

原文:
https://mp.weixin.qq.com/s/Wr3-rY2iLJwvwhUdyBG7Mw
只发布一部手机就能收工的日子一去不复返了,「雷布斯」正在全力加速转型成为「雷斯克」。去年的这个时候,雷军在 MIX4 发布会的结尾遛了一圈机器狗「铁蛋」,宣布进军仿生四足机器人。昨晚的雷军年度演讲,小米首款「全尺寸人形仿生机器人」正式登场了。只见它徐徐上台,手拿一朵小红花:

姓名「CyberOne」,小名「铁大」,高 1.77 米,重 52kg,狮子座,这是它的基本信息。该说不说,乍一看,「铁大」的运动技能和波士顿动力的 Atlas 相比还有一段距离:

借用一位网友的话,看完最大的感受是:
关于这一点,铁大自己也承认了:「我刚刚学会走路,下盘还不太稳,正在练习扎马步。」
单从它的手部设计来说,目测无法承担太复杂的工作:
不过这只是新项目的一个开始,雷军再次强调了小米在机器人领域的投入和决心:「CyberOne 的 AI 和机械能力都是由小米机器人实验室自主开发的。我们在多个领域投入了大量研发资金,包括软件、硬件和算法创新。」
原文:
https://mp.weixin.qq.com/s/dUQZqQoOFjXpW1_7MG9Z4w

关键是,随着这一波造芯成果而来的,还不只一个大动作。更确切地说,快手这把是直接在业务上开启了完全不同以往的尝试:做了11年ToC产品的快手,现在正式推出视频云服务StreamLake,宣告进军云服务市场。
要说清楚这事儿,咱们得先来看看快手这个StreamLake究竟是怎么一回事。StreamLake可以说是一套覆盖底层基础设施到上层场景解决方案的“视频操作系统”。其能力主要体现在Video和AI两个方面。其中,Video侧重视频制作、传输、分发在内的全链路视频能力。AI侧重智能视频创作、智能视频内容理解、数字人等技术领域。

与许多云服务商相似的是,快手视频云服务的雏形,最早也诞生于自家业务之中。对于快手而言,从2015年的千万级日活跃用户数到2022年第一季度日活接近3.5亿,期间面对的是内部业务的爆炸式增长。因此,快手的技术中台化进程也开始得很早。
原文:
https://xw.qq.com/amphtml/20220809A08YY400
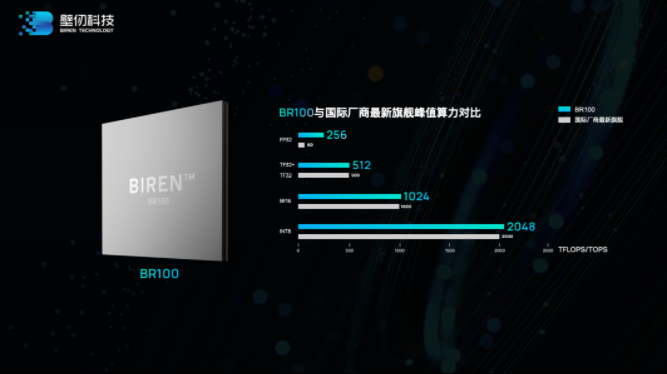
芯东西8月9日报道,今日下午,上海GPU独角兽企业壁仞科技推出首款面向云端人工智能(AI)训练及推理的通用GPU算力产品BR100系列,其旗舰产品的峰值算力超过了英伟达目前在售的旗舰计算产品A100 GPU的3倍。
“全球通用GPU算力记录,第一次由一家中国企业创造。”在发布会上,壁仞科技创始人、董事长、CEO张文宣布,“中国通用GPU芯片进入每秒1,000,000,000,000,000次计算新时代。”
壁仞科技成立于2019年9月9日,再过一个月,就是其三周年的纪念日。团队总共经过1065个日日夜夜的奋战,这才有了这款大算力芯片的诞生。在此之际,张文也宣布他的下一个小目标:“百年基业长青”。
BR100芯片采用7nm制程、壁仞原创“壁立仞”芯片架构,容纳近800亿颗晶体管,配备超300MB片上高速SRAM,并应用Chiplet与2.5D CoWoS封装技术,突破了大尺寸芯片制造与封装中的光罩尺寸限制问题,做到高良率与高性能的兼顾。
原文:https://m.thepaper.cn/baijiahao_17225555
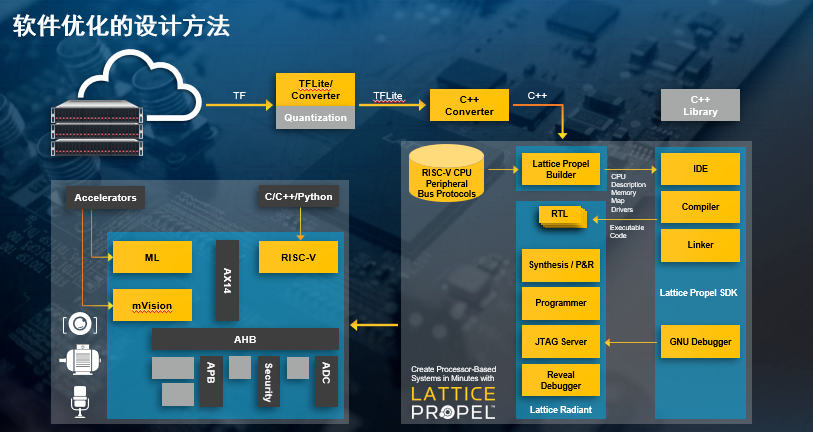
ABI的研究调查表明,预计到2024年设备端的AI推理功能将覆盖近60%的设备。FPGA作为实现边缘AI的技术方式之一受到了青睐。要知道AI的算法灵活多变,FPGA硬件可编程可以适应快速变化的机器学习算法,它可以做灵活的计算资源,包括预处理、后处理、图像处理和滤波等数据。还能进行性能扩展,可实现高速并行处理。因此,我们看到不少FPGA厂商正在大力推动FPGA在边缘计算的应用。
去年莱迪思发布了sensAI 4.1解决方案,当时介绍的一个典型案例是用于PC智能和感知体验。如今,这一方案已经落地于品牌笔记本电脑。凭借其优异特性和不断增强的性能,莱迪思sensAI 4.1解决方案还可广泛应用于工业、安防等众多领域,可挖掘的边缘智能应用非常之多。
Lattice Nexus FPGA和sensAI解决方案集合可用于开发计算机视觉和传感器融合应用,可以提升用户的参与和协作,保护用户隐私,同时可以帮助开发人员实现新颖的AI功能,提高设备的电池寿命。
据测试,与使用CPU来驱动 AI 应用的设备相比,采用 sensAI 开发,并在莱迪思FPGA上运行的 AI 计算设备的电池使用时间延长了28%。sensAI 还支持现场软件更新,从而保持AI算法的演进,还能让OEM厂商灵活选择不同的传感器和SoC技术来适配他们的设备。
比如在用户检测应用上,用户接近或离开设备时会自动启动或关闭客户端设备;注意力追踪:当用户的注意力不在屏幕上时,降低设备的屏幕亮度,节约电量,延长使用时间;面部取景:在视频会议应用中提升视频体验;旁边者检测:检测站在设备后面潜在的窥视者,模糊屏幕以保障数据隐私。
当然,这也需要Lattice和OEM、其他芯片厂商、操作系统和软件支持商,以及传感器厂商合作,共同推动方案落地。据了解,目前莱迪思已与联想合作,ThinkPad X1系列笔记本电脑采用了专为AI优化的软件方案,能够在不损失性能或电池使用时间的情况下提供优化的用户体验,包括沉浸式交互、更好的隐私保护和更高效的协作。LG也在其最新的GRAM系列产品用采用莱迪思AI和计算机视觉解决方案,提升安全和便捷特性。
原文:
https://mp.weixin.qq.com/s/1ih8zHHRW7Wt1Zz0okr8-A
论文地址:
https://arxiv.org/abs/2207.05557
代码地址:
https://github.com/hunto/LightViT
一些轻量级的ViTs工作为增强架构性能,常将卷积操作集成于Transformer模块中。本文为探讨卷积对轻量级ViTs的必要性,设计了一种无卷积的轻量级ViTs架构LightViT,提出一种全局而高效的信息聚合方案。除了在局部窗口内执行自注意计算之外,还在self-attention中引入额外的可学习标记来捕捉全局依赖性,在FFN中引入双维注意机制。LightViT-T在ImageNet上仅用0.7G FLOPs就实现了78.7%的准确率,比PVTv2-B0高出8.2%。代码已开源。

ViTs模型DeiT-Ti和PVTv2-B0在ImageNet上可以达到72.2%和70.5%的准确率,而经典CNN模型RegNetY-800M在类似的FLOPs下达到了76.3%的准确率。这一现象表明某些轻量级的ViTs性能反而不如同级别CNNs。
作者等人将这一现象的原因归咎于CNNs固有的归纳偏置(inductive bias),同时现有很多工作试图将卷积集成于ViTs中来提高模型性能。然而不管是宏观上直接将卷积与self-attention集成/混合,还是微观上将卷积计算纳入self-attention计算之中,都说明了卷积对于轻量级ViTs的性能提升是至关重要的存在。
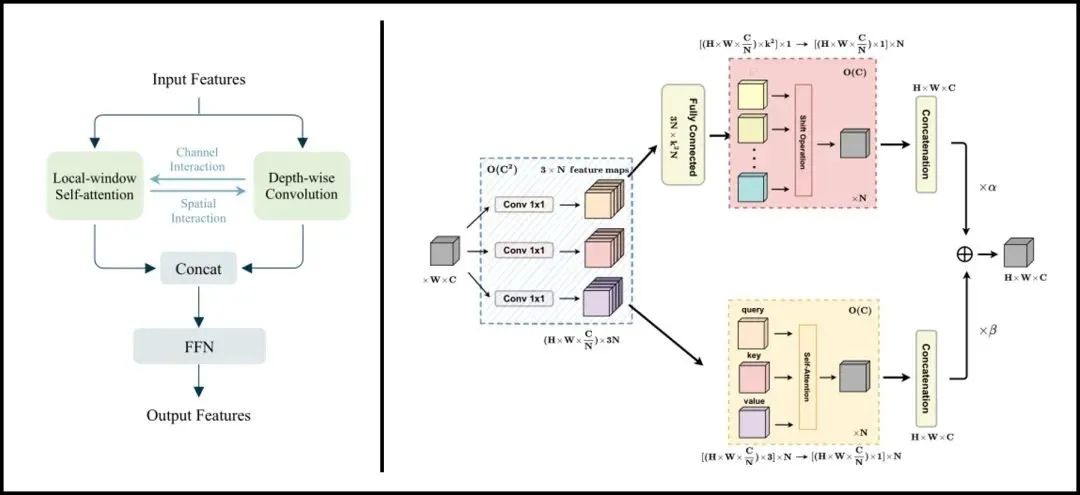
作者等人认为,在ViTs中混合卷积操作,是一种信息聚合的方式,卷积通过共享内核建立了所作用token之间的明确联系。基于这一点,作者等人提出“如果这种明确的聚合能以更均匀的方式发挥作用,那么它们对于轻量级的ViTs来说实际上是不必要的”。
原文:
https://mp.weixin.qq.com/s/-kObYWidUohyk2Sc4FamYg
SIGGRAPH(Special Interest Group for Computer GRAPHICS)是一个成立于1976年的计算机图形和交互技术特别兴趣小组。自1974年起,美国计算机协会计算机图形专业组(ACM SIGGRAPH)每年都会组织一次SIGGRAPH会议。后来,这个会议逐渐成为计算机图形领域最具权威和影响力的国际会议。
在SIGGRAPH会议上,各领域的研究人员们将分享大量学术研究报告,为公众展示丰富的研究成果,并不断给艺术、科学和自适应技术等领域带来新的研究方向和发展驱动力。
在今年的SIGGRAPH 2022上,NVIDIA Research团队共有32篇论文被会议接收,其中有2篇获得了“最佳论文奖”。这两篇论文分别是《基于多分辨率哈希编码的即时神经图形基元》(《Instant Neural Graphics Primitives with a Multiresolution Hash Encoding》)和《图像特征对反应时间的影响:扫视潜伏期的学习概率知觉模型》(《Image Features Influence Reaction Time: A Learned Probabilistic Perceptual Model for Saccade Latency》)。
NVIDIA第一篇获得“最佳论文奖”的是《基于多分辨率哈希编码的即时神经图形基元》(《Instant Neural Graphics Primitives with a Multiresolution Hash Encoding》),该论文介绍了NVIDIA在使用Instant-NGP训练神经图元模型(如NeRF)方面的重大技术突破。
NeRF(Neural Radiance Fields)最早是在2020年ECCV会议上的最佳论文(Best Paper),它将隐式表达推上了一个新的高度。NeRF模型可以用多张2D图像隐式重建3D场景,它可以用来展示任何复杂的空间信息,目前已被应用于图像压缩、三维形状高精度展示和超高分辨率图像等领域,可以进行物体重建、城市大场景重建等。
MLP(Multi-Layer Perceptron,多层感知器)是一种前馈人工神经网络模型,它可以将输入的多个数据集映射到单一的输出的数据集上。这是一个深度学习模型,其计算过程如图所示,这个网络模型在数据中间加了一个隐藏层,受到很多参数权重的影响。
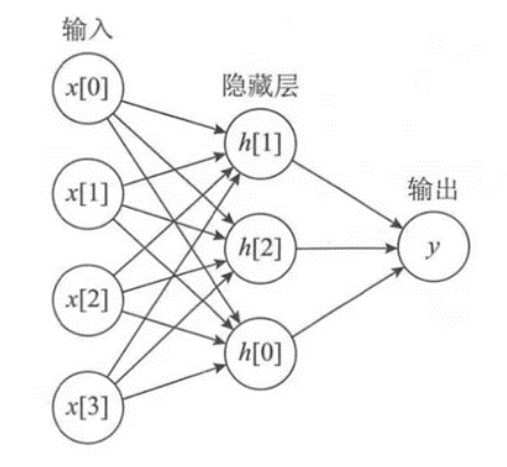
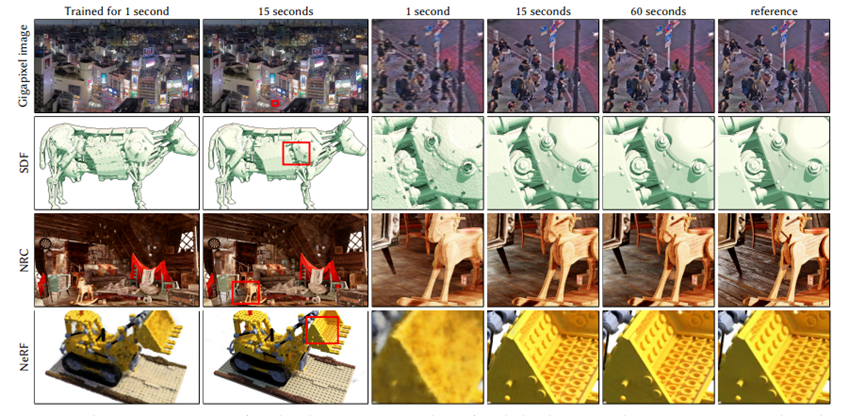
该论文的研究思路是:渲染时间=采样数×每次MLP计算时间。那么在采样数量不改变的情况下,减少MLP计算时间,就能提高计算速度。而减少MLP计算时间的直接方法是减少网络的深度和宽度,但这会让MLP的表达能力减弱,从而无法有效拟合场景;于是研究团队找到了新的解决方法,他们把空间划分为若干个小块(即网格),然后在每个局部空间放置可学习的embedding feature(将客观世界中的物体或对象离散地映射到特征空间中)。同时,论文中也利用了多分辨率网格,每个网格的顶点就是一个embedding feature,通过插值获得空间中任意点的feature,这样就可以分担浅层MLP的压力。又由于浅层MLP和线性插值速度很快,这种方法就可以实现实时渲染的目的。
通过这种方法,该论文解决了NeRF模型中建模和训练速度慢的问题,将NeRF模型训练速度提高了60倍。实验结果显示,在最快的情况下,NeRF模型的建模速度只需要5秒。
谷歌科学家乔恩·巴伦(Jon Barron)特地发Twitter感慨这一研究进展:“18个月前,训练NeRF要5小时;2个月前,训练NeRF仍要5分钟;而现在,NVIDIA的最新技术竟将训练NeRF的时间缩减到5秒!”
原文: https://mp.weixin.qq.com/s/RKEPUvx0C1PfwQ888BWQQg
其实正则化的本质很简单,就是对某一问题加以先验的限制或约束以达到某种特定目的的一种手段或操作。在算法中使用正则化的目的是防止模型出现过拟合。一提到正则化,很多同学可能马上会想到常用的L1范数和L2范数,在汇总之前,我们先看下LP范数是什么?
范数简单可以理解为用来表征向量空间中的距离,而距离的定义很抽象,只要满足非负、自反、三角不等式就可以称之为距离。
LP范数不是一个范数,而是一组范数,其定义如下:
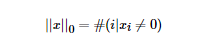
p的范围是[1,∞)。p在(0,1)范围内定义的并不是范数,因为违反了三角不等式。
根据pp的变化,范数也有着不同的变化,借用一个经典的有关P范数的变化图如下:

上图表示了p从0到正无穷变化时,单位球(unit ball)的变化情况。在P范数下定义的单位球都是凸集,但是当0
那问题来了,L0范数是啥玩意?
L0范数表示向量中非零元素的个数,用公式表示如下:
我们可以通过最小化L0范数,来寻找最少最优的稀疏特征项。但不幸的是,L0范数的最优化问题是一个NP hard问题(L0范数同样是非凸的)。因此,在实际应用中我们经常对L0进行凸松弛,理论上有证明,L1范数是L0范数的最优凸近似,因此通常使用L1范数来代替直接优化L0范数。
其他的方法还包括以下的几类方法,感兴趣的小伙伴可以查阅原文来学习:
原文:
https://mp.weixin.qq.com/s/GAf6nAPmdCZ_QGSSPSlCRg
这里推荐一个YOLO系列的算法实现库YOLOU,此处的“U”意为“United”的意思,主要是为了学习而搭建的YOLO学习库,也借此向前辈们致敬,希望不被骂太惨;
整个算法完全是以YOLOv5的框架进行,主要包括的目标检测算法有:YOLOv3、YOLOv4、YOLOv5、YOLOv5-Lite、YOLOv6、YOLOv7、YOLOX以及YOLOX-Lite。
同时为了方便算法的部署落地,这里所有的模型均可导出ONNX并直接进行TensorRT等推理框架的部署,后续也会持续更新。
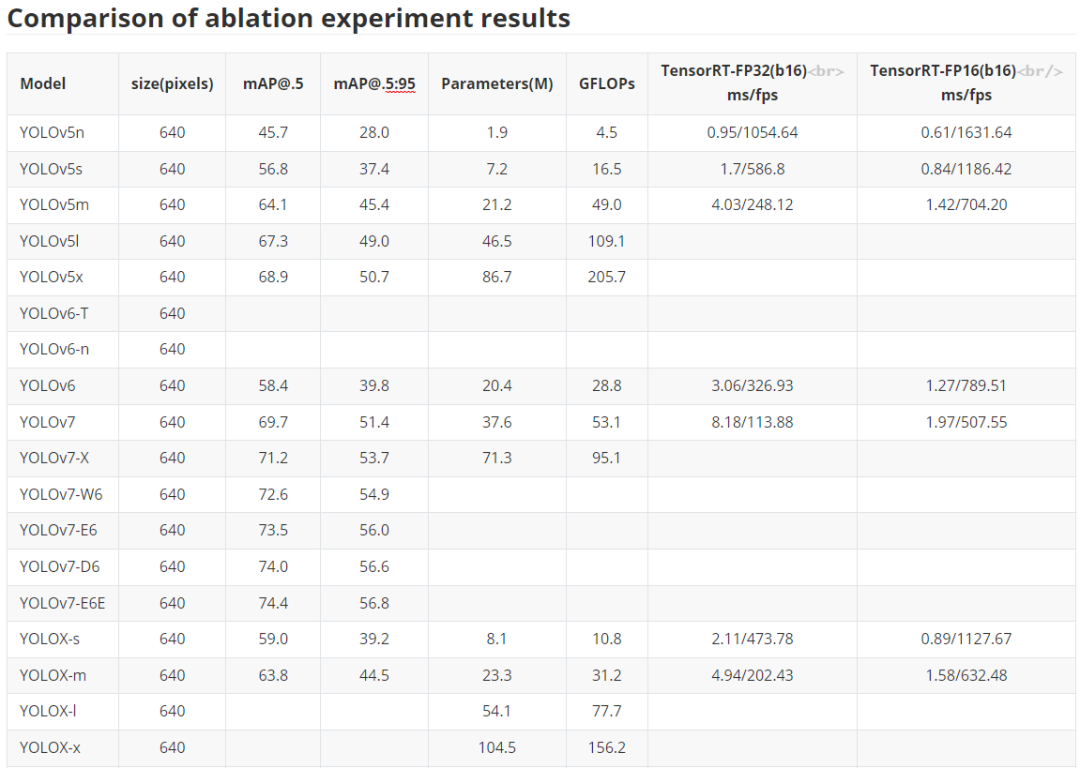
这里主要是对于YOLO系列经典化模型的训练对比,主要是对于YOLOv5、YOLOv6、YOLOv7以及YOLOX的对比,部分模型还在训练之中,后续所有预训练权重均会放出,同时对应的ONNX文件也会给出,方便大家部署应用落地。
注意,这里关于YOLOX也没完全复现官方的结果,后续有时间还会继续调参测试,尽可能追上YOLOX官方的结果。
下表是关于YOLOU中模型的测试,也包括TensorRT的速度测试,硬件是基于3090显卡进行的测试,主要是针对FP32和FP16进行的测试,后续的TensorRT代码也会开源。目前还在整理之中。
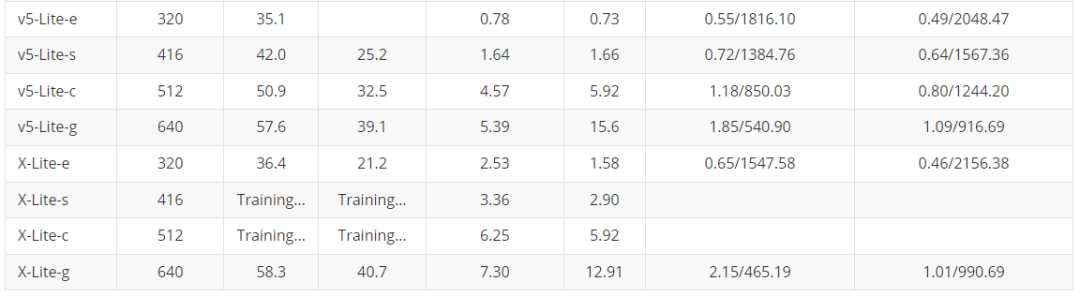
为了大家在手机端或者其他诸如树莓派、瑞芯微、AID以及全志等芯片的部署,YOLOU也对YOLOv5和YOLOX进行了轻量化设计。
下面主要是对于边缘端使用的模型进行对比,主要是借鉴之前小编参与的YOLOv5-Lite的仓库,这里也对YOLOX-Lite进行了轻量化迁移,总体结果如下表所示,YOLOX-Lite基本上可以超越YOLOv5-Lite的精度和结果。
至于如何熟练的使用YOLOU,请大家参考原文的介绍,相信大家一定会有所收获!
原文:
https://mp.weixin.qq.com/s/FN01MIpAP7UIkl8d8HXhtQ

近日,DeepMind 的创始人 Demis Hassabis 作客 Lex Fridman 的播客节目,谈了许多有趣的观点。
在访谈的一开头,Hassabis 就直言图灵测试已经过时,因为这是数十年提出来的一个基准,且图灵测试是根据人的行动与反应来作判断,这就容易出现类似前段时间谷歌一工程师称 AI 系统已有意识的“闹剧”:研究者与一个语言模型对话,将自己的感知映射在对模型的判断上,有失客观。
从2015年成立至今,DeepMind在人工智能领域的发展给世界带来过一次又一次的惊喜:从游戏程序AlphaGo到蛋白质预测模型AlphaFold,深度强化学习的技术突破解决了困扰人类科学家多年的重大科学问题,其背后团队的思考与动力,让人神往。
在Hassabis的这次访谈中,他还谈到一个有趣的观点,即 AI 超越人类的智能局限。当人类可能已经习惯这个有时间的三维世界,AI 也许可以达到从十二维理解世界的智能,摆脱工具的本质,因为我们人类对世界的理解也还存在许多不足之处。
以下是对Demis Hassabis的访谈整理:
从游戏到 AI
Lex Fridman:你是从什么时候开始喜欢上编程的?
Demis Hassabis:我大约4岁开始下棋,8岁时用在一场国际象棋比赛中获得的奖金买了我的第一台电脑,一台zx spectrum,后面我买了关于编程的书。我在一开始用电脑制作游戏时就爱上了计算机,觉得它们非常神奇,是自己思想的延伸,你可以让它们做一些任务,隔天睡醒回来时它就已经解决了。
当然,所有机器在某种程度上都能做到这一点,增强我们的自然能力,例如汽车让我们的移动速度超过奔跑速度。但人工智能是机器能够做所有学习的最终表现,因此,我的想法也很自然地延伸到了人工智能。
Lex Fridman:你是什么时候爱上人工智能的呢?什么时候开始了解到,它不只可以在睡觉的时候写程序、做数学运算,还可以执行比数学运算更复杂的任务?
Demis Hassabis:大概可以分为几个阶段。
我是青少年国际象棋队的队长,在大概10岁、11岁的时候打算成为一名职业棋手,这是我的第一个梦想。12岁时我达到大师级的水平,是世界上排名第二的棋手,仅次于Judith Pologer。当我试图提高棋艺,首先需要提高自己的思维过程,思考大脑是如何想出这些想法的?它为什么会犯错?怎样才能改善这个思维过程?
就像80年代早期和中期的国际象棋计算机,我已经习惯了有一个 Kasparov 的品牌版本,虽然不像今天那么强大,但也可以通过与其练习来达到提高的目的。当时我想,这真是太神奇了,有人把这个棋盘编成程序来下象棋。我买了一本 David Levy 在1984年出版的《国际象棋计算机手册》,这是本非常有意义的书,让我可以充分了解国际象棋程序是如何制作的。
我的第一个人工智能程序是由我的Amiga编程的,我写了一个程序来玩奥赛罗逆向思维,这是一个比国际象棋稍微简单的游戏,但我在当中使用了国际象棋程序的所有原则,即α-β搜索等。
第二个阶段是在我16、17岁左右时设计的一个叫 "主题公园 "的游戏,其中涉及到 AI 在游戏中模拟,尽管以今天的 AI 标准来看它很简单,但它会对你作为玩家的游戏方式做出反应,因此它也被称为沙盒游戏。
Lex Fridman:可否说一些你同AI 的关键联系?在游戏中创建 AI 系统需要什么?
Demis Hassabis:在我还是个孩子时就在游戏中训练自己,后面经历了一个设计游戏和编写 AI for 游戏的阶段。我90年代写的所有游戏,都以人工智能为核心组成部分。之所以在游戏行业这么做,是因为当时我认为游戏行业是技术的最前沿,像 John Carmack 和 Quake,好像都是在游戏中进行的。我们仍在从当中获取好处,像GPU,是为计算机图形而发明的,但后来被发现对 AI 有重要作用。所以当时我认为,游戏中拥有最前沿的人工智能。
早期我参与过一个叫"黑白"的游戏,它是强化学习在计算机游戏中应用最深刻的例子。你可以在游戏中训练一个小宠物,它会从你对待它的方式中进行学习,如果你对它不好,那它就会变得刻薄,并对你的村民和你所管理的小部落刻薄。但如果你善待它,它也会变得善良。
Lex Fridman:游戏对善与恶的映射让我意识到,你可以通过你所做的选择来确定结局。游戏可以带来这种哲学意义。
Demis Hassabis:我认为游戏是一种独特的媒介,作为玩家并不仅仅是被动地消费娱乐,实际上,你是作为一个代表积极参与的。所以我认为这就是游戏在某些方面比其他媒介,例如电影和书籍等更有内涵的原因。
从一开始我们就对 AI 进行了深入的思考,将游戏作为证明和开放 AI 算法的试验场。这也是 Deepmind 最初使用大量游戏作为主要测试平台的原因,因为游戏非常高效,也很容易有指标来查看 AI 系统是如何改进的,思考的方向,以及是否在做渐进式地改进。
Lex Fridman:假设我们不能制造一台能在国际象棋中击败人类的机器,那么人们会认为,由于组合的复杂性,围棋是一个无法破解的游戏。但最终,AI研究者造出了这台机器,人类才意识到,我们没有想象中那么聪明。
Demis Hassabis:这是一段有趣的思考旅程,尤其是当我从两个角度(AI 创造者与游戏玩家)来理解时,更觉得神奇,同时又有点苦乐参半的感觉。
Kasparov 将国际象棋称为智能“果蝇”,我蛮喜欢这个形容,因为国际象棋从一开始就与 AI 密切相关。我认为每一位 AI 实践者,包括图灵和香农,以及这一领域的所有先辈们,都尝试过编写一个国际象棋程序。香农在1949年写了第一个关于国际象棋的程序文档,图灵也曾写过一个著名的国际象棋程序,但由于计算机太慢无法运行,因此他用铅笔和纸来手动运行程序,跟朋友一起玩。
DeepBlue 的出现是一个重要的时刻,它结合了我喜欢的所有东西,包括国际象棋、计算机和人工智能。1996年,它打败了 Garry Kasparov。在那之后,我对 Kasparov 头脑的印象比对 DeepBlue 印象更深,因为 Kasparov 是人类的头脑,他不仅可以与计算机在下棋方面达到同一水平,Kasparov 也可以做人类能做的一切,比如骑自行车、说多国语言、参与政治活动等等。
DeepBlue 虽然在国际象棋中有过辉煌时刻,但它实际上是将国际象棋大师的知识提炼成一个程序,无法做其他任何事情。因此我认为该系统中缺少了一些智能的东西,这也是我们尝试做 AlphaGo 的原因。
Lex Fridman:让我们简单地谈谈国际象棋中关于人类的一面。你从游戏设计的角度提出,象棋之所以吸引人是因为它是游戏。能否解释一下,在bishop(国际象棋中的“象”)和knight(国际象棋中的“马”)之间是否存在一种创造性的张力? 是什么让游戏具有吸引力,并且能跨越几个世纪?
Demis Hassabis:我也在思考这个问题。实际上很多优秀的象棋玩家并不一定是从游戏设计师的角度去思考这个问题。
为什么国际象棋如此吸引人?我认为一个关键的原因是不同棋位的动态,你可以分辨出它们是封闭的还是开放的,想一下象和马的移动方式有多么不同,而后国际象棋在已经进化到平衡这二者的程度,大致都是3分。

END

爱我就给我点在看
 点击 “阅读原文”进入官网
点击 “阅读原文”进入官网
