IEEE x ATEC
IEEE x ATEC科技思享会是由专业技术学会IEEE与前沿科技探索社区ATEC联合主办的技术沙龙。邀请行业专家学者分享前沿探索和技术实践,助力数字化发展。
在社会数字化进程中,随着网络化、智能化服务的不断深入,伴随服务衍生出的各类风险不容忽视。本期分享会的主题是《网络欺诈的风险与对抗》。五位嘉宾将从不同的技术领域和观察视角,围绕网络欺诈场景下的风险及对抗技术展开分享。
以下是庄福振研究员的演讲,《NN模型在金融风控场景中的应用》。
演讲嘉宾 | 庄福振
《NN模型在金融风控场景中的应用》
很高兴能来参加IEEE x ATEC科技思享会。我今天分享的题目是《NN模型在金融风控场景中的应用》。我今天的演讲内容主要分成三个部分:背景,研究工作,我们的一点总结。
众所周知,在过去十几年中,第三方在线支付市场发展迅速。同时,与在线交易相关的犯罪活动也大大增加,并且这种交易欺诈行为严重威胁了在线支付行业。2016年,互联网犯罪投诉中心就收到了近380万投诉,导致超过13亿的财务损失。在线交易欺诈中,最常见的是账户被盗以及卡被盗。账户被盗指的是未经授权的账户操作或欺诈者在控制了某人的付款账户后进行的交易,通常由于凭证泄露造成的。卡被盗表示某人卡的相关信息,例如卡号、账单信息等已被欺诈者获取并用于未经授权的一些收费。
下面我分享一下我们和蚂蚁集团联合做的一些研究工作。主要有三个工作,一个是基于神经层级分解机的用户事件序列分析(SIGIR 2020),第二个是基于双重重要性感知分解机的欺诈检测 (AAAI 2021),第三个是我们在可解释方面提出的利用层级可解释网络建模用户行为序列的跨领域欺诈检测 (WWW 2020)。
一、基于神经层级分解机的用户事件序列分析
首先是基于神经层级分解机的用户事件序列分析。在支付业务中,每个人都从注册系统、登录系统,再到把自己选择的商品放入购物车,最后做交易或者付款。根据用户的账户动态,我们可以判定下次付款到底是不是一个欺诈行为。用户的账户动态有丰富的数据序列信息可供利用。单纯只关注特征组合的工作或者单纯关注序列信息的工作,都只能从单独的角度去建模用户事件序列行为,每个事件仅通过简单的嵌入、拼接或者全连接,而难以获得更好的事件表示。我们希望设计一个层次化的模型同时结合这两方面进行建模,从而对欺诈检测进行分析。

右图有两个案例,一个是在某网站上的电影点评记录(如图1),同样也是一个用户行为序列,这里面最大的一个贡献是怎么去做这个事件的表示。我们刚才看到,每个事件实际上都包含了很多的特征。

如图2所示,一个事件的特征包含X1到Xn这么多个特征。我们在用户的事件序列里,包括e1到eT的T个事件,每个事件在场景里面有56个特征,包括50个类别型特征和6个数字型特征。事件内部的特征之间的组合实际上更具判别性地来判定、预测欺诈检验。例如在1分钟之内进行的跨国交易,我们就很容易判断这是一笔盗卡行为。我们希望用FM模型去建模这种特征组合关系。FM是一种在嵌入空间中自动进行二阶特征组合的模型。看一下(图2)事件的表示:vi跟vj是两个特征向量化的空间表示,它是两两特征之间的一个组合,Xi跟Xj实际上是一个权重的表示。最后我们会得到一个事件的表示,从特征交互得到一个事件表示。

当这个事件表示完后,我们希望得到一个比较好的序列表示,即我们对这个序列进行提取一个比较好的特征表示。每个用户序列实际上包含多个事件,两个事件组合发生,对欺诈行为检测更具有判别性。同样的,我们也希望去考虑事件之间的序列的影响。比如说我们先做A事件再做B事件,可能会导致欺诈的可能性变大。我们希望我们的模型能够去建模这种序列的影响。从刚才的角度出发,事件组合的建模用S来表示,同样也是因子分解机去做的。不同事件两两组合,qi和qj也是它的一个权重。对于序列影响,我们从两方面去考虑,一是从事件自身的重要性去考虑,它有一个自注意力机制来表示就是Sself;还有一个是用RNN网络来去建模事件的历史序列行为信息,也就是双向的LSTM去建模。最后,我们可得出这个序列是由三部分组成:事件的组合;事件的自注意力机制;事件本身具有的一个特征。把三者组合在一起得到整体的序列表示。
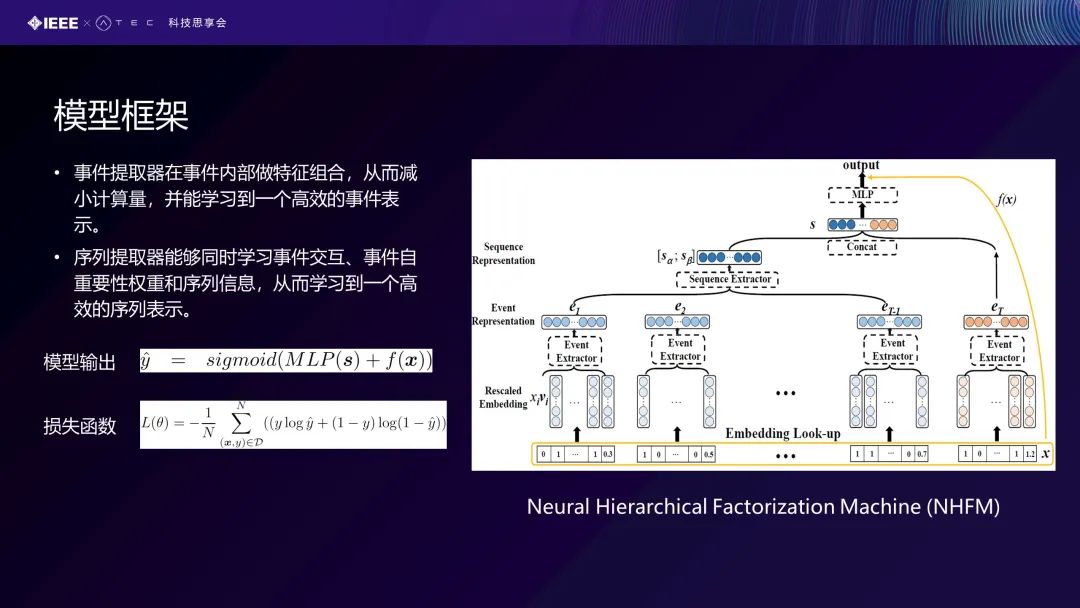
右边这张图是我们提出的一个框架,也叫做神经层级分解机。从底部开始,是事件的特征。我们对这个事件特征进行编码后,就可以得到这个事件的表示,从而学习这个序列的表示。提取后,可以看到模型做一个多层感知机的输出。我们同样可以在这个Feature上面去做一个线性的分类。最终我们把这两部分当成一个Sigmoid的一个参数,得到0到1之间的输出,最终的一个优化函数其实是一个交叉熵的损失函数,N是对所有有标记的数据进行学习。这是我们的模型的一个框架。

在这个实验中,我们利用工业界里面的一个真实的数据集。例如在一个电商平台上,我们从该平台上面拿到了三个地域的数据集。这个数据集正例是欺诈行为,负例是正常的交易行为,可以看到正常交易行为和异常的欺诈行为,相差非常大、类别非常不平衡。我们的公开数据集上、电影上的数据集也做了一个实验。在基准的算法比较上,我们采用了比较先进的一些算法,比如W&D(Wide & deep)宽度和深度,还有NFM、DeepFM、xDeepFM,以及M3利用混合模型同时学习序列的长短期依赖的模型。
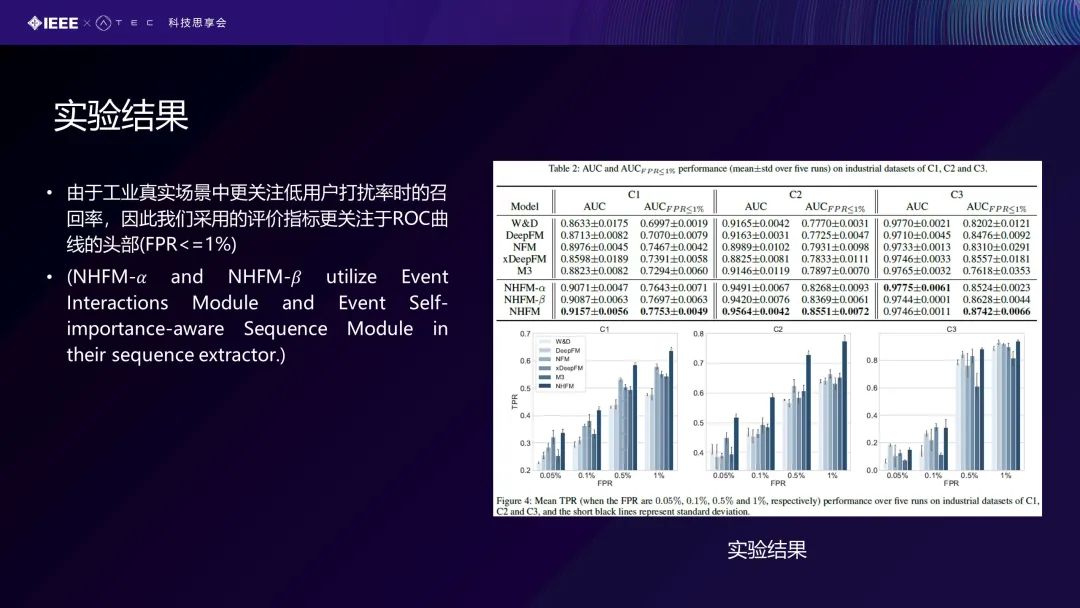
我们的评价指标是采用真实工业场景里面比较关注的低用户打扰率时的召回率,即我们在给出结果时,希望对前面头部的百分之多少的用户打电话告诉他们这可能是一个欺诈行为。例如打1000个电话,这1000个应该都是有欺诈行为,即这个比例应该是越高越好的,因此我们采用的评价指标更关注于ROC曲线的头部(FPR<=1%) 。这里面有一个消融的𝛼 跟 𝛽,比如我们只考虑事件的交互模块,NHFM是我们整体的一个结果,优越于所有的baseline算法,包括消融后的版本也是比baseline要好很多。我们的模型还能够提取到的高风险的特征和高风险的事件,这对于欺诈检测任务具有很好的解释性。比如短时间内从中国IP变到美国IP,也可能是一个欺诈交易。消费金额比平常消费的金额大10倍、100倍,也可能是一个欺诈行为。包括你使用的电脑操作系统的一些高风险的特征和一些低风险的特征,也可以看到一些时间段、交易金额等,比较明显地指向交易行为是不是欺诈行为。
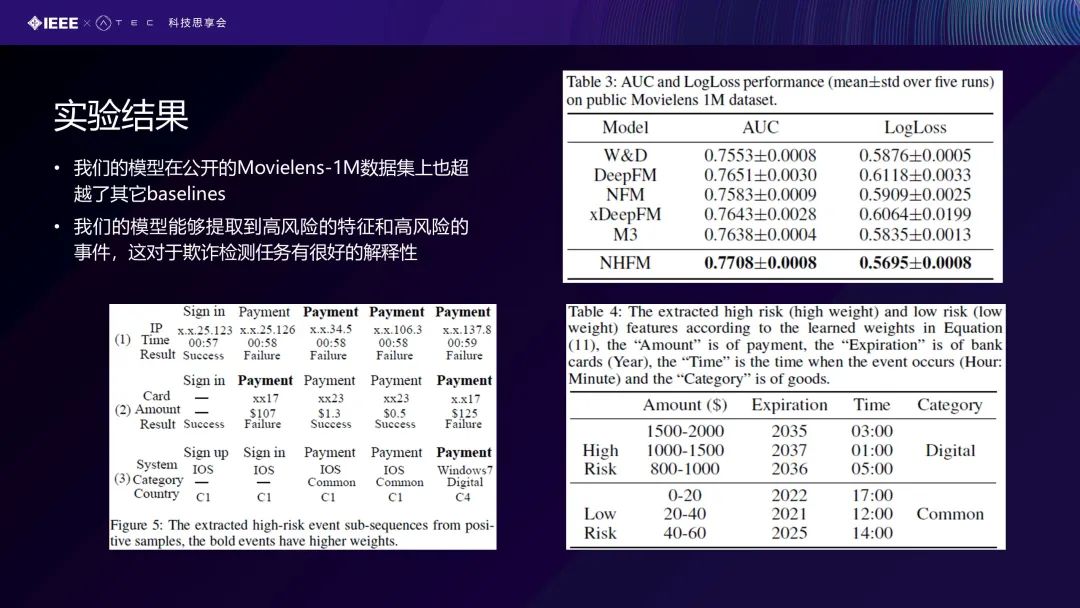
从左下方这张图,可以看到这种IP 的变化、还有包括其他的特征值、字段的值的变化,会导致一些欺诈行为的发生。
二、基于双重重要性感知分解机的欺诈检测

基于双重重要性感知的一个分解机用于欺诈检测。在刚才第一个工作里面,可以看到IP在不断变化。我们需要把一个系列化的事件的某个值、某个字段的演变考虑进去。即同一字段值的演变和不同字段值的交互实际上是非常重要的,而现有的工作没有同时关注到这两点。因此,我们想设计一个DIFM模型同时结合这两个方面。
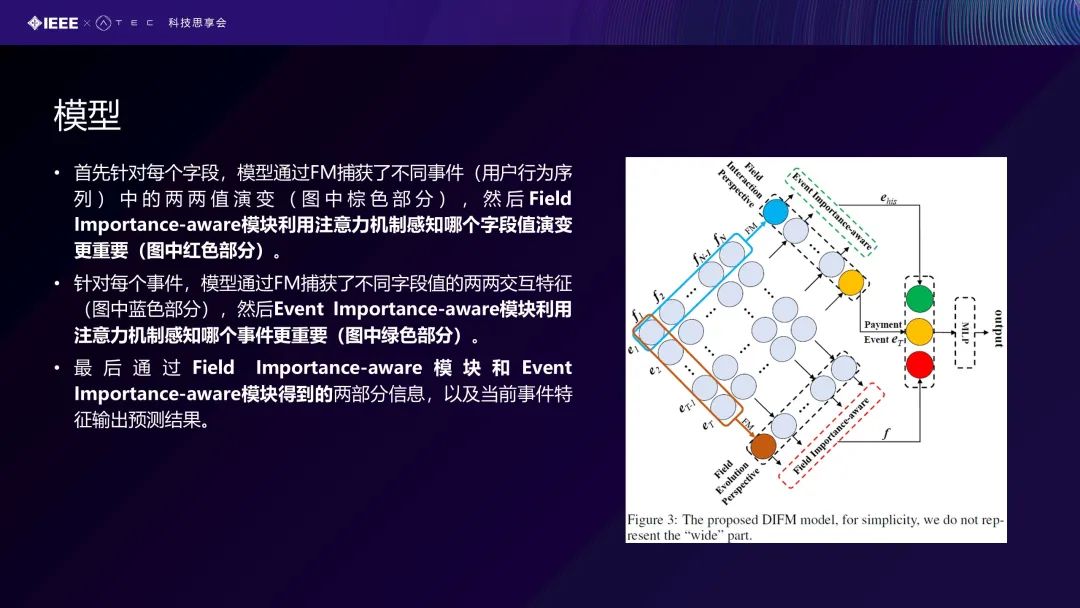
我们同样也是基于这个FM模型做了一个框架。首先,对于每个阶段,我们也是通过FM模型去捕获不同事件的两两之间的演变。可以看到Figure3这张图,从棕色这个方向我们去考虑f1的特征,是指它随事件变化,我们去把它给建模出来,这就是我们新加的一个贡献。到FM建模以后,我们又提出了一个Field Importance-aware这样的一个感知模块。用注意力机制去感知哪个字段的演变对我们的预测更加重要,我们又提出了一个叫重要性感知的模块。另外一个方向的话,我们在前面针对每个事件,模型通过FM捕获了不同字段值的两两交互特征(图中蓝色部分),然后通过Event Importance-aware模块利用注意力机制感知哪个事件更重要(图中绿色部分)。最后我们再通过Field Importance-aware模块和Event Importance-aware模块得到的两部分信息以及当前事件特征输出预测结果。可以看到这个模型是比较简单而且实用的,我们在这个业务应用场景里面,可以高效率而且效果比较好地在线上去部署,这个就是我们提出的第二个工作。

第二个工作的一些实验结果,也是利用了第一个工作里面的三个地域的数据集。我们在这个工作里面又增加了一些精准算法,包括AFM,还有利用LSTM做欺诈检测,还有包括用Latent Cross将上下文信息集成到RNN中,这个数据跟上一个工作的实验数据是一样的。
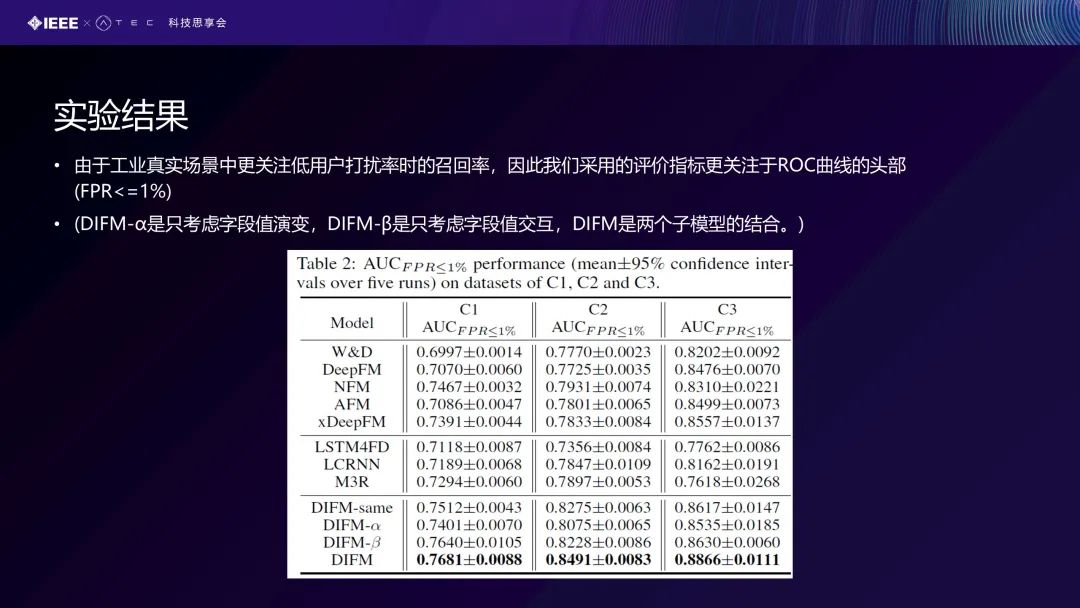
从这个结果可以看到,同样我们是采用低用户打扰率时的召回率去评价我们的实验,可以看到最底下DIFM(我们的一个实验结果),实验结果大大优越所有的baseline,包括消融实验,DIFM-α只考虑字段值演变,DIFM-β只考虑字段值交互,DIFM是两个子模型的结合,DIFM也是优越于前面所有的比较算法,这就是我们提的一个又简单又实用的算法。
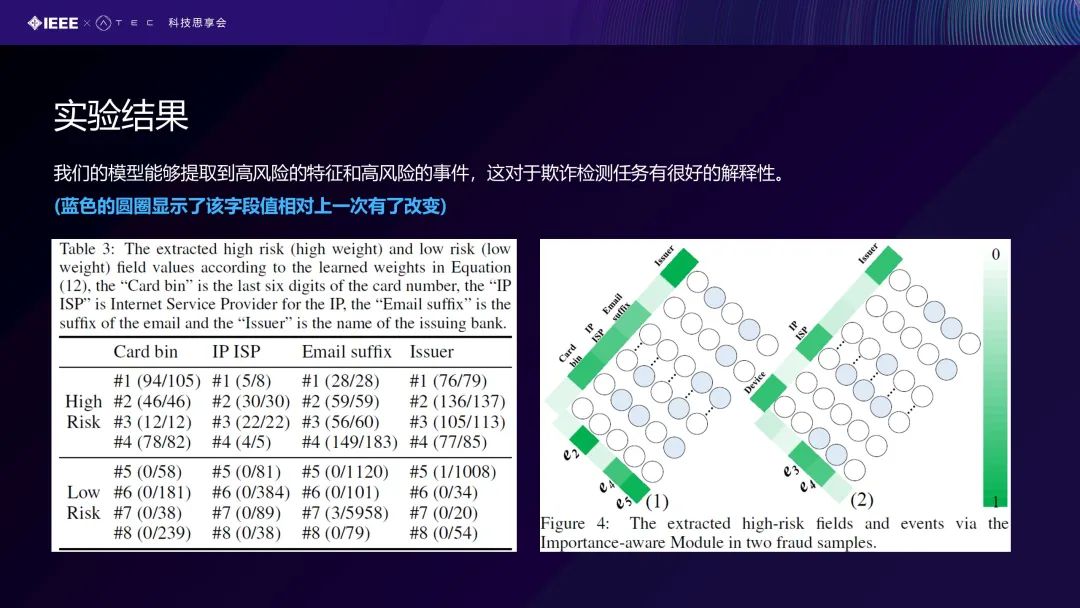
在可解释性方面的话,我们的模型还能够提取到高风险的特征和高风险的事件。从上面右边这张图可以看到蓝色圆圈,每一次变化都会变成一个蓝色圆圈,相对有一些改变。可以看到卡后面尾数落在每个区间,每一次的变化就会产生一个欺诈的行为,或者卡值的一个变化。还有包括IP的变化,我们都可以去把它catch出来。这就是我们提出来的、去显示地建模这种一个字段值随着事件、序列在变化的情况用于欺诈检测,同样也为可解释提供了一个比较好的借鉴。众所周知,在金融欺诈检测里面可解释性是非常必要的,即你去告诉用户此交易行为是一个欺诈行为时,你必须告诉他有哪些特征可能违反了哪些规则,或者你的事件可能导致一些欺诈行为。可解释性就变成了一个非常重要的工作。在接下来的这些工作里,希望我们也从可解释性的角度去对整个过程,从特征层面、从事件层面、 也包括我们跨领域的层面去做可解释性的层次模型。因此我们也提出利用层级可解释性网络来建模用户行为序列的一个跨领域的欺诈检测。
三、利用层级可解释网络建模用户行为序列的跨领域欺诈检测

Motivation的话,其实也比较简单、比较直接。第一,前面我们知道了用户行为序列是非常重要的。第二,我们希望考虑这种可解释性对我们的业务的帮助。第三,这个电商平台在不同的地域新开展业务时,可能因数据量少而不能很好建模的情况下,我们希望从其他数据比较成熟或者模型比较成熟的平台中,把它迁移或借鉴过来,去建模一个跨领域的欺诈检测模型。
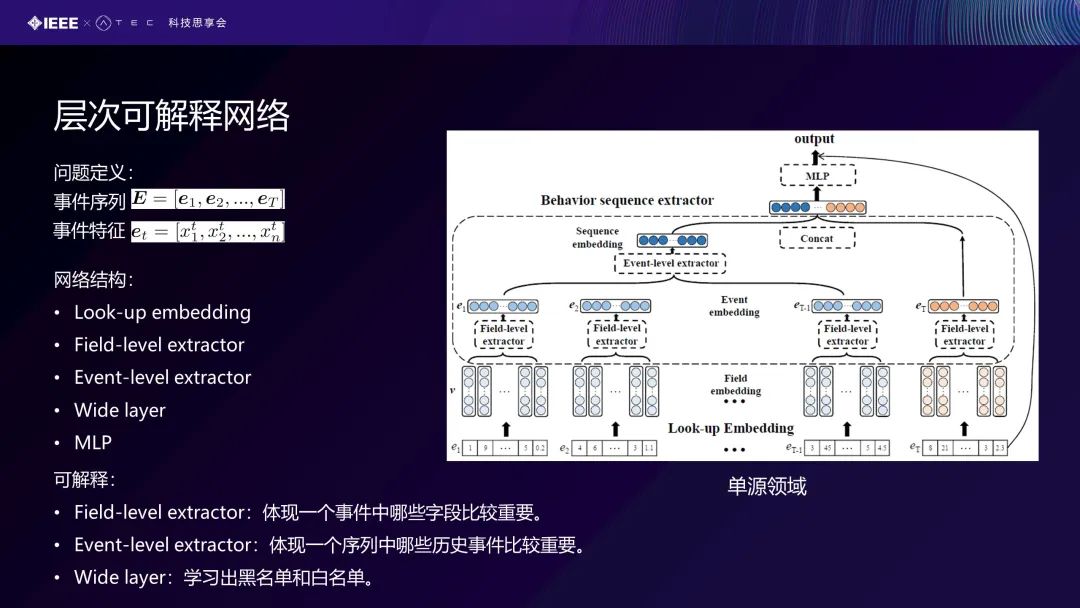
我们提出了这种层次可解释网络。首先我们提出了一个特征层面、事件层面的可解释性网络来对这个欺诈检测。右边的图片是我们提出的一个框架,同样的,前面是我们对这个特征进行编码。Field-level Extractor是对事件的表示。事件表示完之后,是对序列的表示。还有一个我们叫做Wide layer。Wide layer是单纯用特征去学的线性分类器,我们这边串联后用多层感知机来去做。这里面的可解释性就体现在从单领域的模型里面有两个可解释,一个是哪些字段 、哪些特征是比较重要的,以及序列当中哪些历史事件比较重要的。
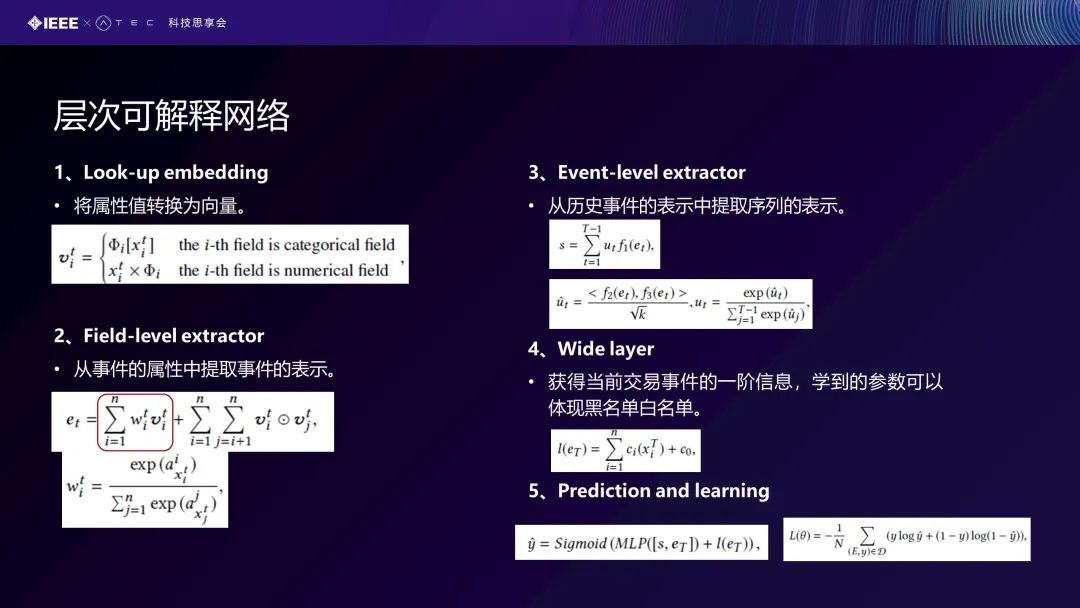
对于每一步,第一个Look-up embedding,我们实际上是对这个特征值进行一个向量的转化。我们把这个转化分为类别型的、数值型的转化规则,采用这个式子去做转化。Field-level Extractor是对事件的一个表示,前面的工作我们只考虑了即两两特征之间的交互,显示哪个特征比较重要,我们加了一个wit,这个wi相当于是说针对这个特征,在T时刻它的特征的重要性的归一化。对于事件,它同样有一个事件重要性的表达式,也就是UT,UT就是下面的表达式。下面还有Wide layer对白名单进行学习,即我们用线性分析去学习,最后预测跟学习问题,我们同样也是用MLP还有包括sigmoid函数,来把它映射到0跟1之间,用交叉熵来去学习整个学习问题,这个是L(θ)。
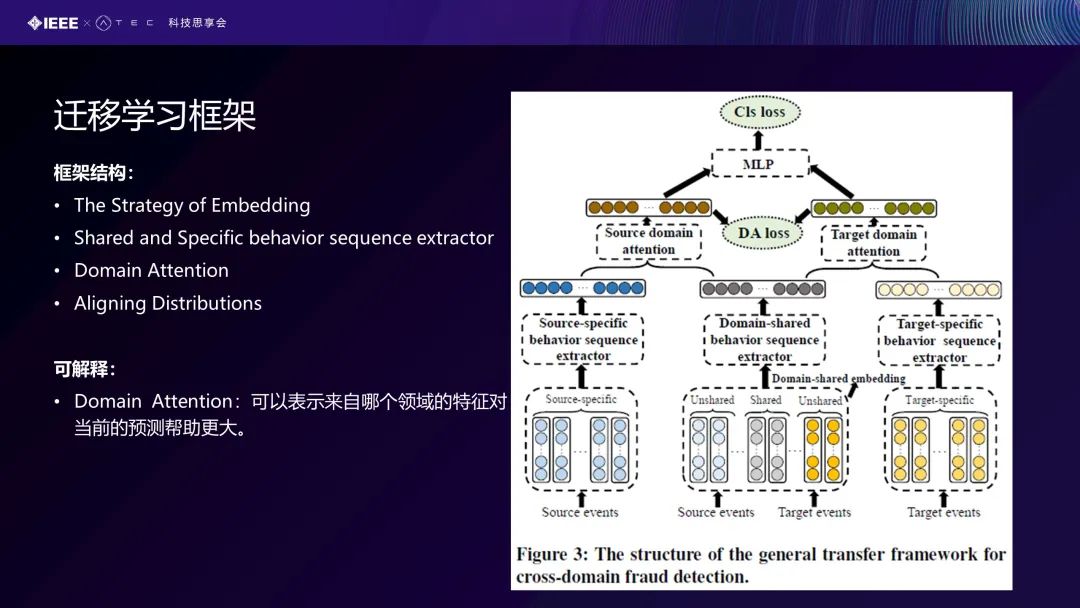
我们又提出一个迁移学习框架,刚才说到可能不同地域或者不同场景,数据有些是少的、有些是多的。我们希望由(数据)少的来帮助(数据)多的。我们把少的叫做Target Events,数据量多的叫做源领域或者Source Events。在这里,我们希望去学到源领域和目标领域特有的一些知识,还有它们两个共享的一些东西。我们希望这个Source可以共享一些知识去帮助Target学习及一些预测。从几方面来考虑,在我们场景里面,一个是Embedding策略、为什么要提出Embedding策略、共享和你特有的行为序列的抽取,还有包括你的领域的注意力。也就是在一定程度上解释说我这个领域帮助了我的Target问题、帮助了多少、我们怎么去对齐不同领域之间的一个分布,也就是Aligning Distributions。可解释性就体现在Domain Attention的角度。

我们为什么要提出这种Embedding策略?我们都知道由于不同地域的相同字段对应的取值可能不同,例如中国跟越南的消费字段、消费额不同,中国可能是0到100块钱,而在越南可能就不是0到100块钱。所以字段的取值可能是不一样的,不同地域的用户行为习惯可能不同,相同的提取器可能无法同时对两个地域有效,所以将行为序列提取器也分为Domain-Specific和Domain-Shared。即我们把一些特定的或者是领域不变的一些特征迁移过来,保持自身领域特有的一些东西。我们在这个领域的Attention上,把它也分成一个领域特有和领域共享的表示,即Shared和Specific两个因子,计算公式如图所示。在不同领域之间的分布的对齐方面,我们知道传统的对齐方法在我们的应用场景里面是不适合的,因为在我们的场景里类别是极其不平衡的,即我们得到的这个正负类比例相差非常大。例如我们甚至可以是一比一万,一万条里面可能只有一条是异常行为。我们去提出这种Class-aware,即类别感知的Euclidean Distance。从这个角度去讲,我们计算这个领域距离时,是从类别上面去做的,即考虑不同类别的一个过程。
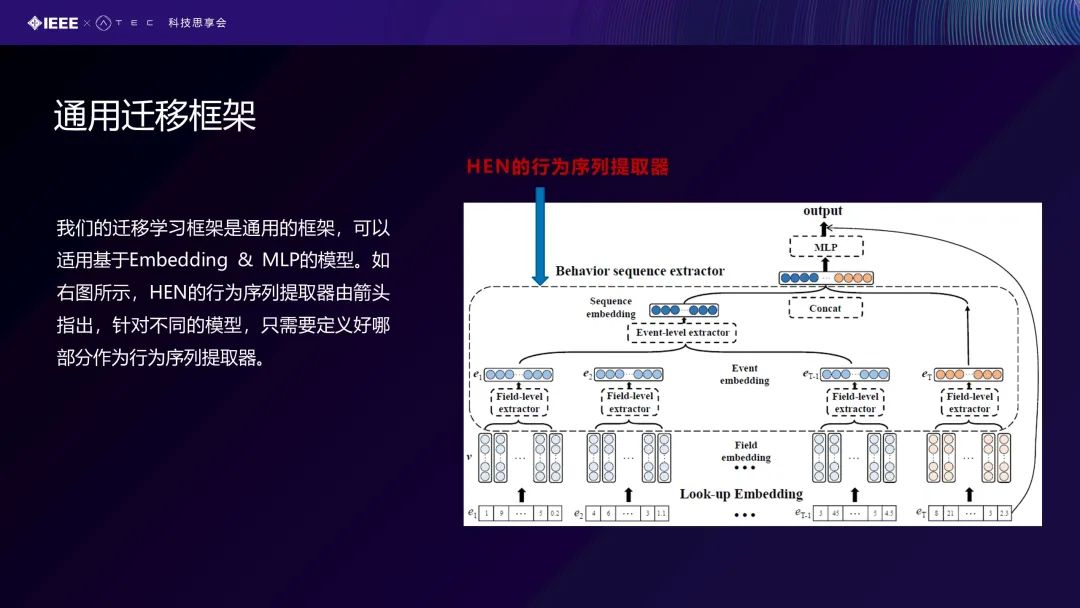
进一步,我们的迁移学习框架泛化成一个通用的迁移学习框架。从上图的右图可以看到:虚线的表示我们提出的是一个层次可解释网络,这是作为一个序列的提取器,即我们可以把这个虚线里面的序列提取器换成其它的模型去作为事件的提取器。例如我们这个迁移模型,我们可以把其他的baseline作为我们的一个特殊情况纳入到我们的迁移学习框架里面。所以只需要定义好哪部分作为行为序列提取器,我们就可以去做这样一个欺诈监测模型。

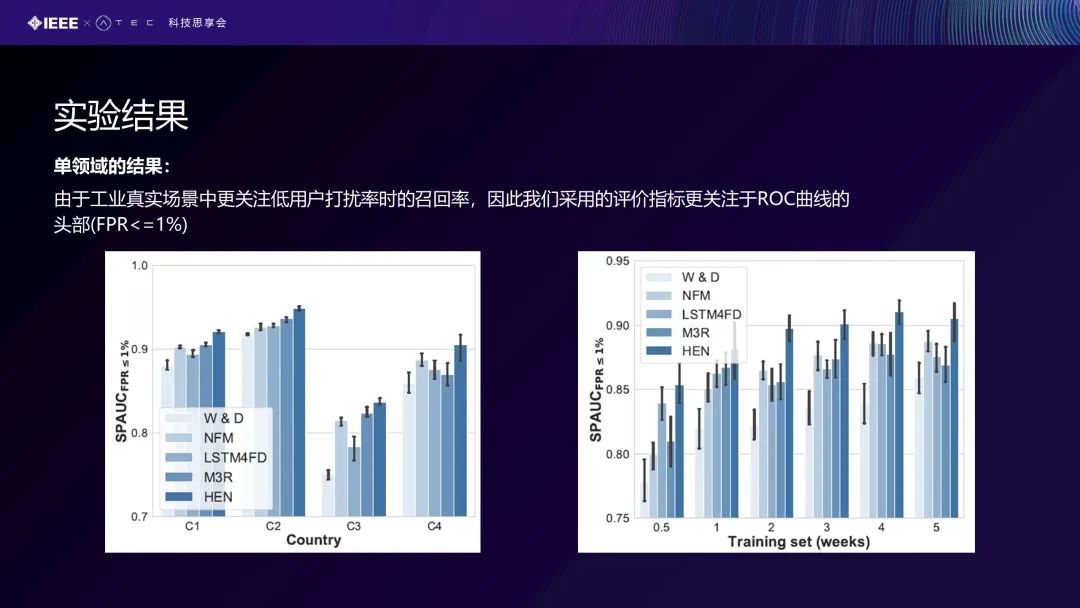
可以看到这两张图,是在C1、C2、C3、C4这4个地域上的实验结果,都比baseline要好很多,最后的竖线就是我们的模型结果。
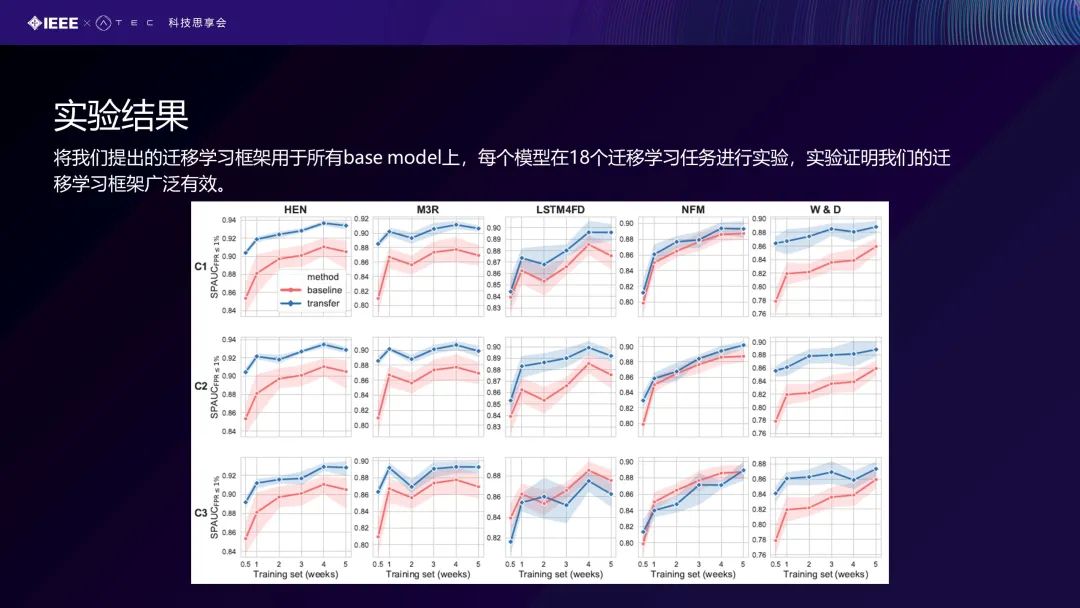
我们同样把我们的迁移学习框架用于所有base model上,即我们把刚才所有baseline的model序列行为提取器放到迁移学习框架里,把中间的虚线部分给替换掉。蓝线是我们用了迁移学习框架后得到的一个结果。结果证明,在迁移学习后可以得到比较好的实验结果。这个横轴是表示我们采用数据的从少到多,如从一个星期作训练数据到两个星期三个星期……所以随着训练数据的增加,结果一般也是变好的。这个蓝线,指我们先前的效果比原来要好很多。大概情况就是这样。
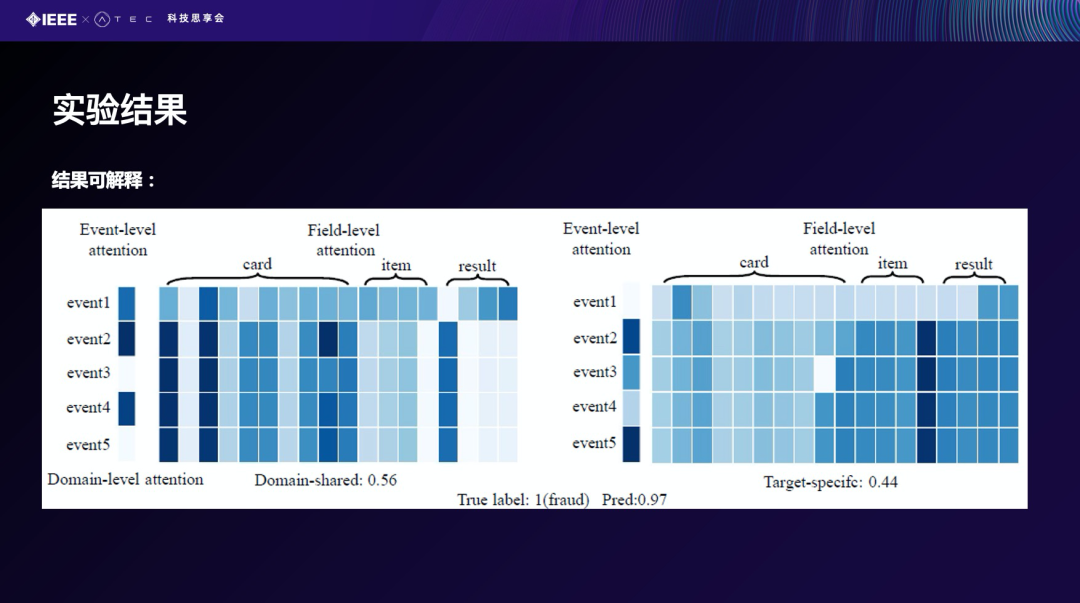
从结果的可解性来看,可以看到从特征层面,每一行的颜色越深、它的特征越重要。可以看到有明显的catch到我们重要性的一个特征。从竖的Y轴上面看,深度越深事件越重要,我们可以catch到不同事件的重要性。下面可以看出Domain-Shared等于0.56,意思是说我们建立这个Target 模型,Shared部分贡献的知识是56%,Target自己本身是44%。可以看到,我们从三个层面,从特征的粒度到事件的力度然后再到属性的力度,去做这样一个可解释。


最后,我们总结一下,我们在合作过程当中,提出神经层次分解机对用户事件序列进行分析,同时建模Field之间交互关系以及Field Value演化的欺诈检测模型,提出通用的迁移学习可解释框架,我们对检测欺诈结果的可解释。最后我们也进行了线上部署应用落地。现在已经应用得比较好,特别是在一些场景里面把我们的算法结合到欺诈检测的模块里面去。
我的分享就到这里,非常感谢。
ABOUT US
IEEE
ATEC

● 【西安交大沈超分享】用全局视角开展网络欺诈风险识别与防御
● 【武汉大学王骞分享】从数据视角看,如何安全地实现更好的AI
● 【北京大学王亦洲分享】基于对抗博弈的主动跟踪算法研究
● 【IEEE张曼分享】核身技术在反诈领域的研究

