前天,小枣君发了一篇关于数据中心网络的文章(链接)。很多读者留言,说没看明白。

本着“将通信科普到底”的原则,今天,我再继续聊一下这个话题。
故事还是要从头开始说起。
1973年夏天,两名年轻的科学家(温顿·瑟夫和罗伯特卡恩)开始致⼒于在新⽣的计算机⽹络中,寻找⼀种能够在不同机器之间进行通讯的⽅法。
不久后,在一本黄⾊的便签本上,他们画出了TCP/IP协议族的原型。

几乎在同时,施乐公司的梅特卡夫和博格思,发明了以太网(Ethernet)。
我们现在都知道,互联网的最早原型,是老美搞出来的ARPANET(阿帕网)。
ARPANET最开始用的协议超烂,满足不了计算节点规模增长的需求。于是,70年代末,大佬们将ARPANET的核心协议替换成了TCP/IP(1978年)。
进入80年代末,在TCP/IP技术的加持下,ARPANET迅速扩大,并衍生出了很多兄弟姐妹。这些兄弟姐妹互相连啊连啊,就变成了举世闻名的互联网。
可以说,TCP/IP技术和以太网技术,是互联网早期崛起的基石。它们成本低廉,结构简单,便于开发、部署,为计算机网络的普及做出了巨大贡献。

但是后来,随着网络规模的急剧膨胀,传统TCP/IP和以太网技术开始显现疲态,无法满足互联网大带宽、高速率的发展需求。
最开始出现问题的,是存储。
早期的存储,大家都知道,就是机器内置硬盘,通过IDE、SCSI、SAS等接口,把硬盘连到主板上,通过主板上的总线(BUS),实现CPU、内存对硬盘数据的存取。
后来,存储容量需求越来越大,再加上安全备份的考虑(需要有RAID1/RAID5),硬盘数量越来越多,若干个硬盘搞不定,服务器内部也放不下。于是,就有了磁阵。

磁阵,磁盘阵列
磁阵就是专门放磁盘的设备,一口子插几十块那种。
硬盘数据存取,一直都是服务器的瓶颈。开始的时候,用的是网线或专用电缆连接服务器和磁阵,很快发现不够用。于是,就开始用光纤。这就是FC通道(Fibre Channel,光纤通道)。
2000年左右,光纤通道还是比较高大上的技术,成本不低。
当时,公共通信网络(骨干网)的光纤技术处于在SDH 155M、622M的阶段,2.5G的SDH和波分技术才刚起步,没有普及。后来,光纤才开始爆发,容量开始迅速跃升,向10G(2003)、40G(2010)、100G(2010)、400G(现在)的方向发展。
光纤不能用于数据中心的普通网络,那就只能继续用网线,还有以太网。
好在那时服务器之间的通信要求还没有那么高。100M和1000M的网线,勉强能满足一般业务的需求。2008年左右,以太网的速率才勉强达到了1Gbps的标准。
2010年后,又出幺蛾子。
除了存储之外,因为云计算、图形处理、人工智能、超算还有比特币等乱七八糟的原因,人们开始盯上了算力。
摩尔定律的逐渐疲软,已经无法支持CPU算力的提升需求。牙膏越来越难挤,于是,GPU开始崛起。使用显卡的GPU处理器进行计算,成为了行业的主流趋势。
得益于AI的高速发展,各大企业还搞出了AI芯片、APU、xPU啊各自五花八门的算力板卡。
算力极速膨胀(100倍以上),带来的直接后果,就是服务器数据吞吐量的指数级增加。
除了AI带来的变态算力需求之外,数据中心还有一个显著的变化趋势,那就是服务器和服务器之间的数据流量急剧增加。
互联网高速发展、用户数猛涨,传统的集中式计算架构无法满足需求,开始转变为分布式架构。
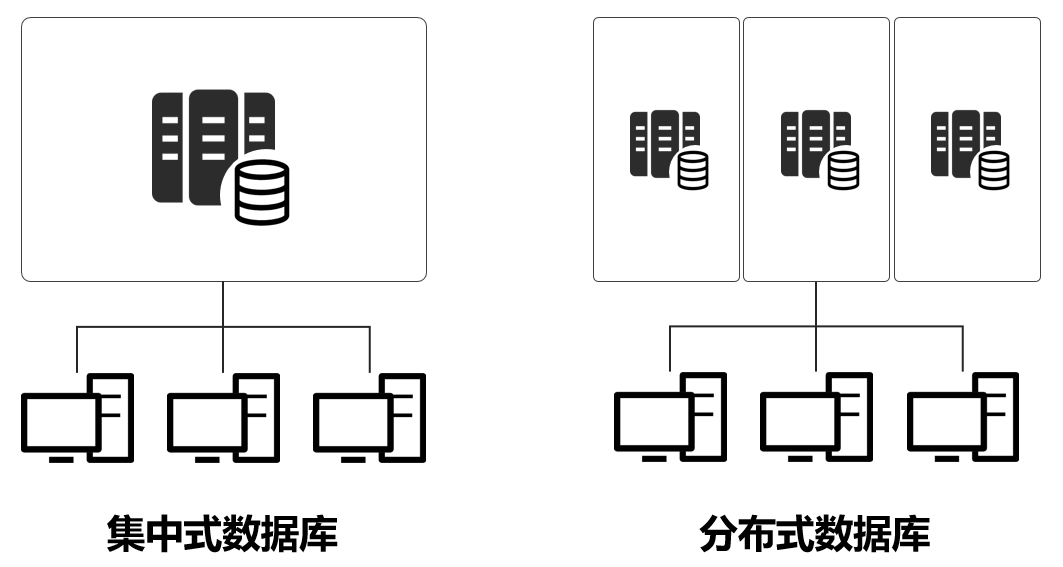
举例来说,现在618,大家都在血拼。百八十个用户,一台服务器就可以,千万级亿级,肯定不行了。所以,有了分布式架构,把一个服务,放在N个服务器上,分开算。
分布式架构下,服务器之间的数据流量大大增加了。数据中心内部互联网络的流量压力陡增,数据中心与数据中心之间也是一样。
这些横向(专业术语叫东西向)的数据报文,有时候还特别大,一些图形处理的数据,包大小甚至是Gb级别。
综上原因,传统以太网根本搞不定这么大的数据传输带宽和时延(高性能计算,对时延要求极高)需求。所以,少数厂家就搞了一个私有协议的专用网络通道技术,也就是Infiniband网络(直译为“无限带宽”技术,缩写为IB)。
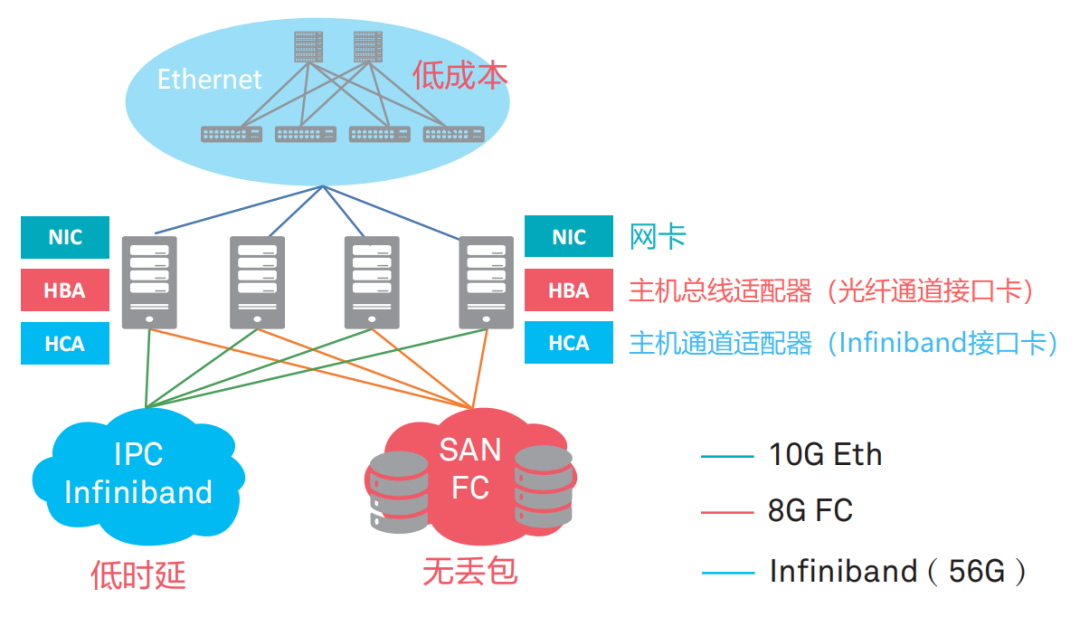
IB技术时延极低,但是造价成本高,而且维护复杂,和现有技术都不兼容。所以,和FC技术一样,只在特殊的需求下使用。
算力高速发展的同时,硬盘不甘寂寞,搞出了SSD固态硬盘,取代机械硬盘。内存嘛,从DDR到DDR2、DDR3、DDR4甚至DDR5,也是一个劲的猥琐发育,增加频率,增加带宽。
处理器、硬盘和内存的能力爆发,最终把压力转嫁到了网卡和网络身上。

学过计算机网络基础的同学都知道,传统以太网是基于“载波侦听多路访问/冲突检测(CSMA/CD)”的机制,极容易产生拥塞,导致动态时延升高,还经常发生丢包。
TCP/IP协议的话,服役时间实在太长,都40多年的老技术了,毛病一大堆。
举例来说,TCP协议栈在接收/发送报文时,内核需要做多次上下文切换,每次切换需要耗费5us~10us左右的时延。另外,还需要至少三次的数据拷贝和依赖CPU进行协议封装。
这些协议处理时延加起来,虽然看上去不大,十几微秒,但对高性能计算来说,是无法忍受的。
除了时延问题外,TCP/IP网络需要主机CPU多次参与协议栈内存拷贝。网络规模越大,带宽越高,CPU在收发数据时的调度负担就越大,导致CPU持续高负载。
按照业界测算数据:每传输1bit数据需要耗费1Hz的CPU,那么当网络带宽达到25G以上(满载)的时候,CPU要消费25GHz的算力,用于处理网络。大家可以看看自己的电脑CPU,工作频率是多少。
那么,是不是干脆直接换个网络技术就行呢?
不是不行,是难度太大。
CPU、硬盘和内存,都是服务器内部硬件,换了就换了,和外部无关。
但是通信网络技术,是外部互联技术,是要大家协商一起换的。我换了,你没换,网络就嗝屁了。
全世界互联网同时统一切换技术协议,你觉得可不可能?
不可能。所以,就像现在IPv6替换IPv4,就是循序渐进,先双栈(同时支持v4和v6),然后再慢慢淘汰v4。
数据中心网络的物理通道,光纤替换网线,还稍微容易一点,先小规模换,再逐渐扩大。换了光纤后,网络的速度和带宽上的问题,得以逐渐缓解。
网卡能力不足的问题,也比较好解决。既然CPU算不过来,那网卡就自己算呗。于是,就有了现在很火的智能网卡。某种程度来说,这就是算力下沉。
搞5G核心网的同事应该很熟悉,5G核心网媒体面网元UPF,承担了无线侧上来的所有业务数据,压力极大。
现在,UPF网元就采用了智能网卡技术,由网卡自己进行协议处理,缓解CPU的压力,流量吞吐还更快。
如何解决数据中心通信网络架构的问题呢?专家们想了半天,还是决定硬着头皮换架构。他们从服务器内部通信架构的角度,重新设计一个方案。
在新方案里,应用程序的数据,不再经过CPU和复杂的操作系统,直接和网卡通信。
这就是新型的通信机制——RDMA(Remote Direct Memory Access,远程直接数据存取)。
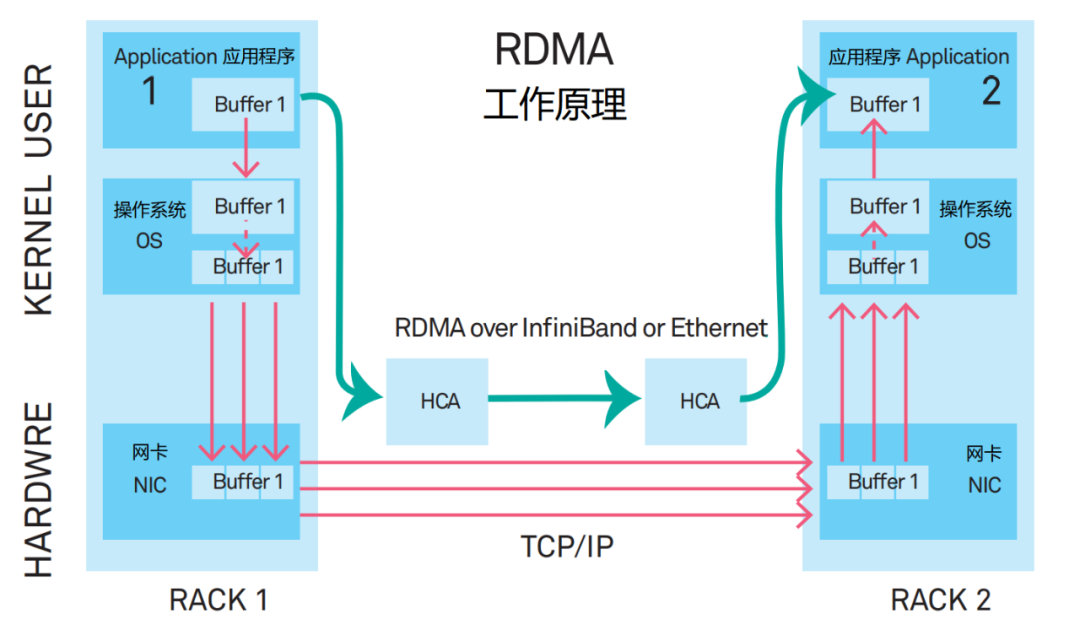
RDMA相当于是一个“消灭中间商”的技术,或者说“走后门”技术。
RDMA有两类网络承载方案,分别是专用InfiniBand和传统以太网络。

RDMA最早提出时,是承载在InfiniBand网络中。
但是,InfiniBand是一种封闭架构,交换机是特定厂家提供的专用产品,采用私有协议,无法兼容现网,加上对运维的要求过于复杂,并不是用户的合理选择。
于是,专家们打算把RDMA移植到以太网上。
比较尴尬的是,RDMA搭配传统以太网,存在很大问题。
RDMA对丢包率要求极高。0.1%的丢包率,将导致RDMA吞吐率急剧下降。2%的丢包率,将使得RDMA的吞吐率下降为0。

于是,专家们必须解决以太网的丢包问题,才能实现RDMA向以太网的移植。再于是,就有了前天文章提到的,华为的超融合数据中心网络智能无损技术。
说白了,就是让以太网做到零丢包,然后支撑RDMA。有了RDMA,就能实现超融合数据中心网络。
关于零丢包技术的细节,我不再赘述,大家看前天那篇文章(再给一遍链接:这里)。
值得一提的是,引入AI的网络智能无损技术是华为的首创,但超融合数据中心,是公共的概念。除了华为之外,别的厂家(例如深信服、联想等)也讲超融合数据中心,而且,这个概念在2017年就很热了。

光通道是王道

—— The End ——
延伸阅读:
互联网究竟是怎么诞生的?
到底什么是叶脊网络(Spine-Leaf)?
什么是OXC(全光交叉)?
关于ROADM的入门科普
关于存储技术的最强入门科普

