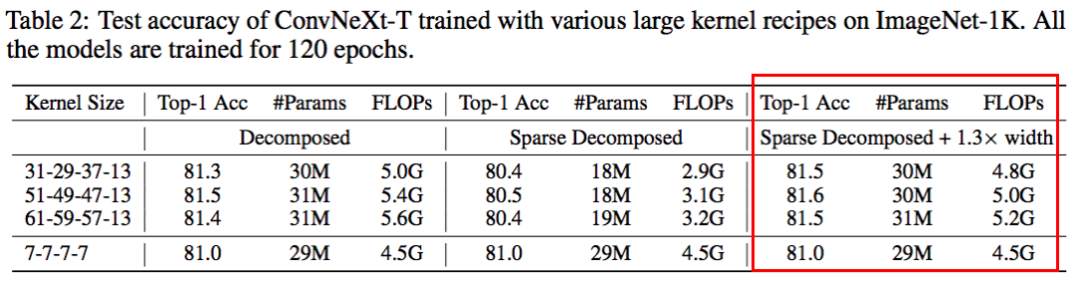
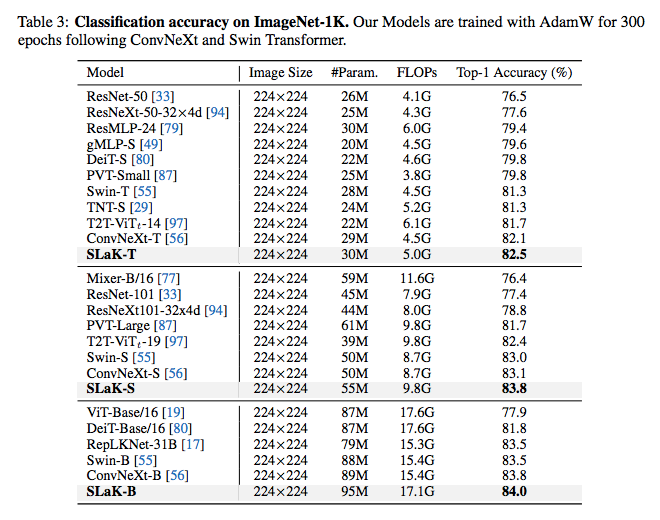
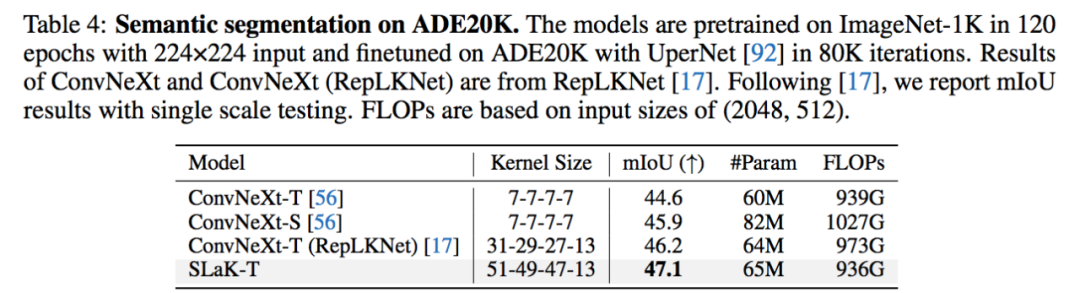
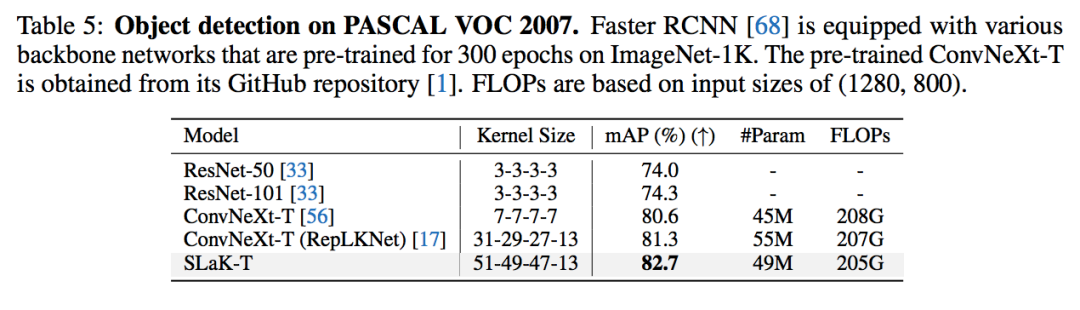
1,微软下载免费Visual Studio Code2,安装C/C++插件,如果无法直接点击下载, 可以选择手动install from VSIX:ms-vscode.cpptools-1.23.6@win32-x64.vsix3,安装C/C++编译器MniGW (MinGW在 Windows 环境下提供类似于 Unix/Linux 环境下的开发工具,使开发者能够轻松地在 Windows 上编写和编译 C、C++ 等程序.)4,C/C++插件扩展设置中添加Include Path 5,
黎查
2025-02-28 14:39
140浏览