
欢迎加入技术交流QQ群(2000人):电力电子技术与新能源 954221326
高可靠新能源行业顶尖自媒体
在这里有电力电子、新能源干货、行业发展趋势分析、最新产品介绍、众多技术达人与您分享经验,欢迎关注微信公众号:电力电子技术与新能源(Micro_Grid),论坛:www.21micro-grid.com,建立的初衷就是为了技术交流,作为一个与产品打交道的技术人员,市场产品信息和行业技术动态也是必不可少的,希望大家不忘初心,怀有一颗敬畏之心,做出更好的产品!

电力电子技术与新能源论坛
www.21micro-grid.com
小编推荐值得一看的书单电力电子技术与新能源小店

The Power MOSFET 应用手册
[视频]反激电路Flyback
车用永磁同步电机控制及弱磁方法
[视频]IGBT模块技术参数详解
[视频]英飞凌双脉冲实验教具使用说明
碳化硅在光伏逆变器中的应用-阳光电源
华为精华资料—终端互连PCB设计规范分享
复旦电赛培训_辅助电源_刘祖望_电力电子技术与新能源
环路指导书LOOP Training
[视频]浙大碳化硅技术发展与应用介绍
register unsigned int variable_name;
Time (numerator / denominator) = C0 + C1* log2 (numerator / denominator)
= C0 + C1 * (log2 (numerator) - log2 (denominator)).
int func_div_and_mod (int a, int b)
{
return (a / b) + (a % b);
}
typedef unsigned int uint;
uint div32u (uint a)
{
return a / 32;
}
int div32s (int a)
{
return a / 32;
}
uint modulo_func1 (uint count)
{
return (++count % 60);
}
uint modulo_func2 (uint count)
{
if (++count >= 60)
count = 0;
return (count);
}
switch ( queue )
{
case 0 : letter = 'W';
break;
case 1 : letter = 'S';
break;
case 2 : letter = 'U';
break;
}
if ( queue == 0 )
letter = 'W';
else if ( queue == 1 )
letter = 'S';
else letter = 'U';
static char *classes="WSU";
letter = classes[queue];
int f(void);
int g(void);
int errs;
void test1(void)
{
errs += f();
errs += g();
}
void test2(void)
{
int localerrs = errs;
localerrs += f();
localerrs += g();
errs = localerrs;
}
void func1( int *data )
{
int i;
for(i=0; i<10; i++)
{
anyfunc( *data, i);
}
}
void func1( int *data )
{
int i;
int localdata;
localdata = *data;
for(i=0; i<10; i++)
{
anyfunc (localdata, i);
}
}
int wordinc (int a)
{
return a + 1;
}
short shortinc (short a)
{
return a + 1;
}
char charinc (char a)
{
return a + 1;
}
void print_data_of_a_structure (const Thestruct *data_pointer)
{
...printf contents of the structure...
}
typedef struct { int x, y, z; } Point3;
typedef struct { Point3 *pos, *direction; } Object;
void InitPos1(Object *p)
{
p->pos->x = 0;
p->pos->y = 0;
p->pos->z = 0;
}
void InitPos2(Object *p)
{
Point3 *pos = p->pos;
pos->x = 0;
pos->y = 0;
pos->z = 0;
}
int g(int a, int b, int c, int d)
{
if (a > 0 && b > 0 && c < 0 && d < 0)
// grouped conditions tied up together//
return a + b + c + d;
return -1;
}
bool PointInRectangelArea (Point p, Rectangle *r)
{
return (p.x >= r->xmin && p.x < r->xmax &&
p.y >= r->ymin && p.y < r->ymax);
}
bool PointInRectangelArea (Point p, Rectangle *r)
{
return ((unsigned) (p.x - r->xmin) < r->xmax &&
(unsigned) (p.y - r->ymin) < r->ymax);
}
int aFunction(int x, int y)
{
if (x + y < 0)
return 1;
else
return 0;
}
int sum(int x, int y)
{
int res;
res = x + y;
if ((unsigned) res < (unsigned) x) // carry set? //
res++;
return res;
}
if( val == 1)
dostuff1();
else if (val == 2)
dostuff2();
else if (val == 3)
dostuff3();
switch( val )
{
case 1: dostuff1(); break;
case 2: dostuff2(); break;
case 3: dostuff3(); break;
}
if(a==1) {
} else if(a==2) {
} else if(a==3) {
} else if(a==4) {
} else if(a==5) {
} else if(a==6) {
} else if(a==7) {
} else if(a==8)
{
}
if(a<=4) {
if(a==1) {
} else if(a==2) {
} else if(a==3) {
} else if(a==4) {
}
}
else
{
if(a==5) {
} else if(a==6) {
} else if(a==7) {
} else if(a==8) {
}
}
if(a<=4)
{
if(a<=2)
{
if(a==1)
{
/* a is 1 */
}
else
{
/* a must be 2 */
}
}
else
{
if(a==3)
{
/* a is 3 */
}
else
{
/* a must be 4 */
}
}
}
else
{
if(a<=6)
{
if(a==5)
{
/* a is 5 */
}
else
{
/* a must be 6 */
}
}
else
{
if(a==7)
{
/* a is 7 */
}
else
{
/* a must be 8 */
}
}
}
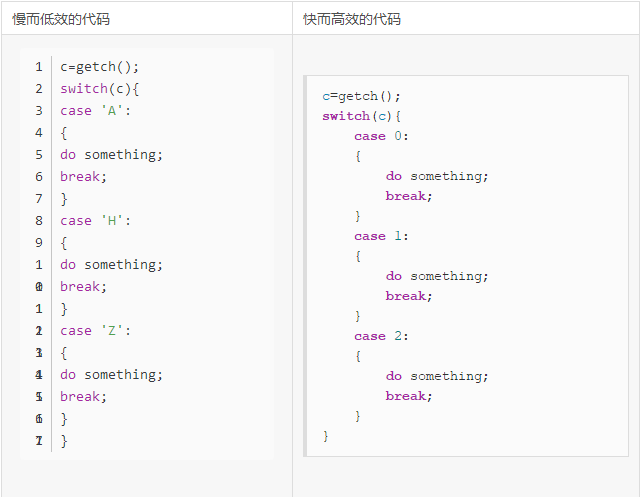
char * Condition_String1(int condition) {
switch(condition) {
case 0: return "EQ";
case 1: return "NE";
case 2: return "CS";
case 3: return "CC";
case 4: return "MI";
case 5: return "PL";
case 6: return "VS";
case 7: return "VC";
case 8: return "HI";
case 9: return "LS";
case 10: return "GE";
case 11: return "LT";
case 12: return "GT";
case 13: return "LE";
case 14: return "";
default: return 0;
}
}
char * Condition_String2(int condition) {
if ((unsigned) condition >= 15) return 0;
return
"EQ\0NE\0CS\0CC\0MI\0PL\0VS\0VC\0HI\0LS\0GE\0LT\0GT\0LE\0\0" +
3 * condition;
}
int fact1_func (int n)
{
int i, fact = 1;
for (i = 1; i <= n; i++)
fact *= i;
return (fact);
}
int fact2_func(int n)
{
int i, fact = 1;
for (i = n; i != 0; i--)
fact *= i;
return (fact);
}
for( i=0; i<10; i++){ ... }
for( i=10; i--; ) { ... }
for(i=10; i; i--){}
for(i=10; i!=0; i--){}
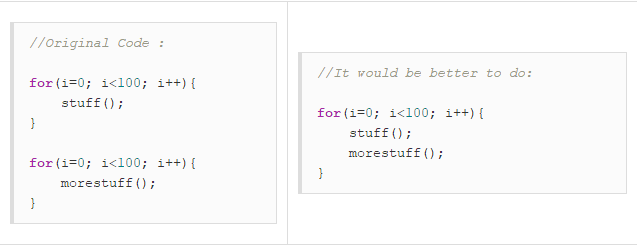
for(i=0 ; i<100 ; i++)
{
func(t,i);
}
-
-
-
void func(int w,d)
{
lots of stuff.
}
func(t);
-
-
-
void func(w)
{
for(i=0 ; i<100 ; i++)
{
//lots of stuff.
}
}

for(i=0;i< limit;i++) { ... }
//Example 1
#include
#define BLOCKSIZE (8)
void main(void)
{
int i = 0;
int limit = 33; /* could be anything */
int blocklimit;
/* The limit may not be divisible by BLOCKSIZE,
* go as near as we can first, then tidy up.
*/
blocklimit = (limit / BLOCKSIZE) * BLOCKSIZE;
/* unroll the loop in blocks of 8 */
while( i < blocklimit )
{
printf("process(%d)\n", i);
printf("process(%d)\n", i+1);
printf("process(%d)\n", i+2);
printf("process(%d)\n", i+3);
printf("process(%d)\n", i+4);
printf("process(%d)\n", i+5);
printf("process(%d)\n", i+6);
printf("process(%d)\n", i+7);
/* update the counter */
i += 8;
}
/*
* There may be some left to do.
* This could be done as a simple for() loop,
* but a switch is faster (and more interesting)
*/
if( i < limit )
{
/* Jump into the case at the place that will allow
* us to finish off the appropriate number of items.
*/
switch( limit - i )
{
case 7 : printf("process(%d)\n", i); i++;
case 6 : printf("process(%d)\n", i); i++;
case 5 : printf("process(%d)\n", i); i++;
case 4 : printf("process(%d)\n", i); i++;
case 3 : printf("process(%d)\n", i); i++;
case 2 : printf("process(%d)\n", i); i++;
case 1 : printf("process(%d)\n", i);
}
}
}
//Example - 1
int countbit1(uint n)
{
int bits = 0;
while (n != 0)
{
if (n & 1) bits++;
n >>= 1;
}
return bits;
}
//Example - 2
int countbit2(uint n)
{
int bits = 0;
while (n != 0)
{
if (n & 1) bits++;
if (n & 2) bits++;
if (n & 4) bits++;
if (n & 8) bits++;
n >>= 4;
}
return bits;
}
found = FALSE;
for(i=0;i<10000;i++)
{
if( list[i] == -99 )
{
found = TRUE;
}
}
if( found )
printf("Yes, there is a -99. Hooray!\n");
found = FALSE;
for(i=0; i<10000; i++)
{
if( list[i] == -99 )
{
found = TRUE;
break;
}
}
if( found )
printf("Yes, there is a -99. Hooray!\n");
int f1(int a, int b, int c, int d) {
return a + b + c + d;
}
int g1(void) {
return f1(1, 2, 3, 4);
}
int f2(int a, int b, int c, int d, int e, int f) {
return a + b + c + d + e + f;
}
ing g2(void) {
return f2(1, 2, 3, 4, 5, 6);
}
__inline int square(int x) {
return x * x;
}
#include
double length(int x, int y){
return sqrt(square(x) + square(y));
}
文章首尾冠名广告正式招商,功率器件:IGBT,MOS,SiC,GaN,磁性器件,电源芯片,DSP,MCU,新能源厂家都可合作,有意者加微信号1768359031详谈。
说明:本文来源网络;文中观点仅供分享交流,不代表本公众号立场,转载请注明出处,如涉及版权等问题,请您告知,我们将及时处理。
电力电子技术与新能源通讯录:
Please clik the advertisement and exit
重点
如何下载《电力电子技术》板块内高清PDF电子书
点击文章底部阅读原文,访问电力电子技术与新能源论坛(www.21micro-grid.com)下载!
或者转发所要文章到朋友圈不分组不屏蔽,然后截图发给小编(微信:1413043922),小编审核后将文章发你!
推荐阅读:点击标题阅读
LLC_Calculator__Vector_Method_as_an_Application_of_the_Design
自己总结的电源板Layout的一些注意点
High_Frequency_Transformers_for_HighPower_Converters_Materials
华为电磁兼容性结构设计规范V2.0
Communication-less Coordinative Control of Paralleled Inverters
Soft Switching for SiC MOSFET Three-phase Power Conversion
Designing Compensators for Control of Switching Power Supplies
100KHZ 10KW Interleaved Boost Converter with full SiC MOSFET
华为-单板热设计培训教材
看完有收获?请分享给更多人
公告:
更多精彩点下方“阅读原文”!
点亮“在看”,小编工资涨1毛!
