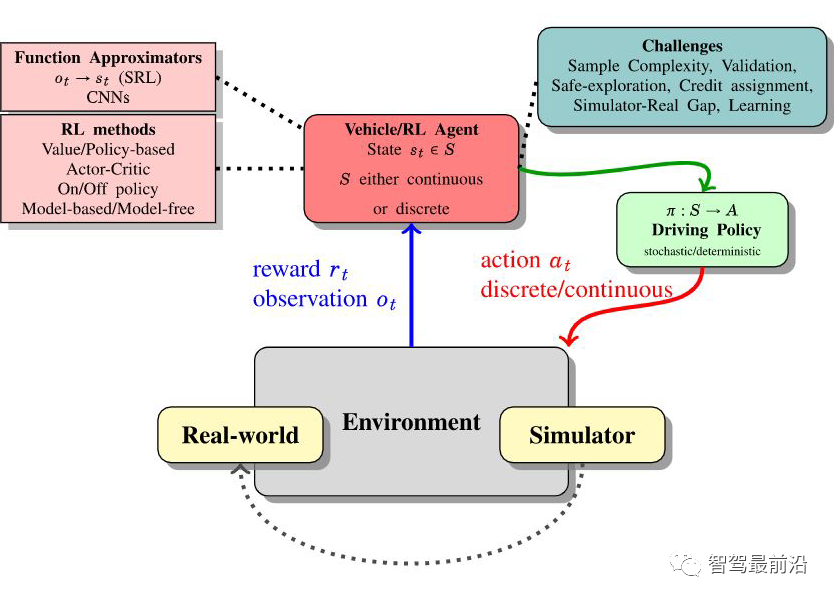
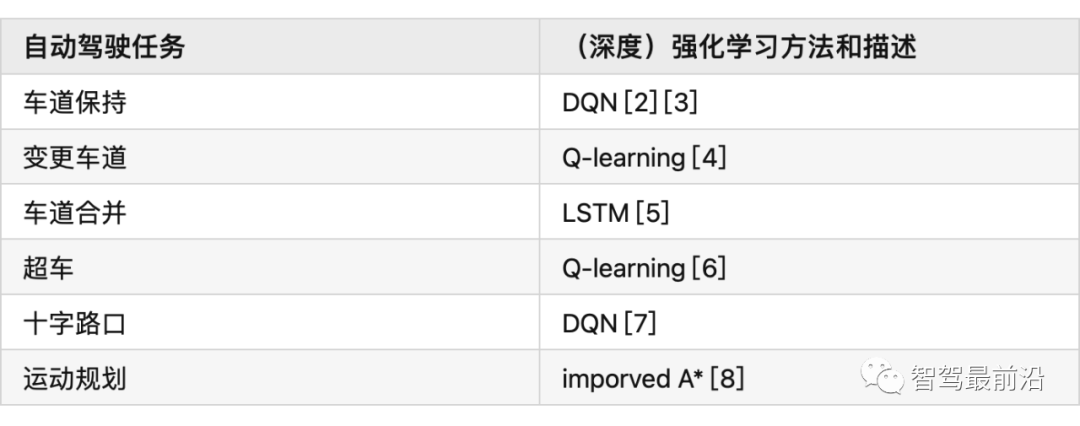
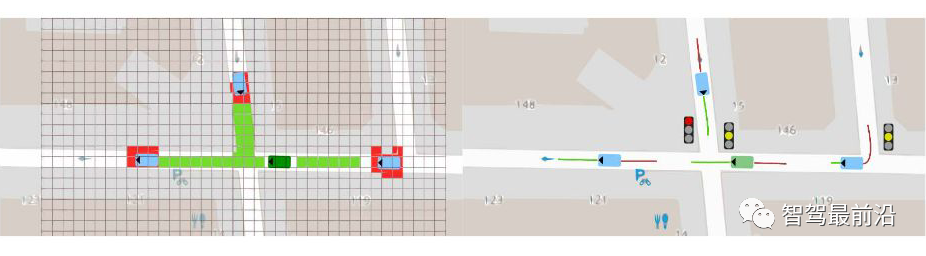
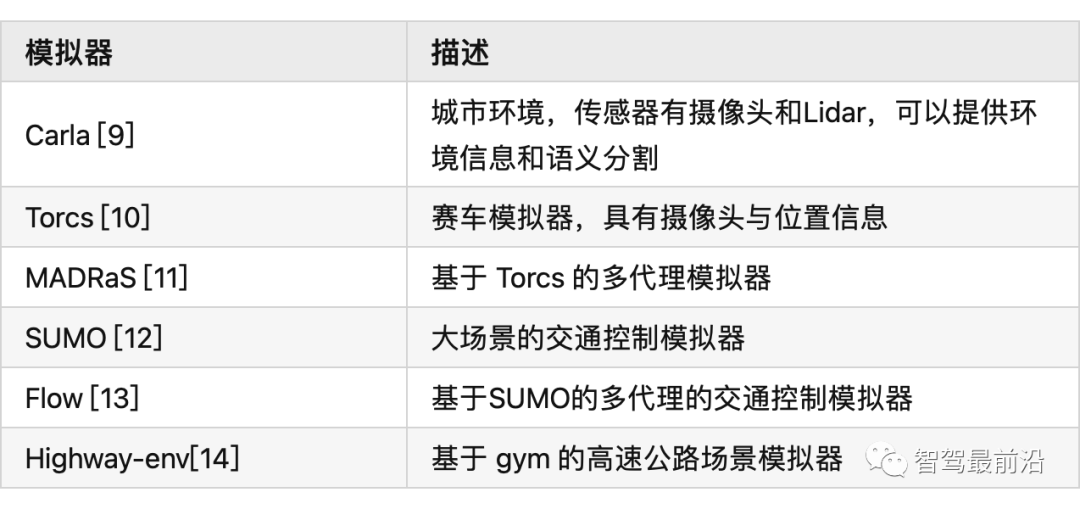
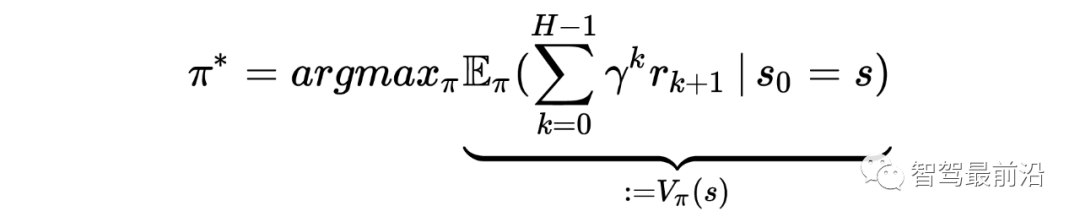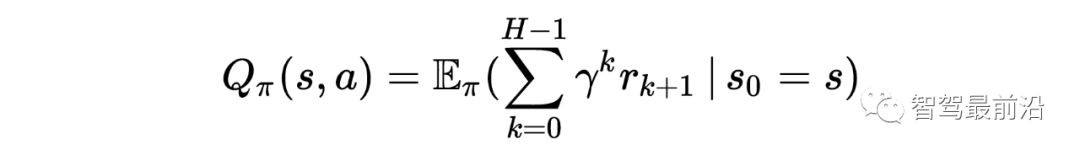在自动驾驶中,RL 可以完成的任务有:控制器优化、路径规划和轨迹优化、运动规划和动态路径规划、为复杂导航任务开发高级驾驶策略、高速公路、交叉路口、合并和拆分的基于场景的策略学习,预测行人、车辆等交通参与者的意图,并最终找到确保安全和执行风险估计的策略。状态空间、动作空间和奖励为了成功地将 DRL 应用于自动驾驶任务,设计适当的状态空间、动作空间和奖励函数非常重要。状态空间自动驾驶汽车常用的状态空间特征包括:本车的位置、航向和速度,以及本车的传感器视野范围内的其他障碍物。此外,我们通常使用一个以自主车辆为中心的坐标系,并在其中增强车道信息,路径曲率、自主的过去和未来轨迹、纵向信息等。我们通常会使用一个鸟瞰图来展示这些信息。▲ 鸟瞰图动作空间自主车辆的控制策略需要操纵一系列执行器,比如方向盘,油门和刹车(暂时不考虑其他的执行器)。有一点需要注意的是,这些控制器都是在连续空间中运行的,而大多数 DRL 控制器属于离散空间。因此我们需要选择合适的时间步长。奖励为自动驾驶的 DRL 代理设计奖励函数仍然是一个悬而未决的问题。AD 任务的标准示例包括:向目的地行驶的距离 、本车的速度、使本车保持静止、与其他道路使用者或场景对象的碰撞,人行道上的违规行为,保持在车道上,保持舒适和稳定性,同时避免极端加速、制动或转向,并遵守交通规则。运动规划和轨迹优化运动规划是确保目标点和目的地点之间存在路径的任务。但是动态环境和变化的车辆动力学中的路径规划是自动驾驶中的一个难题,比如通过十字路口,或者并入高速公路。有许多文章在这方面做了尝试,并获得了不错的效果,比如论文 [4] [5] [6] [7]。模拟器和场景生成工具自动驾驶数据集使用包含图像、标签对的训练集来处理监督学习设置,用于各种模式。强化学习需要一个可以恢复状态-动作对的环境,同时分别对车辆状态、环境以及环境和代理的运动和动作的随机性进行建模。各种模拟器被积极用于训练和验证强化学习算法。具体信息如下:参考文献[1] A Survey of Deep Learning Applications to Autonomous Vehicle Control:https://ieeexplore.ieee.org/abstract/document/8951131?casa_token=fwUZxwU0Eo8AAAAA:B[2] End-to-End Deep Reinforcement Learning for Lane Keeping Assist:https://arxiv.org/abs/1612.04340[3] Deep Reinforcement Learning framework for Autonomous Driving:https://www.ingentaconnect.com/content/ist/ei/2017/00002017/00000019/art00012[4] A Reinforcement Learning Based Approach for Automated Lane Change Maneuvers:https://ieeexplore.ieee.org/abstract/document/8500556?casa_token=OcyB7gHOxcAAAAAA:JrwO6[5] Formulation of deep reinforcement learning architecture toward autonomous driving for on-ramp merge:https://ieeexplore.ieee.org/abstract/document/8317735?casa_token=HaEyBLwaSU0AAAAA:5[6] A Multiple-Goal Reinforcement Learning Method for Complex Vehicle Overtaking Maneuvers:https://ieeexplore.ieee.org/abstract/document/5710424?casa_token=Y-bJbe3K9r0AAAAA:ZNo[7] Navigating Occluded Intersections with Autonomous Vehicles Using Deep Reinforcement Learning:https://ieeexplore.ieee.org/abstract/document/8461233?casa_token=uuC5uVdLp60AAAAA:6fr7[8] Reinforcement Learning with A* and a Deep Heuristic:https://arxiv.org/abs/1811.07745[9] CARLA: An Open Urban Driving Simulator:https://proceedings.mlr.press/v78/dosovitskiy17a.html[10] TORCS - The Open Racing Car Simulator:https://sourceforge.net/projects/torcs/[11] MADRaS Multi-Agent DRiving Simulato:https://www.opensourceagenda.com/projects/madras[12] Microscopic Traffic Simulation using SUMO:https://ieeexplore.ieee.org/abstract/document/8569938?casa_token=1z4z-bT6kTsAAAAA:BdTO6tJB4xEgr_EO0CPveWlForEQHJWyprok3uyy3DssqzT-7Eh-pr7H__3DOJPDdpuIVUr7Lw[13] Flow: Architecture and Benchmarking for Reinforcement Learning in Traffic Control:https://www.researchgate.net/profile/Abdul-Rahman-Kreidieh/publication/320441979_Flow_Archite
1. 在Ubuntu官网下载Ubuntu server 20.04版本https://releases.ubuntu.com/20.04.6/2. 在vmware下安装Ubuntu3. 改Ubuntu静态IP$ sudo vi /etc/netplan/00-installer-config.yaml# This is the network config written by 'subiquity'network: renderer: networkd&nbs