Ftrace公开课火热报名中:Ftrace公开课:站在设计者的角度来理解ftrace(限50人)。课程第一期报名已截止且已开课,第二期报名请咨询客服(小月微信:linuxer2016)。
个人介绍:
许庆伟,云安全公司内核技术专家,主要关注Linux Kernel & 容器的Security和Performance
说明背景:
本文为主题分享《Linux Tracing System浅析 & eBPF框架开发分享》的会议整理和补充。主讲人杨润青,博士毕业于浙江大学,目前从事网络安全研究,研究方向包括高级威胁检测,攻击溯源与响应。
视频回放地址:
https://oxz.h5.xeknow.com/sl/JV1XI
PPT地址:
https://gitee.com/linuxkerneltravel/LearningLinuxKernel/tree/master/files/Linux%20Tracing%20System%20&&%20eBPF
一、讲座内容简要描述
本次讲座内容分为两部分:
1) Linux Tracing System浅析
当初学者接触到Linux平台的tracing系统时,常常被各种词语弄得晕头转向:比如 Kprobe,Tracepoint,Linux Auditing subsystem(auditd),systemtap,LTTng,perf,trace-cmd,eBPF,bpftrace,BCC等等。初学者往往会有以下疑问:这些专业词语是什么意思?它们之间有什么关系?每种tracing技术的优缺点是什么?应该选择哪种技术?为什么eBPF从中脱颖而出,近年来得到广泛关注?
本次讲座尝试从统一的视角来梳理和对比这些技术的异同点,并尝试回答这些问题。
2) eBPF开发经验分享
eBPF目前正在高速发展,很多坑和解决办法缺乏官方文档。本次讲座主要介绍主讲人在eBPF开发实践中经常遇到的问题,包括开发框架的选择,多内核版本兼容性问题,如何为低版本内核生成BTF文件,eBPF验证机制与编译器优化机制的不一致问题,eBPF在ARM架构遇到的问题等等。
二、Linux Tracing System浅析
对于Linux Tracing System尤其是目前最火的eBPF技术来说,主要是通过探针技术,实现特定事件的追踪和采样,达到增强内核行为可观测性、优化系统性能、动态监测网络和加固系统安全的目的。如下图所示,我将Linux Tracing System细分为三个维度,包括1)数据源(内核态),负责提供数据地来源;2)Tracing框架(内核态),负责对接数据源,采集解析发送数据,并对用户态提供接口;3)以及前端工具/库(用户态),对接Tracing内核框架,直接与用户交互,负责采集配置和数据分析。
下面将从这三个维度自下而上地对Linux Tracing System进行梳理和分析。
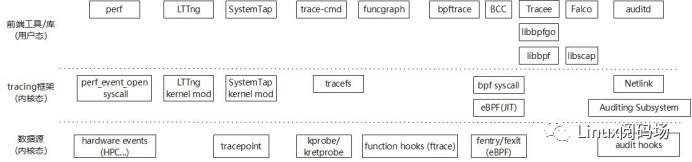
1.1. 数据源(内核态)介绍
如下图所示,从数据提供方的角度来看,数据源可以分成硬件探针、软件探针(又分为动态探针以及静态探针),也就是获取底层数据源的方式和手段。顾名思义,硬件探针技术就是通过在硬件设备上(比如芯片)插入探针,捕获硬件层次行为;而软件探针技术则是通过软件的方式插入探针,捕获软件层次的行为。这些探针技术负责提供数据,上层的Tracing工具和框架则基于这些探针技术来采集数据,并对数据进一步整理、分析、和展现给用户。

硬件探针
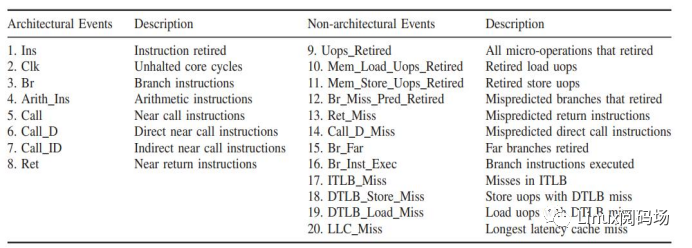
HPC: Hardware Performance Counter 是CPU硬件提供的一种常见的数据源,如下图所示,它能够监控CPU级别的事件,比如执行的 指令数,跳转指令数,Cache Miss等等,被广泛应用于性能调试(Vtune, Perf)、攻击检测等等
1) HPC事件列表
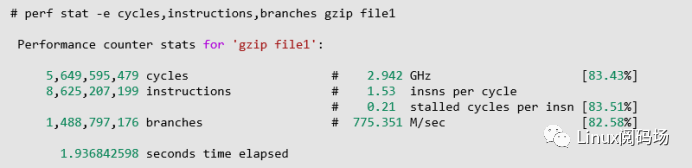
2)HPC数据案例
对于此类硬件数据,我们通常使用用户态工具perf来进行采集,下图展示了一个具体的案例。
LBR: Last Branch Record CPU硬件提供的另一种特性,它能够记录每条分支(跳转)指令的源地址和目的地址。基于LBR硬件特性,可实现调用栈信息的记录
在系统性能优化领域以及调试程序时经常使用的性能分析利器:火焰图(Flame Graph)也可以基于LBR的数据生成,使用命令perf record -F 99 -a --call-graph lbr即可得到完整直观的火焰图数据。
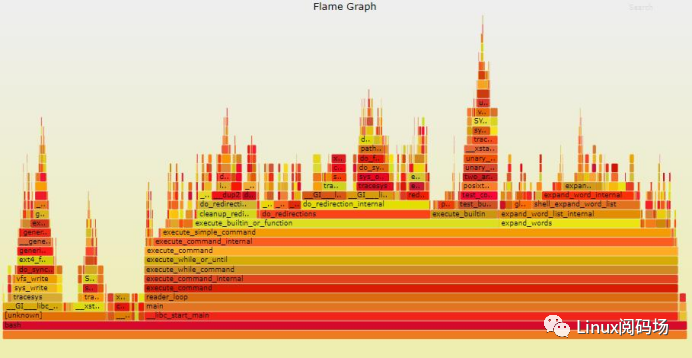
火焰图示例
软件探针(静态探针):
静态内核探针指的是在内核运行之前,在内核源代码或者二进制中插入预先设置好的钩子函数,内核运行时触发生效的探针方案。
Tracepoint: Tracepoint是一种典型的静态探针。它通过在内核源代码中插入预先定义的静态钩子函数来实现内核行为的监控。简单地来看,大家可以把Tracepoint的原理等同于调试程序时加入的printf函数。
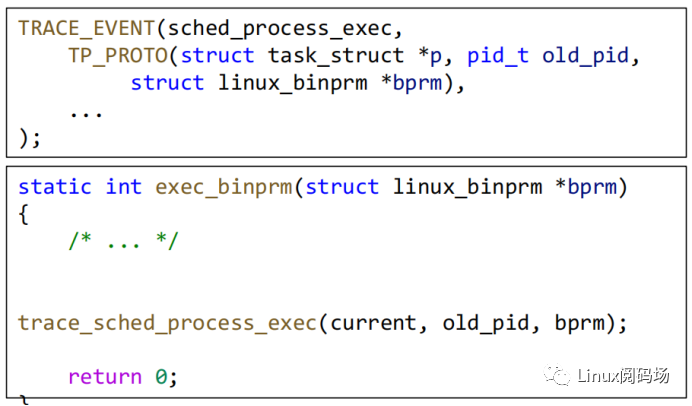
下图展示了2012年,内核引入sched_process_exec Tracepoint时的commit,可以看到,首先用TRACE_EVENT宏定义了新增Tracepoint的名字和参数等信息,然后在内核函数exec_binprm的源代码中加入了钩子函数trace_sched_process_exec。每当程序执行二进制时,都会触发exec_binprm函数,继而触发trace_sched_process_exec钩子函数。Tracing工具和框架将自定义的函数挂载到该钩子函数上,来采集程序执行行为日志。
静态探针的优点:
稳定(内核开发者会负责维护该函数的稳定性)
性能好
静态探针的缺点
需要修改内核代码来添加新的静态探针
内核支持的静态探针数量有限
软件探针(动态探针):
有了静态探针,为什么还需要动态探针呢?主要原因是静态探针都是人工添加的,支持的数量有限,而动态探针就是为了解决这个问题,它能够支持Hook几乎所有的内核函数。
Kprobes:Kprobe是一个典型的动态探针,如下图所示,在内核运行时,Kprobe技术将需要监控的内核函数的指令动态替换,使得该函数的控制流跳转到用户自定义的处理函数上。当内核执行到该监控函数时,相应的用户自定义处理函数被执行,然后继续执行正常的代码路径。

动态探针的优点:
可以Hook几乎所有的内核函数
动态探针的缺点
不稳定(函数的变更、编译器的优化等都可能导致采集程序的失效)
性能相对较差
软件探针(动/静态探针):
静态探针性能好,但支持的数量有限,动态探针支持的数量多,但不稳定、性能相对较差,那么是否存在一种技术,能同时兼顾静态和动态的优势呢?答案是动静态结合的探针方案。
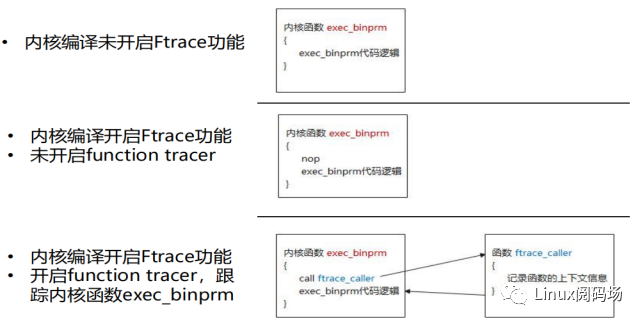
Function Hooks(Ftrace): Function Hooks是Ftrace引入的一种动静态结合的探针方案。 如下图所示,静态指的是它通过gcc编译器,在内核编译阶段,在内核函数的入口处插入了预留的特定指令,当内核运行时,它会将预留的特定指令替换为跳转指令(call ftrace_caller),使得内核函数的控制流跳转到用户自定义函数上,达到数据监控的目的。
Ftrace和Function Tracer
Function Hooks(Ftrace)的优点
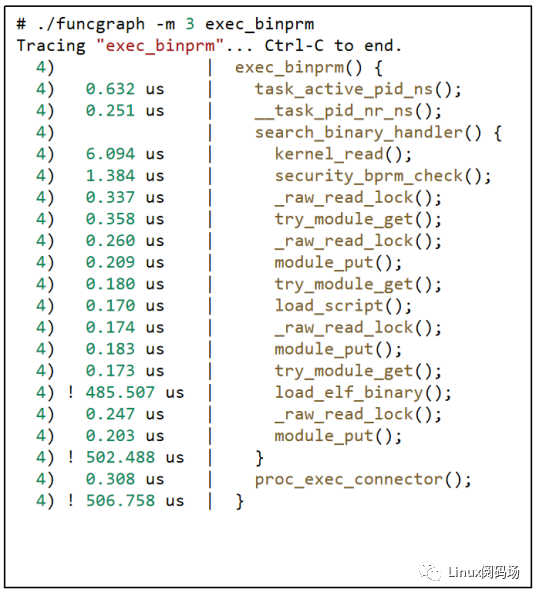
相比于Tracepoint和Kprobe,Function Hooks最显著的功能性特点是它能够方便地监控内核函数的调用关系,如下图所示,监控了内核函数exec_binprm的所有子函数调用关系。
上面分析完各种动态和静态探针的方案和优缺点后,从开发者代码多功能可控的角度出发,建议优先使用静态探针方案。
1.2. Linux Tracing System 发展历程
• 2004年4月,Linux Auditing subsystem(auditd)被引入内核2.6.6-rc1
• 2005年4月,Kprobe被引入内核2.6.11.7
• 2006年,LTTng发布(至今没有合入内核)
• 2008年10月 ,Kernel Tracepoint 被引入内核(v2.6.28)。
• 2008年,Ftrace被引入内核(包括compile time function hooks)。
• 2009年,perf被引入内核
• 2009年,SystemTap发布(至今没有合入内核)
• 2014年,Alexei Starovoitov将eBPF引入内核
1.3. Linux Tracing 框架方案对比
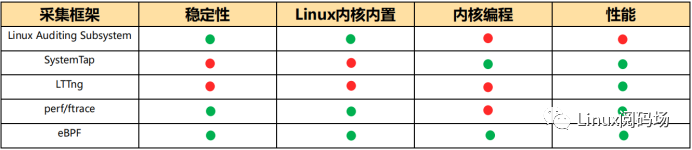
eBPF的优势对比:
稳定:通过验证器,防止用户编写的程序导致内核崩溃
免安装:eBPF内置于linux内核,无需安装额外以来
内核编程:支持开发者插入自定义的代码逻辑(包括数据采集、分析和过滤)到内核中运行
2. eBPF框架开发分析
2.1 eBPF基础架构
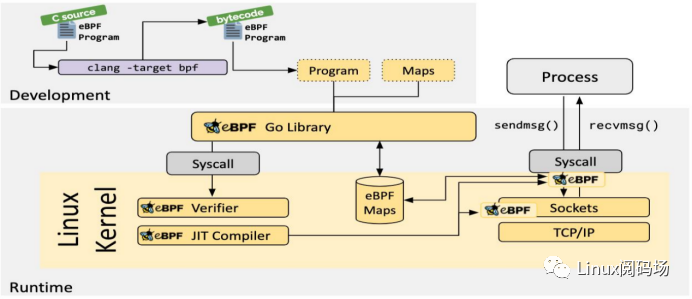
eBPF程序分为两部分: 用户态和内核态代码。
eBPF内核代码:
这个代码首先需要经过编译器(比如LLVM)编译成eBPF字节码,然后字节码会被加载到内核执行。所以 这部分代码理论上用什么语言编写都可以,只要编译器支持将该语言编译为eBPF字节码即可。
目前绝大多数工具都是用的C语言来编写eBPF内核代码,包括BCC。
bpftrace提供了一种易用的脚本语言来帮助用户快速高效的使用eBPF功能,其背后的原理还是利用LLVM 将脚本转为eBPF字节码。
eBPF用户态代码:
这部分代码负责将eBPF内核程序加载到内核,与eBPF MAP交互,以及接收eBPF内核程序发送出来的数据。这个功能的本质上是通过Linux OS提供的syscall(bpf syscall + perf_event_open syscall)完成的,因此这 部分代码你可以用任何语言实现。比如BCC使用python,libbpf使用c或者c++,TRACEE使用Go等等。
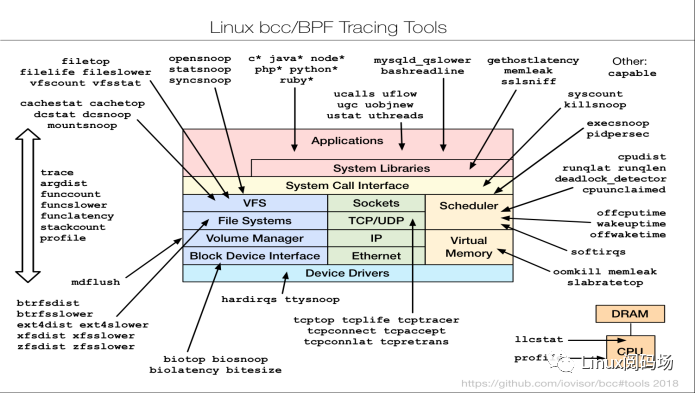
2.2 eBPF数据源
性能分析大师Brendan Gregg(Intel Fellow)总结的Linux BPF Tracing Tools上展示了丰富多彩的eBPF钩子类型,这些钩子类型提供了可以加载BPF程序的范围。
fentry/fexit
Tracepoints
network devices (tc/xdp)
network routes
TCP congestion algorithms
sockets (data level)
kernel functions (kprobes)
userspace functions (uprobes)
system calls
2.3 eBPF框架的发展历程
2014年9月 引入了bpf() syscall,将eBPF引入用户态空间。
自带迷你libbpf库,简单对bpf()进行了封装,功能是将eBPF字节码加载到内核。
2015年2月份 Kernel 3.19 引入bpf_load.c/h文件,对上述迷你libbpf库再进行封装,功能是将eBPF elf二进制文件加载到内核(目前已过时,不建议使用)。
2015年4月 BCC项目创建,提供了eBPF一站式编程。
1. 创建之初,基于上述迷你libbpf库来加载eBPF字节码。
2. 提供了Python接口。
2015年11月 Kernel 4.3 引入标准库 libbpf
1. 该标准库由Huawei 2012 OS内核实验室的王楠提交。
2018年 为解决BCC的缺陷,CO-RE(Compile Once, Run Everywhere)的想法被提出并实现,最后达成共识:libbpf + BTF + CO-RE代表了eBPF的未来,BCC底层实现逐步转向libbpf。
2.4 eBPF可移植性痛点和解决方案
技术痛点:
在内核版本A上编译的eBPF程序,无法直接在另外一个内核版本B上运行。造成可以执行差的根本原因在于eBPF程序访问的内核数据结构(内存空间)是不稳定的,经常随内核版本更迭而变化。
目前使用BCC的方案通过在部署机器上动态编译eBPF源代码可以来解决移植性问题。每一次eBPF程序运行都需要进行一次编译,而且需要在部署机器上按照上百兆大小的依赖,如编译器和头文件Clang/LLVM + Linux headers等。同时在Clang/LLVM编译过程中需要消耗大量的资源(CPU/内存),对业务性能也会造成很大影响。
解决方案(CO-RE Compile Once,Run Everywhere):
1) BTF:将内核数据结构信息高效压缩和存储(相比于DWARF,可达到超过100倍的 压缩比)
2) LLVM/Clang编译器:编译eBPF代码的时候记录下relocation相关的信息
3) Libbpf:基于BTF和编译器提供的信息,动态relocate数据结构
其中BTF为重要组成部分,Linux Kernel 5.2及以上版本自带BTF文件,低版本需要手动移植。
通过分析内核源码,可以发现BTF文件的生成并不需要改动内核,只依赖:
带有debug info的vmlinux image
pahole
LLVM
这意味着,我们可以自己为低版本内核生产BTF文件,以此让低内核版本支持CORE。
为低版本内核生成BTF文件
准备工作:
·安装pahole软件(1.16+)
·https://git.kernel.org/pub/scm/devel/pahole/pahole.git
·安装LLVM(11+)
·获取目标低版本内核的vmlinux文件(带有debug info),文件保存在{vmlinux_file_path}
·通过源下载
·比如对于CentOS,通过yum install kernel-debuginfo可以下载vmlinux
·源码编译内核,获取vmlinux
生成BTF:
·利用pahole在vmlinux文件中生成BTF信息,执行以下命令:
·pahole -J {vmlinux_file_path}
·将BTF信息单独输出到新文件{BTF_file_path},执行以下命令:
·llvm-objcopy --only-section=.BTF --set-section-flags .BTF=alloc,readonly --strip- all {vmlinux_file_path} {BTF_file_path}
·去除非必要的符号信息,降低BTF文件的大小,得到最终的BTF文件(大小约2~3MB):
·strip -x {BTF_file_path}
2.5 eBPF程序实例分析(一个Print引发的惨案)
eBPF程序会被LLVM编译为eBPF字节码,eBPF字节码需要通过eBPF Verifier的(静态)验证后,才能真正运行。边界检查是eBPF Verifier的重点工作,目的是为了防止eBPF程序内存越界访问。接下来通过在eBPF程序中简单的增加、删减print打印信息触发不同原因的几种边界检查异常导致验证失败的例子,进一步讲解深层的原理。
程序实验环境:
1) LLVM 11
2) Linux Kernel 5.8
3) Libbpf commit @9c44c8a
边界检查案例:
1) 内存越界:
SEC("kprobe/do_unlinkat")int BPF_KPROBE(do_unlinkat, int dfd, struct filename *name){// 获取一个数组指针array(数组MAX_SIZE为16个字节)u32 key = 0;char *array = bpf_map_lookup_elem(&array_map, &key);if (array == NULL)return 0;// 获取当前运行程序的CPU编号(当前机器的CPU有16个核)unsigned int pos = bpf_get_smp_processor_id();// 根据下表修改数组的值array[pos] = 1;return 0;}
上述代码编译运行后,提示Verifier失败,然后使用objdump命令来看一下具体的字节码,通过以下字节码程序,可以看到Verifier失败的原因在于第14行R6寄存器(变量pos)没有进行边界检查导致。
Root Cause:
当eBPF Verifier走到第14行的时候尝试去访问array数组,但是此时数组的下标pos是来自bpf_get_smp_processor_id获取到的unsigned int 类型的动态变量,此时Verifier无法判断变量的具体数值,所以会保守认为可能会达到最大值,这样的话就会超出array数组的范围,造成内存越界。
0000000000000000: ;int BPF_KPROBE(do_unlinkat, int dfd, struct filename *name) 0:r1 = 0; u32 key = 0;1: *(u32 *)(r10 - 4) = r12: r2 = r103: r2 += -4; char *array = bpf_map_lookup_elem(&array_map, &key); 4:r1 = 0 ll6: call 17: r6 = r0; if (array == NULL)8: if r6 == 0 goto +6; unsigned int pos = bpf_get_smp_processor_id();; 9:call 8; array[pos] = 1; 10:r0 <<= 3211: r0 >>= 3212: r6 += r013: r1 = 1; array[pos] = 1;14: *(u8 *)(r6 + 0) = r1
解决方案:
添加边界检查代码
if (pos < MAX_SIZE)if r0 > 15 goto +3
2) Verifier验证机制和编译器优化机制不一致导致边界检查不通过
① 使用错误寄存器做边界检查:
SEC("kprobe/do_unlinkat")int BPF_KPROBE(do_unlinkat, int dfd, struct filename *name){// 获取一个数组指针array(数组MAX_SIZE为16个字节)u32 key = 0;char *array = bpf_map_lookup_elem(&array_map, &key); if (array == NULL)return 0;// 获取当前运行程序的CPU编号(当前机器的CPU有16个核)unsigned int pos = bpf_get_smp_processor_id();;// 修改数值if (pos < MAX_SIZE){array[pos] = 1;pos += 1;}// debug代码,输出一些上下文信息bpf_printk("debug %d %d %d\n", bpf_get_current_pid_tgid() >> 32, bpf_get_current_pid_tgid(), array[1]);// 修改数值if (pos < MAX_SIZE)array[pos] = 1;return 0;}
编译这个代码后Verifier验证通过,可以正常运行。但是此时如果把bpf_printk打印信息删掉,竟然提示Verifier验证失败,原因是R0寄存器(变量pos)没有通过边界检查,但是明明已经加了边界检查代码,怎么还会出现问题,这么神奇!
Root Cause:

由于编译器的优化策略,导致删减bpf_printk后编译生成的eBPF字节码使用寄存器r1(表示pos变量)来进行边界检查,但是却用r0+1(同样表示pos变量)来访问数组array。
相比之下,从eBPF verifier的角度来看,由于在编译过程中,r1和r0+1的关联性丢失了,导致eBPF verifier无法知道pos变量已经通过了检查,因此错误的认为pos变量没有进行边界检查,不允许程序运行。
②寄存器溢出或重新加载后,状态丢失:
SEC("kprobe/do_unlinkat")int BPF_KPROBE(do_unlinkat, int dfd, struct filename *name){// 获取一个数组指针array(数组MAX_SIZE为16个字节)u32 key = 0;char *array = bpf_map_lookup_elem(&array_map, &key); if (array == NULL)return 0;// 获取当前运行程序的CPU编号(当前机器的CPU有16个核)unsigned long pos = bpf_get_smp_processor_id();;// 修改数值if (pos < MAX_SIZE){for (unsigned long i = 0; i < MAX_SIZE; i++)bpf_printk("debug %d %d %d\n", bpf_get_current_pid_tgid() >> 32, \bpf_get_current_pid_tgid(), array[i]);array[pos] = 1;}return 0;}
在上述边界检查代码中添加一段print调试打印信息后编译验证又会出现Verifier失败,通过排查发现不是已知的两类问题,依然使用objdump查看添加后的字节码信息。
Root Cause:

加入bpf_printk后通过字节码可以看到,代码先使用R0(表示pos变量)进行边界检查。由于当前寄存器数量不足,编译器决定将将R0临时保存到栈上的空间(R10-16,在eBPF字节码中,R10存储存放着 eBPF 栈空间的栈帧指针的地址),这样R0就可以空闲出来,留给其他代码使用,我们称这种行为为寄存器溢出(register spill)。当真正需要使用pos变量的时候,编译器会从栈上(R10-16)将之前保存的内容取出来赋给R1(也表示pos变量),然后使用R1对数组array进行访问。但神奇的是,当寄存器溢出发生时,pos变量的状态丢失了,eBPF忘记了该变量曾经进行了边界检查,导致程序无法通过验证。
解决方案:
在源码中加入 &= 操作符,引导编译器生成理想的eBPF字节码
array[pos &= MAX_SIZE - 1] = 1;
如果上述方法失效,无法引导编译器,那么针对出错的部分源代码人工编写eBPF字节码,替代编译器生成的字节码
#define STR(s) #s #define XSTR(s) STR(s)#define asm_variable_bound_check(variable)\({\asm volatile (\"%[tmp] &= " XSTR(MAX_SIZE - 1) " \n" \:[tmp]"+&r"(variable)\);\})asm_check(pos);array[pos] = 1;
3. 总结
本文总结了从动静态探针的角度梳理分析Linux Tracing System以及实例解决eBPF程序中遇到的问题。eBPF目前正在高速发展,很多坑和解决办法缺乏官方文档。本文在以下几点上做了自己的分析和分享,希望对大家更清晰的认识Linux Tracing System和eBPF有所帮助。
1. 自下而上的方式分析动静态探针
2. 各种场景下动静态探针的选择
3. BPF开发框架的选择
4. 多内核版本兼容性问题
5. 如何为低版本内核生成BTF文件
6. eBPF边界检查问题分析
7. eBPF Verifier验证机制与编译器优化机制不一致问题
往期精华文章:【精华】Linux阅码场原创精华文章汇总
阅码场付费会员专业交流群
会员招募:各专业群会员费为88元/季度,权益包含群内提问,线下活动8折,全年不定期群技术分享(普通用户直播免费,分享后每次点播价为19元/次),有意加入请私信客服小月(小月微信号:linuxer2016)
专业群介绍:
甄建勇-性能优化与体系结构
本群定位Perf、cache和CPU架构技术交流,覆盖云/网/车/机/芯领域资深用户,由阅码场资深讲师甄建勇主持。
李春良-Xenomai与实时优化
本群定位Xenomai与实时优化技术交流,覆盖云/网/车/机/芯领域资深用户,由阅码场资深讲师李春良和彭伟林共同主持。
周贺贺-Tee和ARM架构
本群定位Tee和ARM架构技术交流,覆盖云/网/车/机/芯领域资深用户,由阅码场资深讲师周贺贺主持。
谢欢-Linux tracers
本群定位Linux tracers技术交流,覆盖云/网/车/机/芯领域资深用户,由阅码场资深讲师谢欢主持。
✦
✦
