-- 关注 回复“ SOA ” --
↓ ↓领取:面向智能车辆开发的开放性SOA方案↓↓
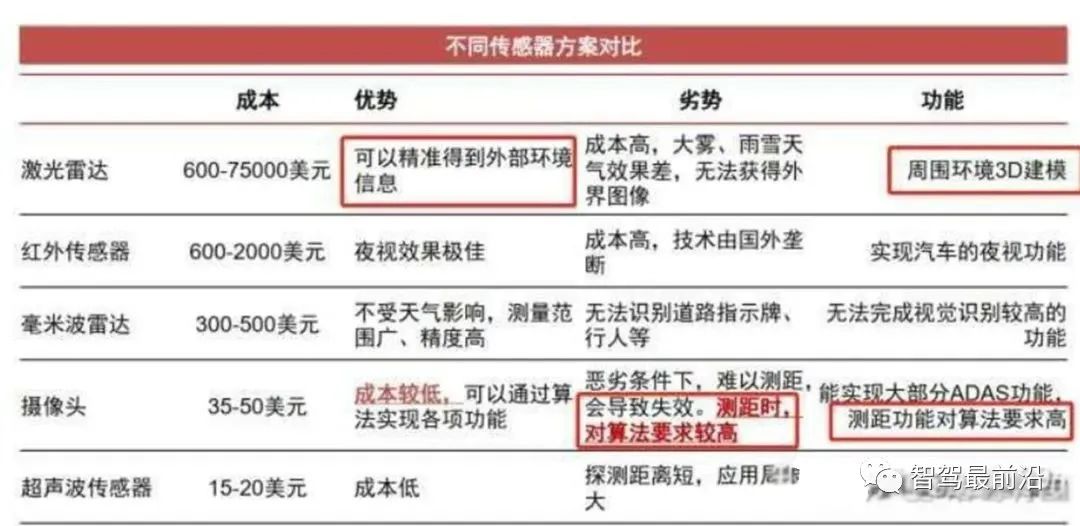
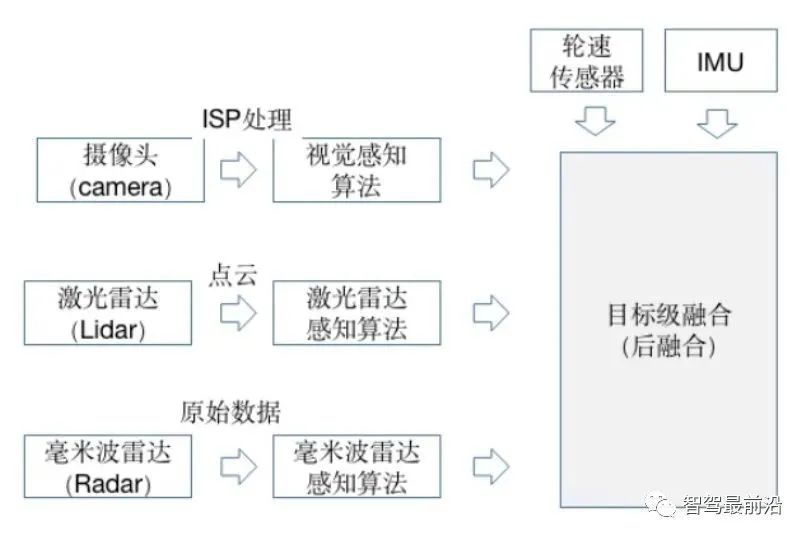
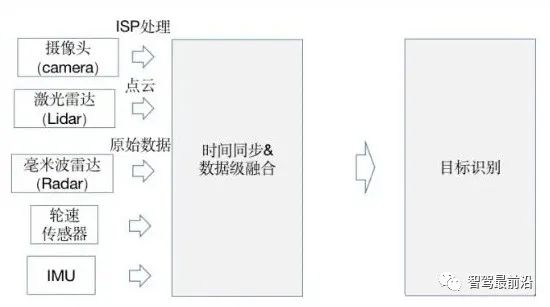
感知是什么? 在自动驾驶赛道中,感知的目的是为了模仿人眼采集相关信息,为后续做决策提供必要的信息。根据所做决策的任务不同,感知可以包括很多子任务:如车道线检测、3D目标检测、障碍物检测、红绿灯检测等等;再根据感知预测出的结果,完成决策;最后根据决策结果执行相应的操作(如变道、超车等); 如何进行感知? 由于感知是为了模仿人眼获取周围的环境信息,那就必然需要用到传感器来完成信息的采集工作;目前在自动驾驶领域中用到的传感器包括:摄像头(camera)、激光雷达(lidar)、毫米波雷达(radar)等; 可以看到传感器的种类众多且成本参差不齐,所以如何使用这些传感器进行感知任务,各个自动驾驶厂商都有各自的解决方案; 纯视觉感知方案的优缺点也很明显:优点:价格成本很低;缺点:摄像头采集到的图片是2D的,缺少深度信息,深度信息需要靠算法学习得到,缺少鲁棒性; 目前大多数厂商采用的都是多传感器融合的解决方案;其优缺点是:优点:能够充分利用不同工作原理的传感器,提升对不同场景下的整体感知精度,也可以在某种传感器出现失效时,其他传感器可以作为冗余备份,提高系统的鲁棒性;缺点:由于采用多种传感器价格相比纯视觉高很多; 多传感器融合的感知方案 所谓后融合,是指各传感器针对目标物体单独进行深度学习模型推理,从而各自输出带有传感器自身属性的结果;每种传感器的识别结果输入到融合模块,融合模块对各传感器在不同场景下的识别结果,设置不同的置信度,最终根据融合策略进行决策。 图源:https://mp.weixin.qq.com/s/bmy9EsQaLNPQQKt9mPTroA 优点:不同的传感器都独立进行目标识别,解耦性好,且各传感器可以互为冗余备份;同时后融合方案便于做标准的模块化开发,把接口封装好,提供给主机厂“即插即用”;对于主机厂来说,每种传感器的识别结果输入到融合模块,融合模块对各传感器在不同场景下的识别结果,设置不同的置信度,最终根据融合策略进行决策。 缺点:存在“时间上的感知不连续”及“空间上的感知碎片化” 由于车身四周的lidar、camera角度的安装问题,多个传感器实体无法实现空间域内的连续覆盖和统一识别,导致摄像头只捕捉到了目标的一小部分,无法根据残缺的信息作出正确的检测结果,从而使得后续的融合效果无法保证。 摄像头采集到的结果是以帧为单位的,常用的感知方法是把连续单帧的检测结果串联起来,类似后融合的策略,无法充分利用时序上的有用信息。 所谓前融合,是将各个传感器采集到的数据汇总到一起,经过数据同步后,对这些原始数据进行融合。 图源:https://mp.weixin.qq.com/s/bmy9EsQaLNPQQKt9mPTroA 优点:让数据更早的做融合,使数据更有关联性;比如把激光雷达的点云数据和摄像头的像素级数据进行融合,数据的损失也会比较少。 缺点:由于不同传感器获取的数据(摄像图获取的像素数据以及激光雷达获取的点云数据),其坐标系是不同的;视觉数据是2D空间,而激光雷达的点云数据是3D空间。所以在异构数据的融合时,有两种途径:途径一:在图像空间利用点云数据提供深度信息;途径二:在点云空间利用视觉数据提供语义特征,进行点云染色或特征渲染; 图源:https://mp.weixin.qq.com/s/bmy9EsQaLNPQQKt9mPTroA 所以为了保证将不同坐标系下的数据(像素数据、点云数据)转换到同一坐标系下进行数据融合方便后续的感知任务,BEV(Bird Eye View)视角下的感知逐渐受到广泛的关注。 所谓中融合,就是先将各个传感器采集到的数据通过神经网络提取数据的特征,再对神经网络提取到的多种传感器特征进行特征级的融合,从而更有可能得到最佳感知结果。对异构数据提取到的特征在BEV空间进行特征级的融合,一来数据损失少,二来算力消耗也较少(相对于前融合),所以针对BEV视角下的感知任务,采用中融合的策略比较多。 BEV视角下的感知任务范式 将摄像头数据(2D图片)输入到特征提取网络中完成多个摄像头数据的特征提取; 将所有摄像头数据提取到的特征通过网络学习的方式映射到BEV空间下; 在BEV空间下,进行异构数据的融合,将图像数据在BEV空间下映射的特征与激光雷达点云特征进行融合;(可选,如BEVFormer仅用6个摄像头构建BEV空间特征) 进行时序融合,融合前几个时刻的特征,增强感知能力;(个人认为:引入时序特征后可以在一定程度上解决遮挡问题) 根据获得到BEV特征,用于下游任务;(车道线检测、障碍物检测、3D目标检测等子任务,相当于整个模型是一个多任务学习模型) BEV视角下的感知具有的优势 跨摄像头融合或者异构数据进行融合时,由于不同数据其表示的坐标系不同,需要用很多后处理规则去关联不同传感器的感知结果,流程非常复杂。在BEV空间内做融合后,通过网络自主学习映射规则,产生BEV特征用于感知下游任务,算法实现更加简单,并且BEV空间内视觉感知到的物体大小和朝向也都能直接得到表达。 在构建BEV空间时,可以很容易地融合时序信息,使得获取的BEV特征可以更好地实现下游的一些感知任务,如测速任务。 传统的2D感知任务只能感知看得见的目标,对于遮挡完全无能为力,而在BEV空间内,可以基于先验知识或者利用时序融合,对被遮挡的区域进行预测,从而“脑补”出被遮挡区域可能存在物体。虽然“脑补”出的物体,有一定“想象”的成分,但这对于下游的规控模块仍有很多好处。 使用传统方法做感知任务时,需要依次做目标识别、追踪和运动预测,更像是个“串行系统”,上游的误差会传递到下游从而造成误差累积;而在BEV空间内,感知和运动预测在统一空间内完成,因而可以通过神经网络直接做端到端优化,“并行”出结果,这样既可以避免误差累积,也大大减少了人工逻辑的作用,让感知网络可以通过数据驱动的方式来自学习,从而更好地实现功能迭代。 转载自 知乎@zhFang1999 ,文中观点仅供分享交流,不代表本公众号立场,如涉及版权等问题,请您告知,我们将及时处理。
-- END --