


点击上方蓝字关注我们
Chiplet技术和NoC技术目前已经成为解决摩尔定律无法延续的一种重要方法,现在的CPU芯片对外的接口已经不是普通的IO了,而是一套标准的NoC总线接口,可以与专门的NoC总线DIE(暂称为IO DIE)利用Chiplet技术连接,多个CPU核或异构核与多个IO DIE再通过Chiplet技术进行集成,就可以做出来更大规模的芯片。正是Chiplet技术和NoC技术的出现给体系结构带来了发展的黄金时代,异构计算和DSA(Domain-Specific Architecture,领域特定体系结构)慢慢走上舞台,人工智能领域各种高效的架构层出不穷,甚至Nvidia最新的Hopper GPU也开始向DSA慢慢靠拢;异构计算的核心之一是互连,传统的PCIe总线缺乏缓存一致性机制,导致内存性能低下,延迟低于可接受水平,因此出现了CCIX和CXL等协议,这些协议基于PCIe又高于PCIe,在继承PCIe兼容性的基础上,又提供了缓存一致性支持。在今年的FCCM会议上,德国TU Darmstadt和Reutlingen University联合发表了一篇CCIX相关的文章,该文章使用CCIX作为FPGA与Host之间的接口,并详细评估了CCIX与PCIe之间的差异,现将该文章译文奉上,以飨读者。
摘要:长期以来,大多数分立加速器都使用各代 PCI-Express 接口连接到主机系统。然而,由于缺乏对加速器和主机缓存之间一致性的支持,细粒度的交互需要频繁的缓存刷新,甚至需要使用低效的非缓存内存区域。加速器缓存一致性互连 (CCIX) 是第一个支持缓存一致性主机加速器附件的多供应商标准,并且已经表明了即将推出的标准的能力,例如 Compute Express Link (CXL)。在我们的工作中,当基于 ARM 的主机与两代支持 CCIX 的 FPGA 连接时,我们比较了 CCIX 与 PCIe 的使用情况。我们为访问和地址转换提供低级吞吐量和延迟测量,并检查使用 CCIX 在 FPGA 加速数据库系统中进行细粒度同步的应用级用例。我们可以证明,从 FPGA 到主机的特别小的读取可以从 CCIX 中受益,因为其延迟比 PCIe 短约 33%。不过,对主机的小写入延迟大约比 PCIe 高 32%,因为它们携带更高的一致性开销。对于数据库用例,即使在主机-FPGA 并行度很高的情况下,使用 CCIX 也可以保持恒定的同步延迟。

01
引言
当将主机 CPU 上基于软件的传统处理与专用硬件加速器相结合以执行异构计算以获得更高的性能或更高的效率时,主机和加速器之间接口的性质是一个关键的设计决策。
对于大多数离散加速器,例如 GPU 或 FPGA 板卡,PCI Express(简称:PCIe)长期以来一直是主要的接口。其性能稳步提升,最新广泛部署的 PCIe 4.0 版本达到每通道 1.97 GB/s。然而,PCIe 主要针对高吞吐量批量传输进行了优化。例如,如 [1] 所示,需要 128 到 256 KB 的传输才能达到至少 50% 的理论带宽。对于细粒度主机-加速器交互所需的较小传输大小(降至缓存行大小),可实现的吞吐量显著下降。虽然 PCIe 添加了诸如地址转换服务 (ATS) / 页面请求接口 (PRI) 之类的扩展来支持共享虚拟内存或原子操作,但大多数实现并不包含缓存一致性机制。
这使得细粒度的交互变得非常昂贵,因为在同步执行或交换小参数或结果时,主机或加速器端都需要缓存刷新,或者用于数据传输的内存区域必须标记为未缓存,从而减慢它们所在物理位置的处理元件(主机或加速器)的访问速度。
为了解决这个问题,已经提出了许多还涵盖高速缓存一致性的接口和协议。在这项工作中,我们研究了加速器缓存一致性互连 (CCIX) 的使用,这是第一个被指定为多供应商标准并跨多个不同加速器和主机架构实现的接口。一旦获得更广泛行业支持的 Compute Express Link (CXL) 等协议进入市场,预计在不久的将来会有进一步的改进。
我们提供了各种 CCIX 访问场景的详细低级测量,以及应用程序级用例。后者在运行利用近数据处理 (NDP) 的数据库管理系统(DBMS) 时,采用 CCIX 实现 FPGA 加速器和主机之间的高性能同步。据我们所知,这是第一次为此目的使用缓存一致的加速器接口。
我们将在下一节中概述一些接口和协议,然后在第 III 节中讨论 CCIX 细节,尤其是关于FPGA加速器的内容。不过,我们的主要贡献是评估,我们在第四节中介绍了低级特征,在第五节中介绍了应用程序级用例。我们在第六节中总结并期待未来的工作。
02
相关工作
a) PCIe:PCI Express [2] 是将外围设备连接到桌面和服务器系统的标准。PCIe 通过为单个设备捆绑多个通道来扩展链路的带宽。在 1.0 版中,它能够以每通道 250 MB/s 的速度传输。每个后续版本的带宽大约翻了一番,现在在 6.0 版本中达到了每通道 7.88 GB/s。目前,6.0 版本刚刚被指定,而 5.0 的硬件即将推出,4.0 是当前硬件上部署最广泛的版本。PCIe 使用全双工串行链路,采用点对点拓扑结构,在电气链路层之上有两个附加层,即数据链路层和事务层。这些附加层提供纠错和基于数据包的通信。除了传输数据、设备初始化等基本操作外,PCIe 还支持更高级(可选)的功能,例如 PRI 和 ATS,但不包括缓存一致性。
b) CCIX:CCIX [3]、[4] 是一种高级 I/O 互连,它使两个或多个设备能够以一致的方式共享数据。在物理层上,它可以与PCIe 兼容(尽管它可以选择允许更高的信令速率),并且仅在协议和端点控制器上有所不同。它由 CCIX 联盟于 2016 年推出,该联盟由 AMD、ARM、华为、IBM、Mellanox、高通、赛灵思 [5] 创立。CCIX 已在基于 ARM 和基于 x86 的 CPU 上实现。
c) 其他共享虚拟内存 (SVM) 或缓存一致性 SVM 互连:CCIX 并不是共享虚拟内存互连的唯一竞争者。阿里巴巴集团、思科系统、戴尔/EMC、Facebook、谷歌、HPE、华为、英特尔和微软在 2019 年基于英特尔之前的工作提出了 CXL [6]。虽然 CCIX 可以在较旧的 PCIe 连接上运行,但 CXL 最初是基于 PCIe 5.0 设计的。因此,CXL 可以达到每个通道高达 32 GT/s(即 3.94 GB/s),它提供与 CCIX 类似的功能,但使用不同的逻辑视图。CXL 已经看到比 CCIX 更广泛的工业应用,并有望成为未来几年的主要解决方案。
另一种选择是 IBM 于 2014 年推出的 Coherent Accelerator Processor Interface(CAPI,后来的 OpenCAPI)。虽然第一个版本也是在PCIe 之上实现的,但最近的版本是供应商特定的接口。CAPI 主要用于基于 IBM POWER 的主机,因此其范围比CCIX 和 CXL 更有限。在 OpenCAPI 3.0(x8 通道)中,它提供 22 GB/s 的带宽和 298/80 ns [7] 的读/写延迟。
虽然不是像 CCIX 那样直接扩展 PCIe,但支持缓存一致性协议的另一个互连是 Gen-Z [8]。它每通道提供高达 56 GT/s 的速度,并允许与 PCIe 类似地组合多个通道。尽管具有令人鼓舞的功能,但尚未商业发布 Gen-Z 硬件,该技术将合并到 CXL中。
d) FPGA 上的数据库加速:[9] 很好地概述了使用 FPGA 加速数据库操作。最常见的方法,例如在 Centaur [10] 等最先进的解决方案中使用的方法,采用 FPGA 作为大规模过滤、排序、连接或算术计算的卸载加速器。但是,这种操作模式会带来大量数据从 FPGA 传输到 FPGA 的成本,并且与这里研究的旨在避免这些传输的近数据处理方法不同。
03
CCIX架构及在FPGA上的使用
本节将概述通用 CCIX 架构,并讨论如何在两个不同的 FPGA 系列中使用它。
设备在端点连接到 CCIX。对于这里的讨论,相关类型的端点是归属代理 (HA) 和请求代理 (RA)。HA 充当物理内存的“所有者”,它提供对物理内存的一致访问,而 RA 通过与拥有的 HA 通信来执行对远程内存的非本地读取和写入。CCIX 与 PCIe 的区别在于 RA 可以提供自己的缓存,但通过 CCIX 保持与 HA 的一致性。在 HA 侧,缓存状态的变化将通过发送适当的消息传播到访问的 RA。CCIX 本身使用物理地址进行访问,但可以选择使用现有的 PCIe 机制来允许加速器使用虚拟地址。为了执行实际的地址转换,CCIX 依赖于 PCIe ATS 机制,这也是 CCIX 附加的加速器也在不同的 PCIe 虚拟通道 (VC) 上保持与主机的传统 PCIe 连接的原因之一。在包括网格和交换层次结构在内的各种 CCIX 拓扑中,我们采用了一种简单的拓扑,它依赖于主机和加速器之间的直接连接。此外,由于硬件接口级别支持所有必需的操作,包括地址转换和一致性,因此主机上不需要特殊的设备驱动程序或自定义固件。
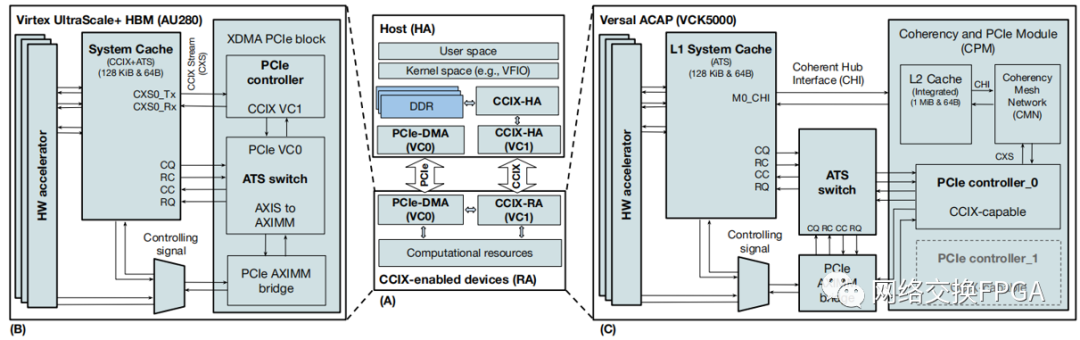
图1 中间 (A):具有 CCIX 功能的主机的架构,充当 HA,附加 CCIX 的加速器充当 RA。 左 (B):在 Xilinx UltraScale+ HBM 器件上实现CCIX-RA 的 SoC。 右 (C):在 Versal ACAP 设备上实现 CCIX-RA 的 SoC。
图 1-(A) 显示了支持 CCIX 设备的高速缓存一致性主机 FPGA 附件的高级架构。此框图的顶部是主机,底部是加速器,两者都通过支持 CCIX 的 PCIe 接口连接。CCIX 在 PCIe 事务层上使用多个VC,在同一个 PCIe 插槽上传输 PCIe 和 CCIX 流量。在支持 CCIX 的插槽上,事务层对 PCIe 数据包使用 VC0,对 CCIX 数据包使用 VC1,共享相同的物理层和链路层。但是,CCIX 可以选择使用扩展速度模式 (ESM),这会增加信令速率。对于我们使用的 PCIe 4.0 附件,ESM 将速率从 16 GT/s 提高到 25 GT/s,每次传输 128 个有效负载位。如果双方(即 RA 和 HA)都支持,ESM 模式将在引导时的 CCIX 发现阶段自动启用。
Xilinx Virtex UltraScale+ HBM 器件支持 CCIX,但必须以扩展 XDMA IP 块的形式将 CCIX 功能实现为可重新配置的“软”逻辑。如图 1-(B) 所示,关键模块包括一个支持 CCIX 的 PCIe 控制器、一个 ATS 交换机和一个 PCIe-AXIMM 桥。ATS 开关用于通过 PCIe VC0 将虚拟到物理地址转换请求插入到常规 PCIe 通信中,然后检索它们的结果。它还包括一个小的地址转换缓存 (ATC) 来缓冲现有的转换结果,以避免对已知映射进行相对昂贵的地址转换。AXIMM 桥提供主机和加速器之间的内存映射通信(主要是控制平面流量)。对于数据平面访问,加速器采用了使用赛灵思系统缓存 IP 块 [11] 实现的片上缓存,该缓存又使用 CCIX 流协议与 CCIX 一致性机制交互。此缓存中的未命中成为远程内存访问,通过 CCIX 转发到 HA 以检索数据。反过来,HA 确保了 FPGA 端 SC 与主机端缓存的一致性。
最新的 Xilinx Versal 器件在其芯片中优化了对 CCIX 的“强化”支持。具体来说,一致性和 PCIe 模块 (CPM) IP 块 [12] 包括一个集成的 L2 缓存,使用ARM的CHI协议与芯片范围内的一致性网状网络通信,后者又使用CXS 与支持 CCIX 的 PCIe 控制器接口。与之前在UltraScale+设备中一样,两个 PCIe VC 用于分离在同一PCIe插槽上运行的PCIe和CCIX流量。我们的设置只需要CPM模块提供的两个支持CCIX的PCIe 控制器之一。ATS Switch 和 AXIMM 块与以前一样使用。
在系统缓存 (SC) 收到来自加速器的读/写请求后,它会检查 ATC 的虚拟到物理映射。如果 SC 在 ATC 中没有找到有效的转换(即ATC未命中),它会通过 VC0 使用 PCIe ATS 功能向主机请求转换。系统缓存上的 ATS 接口使用请求完成协议 [13] 通过四个流接口提供翻译服务:传入完成者请求 (CQ)、传出完成者完成 (CC)、传出请求者请求 (RQ) 和传入请求者完成(RC)。来自主机的回复(例如,保留物理地址)使用相同的机制传递回 FPGA。
CCIX 事务的平均延迟如公式 1 所示。每个事务的延迟取决于ATC中可用的有效缓存地址转换的概率与ATS必须从主机请求新转换的概率,以及所请求的数据是否存在于本地片上缓存中。必须从远程 HA 请求。请注意,使用 ESM 时,物理 CCIX 延迟可能比物理 PCIe 延迟更短。

04
实验设置和评估
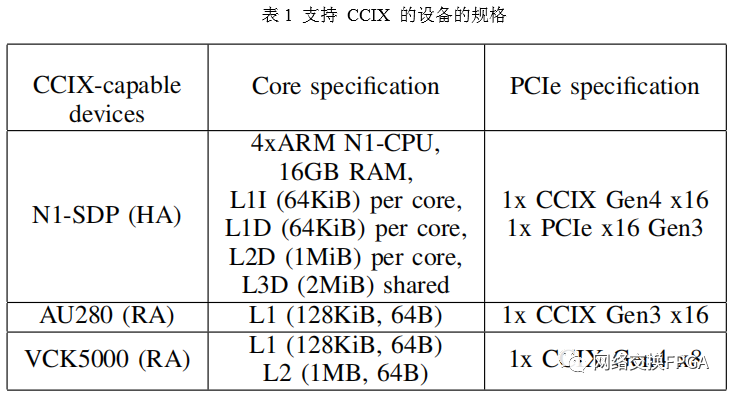
我们在真实硬件中进行实际评估,即使用支持 CCIX 的 ARM N1-SDP 平台作为主机,使用分别具有UltraScale+ HBM 和 Versal ACAP FPGA Xilinx 的Alveo U280 (AU280) 和 VCK5000 CCIX附加板作为加速器。表I显示了不同设备的规格。
稍后描述的所有低级基准测试都使用相同的基本测量方法,该方法由三个主要组件组成:软件应用程序编程接口 (API)、硬件模块和上述片上 CCIX 组件。软件 API 在主机上运行,负责执行基准测试并读取硬件分析的 CCIX 延迟特性。软件 API 有四个主要任务:a) 在主机内存中分配缓冲区,b) 初始化硬件模块以访问测量,c) 检索硬件模块记录的延迟数据,以及 d) 分析结果。软件 API 的伪代码如算法 1 所示。请注意,我们将地址随机化以强制 SC 未命中,从而确保我们感兴趣的 CCIX 传输实际发生。

称为 CCIX 流量生成器 (CTG) 的硬件模块使用获取/存储方法来捕获 CCIX延迟。该模块接受来自主机中软件API的 startTrans 调用的请求(包括类型、虚拟地址和长度)。在 API 请求之后,CTG 通过 AXI4-MM 接口向 SC 创建请求,SC 执行 CCIX RA 的角色,然后计算响应到达 SC 的时间。然后可以通过软件 API 读取捕获的时序。请注意,我们仅在其所有数据到达后才认为事务完成。
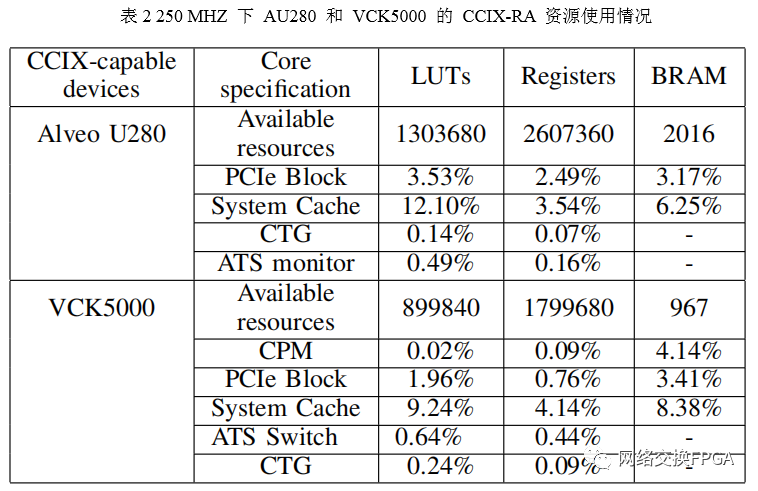
表II 显示了我们检查的简单 CCIX-RA 所需的 FPGA 资源。如图 1-(C) 所示,VCK5000 使用硬化 CPM 模块形式的 PCIe 控制器,但仍需要一些额外的“软”逻辑来支持 PCIe 传输和 ATS 转换。
实验 1:CCIX 与 PCIe - 延迟和吞吐量。
在这个实验中,我们比较了细粒度交互中相对较小的块大小(32B 到 16KiB)的 CCIX 和 PCIe 传输延迟(并且比 [1] 中检查的 PCIe 批量传输要小得多)。开源 TaPaSCo [14] 框架用于测试 DMA 传输。在这个实验中,通过确保地址转换已经存在于ATC中来消除 ATS 延迟。图 2-(A) 和图 2-(B) 分别显示了 PCIe 和 CCIX 流量的读取和写入延迟。对于 PCIe-DMA 传输,我们使用TaPaSCo 的高性能 DMA 引擎,通过设置不同的数据传输大小,直接使用主机内存数据的物理地址。对于 CCIX 测量,在主机内存中分配一个缓冲区,并将其虚拟地址传递给 CTG 模块。
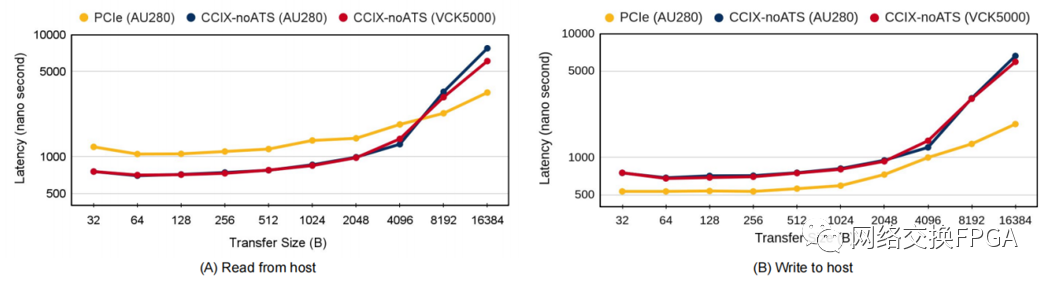
图2 比较 AU280 和 VCK5000 上的 CCIX 和 PCIe 读/写访问延迟
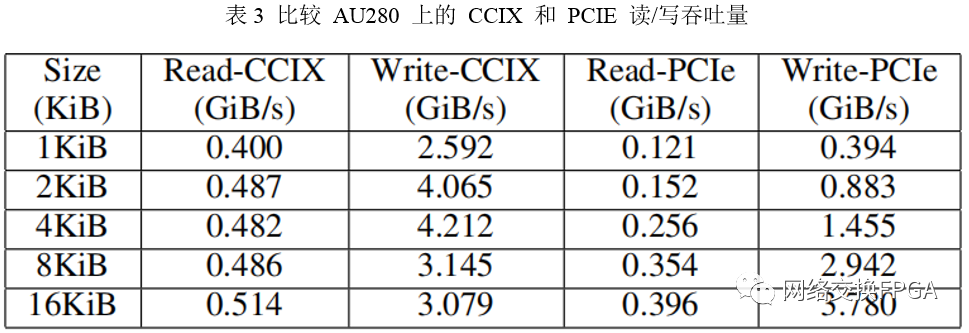
我们的评估表明,在AU280和VCK5000上,与 PCIe-DMA 传输相比,CCIX 传输具有更好的主机读取延迟,只要传输的数据短于 4 KiB。在这两种情况下,加速都是由于 CCIX 使用的优化数据包协议。但是,当使用优化的数据包协议从 FPGA 写入主机存储器时,CCIX 会产生比 PCIe 传输更长的延迟,因为这些写入参与了一致性机制。我们的吞吐量测量显示,对于 1KiB、16KiB 和 32KiB 的数据集大小,CCIX 的读取吞吐量相对于 PCIe 分别为 3.3x、1.29x、0.87x。读取和写入吞吐量的其他数据点显示在表 III 中。
实验 2:ATS 的成本。
透明地解析虚拟地址的能力大大简化了加速器设计和主机接口。但是,该操作可能代价高昂,因为如果请求的转换不存在于主机 IOMMU 的 TLB 之一中,它可能会触发主机上缓慢的完整页表遍历。在实验 1 中,我们检查了不需要地址转换 (noATS) 的访问。但是为了检查 ATS 的成本,我们现在构建了两个访问场景,如图 3 所示:在第一个场景中(使用 ATS),我们强制在 SC 和 ATC 中未命中,因此总是会产生 ATS 开销。在第二个(noATS)中,我们允许 ATC 命中,但仍然强制 SC 未命中,以便实际发生 CCIX 事务。结果表明,特别是对于较小的传输,ATS 开销可能很大,导致 ATC 未命中时的访问延迟增加三倍。但是,对于 32KB 及以上的传输,传输时间开始主导 ATS 开销。
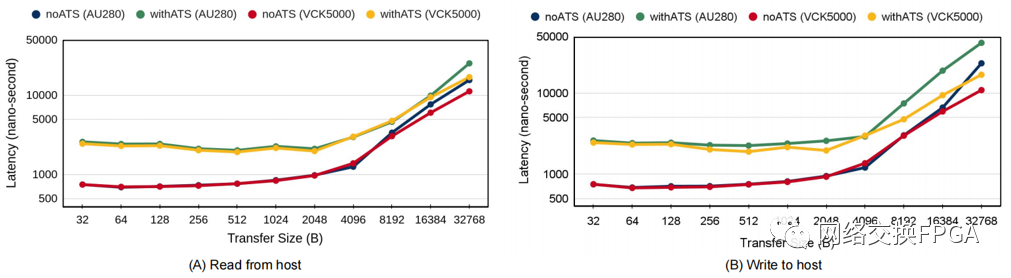
图3 ATS 对从 Alveo U280 卡和 VCK5000 上的 CTG 模块随机访问 RA 模块的 CCIX 访问延迟的影响
为了进一步研究 ATS 延迟,我们可以利用整个 ATS 机制在 SoC 的 ATS Switch 块中实现的事实。因此,我们可以监控该模块的请求/回复接口,以捕获 ATS 操作本身的确切请求-响应时间。图4显示了 64 B(高速缓存行大小)、128 B 和 4 KiB 块的 CCIX 访问延迟。由于 Linux Page Size 为 4KiB,因此这些请求每个只需要一个 ATS 转换。通过增加请求的大小,需要更多的翻译。对主机内存中分配的缓冲区的初始访问具有最长的延迟。以后的顺序访问具有较少的 ATS 开销,即使在 4 KiB 跨到另一个页面时也是如此。我们假设这是由于主机 IOMMU 对此处使用的顺序访问执行了预翻译。对于重复 64 B 读取的情况,通过比较主机 IOMMU 响应 ATS 请求所需的延迟(≈ 617 ns,在 ATS 交换机处捕获),以及在 SC 未命中情况下读取 64B 的已知延迟(≈ 700 ns,来自图 3-(A)),ATC 本身似乎需要 (2453 - 617 - 700 ≈ 1136 ns) 进行操作。
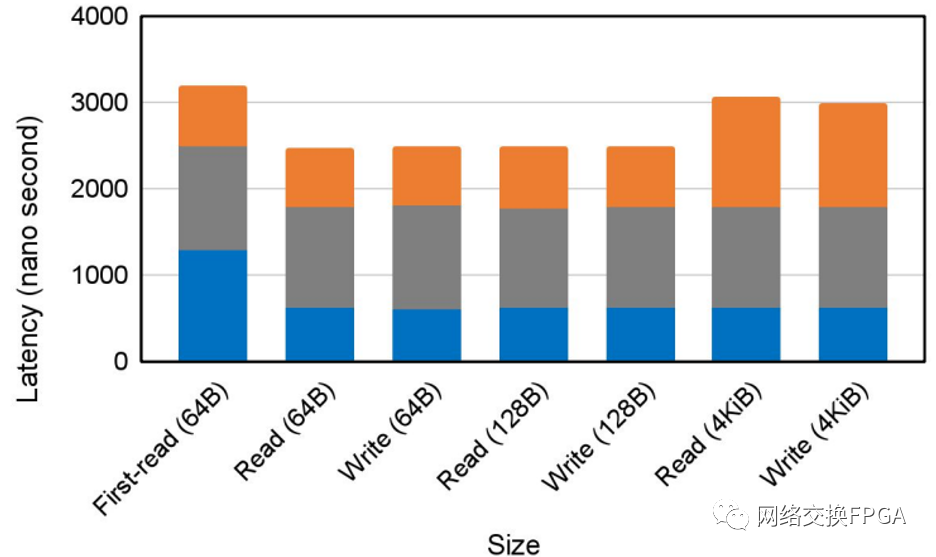
图4 比较 Alveo U280 卡上 CCIX-RA 的读/写延迟和 ATS 延迟
改善 CCIX 流量延迟的一种方法是减轻地址转换的影响。例如,这可以通过使用Linux大页面支持来实现。这将导致更大的页面,进而需要新翻译的页面边界交叉更少。N1-SDP平台在启动时确实支持不同大小(即 64KB、2MB、32MB 和 1GB)的巨页。我们在数据库用例(第 V 节)中采用了这种方法来提高性能。
实验 3:数据局部性。
CCIX 的使用允许加速器使用自己的缓存,确信它们将始终与主机保持一致。为了展示两个 SoC 的最佳情况基线性能,我们评估了保证所有访问都在设备上缓存中命中的情况,在图 5 中称为本地数据,并测量这些命中的延迟。为了比较,我们还展示了覆盖缓存未命中的数据远程案例。AU280 中更简单的缓存层次结构实现了比 VCK5000 上的二级缓存(写入 ≈ 150 ns,读取 ≈ 170 ns)更小的延迟(写入 ≈ 80 ns,读取 ≈ 100 ns),以实现更小的传输大小。但是,对于较大的传输,两级层次结构变得更快。
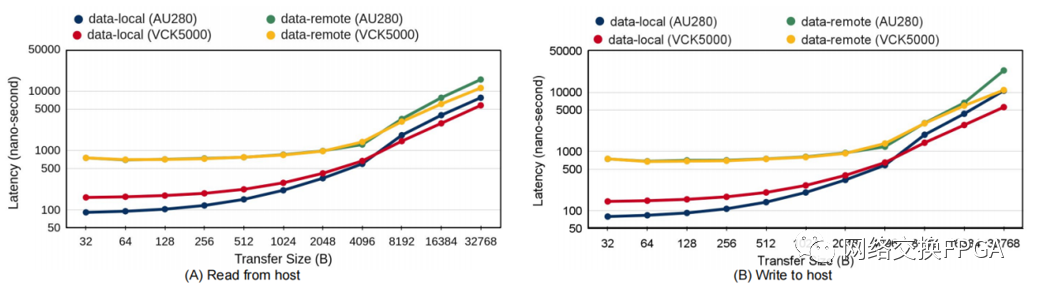
图5 数据局部性对 AU280 和 VCK5000 的 CCIX 延迟的影响
实验 4:一致性努力。
在这种情况下,主机上的应用程序分配一个共享缓冲区,主机和加速器同时访问和修改该缓冲区。这些并发访问/修改增加了一致性工作,进而增加了访问延迟。大页面用于避免 ATS 开销。如算法 2 所述,硬件 CTG 和软件 API 同时修改共享缓冲区中的缓存行。最初,我们使用 2 MiB 的缓冲区进行测量,然后分别缩小到 512 KiB、128 KiB 和 32 KiB,以增加争用程度,从而增加保持一致性所需的努力。缓冲区的这种缩小显示在图 6 左侧的 Y 轴上。对于这些共享缓冲区大小中的每一个,我们使用单个 CPU 内核和 FPGA 从两个主机对缓冲区中的随机地址执行 1024 次访问,并跟踪它们的延迟。正如预期的那样,随着访问次数的增加以及缓冲区大小的缩小,争用都会增加。在这两种情况下,必须解决的一致性冲突的可能性都会增加。有趣的是,额外的一致性工作主要影响主机的访问,FPGA 端访问的延迟几乎保持不变。这在图 6 的右侧进行了更详细的检查,该图绘制了访问时间的直方图,现在为 20,000 次访问,对于 32 KiB 和 2 MiB 共享缓冲区大小。虽然时间更长,但来自 FPGA 端的远程访问比本地主机端访问的“抖动”(分布更窄)要少得多。请注意,FPGA 端访问的非常短的异常值实际上是 SC 中的命中,其概率在较小的 32 KiB 中大于在较大的共享缓冲区中。在这个实验中,主机上只有一个内核访问共享缓冲区。为了进一步调查,我们使用主机上的多个内核来修改和访问共享缓冲区。我们的评估表明,由于更多的缓存命中,将 32 KiB 地址范围的内核数量从 1 个增加到 3 个实际上将本地主机端平均访问延迟从 333 ns 缩短到 235 ns。另一方面,由于更多的缓存未命中,设备访问延迟从 674 ns 增长到 741 ns。对于更大的内存范围,访问时间将再次保持几乎恒定。

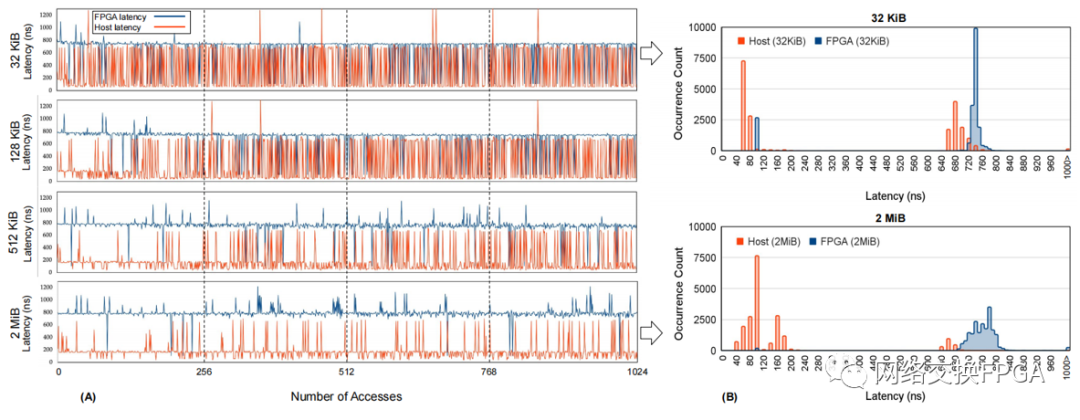
图6 使用单个 CPU 内核增加主机-FPGA 访问争用的一致性工作。左 (A):在从 2 MiB 缩小到 32 KiB 的地址范围内同时进行1024 次随机访问。右 (B):直方图显示两个地址范围的访问延迟“抖动”。
实验 5:原子操作。
CCIX 还能够通过支持AtomicStore、AtomicLoad、AtomicSwap 和AtomicCompare 操作在 RA(例如 AU280)和 HA(例如 N1-SDP)之间执行原子事务。它们在RA 端构建为 AXI4-MM 请求的多步序列。我们的评估表明,从主机启动的 AtomicCompare 需要 50 ns,而从加速器启动的 AtomicCompare 需要 740-800 ns。
05
数据库应用
在这些详细的低级别测量之后,我们现在检查 CCIX 在应用程序级别的使用,用于需要细粒度主机加速器交互的场景。作为一个现实场景,我们选择了数据库加速领域。所研究的系统是 neoDBMS(图 7)[15]、[16],一种基于 PostgreSQL 的 DBMS,使用 FPGA 加速的 NDP。以这种方式,计算被移到更靠近存储(例如,闪存、NVM)的地方,假设存储直接连接到 加速器。使用 NDP 可减少数据传输并提高整体系统性能。然而,数据库应用程序中的 NDP 面临一些挑战,例如同步和事务一致性。在数据库中,NDP模式下的事务有两种,只读NDP和更新NDP。在只读NDP中,为了使事务免于干预,每个事务都针对自己的快照进行操作。这需要首先收集主机主内存中的所有 DBMS 更新,然后在每次 NDP 调用 [15] 时将更改的 DBMS 状态传送到加速器。
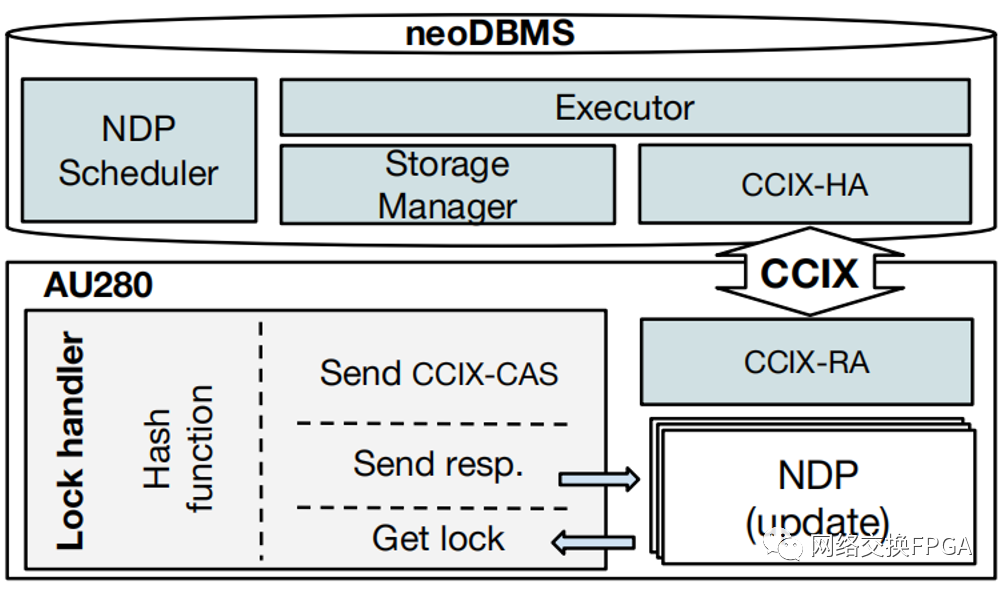
图7 具有共享锁表的 neoDBMS 架构
在更新 NDP 中,由于主机和加速器对同一记录的并发修改,使事务免干预具有挑战性。最初,相同的当前版本记录存在于加速器和 DBMS 的内存中。如果两者同时创建记录的新后继版本,则会导致两个当前版本分支,从而导致无法解决的不一致,称为写入/写入冲突。减轻这种不一致性的一种方法是在执行之前以独占方式锁定整个数据库表,但这会严重限制并发性。另一种方法是使用支持记录级锁定的细粒度缓存一致性共享锁表,从而可以锁定每条记录的版本,以同步 DBMS 和加速器之间的修改。
为了在 DBMS 和加速器之间实现一致且无干预的更新 NDP 操作,需要低延迟的缓存一致性失效和同步机制。为了处理上述neoDBMS中的写/写冲突,我们通过采用基于CCIX的解决方案来实现共享锁表。如果没有 CCIX,同步的成本会高得多,并且很可能会浪费 NDP 处理所获得的任何性能增益。为此,我们修改后的 neoDBMS 在主机内存中分配了一个共享锁表,主机和 FPGA 双方在更新记录之前请求锁定记录。neoDBMS 依靠 Linux 内核中的大页面(即HugeTLB Page)支持来请求物理上连续的内存页面,用于分配锁表并确保它们被固定。由于锁表的大小相对较小,并且在 DBMS 的整个运行时间内都非常频繁地访问条目,因此将表固定在物理主机内存中是有效的。
通过在位于哈希桶中的队列中插入一个条目来执行获取行级锁。因此,队列可以同时包含多个锁条目。通过对记录版本标识符应用哈希函数来计算存储桶位置。图 8 显示了两个并发进程的示例,一个在主机上,一个在设备上,请求相同记录版本(即 Rv2)的锁。对记录版本标识符应用哈希函数会导致两个进程尝试将锁插入位于同一哈希桶中的同一锁定队列中,此处编号为 2。在此示例中,首先,设备请求锁并立即获取锁.第一个槽代表当前持有锁并且允许修改数据的进程。稍后,主机尝试也请求相同的锁。由于锁队列的第一个槽已经被占用,主机无法获取锁,并将其请求附加到锁队列的尾部并等待。一旦设备完成,它通过将整个队列向左移动来释放锁,将现在位于队列头的锁授予下一个进程。然后主机获取锁并且可以继续执行。
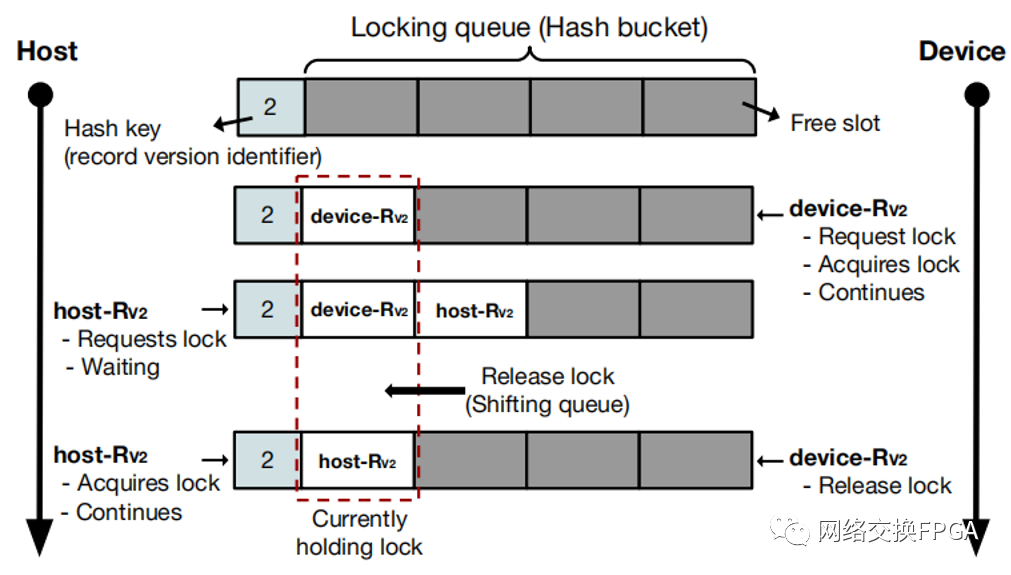
图8 共享锁表中的单个哈希桶(用于哈希键 2)的示例,来自主机和设备的并发锁请求在桶中排队等待相同的记录版本。
在 FPGA 上,已经开发了一个 Bluespec 模块来处理来自NDP-update 模块的锁定请求。该模块在提供的虚拟地址上创建一个哈希表组织的锁表。分配的缓冲区地址和锁表由 neoDBMS 指定。模块通过流接口接收/发送锁定请求/响应。收到锁请求后,模块会创建 CCIX 原子比较和交换 (CAS) 操作来放置锁并更新队列,然后AU280 上的 CCIX-RA 将其发送给主机。通过缓存一致性共享锁表和所采用的CCIX原子操作,我们实现了DBMS和FPGA之间数据的细粒度协同处理。
为了评估基于 CCIX 的同步机制的性能,我们测量了在 N1-SDP 平台和基于 AU280 的加速器上运行的 neoDBMS 的端到端锁定请求延迟,如图9 所示。由于共享锁表的大小大于Linux 4KiB 页面,因此访问会产生较长的 ATS 开销的风险很高。这已经通过使用大页面来避免。硬件模块执行一个独立于实际共享锁操作的请求,以通过对大页面的物理转换来“预热”ATC。然后,所有实际的锁定请求都会有 ATC 命中,并且不会受到 ATS 开销的影响。
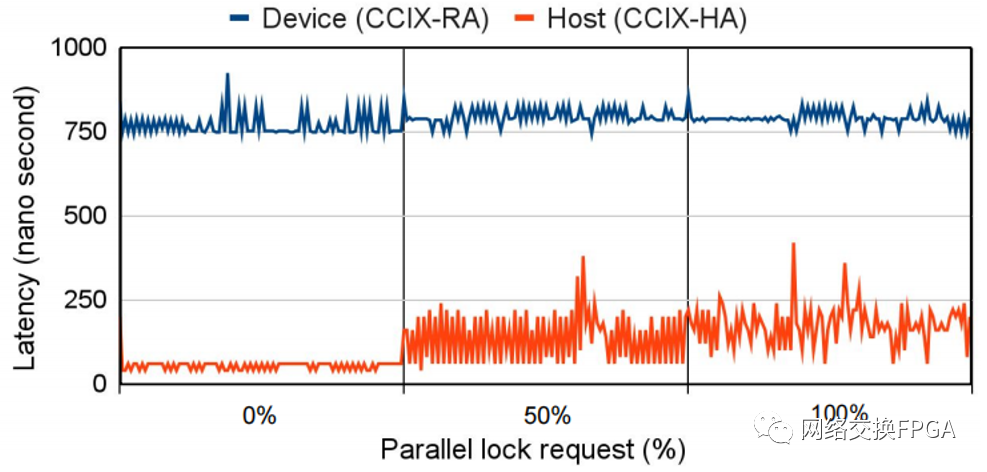
图9 并行访问共享锁表的影响
在实验中,neoDBMS(在单个 CPU 内核上)和加速器都会不断地创建锁请求,而我们在另一侧增加了争用。在低竞争下,neoDBMS 能够在 80 ns 内锁定本地驻留锁表中的记录版本。在高竞争下,neoDBMS 的本地锁定延迟增加到200-250 ns。从加速器锁定当然需要更长的时间,因为远程访问是对主机内存执行的,但观察到的 750 到 800 ns 的延迟是 CCIX 原子 CAS 操作的典型延迟(参见上面的实验 5),最重要的是,不受竞争增加的影响。虽然这证实了上面实验 4 中已经观察到的行为,但有趣的是,它不仅适用于实验 4 的简单读/写操作,还适用于此处使用的更复杂的原子 CAS 访问。
06
结论
我们研究了使用 CCIX 在主机和基于 FPGA 的加速器之间进行细粒度交互。在我们的结果中,我们表明,尤其是对于较小的传输块大小,与 PCIe 相比,可以实现更短的延迟。此外,地址转换与 CCIX 操作的透明集成支持主机和 FPGA 加速器之间的缓存一致共享虚拟内存 (ccSVM) 编程模型,该模型传统上仅适用于高度专业化的平台,例如 Convey HC 级机器。对于数据库用例,可以看出 CCIX 远程访问虽然比本地访问慢,但即使对锁表等共享数据结构的更高程度的竞争访问也不会受到影响。
从我们的结果也可以看出,优化潜力存在于硬件/软件协议栈的多个级别。例如,我们已经演示了使用大页面来减少地址转换开销。还可以在 SoC 中插入更有效的特定于应用程序的翻译机制,因为所有翻译都发生在 ATS Switch 模块中,该模块具有良好记录的接口,可以用自定义版本替换。这可以被利用,例如,在 Sec.V 的 DBMS 用例中,即使对于超过 ATC 容量的随机访问模式,也可以完全避免 ATS。ATC 本身似乎也有优化潜力,但这需要更大的工程努力,因为它与供应商提供的系统黑盒部分更紧密地集成在一起。

THE END
翻译:孙欢 图文排版:潘伟涛
责任编辑:刘欢 潘伟涛
往期精选




FPGA技术江湖广发江湖帖
无广告纯净模式,给技术交流一片净土,从初学小白到行业精英业界大佬等,从军工领域到民用企业等,从通信、图像处理到人工智能等各个方向应有尽有,QQ微信双选,FPGA技术江湖打造最纯净最专业的技术交流学习平台。
FPGA技术江湖微信交流群

加群主微信,备注职业+方向+名字进群
FPGA技术江湖QQ交流群

备注地区+职业+方向+名字进群


