
来源:内容由半导体行业观察(ID:icbank)编译自semiwiki,谢谢。
正如大家所知道,英特尔将在VLSI技术会议上展示他们的Intel 4 工艺。上周三,来自英特尔的Bernhard Sell (Ben) 向媒体提前简要介绍了这一工艺,并为我们提供了早期访问该文件的机会。
“Intel 4 CMOS 技术采用先进的 FinFET 晶体管,针对高密度和高性能计算进行了优化,”
我首先要讨论的是英特尔再大会上发表的那篇论文的质量。该论文是写得很好的一篇描述工艺技术的论文范例。在文中包括判断工艺密度所需的关键间距,性能数据显示在具有实际单位的图上,并且讨论提供了有关工艺的有用信息。
我之所以这样说,是因为在 2019 年的 IEDM 上,台积电发表了一篇没有间距的 5nm 技术论文,并且所有性能图都在没有实际单位的情况下进行了归一化。在我看来,那是一份营销文件而不是技术文件。在会议新闻午宴上,我问组委会是否考虑因缺乏内容而拒绝该论文,他们说有,但最终认为 5nm 太重要了。
英特尔已经公布了未来四个节点(Intel 4、3、20A 和 18A)的路线图,其中包含日期、设备类型和性能改进目标。他们现在正在填写有关Intel 4 的更多详细信息。
相比之下,三星面临着从 3nm 开始的风险,并且已经披露了 PPA(功率、性能和面积)目标,但没有其他细节,对于 2nm,他们已经披露这将是他们的第三个新一代 Gate All Around (GAA) 技术,这将于 2025 年到期,但没有性能目标。
台积电也已经披露了目前处于风险启动中的 3nm 的 PPA,对于 2nm,风险启动日期已经披露,但没有关于性能或设备类型的信息。
Intel 4 使用目标
在深入了解 Intel 4 的细节之前,我想评论一下这个制程的目标。当我们仔细研究细节时,很明显这个过程是针对英特尔内部用于制造计算块(compute tiles)的,它不是一个通用的代工工艺。
Intel 4 将于今年晚些时候发布,Intel 3 将于明年发布;Intel 3 是英特尔代工服务的重点。具体来说,Intel 4 没有 I/O Fin,因为在仅与基板上的其他芯片通信的计算块上,这毫无用处。并且Intel 4 仅提供高性能单元并且没有高密度单元。Intel 3 将提供 I/O Fin和高密度单元,以及更多的 EUV 使用和更好的晶体管和互连。Intel 3 旨在成为Intel 4 的简单端口。
密度
任何读过我以前的文章和比较的人都知道我非常强调密度。在 Intel 4 文章的图 1 中,他们披露了 Intel 4 的关键间距并将其与 Intel 7 进行比较,见图 1。

图 1. Intel 4 与 7 间距。
Intel 7 的高性能单元高度 (cell height :CH) 为 408 纳米,而Intel 4 的CH为 240 纳米。Intel 7 的 Contacted Poly Pitch (CPP) 为 60,Intel 4 为 50,Intel 7 的 CH 和 CPP 的乘积为24,480nm²,Intel 4 为 12,000nm²,为高性能cell提供了约 2 倍的密度提升。与 Intel 7 相比,Intel 4 的每wall性能提高了 20%,高密度 SRAM 扩展了 0.77 倍。
为了将这种密度改进放在上下文中,更好地了解英特尔最近的工艺进展是有用的。图 2 总结了四代英特尔 10nm 工艺。
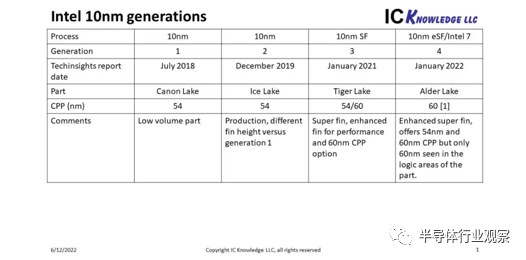
图 2. Intel 10nm 代。
IC Knowledge 与 TechInsights 建立了战略合作伙伴关系,我们相信他们在尖端半导体的结构分析方面是世界上最好的。TechInsights 于 2018 年 7 月首次分析英特尔 10nm,并将其称为第 1 代,TechInsights 于 2019 年 12 月完成了另一次 10nm 分析,发现相同的密度但不同的鳍片结构导致他们将其称为第 2 代。
2021 年 1 月,TechInsights 分析了 10nm Super Fin 部件提供 60nm CPP 选项以提高性能以及原始 54nm CPP(第 3 代)。最终在 2022 年 1 月,TechInsights 分析了 10nm 增强型 Super Fin 部件,这就是英特尔现在称之为Intel 7(10nm 第 4 代)的工艺。关于Itel 7 分析结果的一件有趣的事情是,TechInsights 仅在逻辑区域发现 60nm CPP,没有 54nm CPP 和更高的单元。
我表征制程(characterizing process )密度的策略是基于制程中可用的最密集单元。
对于 Intel 7,272nm 高的 54nm CPP 单元“可用”但未使用,具有 60nm CPP 的 408nm 高单元产生的晶体管密度约为每平方毫米 6500 万个晶体管 (Mtx/mm² ),而前几代约为 100 MTx/mm²。那么我们如何将Intel 4 与上一代工艺和即将推出的Intel 3 工艺进行对比,见图 3。
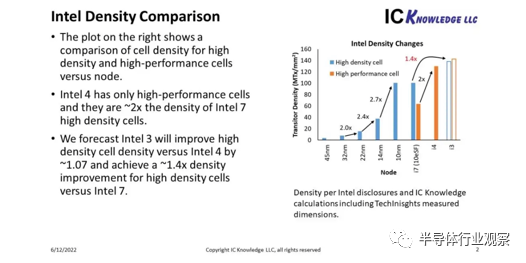
图 3. 英特尔密度比较。
在图 3 中,我分别展示了高密度和高性能单元密度。正如英特尔所披露的,Intel 4 的高性能单元密度约为Intel 7 的 2 倍。与Intel 4 相比,Intel 3 应该具有“更密集”的库。如果我假设Intel 3 的间距相同但轨道高度更小,那么与Intel 10/7相比,我得到的高性能单元密度约为 1.07 倍,高密度单元的密度约为 1.4 倍。
另一个有趣的比较是Intel 4 高性能单元尺寸与 TSMC 5nm 和 3nm 的高性能单元尺寸,见图 4。
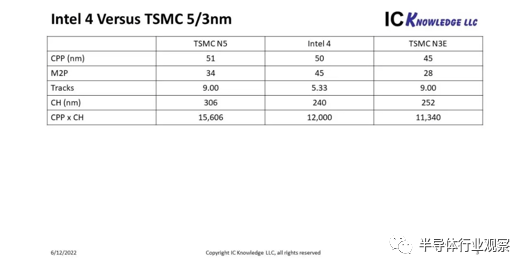
图 4. Intel 4 与 TSMC N3 和 N5 高性能单元。
TSMC N5 具有 51nm CPP 和 34nm M2P 以及 9.00 轨(track)高性能单元,可产生 306nm CH 和 15,606nm² CPP x CH。我们相信台积电 N3 具有 45nm CPP 和 28nm M2P,以及 9.00 轨道的高性能单元,可产生 252nm 的 CH 和 11,340nm 2的 CPP x CH 。
对于 Intel 4,CPP 为 50nm,M2P 为 45nm(在简报中披露,但未在论文中),对于引用的 240nm CH 和 CPP x CH 为 12,000nm²,这产生的轨道高度仅为 5.33. 这些值与 4 名称一致,因为它位于领先的代工公司台积电的 N5 和 N3 之间,想比台积电 N5 ,Intel 4更接近台积电 N3。我们也相信 Intel 4 的性能会略好于台积电 N3。
我没有在图 4 中包括三星,但根据我目前的估计,Intel 4 比三星 GAE3 更密集。三星可能比Intel 4 和台积电 N3 有一点性能优势,但Intel 3 明年的性能应该会超过三星 GAE3 和台积电 N3。
令我惊讶的是,英特尔的高性能单元的高度刚好超过 5 条轨道,但这是公开的单元高度和 M2P 的数学计算。
DTCO
从设计-技术-协同优化 (DTCO) 的角度来看,Intel 4 比Intel 7 有 3 项改进:
1.Contact Over Active Gate 针对 Intel 4 进行了优化。
2.去除伪栅极的扩散中断过去需要两个伪栅极(双扩散中断),Intel 7 变为 1(单扩散中断)。
3.n 到 p 间距曾经是两个鳍片间距,现在是 1 个鳍片间距。当我们在 M2P 和轨道方面谈论 CH 时,很容易忘记设备必须适应相同的高度,图 5 说明了 n 到 p 间距如何影响单元高度。

图 5. 像元高度 (CH) 缩放。
在简报问答中,有一个关于每个晶体管成本的问题,Ben 说Intel 4 与Intel 7 相比,每个晶体管的成本下降了。
性能
Intel 10/7 提供 2 个阈值电压(2 个 PMOS 和 2 个 NMOS = 总共 4 个)和 3 个阈值电压(3 个 PMOS 和 3 个 NMOS = 总共 6 个)版本。Intel 4 提供 4 个阈值电压(4 个 PMOS 和 3 个 NMOS = 8 个)。这使得功耗降低约 40%,性能提高约 20%。
我相信简报中提到的驱动电流值对于 PMOS 是 2mA/μm,对于 NMOS 是 2.5mA/μm。
EUV 使用
EUV 用于工艺的后端和前端。英特尔将 EUV 的使用重点放在了单次 EUV 曝光可以取代多次浸没式曝光的地方。尽管 EUV 曝光比浸入式曝光更昂贵,但用相关的沉积和蚀刻步骤代替多次浸入式曝光可以节省成本,提高周期时间和产量。
事实上,Ben 提到单次 EUV 曝光使得英特尔在 EUV 取代的部分中的步骤减少了 3-5 倍。从Intel 7 到Intel 4 升级, 我们看到光罩和步骤的减少。在生产线的前端,EUV 专注于替换复杂的切割、栅极或接触。英特尔没有明确披露 EUV 用于鳍片图案化,但我们认为Intel 7 鳍片图案化涉及一个mandrel mask (英特尔称其为grating mask)和 3 个cut mask (英特尔称这些collection masks)。对于 Intel 4,这可以很容易地转换为 4 cut mask。没有提到用单个 EUV 掩模替换 4 个cut masks 的层,我们相信这可能就是发生这种情况的地方。
在论文中,英特尔提到 M0 是四重图案。对于Intel 10/7,英特尔还披露了四重图案化,TechInsights 分析表明需要 3 个块(block)掩模。英特尔 4 可能需要 4 个用于 M0 的块掩模,这可能是 EUV 消除 4 个切割/块(cut/block )掩模的另一个地方。
网格布局用于互连以提高良率和性能。
我们相信在这个制程中使用了大约 12 次 EUV 曝光,但英特尔没有透露这一点。
互连
众所周知,英特尔在 10nm 时为 M0 和 M1 选择了钴 (Co)。Co 提供比铜 (Cu) 更好的电迁移电阻,但电阻更高(作者指出,金属的电迁移电阻与熔点成正比)。
对于Intel 4,英特尔采用了“增强型”铜方案,其中纯铜被包裹在钴中(过去英特尔掺杂铜)。将 Cu 封装在 Co 中的典型流程是用 Co 层放置阻挡层,作为电镀的种子。一旦电镀完成并平面化以形成互连,Cu 就会被 Co 覆盖。该过程导致电迁移电阻与 Co 相比略有下降,但仍高于 10 年寿命目标,并且线路的电阻降低。事实上,即使 Intel 4 的互连线比 Intel 7 的互连线更窄,RC 值仍然保持不变。
该工艺有 5 个增强铜层、2 个巨型金属层和 11 个“标准”金属层,共 18 层。
MIM caps
随着电力传输的重要性日益增加,金属-绝缘体-金属 (MIM:Metal-Insulator-Metal ) 电容器被用于减少功率波动,并不断得到改进。对于英特尔的 14nm 工艺,实现了 37 fF/μm²,10nm 提高到 141 fF/μm² ,Intel 7 提高到193 fF/μm²,现在Intel 4提高了约 2 倍,达到 376 fF/μm²。更高的值使 MIM 电容器具有更大的电容,从而提高功率稳定性,而不会占用过多的空间。
他们哪里出错了
在问答环节中,Ben 被问及英特尔过去哪里出了问题,他说过去英特尔试图一次做太多事情(作者指出,例如英特尔 22nm 到 14nm 是 2.4 倍的密度增加,然后 14nm 到 10nm 是密度增加了 2.7 倍,见图 3。英特尔现在采用了模块化方法,您可以单独开发模块并更快地提供更高的性能。
当被问及他最自豪的是什么时,他说通过库扩展实现了良率和性能,并且该工艺在工厂中看起来不错。由于 EUV 提高了产量并减少了配准问题,该过程更加简单。
生产基地
在问答环节中,Ben 还被问及生产地点。他说,最初的生产将在Hillsboro,然后是爱尔兰。他说他们没有透露除此之外的其他生产计划。
在我们自己对 EUV 可用性的分析中,我们已在此处发布未来几年 EUV 曝光工具将供不应求。这也与 Pat Gelsinger 讨论英特尔新晶圆厂的工具短缺问题一致。我们相信 EUV 工具的可用性将缩短英特尔的晶圆厂斜坡。
此外,我们相信英特尔目前拥有约 10 到 12 个 EUV 工具,直到最近它们都在 Hillsboro。其中一个工具现已移至爱尔兰的 Fab 34,我们相信,随着英特尔今年收到更多 EUV 工具,他们将能够扩大 Fab 34。今年晚些时候,我们预计以色列的 Fab 38 将开始加速生产,我们相信这将成为下一个英特尔 4/3 生产基地。随后在 2023 年下半年,亚利桑那州的 Fab 52 和 62 应该开始接收 EUV 工具。
良率和准备情况
在整个简报中,我们听到的关于良率的一切都是“健康的”和“按计划进行的”。Meteor Lake 计算块已启动并在进程中运行。该工艺已准备好在明年下半年生产。
结论
我对这个制程印象深刻。我越是将它与台积电和三星的产品进行比较,我的印象就越深刻。在 2000 年代和 2010 年代初,英特尔是逻辑处理技术的领导者,之后三星和台积电以卓越的执行力领先。如果英特尔继续走上正轨并在明年发布Intel 3,他们将拥有一个在密度上具有竞争力并且可能在性能上处于领先地位的代工工艺。英特尔还制定了 2024 年英特尔 20A 和 18A 的路线图。三星和台积电都将在 2024/2025 年推出 2nm 工艺,它们需要在 3nm 工艺上进行重大改进,以跟上英特尔的步伐。
免责声明
本平台所刊载的所有资料及图表仅供参考使用。刊载这些文档并不构成对任何股份的收购、购买、认购、抛售或持有的邀约或意图。投资者依据本网站提供的信息、资料及图表进行金融、证券等投资项目所造成的盈亏与本网站无关。除原创作品外,本平台所使用的文章、图片、视频及音乐属于原权利人所有,因客观原因,或会存在不当使用的情况,如部分文章或文章部分引用内容未能及时与原作者取得联系,或作者名称及原始出处标注错误等情况,非恶意侵犯原权利人相关权益,敬请相关权利人谅解并与我们联系及时处理,共同维护良好的网络创作环境。


芯通社
- SemiWebs -
专注半导体-手机通信-人工智能
请长按下面二维码关注芯通社
▼


伙伴们
错过也许就是一辈子
还不快关注我们?
