Ftrace训练营火热报名中:Ftrace训练营:站在设计者的角度来理解ftrace(限50人)。训练营第一期报名已圆满成功,好评如潮。第二期报名正在火爆进行中(咨询小月微信:linuxer2016)。
ARM安全架构训练营2期火热报名中:阅码场训练营:ARM安全架构之Trustzone/TEE实战--【介绍视频】。报名咨询客服(小月微信:linuxer2016)。
ARM架构与调优调试训练营火热报名中:阅码场训练营:ARM架构与调试调优。报名咨询客服(小月微信:linuxer2016)。
阅码场用户程磊对《Linux内核深度解析》推荐如下:
1.语言浅显易懂,内容深入浅出。
2.逻辑清晰,条理分明,逐步深入,层层递进。
3.基于较新的4.12内核版本,很多经典内核书籍虽然写的都非常好,但是都是基于2.6内核,很多在2.6之后引入的新技术并没有讲到,而本书对这些新技术都有非常详细的讲解。

作者简介:
余华兵,2005年毕业于华中科技大学计算机学院,取得硕士学位。毕业后的十余年一直在网络通信行业从事软件设计和开发工作,研究方向包括IPv4协议栈、IPv6协议栈和Linux内核。
目录
3.1 概述
3.1.2 内核空间
3.1.3 硬件层面
3.2 虚拟地址空间布局
3.3 物理地址空间
3.1 内存管理概述
内存管理子系统的架构如图 3.1 所示,分为用户空间、内核空间和硬件 3 个层面。
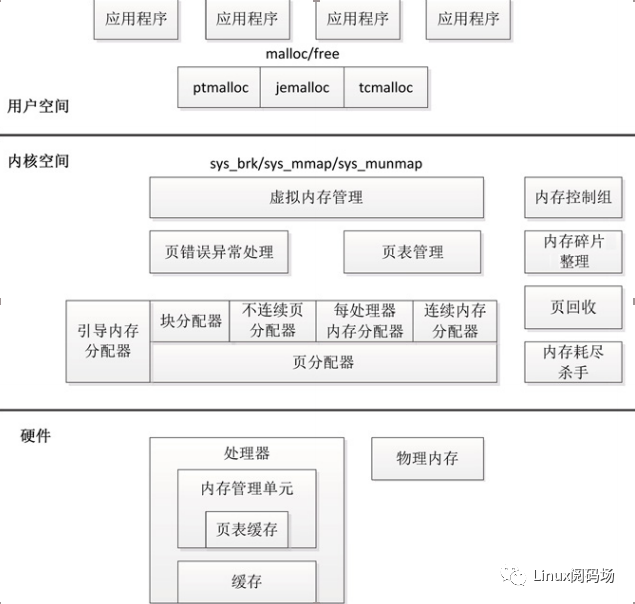
图3.1 内存管理架构
3.1.1.用户空间
应用程序使用 malloc()申请内存,使用 free()释放内存。
malloc()和 free()是 glibc 库的内存分配器 ptmalloc 提供的接口,ptmalloc 使用系统调用brk 或 mmap 向内核以页为单位申请内存,然后划分成小内存块分配给应用程序。
用户空间的内存分配器,除了 glibc 库的 ptmalloc,还有谷歌公司的 tcmalloc 和 FreeBSD的 jemalloc。
3.1.2.内核空间
(1)内核空间的基本功能。
虚拟内存管理负责从进程的虚拟地址空间分配虚拟页,sys_brk 用来扩大或收缩堆,sys_mmap 用来在内存映射区域分配虚拟页,sys_munmap 用来释放虚拟页。
内核使用延迟分配物理内存的策略,进程第一次访问虚拟页的时候,触发页错误异常,页错误异常处理程序从页分配器申请物理页,在进程的页表中把虚拟页映射到物理页。
页分配器负责分配物理页,当前使用的页分配器是伙伴分配器。
内核空间提供了把页划分成小内存块分配的块分配器,提供分配内存的接口 kmalloc()和释放内存的接口 kfree(),支持 3 种块分配器:SLAB 分配器、SLUB 分配器和 SLOB分配器。
在内核初始化的过程中,页分配器还没准备好,需要使用临时的引导内存分配器分配内存。
(2)内核空间的扩展功能。
不连续页分配器提供了分配内存的接口 vmalloc 和释放内存的接口 vfree,在内存碎片化的时候,申请连续物理页的成功率很低,可以申请不连续的物理页,映射到连续的虚拟页,即虚拟地址连续而物理地址不连续。
每处理器内存分配器用来为每处理器变量分配内存。
连续内存分配器(Contiguous Memory Allocator,CMA)用来给驱动程序预留一段连续的内存,当驱动程序不用的时候,可以给进程使用;当驱动程序需要使用的时候,把进程占用的内存通过回收或迁移的方式让出来,给驱动程序使用。
内存控制组用来控制进程占用的内存资源。
当内存碎片化的时候,找不到连续的物理页,内存碎片整理(“memory compaction”的意译,直译为“内存紧缩”)通过迁移的方式得到连续的物理页。
在内存不足的时候,页回收负责回收物理页,对于没有后备存储设备支持的匿名页,把数据换出到交换区,然后释放物理页;对于有后备存储设备支持的文件页,把数据写回存储设备,然后释放物理页。如果页回收失败,使用最后一招:内存耗尽杀手(OOM killer,Out-of-Memory killer),选择进程杀掉。
3.1.3.硬件层面
处理器包含一个称为内存管理单元(Memory Management Unit,MMU)的部件,负责把虚拟地址转换成物理地址。
内存管理单元包含一个称为页表缓存(Translation Lookaside Buffer,TLB)的部件,保存最近使用过的页表映射,避免每次把虚拟地址转换成物理地址都需要查询内存中的页表。
为了解决处理器的执行速度和内存的访问速度不匹配的问题,在处理器和内存之间增加了缓存。缓存通常分为一级缓存和二级缓存,为了支持并行地取指令和取数据,一级缓存分为数据缓存和指令缓存。
3.2 虚拟地址空间布局
3.2.1 虚拟地址空间划分
因为目前应用程序没有那么大的内存需求,所以 ARM64 处理器不支持完全的 64 位虚拟地址,实际支持情况如下。

图3.2 ARM64内核/用户虚拟地址空间划分
(1)虚拟地址的最大宽度是 48 位,如图 3.2 所示。内核虚拟地址在 64 位地址空间的顶部,高 16 位是全 1,范围是[0xFFFF 0000 00000000,0xFFFF FFFF FFFF FFFF];用户虚拟地址在 64 位地址空间的底部,高 16 位是全 0,范围是[0x0000 0000 0000 0000,0x0000 FFFF FFFF FFFF];高 16 位是全 1 或全 0 的地址称为规范的地址,两者之间是不规范的地址,不允许使用。
(2)如果处理器实现了 ARMv8.2 标准的大虚拟地址(Large Virtual Address,LVA)支持,并且页长度是 64KB,那么虚拟地址的最大宽度是 52 位。
(3)可以为虚拟地址配置比最大宽度小的宽度,并且可以为内核虚拟地址和用户虚拟地址配置不同的宽度。转换控制寄存器(Translation Control Register)TCR_EL1 的字段 T0SZ 定义了必须是全 0 的最高位的数量,字段 T1SZ 定义了必须是全 1 的最高位的数量,用户虚拟地址的宽度是(64-TCR_EL1.T0SZ),内核虚拟地址的宽度是(64-TCR_EL1.T1SZ)。
在编译 ARM64 架构的 Linux 内核时,可以选择虚拟地址宽度。
(1)如果选择页长度 4KB,默认的虚拟地址宽度是 39 位。
(2)如果选择页长度 16KB,默认的虚拟地址宽度是 47 位。
(3)如果选择页长度 64KB,默认的虚拟地址宽度是 42 位。
(4)可以选择 48 位虚拟地址。
在 ARM64 架构的 Linux 内核中,内核虚拟地址和用户虚拟地址的宽度相同。
所有进程共享内核虚拟地址空间,每个进程有独立的用户虚拟地址空间,同一个线程组的用户线程共享用户虚拟地址空间,内核线程没有用户虚拟地址空间。
3.2.2 用户虚拟地址空间布局
进程的用户虚拟地址空间的起始地址是 0,长度是 TASK_SIZE,由每种处理器架构定义自己的宏 TASK_SIZE。ARM64 架构定义的宏 TASK_SIZE 如下所示。
(1)32 位用户空间程序:TASK_SIZE 的值是TASK_SIZE_32,即0x100000000,等于4GB。
(2)64 位用户空间程序:TASK_SIZE 的值是 TASK_SIZE_64,即 2VA_BITS字节,VA_BITS是编译内核时选择的虚拟地址位数。
arch/arm64/include/asm/memory.h#define VA_BITS (CONFIG_ARM64_VA_BITS)#define TASK_SIZE_64 (UL(1) << VA_BITS)#ifdef CONFIG_COMPAT /* 支持执行32位用户空间程序 */#define TASK_SIZE_32 UL(0x100000000)/* test_thread_flag(TIF_32BIT)判断用户空间程序是不是32位 */#define TASK_SIZE (test_thread_flag(TIF_32BIT) ? \TASK_SIZE_32 : TASK_SIZE_64)#define TASK_SIZE_OF(tsk) (test_tsk_thread_flag(tsk, TIF_32BIT) ? \TASK_SIZE_32 : TASK_SIZE_64)#else#define TASK_SIZE TASK_SIZE_64#endif /* CONFIG_COMPAT */
进程的用户虚拟地址空间包含以下区域。
(1)代码段、数据段和未初始化数据段。
(2)动态库的代码段、数据段和未初始化数据段。
(3)存放动态生成的数据的堆。
(4)存放局部变量和实现函数调用的栈。
(5)存放在栈底部的环境变量和参数字符串。
(6)把文件区间映射到虚拟地址空间的内存映射区域。
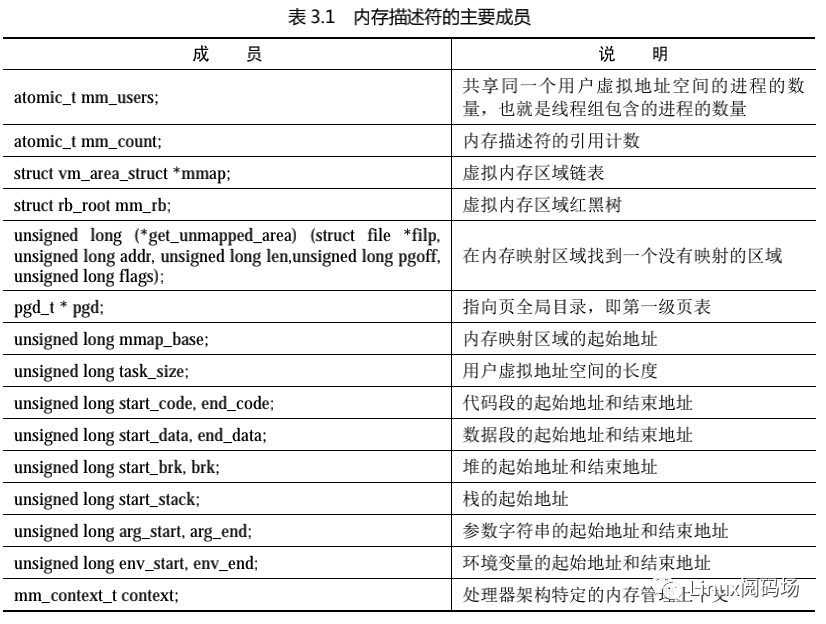
内核使用内存描述符 mm_struct 描述进程的用户虚拟地址空间,内存描述符的主要成员如表 3.1 所示。
进程描述符(task_struct)中和内存描述符相关的成员如表 3.2 所示。

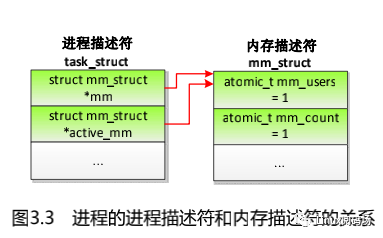
如果进程不属于线程组,那么进程描述符和内存描述符的关系如图 3.3 所示,进程描述符的成员 mm 和 active_mm 都指向同一个内存描述符,内存描述符的成员 mm_users 是 1、成员 mm_count 是 1。
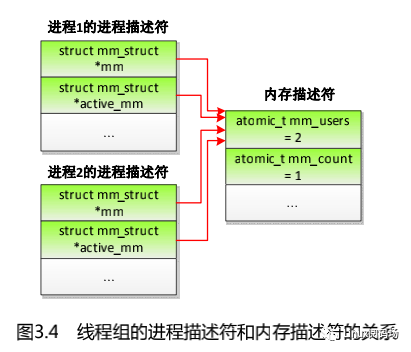
如果两个进程属于同一个线程组,那么进程描述符和内存描述符的关系如图 3.4 所示,每个进程的进程描述符的成员 mm 和 active_mm 都指向同一个内存描述符,内存描述符的成员 mm_users 是 2、成员 mm_count 是 1。
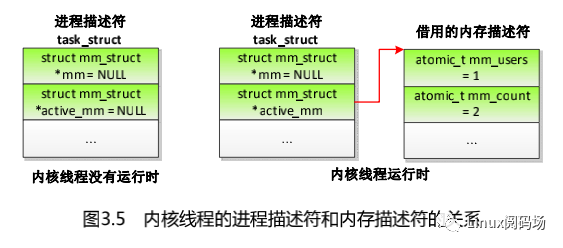
内核线程的进程描述符和内存描述符的关系如图 3.5 所示,内核线程没有用户虚拟地址空间,当内核线程没有运行的时候,进程描述符的成员 mm 和 active_mm 都是空指针;当内核线程运行的时候,借用上一个进程的内存描述符,在被借用进程的用户虚拟地址空间的上方运行,进程描述符的成员 active_mm 指向借用的内存描述符,假设被借用的内存描述符所属的进程不属于线程组,那么内存描述符的成员 mm_users 不变,仍然是 1,成员mm_count 加 1 变成 2。
为了使缓冲区溢出攻击更加困难,内核支持为内存映射区域、栈和堆选择随机的起始地址。进程是否使用虚拟地址空间随机化的功能,由以下两个因素共同决定。
(1)进程描述符的成员 personality(个性化)是否设置 ADDR_NO_RANDOMIZE。
(2)全局变量 randomize_va_space:0 表示关闭虚拟地址空间随机化,1 表示使内存映射区域和栈的起始地址随机化,2 表示使内存映射区域、栈和堆的起始地址随机化。可以通过文件“/proc/sys/kernel/randomize_va_space”修改。
mm/memory.cint randomize_va_space __read_mostly =#ifdef CONFIG_COMPAT_BRK1;#else2;#endif
为了使旧的应用程序(基于 libc5)正常运行,默认打开配置宏 CONFIG_COMPAT_BRK,禁止堆随机化。所以默认配置是使内存映射区域和栈的起始地址随机化。
栈通常自顶向下增长,当前只有惠普公司的 PA-RISC 处理器的栈是自底向上增长。栈的起始地址是 STACK_TOP,默认启用栈随机化,需要把起始地址减去一个随机值。STACK_TOP是每种处理器架构自定义的宏,ARM64 架构定义的 STACK_TOP 如下所示:如果是 64 位用户空间程序,STACK_TOP 的值是 TASK_SIZE_64;如果是 32 位用户空间程序,STACK_TOP的值是异常向量的基准地址 0xFFFF0000。
arch/arm64/include/asm/processor.h#define STACK_TOP_MAX TASK_SIZE_64#ifdef CONFIG_COMPAT /* 支持执行32位用户空间程序 */#define AARCH32_VECTORS_BASE 0xffff0000#define STACK_TOP (test_thread_flag(TIF_32BIT) ? \AARCH32_VECTORS_BASE : STACK_TOP_MAX)#else#define STACK_TOP STACK_TOP_MAX#endif /* CONFIG_COMPAT */
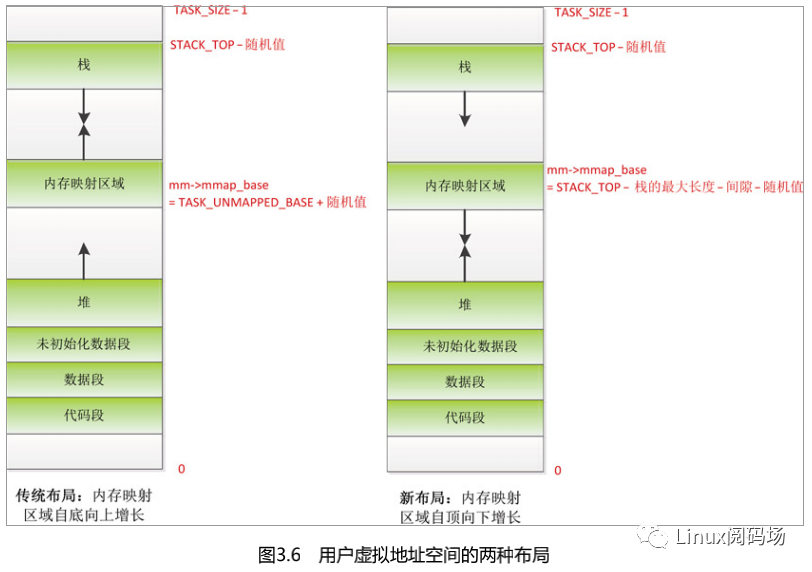
内存映射区域的起始地址是内存描述符的成员 mmap_base。如图 3.6 所示,用户虚拟
地址空间有两种布局,区别是内存映射区域的起始位置和增长方向不同。
(1)传统布局:内存映射区域自底向上增长,起始地址是 TASK_UNMAPPED_BASE,每种处理器架构都要定义这个宏,ARM64 架构定义为 TASK_SIZE/4。默认启用内存映射区域随机化,需要把起始地址加上一个随机值。传统布局的缺点是堆的最大长度受到限制,在 32 位系统中影响比较大,但是在 64 位系统中这不是问题。
(2)新布局:内存映射区域自顶向下增长,起始地址是(STACK_TOP − 栈的最大长度− 间隙)。默认启用内存映射区域随机化,需要把起始地址减去一个随机值。当进程调用 execve 以装载 ELF 文件的时候,函数 load_elf_binary 将会创建进程的用户虚拟地址空间。函数 load_elf_binary 创建用户虚拟地址空间的过程如图 3.7 所示。
如果没有给进程描述符的成员 personality 设置标志位ADDR_NO_RANDOMIZE(该标志位表示禁止虚拟地址空间随机化),并且全局变量 randomize_va_space 是非零值,那么给进程设置标志 PF_RANDOMIZE,允许虚拟地址空间随机化。
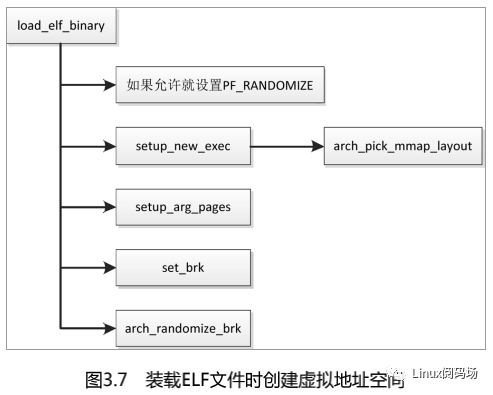
各种处理器架构自定义的函数 arch_pick_mmap_layout 负责选择内存映射区域的布局。ARM64 架构定义的函数 arch_pick_mmap_layout 如下:
arch/arm64/mm/mmap.c1 void arch_pick_mmap_layout(struct mm_struct *mm)2 {3 unsigned long random_factor = 0UL;45 if (current->flags & PF_RANDOMIZE)6 random_factor = arch_mmap_rnd();78 if (mmap_is_legacy()) {9 mm->mmap_base = TASK_UNMAPPED_BASE + random_factor;10 mm->get_unmapped_area = arch_get_unmapped_area;11 } else {12 mm->mmap_base = mmap_base(random_factor);13 mm->get_unmapped_area = arch_get_unmapped_area_topdown;14 }15 }1617 static int mmap_is_legacy(void)18 {19 if (current->personality & ADDR_COMPAT_LAYOUT)20 return 1;2122 if (rlimit(RLIMIT_STACK) == RLIM_INFINITY)23 return 1;2425 return sysctl_legacy_va_layout;26 }
第 8~10 行代码,如果给进程描述符的成员 personality 设置标志位 ADDR_COMPAT_LAYOUT 表示使用传统的虚拟地址空间布局,或者用户栈可以无限增长,或者通过文件“/proc/sys/vm/legacy_va_layout”指定,那么使用传统的自底向上增长的布局,内存映射区域的起始地址是 TASK_UNMAPPED_BASE 加上随机值,分配未映射区域的函数是arch_get_unmapped_area。
第 11~13 行代码,如果使用自顶向下增长的布局,那么分配未映射区域的函数是 arch_get_unmapped_area_topdown,内存映射区域的起始地址的计算方法如下:
arch/arm64/include/asm/elf.h#ifdef CONFIG_COMPAT#define STACK_RND_MASK (test_thread_flag(TIF_32BIT) ? \0x7ff >> (PAGE_SHIFT - 12) : \0x3ffff >> (PAGE_SHIFT - 12))#else#define STACK_RND_MASK (0x3ffff >> (PAGE_SHIFT - 12))#endifarch/arm64/mm/mmap.c#define MIN_GAP (SZ_128M + ((STACK_RND_MASK << PAGE_SHIFT) + 1))#define MAX_GAP (STACK_TOP/6*5)static unsigned long mmap_base(unsigned long rnd){unsigned long gap = rlimit(RLIMIT_STACK);if (gap < MIN_GAP)gap = MIN_GAP;else if (gap > MAX_GAP)gap = MAX_GAP;return PAGE_ALIGN(STACK_TOP - gap - rnd);}
先计算内存映射区域的起始地址和栈顶的间隙:初始值取用户栈的最大长度,限定不能小于“128MB + 栈的最大随机偏移值 + 1”,确保用户栈最大可以达到 128MB;限定不能超过 STACK_TOP 的 5/6。内存映射区域的起始地址等于“STACK_TOP−间隙−随机值”,然后向下对齐到页长度。
回到函数load_elf_binary:函数 setup_arg_pages 把栈顶设置为 STACK_TOP 减去随机120 3.2 虚拟地址空间布局值,然后把环境变量和参数从临时栈移到最终的用户栈;函数 set_brk 设置堆的起始地址,如果启用堆随机化,把堆的起始地址加上随机值。
fs/binfmt_elf.cstatic int load_elf_binary(struct linux_binprm *bprm){…retval = setup_arg_pages(bprm, randomize_stack_top(STACK_TOP),executable_stack);…retval = set_brk(elf_bss, elf_brk, bss_prot);…if ((current->flags & PF_RANDOMIZE) && (randomize_va_space > 1)) {current->mm->brk = current->mm->start_brk =arch_randomize_brk(current->mm);}…}
3.2.3 内核地址空间布局
ARM64 处理器架构的内核地址空间布局如图 3.8 所示。
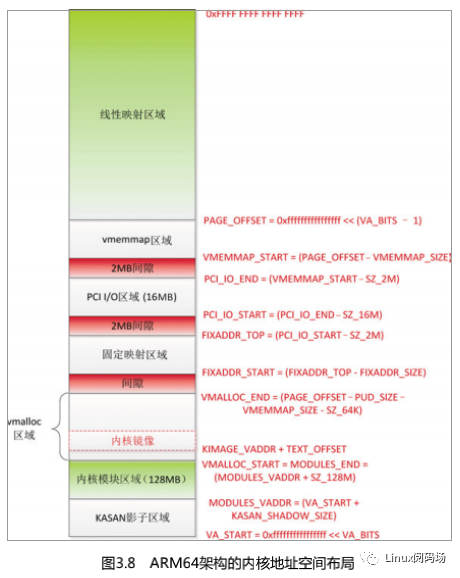
(1)线性映射区域的范围是[PAGE_OFFSET,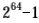 ],起始位置是 PAGE_OFFSET =(0xFFFF FFFF FFFF FFFF << (VA_BITS-1)),长度是内核虚拟地址空间的一半。称为线性映射区域的原因是虚拟地址和物理地址是线性关系:
],起始位置是 PAGE_OFFSET =(0xFFFF FFFF FFFF FFFF << (VA_BITS-1)),长度是内核虚拟地址空间的一半。称为线性映射区域的原因是虚拟地址和物理地址是线性关系:
虚拟地址 =((物理地址 − PHYS_OFFSET)+ PAGE_OFFSET),其中 PHYS_OFFSET是内存的起始物理地址。
(2)vmemmap 区域的范围是 [VMEMMAP_START, PAGE_OFFSET),长度是
VMEMMAP_SIZE =(线性映射区域的长度 / 页长度 * page 结构体的长度上限)。
内核使用 page 结构体描述一个物理页,内存的所有物理页对应一个 page 结构体数组。如果内存的物理地址空间不连续,存在很多空洞,称为稀疏内存。vmemmap 区域是稀疏内存的 page 结构体数组的虚拟地址空间。
(3)PCI I/O 区域的范围是[PCI_IO_START, PCI_IO_END),长度是 16MB,结束地址是PCI_IO_END = (VMEMMAP_START − 2MB)。
外围组件互联(Peripheral Component Interconnect,PCI)是一种总线标准,PCI I/O 区域是 PCI 设备的 I/O 地址空间。
(4)固定映射区域的范围是[FIXADDR_START, FIXADDR_TOP),长度是FIXADDR_SIZE,结束地址是 FIXADDR_TOP = (PCI_IO_START − 2MB)。
固定地址是编译时的特殊虚拟地址,编译的时候是一个常量,在内核初始化的时候映射到物理地址。
(5)vmalloc 区域的范围是[VMALLOC_START, VMALLOC_END),起始地址是VMALLOC_START,等于内核模块区域的结束地址,结束地址是 VMALLOC_END = (PAGE_OFFSET −PUD_SIZE − VMEMMAP_SIZE − 64KB),其中 PUD_SIZE 是页上级目录表项映射的地址空间的长度。
vmalloc 区域是函数 vmalloc 使用的虚拟地址空间,内核使用 vmalloc 分配虚拟地址连续但物理地址不连续的内存。内核镜像在 vmalloc 区域,起始虚拟地址是(KIMAGE_VADDR + TEXT_OFFSET) ,其中 KIMAGE_VADDR 是内核镜像的虚拟地址的基准值,等于内核模块区域的结束地址MODULES_END;TEXT_OFFSET 是内存中的内核镜像相对内存起始位置的偏移。
(6)内核模块区域的范围是[MODULES_VADDR, MODULES_END),长度是 128MB,起始地址是 MODULES_VADDR =(内核虚拟地址空间的起始地址 + KASAN 影子区域的长度)。
内核模块区域是内核模块使用的虚拟地址空间。
(7)KASAN 影子区域的起始地址是内核虚拟地址空间的起始地址,长度是内核虚拟地址空间长度的 1/8。
内核地址消毒剂(Kernel Address SANitizer,KASAN)是一个动态的内存错误检查工具。它为发现释放后使用和越界访问这两类缺陷提供了快速和综合的解决方案。
3.3 物理地址空间
物理地址是处理器在系统总线上看到的地址。使用精简指令集(Reduced Instruction SetComputer,RISC)的处理器通常只实现一个物理地址空间,外围设备和物理内存使用统一的物理地址空间。有些处理器架构把分配给外围设备的物理地址区域称为设备内存。
处理器通过外围设备控制器的寄存器访问外围设备,寄存器分为控制寄存器、状态寄存器和数据寄存器三大类,外围设备的寄存器通常被连续地编址。处理器对外围设备寄存器的编址方式有两种。
(1)I/O 映射方式(I/O-mapped):英特尔的 x86 处理器为外围设备专门实现了一个单独的地址空间,称为“I/O 地址空间”或“I/O 端口空间”,处理器通过专门的 I/O 指令(如x86 的 in 和 out 指令)来访问这一空间中的地址单元。
(2)内存映射方式(memory-mapped):使用精简指令集的处理器通常只实现一个物理地址空间,外围设备和物理内存使用统一的物理地址空间,处理器可以像访问一个内存单元那样访问外围设备,不需要提供专门的 I/O 指令。
程序只能通过虚拟地址访问外设寄存器,内核提供了以下函数来把外设寄存器的物理地址映射到虚拟地址空间。
(1)函数 ioremap()把外设寄存器的物理地址映射到内核虚拟地址空间。
void * ioremap(unsigned long phys_addr, unsigned long size, unsigned long flags);(2)函数 io_remap_pfn_range()把外设寄存器的物理地址映射到进程的用户虚拟地址空间。
int io_remap_pfn_range(struct vm_area_struct *vma, unsigned long addr,unsigned long pfn,unsigned long size, pgprot_t prot);
除了 SPARC 处理器以外,在其他处理器架构中函数 io_remap_pfn_range()和函数 remap_pfn_range()等价。函数 remap_pfn_range()用于把内存的物理页映射到进程的用户虚拟地址空间。
内核提供了函数 iounmap(),它用来删除函数 ioremap()创建的映射。
void iounmap(void *addr);ARM64 架构的实现
ARM64 架构定义了两种内存类型。
(1)正常内存(Normal Memory):包括物理内存和只读存储器(ROM)。
(2)设备内存(Device Memory):指分配给外围设备寄存器的物理地址区域。
对于正常内存,可以设置共享属性和缓存属性。共享属性用来定义一个位置是否可以被多个核共享,分为不可共享、内部共享和外部共享。不可共享是指只被处理器的一个核使用,内部共享是指一个处理器的所有核共享或者多个处理器共享,外部共享是指处理器和其他观察者(比如图形处理单元或 DMA 控制器)共享。缓存属性用来定义访问时是否通过处理器的缓存。
设备内存的共享属性总是外部共享,缓存属性总是不可缓存(即必须绕过处理器的缓存)。
ARM64 架构根据 3 种属性把设备内存分为 4 种类型。
(1)Device-nGnRnE,这种类型限制最严格。
(2)Device-nGnRE。
(3)Device-nGRE。
(4)Device-GRE,这种类型限制最少。
3 种属性分别如下。
(1)聚集属性:G 表示聚集(Gathering),nG 表示不聚集(non Gathering)。聚集属性决定对内存区域的多个访问是否可以被合并为一个总线事务。如果地址被标记为“不聚集”,那么必须按照程序里面的地址和长度访问。如果地址被标记为“聚集”,处理器可以把两个“写一个字节”的访问合并成一个“写两个字节”的访问,可以把对相同内存位置的多个访问合并,例如读相同位置两次,处理器只需要读一次,为两条指令返回相同的结果。
(2)重排序属性:R 表示重排序(Re-ordering),nR 表示不重排序(non Re-ordering)。这个属性决定对相同设备的多个访问是否可以重新排序。如果地址被标记为“不重排序”,那么对同一个块的访问总是按照程序顺序执行。
(3)早期写确认属性:E 表示早期写确认(Early Write Acknowledgement),nE 表示不执行早期写确认(non Early Write Acknowledgement)。
这个属性决定是否允许处理器和从属设备之间的中间写缓冲区发送“写完成”确认。如果地址被标记为“不执行早期写确认”,那么必须由外围设备发送“写完成”确认。如果地址被标记为“早期写确认”,那么允许写缓冲区在外围设备收到数据之前发送“写完成”确认。
物理地址宽度
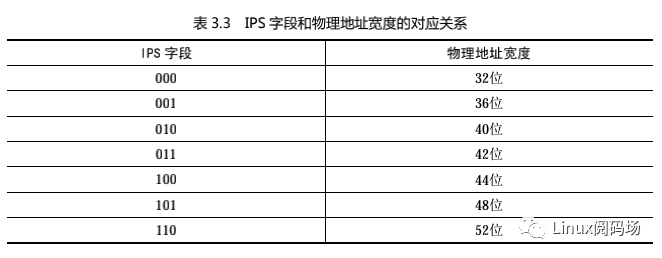
目前 ARM64 处理器支持的最大物理地址宽度是 48 位,如果实现了 ARMv8.2 标准的大物理地址(Large Physical Address,LPA)支持,并且页长度是 64KB,那么物理地址的最大宽度是 52 位。
可以使用寄存器 TCR_EL1(Translation Control Register for Exception Level 1,异常级别 1 的转换控制寄存器)的字段 IPS(Intermediate Physical Address Size,中间物理地址长度)控制物理地址的宽度,IPS 字段的长度是 3 位,IPS 字段的值和物理地址宽度的对应关系如表 3.3 所示。
感兴趣者可进群一起交流学习
精华文章:【精华】Linux阅码场原创精华文章汇总
阅码场付费会员专业交流群
会员招募:各专业群会员费为88元/季度,权益包含群内提问,线下活动8折,全年不定期群技术分享(普通用户直播免费,分享后每次点播价为19元/次),有意加入请私信客服小月(小月微信号:linuxer2016)
专业群介绍:
甄建勇-性能优化与体系结构
本群定位Perf、cache和CPU架构技术交流,覆盖云/网/车/机/芯领域资深用户,由阅码场资深讲师甄建勇主持。
李春良-Xenomai与实时优化
本群定位Xenomai与实时优化技术交流,覆盖云/网/车/机/芯领域资深用户,由阅码场资深讲师李春良和彭伟林共同主持。
周贺贺-Tee和ARM架构
本群定位Tee和ARM架构技术交流,覆盖云/网/车/机/芯领域资深用户,由阅码场资深讲师周贺贺主持。
谢欢-Linux tracers
本群定位Linux tracers技术交流,覆盖云/网/车/机/芯领域资深用户,由阅码场资深讲师谢欢主持。
✦
✦

