
作者:出出啊
链接:
https://club.rt-thread.org/ask/article/64a11e0669eabd42.html

严格讲,这一篇不涉及 rt-thread 驱动,但是它是 LVGL 和 rt-thread 的接口。LVGL 在 rt-thread 上运行的基石。
前人植树,后人纳凉。首先得感谢 Meco 大佬做的工作,他给我们带了全新的 LVGL 接口。
第一步,打开 menuconfig。定位到 LVGL: powerful and easy-to-use embedded GUI library
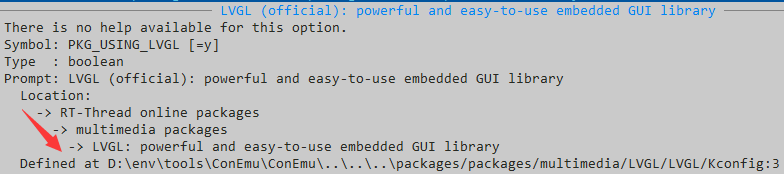
选择 “LVGL (official)” 以及 “Enable LVGL music player demo for RT-Thread” 两项,不用选 “LittlevGL2RTT (legacy)” 。
保存退出。
第二步,执行 pkgs --update 下载 LVGL 及 demo 包。
第三步,在 bsp 目录下搜索 lvgl 文件夹。随便选一个拷贝到自己项目的 Application 目录下。笔者这里从 “nuvoton\nk-980iot” 下拷贝了一份。如果你使用 RT-Studio 拷贝过来就可以了,如果是使用 keil,需要之后手动把 这个文件夹的文件添加的项目,并添加头文件路径。
第四步,找到 lv_port_indev.c 文件,先注释掉 #include "touch.h" 及 nu_touch_inputevent_cb 两个函数,input 驱动先放一放。
第五步,打开 lv_port_disp.c 文件,注释掉 lv_port_disp_init 部分与 lcd_device 相关的部分,因为 drv_lcd 里并不一定实现了 lcd 设备注册。修改 draw buffer 的申请内存,以及屏幕尺寸
draw_buf1 =(void*)rt_malloc(LCD_WIDTH *50*sizeof(lv_color_t));
lv_disp_draw_buf_init(&disp_buf, draw_buf1, RT_NULL, LCD_WIDTH *50);
...
disp_drv.hor_res = LCD_WIDTH;
disp_drv.ver_res = LCD_HEIGHT;
这个 draw buffer 不一定要按照全屏尺寸申请缓存,可以只申请十分之一行的,但是这样一整屏数据刷新会分 10 次,优点儿就是内存占用少。笔者的屏幕是 480*272 的,试过只申请 20 行的缓存,刷新显示没压力。
第六步,添加 flush_cb 回调函数。flush_cb 的原型是 void (*flush_cb)(struct _lv_disp_drv_t * disp_drv, const lv_area_t * area, lv_color_t * color_p); 。
staticvoid tft_flush(lv_disp_drv_t*disp_drv,constlv_area_t*area,lv_color_t*color_p)
{
rt_int32_t x, y;
lv_coord_t hres = disp_drv->hor_res;
lv_coord_t vres = disp_drv->ver_res;
/*Return if the area is out the screen*/
if(area->x2 <0|| area->y2 <0|| area->x1 > hres -1|| area->y1 > vres -1){
lv_disp_flush_ready(disp_drv);
return;
}
for(y = area->y1; y <= area->y2 && y < disp_drv->ver_res; y++){
for(x = area->x1; x <= area->x2 && x < disp_drv->hor_res; x++){
((UINT16*)u8FrameBufPtr)[y * disp_drv->hor_res + x]= lv_color_to16(*color_p);
color_p++;
}
}
lv_disp_flush_ready(disp_drv);
}
同时,指定 disp_drv.flush_cb = tft_flush; 指向我自己的 flush_cb 。
第七步,显示驱动搞好了,是不是可以运行起来了呢?编译、调试运行。demo 应该可以跑起来了。
但是上面的 tft_flush 回调函数是用 for 循环拷贝显示数据的。这样效率会不会低?NUC97x 系列带 GE2D 图形加速引擎,是否可以把它用上?
第一步,修改 drv_lcd ,初始化 LCM 的时候执行 vpostVAStartTrigger 之前,添加 GE2D 初始化
ge2dInit(16,800,480,(void*)u8FrameBufPtr);// 这里的参数根据实际屏幕参数而定
ge2dClearScreen(0x0);
第二步,修改 tft_flush 函数
staticvoid tft_flush(lv_disp_drv_t*disp_drv,constlv_area_t*area,lv_color_t*color_p)
{
unsignedint cmd32 =0xcc410000;
unsignedint src_x =0;
unsignedint src_y =0;
unsignedint src_width = lv_area_get_width(area);
unsignedint src_height = lv_area_get_height(area);
unsignedint dst_x = area->x1;
unsignedint dst_y = area->y1;
sysFlushCache(I_D_CACHE);
outpw(REG_GE2D_CTL, cmd32);
switch(LV_COLOR_DEPTH){
case8:
cmd32 =0x00;
break;
case16:
cmd32 =0x10;
break;
case32:
cmd32 =0x20;
break;
}
cmd32 |=(inpw(REG_GE2D_MISCTL)&0xFFFFFFF8);
outpw(REG_GE2D_MISCTL, cmd32);
outpw(REG_GE2D_SDPITCH,((disp_drv->hor_res <<16)| src_width));
outpw(REG_GE2D_SRCSPA,0);
outpw(REG_GE2D_DSTSPA,((dst_y <<16)| dst_x));
outpw(REG_GE2D_RTGLSZ,((src_height <<16)| src_width));
outpw(REG_GE2D_XYSORG,(unsignedint)draw_buf1);// 上文提到的 draw_buf1,需要改成全局指针变量
outpw(REG_GE2D_XYDORG,(unsignedint)u8FrameBufPtr);
outpw(REG_GE2D_TRG,1);
while((inpw(REG_GE2D_INTSTS)&0x1)==0);
outpw(REG_GE2D_INTSTS,1);
lv_disp_flush_ready(disp_drv);
}
第三步,试跑一下,不错!
不对!!!有时候显示有异常,但是过一会又好了,下图左边是异常显示,右边是正常显示。

经过长时间的调试,摸排,对比,最后发现(这一句话,怎能概括这几天偶的辛苦!
当
lv_area_get_width(area)的值是奇数的时候,就是左边的样子,是偶数的时候是右边的样子。
跟官方技术支持邮件沟通,他们提示笔者 TRM 里有一段话描述。
HostBLT is executed through eight 32-bit MMIO data ports for bit block data transfer. The host must
perform 32-bit word-aligned accesses when writing data to, or reading data from the Graphics Engine.
大意就是,GE2D 在 HostBLT 工作方式下,传输的数据是需要 32-bit 对齐的。说的好像挺有道理。但是笔者的屏幕使用的 RGB565 颜色格式 16bit BPP 的,如果对齐到 32bit?
顺着 TRM 的这段描述,笔者大胆猜测了一下 HostBLT 的工作模式。
1、它是按行搬运数据的,虽然源数据 color_p 是连续内存区域,我们可以把它当作一维数组,或者二维数组都行。显存的目标区域不是连续的,是行连续的。
2、当搬运第一行数据的时候,源数据 color_p 的第一个数据(或者说 color_p 这个指针)地址是 32bit 对齐的。这一行搬运的数据总量等于 width * bpp / 8。
3、当搬运第二行的时候,情况就变了,因为列数 width 是奇数,上一行搬运的数据总量是 2 的倍数,不是 4 的倍数。当前行第一个像素点的数据所在的地址也就不是 32bit 对齐的了——上一行最后一个像素点的数据才是 32bit 对齐的。HostBLT 拷贝这一行数据的时候,行首地址被强行抹去了 2 变成上一行最后一个数据的地址。造成奇数行显示正常,偶数行行首像素是上一行最后一个像素,其它像素均向后错了一个的怪象。
笔者广求各路大佬,有测试条件的,有 NUC97x 系列或者 N9H30 系列开发板,或者自己做的带 TFT 显示屏的,可以 RGB565 模式显示的,都可以测试一下。笔者提供测试源码。
笔者设计了个实验,用于验证上述工作模式的描述。
首先构造一个 19列 28 行的数组 fill1 表示显示数据。以及一个 18列 28 行的数组 fill2 做比对项。
fill1 数组的第一列数据编辑成 0xF800 (红色),最后一列 0x07FF (或者其它非红色值)。fill2 可以和 fill1 一样,也可以不一样。
对这两个数组分别执行操作
ge2dSpriteBlt_Screen(x, y,19,28, fill1);// 1
ge2dBitblt_ScreenToScreen(x, y, x+20, y,19,28);// 2
ge2dBitblt_ScreenToScreen(x, y, x+40, y,18,28);// 3
ge2dSpriteBlt_Screen(x, y+30,18,28, fill2);// 4
ge2dBitblt_ScreenToScreen(x, y+30, x+20, y+30,18,28);// 5
ge2dBitblt_ScreenToScreen(x, y+30,70, y+30,19,28);// 6
1 4 分别从数组搬运数据到显存。2 3 是将 1 搬运后显存中的数据在显存内再次搬运两次。5 6 是将 2 搬运后显存中的数据在显存内再次搬运两次。测试结果

1、对比 1 4 我们发现,同样是从外部内存搬运到显存,数据列数不同,显示效果不一样,当列数为奇数的时候(1)显示异常,出现像素错位。
2、横向观察 1 2 3 从显存搬运到显存,虽然数据列数同样是奇数,但是并没有二次像素错位。横向比较 4 5 6 可以得出同样的结论。
3、2 3 显示和 1 一样是像素错位的,表明显存中的数据已经是错的了。
4、修改上述代码中的 x 坐标值,我们还能发现一个事情,那就是,x 坐标是奇数的时候,总有一半行的第一个像素值所在的显存地址不是 4 的整数倍,但是显存内部数据搬运并没有出现像素错位!!!显存内部数据搬运不遵守 32bit 对齐限制?!
笔者对这类 gpu 没有研究,不清楚这种工作模式是在所有架构上都这样的,还是 GE2D 的设计缺陷。
如果要解决这个问题,目前只能要求 LVGL 在 16bit 颜色深度的时候,把 area 处理成偶数列的。
但是吧,lvgl 被移植应用到无数芯片上了吧,也肯定有很多用 gpu 加速的,他们都是怎么处理这个问题的?如果在其它芯片上 gpu 都是这样工作的,LVGL 难道就不考虑这个问题?
LVGL 局部刷新时,强制偶数列刷新修改。lv_refr.c 文件的 lv_refr_area 函数中有两处处理 sub_area 的地方,对 sub_area 做如下补丁。
#if LV_COLOR_DEPTH == 16
~~ if ((sub_area.x2 - sub_area.x1) % 2 == 0) {~~
~~ if (sub_area.x1 == 0) {~~
~~ sub_area.x2++;~~
~~ } else {~~
~~ sub_area.x1 &= ~0x1;~~
~~ }~~
~~ }~~
#endif
PS: 以上修改位置是错了,可能会引起内存溢出。严谨的修改如下:
修改 lv_refr_areas 函数,在调用 lv_refr_area 之前
disp_refr->driver->draw_buf->last_part =0;
#if LV_COLOR_DEPTH == 16
if((disp_refr->inv_areas[i].x2 - disp_refr->inv_areas[i].x1)%2==0){
if(disp_refr->inv_areas[i].x1 ==0){
disp_refr->inv_areas[i].x2++;
}else{
disp_refr->inv_areas[i].x1--;
}
}
#endif
lv_refr_area(&disp_refr->inv_areas[i]);
GE2D 的效率:实测,启用 full_refresh 的时候 GE2D 有 30% 的 FPS 提升。不启用的时候 FPS 提升就没那么明显了,可能只有 10%。
rt-thread 的 LVGL 接口还有些欠缺的地方。LVGL 8.x 有两个 conf.h ,lv_conf.h lv_drv_conf.h lv_demo_conf.h。能用上 lvgl 提供的模板文件,从模板文件修改是最好的了。而不是把这几个文件合并成一个 lv_rt_thread_conf.h ,删掉了很多配置项。


相关阅读
NUC980支持RT-Thread应用于串口服务器的方案及优势视频 https://www.bilibili.com/video/BV1CU4y1Z7uy
在当下芯片紧缺涨价下,如何为项目选择更合适的芯片是个不太容易的事,
如果你对新唐NUC980有兴趣,
如果你没有使用过Nuvoton的产品,
想知道自己的项目所选择的MCU型号是不是最佳 ?
供货是否有保障?
现在你可以和Nuvoton原厂MCU产品经理直接对话,咨询上述问题,扫码预约哦,名额有限:

👆👆👆
立即长按识别二维码预约
内容仅供各位学习参考,文章仅代表作者个人看法,不代表本平台观点,版权归原作者所有,转载请联系作者,如有版权疑问,请联系本微信后台,我们会第一时间处理。
END

爱我就给我点在看
 点击 “阅读原文”
点击 “阅读原文”
