

嵌入式Linux开发中,使用gdb对core文件进行调试是一种有效的定位程序崩溃的方法。这种方法在之前的文章《C开发中段错误的3种调试方法》中也有简单提过,不了解的小伙伴可以参考一下。
有些知识,在没用到之前,可以简单地进行了解;等实际用的时候,再去详细地学习。最近我在实际工作中使用了gdb对core文件进行调试,遇到了一些问题,今天特意总结出来分享给大家。
以下是本文分享的几个知识点:
什么是core文件?
前台进程如何生成core文件?
后台进程如何生成core文件?
如何调试core文件?
崩溃栈有用信息有限的可能原因?
在Linux下,一个程序崩溃时,它一般会在指定目录下生成一个core文件。core文件仅仅是一个内存映象(同时加上调试信息),主要是用来调试的。
实际中,我们的程序可以运行于前台,也可以运行于后台。前、后台运行程序,生成core文件的方法有些不同。
前台进程:一般而言,用户在shell中使用./执行的程序都是前台程序,前台程序可由用户自己控制,程序运行过程中可与用户进行交互,其运行优先级相比后台程序稍高,前台程序运行过程中用户可使用ctrl+c来终止。
core文件配置基本命令:
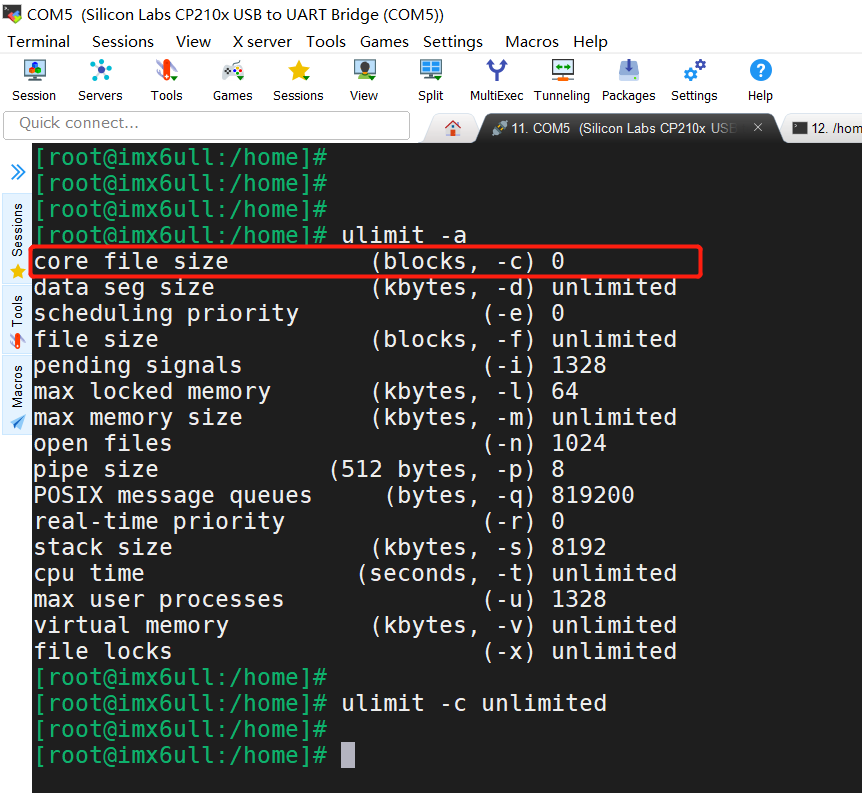
ulimit -c # 查看core文件是否打开
ulimit -a # 也可以查看core文件是否打开
ulimit -c 0 # 禁止产生core文件
ulimit -c unlimited #设置core文件大小为不限制大小
ulimit -c 1024 #限制产生的core文件的大小不能超过1024KB
core文件的转储文件目录和命名规则是可以设置的。
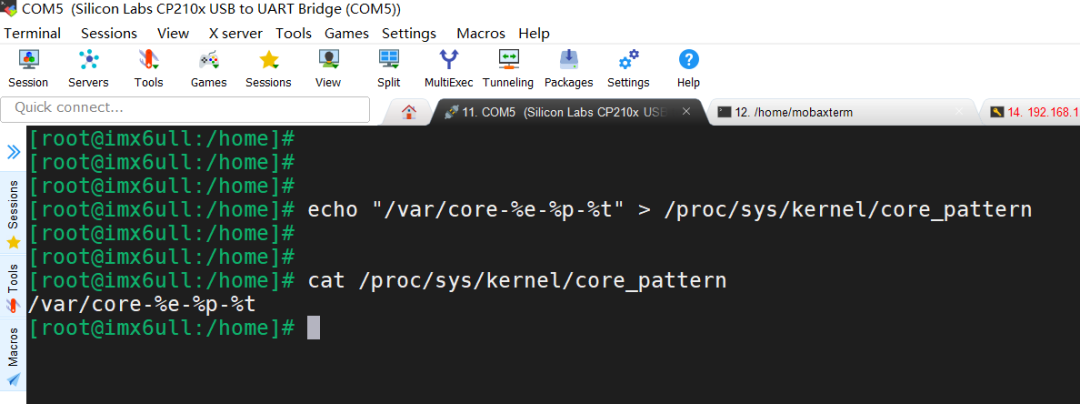
通过配置/proc/sys/kernel/core_uses_pid可以控制产生的core文件的文件名中是否添加pid作为扩展;
通过配置/proc/sys/kernel/core_pattern可以设置格式化的core文件保存位置或文件名。
比如:
echo "1" > /proc/sys/kernel/core_uses_pid
echo "/var/core-%e-%p-%t" > /proc/sys/kernel/core_pattern
参数%e、%p、%t表示的意思如:
%p - insert pid into filename 添加pid
%u - insert current uid into filename 添加当前uid
%g - insert current gid into filename 添加当前gid
%s - insert signal that caused the coredump into the filename 添加导致产生core的信号
%t - insert UNIX time that the coredump occurred into filename 添加core文件生成时的unix时间
%h - insert hostname where the coredump happened into filename 添加主机名
%e - insert coredumping executable name into filename 添加可执行程序名
下面开始进行实操:
查看core文件是否有打开,并设置core文件大小为不限制大小:
设置格式化的core文件保存位置或文件名:
测试代码:
#include
int main(int argc, char **argv)
{
printf("==================segmentation fault test==================\n");
int *p = NULL;
*p = 1234;
return 0;
}
运行测试程序生成core文件:
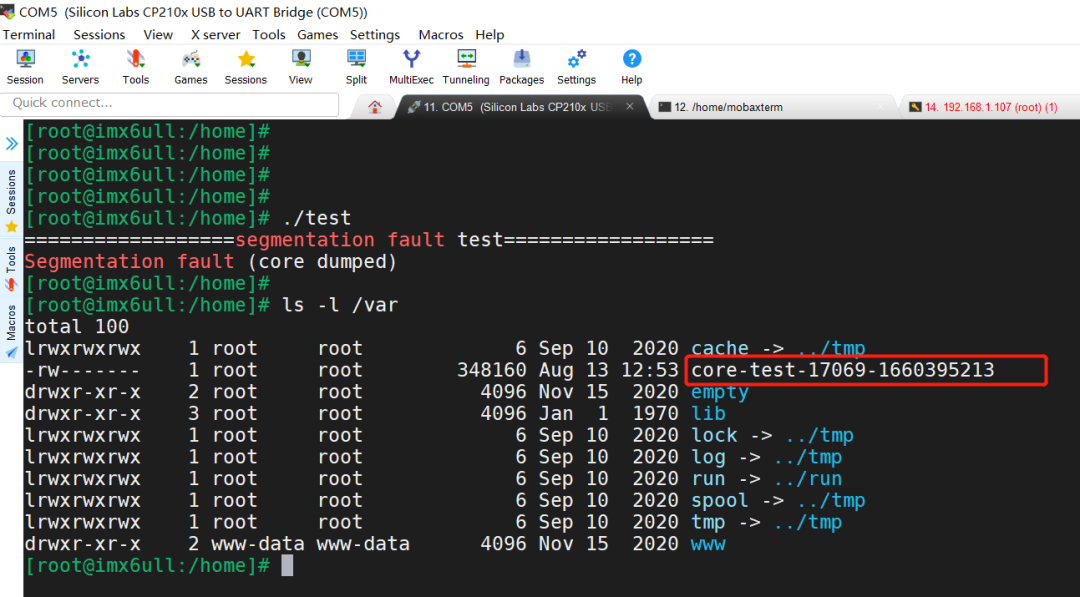
后台程序生成core文件的方式与前台程序不一样。这我也是前几天才知道的,我们设备上的程序设置为开机自启动运行于后台,程序崩溃时,竟然没有生成core文件。后来查了些资料才知道后台程序打开core文件的方式不同。
后台进程:后台进程又叫守护进程,是运行在系统后台的一种特殊进程,它独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件,后台进程最大的特点就是不受终端控制。一般用作系统服务,比如日志管理进程rsyslogd,数据库服务myspld等,当然也有一些用户程序因需要被放在后台运行,一般被放在/etc/ini.d/文件夹中设置开机自启动。
ulimit命令是有作用范围的,ulimit限制的是当前shell进程以及其派生的子进程,所以通过ulimit修改coresize只是针对在当前shell下启动的子进程,而不能影响其他shell下启动的进程。
所以当我们配置完成生成core dump的参数后,在当前shell直接执行的进程发生崩溃时可以正常生成core,而后台开机自启动的程序则无法生成,而实际总,嵌入式应用程序一般都是开机自启动的,并且发送崩溃的时机也是不可预测的,那么使用这种方式就不能正确的去捕捉coredump文件了。
后台进程要生成core dump文件需在进程代码中开启core dump功能,如:
左右滑动查看全部代码>>>
// 公众号:嵌入式大杂烩
#include
#include
#include
#include
#define SHELL_CMD_CONF_CORE_FILE "echo /var/core-%e-%p-%t > /proc/sys/kernel/core_pattern"
#define SHELL_CMD_DEL_CORE_FILE "rm -f /var/core*"
static int enable_core_dump(void)
{
int ret = -1;
int resource = RLIMIT_CORE;
struct rlimit rlim;
rlim.rlim_cur = 1 ? RLIM_INFINITY : 0;
rlim.rlim_max = 1 ? RLIM_INFINITY : 0;
system(SHELL_CMD_DEL_CORE_FILE);
if (0 != setrlimit(resource, &rlim))
{
printf("setrlimit error!\n");
return -1;
}
else
{
system(SHELL_CMD_CONF_CORE_FILE);
printf("SHELL_CMD_CONF_CORE_FILE\n");
return 0;
}
return ret;
}
int main(int argc, char **argv)
{
enable_core_dump();
printf("==================segmentation fault test==================\n");
int *p = NULL;
*p = 1234;
return 0;
}
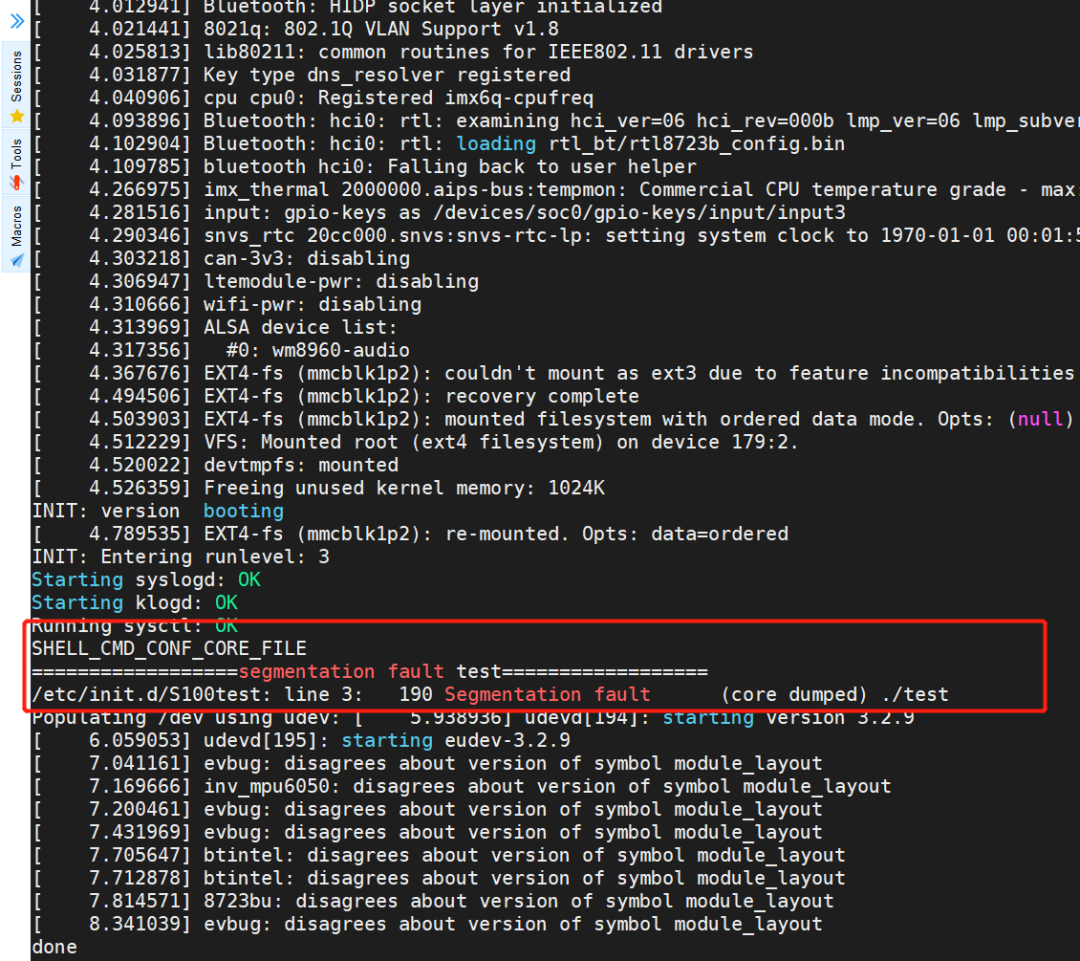
让程序开机运行于后台:
在开发板/etc/init.d/目录下新建文件S100Test:
#!/bin/sh
cd /home
./test
设置程序开机自启动可参考我们往期文章:《浅析程序开机自启动》
重启设备,程序运行崩溃时可生成core文件:
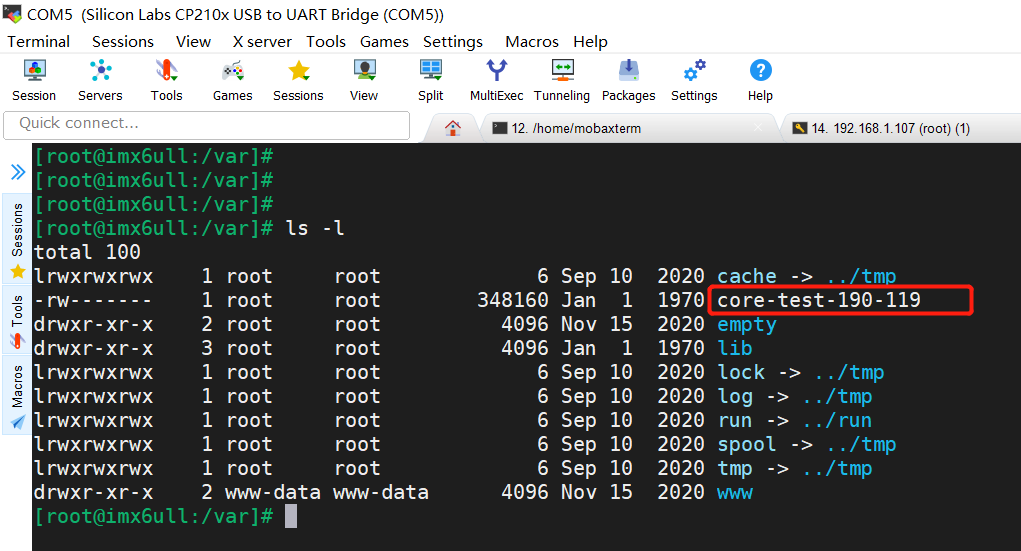
把core文件传到pc端,使用arm-linux-gnueabihf-gdb对test程序进行调试:
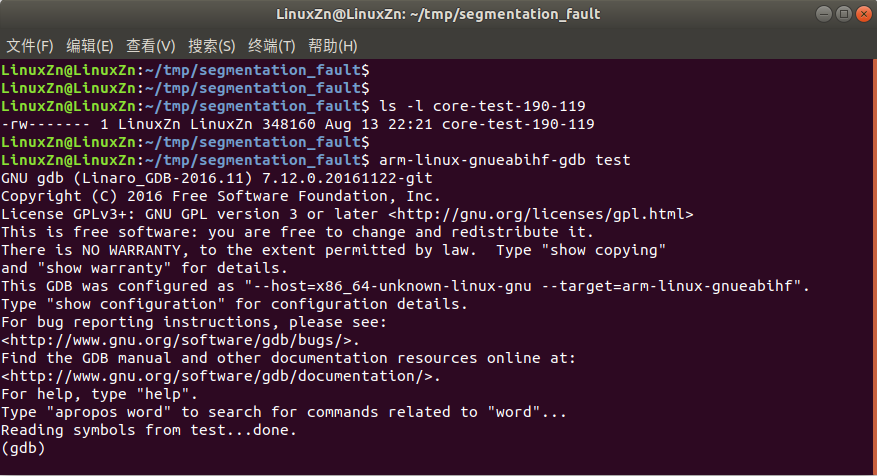
arm-linux-gnueabihf-gdb test
core-file core-test-190-119
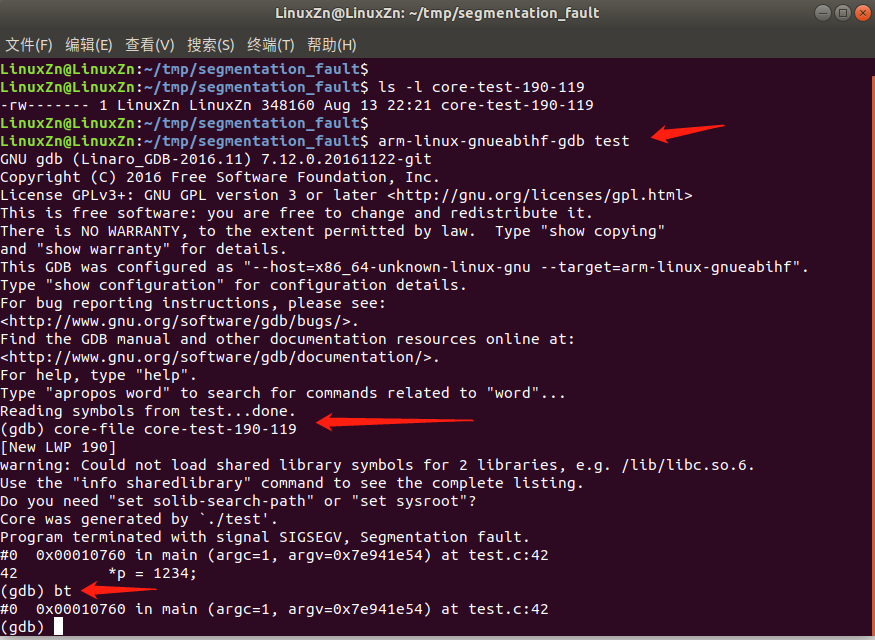
这个demo比较简单,可以很快定位到问题。实际中,我们的程序会依赖很多动态库,这时候在调试时需要设置库的搜索路径。
这些库需要和板子上的库对应上,最好是用板子里的库。可以把板子里用到的库放到PC上的某个路径,假如放到/home/LinuxZn/lib这个路径。
我们进入gdb时,可以输入如下命令设置及查看库信息:
set solib-search-path /home/LinuxZn/lib
info sharedlibrary
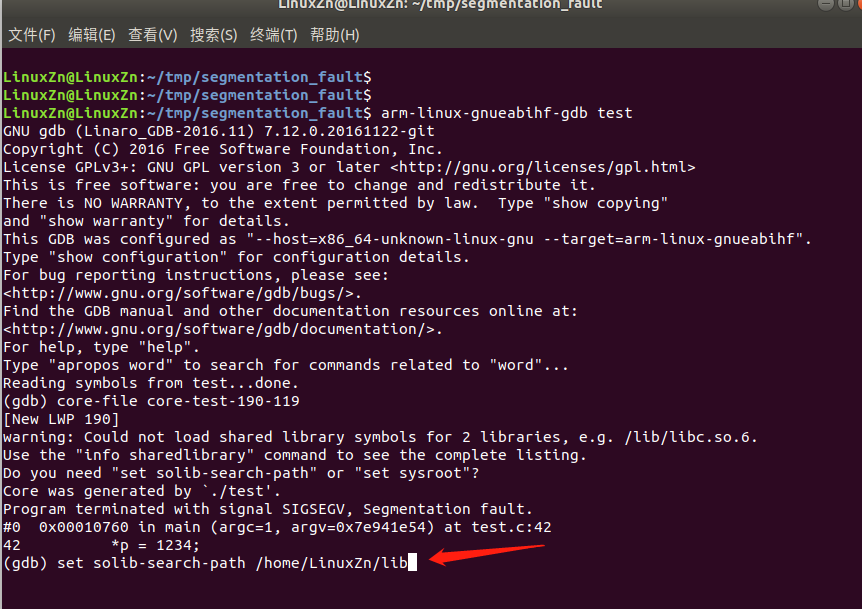
有时候,加载库信息之后,还是看不到有意义的崩溃栈。
有如下两点需要确认:
如果不一致,可以把交叉编译器所使用的libc库更新到板子里。
参考:
https://baijiahao.baidu.com/s?id=1661025717994426637&wfr=spider&for=pc
https://blog.csdn.net/lhl_blog/article/details/106542754
以上就是本次的分享,期待你的三连!
END
