

原文: STM32N6,首款带有NPU的MCU即将问世 (qq.com)
据报道,ST将推出其首款配备完整神经处理单元 (NPU) 的微控制器STM32N6。
ST 微控制器和数字 IC 事业部总裁 Remi El-Ouazzane 表示:与其他STM32 MCU不同,STM32N6 包含一个专有的 NPU 和一个 ARM Cortex 内核。它还提供与配备 AI 加速器的四核处理器相同的 AI 性能,但功耗只有十二分之一,成本只有十分之一。
他说,该芯片将于 2022 年底出样。虽然没有提及将使用的 ARM 内核,但性能和功耗数据指向 ARM 的 M55 甚至是最近发布的最新内核 M85。M85 是 ARM 最高性能的 M 内核,每个周期最多发出 3 条指令,并具有用于 AI 的内部加速器,有助于提升性能。
ST 是 ARM 微控制器内核的主要领先开发商,在双核 M4/M7 STM32H7 和 STM32F7 系列中使用 ARM M7 内核以及 ART AI 加速器。一个新的家族,N6,指向使用一个新的核心。

“新的 STM32N6 神经 MCU 显着降低了 AI 技术实施的价格点。这一突破支持我们的新一代智能传感器路线图,允许在智能城市中迅速普及,”开发商 Lacroix 执行董事总经理 Vincent SABOT 说。
在工业和嵌入式设计中支持 AI 的推动下,ST 收购了 Frech 软件开发商 Cartesian,后者专注于 AI 工具的开发,使基于 ARM 的微控制器具备机器学习和推理能力。
此外,意法半导体的目标是最迟在 2027 年实现 200 亿美元的收入目标。意法半导体2021年的总销售额为127.6亿美元。到 2022 年,销售额预计将在 148 亿美元至 153 亿美元之间。
近年来,在严峻的经济环境下,全球核心短缺严重冲击了汽车等制造业。大多数芯片制造厂目前都在满负荷运转。意法半导体也不例外,其客户包括iPhone制造商苹果和电动汽车龙头特斯拉,因此不得不重金投资扩大产能。这也意味着ST可能会实现更高的新销售额和毛利率目标。
原文: 从头开始构建,DeepMind新论文用伪代码详解Transformer (qq.com)
2017 年 Transformer 横空出世,由谷歌在论文《Attention is all you need》中引入。这篇论文抛弃了以往深度学习任务里面使用到的 CNN 和 RNN。这一开创性的研究颠覆了以往序列建模和 RNN 划等号的思路,如今被广泛用于 NLP。大热的 GPT、BERT 等都是基于 Transformer 构建的。
Transformer 自推出以来,研究者已经提出了许多变体。但大家对 Transformer 的描述似乎都是以口头形式、图形解释等方式介绍该架构。关于 Transformer 的伪代码描述可参考的资料很少。
正如下面这段话所表达的:一位 AI 领域非常出名的研究者,曾向一位著名的复杂性理论家发送了一篇自认为写得非常好的论文。而理论家的回答是:我在论文中找不到任何定理,我不知道这篇论文是关于什么的。
对于从业者来说,论文可能足够详细,但理论家需要的精度通常更高。由于某些原因,DL 社区似乎不愿为他们的神经网络模型提供伪代码。
来自 DeepMind 的研究者认为提供伪代码有很多用途,与阅读文章或滚动 1000 行实际代码相比,伪代码将所有重要的内容浓缩在一页纸上,更容易开发新的变体。为此,他们最近发表的一篇论文《 Formal Algorithms for Transformers 》,文章以完备的、数学上精确的方式来描述 Transformer 架构。
本文涵盖了什么是 Transformer、Transformer 如何训练、Transformer 被用来做什么、Transformer 关键架构组件以及比较出名的模型预览。

论文地址:https://arxiv.org/pdf/2207.09238.pdf
原文:
https://mp.weixin.qq.com/s/OqKCF3xByXfvGLAYUDsBuA
首先,先让我 brainstorm 一下。当你看到 neural network scaling 这个词的时候你能想到什么?先不要看下文,把你想到的东西记下来。说不定这个简单的 brainstorm 能让你找到绝妙的 idea。
我想大多数人想到的应该是模型大小(宽度 + 深度),数据大小,或者图片像素等等。有没有哪位小科学家曾经想过去 scale convolutional kernels?scale 卷积核同样能增大模型的参数,但能带来像宽度和深度一样的增益吗?我这篇文章从这个角度出发深入探究了超大卷积核对模型表现的影响。我发现现有的大卷积核训练方法的瓶颈:现有的方法都无法无损的将卷积核 scale 到 31x31 以上,更别说用更大的卷积来进一步获得收益。
我这篇文章的贡献可以总结为以下几点:
(1)现有的方法可以将卷积核增大到 31x31。但在更大的卷积上,例如 51x51 和 61x61,开始出现明显掉点的现象。
(2)经典的 CNN 网络,如 ResNet 和 ConvNeXt,stem cell 都采用了 4× 降采样。所以对典型的 224×224 ImageNet 来说,51×51 的极端核已经大致等于全局卷积。和全局注意力机制一样,我推测全局卷积也存在着捕捉局部低级特征的能力不足的问题。
(3)基于此观察,我提出了一套训练极端卷积核的 recipe,能够丝滑的将卷积核增大到 61x61,并进一步提高模型的表现。我的方法论主要是基于人类视觉系统中普遍存在的稀疏性提出来的。在微观层面上,我将 1 个方形大卷积核分解为 2 个具有动态稀疏结构的,平行的长方形卷积核,用来提高大卷积的可扩展性;在宏观层面上,我构建了一个纯粹的稀疏网络,能够在提升网络容量的情况下保持着和稠密网络一样的参数和 FLOPs。
(4)根据这个 recipe,我构造了一个新型网络结构 Sparse Large Kernel Network,简称 SLaK。SLaK 搭载着有史以来最大的 51x51 卷积核,能够在相似的参数量和 FLOPs 的条件下,获得比最新先进的 ConvNeXt,Swin Transformer 和 RepLKNet 更好的性能。
(5)最后,作者认为本文最重要的贡献是 sparsity,通常作为模型压缩的“老伙计”,can be a promising tool to boost neural network scaling。

论文:https://arxiv.org/pdf/2207.03620.pdf
Pytorch 开源代码:https://github.com/VITA-Group/SLaK
原文:
https://mp.weixin.qq.com/s/XIo0EBVmXnVS1Iko31OokA
Andrej Karpathy撰文称:“很高兴帮助特斯拉实现过去 5 年的目标,做出这个离开的决定十分艰难。在与特斯拉的一起的日子里,Autopilot 从车道保持的研究中毕业,并开始城市街道方面的研究,我期望看到 Autopilot 团队继续保持这种势头勇往直前。”
据悉,Andrej Karpathy于2017年加盟特斯拉,在特斯拉任AI主管,并负责领导Autopilot计算机视觉团队(Director of AI and Autopilot Vision),负责构建Autopilot自动驾驶系统,直接向马斯克报告。
在特斯拉工作的5年中,Andrej领导了特斯拉自动辅助驾驶系统 Autopilot的开发,这项技术对特斯拉的全自动驾驶系统(FSD,Full Self-Driving Computer)有着至关重要的作用。Andrej在各大新闻中更是一度被称作为 「特斯拉的秘密武器」。
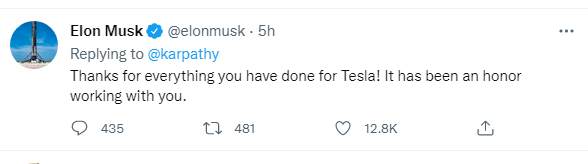
图注:马斯克在Andrej推下的回复
对此马斯克也进行了发声。他在Andrej推下表示“感谢你为特斯拉做的一切,与你共事是我的荣幸”。
原文:
https://mp.weixin.qq.com/s/fze-tgeCINiDdNGqNF-8RA
近日,ICML 2022 大会在美国马里兰州巴尔的摩市以线上线下结合的方式举办。这也是新冠疫情以来大会首次恢复线下形式举办。
目前,大会已经公布了全部奖项,包括 15 篇杰出论文奖和 1 项时间检验奖。其中,复旦大学、上海交通大学、厦门大学、莱斯大学胡侠团队等多个华人团队的研究获得杰出论文奖。ICML 2012 关于「投毒攻击」的论文《Poisoning Attacks against Support Vector Machines》获得了本次大会的时间检验奖。
杰出论文奖
论文 1:Monarch: Expressive Structured Matrices for Efficient and Accurate Training
机构:斯坦福大学、纽约州立大学布法罗分校、密歇根大学
作者:Tri Dao、Beidi Chen、Nimit Sohoni、 Arjun Desai、Michael Poli、Jessica Grogan、Alexander Liu、Aniruddh Rao、Atri Rudra、Christopher Re
论文地址:https://arxiv.org/abs/2204.00595

论文简介:该研究提出了一类硬件高效的矩阵 Monarch,具有解析最优解。实验表明,Monarch 可以加速 ViT 和 GPT-2 在 ImageNet 分类任务上的训练。在密集到稀疏微调中,作为概念验证,我们的 Monarch 近似算法以相当的精度将 GLUE 上的 BERT 微调速度提高了 1.7 倍。
论文 2:Solving Stackelberg Prediction Game with Least Squares Loss via Spherically Constrained Least Squares Reformulation
机构:复旦大学、厦门大学、卡内基梅隆大学
作者:Jiali Wang、Wen Huang、Rujun Jiang、Xudong Li、Alex L. Wang
论文地址:https://arxiv.org/abs/2206.02991

论文简介:Stackelberg 预测博弈 (SPG) 是表征学习者和攻击者之间策略交互中很重要的一个问题。该研究探索了 SPG-LS 的一种新型表述,将 SPG-LS 重写为球面约束最小二乘 (SCLS) 问题。数值结果合成和真实世界的数据集表明,借助 SCLS 方法,SPG-LS 可以比当前 SOTA 解决方案快几个数量级。
论文 3:G-Mixup: Graph Data Augmentation for Graph Classification
机构:莱斯大学胡侠团队
作者:韩霄天、Zhimeng Jiang 、Ninghao Liu、 胡侠(Xia Hu)
论文地址:https://arxiv.org/pdf/2202.07179.pdf

论文简介:该研究提出了一种名为 G-Mixup 的方法,通过插入不同类别图的生成器(即 graphon)来增强图分类。具体来说,该研究首先使用同一类中的图来估计一个 graphon,然后在欧几里得空间中插值不同类别的 graphon 以获得混合 graphon,合成图基于混合 graphon 生成。大量实验表明,G-Mixup 显著提高了 GNN 的泛化性和稳健性。
限于篇幅,剩下的论文各位可以跳转查看
原文:
https://mp.weixin.qq.com/s/hX0FMGRLy2yugR8__08dFQ
自动驾驶汽车靠各种传感器「看到」这个世界,然后再借助人工神经网络处理来自传感器的数据。它们和人类不同,因为人类是有记忆的,一条路多走几次就熟了,但对于使用人工神经网络的自动驾驶汽车来说,这条路每天都是新的。这在天气恶劣时会成为一个问题,因为这种天气下,传感器往往没有那么可靠。
为了缓解这一问题,来自康奈尔大学 Ann S. Bowers 计算机与信息科学学院和工程学院的研究人员在 CVPR 2022 上发表了两篇研究论文,在ICLR 22上发表了一篇论文,其核心思想是为自动驾驶汽车创造「记忆」,并在后续的行驶中使用这些记忆。
论文 1 标题为「HINDSIGHT is 20/20: Leveraging Past Traversals to Aid 3D Perception」,一作是博士生游宇榕(Yurong You),senior author 是康奈尔大学 Bowers CIS 计算机科学教授 Kilian Weinberger。

论文链接:https://arxiv.org/pdf/2203.11405.pdf
原文:
https://mp.weixin.qq.com/s/p808b8cFugcw1A_n6neNqg
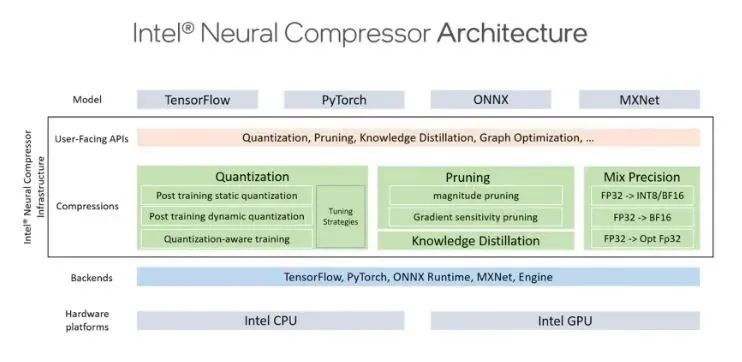
英特尔最近发布了 Neural Compressor,这是一个用于模型压缩的开源 Python 包。该库可应用于 CPU 或 GPU 上的深度学习部署,以减小模型大小并加快推理速度。此外它为著名的网络压缩技术提供统一的用户界面,包括跨各种深度学习框架的量化、修剪和知识蒸馏。该工具的自动精度驱动调整技术可用于生成最佳量化模型。此外,它允许知识蒸馏,以便可以将来自教师模型的知识转移到学生模型中。它实现了几种权重剪枝方法,以使用预定的稀疏目标生成剪枝模型。为了改进框架互操作性,
为了允许从模型级别到操作员级别的细粒度量化粒度,库的量化功能建立在标准 PyTorch 量化 API 之上并进行更改。英特尔神经压缩器通过提供用于量化、自动混合精度和精度感知调整的复杂配方来扩展 PyTorch 量化。它接受 PyTorch 模型作为输入,并生成一个理想模型作为响应。使用这种方法,用户可以提高准确性,而无需进行任何额外的手动调整。Neural Compressor 还具有自动精度感知调整方法,可提高量化效率。该工具在第一阶段搜索框架以获取多种量化能力,包括量化粒度、方案、数据类型和校准方法。然后询问每个运算符支持的数据类型。该工具使用这些查询的功能来产生各种量化配置的巨大调整空间并开始调整轮次。它对每组量化配置进行校准、量化和评估。当评估达到准确度目标时,该工具停止调整并创建量化模型。
非结构化和结构化权重修剪和过滤器修剪是英特尔神经压缩器修剪功能的重点。当训练期间权重的大小低于设定的阈值时,使用非结构化剪枝过程对权重进行剪枝。为了提高稀疏模型的效率,结构化剪枝结合了实验性的 tile-wise 稀疏内核。NLP 模型的头部、中间层和隐藏状态是根据梯度确定的重要性分数使用一种称为过滤器剪枝的剪枝算法进行剪枝的,该剪枝算法还包括梯度敏感性剪枝。为了将知识从较大的“教师”模型传输到较小的“学生”模型而不失去有效性,英特尔神经压缩器还使用了知识蒸馏技术。
为了在使用流行的神经网络压缩技术时提高生产力并解决与精度损失相关的问题,英特尔推出了 Neural Compressor。Neural Compressor 具有易于使用的 API 和自动调整机制。该团队一直致力于通过包含更多压缩公式并融合这些方法来创建理想模型来改进该工具。此外,该团队还征求开源社区的意见,并鼓励人们为 Python 包做出贡献。可以在此处访问该库的 Github 存储库。
https://github.com/intel/neural-compressor
原文:
https://mp.weixin.qq.com/s/bbOUeG0aQX6pJb_oki8jYA
咦,怎么好好的藤原千花,突然变成了“高温红色版”?

这大紫手,难道是灭霸在世??

如果你以为上面的这些效果只是对物体后期上色了,那还真是被AI给骗到了。
这些奇怪的颜色,其实是对视频对象分割的表示。
但u1s1,这效果还真是让人一时间分辨不出。
AI对目标的分割都称得上是严丝合缝,仿佛是把颜色“焊”了上去。
不只是高精度分割目标,这种方法还能处理超过10000帧的视频。
而且分割效果始终保持在同一水平,视频后半段依旧丝滑精细。

更意外的是,这种方法对GPU要求不高。
研究人员表示实验过程中,该方法消耗的GPU内存从来没超过1.4GB。
要知道,当下基于注意力机制的同类方法,甚至都不能在普通消费级显卡上处理超过1分钟的视频。
这就是伊利诺伊大学厄巴纳-香槟分校学者最新提出的一种长视频目标分割方法XMem。
目前已被ECCV 2022接收,代码也已开源。
论文地址:
https://arxiv.org/abs/2207.07115
GitHub:
https://github.com/hkchengrex/XMem
仅提供链接。
内容仅供各位学习参考,文章仅代表作者个人看法,不代表本平台观点,版权归原作者所有,转载请联系作者,如有版权疑问,请联系本微信后台,我们会第一时间处理。
END

爱我就给我点在看
 点击 “阅读原文”
点击 “阅读原文”
