Ftrace公开课火热报名中:Ftrace公开课:站在设计者的角度来理解ftrace(限50人)。课程第二期报名已经开始,请咨询客服报名(小月微信:linuxer2016)。
作者简介:
程磊,一线码农,在某手机公司担任系统开发工程师,日常喜欢研究内核基本原理。
1.序言
内存对计算机系统来说是一项非常重要的资源,直接影响着系统运行的性能。最初的时候,系统是直接运行在物理内存上的,这存在着很多的问题,尤其是安全问题。后来出现了虚拟内存,内核和进程都运行在虚拟内存上,进程与进程之间有了空间隔离,增加了安全性。进程与内核之间有特权级的区别,进程运行在非特权级,内核运行在特权级,进程不能访问内核空间,只能通过系统调用和内核进行交互,内核会对进程进行严格的权限检查和参数检查,使得系统更加安全。通过虚拟内存访问物理内存,每次都需要解析页表,这大大降低了内存访问的性能,为此CPU的MMU里面加入了TLB用来缓存页表解析的结果,这样由于程序的时间局部性和空间局部性,能极大的提高内存访问的速度。虽然和直接访问物理内存相比,仍然存在着一些性能损耗,但是损耗已经降到很低了。因此虚拟内存机制在系统安全和性能之间达到了最大的平衡。虽然如此,但是虚拟内存机制也使得计算机的内存系统变得异常复杂,给我们的编程带来了巨大的挑战。内存问题,在很多软件公司里面,都是一个非常重要非常让人头疼的问题,今天我们从OOM的角度来帮大家提高一点内存方面的知识,虽然不能说帮助人们来完全解决内存问题,但是也能从一个侧面来提高大家分析内存问题相关的能力。2.内存的分配管理
我们已经知道了物理内存、虚拟内存、用户空间、内核空间之间的区别,下面我们再来深入的了解一下这方面的知识。系统刚启动的时候是运行在物理内存之上的,然后系统建立了一段足够自己继续运行的恒等映射的页表,也就是把物理地址映射到相同地址的虚拟地址上。等到系统再进一步初始化之后,就会建立完整的页表来映射物理内存,并把内核映射在虚拟地址空间的高部位,对于32位系统来说是3G之上的内存空间,对于64系统来说,是映射到比较接近虚拟地址顶端的地方。内核初始化之后就会启动init进程,从而启动整个用户空间的所有进程。内核空间和用户空间的内存管理方式的差别是非常大的,首先内核是不会缺页也不会换页的,不会缺页是指内核的物理内存在启动时就直接映射好了,使用时直接分配就行了,分配好虚拟内存的同时物理内存也分配好了。不会换页是指,当系统内存不足时内核自身使用的物理内存不会被swap出去。与此相反,用户空间的内存分配是先分配虚拟内存,此时并不会直接分配物理内存,而是延迟到程序运行时访问到哪里的内存,如果这个内存还没有对应的物理内存,MMU就会报缺页异常从而陷入内核,执行内核的缺页异常handler给分配物理内存,并建立页表映射,然后再回到用户空间刚才的那个指令处继续执行。当系统内存不足时,用户空间使用的物理内存会被swap到磁盘,从而回收物理内存。之后如果进程再访问这段内存又会再发生缺页异常从swap处把内存内容加载回来。3.进程的内存空间布局
明白了上面这些,我们再来看看进程的用户空间内存布局。我们都知道进程的内存空间是由代码区、数据区、堆区、栈区组成。我们先来看下面的图,我们以32位进程为例进行讲解,64位的数值太大不好画的,但是原理都是一样的。
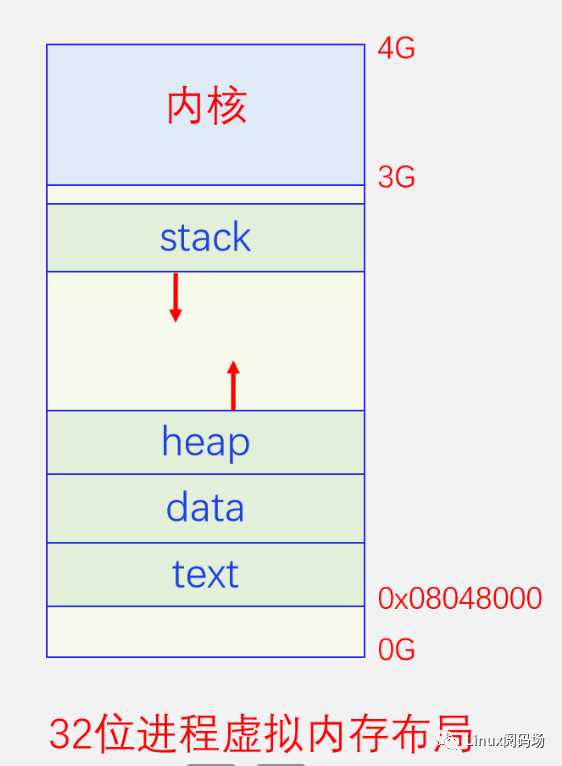
进程启动之后的内存布局如上图所示,程序file的代码段被映射到text区,数据段映射到data区,内核还会帮进程建立堆内存区映射和栈内存区映射,堆一般紧挨着data区的末尾往上增长,栈区在3G下面一点点往下增长。数据区和代码区是在进程启动时由内核之间分配好的,之后大小就不会再改变,heap区是随着程序运行中不断的malloc/free而增长或者缩小的,stack区是随时程序运行的局部变量分配释放而变化的,局部变量的分配释放是自动的,因此这三个区域也分别被叫做静态内存、动态内存、自动内存。由此我们可以看出,我们不必对静态内存、自动内存太操心,我们最应该关系的是动态内存。我们可以brk系统调用扩大heap区域来增加堆内存,然后再自己管理使用堆内存,但是这样做显然很麻烦。因此C库为我们准备了相关的API,malloc、free,来分配和释放堆内存,这样就方便到了。C库里面最早的malloc实现叫做dlmalloc,在计算机早期还是单CPU时代的时候非常流行,效率也非常高,但是随着SMP多CPU时代的到来,dlmalloc的缺点也越来越明显,尤其是多线程同时调用malloc的时候,锁冲突越来越严重,严重影响了性能。后来业界相继出现了ptmalloc、jemalloc、scudo等优秀的malloc库。Ptmalloc是Glibc的默认malloc实现,jemalloc库是首先实现在FreeBSD的malloc库,后广泛应用于FireFox、Redis、Netty等众多产品中,也长期是安卓的默认malloc库实现。目前安卓已经把malloc库替换为scudo了,据说scudo在安全和性能方面都很不错。程序简单的时候还好说,但是对于很多产品级的软件来说,其逻辑结构都非常复杂,进而导致其内存管理方面也很复杂,很容易出现栈溢出、野指针、内存泄漏等问题。我们有着很多方法和规则来规避这些问题,比如谁申请谁释放,引用计数,智能指针等,但是仍然不能完全解决这些问题。尤其是内存泄漏,在很多公司里面都是令人头疼的顽疾,对于内存泄漏也存在着很多工具,但是都无法完美的解决这个问题。我们今天要说的不是内存泄漏,而是由于内存泄漏或者内存使用不合理而导致的OOM问题。4.内存回收基本框架
在讲OOM之前,我们先来了解一下内核内存回收的总体框架。内存作为系统最宝贵的资源,总是不够用的,经常需要进行回收。内存回收可分为两种方式,同步回收和异步回收,同步回收是在分配内存时发现内存不足直接调用函数进行回收,异步回收是唤醒专门的回收线程kswapd进行回收。我们先看一下它们的总体架构图,然后再一一说明。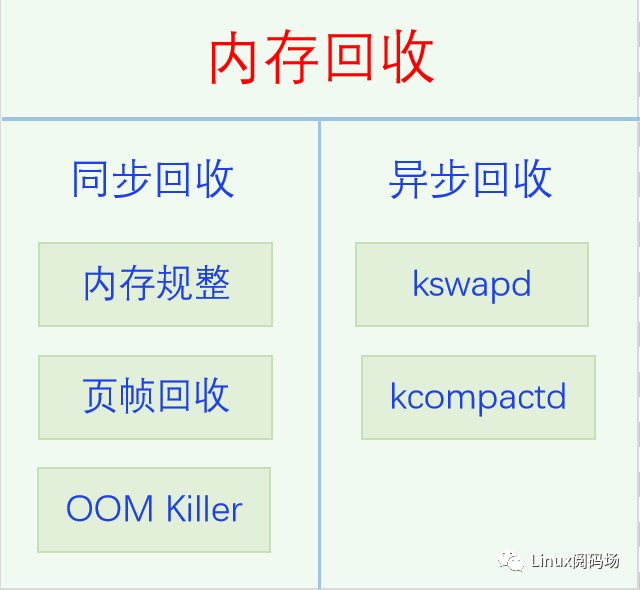
同步回收的话是在alloc_pages时发现内存不足就直接进行回收,首先尝试的是内存规整,也就是内存碎片整理,比如说系统当前有10个不连续的空闲page,但是你要分配两个连续的page,显然是无法分配的,此时就要进行内存规整,通过移动movable page,使空闲page尽量连在一起,这样能有可能分配出多个连续的page了。如果内存规整之后还是无法分配到内存,此时就会进行页帧回收了。用户空间的物理内存可以分为两种类型,文件页和匿名页,文件页是text data段对应的页帧,它们都有文件做后备存储,匿名是栈和堆对应的内存页,它们没有对应的文件,一般用swap分区或者swap文件做它们的后备存储。系统会首先考虑干净的文件页进行回收,因为回收它们只要直接丢弃内容就可以了,需要的时候再直接从文件里读取回来,这样不会有数据丢失。如果没有干净的文件页或者干净的文件页不太多,此时就要从dirty 文件页和匿名页进行回收了,因为它们都要进行IO操作,所以会非常的慢。如果页帧回收也回收不到内存的话,内核只能使出最后一招了,OOM Killer,直接杀进程进行内存回收,虽然这招好像不太文雅,但是也是没有办法,因为不这样做的话,系统没有多余的内存就没法继续运行,系统就会卡死,用户就会重启系统,结果更糟,所以杀进程也是最后的无奈之举。一般能走到这一步都是因为进程有长期或者严重的内存泄漏导致的。异步回收线程kswapd是被周期性的唤醒来执行回收任务的,当然同步回收的时候也会顺便唤醒它来一起回收内存。有一点需要注意的是kswapd线程不是per CPU的,而是per node的,是一个NUMA节点一个线程,这是因为内存的分配是per node不是 per CPU的,大部分内存分配都是优先从本node分配或者只能从本node分配,因此哪个node的内存不足了就唤醒哪个node的kswapd线程就行内存回收工作。对于家庭电脑和手机来说都是一个node,所以一般就只有一个kswapd线程。Kswapd完成回收工作之后,它会唤醒kcompactd线程进行内存规整,对的,内存规整也可以异步执行。5.OOM基本原理
在讲内核的OOM Killer之前,我们先来说一下OOM基本概念。OOM,out of memory,就是内存用完了耗尽了的意思。OOM分为虚拟内存OOM和物理内存OOM,两者是不一样的。虚拟内存OOM发生在用户空间,因为用户空间分配的就是虚拟内存,不能分配物理内存,程序在运行的时候触发缺页异常从而需要分配物理内存,内核自身在运行的时候也需要分配物理内存,如果此时物理内存不足了,就会发生物理内存OOM。用户空间虚拟内存OOM表现为malloc、mmap等内存分配接口返回失败,错误码为ENOMEM。大家也许会想,虚拟内存会OOM吗,虚拟内存那么大,对于32位进程来说就有3G,对于64位进程来说至少也得有上百G,应有尽有,而且很多教科书上都说的是虚拟内存可以随意分配,不受物理内存的限制,事实上真的是这样吗,让我们来看一看。5.1、虚拟内存OOM
虚拟内存我们是不是可以随意分配,虚拟空间有多大我们就能分配多少?事实不是这样的。UNIX世界有个著名的哲学原理,提供机制而不是策略,对于这个问题,Linux也提供了机制,我们可以通过 /proc/sys/vm/overcommit_memory 文件来选择策略。我们有三种选择,我们可以往这个文件里面写入0、1、2来选择不同的策略,这三个值对应的宏是:#define OVERCOMMIT_GUESS 0
#define OVERCOMMIT_ALWAYS 1
#define OVERCOMMIT_NEVER 2
通过宏名我们也可以大概猜出来是啥意思,下面我们一一解析一下,先从最简单的开始,OVERCOMMIT_ALWAYS,从名字就可以看出来,只要虚拟内存空间还有富余,你malloc多少内存就给你多少虚拟内存,不管它物理内存到底还够不够用。OVERCOMMIT_GUESS,名为GUESS,实在不好guess的,通过看代码发现,这个模式允许你最多分配的虚拟内存不能超过系统总的物理内存(这里说的总物理内存是物理内存加swap的总和,因为swap在一定意义上也相当于是增加了物理内存),也就是说一个进程分配的总虚拟内存可以和系统的总物理内存相同,还是够可以的。OVERCOMMIT_NEVER,这个就比较苛刻了,它像一位勤俭持家的妈妈,总是只给你勉强够用的零花钱,从来不多给一分。我们来看一下它的计算过程,它先计算一个基准值,默认等于50%的物理内存加上swap大小,然后再减去系统管理保留的内存,再减去用户管理保留的内存,如果系统所有已分配的虚拟内存大于这个值,就返回分配失败。具体情况大家可以去看代码:linux-src/mm/util.c:__vm_enough_memory。
我们再来看一个这个三个宏的公共部分OVERCOMMIT,过度承诺,这个词想表达什么含义呢,过程承诺 always never guess,我们可以看出来,过程承诺指的是,系统允许分配给你的虚拟内存是对你的承诺,后面当你具体用访问内存的时候,是要给你分配物理内存来实现对你的承诺的,那么这个承诺到底能不能实现呢,如果不能实现会怎么样呢?5.2、物理内存OOM
出来混迟早是要还的,分配出去的虚拟内存迟早是要兑现物理内存的。内核运行时会分配物理内存,程序运行时也会通过缺页异常去分配物理。如果此时没有足够的物理内存,内核会通过各种手段来收集物理内存,比如内存规整、回收缓存、swap等,如果这些手段都用尽了,还是没有收集到足够的物理内存,那么就只能使出最后一招了,OOM Killer,通过杀死进程来回收内存。代码实现在linux-src/mm/oom_kill.c:out_of_memory,触发点在linux-src/mm/page_alloc.c:__alloc_pages_may_oom,当使用各种方法都回收不到不到内存时会调用out_of_memory函数。
out_of_memory函数的实现还是有点复杂,我们把各种检测代码和辅助代码都去除之后,高度简化之后的函数如下:bool out_of_memory(struct oom_control *oc){ select_bad_process(oc); oom_kill_process(oc, "Out of memory");}
oom_kill_process函数的目的很简单,但是实现过程也有点复杂,这里就不展开分析了,大家可以自行去看一下代码。我们重点分析一下select_bad_process函数的逻辑,select_bad_process主要是依靠oom_score来进行进程选择的。我们先来看一下和每一个进程相关联的三个文件。/proc//oom_score系统计算出来的oom_score值,只读文件,取值范围0 –- 1000,0代表never kill,1000代表aways kill,值越大,进程被选中的概率越大。让用户空间调节oom_score之值的接口,root可读写,取值范围 -1000 --- 1000,默认为0,若为 -1000,则oom_score加上此值一定小于等于0,从而变成never kill进程。OS可以把一些关键的系统进程的oom_score_adj设为-1000,从而避免被oom kill。旧的接口文件,为兼容而保留,root可读写,取值范围 -16 — 15,会被线性映射到oom_score_adj,特殊值 -17代表 OOM_DISABLE,大家尽量不用再用此接口。
下面我们来分析一下select_bad_process函数的实现:
static void select_bad_process(struct oom_control *oc){ oc->chosen_points = LONG_MIN; struct task_struct *p;
rcu_read_lock(); for_each_process(p) if (oom_evaluate_task(p, oc)) break; rcu_read_unlock();}
函数首先把chosen_points初始化为最小的Long值,这个值是用来比较所有的oom_score值,最后谁的值最大就选中哪个进程。然后函数已经遍历所有进程,计算其oom_score,并更新chosen_points和被选中的task,有点类似于选择排序。我们继续看oom_evaluate_task函数是如何评估每个进程的函数。static int oom_evaluate_task(struct task_struct *task, void *arg){ struct oom_control *oc = arg; long points; if (oom_unkillable_task(task)) goto next; if (!is_memcg_oom(oc) && !oom_cpuset_eligible(task, oc)) goto next; if (oom_task_origin(task)) { points = LONG_MAX; goto select; } points = oom_badness(task, oc->totalpages); if (points == LONG_MIN || points < oc->chosen_points) goto next;select: if (oc->chosen) put_task_struct(oc->chosen); get_task_struct(task); oc->chosen = task; oc->chosen_points = points;next: return 0;abort: if (oc->chosen) put_task_struct(oc->chosen); oc->chosen = (void *)-1UL; return 1;}
此函数首先会跳轨所有不适合kill的进程,如init进程、内核线程、OOM_DISABLE进程等。然后通过select_bad_process算出此进程的得分points 也就是oom_score,并和上一次的胜出进程进行比较,如果小的会话就会goto next 返回,如果大的话就会更新oc->chosen 的task 和 chosen_points 也就是目前最高的oom_score。那么 oom_badness是如何计算的呢?
long oom_badness(struct task_struct *p, unsigned long totalpages){ long points; long adj; if (oom_unkillable_task(p)) return LONG_MIN; p = find_lock_task_mm(p); if (!p) return LONG_MIN; adj = (long)p->signal->oom_score_adj; if (adj == OOM_SCORE_ADJ_MIN || test_bit(MMF_OOM_SKIP, &p->mm->flags) || in_vfork(p)) { task_unlock(p); return LONG_MIN; } points = get_mm_rss(p->mm) + get_mm_counter(p->mm, MM_SWAPENTS) + mm_pgtables_bytes(p->mm) / PAGE_SIZE; task_unlock(p); adj *= totalpages / 1000; points += adj; return points;}
oom_badness首先把unkiller的进程也就是init进程内核线程直接返回 LONG_MIN,这样他们就不会被选中而杀死了,这里看好像和前面的检测冗余了,但是实际上这个函数还被/proc//oom_score的show函数调用用来显示数值,所以还是有必要的,这里也说明了一点,oom_score的值是不保留的,每次都是即时计算。然后又把oom_score_adj为-1000的进程直接也返回LONG_MIN,这样用户空间专门设置的进程就不会被kill了。最后就是计算oom_score了,计算方法比较简单,就是此进程使用的RSS驻留内存、页表、swap之和越大,也就是此进程所用的总内存越大,oom_score的值就越大,逻辑简单直接,谁用的物理内存最多就杀谁,这样就能够回收更多的物理内存,而且使用内存最多的进程很可能是内存泄漏了,所以此算法虽然很简单,但是也很合理。
可能很多会觉得这里讲的不对,和自己在网上的看到的逻辑不一样,那是因为网上有很多讲oom_score算法的文章都是基于2.6版本的内核讲的,那个算法比较复杂,会考虑进程的nice值,nice值小的,oom_score会相应的降低,也会考虑进程的运行时间,运行时间越长,oom_score值也会相应的降低,因为当时认为进程运行的时间长消耗内存多是合理的。但是这个算法会让那些缓慢内存泄漏的进程逃脱制裁。因此后来这个算法就改成现在这样的了,只考虑谁用的内存多就杀谁,简洁高效。5.3、安卓LMK简介
除了OOM Killer,Android上还开发了low memory killer机制,我们在此也简单介绍一下。LMK是在系统内存较低时就开始杀进程,而不是等到内存不足时再杀。LMK复用了OOM Killer 的 /proc//oom_score_adj 文件接口,但是没有使用/proc//oom_score。LMK仅根据oom_score_adj值的大小选择杀进程,而不会考虑进程本身占用内存的大小。apk进程的oom_score_adj的值由AMS根据apk的生命周期和其他一些因素进行设置,会动态变。apk进程的oom_score_adj都大于等于0,native进程的oom_score_adj的值由rc文件设置或者继承自父进程,一般都是静态的,不会变化,其值一般都小于0。很多重要的系统进程的oom_score_adj值为 -1000,在oom killer的情况下也免杀。LMK默认只管理oom_score_adj大于等于0的进程,所以只能杀死apk进程。LMK的优点是,1.它在系统内存开始紧张时就开始杀进程,而不是拖到最后一刻一点内存都没有了才去杀进程,2.安卓framework对apk的运行状态很了解,知道哪个进程重要不重要,哪个进程处于什么状态,能更针对性的选择杀哪些进程。LMK和OOM Killer 共同构成了系统内存不足的两道防线,LMK在前,内存有些不足时就杀进程,OOM killer在后,作为最后一道屏障,作最后的努力去回收内存。6.总结
Linux内存管理是一门庞大的学问,内存回收作为其中的一部分也是十分复杂的,我们今天给大家大概介绍了内核的内存回收概览,并详细的介绍了OOM Killer机制,也算是抛砖引玉让大家对内存回收有个初步的认识。另外如果你在工作中遇到你的进程莫名其妙挂掉了,如果你能在内核log中找到OOM Killer的log的话(搜索 out of memory 关键字并过滤你的进程名),那么你就可以快速的断定你的是因为系统内存不足了,而且你的进程占用物理内存最多,所以被杀了,此时你就有很大的理由怀疑自己的进程内存泄漏了,就可以开始进行内存相关问题的排查了。
致谢
非常感谢华章图书赠送的《深度探索Linux系统虚拟化原理与实现》,书写的很不错,有兴趣的同学可以购买学习一下。

参考文献:
linux/Documentation/vm/overcommit-accounting.rst
https://lwn.net/Articles/317814/
https://lwn.net/Articles/359998/
https://lwn.net/Articles/785709/
https://lwn.net/Articles/668126/
往期精华文章:【精华】Linux阅码场原创精华文章汇总
阅码场付费会员专业交流群
会员招募:各专业群会员费为88元/季度,权益包含群内提问,线下活动8折,全年不定期群技术分享(普通用户直播免费,分享后每次点播价为19元/次),有意加入请私信客服小月(小月微信号:linuxer2016)
专业群介绍:
本群定位内核性能与稳定性技术交流,覆盖云/网/车/机/芯领域资深内核专家,由阅码场资深讲师彭伟林主持。
甄建勇-性能优化与体系结构
本群定位Perf、cache和CPU架构技术交流,覆盖云/网/车/机/芯领域资深用户,由阅码场资深讲师甄建勇主持。
李春良-Xenomai与实时优化
本群定位Xenomai与实时优化技术交流,覆盖云/网/车/机/芯领域资深用户,由阅码场资深讲师李春良和彭伟林共同主持。
周贺贺-Tee和ARM架构
本群定位Tee和ARM架构技术交流,覆盖云/网/车/机/芯领域资深用户,由阅码场资深讲师周贺贺主持。
谢欢-Linux tracers
本群定位Linux tracers技术交流,覆盖云/网/车/机/芯领域资深用户,由阅码场资深讲师谢欢主持。
