

击上方“一口Linux”,选择“置顶/星标公众号”

进程是处于执行期的程序以及它所管理的资源(如打开的文件、挂起的信号、进程状态、地址空间等等)的总称。注意,程序并不是进程,实际上两个或多个进程不仅有可能执行同一程序,而且还有可能共享地址空间等资源。
Linux内核通过一个被称为进程描述符的task_struct结构体来管理进程,这个结构体包含了一个进程所需的所有信息。它定义在include/linux/sched.h文件中。
谈到task_struct结构体,可以说她是linux内核源码中最复杂的一个结构体了,成员之多,占用内存之大。
鉴于她的复杂,我们不能简单的亵渎,而是要深入“窥探”.
下面来慢慢介绍这些复杂成员
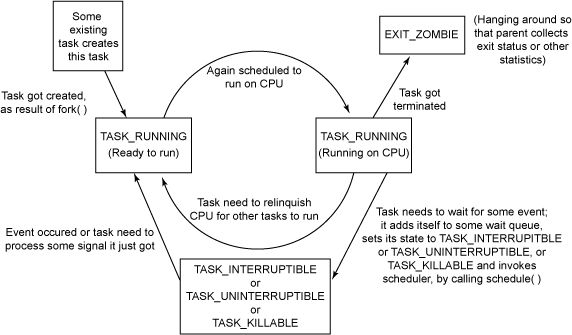
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
state成员的可能取值如下
/*
* Task state bitmask. NOTE! These bits are also
* encoded in fs/proc/array.c: get_task_state().
*
* We have two separate sets of flags: task->state
* is about runnability, while task->exit_state are
* about the task exiting. Confusing, but this way
* modifying one set can't modify the other one by
* mistake.
*/
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define __TASK_STOPPED 4
#define __TASK_TRACED 8
/* in tsk->exit_state */
#define EXIT_DEAD 16
#define EXIT_ZOMBIE 32
#define EXIT_TRACE (EXIT_ZOMBIE | EXIT_DEAD)
/* in tsk->state again */
#define TASK_DEAD 64
#define TASK_WAKEKILL 128 /** wake on signals that are deadly **/
#define TASK_WAKING 256
#define TASK_PARKED 512
#define TASK_NOLOAD 1024
#define TASK_STATE_MAX 2048
/* Convenience macros for the sake of set_task_state */
#define TASK_KILLABLE (TASK_WAKEKILL | TASK_UNINTERRUPTIBLE)
#define TASK_STOPPED (TASK_WAKEKILL | __TASK_STOPPED)
#define TASK_TRACED (TASK_WAKEKILL | __TASK_TRACED)
state域能够取5个互为排斥的值(通俗一点就是这五个值任意两个不能一起使用,只能单独使用)。系统中的每个进程都必然处于以上所列进程状态中的一种。

其实还有两个附加的进程状态既可以被添加到state域中,又可以被添加到exit_state域中。只有当进程终止的时候,才会达到这两种状态.
/* task state */
int exit_state;
int exit_code, exit_signal;

进程状态 TASK_UNINTERRUPTIBLE 和 TASK_INTERRUPTIBLE 都是睡眠状态。现在,我们来看看内核如何将进程置为睡眠状态。
Linux 内核提供了两种方法将进程置为睡眠状态。
将进程置为睡眠状态的普通方法是将进程状态设置为 TASK_INTERRUPTIBLE 或 TASK_UNINTERRUPTIBLE 并调用调度程序的 schedule() 函数。这样会将进程从 CPU 运行队列中移除。
如果进程处于可中断模式的睡眠状态(通过将其状态设置为 TASK_INTERRUPTIBLE),那么可以通过显式的唤醒呼叫(wakeup_process())或需要处理的信号来唤醒它。
但是,如果进程处于非可中断模式的睡眠状态(通过将其状态设置为 TASK_UNINTERRUPTIBLE),那么只能通过显式的唤醒呼叫将其唤醒。除非万不得已,否则我们建议您将进程置为可中断睡眠模式,而不是不可中断睡眠模式(比如说在设备 I/O 期间,处理信号非常困难时)。
当处于可中断睡眠模式的任务接收到信号时,它需要处理该信号(除非它已被屏弊),离开之前正在处理的任务(此处需要清除代码),并将 -EINTR 返回给用户空间。再一次,检查这些返回代码和采取适当操作的工作将由程序员完成。
因此,懒惰的程序员可能比较喜欢将进程置为不可中断模式的睡眠状态,因为信号不会唤醒这类任务。
但需要注意的一种情况是,对不可中断睡眠模式的进程的唤醒呼叫可能会由于某些原因不会发生,这会使进程无法被终止,从而最终引发问题,因为惟一的解决方法就是重启系统。一方面,您需要考虑一些细节,因为不这样做会在内核端和用户端引入 bug。另一方面,您可能会生成永远不会停止的进程(被阻塞且无法终止的进程)。
现在,我们在内核中实现了一种新的睡眠方法
Linux Kernel 2.6.25 引入了一种新的进程睡眠状态

它定义如下:
#define TASK_WAKEKILL 128 /** wake on signals that are deadly **/
/* Convenience macros for the sake of set_task_state */
#define TASK_KILLABLE (TASK_WAKEKILL | TASK_UNINTERRUPTIBLE)
#define TASK_STOPPED (TASK_WAKEKILL | __TASK_STOPPED)
#define TASK_TRACED (TASK_WAKEKILL | __TASK_TRACED)
换句话说,TASK_UNINTERRUPTIBLE + TASK_WAKEKILL = TASK_KILLABLE。
而TASK_WAKEKILL 用于在接收到致命信号时唤醒进程
新的睡眠状态允许 TASK_UNINTERRUPTIBLE 响应致命信号
进程状态的切换过程和原因大致如下图
pid_t pid;
pid_t tgid;
Unix系统通过pid来标识进程,linux把不同的pid与系统中每个进程或轻量级线程关联,而unix程序员希望同一组线程具有共同的pid,遵照这个标准linux引入线程组的概念。一个线程组所有线程与领头线程具有相同的pid,存入tgid字段,getpid()返回当前进程的tgid值而不是pid的值。
在CONFIG_BASE_SMALL配置为0的情况下,PID的取值范围是0到32767,即系统中的进程数最大为32768个。
#define PID_MAX_DEFAULT (CONFIG_BASE_SMALL ? 0x1000 : 0x8000)
在Linux系统中,一个线程组中的所有线程使用和该线程组的领头线程(该组中的第一个轻量级进程)相同的PID,并被存放在tgid成员中。只有线程组的领头线程的pid成员才会被设置为与tgid相同的值。注意,getpid()系统调用返回的是当前进程的tgid值而不是pid值。
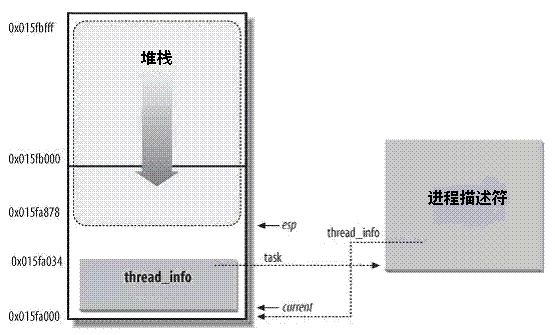
void *stack;
内核栈与线程描述符
对每个进程,Linux内核都把两个不同的数据结构紧凑的存放在一个单独为进程分配的内存区域中
一个是内核态的进程堆栈,
另一个是紧挨着进程描述符的小数据结构thread_info,叫做线程描述符。
Linux把thread_info(线程描述符)和内核态的线程堆栈存放在一起,这块区域通常是8192K(占两个页框),其实地址必须是8192的整数倍。
在
linux/arch/x86/include/asm/page_32_types.h中,
#define THREAD_SIZE_ORDER 1
#define THREAD_SIZE (PAGE_SIZE << THREAD_SIZE_ORDER)
出于效率考虑,内核让这8K空间占据连续的两个页框并让第一个页框的起始地址是213的倍数。
内核态的进程访问处于内核数据段的栈,这个栈不同于用户态的进程所用的栈。
用户态进程所用的栈,是在进程线性地址空间中;
而内核栈是当进程从用户空间进入内核空间时,特权级发生变化,需要切换堆栈,那么内核空间中使用的就是这个内核栈。因为内核控制路径使用很少的栈空间,所以只需要几千个字节的内核态堆栈。
需要注意的是,内核态堆栈仅用于内核例程,Linux内核另外为中断提供了单独的硬中断栈和软中断栈
下图中显示了在物理内存中存放两种数据结构的方式。线程描述符驻留与这个内存区的开始,而栈顶末端向下增长。下图摘自ULK3,进程内核栈与进程描述符的关系如下图:
但是较新的内核代码中,进程描述符task_struct结构中没有直接指向thread_info结构的指针,而是用一个void指针类型的成员表示,然后通过类型转换来访问thread_info结构。
相关代码在include/linux/sched.h中
#define task_thread_info(task) ((struct thread_info *)(task)->stack)
在这个图中,esp寄存器是CPU栈指针,用来存放栈顶单元的地址。在80x86系统中,栈起始于顶端,并朝着这个内存区开始的方向增长。从用户态刚切换到内核态以后,进程的内核栈总是空的。因此,esp寄存器指向这个栈的顶端。一旦数据写入堆栈,esp的值就递减。
thread_info是体系结构相关的,结构的定义在thread_info.h中

Linux内核中使用一个联合体来表示一个进程的线程描述符和内核栈:
union thread_union
{
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
获取当前在CPU上正在运行进程的thread_info
下面来说说如何通过esp栈指针来获取当前在CPU上正在运行进程的thread_info结构。
实际上,上面提到,thread_info结构和内核态堆栈是紧密结合在一起的,占据两个页框的物理内存空间。而且,这两个页框的起始起始地址是213对齐的。
早期的版本中,不需要对64位处理器的支持,所以,内核通过简单的屏蔽掉esp的低13位有效位就可以获得thread_info结构的基地址了。
我们在下面对比了,获取正在运行的进程的thread_info的实现方式

早期版本
当前的栈指针(current_stack_pointer == sp)就是esp,
THREAD_SIZE为8K,二进制的表示为0000 0000 0000 0000 0010 0000 0000 0000。
~(THREAD_SIZE-1)的结果刚好为1111 1111 1111 1111 1110 0000 0000 0000,第十三位是全为零,也就是刚好屏蔽了esp的低十三位,最终得到的是thread_info的地址。
进程最常用的是进程描述符结构task_struct而不是thread_info结构的地址。为了获取当前CPU上运行进程的task_struct结构,内核提供了current宏,由于task_struct *task在thread_info的起始位置,该宏本质上等价于current_thread_info()->task,在
include/asm-generic/current.h中定义:
#define get_current() (current_thread_info()->task)
#define current get_current()
这个定义是体系结构无关的,当然linux也为各个体系结构定义了更加方便或者快速的current
进程通过alloc_thread_info_node函数分配它的内核栈,通过free_thread_info函数释放所分配的内核栈。
# if THREAD_SIZE >= PAGE_SIZE
static struct thread_info *alloc_thread_info_node(struct task_struct *tsk,
int node)
{
struct page *page = alloc_kmem_pages_node(node, THREADINFO_GFP,
THREAD_SIZE_ORDER);
return page ? page_address(page) : NULL;
}
static inline void free_thread_info(struct thread_info *ti)
{
free_kmem_pages((unsigned long)ti, THREAD_SIZE_ORDER);
}
# else
static struct kmem_cache *thread_info_cache;
static struct thread_info *alloc_thread_info_node(struct task_struct *tsk,
int node)
{
return kmem_cache_alloc_node(thread_info_cache, THREADINFO_GFP, node);
}
static void free_thread_info(struct thread_info *ti)
{
kmem_cache_free(thread_info_cache, ti);
}
其中,THREAD_SIZE_ORDER宏的定义请查看

unsigned int flags; /* per process flags, defined below */
反应进程状态的信息,但不是运行状态,用于内核识别进程当前的状态,以备下一步操作
flags成员的可能取值如下,这些宏以PF(ProcessFlag)开头
例如
PF_FORKNOEXEC 进程刚创建,但还没执行。
PF_SUPERPRIV 超级用户特权。
PF_DUMPCORE dumped core。
PF_SIGNALED 进程被信号(signal)杀出。
PF_EXITING 进程开始关闭。
/*
* Per process flags
*/
#define PF_EXITING 0x00000004 /* getting shut down */
#define PF_EXITPIDONE 0x00000008 /* pi exit done on shut down */
#define PF_VCPU 0x00000010 /* I'm a virtual CPU */
#define PF_WQ_WORKER 0x00000020 /* I'm a workqueue worker */
#define PF_FORKNOEXEC 0x00000040 /* forked but didn't exec */
#define PF_MCE_PROCESS 0x00000080 /* process policy on mce errors */
#define PF_SUPERPRIV 0x00000100 /* used super-user privileges */
#define PF_DUMPCORE 0x00000200 /* dumped core */
#define PF_SIGNALED 0x00000400 /* killed by a signal */
#define PF_MEMALLOC 0x00000800 /* Allocating memory */
#define PF_NPROC_EXCEEDED 0x00001000 /* set_user noticed that RLIMIT_NPROC was exceeded */
#define PF_USED_MATH 0x00002000 /* if unset the fpu must be initialized before use */
#define PF_USED_ASYNC 0x00004000 /* used async_schedule*(), used by module init */
#define PF_NOFREEZE 0x00008000 /* this thread should not be frozen */
#define PF_FROZEN 0x00010000 /* frozen for system suspend */
#define PF_FSTRANS 0x00020000 /* inside a filesystem transaction */
#define PF_KSWAPD 0x00040000 /* I am kswapd */
#define PF_MEMALLOC_NOIO 0x00080000 /* Allocating memory without IO involved */
#define PF_LESS_THROTTLE 0x00100000 /* Throttle me less: I clean memory */
#define PF_KTHREAD 0x00200000 /* I am a kernel thread */
#define PF_RANDOMIZE 0x00400000 /* randomize virtual address space */
#define PF_SWAPWRITE 0x00800000 /* Allowed to write to swap */
#define PF_NO_SETAFFINITY 0x04000000 /* Userland is not allowed to meddle with cpus_allowed */
#define PF_MCE_EARLY 0x08000000 /* Early kill for mce process policy */
#define PF_MUTEX_TESTER 0x20000000 /* Thread belongs to the rt mutex tester */
#define PF_FREEZER_SKIP 0x40000000 /* Freezer should not count it as freezable */
#define PF_SUSPEND_TASK 0x80000000 /* this thread called freeze_processes and should not be frozen */
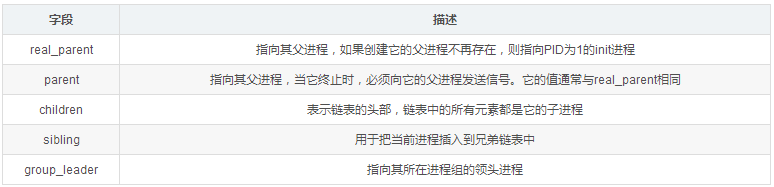
表示进程亲属关系的成员
/*
* pointers to (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->real_parent->pid)
*/
struct task_struct __rcu *real_parent; /* real parent process */
struct task_struct __rcu *parent; /* recipient of SIGCHLD, wait4() reports */
/*
* children/sibling forms the list of my natural children
*/
struct list_head children; /* list of my children */
struct list_head sibling; /* linkage in my parent's children list */
struct task_struct *group_leader; /* threadgroup leader */
在Linux系统中,所有进程之间都有着直接或间接地联系,每个进程都有其父进程,也可能有零个或多个子进程。拥有同一父进程的所有进程具有兄弟关系。
Ptrace 提供了一种父进程可以控制子进程运行,并可以检查和改变它的核心image。
它主要用于实现断点调试。一个被跟踪的进程运行中,直到发生一个信号。则进程被中止,并且通知其父进程。在进程中止的状态下,进程的内存空间可以被读写。父进程还可以使子进程继续执行,并选择是否是否忽略引起中止的信号。
unsigned int ptrace;
ptraced is the list of tasks this task is using ptrace on.
* This includes both natural children and PTRACE_ATTACH targets.
* p->ptrace_entry is p's link on the p->parent->ptraced list.
*/
struct list_head ptraced;
struct list_head ptrace_entry;
unsigned long ptrace_message;
siginfo_t *last_siginfo; /* For ptrace use. */
成员ptrace被设置为0时表示不需要被跟踪,它的可能取值如下:
/*
* Ptrace flags
*
* The owner ship rules for task->ptrace which holds the ptrace
* flags is simple. When a task is running it owns it's task->ptrace
* flags. When the a task is stopped the ptracer owns task->ptrace.
*/
#define PT_SEIZED 0x00010000 /* SEIZE used, enable new behavior */
#define PT_PTRACED 0x00000001
#define PT_DTRACE 0x00000002 /* delayed trace (used on m68k, i386) */
#define PT_PTRACE_CAP 0x00000004 /* ptracer can follow suid-exec */
#define PT_OPT_FLAG_SHIFT 3
/* PT_TRACE_* event enable flags */
#define PT_EVENT_FLAG(event) (1 << (PT_OPT_FLAG_SHIFT + (event)))
#define PT_TRACESYSGOOD PT_EVENT_FLAG(0)
#define PT_TRACE_FORK PT_EVENT_FLAG(PTRACE_EVENT_FORK)
#define PT_TRACE_VFORK PT_EVENT_FLAG(PTRACE_EVENT_VFORK)
#define PT_TRACE_CLONE PT_EVENT_FLAG(PTRACE_EVENT_CLONE)
#define PT_TRACE_EXEC PT_EVENT_FLAG(PTRACE_EVENT_EXEC)
#define PT_TRACE_VFORK_DONE PT_EVENT_FLAG(PTRACE_EVENT_VFORK_DONE)
#define PT_TRACE_EXIT PT_EVENT_FLAG(PTRACE_EVENT_EXIT)
#define PT_TRACE_SECCOMP PT_EVENT_FLAG(PTRACE_EVENT_SECCOMP)
#define PT_EXITKILL (PTRACE_O_EXITKILL << PT_OPT_FLAG_SHIFT)
#define PT_SUSPEND_SECCOMP (PTRACE_O_SUSPEND_SECCOMP << PT_OPT_FLAG_SHIFT)
/* single stepping state bits (used on ARM and PA-RISC) */
#define PT_SINGLESTEP_BIT 31
#define PT_SINGLESTEP (1<
#define PT_BLOCKSTEP_BIT 30
#define PT_BLOCKSTEP (1<
Performance Event
Performance Event是一款随 Linux 内核代码一同发布和维护的性能诊断工具。这些成员用于帮助PerformanceEvent分析进程的性能问题。
#ifdef CONFIG_PERF_EVENTS
struct perf_event_context *perf_event_ctxp[perf_nr_task_contexts];
struct mutex perf_event_mutex;
struct list_head perf_event_list;
#endif
优先级
int prio, static_prio, normal_prio;
unsigned int rt_priority;

实时优先级范围是0到MAX_RT_PRIO-1(即99),而普通进程的静态优先级范围是从MAX_RT_PRIO到MAX_PRIO-1(即100到139)。值越大静态优先级越低。
/* http://lxr.free-electrons.com/source/include/linux/sched/prio.h#L21 */
#define MAX_USER_RT_PRIO 100
#define MAX_RT_PRIO MAX_USER_RT_PRIO
/* http://lxr.free-electrons.com/source/include/linux/sched/prio.h#L24 */
#define MAX_PRIO (MAX_RT_PRIO + 40)
#define DEFAULT_PRIO (MAX_RT_PRIO + 20)
/* http://lxr.free-electrons.com/source/include/linux/sched.h?v=4.5#L1426 */
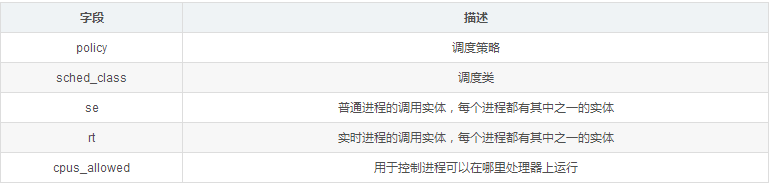
unsigned int policy;
/* http://lxr.free-electrons.com/source/include/linux/sched.h?v=4.5#L1409 */
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
cpumask_t cpus_allowed;
policy表示进程的调度策略,目前主要有以下五种:
/*
* Scheduling policies
*/
#define SCHED_NORMAL 0
#define SCHED_FIFO 1
#define SCHED_RR 2
#define SCHED_BATCH 3
/* SCHED_ISO: reserved but not implemented yet */
#define SCHED_IDLE 5
#define SCHED_DEADLINE 6

sched_class结构体表示调度类,目前内核中有实现以下四种:
extern const struct sched_class stop_sched_class;
extern const struct sched_class dl_sched_class;
extern const struct sched_class rt_sched_class;
extern const struct sched_class fair_sched_class;
extern const struct sched_class idle_sched_class;
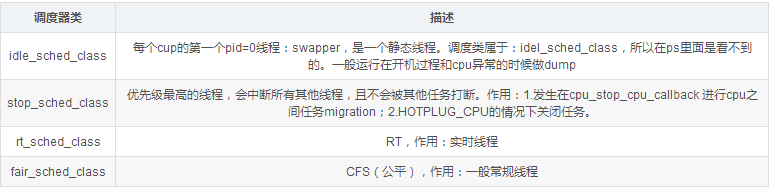
目前系統中,Scheduling Class的优先级顺序为StopTask > RealTime > Fair > IdleTask
开发者可以根据己的设计需求,來把所属的Task配置到不同的Scheduling Class中.
/* http://lxr.free-electrons.com/source/include/linux/sched.h?V=4.5#L1453 */
struct mm_struct *mm, *active_mm;
/* per-thread vma caching */
u32 vmacache_seqnum;
struct vm_area_struct *vmacache[VMACACHE_SIZE];
#if defined(SPLIT_RSS_COUNTING)
struct task_rss_stat rss_stat;
#endif
/* http://lxr.free-electrons.com/source/include/linux/sched.h?V=4.5#L1484 */
#ifdef CONFIG_COMPAT_BRK
unsigned brk_randomized:1;
#endif

因此如果当前内核线程被调度之前运行的也是另外一个内核线程时候,那么其mm和avtive_mm都是NULL
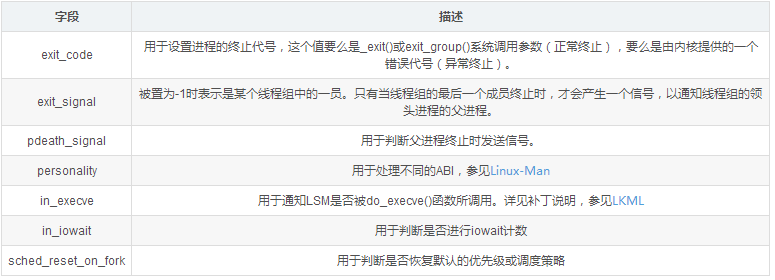
int exit_code, exit_signal;
int pdeath_signal; /* The signal sent when the parent dies */
unsigned long jobctl; /* JOBCTL_*, siglock protected */
/* Used for emulating ABI behavior of previous Linux versions */
unsigned int personality;
/* scheduler bits, serialized by scheduler locks */
unsigned sched_reset_on_fork:1;
unsigned sched_contributes_to_load:1;
unsigned sched_migrated:1;
unsigned :0; /* force alignment to the next boundary */
/* unserialized, strictly 'current' */
unsigned in_execve:1; /* bit to tell LSMs we're in execve */
unsigned in_iowait:1;
cputime_t utime, stime, utimescaled, stimescaled;
cputime_t gtime;
struct prev_cputime prev_cputime;
#ifdef CONFIG_VIRT_CPU_ACCOUNTING_GEN
seqcount_t vtime_seqcount;
unsigned long long vtime_snap;
enum {
/* Task is sleeping or running in a CPU with VTIME inactive */
VTIME_INACTIVE = 0,
/* Task runs in userspace in a CPU with VTIME active */
VTIME_USER,
/* Task runs in kernelspace in a CPU with VTIME active */
VTIME_SYS,
} vtime_snap_whence;
#endif
unsigned long nvcsw, nivcsw; /* context switch counts */
u64 start_time; /* monotonic time in nsec */
u64 real_start_time; /* boot based time in nsec */
/* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */
unsigned long min_flt, maj_flt;
struct task_cputime cputime_expires;
struct list_head cpu_timers[3];
/* process credentials */
const struct cred __rcu *real_cred; /* objective and real subjective task
* credentials (COW) */
const struct cred __rcu *cred; /* effective (overridable) subjective task
* credentials (COW) */
char comm[TASK_COMM_LEN]; /* executable name excluding path
- access with [gs]et_task_comm (which lock
it with task_lock())
- initialized normally by setup_new_exec */
/* file system info */
struct nameidata *nameidata;
#ifdef CONFIG_SYSVIPC
/* ipc stuff */
struct sysv_sem sysvsem;
struct sysv_shm sysvshm;
#endif
#ifdef CONFIG_DETECT_HUNG_TASK
/* hung task detection */
unsigned long last_switch_count;
#endif

/* signal handlers */
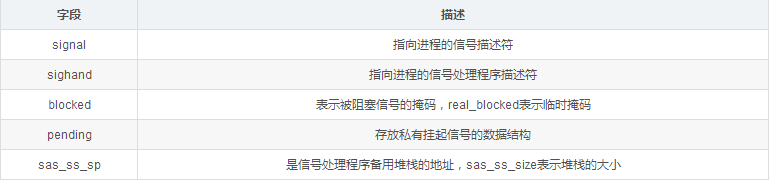
struct signal_struct *signal;
struct sighand_struct *sighand;
1583
sigset_t blocked, real_blocked;
sigset_t saved_sigmask; /* restored if set_restore_sigmask() was used */
struct sigpending pending;
1587
unsigned long sas_ss_sp;
size_t sas_ss_size;
(1)、用于保护资源分配或释放的自旋锁
/* Protection of (de-)allocation: mm, files, fs, tty, keyrings, mems_allowed,
* mempolicy */
spinlock_t alloc_lock;
(2)、进程描述符使用计数,被置为2时,表示进程描述符正在被使用而且其相应的进程处于活动状态
atomic_t usage;
(3)、用于表示获取大内核锁的次数,如果进程未获得过锁,则置为-1。
int lock_depth; /* BKL lock depth */
(4)、在SMP上帮助实现无加锁的进程切换(unlocked context switches)
#ifdef CONFIG_SMP
#ifdef __ARCH_WANT_UNLOCKED_CTXSW
int oncpu;
#endif
#endif
(5)、preempt_notifier结构体链表
#ifdef CONFIG_PREEMPT_NOTIFIERS
/* list of struct preempt_notifier: */
struct hlist_head preempt_notifiers;
#endif
(6)、FPU使用计数
unsigned char fpu_counter;
(7)、 blktrace是一个针对Linux内核中块设备I/O层的跟踪工具。
#ifdef CONFIG_BLK_DEV_IO_TRACE
unsigned int btrace_seq;
#endif
(8)、RCU同步原语
#ifdef CONFIG_PREEMPT_RCU
int rcu_read_lock_nesting;
char rcu_read_unlock_special;
struct list_head rcu_node_entry;
#endif /* #ifdef CONFIG_PREEMPT_RCU */
#ifdef CONFIG_TREE_PREEMPT_RCU
struct rcu_node *rcu_blocked_node;
#endif /* #ifdef CONFIG_TREE_PREEMPT_RCU */
#ifdef CONFIG_RCU_BOOST
struct rt_mutex *rcu_boost_mutex;
#endif /* #ifdef CONFIG_RCU_BOOST */
(9)、用于调度器统计进程的运行信息
#if defined(CONFIG_SCHEDSTATS) || defined(CONFIG_TASK_DELAY_ACCT)
struct sched_info sched_info;
#endif
(10)、用于构建进程链表
struct list_head tasks;
(11)、to limit pushing to one attempt
#ifdef CONFIG_SMP
struct plist_node pushable_tasks;
#endif
(12)、防止内核堆栈溢出
#ifdef CONFIG_CC_STACKPROTECTOR
/* Canary value for the -fstack-protector gcc feature */
unsigned long stack_canary;
#endif
在GCC编译内核时,需要加上-fstack-protector选项。
(13)、PID散列表和链表
/* PID/PID hash table linkage. */
struct pid_link pids[PIDTYPE_MAX];
struct list_head thread_group; //线程组中所有进程的链表
(14)、do_fork函数
struct completion *vfork_done; /* for vfork() */
int __user *set_child_tid; /* CLONE_CHILD_SETTID */
int __user *clear_child_tid; /* CLONE_CHILD_CLEARTID */
在执行do_fork()时,如果给定特别标志,则vfork_done会指向一个特殊地址。
如果copy_process函数的clone_flags参数的值被置为CLONE_CHILD_SETTID或CLONE_CHILD_CLEARTID,则会把child_tidptr参数的值分别复制到set_child_tid和clear_child_tid成员。这些标志说明必须改变子进程用户态地址空间的child_tidptr所指向的变量的值。
(15)、缺页统计
/* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */
unsigned long min_flt, maj_flt;
(16)、进程权能
const struct cred __rcu *real_cred; /* objective and real subjective task
* credentials (COW) */
const struct cred __rcu *cred; /* effective (overridable) subjective task
* credentials (COW) */
struct cred *replacement_session_keyring; /* for KEYCTL_SESSION_TO_PARENT */
(17)、相应的程序名
char comm[TASK_COMM_LEN];
(18)、文件
/* file system info */
int link_count, total_link_count;
/* filesystem information */
struct fs_struct *fs;
/* open file information */
struct files_struct *files;
fs用来表示进程与文件系统的联系,包括当前目录和根目录。
files表示进程当前打开的文件。
(19)、进程通信(SYSVIPC)
#ifdef CONFIG_SYSVIPC
/* ipc stuff */
struct sysv_sem sysvsem;
#endif
(20)、处理器特有数据
/* CPU-specific state of this task */
struct thread_struct thread;
(21)、命名空间
/* namespaces */
struct nsproxy *nsproxy;
(22)、进程审计
struct audit_context *audit_context;
#ifdef CONFIG_AUDITSYSCALL
uid_t loginuid;
unsigned int sessionid;
#endif
(23)、secure computing
seccomp_t seccomp;
(24)、用于copy_process函数使用CLONE_PARENT 标记时
/* Thread group tracking */
u32 parent_exec_id;
u32 self_exec_id;
(25)、中断
#ifdef CONFIG_GENERIC_HARDIRQS
/* IRQ handler threads */
struct irqaction *irqaction;
#endif
#ifdef CONFIG_TRACE_IRQFLAGS
unsigned int irq_events;
unsigned long hardirq_enable_ip;
unsigned long hardirq_disable_ip;
unsigned int hardirq_enable_event;
unsigned int hardirq_disable_event;
int hardirqs_enabled;
int hardirq_context;
unsigned long softirq_disable_ip;
unsigned long softirq_enable_ip;
unsigned int softirq_disable_event;
unsigned int softirq_enable_event;
int softirqs_enabled;
int softirq_context;
#endif
(26)、task_rq_lock函数所使用的锁
/* Protection of the PI data structures: */
raw_spinlock_t pi_lock;
(27)、基于PI协议的等待互斥锁,其中PI指的是priority inheritance(优先级继承)
#ifdef CONFIG_RT_MUTEXES
/* PI waiters blocked on a rt_mutex held by this task */
struct plist_head pi_waiters;
/* Deadlock detection and priority inheritance handling */
struct rt_mutex_waiter *pi_blocked_on;
#endif
(28)、死锁检测
#ifdef CONFIG_DEBUG_MUTEXES
/* mutex deadlock detection */
struct mutex_waiter *blocked_on;
#endif
(29)、JFS文件系统
/* journalling filesystem info */
void *journal_info;
(30)、块设备链表
/* stacked block device info */
struct bio_list *bio_list;
(31)、内存回收
struct reclaim_state *reclaim_state;
(32)、存放块设备I/O数据流量信息
struct backing_dev_info *backing_dev_info;
(33)、I/O调度器所使用的信息
struct io_context *io_context;
(34)、记录进程的I/O计数
struct task_io_accounting ioac;
if defined(CONFIG_TASK_XACCT)
u64 acct_rss_mem1; /* accumulated rss usage */
u64 acct_vm_mem1; /* accumulated virtual memory usage */
cputime_t acct_timexpd; /* stime + utime since last update */
endif
在Ubuntu 11.04上,执行cat获得进程1的I/O计数如下:
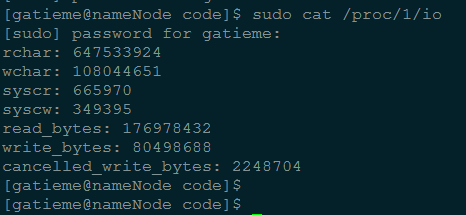
输出的数据项刚好是task_io_accounting结构体的所有成员。
(35)、CPUSET功能
#ifdef CONFIG_CPUSETS
nodemask_t mems_allowed; /* Protected by alloc_lock */
int mems_allowed_change_disable;
int cpuset_mem_spread_rotor;
int cpuset_slab_spread_rotor;
#endif
(36)、Control Groups
#ifdef CONFIG_CGROUPS
/* Control Group info protected by css_set_lock */
struct css_set __rcu *cgroups;
/* cg_list protected by css_set_lock and tsk->alloc_lock */
struct list_head cg_list;
#endif
#ifdef CONFIG_CGROUP_MEM_RES_CTLR /* memcg uses this to do batch job */
struct memcg_batch_info {
int do_batch; /* incremented when batch uncharge started */
struct mem_cgroup *memcg; /* target memcg of uncharge */
unsigned long bytes; /* uncharged usage */
unsigned long memsw_bytes; /* uncharged mem+swap usage */
} memcg_batch;
#endif
(37)、futex同步机制
#ifdef CONFIG_FUTEX
struct robust_list_head __user *robust_list;
#ifdef CONFIG_COMPAT
struct compat_robust_list_head __user *compat_robust_list;
#endif
struct list_head pi_state_list;
struct futex_pi_state *pi_state_cache;
#endif
(38)、非一致内存访问(NUMA Non-Uniform Memory Access)
#ifdef CONFIG_NUMA
struct mempolicy *mempolicy; /* Protected by alloc_lock */
short il_next;
#endif
(39)、文件系统互斥资源
atomic_t fs_excl; /* holding fs exclusive resources */
(40)、RCU链表
struct rcu_head rcu;
(41)、管道
struct pipe_inode_info *splice_pipe;
(42)、延迟计数
#ifdef CONFIG_TASK_DELAY_ACCT
struct task_delay_info *delays;
#endif
(43)、fault injection
#ifdef CONFIG_FAULT_INJECTION
int make_it_fail;
#endif
(44)、FLoating proportions
struct prop_local_single dirties;
(45)、Infrastructure for displayinglatency
#ifdef CONFIG_LATENCYTOP
int latency_record_count;
struct latency_record latency_record[LT_SAVECOUNT];
#endif
(46)、time slack values,常用于poll和select函数
unsigned long timer_slack_ns;
unsigned long default_timer_slack_ns;
(48)、socket控制消息(control message)
struct list_head *scm_work_list;
(47)、ftrace跟踪器
#ifdef CONFIG_FUNCTION_GRAPH_TRACER
/* Index of current stored address in ret_stack */
int curr_ret_stack;
/* Stack of return addresses for return function tracing */
struct ftrace_ret_stack *ret_stack;
/* time stamp for last schedule */
unsigned long long ftrace_timestamp;
/*
* Number of functions that haven't been traced
* because of depth overrun.
*/
atomic_t trace_overrun;
/* Pause for the tracing */
atomic_t tracing_graph_pause;
#endif
#ifdef CONFIG_TRACING
/* state flags for use by tracers */
unsigned long trace;
/* bitmask of trace recursion */
unsigned long trace_recursion;
#endif /* CONFIG_TRACING */
end
一口Linux
关注,回复【1024】海量Linux资料赠送
精彩文章合集
文章推荐
点击“阅读原文”查看更多分享,欢迎点分享、收藏、点赞、在看
