


存储领域七篇推荐论文中一篇来自中国。
在 VLSI Symposium 2022 上,有七篇关于内存的论文引起了半导体产业的关注。值得关注的是,华为在3D DRAM上的研究论文受到关注。
 华为:采用垂直CAA型IGZO FET的3D-DRAM技术
华为:采用垂直CAA型IGZO FET的3D-DRAM技术
华为与中科院微电子实验室报告了使用CAA-IGZO-FET的3D DRAM相关研究,该研究成果推动了IGZO晶体管在高密度DRAM领域的应用。同时该研究也入选了IEDM 2021,同时获选Highlight Paper和Top Ranked Student Paper。
CAA为Channel-All-Around,垂直通道全环绕技术。CAA结构可以减小器件面积,且支持多层堆叠,通过将上下两个CAA器件直接相连,每个存储单元的尺寸可减小至4F2,使IGZO-DRAM拥有了密度优势。
假设有效器件面积为 50 × 50nm 2以下,IGZO 厚度为3 nm,使用 HfOx 绝缘膜的 IGZO-FET 在 32.8 μA/μm(Vth + 1V)。它具有出色的温度稳定性和可靠性,PBTS(正栅极偏置温度负载)特性已在-40°C至120°C范围内得到证实。
IGZO(铟镓锌氧)是一种由In、Ga、Zn、O组成的透明氧化物,由东京工业大学的细野教授于 2004 年生产并发表在《Nature》杂志上。
虽然受到美国政府半导体技术限制,但华为仍保持着对尖端的半导体技术的研究,并被接受率为30%的VLSI会议采用。

图1: 通过垂直CAA型IGZO FET横截面SEM图像和EDX实现元素分布的可视化,来源VLSI
IBM:具有双自旋力矩磁结的MRAMIBM 展示了使用双自旋扭矩磁隧道结(DSMTJ) 实现亚纳秒切换的可靠性和运行速度。以 250 ps 或更低的写入操作实现了低错误率,并在 -40°C 至 85°C 的宽温度范围内实现了紧密的特性分布。1 x 10 10写周期后没有恶化。

图 2: DSMTJ 开关时电流密度的开关脉冲宽度依赖性,来源VLSI
磁性随机存储器(MRAM)是一种基于自旋电子学的新型信息存储器件,其核心结构由一个磁性隧道结和一个访问晶体管构成。
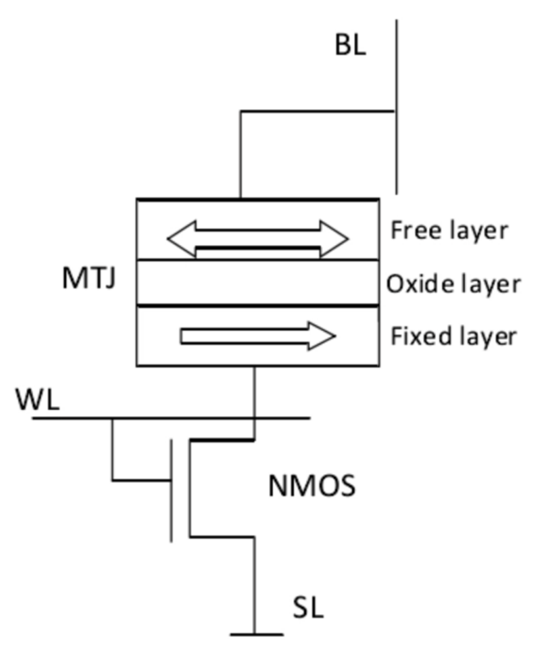
MRAM结构图
第一代 MRAM 的写入方式是磁场写入式。它利用导体中流过的正反两个电流方向产生磁化感应,使得 STT 存储单元的 MTJ 自由层相对固定层磁化方向为同向和反向两个方向,从而表现出高低两种大小的阻抗状态用于存取数字逻辑“1”和“0”。
第二代 MRAM 的写入方式是自旋转移矩写入式。它是利用自旋转移矩(spin - transfer torque)效应诱导磁性材料发生磁化翻转,即利用流过隧道结中不同方向的自旋极化电流,驱动软磁体磁化方向的改变,实现 MTJ 结高低阻抗状态的写入。
第三代MRAM的自旋道矩磁随机存储器(SOT-MRAM),电流通过底层重金属,产生自旋流并注入到自由层中,利用自旋轨道矩使自由层的磁化方向产生扰动,并结合多种方式让磁化方向产生确定性的翻转。
而本次IBM提出的DS-MTJ与SOT-MRAM相比,工作电流密度可降低至1/10,功耗可降低至1/3至1/10。
斯坦福大学:基于GST(Ge 2 Sb 2 Te 5)的超晶格相变存储器
斯坦福大学报告称,它开发了一种先进的相变存储器结构,具有 GST 超晶格异质结构,可以降低复位电流和电阻漂移系数。
X射线衍射(XRD)和高角度散射环形暗场扫描透射显微镜(HAADF-STEM)分析表明,具有超晶格结构的PCM的复位电流和电阻漂移系数随着超晶格堆叠数量的增加而降低。演示了复位电流~3mA/cm2、7 个电阻值状态和电阻漂移系数(~0.002)。

图3 :GST超晶格异质结构,来源:VLSI
相变存储器是一种非易失性存储器设备简称PCM,相变存储器利用特殊材料在晶态和非晶态之间相互转化时所表现出来的导电性差异来存储数据。
PCM因其具备非易失性、可字节寻址等特性而同时具备作为主存和外存的潜力,在其影响下,主存和外存之间的界限也正在逐渐变得模糊,甚至有可能对未来的存储体系结构带来重大的变革。因此,它被认为是极具发展前景、最有可能完全替代DRAM的新型NVM技术之一。
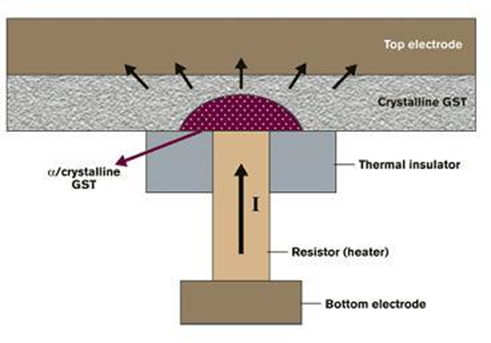
PCM器件典型结构
三星电子:16GB 1024GB/s HBM3 DRAM,通过片上错误代码纠正增强RAS功能HBM(High BandwidthMemory)是最受青睐的内存,因为它具有高带宽、低功耗和大容量的特点,但它是一个可用于汽车、数据中心和人工智能等工业应用的系统。可用性和可维护性 (RAS) 挑战必须克服。
三星发表了名为“ A 16 GB 1024 GB/s HBM3 DRAMwith On-Die Error Control”的研究。三星使用了一种新的片上错误代码纠正 (ECC) 方案,该方案可以同时纠正 16 位字错误和 2 个单位错误,同时三星将该方案合并到新版本的“High Bandwidth Memory-3”中(HBM3) DRAM。
在16GB DRAM 模块中, 通过这一方案在每个单独的 DRAM 裸片上本地执行校正,而不必访问堆栈中的其他裸片,减少延迟并将引脚数据速率从上一代的 5 Gb/s/pin 提高到 8.0 Gb/s/pin,总共每个内存立方体的内存带宽为 1024 GB/s。

图 4:16GB HBM3 DRAM 芯片,来源VLSI
高带宽存储器(英文:High Bandwidth Memory,缩写HBM)是三星电子、超微半导体和SK海力士发起的一种基于3D堆栈工艺的高性能DRAM,适用于高存储器带宽需求的应用场合,像是图形处理器、网络交换及转发设备(如路由器、交换器)等。
Intel:采用 4nmCMOS 的高效宽带 6T SRAM 设计为了提高高吞吐量应用的计算处理的功率效率,增加片上存储器的容量和带宽已成为一个问题。传统上,6 晶体管 SRAM(6T SRAM)满足小面积要求,8 晶体管 SRAM(8T SRAM)支持较低的动态功耗,但很难同时实现两者。
英特尔报告了采用 4nm 级 CMOS 技术的高能效SRAM。针对0.03 μm 2位单元面积优化的6T SRAM设计,实现了与8T SRAM相同的功耗,与传统的6T SRAM设计相比,动态功耗降低了5.8倍。

图 5:采用 4nm CMOS 的高效、宽带 6T SRAM,来源VLSI
SRAM是随机存取存储器的一种。所谓的“静态”,是指这种存储器只要保持通电,里面储存的数据就可以恒常保持。相对之下,动态随机存取存储器(DRAM)里面所储存的数据就需要周期性地更新。然而,当电力供应停止时,SRAM储存的数据还是会消失(被称为volatile memory),这与在断电后还能储存资料的ROM或闪存是不同的。
Meta:7nm SRAM使用 AR 应用程序的连续访问模式将访问功率降低 58%AR 应用程序需要为支持边缘智能的传感器提供超低功耗。传统的 SRAM 宏针对随机数据流量进行了优化,因此无法有效地使用顺序数据访问来降低功耗。
推广元宇宙的 Meta(前Facebook)优化了测量模态的内存设计,并提出了一种专门针对连续访问而不是随机访问内存的方法。在从存储器连续读取和写入操作中,电路操作的数量被最小化。与传统设计相比,这种方法降低了 52% 的读取功率和 58% 的写入功率。

图 6 :EMG(肌电图)腕带原型(右)中安装在PCB(中)上的 SoC 芯片(左),来源VLSI
佐治亚理工学院:具有脉宽调制输入的无 AD 转换器的 Compute-in-Memory (CIM) 宏
迄今为止的CIM宏中,乘积和运算结果通过AD转换器转换为二进制位,然后在每个存储器阵列中实现运算。然而,包括AD转换器在内的二进制位转换电路的开销较大,并且存在由于AD转换器的量化误差而导致计算精度降低的问题。
佐治亚理工学院通过对存储器阵列输入应用脉冲宽度调制,消除了对 AD 转换器的需求。通过消除将积和计算结果数字化的开销,与配备电阻的CIM宏相比,与计算相关的电路面积减少了50%,电源效率提高了11.6倍,计算量提高了4.3倍使用AD转换器改变类型的内存。据说已经实现了效率的提高。

图 7:GIT 生产的具有电阻变化存储器的 Compute-in-Memory (CIM) 宏芯片
本次研讨会论文总申请量为580篇,录用198篇,占比34%,与常年持平。申请数量最多的是北美(美国/加拿大),有 134 份申请入选65篇,接受率为49%,远高于平均水平;相对来说中国仅入选12篇论文,录取率极低仅为13%。
*声明:本文系原作者创作。文章内容系其个人观点,我方转载仅为分享与讨论,不代表我方赞成或认同,如有异议,请联系后台。







