


Paper: https://arxiv.org/abs/2203.15439
Part 1
摘要
事件相机(Event Camera)是一种生物启发式的新型视觉传感器,也被称作动态视觉传感器(DVS,Dynamic Vision Sensor),它根据外部场景亮度的动态变化进行采样,具有独特的异步性和输出数据的稀疏性。由于其低延迟、低功耗、高动态范围、低数据冗余等优点,事件相机在小型移动终端的计算机视觉算法部署上具有广阔应用前景。基于单目事件相机的立体视觉算法(Event-based Monocular Multi-view Stereo, EMVS)利用一个运动轨迹已知的事件相机所产生的事件流,估计观测场景的半稠密三维空间结构,是基于单目事件相机的SLAM系统的重要组成部分,其运行效率直接关系到系统整体的性能表现。然而,若想在计算资源与电源功率均受限的嵌入式平台上部署EMVS算法并实时运行,目前的通用处理器则难以满足需求。
为了解决此问题,我们采取软硬件协同优化策略,提出了一种基于单目事件相机的立体视觉高效能FPGA加速器:Eventor。Eventor配备有高度并行化且完全流水化的FPGA硬件加速模块,用于加速EMVS算法中最关键且耗时的部分;此外,Eventor还集成了一个嵌入式ARM处理器用于处理算法的其他部分,并驱动和调度FPGA加速模块。同时,我们使用算法重构、近似计算和混合精度数据量化等策略,对Eventor所搭载的EMVS软件算法进行了优化,使其对硬件更加友好。最终实现的实验评估结果表明,运行EMVS算法时,Eventor的性能功耗比可以达到 Intel i5 CPU 的24倍,满足了在嵌入式平台上低功耗实时运行的要求。
Part 2
研究背景
事件相机
事件相机是近年来新兴的一种生物启发式视觉传感器,具备类脑感知的属性。不同于传统相机以帧为单位按固定的频率采集图像,事件相机的每个感光单元异步地测量每个像素接受光照的亮度变化。当一个像素位置发生的亮度变化超过既定的阈值时,会在当前位置触发一个“事件”(event),每个事件由对应亮度变化的像素位置、时间戳和极性三部分信息编码组成:![]()
事件相机将其捕捉到的亮度变化以事件流的格式输出。
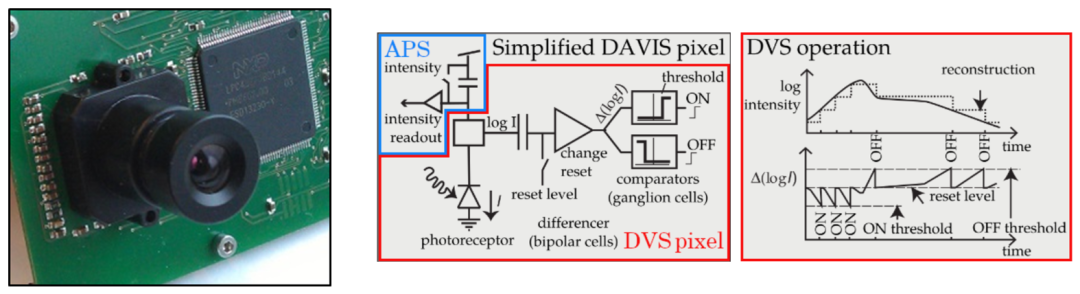

图2 事件相机与传统相机的输出对比示意图[2]
事件相机具有高时间分辨率和低延迟、高动态范围、低能耗和低数据冗余等特点,在机器人、便携设备等平台上,以及在处理高速、高动态光照渲染(High Dynamic Range, HDR)任务时具有很高的应用潜力。

图3 事件相机与传统相机观测现实场景的输出对比[2]
基于单目事件相机的立体视觉算法(EMVS)
立体视觉算法(Multi-view Stereo, MVS)的任务可以概括为“给定一组二维照片,在相机观测位置、场景光照条件和物体表面材料已知的条件下,创建照片中内容对应的三维模型”。而基于单目事件相机的立体视觉算法(EMVS)就是使用一个单目事件相机完成上述任务。只不过由于事件相机并不输出完整的二维图片而是持续输出事件流,所以不同于传统MVS算法可以得到稠密的场景重建模型,EMVS算法得到的重建结果通常是半稠密的。

图4 EMVS算法示意图

图5 一个典型的EMVS系统对现实场景进行重建的效果演示[2]
问题与挑战:EMVS在边缘嵌入式设备上的部署
Part 3
Evetor加速器:软硬件协同优化
基于上文提到的问题与挑战,我们采取软硬件协同优化的策略,针对EMVS算法设计了高效能FPGA硬件加速器——Eventor。
基础算法框架
Eventor的算法框架改进于一种目前已有的EMVS算法,由Henri Rebecq等人提出,其核心为一种基于事件的空间扫描方法(Event-based Space-Sweep Method)。
该EMVS算法首先将单目事件相机输出的事件流划分为若干事件帧(Event Frame),每一事件帧包含一定数量的事件,并且对应一个已知的相机位姿。算法以关键帧对应的相机坐标系为基准,对观测空间进行划分,创建离散化空间体素网格;随后将事件反向投影到观测空间中,统计每个空间体素网格中通过的反向投影射线数量;最后通过寻找射线密度局部最大值所在的网格,来估计空间中存在三维实体的位置。
存储观测空间各个体素网格中通过射线数量的数据结构被称为DSI (Disparity Space Image).
该算法与其他EMVS算法相比,有着相对较高的内部并行性、较低的计算冗余度和耦合性,最适合作为EMVS在嵌入式平台上部署的基础算法。为了确定限制算法整体性能的瓶颈,我们在DAVIS事件相机数据集上对目标算法进行了测试分析,结果表明“事件反向投影”(Event Back-Projection)和“体素化空间射线计数”(Volumetric Ray-Counting)占据了85%以上的算法运行时间。因此我们设计了FPGA硬件加速模块,主要对这两个环节进行加速。
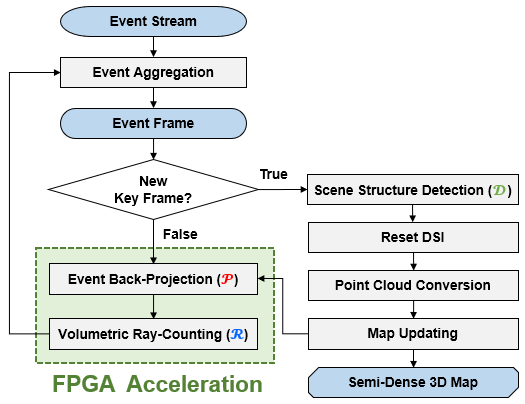
图6 Eventor采用的基础EMVS算法流程图

图7 基于事件的空间扫描方法的动画演示
软件算法优化
为了使目标EMVS算法对硬件加速更加友好,我们首先对其进行了软件算法方面的优化。我们采用了三种优化策略:算法重构、近似计算和混合精度数据量化。
在进行优化之前,我们对“事件反向投影”和“体素化空间射线计数”这两个关键环节进行了划分,将其分解为若干子任务。“事件反向投影”可以分为“向基准平面的事件反向投影”(Canonical Event Back-Projection,简称为基准投影)和“成比例的事件反向投影”(Proportional Event Back-Projection,简称为比例投影)及对应的参数计算环节。EMVS算法先将各事件帧中的事件反向投影到观测空间中的一个基准平面上,再使用基准平面上的投影坐标按照一种近似的比例运算关系将事件投影至空间的各个深度,遵循这种两步投影的方式将事件反向投影到观测空间中。
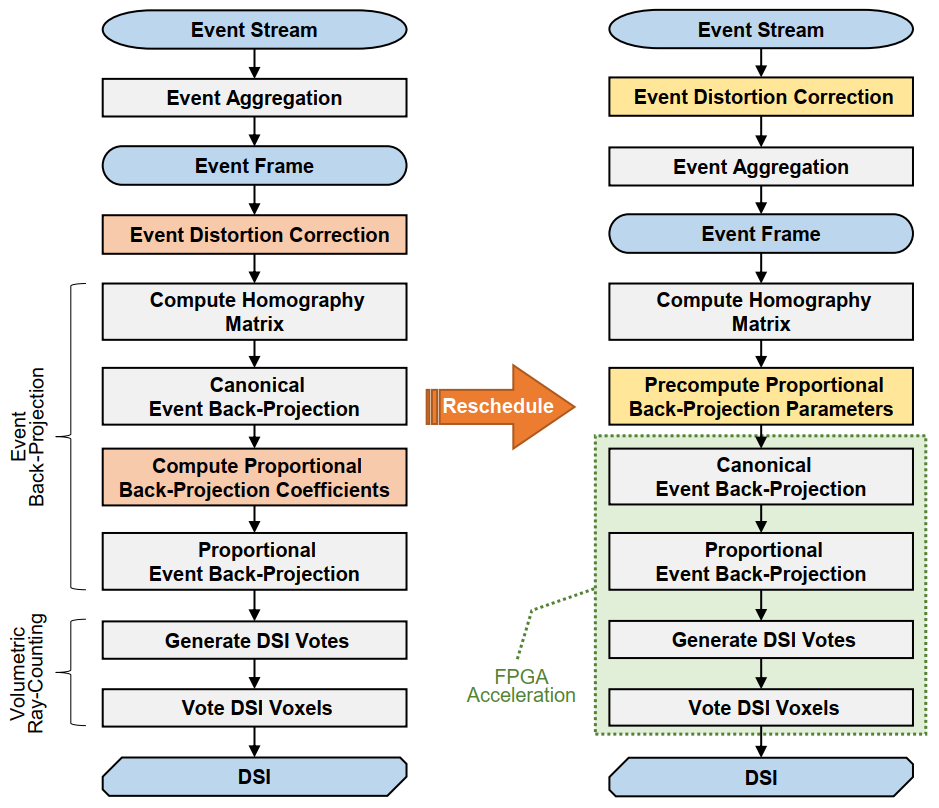
图8 Eventor对原始EMVS算法框架进行重构的示意图
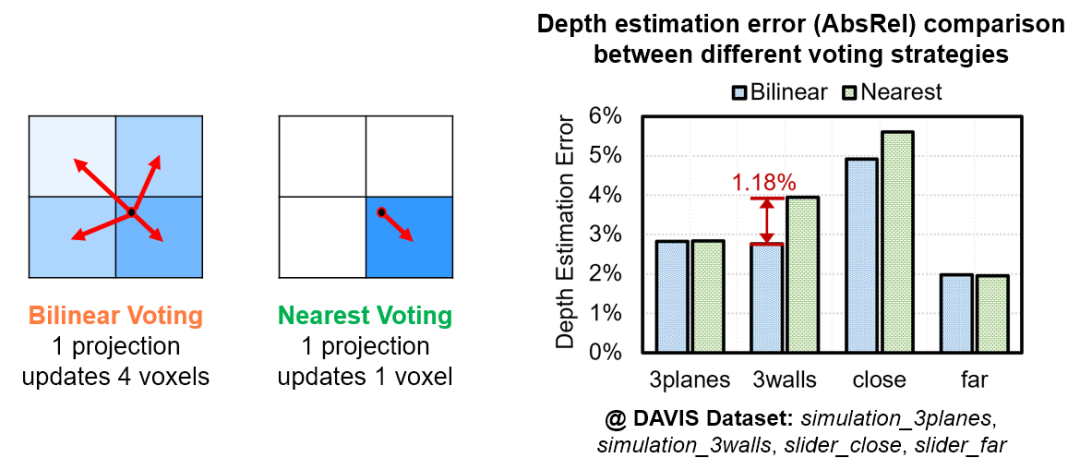
图9 两种DSI投票方法的示意图以及精度对比
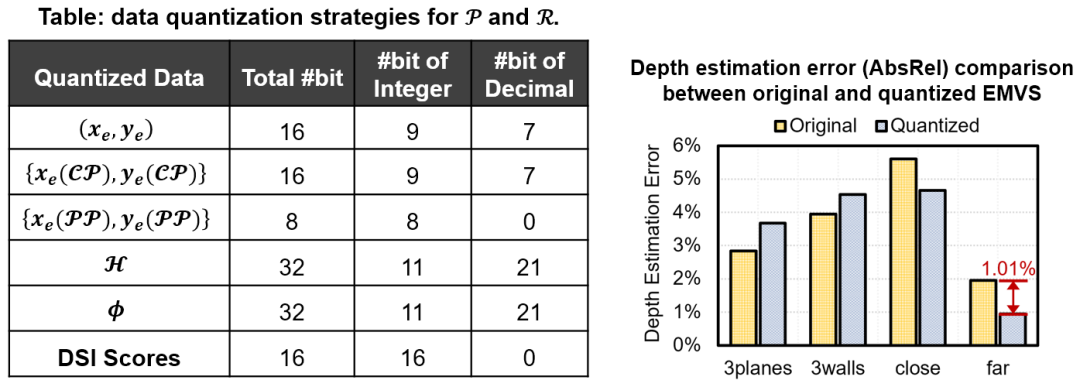
图10 Eventor采取的混合精度数据量化策略和量化前后算法精度对比
硬件加速器设计
基于优化后的EMVS算法框架,我们设计并实现了Eventor加速器的硬件部分。
为了设计专用计算硬件来有效地加速EMVS算法,我们首先分析了EMVS算法中可以被利用的计算并行性,并以此指导Eventor的硬件架构设计。EMVS的计算并行性可以按照粒度从细到粗划分为三个层次:
算子层次的并行性:可以通过同时部署多个ALU对矩阵和向量的运算进行加速,如乘法器阵列、加法器树等;
事件层次的并行性:不同事件在参与运算时相互间不存在数据依赖,因此可以被并行处理,且计算过程可以完全流水化;
DSI层次的并行性:DSI网格数据之间不存在相互依赖,因此同一事件向不同DSI网格的反向投影与投票等操作可以被并行处理。
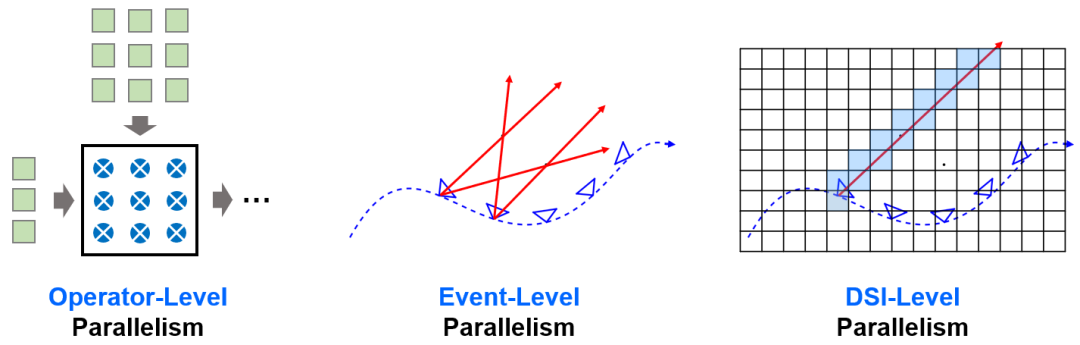
图11 EMVS算法中三个层次并行性的示意图
Eventor是一个ARM-FPGA异构加速器,架构如图12所示。其顶层可分为处理器系统 (Processing System, PS)、可编程逻辑 (Programmable Logic, PL)和外部存储空间 (External Memory) 三部分。处理器系统部分部署有一个嵌入式ARM处理器、DMA单元和DRAM控制器;可编程逻辑部分部署有两个FPGA计算加速模块。
Eventor开始工作时,ARM处理器配置DMA单元,将输入数据从DRAM搬运到FPGA加速模块的输入缓存中;随后ARM处理器配置并启动FPGA加速模块;FPGA加速模块开始计算并更新存储在DRAM中的DSI数据。
Eventor配备有两个FPGA计算加速模块:基准投影模块(Canonical Projection Module) 和比例投影模块 (Proportional Projection Module)。前者负责”向基准平面的事件反向投影“任务,后者负责”成比例的事件反向投影“和“体素化空间射线计数”任务。
基准投影模块:
缓存:输入缓存,存储输入事件坐标和预计算参数;中间缓存,存储事件基准投影后的坐标;采用乒乓缓存结构,减少输入输出延迟;
处理单元 (PE_Z0) :配有矩阵向量乘加单元(Matrix-Vector Multiply-Accumulate Units)和归一化函数单元;
控制器:有限状态机控制器,被配置完毕并启动后,无需ARM再进行控制;
利用并行性:算子层次的并行性、事件层次的并行性。
比例投影模块:
缓存:输出缓存,存储DSI投票地址(即需要更新的DSI网格坐标);采用乒乓缓存结构;
数据分配单元 (Data Allocator):将输入缓存中的比例投影参数和中间缓存中的事件投影坐标分配给各个处理单元;
处理单元 (PE_Zi):配有标量乘加单元 (Scalar Multiply-Accumulate Units) ,最邻近网格搜索单元,投票地址生成单元;并行部署多组,同时计算一个事件对多个DSI深度层的反向投影与投票;
投票执行单元 (Vote Execute Unit):使用输出缓存中的DSI投票地址,更新DRAM中存储的DSI数据;
控制器:有限状态机控制器,被配置完毕并启动后,无需ARM再进行控制;
利用并行性:算子层次的并行性、事件层次的并行性、DSI层次的并行性。
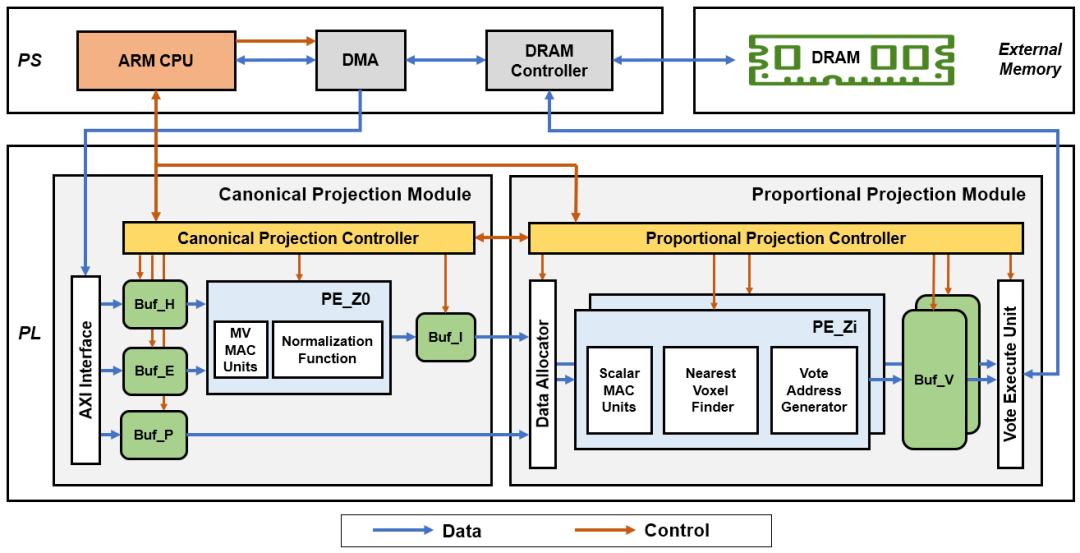
图12 Eventor加速器的硬件架构
Eventor的基准投影模块和比例投影模块按照流水化的模式进行工作。对于输入的普通事件帧,两个加速模块同时工作,无需等待流水线清空。此时每帧的实际处理时间等于”成比例的事件反向投影“和“体素化空间射线计数”两个任务的处理时间,而”向基准平面的事件反向投影“的处理时间被覆盖。这种流水化的工作流程同样利用了事件层次的并行性。
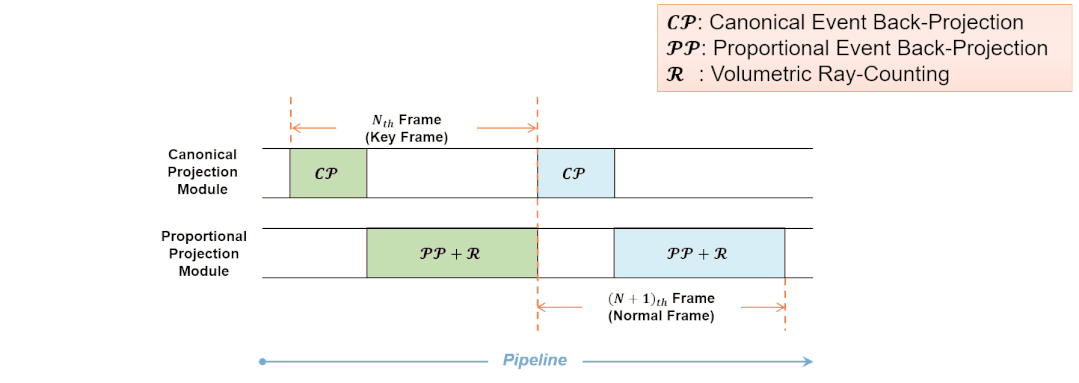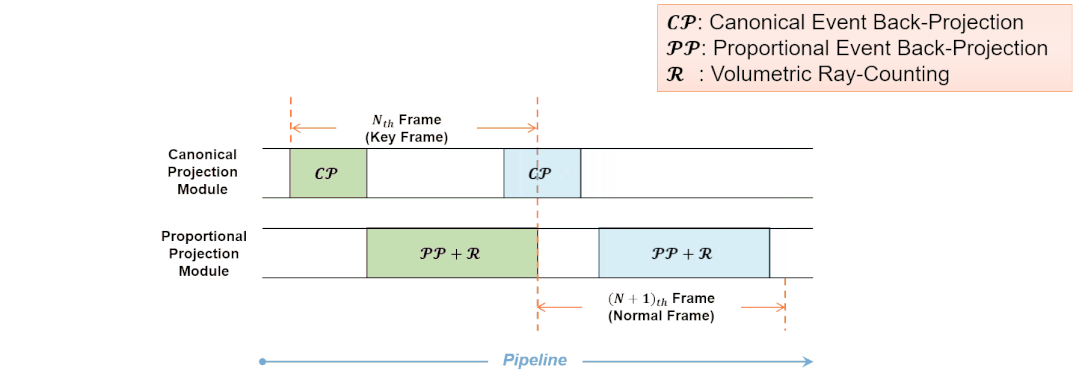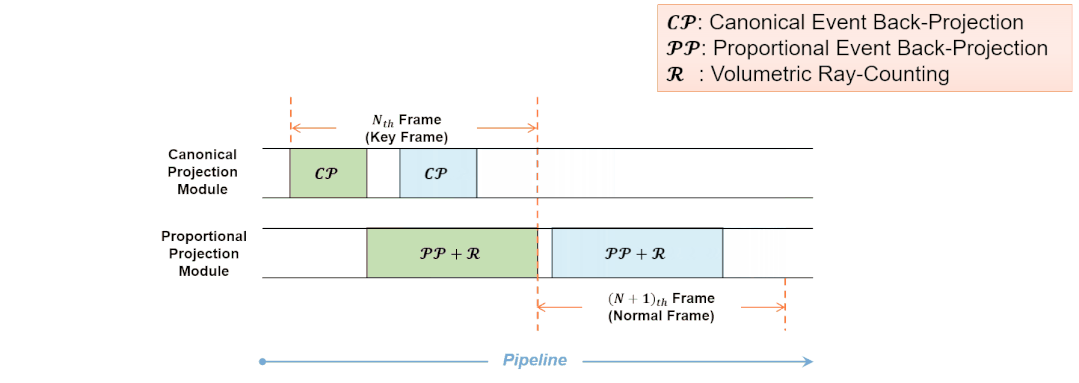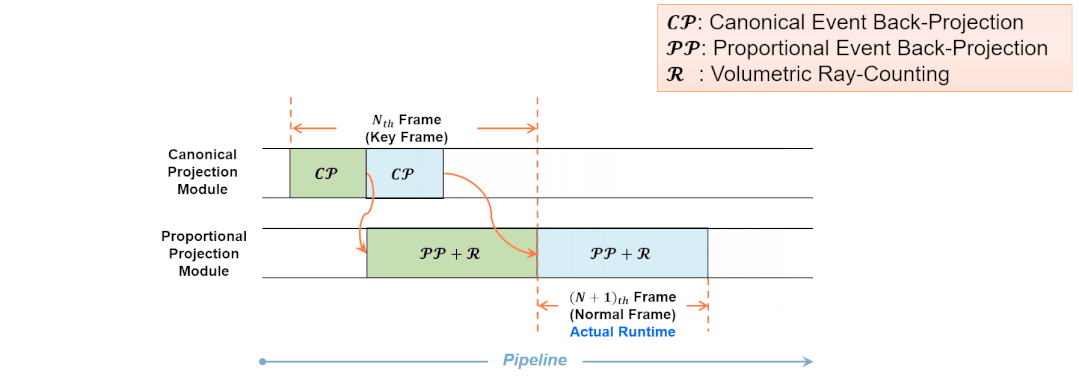
图13 基准投影模块和比例投影模块的流水化工作流程
Part 4
实验验证与分析
我们在FPGA异构开发平台上实现了Eventor,并使用DAVIS事件相机数据集对Eventor的计算准确度和效能表现进行了评估。
实验设置
硬件实现:
FPGA异构开发平台:Xilinx Zynq XC7Z020 SoC
Eventor时钟频率:FPGA加速模块为130MHz,DDR为533MHz
数据集:
DAVIS事件相机数据集:[Mueggler et al., The event-camera dataset and simulator: Event-based data for pose estimation, visual odometry, and SLAM. IJRR’17.]
事件相机分辨率:240×180
使用的事件相机模拟器生成样例:
simulation_3planes, simulation_3walls
使用的事件相机实拍样例:slider_close, slider_far

图14 实验使用的 Xilinx Zynq XC7Z020 SoC 和 Eventor 的开发板资源使用情况
计算准确度分析
我们使用DAVIS数据集中的四个样例(包括两个事件相机实拍样例和两个事件相机模拟器生成的样例)对我们优化后的硬件友好型EMVS框架进行了计算准确度测试,测试指标为平均深度估计误差。图15为原始EMVS框架和Eventor采取的改良后的EMVS框架的计算误差对比。实验结果表明,我们的EMVS框架对所有样例的计算误差均低于5%,且与原始框架相比最大的误差值仅有1.78%;在部分场景中,我们的EMVS框架拥有更高的精度。上述结果可以证明我们的EMVS框架的计算准确度满足实际应用要求。
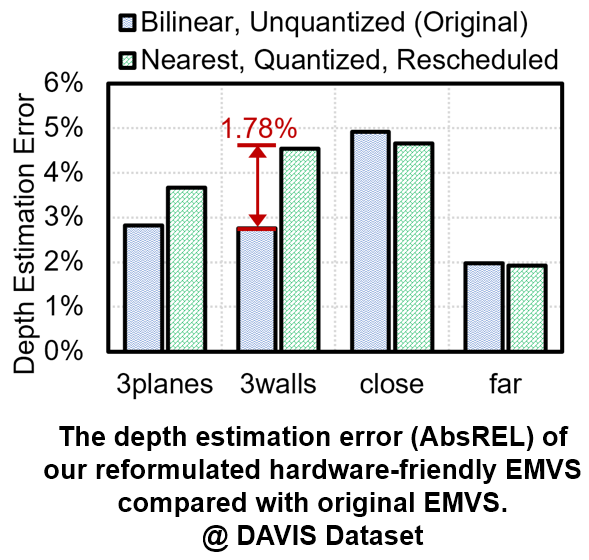
图15 原始EMVS框架和Eventor采取的改良EMVS框架的计算准确度对比
图16为使用我们的改良EMVS框架对simulation_3planes样例进行立体视觉重建的效果。该样例通过事件相机模拟器生成,观测场景为三个深度不同的平面。重建得到参考视点的置信图(统计参考视点各视线上的光线密度)、半稠密遮罩图(记录被物体边缘触发的视线位置)和最终重建得到的半稠密深度图如图所示。

图16 Eventor采取的改良EMVS框架对simulation_3planes样例进行立体视觉重建的效果展示
Eventor效能评估
我们以原始EMVS算法框架在Intel i5-7300HQ CPU上的实现作为基准,对Eventor的效能(包括计算性能、系统功耗和系统的性能功耗比)进行评估。下表列出了二者在算法运行时间、事件处理速率和系统功耗三方面的数据对比。可以看到与i5 CPU相比,Eventor的事件处理速率并无显著优势,但在系统功耗上Eventor远低于i5 CPU;考虑系统整体的性能功耗比,Eventor是i5 CPU的24倍以上。同时Eventor的事件处理速率高于1.8 M events/s, 满足EMVS算法实际运行时的实时性要求。
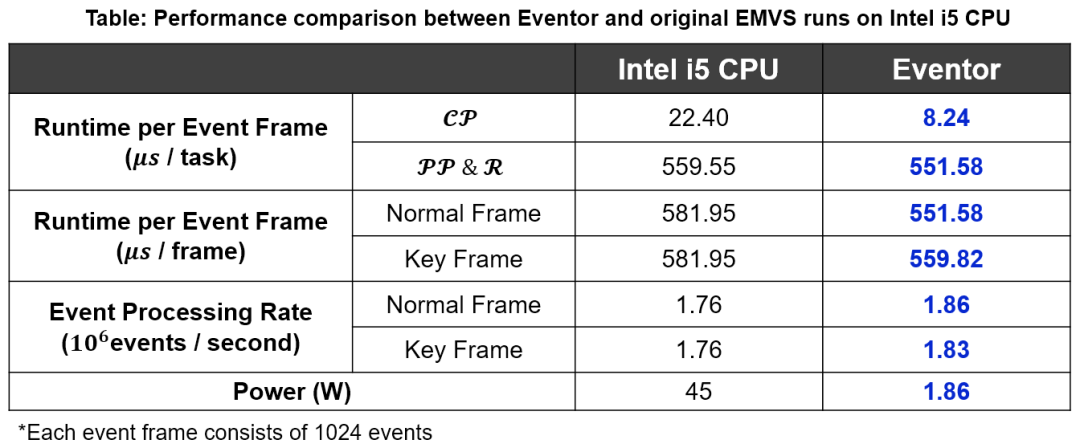
综上所述,Eventor的整体表现满足EMVS算法在资源和功率受限的嵌入式平台上实时运行的要求。
Part 5
总结
本工作提出了一种高效能的EMVS加速器——Eventor,并且在Zynq FPGA平台上完成了实现和测试。我们采取软硬件协同优化的策略来优化系统整体效能,最终实现的Eventor与Intel i5 CPU相比,性能功耗比提高了24倍,满足EMVS算法在资源和功率受限的嵌入式平台上实时运行的要求。
部分图片与演示引用自:
[1] Gallego G, Delbrück T, Orchard G, et al. Event-based vision: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 44(1): 154-180.
[2] Rebecq H, Gallego G, Mueggler E, et al. EMVS: Event-based multi-view stereo - 3D reconstruction with an event camera in real-time. IJCV’18.
以下为本工作在DAC 2022会议上的Talk Video:

