那样利⽤图像的⼏何结构。其最基本的格式就是深度神经⽹络的输⼊是⼀对连续的图像,输出是两帧图像之间的平移和旋转的估算。
早期研究中,将视觉⾥程计定义为⼀个分类问题,并使⽤卷积神经⽹ (ConvNet) 从输⼊图像中预测⽅向和速度的离散变化。也有使⽤ ConvNet 从密集光流中提取视觉特征,并基于这些视觉特征输出帧到帧运动估计。尽管如此,它们都没有实现从图像到运动估计的端到端学习,性能仍然有限。
端到端的解决方案中, DeepVO 框架是实现 VO 监督学习的典型选择。DeepVO 利⽤ConvNet 和 RNN 的组合来实现视觉⾥程计的估算。该系统通过 ConvNet 从图像对中提取视觉特征,并通过 RNN 传递特征以对特征的时间相关性进⾏建模。递归模型将历史信息汇总到其隐藏状态中,以便从过去的经验和来⾃传感器观察的当前 ConvNet 特征推断输出。它在以真实相机姿势作为标签的⼤规模数据集上进⾏训练,参数框架的优化⽬标是最⼩化估计平移的均⽅误差 (MSE)
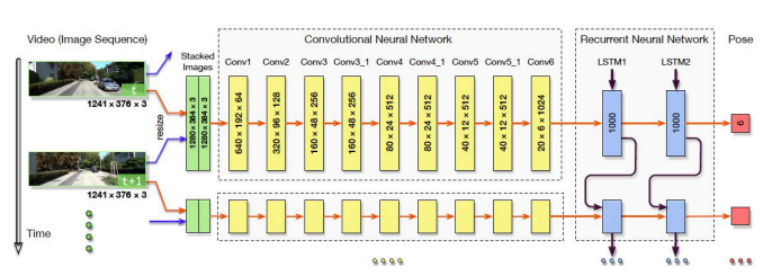
( S. Wang, R. Clark, H. Wen, and N. Trigoni, 2017)
DeepVO 在估算驾驶⻋辆姿势⽅⾯取得令⼈印象深刻的结果,即使在之前没经历的场景中也是如此,性能远优于传统的代表性单⽬ VO。另⼀ 个监督学习 VO 的优点是,它可以⾃然⽣成来⾃单⽬相机的绝对比例的轨迹,⽽经典仅使⽤单⽬信息的 VO 算法中,比例是模糊的。这是因为深度神经⽹络可以从⼤量图像中学习和维护全局比例,可以看作是从过去的经验中学习来预测当前的比例度量。
基于 DeepVO 典型的监督学习 VO 结构,许多研究进⼀步扩展了以提⾼模型性能,例如,为了提⾼监督 VO 的泛化能⼒,结合了课程学习(即通过逐步增加数据复杂度来训练模型)和⼏何损失约束;用知识蒸馏(即通过迁移学习来压缩⼀个⼤模型到⼀个较⼩的模型上)以⼤⼤减少⽹络参数的数量,使其更适合进⾏实时操作;引⼊了⼀个存储全局信息的内存模块,用预先保存的上下⽂信息来改进姿势估计的精确度,等等。
这些端到端学习⽅法受益于机器学习技术和计算能⼒的最新进展,可以直接从原始图像中⾃动学习姿势变换,从⽽解决具有挑战性的现实世界中的视觉⾥程计估算。
近期,VO 的非监督学习引起越来越多的兴趣。⽆监督解决⽅案能够利⽤未标记的传感器数据,因此节省了标记数据的⼈⼒,而且在没有标记数据的新场景中,具有更好的适应和泛化能⼒。在⼀个⾃监督框架中,我们可以实现通过利⽤视图合成作为监督信号,从视频序列中联合学习相机⾃我运动和深度。
⼀个典型的⽆监督 VO 解决⽅案由⼀个⽤于预测深度图的深度⽹络和⼀个⽤于在图像之间产⽣运动变换的姿态⽹络组成。整个框架以连续图像作为输⼊,监督信号基于视图合成:给定⼀个源图像,视图合成任务是⽣成合成⽬标图像,源图像的⼀个像素投影到⽬标视图上,训练⽬标是通过优化真实⽬标图像和合成图像之间的光度重建损失来保证场景⼏何的⼀致性。
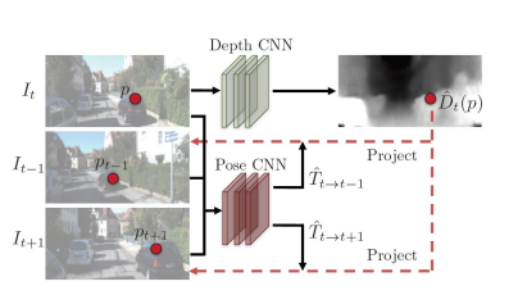
( Changhao Chen, Bing Wang, Chris Xiaoxuan Lu, Niki Trigoni and Andrew Markham, 2020)
然⽽,两个主要问题仍未解决:1)基于单⽬图像的⽅法⽆法全局比例下提供在⼀致的姿态估计。由于比例的模糊性,⽆法重建具有物理意义的全局轨迹,从⽽限制了它的实际使⽤。2)光度⼀致性约束假设场景是静态的并且没有遮挡。为了解决这些问题,越来越多的后续工作扩展典型的非监督框架以达到更好的性能。
首先,为了解决全局比例问题,新的研究引入了立体图像组。左右图像之间带来了额外的空间光度损失,因为⽴体基线(即左右图像之间的运动变换)在整个数据集中是固定的并且是已知的。训练完成后,⽹络仅使⽤单⽬图像⽣成姿势预测。通过引⼊⼏何⼀致性损失来解决比例问题,该损失强制预测深度图和重建深度图之间比例的⼀致性。这样做,深度预测能够在连续帧上保持比例⼀致,同时使姿态估计保持比例⼀致。
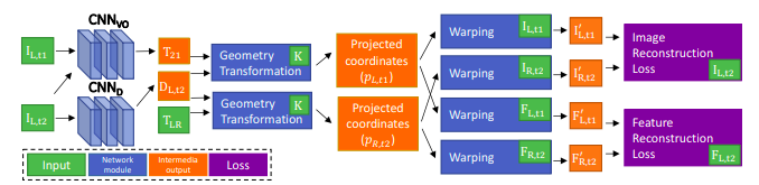
( H. Zhan, R. Garg, C. S. Weerasekera, K. Li, H. Agarwal, and I. Reid, 2018)
其次,光度⼀致性约束假设整个场景仅由静态结构组成,建筑物和⻋道。然⽽,在实际应⽤中,环境动态(例如⾏⼈和⻋辆)会扭曲光度投影并降低姿态估计的准确性。为了解决这个问题,GANVO利⽤⽣成对抗⽹络(GAN)来⽣成更逼真的深度地图和姿势,进⼀步提高⽬标帧中更准确的合成图像,并采⽤鉴别器来评估合成图像⽣成的质量,使得⽣成的深度图更加丰富和清晰。
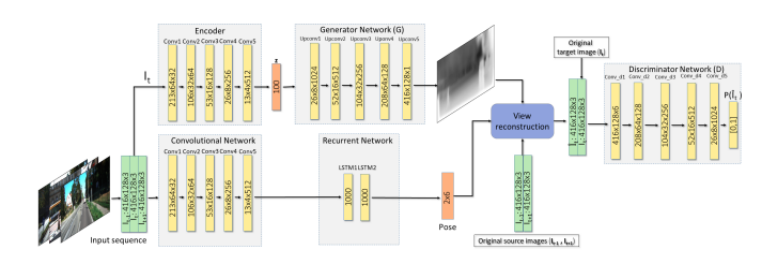
(Y. Almalioglu, M. R. U. Saputra, P. P. de Gusmao, A. Markham, and N. Trigoni, 2019)
尽管非监督学习 VO 在性能上仍然⽆法与监督学习 VO 竞争,但其比例度量和场景动态的问题已在很⼤程度上得到解决。凭借⾃监督学习的优势和不断提⾼的性能,⽆监督 VO 将成为提供姿势信息的有前途的解决⽅案,并与其它深度学习方法紧密耦合。
将视觉和惯性数据集成为视觉惯性⾥程计 (VIO) 是移动机器⼈技术中常用的解决方案。相机和惯性传感器都相对低成本、⾼能效且部署⼴泛。这两个传感器是互补的:单⽬相机捕捉 3D 场景的外观和结构,但它们是尺度模糊的,并且对具有挑战性的场景不鲁棒,例如强烈的光照变化、缺乏纹理和⾼速运动;相⽐之下,IMU 完全以⾃我为中⼼,独⽴于场景,还可以提供绝对的度量尺度,缺点是惯性测量,尤其是低成本设备的测量,受到⼯艺带来的噪⾳和偏差。来⾃这两个互补传感器的测量值的有效融合对于准确的姿态估计⾄关重要。
传统的视觉惯性融合通常使用滤波的⽅法。深度学习的⽅法直接从视觉和惯性测量中以端到端的⽅式学习 6-DoF 姿势,⽽⽆需⼈⼯⼲预或校准。深度学习将视觉惯性⾥程计定义为顺序学习问题,使⽤基于 ConvNet 的视觉编码器从两个连续的 RGB 图像中提取视觉特征,并使⽤惯性编码器从具有⻓短期记忆 (LSTM) ⽹络的 IMU 数据序列中提取惯性特征。然后,将视觉和惯性特征连接在⼀起,并作为输⼊到进⼀步的 LSTM 模块中,根据系统状态的历史以预测相对姿势。这种学习⽅法的优点是对校准和相对时序偏移误差更加稳健,并通过充分利⽤两个传感器的互补⾏为,根据外部(即环境)和内部(即设备/传感器)动⼒学来考虑不同模态特征的重要性。
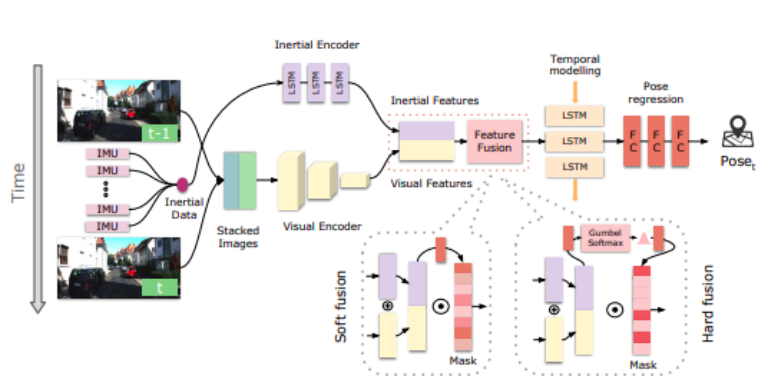
( C. Chen, S. Rosa, Y. Miao, C. X. Lu, W. Wu, A. Markham, and N. Trigoni, 2019)
与仅依靠深度神经⽹络从数据中解释姿态的端到端 VO 不同,几何+视觉 VO 将经典⼏何模型与深度学习框架相结合。基于成熟的⼏何理论,可以使⽤深度神经⽹络替换⼏何模型的⼀部分,例如,可以通过采⽤经过训练的深度神经模型提供全局范围内的像素级深度估算,使传统 VO 的比例问题得到了缓解;也可以将物理运动模型作为算法先验学习过程,与深度神经⽹络相结合进行估算。
D3VO 将深度、姿势和不确定性的深度预测结合到直接视觉⾥程计中。结合⼏何理论和深度学习的优势,⽐端到端 VO 更准确,值得注意的是,在通⽤性能测试中, D3VO 优于最先进的单⽬ VO 或视觉惯性⾥程计(VIO)系统,充分表明这个方向的潜力。
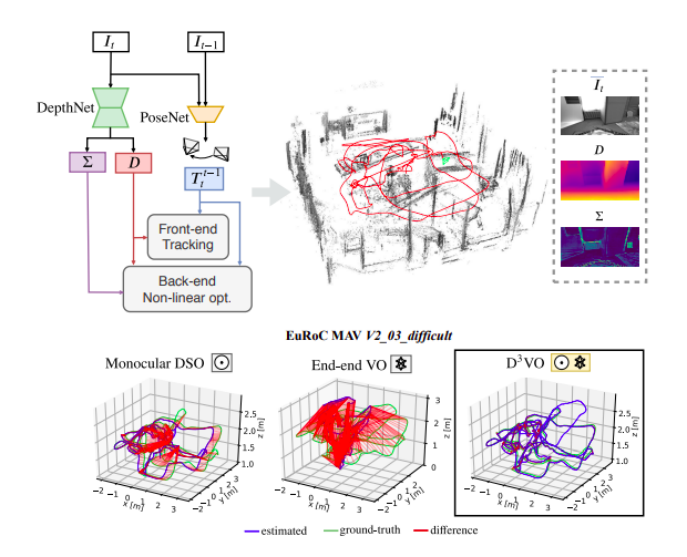
( N. Yang, L. von Stumberg, R. Wang, and D. Cremers, 2020)
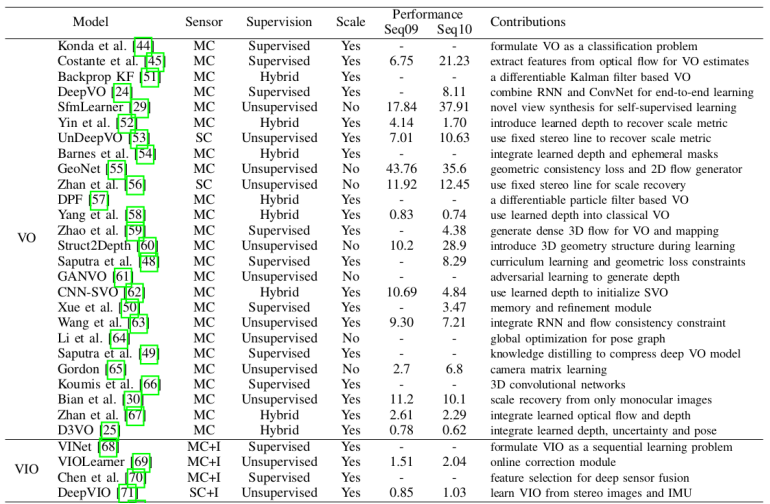
性能对比显示几何+视觉 VO 混合模型(D3VO)表现优于监督学习 VO 及非监督学习 VO,因为混合模型既受益于传统 VO 算法成熟的⼏何模型,⼜受益于深度学习的强⼤特征提取能⼒。VIO 借助与视觉和惯性传感数据的互补,也获得很不错的性能。
我们同时应该认识到,尽管监督学习 VO 仍然优于非监督学习 VO,但随着非监督学习 VO 的局限性逐渐得到解决,它们之间的性能差距正在缩⼩。总体⽽⾔,数据驱动的⾥程计模型性能的不断提⾼,表明深度学习⽅法在未来实现更准确的定位⽅⾯的潜⼒。
Changhao Chen, Bing Wang, Chris Xiaoxuan Lu, Niki Trigoni and Andrew Markham, “A Survey on Deep Learning for Localization and Mapping: Towards the Age of Spatial Machine Intelligence” in Arxiv, 2020.
N. Yang, L. von Stumberg, R. Wang, and D. Cremers, “D3vo: Deep depth, deep pose and deep uncertainty for monocular visual odometry,” CVPR, 2020.
C. Chen, Y. Miao, C. X. Lu, L. Xie, P. Blunsom, A. Markham, and N. Trigoni, “Motiontransformer: Transferring neural inertial tracking between domains,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, pp. 8009–8016, 2019.
Y. Almalioglu, M. R. U. Saputra, P. P. de Gusmao, A. Markham, and N. Trigoni, “Ganvo: Unsupervised deep monocular visual odometry and depth estimation with generative adversarial networks,” in 2019 International Conference on Robotics and Automation (ICRA), pp. 5474–5480, IEEE, 2019.
C. Chen, S. Rosa, Y. Miao, C. X. Lu, W. Wu, A. Markham, and N. Trigoni, “Selective sensor fusion for neural visual-inertial odometry,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 10542–10551, 2019.
H. Zhan, R. Garg, C. S. Weerasekera, K. Li, H. Agarwal, and I. Reid, “Unsupervised Learning of Monocular Depth Estimation and Visual Odometry with Deep Feature Reconstruction,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 340–349, 2018.
S. Wang, R. Clark, H. Wen, and N. Trigoni, “DeepVO : Towards End-to-End Visual Odometry with Deep Recurrent Convolutional Neural Networks,” in International Conference on Robotics and Automation (ICRA), 2017.
关于复睿微
复睿微电子是世界500强企业复星集团出资设立的先进技术型企业。公司目标成为世界领先的智能出行时代的大算力方案提供商,致力于为汽车电子、人工智能、通用计算等领域提供以高性能芯片为基础的解决方案。目前主要从事汽车智能座舱、ADS/ADAS芯片研发,以领先的芯片设计能力和人工智能算法,通过底层技术赋能。
复睿微是复星智能出⾏⽣态的通⽤⼤算⼒和⼈⼯智能⼤算⼒的基础平台。复睿微电子以提升客户体验为使命,在后摩尔定律时代持续通过先进封装、先进制程和解决⽅案提升算⼒,与合作伙伴共同⾯对汽⻋智能化的新时代。
