本文授权转载自公众号“车轮上的电脑”,作者Max Tao
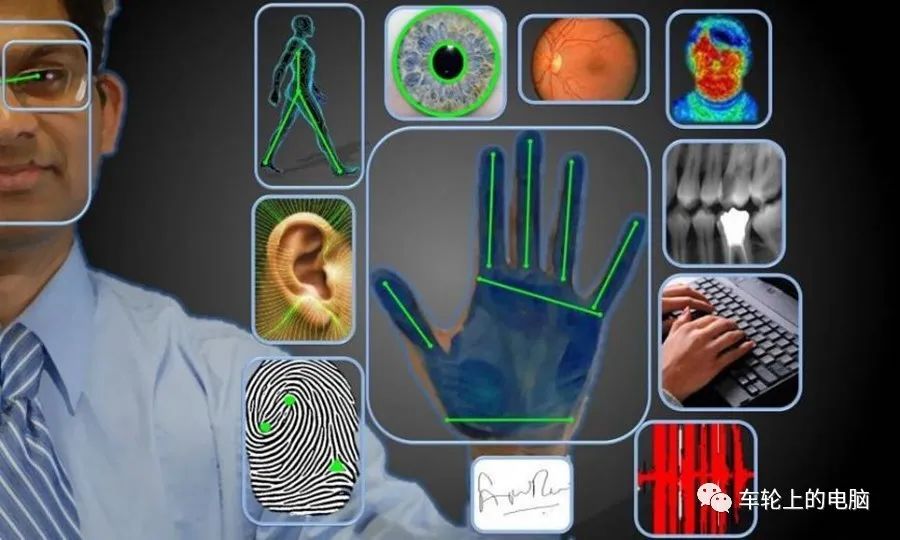
人脸识别,即生物特征识别技术(biometric recognition or biometrics) 是指利用个体与生俱来的生理特性(如指纹、人脸或面部、虹膜、掌纹、静脉等)或长年累月形成的行为特征(如笔迹、声音、步态等)来进行个人身份的鉴定。一般来说,该技术的便捷性和安全性远高于口令、密码等传统身份鉴定方法。目前主流的生物特征识别技术有指纹识别、人脸识别、虹膜识别、语音识别、静脉识别、声纹识别等(参考图1)。人脸是日常生活中最常见和最熟悉的生物特征。人脸识别技术被广泛应用于安防、支付、考勤、金融等领域,其使用大大提升了人们生活的安全性和便捷性。与其他生物特征识别技术相比,人脸识别能够得到广泛应用,是因为具有以下的优势:不像指纹识别需要用户把手指放置到指纹识别机上,人脸识别无需接触人体,直接通过摄像头等前端设备采集人脸图像信息。人脸识别的非接触性为用户带来非侵扰性的体验。首先人脸识别采集无需人工干预,可无感知自动采集人脸图像;另外由于人脸属于暴露在外的生物特征,对人脸图像的采集相对来说易于被普通用户接受。相对于需要特定采集设备的指纹识别或者虹膜识别等,人脸识别系统只需要摄像头和计算机,结合相关的软件算法就可以实现,性价比高。在目前移动终端以及智能终端已经得到广泛使用的情况下,也易于扩展使用。
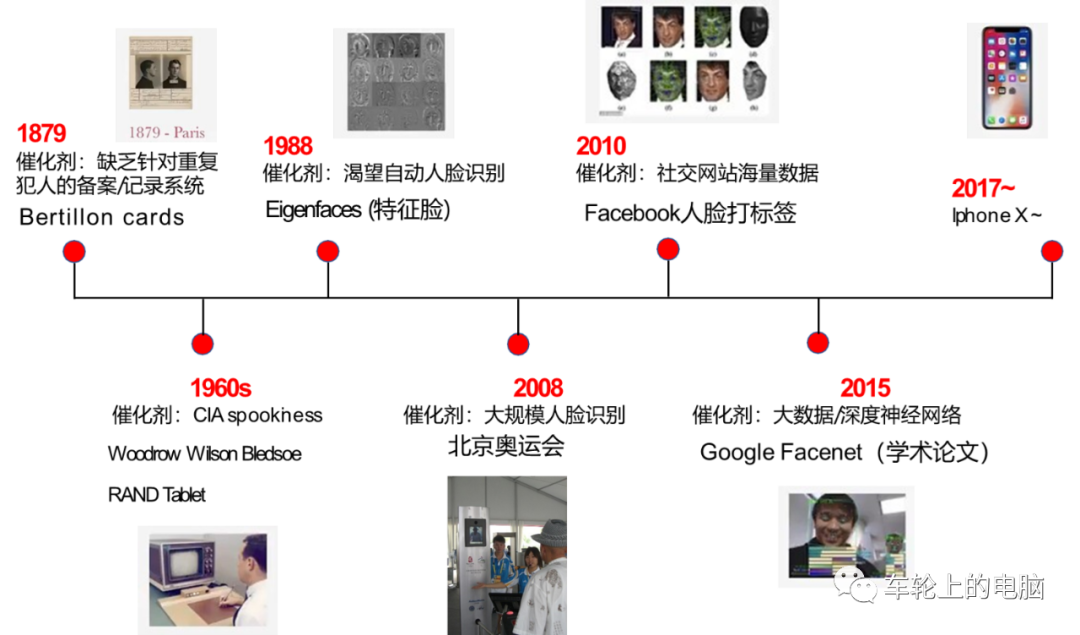
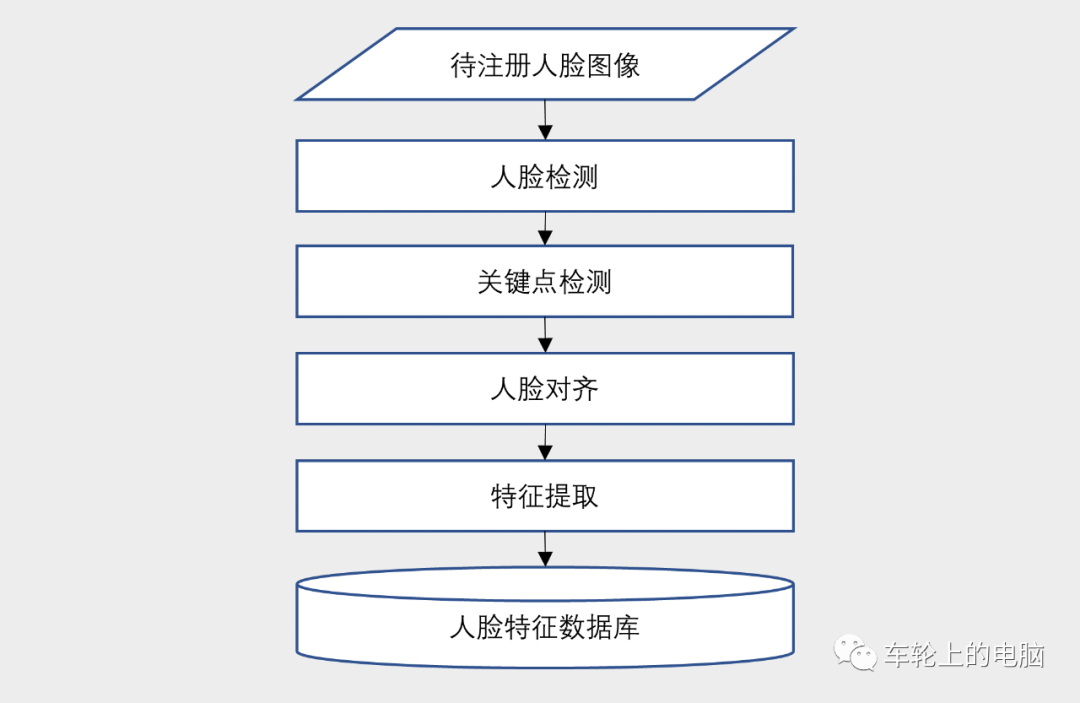
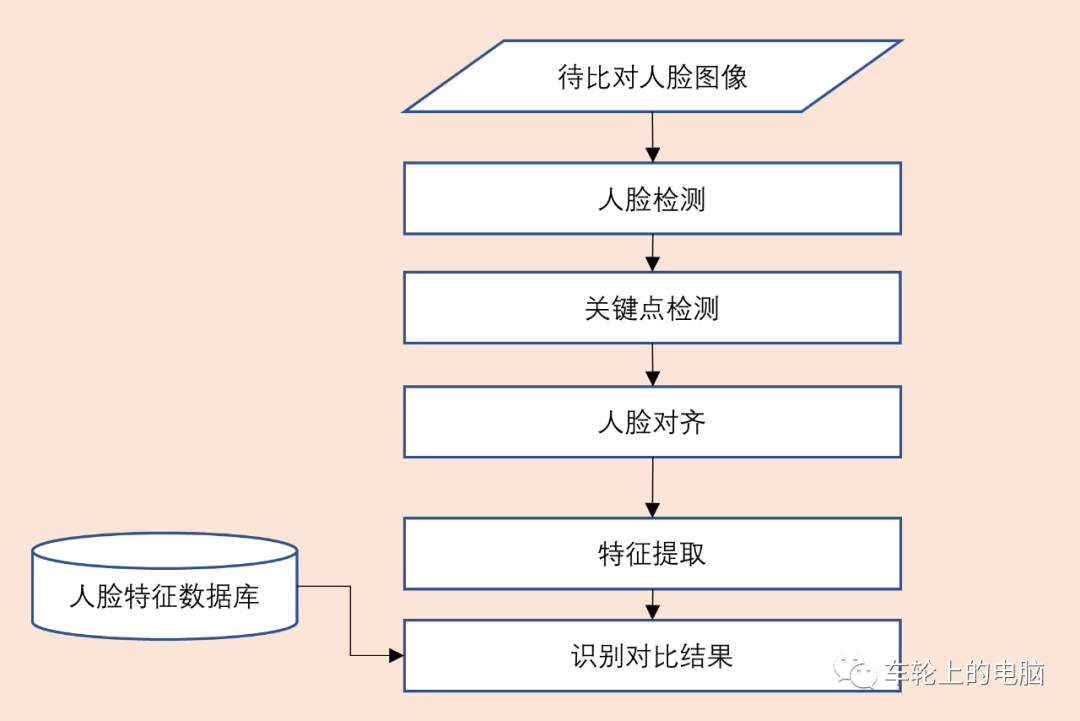
通过面部特征进行身份认证最早可追溯到19世纪70年代。一名叫贝迪永(Alphonse Bertillion)的巴黎警察根据人体特征,开发出了一种“人体测量学”(其中包括部分人脸特征)。他认为人到20岁,骨骼就会基本定型。通过记录人的头长、头宽、中指长度、耳长、身高、坐高等多组数据,配上相应的面部照片,来比对识别罪犯。然而这种全人工的方法既费时费力,准确率也不高,急需自动化高精度的人脸识别系统。真正自动化的人脸识别系统的研究始于20世纪60年代,80年代随着计算机技术和光学成像技术发展得到了提高。2008年北京奥运会就引入了人脸识别进行身份的快速核查。随着人脸大数据积累(Facebook社交网站海量人脸数据打标签)以及深度学习技术的快速发展,基于深度学习的人脸识别技术逐渐占据了研究和应用主流。2015年Google发表的论文FaceNet[3]在常用的人脸识别验证集LFW上达到了99.63%的高精度。2017年苹果IphoneX发布,第一次在手机端实现人脸解锁功能,人脸识别技术迎来了一波研究和落地热潮。大家应该都使用过手机的人脸解锁功能,在第一次使用此功能的时候需要进行人脸注册(图3)得到人脸模板,这样下次才可以在线进行人脸识别比对登录(图4)。人脸识别在使用的时候一般有三种模式,即1:1,1:N,M:N。一般用于人证核验,可以理解为证明“你就是你”。例如在乘坐火车/飞机,银行办卡等场景下,通常需要验证本人与其持有的身份证是否为同一个人。将一张人脸图片与人脸特征库中的所有人脸进行逐一比对。在人脸库中搜索与其相似(人脸比对的相似度大于设定阈值)的图片,即找出来“你是谁”。常用场景如疑犯追踪,小区门禁,公司考勤等。两个人脸库进行对比。例如人脸库A有M个人脸,人脸库B有N个人脸。如果想要知道A库和B库有多少相同的人,就需要A库中M个人脸与B库中N个人脸进行逐一比对,相当于M个1:N相加的结果。从图3和图4可以看出,不管是注册还是识别阶段,基本都包括:人脸检测、人脸关键点检测、人脸对齐以及人脸特征提取这几个重要步骤。本文先介绍一下人脸检测技术。人脸检测是指在给定的人脸图像中准确定位出人脸的位置和大小。只有知道图像中的人脸在哪里,才能开展后续的人脸相关任务。所以说人脸检测是人脸相关算法及工程落地的基础算法。人脸检测可以看成是目标检测的一个子集。目标检测(或称为通用物体检测)针对的是多类别,人脸检测是二分类,结果是人脸或非人脸。理论上,通用物体检测算法都可以直接用来做人脸检测,只需要改一下输出类别即可。通用物体检测考虑的是更广泛通用的物体,具有场景复杂多变,物体形状、背景、大小等都比人脸这种单一的类别更复杂。人脸检测虽然类别单一,但也不是那么简单,姿态、光照、遮挡(见图5)以及极小人脸(见图6)等都是人脸检测里面的难点。基于通用物体检测算法基础,人脸检测的问题可以针对性优化,如anchor设置、背景处理、抑制误检等。在具体介绍检测算法前,先介绍下人脸检测常用数据库以及评测指标。常用的人脸检测数据库包括:FDDB[6]和WIDER FACE[4]。FDDB是全世界最具权威的人脸检测评测数据库之一,数据集完全公开,一共有2845张图像,5171个人脸标注。包括不同姿势、不同分辨率、旋转和遮挡等人脸图片,同时包括灰度图和彩色图。图像分辨率较小,所有图像的长边缩放到450像素,也就是说所有图像都小于450*450,最小标注人脸大小20*20。绝大多数图像都只有一个人脸。一共有32203张图像,393703个人脸标注,分训练集(train)/验证集(val)/测试集(test),分别占40%/10%/50%。数据集包括各种尺度,姿态,遮挡,表情,化妆,光照等人脸图像,难度较大。图像分辨率普遍偏高,所有图像的宽都缩放到1024,最小标注人脸大小10*10,都是彩色图像;平均12.2个人脸/图,密集小人脸多。
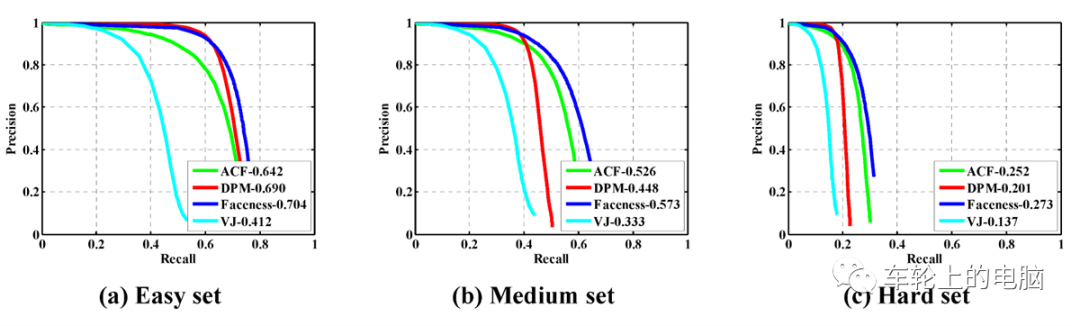
WIDER FACE不公开测试集的标注结果(GT:ground truth),需要提交结果给官方评测,结果公平公正,而且测试集大,可靠性高。根据EdgeBox方法的检测率WIDER FACE评测集被划分为三个难度等级:Easy, Medium, Hard。算法可以在各个任务维度上进行评测,比如Hard等级非常适合评测小人脸。- 准确率(Precision)代表着预测为正的样本中有多少是正样本;
- 召回率(Recall)代表着总的正样本中有多少被成功预测出来(预测为正)。
下面举例来说明如何计算准确率和召回率。这里假设测试集中有100个正样本和100个负样本,100个正样本有90个被正确预测为正,10个被错误预测为负;100个负样本中有80个被正确预测为负,20个被错误预测为正:- TP(true positive)代表着正样本被正确预测为正的数量,于是TP=90;
- TN(true negative)代表着负样本被正确预测为负的数量,于是TN=80;
- FP(false positive)代表着负样本被错误预测为正的数量,于是FP=20;
- FN(false negative)代表着正样本被错误预测为负的数量,于是FN=10。
- 准确率Precision = TP/(TP+FP)=90/(90+20)=0.818
- 召回率Recall = TP/(TP+FN)=90/(90+10)=0.900
前面提到的人脸检测里只有人脸和背景两类,那么如何用准确率和召回率去评价人脸检测算法性能呢?人脸检测一般输出检测框,就要定义出什么样的检测结果是正确的。一般情况下,当检测框和GT的IOU(Intersection over Union)大于一个给定的阈值(如0.7)时,认为这张人脸被正确检测到,基于这个前提,就可以按照二分类进行统计。继续举例来说明。假设实际测试集中有100张人脸,算法检测出95个人脸框,其中有90是满足阈值要求被认为是正确的,剩下的5个被认为是错误检测。那么TP/TN/FP/FN分别计算如下:- TP:100个人脸被正确预测出来的人脸有90个,所以TP=90;
- FP:预测是人脸,实际是非人脸,即错误的检测有5张,于是FP=5;
- FN:正样本未被检测出来,即漏检,于是FN=100-90=10。
- 准确率Precision = TP/(TP+FP)=90/(90+5)=0.947
- 召回率Recall = TP/(TP+FN)=90/(90+10)=0.900
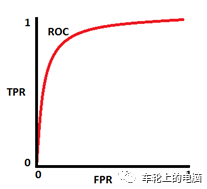
根据不同的阈值,可以得到很多对准确率Precision和召回率Recall,即可以得到PR曲线,示例见图7。ROC曲线是另一种评价二分类算法的指标。纵坐标为真正例率(True Positive Rate,TPR=TP/(TP+FN),横坐标为假正例率(False Positive Rate,FPR=FP/(TN+FP))同样根据不用阈值得到很多对TPR和FPR,即可以得到ROC曲线(见图8)。接下来我们就具体介绍下人脸检测算法。我们将整个人脸检测算法分为三个阶段:早期算法,AdaBoost框架以及深度学习框架。早期算法使用模板匹配技术,即用一个人脸模板图像与被检测图像中的各个位置进行匹配,确定这个位置处是否有人脸;AdaBoost框架以2001年Viola和Jones设计的一种人脸检测算法[7]为代表。其使用Haar-like特征和级联的AdaBoost分类器,检测速度较之前的方法有2个数量级的提高,并且保持了很好的精度,一般称这种方法为VJ框架。VJ框架是人脸检测历史上第一个最具有里程碑意义的成果,奠定了基于AdaBoost目标检测框架的基础。深度学习方法出现以前工业界的方案基本都是基于VJ算法;随着卷积神经网络在图像分类问题上取得成功之后,很快也被用于人脸检测问题,在精度上大幅度超越之前的算法,逐渐成为研究和应用的主流。
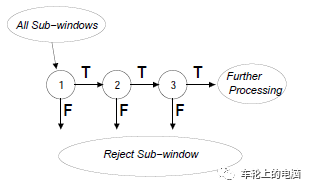
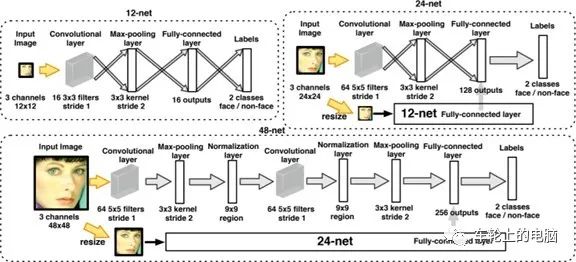
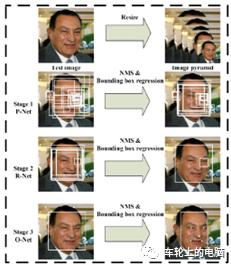
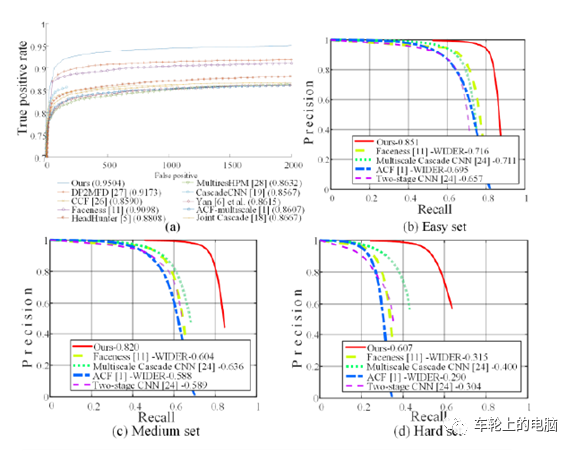
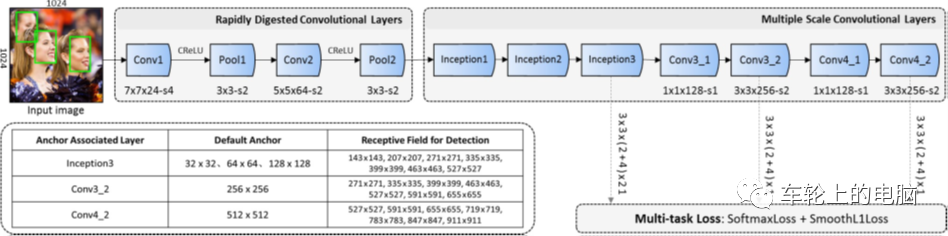
图片中人脸可能出现在任何位置,所以在检测时用固定大小的窗口以一定的步长对图像从上到下、从左到右扫描,这称为滑动窗口技术(sliding window)。另外为了检测不同大小的人脸,还需要对图像进行缩放来构造图像金字塔,对每张缩放后的图像都用滑动窗口技术进行扫描。得到图像子窗口后,提取相应的特征描述子。实际检测使用比较多的特征描述子是2001年Viola和Jones提出的 Haar-like特征[7]。图11是Haar-like特征的示意图。Haar-like特征是白色矩形框内的像素值之和,减去黑色区域内的像素值之和。这种特征捕捉图像的边缘、变化等信息,各种特征描述在各个方向上的图像变化信息。人脸的五官有各自的亮度信息,非常符合Haar-like特征特点。由于采用了滑动窗口扫描技术,并且要对图像进行反复缩放扫描,得到的图像非常多,而绝大部分窗口都是背景,即人脸是一个稀疏事件,如果能快速的背景图像子窗口排除掉,则能大大提高目标检测的效率。所以采用AdaBoost这样的级联分类器进行人脸检测。这种思想的精髓在于用简单的弱分类器在初期快速排除掉大量的非人脸窗口,同时保证高的召回率,最终能通过所有级弱分类器的窗口即认为包括人脸。图12是分类器级联进行判断的示意图:图12 AdaBoost级联分类器示例[7]:三个臭皮匠顶一个诸葛亮 卷积神经网络在图像分类问题上取得成功之后,很快被用于人脸检测,在精度上超越之前的AdaBoost框架。此外直接用滑动窗口进行人脸检测的方案计算量太大很难达到实时,使用卷积网络进行人脸检测的方法采用各种手段优化这个问题。Cascade CNN[8]借鉴AdaBoost人脸检测器思想,其也包含了多个分类器,这些分类器采用级联结构进行组织。不同的地方在于,Cascade CNN采用卷积网络作为每一级的分类器。首先使用一个小型网络12-net对输入图像进行密集人脸候选区域搜索,检测区域是12×12,搜索步长是4个像素,快速排除90%的非人脸区域,剩余的检测窗口送入12-calibration-net调整它的尺寸和位置。然后采用非极大值抑制(NMS)合并高度重叠的检测窗口,保留下来的候选检测窗口将会被归一化到24x24送入24-net。24-net将进一步剔除掉剩下来的将近90%的检测窗口。和之前的过程一样,通过24-calibration-net矫正检测窗口,并应用NMS进一步合并减少检测窗口的数量。保留下来的候选检测窗口也将会被归一化到48x48送入48-net进行分类得到进一步过滤的人脸候选窗口。然后利用NMS进行窗口合并,送入48-calibration-net矫正检测窗口作为最后的输出(算法结构见图13)。 图13 Cascade CNN[8]算法pipeline一些论文认为,在人脸检测中加入一些辅助任务构成多任务学习可以提高检测性能。MTCNN[9]在人脸检测任务中加入人脸关键点检测,通过两个任务协同提高检测性能。同Cascade CNN一样也是基于Cascade的框架。MTCNN总体来说可分为三个部分:P-Net、R-Net和O-Net(见图14)。MTCNN利用一个浅层网络P-Net快速产生候选窗口,利用一个稍微复杂网络R-Net排除掉大量非人脸窗口,最后利用一个更强大的网络O-Net进一步改善结果,并联合输出人脸关键点位置。与Cascade CNN[8]的12-net需要在整张图片上做密集窗口采样进行分类不同,MTCNN在测试第一阶段的PNet是全卷积网络(FCN, Fully Convolutional Networks),全卷积网络的优点在于可以输入任意尺寸的图像,同时使用卷积运算代替了滑动窗口运算,大幅提高了检测的效率。MTCNN算法在FDDB以及WIDER FACE上取得了当时SOTA的结果(见图15)。详情可参见论文[9]。图15 MTCNN[9]评测的结果,(a) FDDB;(b-d) 3 subsets of WIDER FACE.在实际落地应用中,需要寻求实时性和准确性的折中,因为高准确率的网络往往有大量的计算,速度较慢。FaceBoxes[10]是一个足够轻量的人脸检测器,由中科院李子青教授团队2017年提出,如文章题目所指旨在实现CPU下的实时人脸检测,图16给出了相应的算法pipeline。其针对MTCNN存在的问题:1)检测速度会受到人脸数量的影响;2)多阶段训练,过程复杂;3) 速度还是较慢,提出了以下几个创新点:- 使用RDCL(Rapidly Digested Convolutional Layers)模块快速降低特征图大小,为检测速度提供了保证: 通过适当的卷积核大小来快速缩小输入空间大小,减少输出通道的数量,使CPU设备上的FaceBoxes达到实时速度;
- MSCL(Multiple Scale Convolutional Layers)模块使用多尺度特征图预测,处理不同尺度下的人脸;
- 使用anchor稠密化策略,以提高小人脸的召回率。
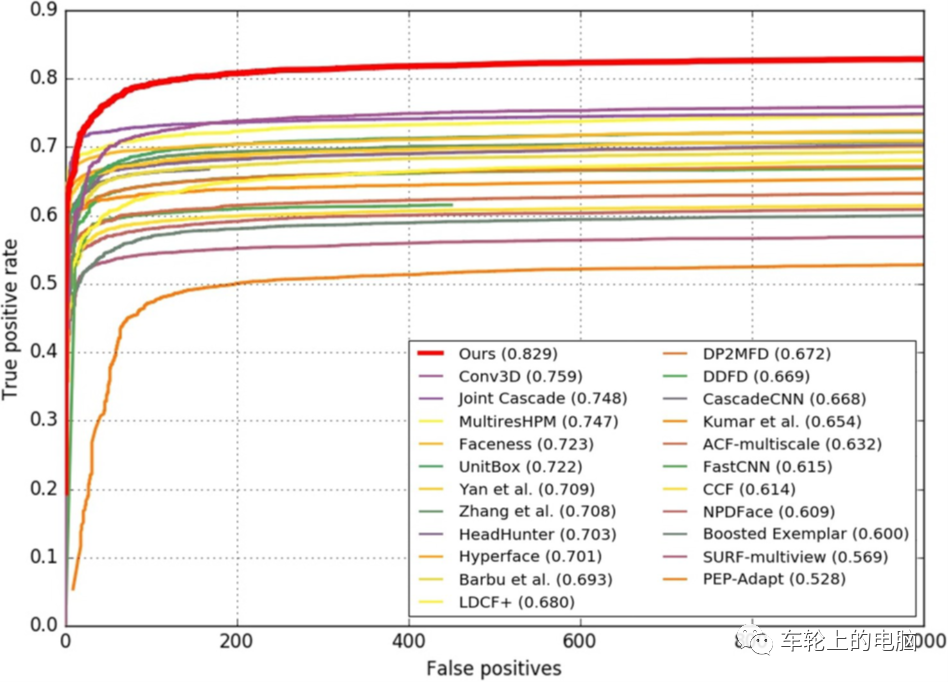
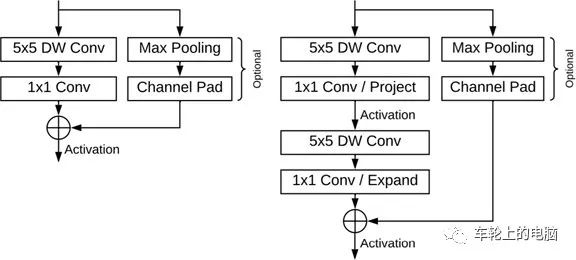
图16 FaceBoxes[10]算法pilelineVGA分辨率图像输入,单个CPU内核上(E5-2660v3@2.60)运行速度为20FPS,GPU(Titan X (Pascal))上125FPS。方法在FDDB上也取得了当时SOTA的结果(见图17)。图17 FaceBoxes[10]在FDDB上的实验结果 2019年谷歌发布了一款专为移动 GPU 推理量身定制的轻量级且性能卓越的人脸检测器——亚毫秒级的人脸检测算法 BlazeFace[11]。它能够在旗舰设备上以200-1000+FPS的速度运行。这种超实时性能使BlazeFace能够应用于任何对性能要求极高的现实应用中,如手机上。方法的主要创新点为:- 受MobileNet启发,提出极轻量级特征提取网络BlazeBlock。具体的使用5*5卷积核代替3*3卷积核,不会带来太大开销,但是可以增大感受野。前置摄像头下,人脸尺度变化较小,可以定义更加轻量级的特征提取,输入图像128*128,含有5个BlazeBlock和6个double BlazeBlock(见图18)。
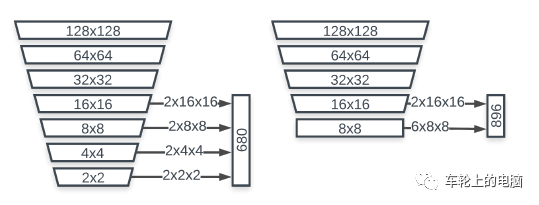
图18 BlazeBlock和double BlazeBlock结构图 [11]- 优化的anchor 机制,在8*8特征图尺寸处停止下采样(见图19),将8*8,4*4和2*2分辨率中的每个像素的2个anchor替换为8*8的6个anchor。由于人脸长宽比的变化有限,因此将anchor固定为1:1足以进行精确的人脸检测。
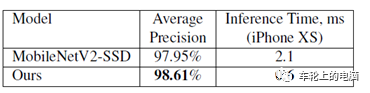
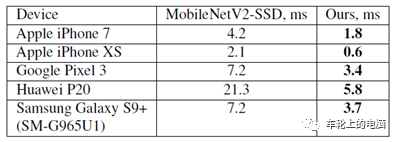
图19 Anchor计算: SSD (left) vs. BlazeFace [11]BlazeFace重点说明在手机终端真实应用中,检测算法的加速,故没有与但是SOTA(state-of-the-art)的算法在公开数据集上精度的比较,而只是在谷歌的私有数据集上与MobileNetV2-SSD进行了比较。图20是比较结果,精度高于MobileNetV2-SSD,在iPhone XS上的速度也从2.1ms降到0.6ms。另外可以看到BlazeFace在不同的手机上也获得了很大的速度提升。人脸识别技术经过多年的发展,内涵已极为丰富并且应用广泛。本次为大家讲解了人脸识别的发展历史、技术流程以及重点介绍了人脸检测算法,希望借此帮助大家理解、认识如今我们已经习惯使用的人脸识别功能。下次,我们将继续为大家讲解人脸识别的另一关键技术——人脸关键点检测算法。我们下期见!
引用附录:
[1]科普文章丨生物特征识别:确认过“掌纹” 找到对的人
http://www.ioa.cas.cn/kxchb/kpzp/kpwz/202112/t20211222_6325383.html
[2]Adjabi, Insaf, et al. "Past, present, and future of face recognition: A review." Electronics 9.8 (2020): 1188.
[3]Schroff, Florian, Dmitry Kalenichenko, and James Philbin. "Facenet: A unified embedding for face recognition and clustering." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
[4]http://shuoyang1213.me/WIDERFACE/
[5]Hu, Peiyun, and Deva Ramanan. "Finding tiny faces." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[6]http://vis-www.cs.umass.edu/fddb/index.html
[7]Viola P, Jones M. Rapid object detection using a boosted cascade of simple features[C]//Proceedings of the 2001 IEEE computer society conference on computer vision and pattern recognition. CVPR 2001. IEEE, 2001, 1: I-I.
[8]Li, Haoxiang, et al. "A convolutional neural network cascade for face detection." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
[9]Zhang K, Zhang Z, Li Z, et al. Joint face detection and alignment using multitask cascaded convolutional networks[J]. IEEE Signal Processing Letters, 2016, 23(10): 1499-1503.
[10]Zhang S, Zhu X, Lei Z, et al. Faceboxes: A CPU real-time face detector with high accuracy[C]//2017 IEEE International Joint Conference on Biometrics (IJCB). IEEE, 2017: 1-9.
[11]Bazarevsky, Valentin, et al. "Blazeface: Sub-millisecond neural face detection on mobile gpus." arXiv preprint arXiv:1907.05047 (2019).
[12]https://www.52cv.net/?p=1006
[13]https://www.nist.gov/programs-projects/face-recognition-grand-challenge-frgc
[14]https://www.cs.cmu.edu/~deva/papers/face/face-cvpr12.pdf
[15]https://www.tugraz.at/institute/icg/research/team-bischof/lrs/downloads/aflw/
[16]https://ieeexplore.ieee.org/document/6751298
[17]https://ibug.doc.ic.ac.uk/resources/300-W/
[18]Belhumeur, P., Jacobs, D., Kriegman, D., Kumar, N.. ‘Localizing parts of faces using a consensus of exemplars’. In Computer Vision and Pattern Recognition, CVPR. (2011).
[19]X. Zhu, D. Ramanan. ‘Face detection, pose estimation and landmark localization in the wild’, Computer Vision and Pattern Recognition (CVPR) Providence, Rhode Island, June 2012.
[20]Vuong Le, Jonathan Brandt, Zhe Lin, Lubomir Boudev, Thomas S. Huang. ‘Interactive Facial Feature Localization’, ECCV2012.
[21]Messer, K., Matas, J., Kittler, J., Luettin, J., Maitre, G. ‘Xm2vtsdb: The ex- tended m2vts database’. In: 2nd international conference on audio and video-based biometric person authentication. Volume 964. (1999).
[22]https://wywu.github.io/projects/LAB/WFLW.html
[23]https://facial-landmarks-localization-challenge.github.io/
[24]T.F. Cootes, C.J. Taylor, D.H. Cooper, et al. Active Shape Models-Their Training and Application[J]. Computer Vision and Image Understanding, 1995, 61(1):38-59.
[25]G. J. Edwards, T. F. Cootes, C. J. Taylor. Face recognition using active appearance models[J]. Computer Vision—Eccv』, 1998, 1407(6):581-595.
[26]Dollár P, Welinder P, Perona P. Cascaded pose regression[J]. IEEE, 2010, 238(6):1078-1085.
[27]Sun Y, Wang X, Tang X. Deep convolutional network cascade for facial point detection, CVPR. 2013: 3476-3483.
[28]Zhang Z, Luo P, Loy C C, et al. Facial landmark detection by deep multi-task learning, European conference on computer vision. Springer, Cham, 2014: 94-108.
[29]https://towardsdatascience.com/understanding-auc-roc-curve-68b2303cc9c5
[30]O. Jesorsky, K. J. Kirchberg, and R. Frischholz. Robust face detection using the hausdorff distance. In Proc. AVBPA, 2001.
[31]P. N. Belhumeur, D. W. Jacobs, D. J. Kriegman, and N. Kumar. Localizing parts of faces using a consensus of exemplars. In Proc. CVPR, 2011.
免责声明:本文系网络转载,版权归原作者所有。本文所用视频、图片、文字如涉及作品版权问题,请第一时间告知,我们将立即删除内容!本文内容为原作者观点,并不代表本公众号赞同其观点和对其真实性负责。