


就像人类用眼睛看东西一样,自动驾驶汽车使用传感器收集信息。这些传感器收集了大量数据,因此需要高效率的车载数据处理,以便车辆对道路情况做出快速反应。这种能力对自动驾驶汽车的安全以及虚拟驾驶员的智能化水平至关重要。
由于需要冗余和多样化的传感器和计算系统,因此处理流水线的设计和优化存在一定的难度。本文将介绍小马智行(Pony.ai)车载传感器数据处理流水线的发展历程。
小马智行的传感器配置包含多个摄像头、激光雷达和雷达。上游模块负责同步传感器,将数据封装成消息并发送到下游模块,后者根据这些数据消息完成物体分割、分类和检测等。
每种类型的传感器数据可能被多个模块使用,并且用户的算法可能是传统的或基于神经网络的。
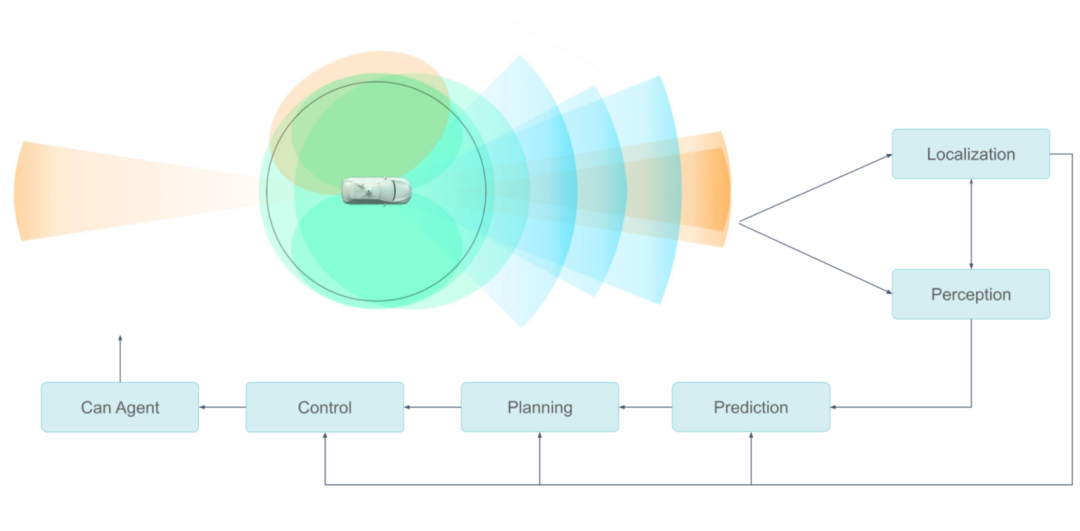
小马智行自动驾驶传感系统功能
乘员安全是第一要务,因此整个流水线必须以最高效率运行。而传感器数据处理系统对安全的影响主要体现在两个方面。
第一,自动驾驶系统处理传感器数据的速度是安全的决定性因素之一。如果感知和定位算法收到的传感器数据出现数百毫秒的延迟,那么车辆就无法及时做出决策。
第二,整个硬件/软件系统必须是可靠的,才能实现长期保障。消费者绝不会愿意购买或乘坐在制造几个月后就出现问题的自动驾驶汽车,这一点在量产阶段至关重要。
高效处理传感器数据
考虑到传感器、 GPU 架构和 GPU 内存,需要采取较为全面的方法应对传感器处理流水线中的瓶颈。
从传感器到 GPU
在小马智行成立之初,传感器配置由现成组件构成。小马智行使用基于 USB 和以太网的摄像头,并将其直接连接到车载电脑上, CPU 负责从 USB /以太网接口读取数据。
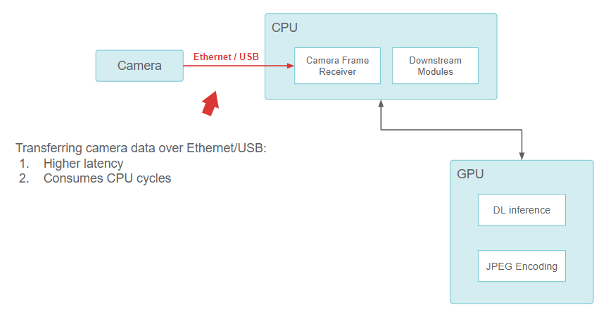
从摄像头到 CPU 再到 GPU 的流水线功能
虽然这种方法有效,但在设计上存在一个基本问题。USB 和以太网摄像头接口(GigE-camera)会消耗 CPU。随着越来越多高分辨率摄像头的加入, CPU 很快就会不堪重负,无法执行所有输入输出(I/O)操作。这种设计很难在保持足够低的延迟的情况下进行扩展。
为了解决这个问题,小马智行为摄像头和激光雷达增加了基于 FPGA 的传感器网关。
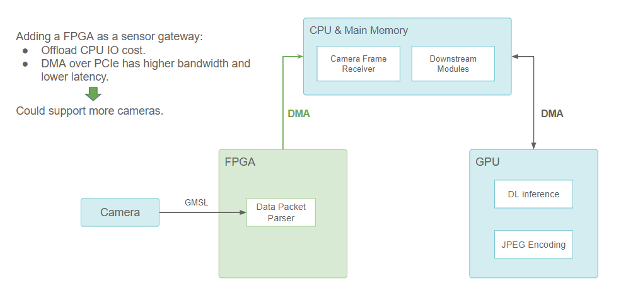
担任传感器网关的 FPGA (传感器部分使用摄像头示范)
FPGA 通过处理摄像头触发和同步逻辑来实现更好的传感器融合。当摄像头数据包准备就绪时,就会触发 DMA 传输,通过 PCIe 总线将数据从 FPGA 复制到主存储器。DMA 引擎在 FPGA 上执行此操作,不会占用 CPU。它不仅解放了 CPU 的 I/O 资源,而且还减少了数据传输延迟,使传感器的配置更具有可扩展性。
由于许多在 GPU 上运行的神经网络模型都需要使用摄像头数据,在通过 DMA 将数据从 FPGA 传输到 CPU 之后,仍须将其复制到 GPU 内存。因此在某处需要进行 CUDA HostToDevice 内存拷贝, FHD 分辨率的图像每帧的用时需要约 1.5ms。
但小马智行想进一步减少延迟。理想情况下,应直接将摄像头数据传输到 GPU 内存,而不需要通过 CPU。
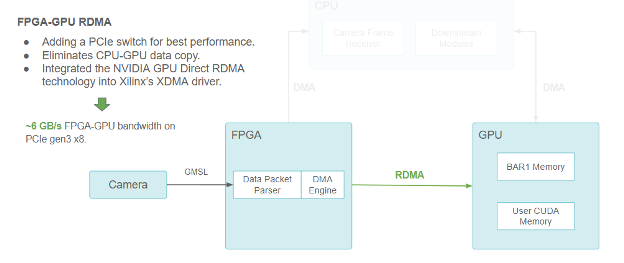
摄像头/FPGA/CPU/GPU流水线功能块图,使用 RDMA 在 FPGA 和 GPU 之间进行通信
GPU Direct RDMA 使小马智行能够通过 PCIe BAR (定义 PCIe 地址空间线性窗口的基地址寄存器)预分配 CUDA 内存供 PCIe peers 访问。
它还为第三方设备驱动程序提供了一系列内核空间 API 以获得 GPU 内存物理地址。这些 API 方便了第三方设备的 DMA 引擎直接向 GPU 内存发送和读取数据,就像是在向主内存发送和读取数据一样。
GPU Direct RDMA 通过消除 CPU 到 GPU 的复制来减少延迟,并在 PCIe Gen3 x8 下实现约 6 GB/s 的最高带宽(理论极限值为 8 GB/s)。
跨 GPU 扩展
由于计算工作负载的增加,小马智行需要不止一个 GPU。随着越来越多的 GPU 加入到系统中,GPU之间的通信也可能成为瓶颈。经中转缓冲区通过 CPU 会增加 CPU 成本,并限制整体带宽。
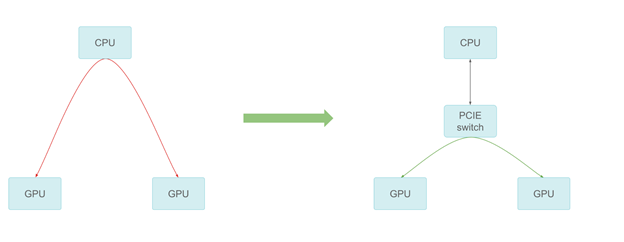
通过 PCIe 交换机进行 GPU-GPU 通信
小马智行添加了 PCIe 开关提供最好的对等传输性能。在测量中,对等通信可以达到 PCIe 速度上限,提高了跨多个 GPU 的扩展性。
将计算转移到专用硬件
小马智行还将以前在 CUDA 核上运行的任务转移到专用硬件上,以加速传感器数据处理。
例如,当把 FHD 摄像头图像编码成 JPEG 字符串时, NvJPEG 库在 RTX5000 GPU 的单个 CPU 线程上需要约 4 毫秒。NvJPEG 可能会消耗 CPU 和 GPU 资源,这是因为它的一些阶段(比如 Huffman 编码)可能完全是在 CPU 上运行的。
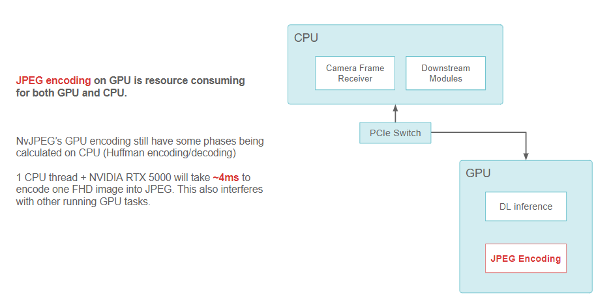
使用 GPU 上的 NvJPEG 库进行 JPEG 编码的数据流功能块图
小马智行在车辆上采用了 NVIDIA 视频编解码器,以减轻 CPU 和 GPU ( CUDA 部分)进行图像编码和解码的负担。此编解码器在 GPU 的专用部分使用编码器。它属于 GPU 的一部分,但不会与用于运行内核和深度学习模型的其他 CUDA 资源相冲突。
小马智行也一直在使用 NVIDIA GPU 上的专用硬件视频编码器将图像压缩格式从 JPEG 迁移到 HEVC(H.265)。这实现了编码速度的提高,并为其他任务释放了 CPU 和 GPU 资源。
在不影响 CUDA 性能的情况下,在 GPU 上对 FHD 图像进行完全编码需要 3 毫秒。该性能在纯 I 帧模式下测量,可确保各帧之间质量和压缩伪影的一致性。

避免消耗 CUDA 核或 CPU 的 HEVC 编码数据流功能块图
NVIDIA 视频编解码器在 GPU 芯片的专用分区中使用编码器,不会消耗 CUDA 核或 CPU。NVENC 支持 H264/H265。将 FHD 图像编码为 HEVC 需要约 3ms,因此可以释放 GPU 和 CPU 去处理其他任务。小马智行使用纯 I 帧模式,确保每帧都有相同的质量和相同类型的伪影。
GPU 上的数据流
另一个关键是将摄像头帧作为信息发送到下游模块的效率。
小马智行使用谷歌的 ProtoBuf 来定义消息。以 CameraFrame 信息为例,摄像头规格和属性是该消息中的基本数据类型。由于 ProtoBuf 的限制,真正的有效载荷——摄像头数据必须被定义为主系统内存中的字节。
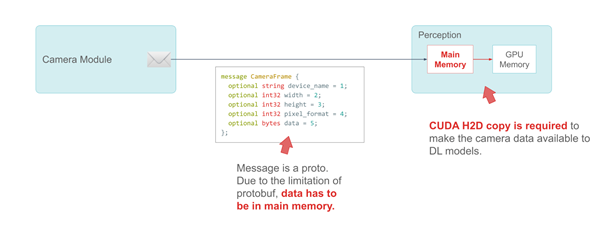
CameraFrame 消息示例
以下代码示例中的消息是一个原型。由于 protobuf 的限制, data 这一成员必须在主内存中。
message CameraFrame {
optional string device_name = 1;
optional int32 width = 2;
optional int32 height = 3;
optional int32 pixel_format = 4;
optional bytes data = 5;
};
小马智行使用发布-订阅模式,通过模块间的零拷贝消息传递来共享信息。CameraFrame 信息的许多用户模块使用摄像头数据进行深度学习推理。
在最初的设计中,当此类模块收到信息时,它不得不调用 CUDA 的 HostToDevice 拷贝,在推理前将摄像头数据传输到 GPU 上。
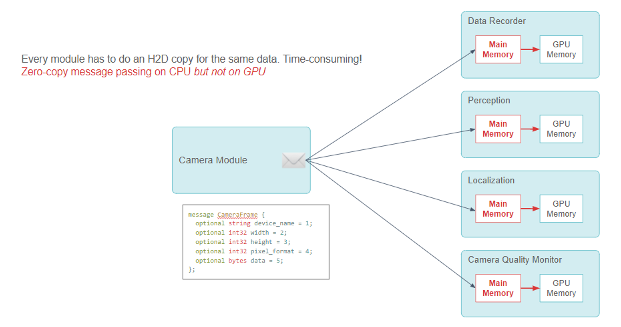
发布-订阅模型功能:摄像头模块向多个用户模块发送 CameraFrame 信息。每个用户模块需要进行 CPU 到 GPU 的内存拷贝。
每个模块都必须进行 CUDA HostToDevice 拷贝,这项工作既多余又消耗资源。虽然零拷贝消息传递框架在 CPU 上运行良好,但它需要进行大量 CPU-GPU 数据拷贝。
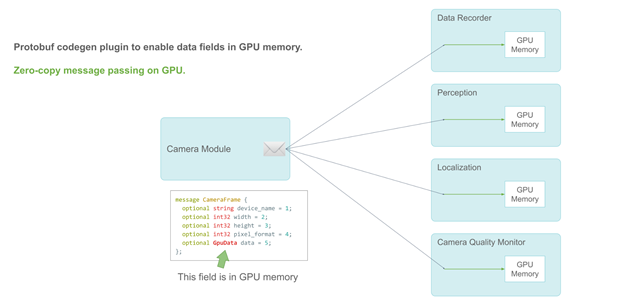
支持 GPU 的零拷贝发布-订阅信息传递
小马智行通过 protobuf 的插件 API 将新的数据类型—— GpuData 字段添加到 protobuf 代码生成器中,从而解决了这个问题。如同 CPU 内存 bytes 字段, GpuData 支持标准 resize 操作。但它的物理数据存储在 GPU 上。
当用户模块收到消息时,他们可以检索能够直接使用的 GPU 数据指针。因此,小马智行在整个流水线上实现了完全的零拷贝。
改进 GPU 内存分配
当我们调用 GpuData proto 的 resize 操作时,它会调用 CUDA 中的 cudaMalloc 参数。当 GpuData proto 信息被销毁时,它会调用 cudaFree。
这两个 API 操作的成本并不低,因为它们必须修改 GPU 的内存映射。每次调用可能需要约 0.1ms。
由于该 proto 消息被广泛使用,而摄像头在不停地产生数据,所以小马智行应该优化 GPU proto 消息的分配与释放(alloc/free)成本。
小马智行采用了固定片段大小的 GPU 内存池来解决这个问题。这个想法很简单:维护一个预先分配的 GPU 内存池,内存池的每个片段大小匹配摄像头数据帧的大小。每次 alloc 时,就从堆栈中取出一片 GPU 内存。每次 free 时,该 GPU 内存片段就会返回到池中。通过重新使用 GPU 内存, alloc/free 时间接近于零。

仅支持固定分配大小的 GPU 内存池
如果想支持不同分辨率的摄像头该怎么办?使用这种固定大小的内存池,就必须始终分配尽量多的大小,或者初始化插槽大小不同的多个内存池。这两种情况都会降低效率。
CUDA 11.2 的新功能解决了这个问题。它正式支持 cudaMemPool,该内存池可以被预先分配并在之后用于 cudaMalloc 和 free。与之前的方法相比,这种方法适用于任何分配大小,以极小性能代价极大地提高了灵活性(每次分配约 2us)。

支持动态分配大小的 GPU 内存池
在这两种方法中,当内存池溢出时, resize 的调用会退回到传统的 cudaMalloc 和 free。
YUV 颜色空间中更干净的数据流
通过上述所有的硬件设计和系统软件架构优化,小马智行实现了高效的数据流。下一步是优化数据格式本身。
小马智行的系统曾经在 RGB 颜色空间中处理摄像头数据。但摄像头的图像信号处理(ISP)输出是在 YUV 颜色空间,在 GPU 上进行 YUV 到 RGB 的转换需要约 0.3ms。此外,一些感知组件不需要颜色信息。向它们提供 RGB 颜色像素是一种浪费。
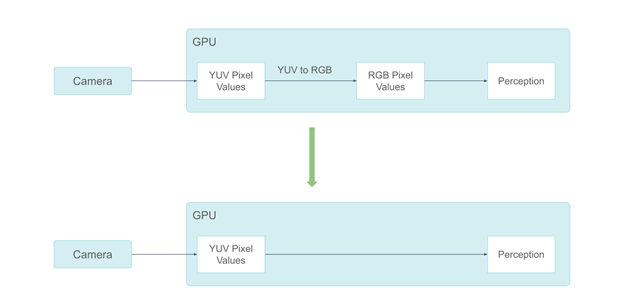
使用 YUV 格式避免颜色空间转换
鉴于这些原因,小马智行从 RGB 摄像头格式迁移到 YUV 格式。由于人类视觉对色度信息不如对亮度信息那么敏感,因此小马智行选择使用 YUV420 像素格式。
通过采用 YUV420 像素格式,小马智行减少了一半的 GPU 内存消耗。这也使小马智行能够只将 Y 通道发送到不需要色度信息的感知组件。与 RGB 相比,这减少了三分之二的 GPU 内存消耗。
在 GPU 上处理激光雷达数据
除了摄像头数据,小马智行还在 GPU 上处理激光雷达数据,而且这些数据更加稀疏。不同类型的激光雷达增加了这项处理工作的难度。在处理激光雷达数据时,小马智行采取了一些优化措施。
由于激光雷达扫描数据包含大量物理信息,小马智行使用对 GPU 友好的数组结构代替结构数组来描述点云,使 GPU 的内存访问模式变得更加凝聚而不是分散。
当必须在 CPU 和 GPU 之间交换时,将数据保存在锁定内存中以加速传输。
NVIDIA CUB 库在小马智行的的处理流水线中被广泛使用,尤其是 Scan/Select 操作。
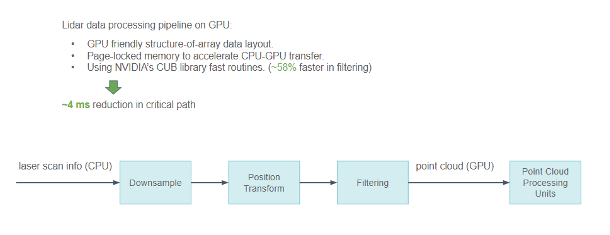
从激光雷达传感器到 GPU 上点云处理的流水线功能
通过所有这些优化,小马智行在关键路径上将整个流水线的延迟减少了约 4ms。
总时间线
凭借所有这些优化,小马智行可以使用内部的时间线可视化工具查看系统追踪。

从传感器数据到深度学习推理的总时间线
总时间线显示了小马智行目前对 GPU 的总体依赖程度。尽管这两个 GPU 在 80% 的时间内被使用,但 GPU0 和 GPU1 的工作负载并不平衡。GPU 0 在整个感知模块迭代过程中被大量使用,而 GPU1 在迭代的中间阶段有更多的空闲时间。
未来小马智行将专注于进一步提高 GPU 的效率。
生产就绪
在开发初期,小马智行通过 FPGA 轻松试验在基于硬件的传感器数据处理方面的想法。随着传感器数据处理单元变得越来越成熟,小马智行开始研究如何使用系统级芯片(SoC)提供紧凑、可靠的生产级传感器数据处理器。
经发现,车规级 NVIDIA DRIVE Orin 系统级芯片完全满足小马智行的要求。它符合 ASIL 认证,因此非常适合在量产车辆上运行。
从 FPGA 迁移到 NVIDIA DRIVE Orin
在开发初期,小马智行通过 FPGA 轻松试验在基于硬件的传感器数据处理方面的想法。
随着传感器数据处理单元变得越来越成熟,小马智行开始研究如何使用系统级芯片(SoC)提供紧凑、可靠的生产级传感器数据处理器。
小马智行发现,车规级 NVIDIA DRIVE Orin 系统级芯片完全满足要求。它符合 ASIL 认证,因此非常适合在量产车辆上运行。
小马智行将使用 NVIDIA DRIVE Orin 来处理所有传感器信号处理、同步、数据包收集以及摄像头帧编码。小马智行估计这种设计与其他架构优化结合后,将节省约 70% 的总硬件成本。
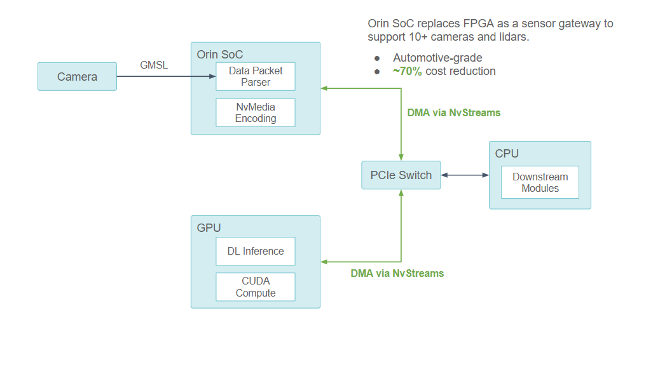
使用 NVIDIA DRIVE Orin 系统级芯片作为新的传感器网关
通过与 NVIDIA 合作,小马智行确保 Orin-CPU-GPU 组件之间的所有通信均通过 PCIe 总线进行,并通过 NvStreams 支持 DMA。
对于计算密集型深度学习工作, NVIDIA Orin 系统级芯片使用 NvStream 将传感器数据传输到独立的 GPU 上进行处理。
对于非 GPU 工作, NVIDIA Orin 系统级芯片使用 NvStream 将数据传输到主机 CPU 进行处理。
Orin 提供每秒 254 万亿次计算性能,可以处理与目前 L4 级自动驾驶汽车计算平台上所使用的 RTX5000 独立 GPU 类似的工作负载。但它需要通过多项优化,才能充分释放 NVIDIA DRIVE Orin 系统级芯片的潜力,例如:
结构性稀疏网络
DLA(深度学习加速器)核
跨多个 NVIDIA DRIVE Orin 系统级芯片的扩展
结论
小马智行传感器数据处理流水线的发展历程显示了小马智行采用系统化方法来实现高效率的数据处理流水线和更高的系统可靠性,这有助于实现更高的安全目标。这种方法背后的简单理念是:
使数据流简单而流畅。数据应该以最小化转化开销的格式被直接传输到它将被使用的地方。
专用硬件用于计算密集型任务,通用计算资源用于其他任务。
这种方法无法仅靠软件或硬件来实现,而是依靠在软件和硬件协同设计方面的共同努力。这对于满足快速增长的计算需求与生产期望至关重要。
欢迎自动驾驶领域的各位有志之士加入 NVIDIA Developer Program,点击“阅读原文”或复制链接“https://developer.nvidia.cn/login”在浏览器中打开即可注册(请在 Industry Segment 注册选项中选择 Automotive)。
长按二维码
添加 NVIDIA 自动驾驶小助手
了解更多内容


