关注+星标公众号,不错过精彩内容
转自 | 半导体行业观察
关于RISC和CISC处理器的区别,大多数人会认为是一些特性、指令,或者是晶体管数量的差异。但实际上两者之间的差别不能简单的一概而论。首先,我们需要摒弃一些非常明显的误解。因为RISC的意思是简化指令集计算机(Reduced Instruction Set Computer),所以很多人认为RISC处理器只是一个没有多少指令的CPU。如果是这样的话,那么6502处理器将是有史以来最RISCy的处理器之一,它只有56条指令。甚至英特尔8086也可以算作RISC处理器,因为它只有81条指令。即使是后来的Intel 80286也只有大约100条指令。像AVR这样简单的8位RISC处理器有78条指令。如果您看看最早的32位RISC处理器之一,比如PowerPC 601(1993年发布),它有273个指令。MIPS32指令集来源于伯克利的原始RISC处理器,它也有200多条指令。我们可以将其与CISC 32位处理器(如80386)进行比较,后者只有略多于170条指令。差不多时间亮相的MIPS R2000处理器在大约有92条指令。For the curios:
x86 instruction listings
Pentium instruction set
6502 Instruction Set
MIPS R2000 InstructionSet
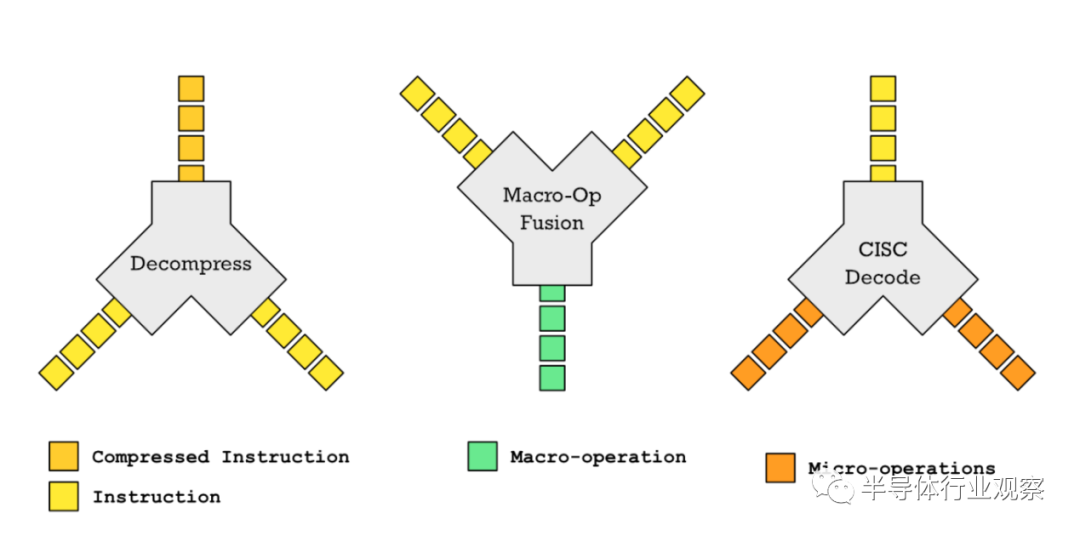
也就是说,类似x86指令集、奔腾指令集、6502指令集、MIPS R2000指令集一开始都具有很少指令集,但它们都不是RISC处理器。CISC和RISC处理器之间的晶体管数量的分界点是多少?根本没有。6502有4528个晶体管。第一个ARM处理器有25000个晶体管。或者这个有趣的小事实。摩托罗拉68060被认为是那个时代最具代表性的CISCy的处理器之一,它只有250万个晶体管,比1994年发布的IBM PowerPC 601的280万个晶体管还要少。如果你看一下几乎同时发布的RISC和CISC处理器,没有明显的趋势表明RISC处理器比CISC处理器有更少的晶体管和更少的指令。上世纪90年代初流行的RISC和CISC处理器晶体管和指令的比较所以让我们得出结论,我们不能根据晶体管或指令数量区分RISC或CISC芯片。但是问题仍然存在,到底是什么是RISC微处理器或CISC微处理器?当你的老板告诉你“这里,有一百万个晶体管,给我做一个快速的处理器!”,那么你就有很多方法可以实现这个目标。对于相同数量的晶体管,RISC和CISC的设计者将会做出不同的选择。伯克利的David A. Patterson广为人所知的可能是他在1980年发表的论文《简化指令集计算机的案例》中推广了RISC处理器的思想。Patterson在这篇论文中概述的并不是芯片制造的详细蓝图,而更像是哲学指导方针。在现实世界的程序中,添加这个指令会提高多少性能?硬件方面的影响是什么?我们是否需要存储大量复杂的状态,这使得上下文切换和无序执行更加复杂,因为需要存储大量的状态?一个设计良好的简单指令的组合能以相当的性能完成同样的工作吗?我们是否可以利用现有的算术逻辑单元(ALUs)和CPU上的其他资源来添加这条指令,或者我们需要添加很多新东西?如果不添加这条指令,这些晶体管的其他用途是什么?更多的缓存吗?更好的分支预测吗?重要的是要理解这些规则适用于给定的晶体管预算。如果你有更多的晶体管,你可以添加更多的指令,甚至更复杂的指令。然而,RISC的哲学优先考虑保持指令集的简单。这意味着RISC设计者首先会尝试通过其他方法来提高性能,而不是添加如下指令:使用晶体管增加更多的缓存
更多的CPU寄存器
更好的管道
更好的分支预测
超标量体系结构的体系结构
添加更多的指令解码器
乱序执行
Macro-operation融合
压缩指令
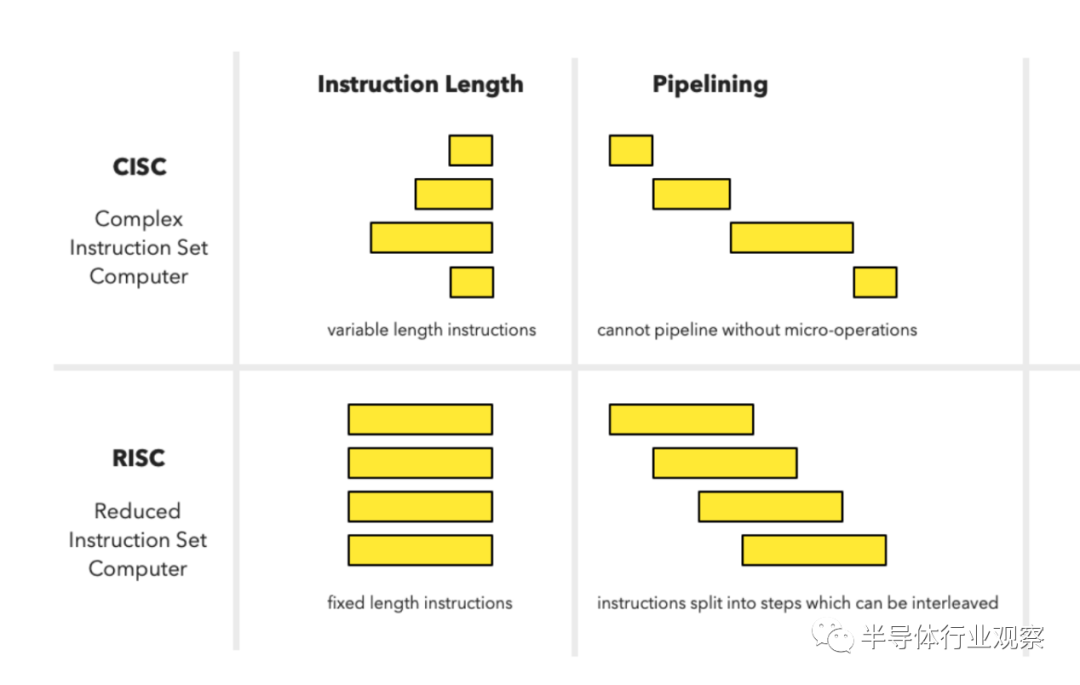
因此,设计一个好的RISC指令集(ISA)的一个关键目标是使设计不妨碍未来的微架构优化。这与CISC设计者设计CPU的方式不同。为了能够提供更好的性能,那么CISC设计者将添加引入更多状态以跟踪状态寄存器等复杂指令。问题是CISC的设计师没有超前思考。将来你的晶体管预算可能会增加。突然之间,你有了所有这些好的晶体管,可以用来创建无序(OoO)超标标量处理器逻辑。这意味着您在每个时钟周期解码多个指令,并将它们放在一个指令队列中。然后,OoO逻辑会找出哪些指令不相互依赖,以便它们可以并行运行。如果您是软件开发人员,您可以考虑函数式编程(functional programming)和命令式编程(imperative programming)之间的区别。为了获得短期性能收益而改变全局数据可能很诱人。然而,一旦你并行运行,而全局状态被多个函数改变了,这可能会在多个线程中并行运行,这绝对是一场噩梦。函数式编程喜欢只依赖于输入而不依赖全局数据的纯函数。这些函数可以很容易地并行运行。同样的机制也适用于CPU。不依赖于全局状态(如状态寄存器)的汇编代码指令可以更容易地并行或流水线运行。RISC-V就是这种思想的一个很好的例子。RISC-V没有状态寄存器。比较和跳转指令合二为一。除非运行额外的计算来确定是否发生了溢出,否则无法用状态寄存器捕获整数溢出。这应该会给你一些关于RISC和CISC区别的线索。如果10条新指令对微架构没有显著影响,那么RISC设计者添加10条新指令不一定会有问题。如果一条指令要求在CPU中表示更多的全局状态,那么RISC设计人员将会非常不愿意添加一条指令。这种哲学的最终结果是,从历史上看,在RISC处理器上添加管道和超标量架构比CISC处理器更容易,因为人们避免了添加指令,从而引入状态管理或控制逻辑,这使得添加这些微架构创新变得困难。这就是为什么RISC-V团队更喜欢进行宏操作(macro-operation)融合,而不是添加支持复杂寻址模式或整数溢出检测的指令。RISC的理念导致了不断出现的特殊设计选择,这让我们能够讨论在比较RISC和CISC处理器时所观察到的更具体的差异。让我们看看这些。某些设计选择不断出现在许多不同的RISC处理器上。通常情况下,RISC处理器倾向于使用固定长度的32位指令。也有一些例外,比如AVR,它使用固定长度的16位指令。相比之下,Intel x86处理器的指令长度为1到15字节。摩托罗拉68k处理器,另一个著名的CISC设计,有2到10字节长的指令(16位到80位)。对于汇编程序员来说,变长指令实际上非常方便。我的第一台电脑是Amiga 1000,它有一个摩托罗拉68k处理器,所以它向我介绍了68k组装,坦白说非常整洁。它有将数据从一个内存位置移动到另一个内存位置的指令,或者可以将数据从寄存器A1给出的地址移动到另一个寄存器A2给出的内存位置。; 68k Assembly code
MOVE.B 4, 12 ; mem[4] → mem[12]
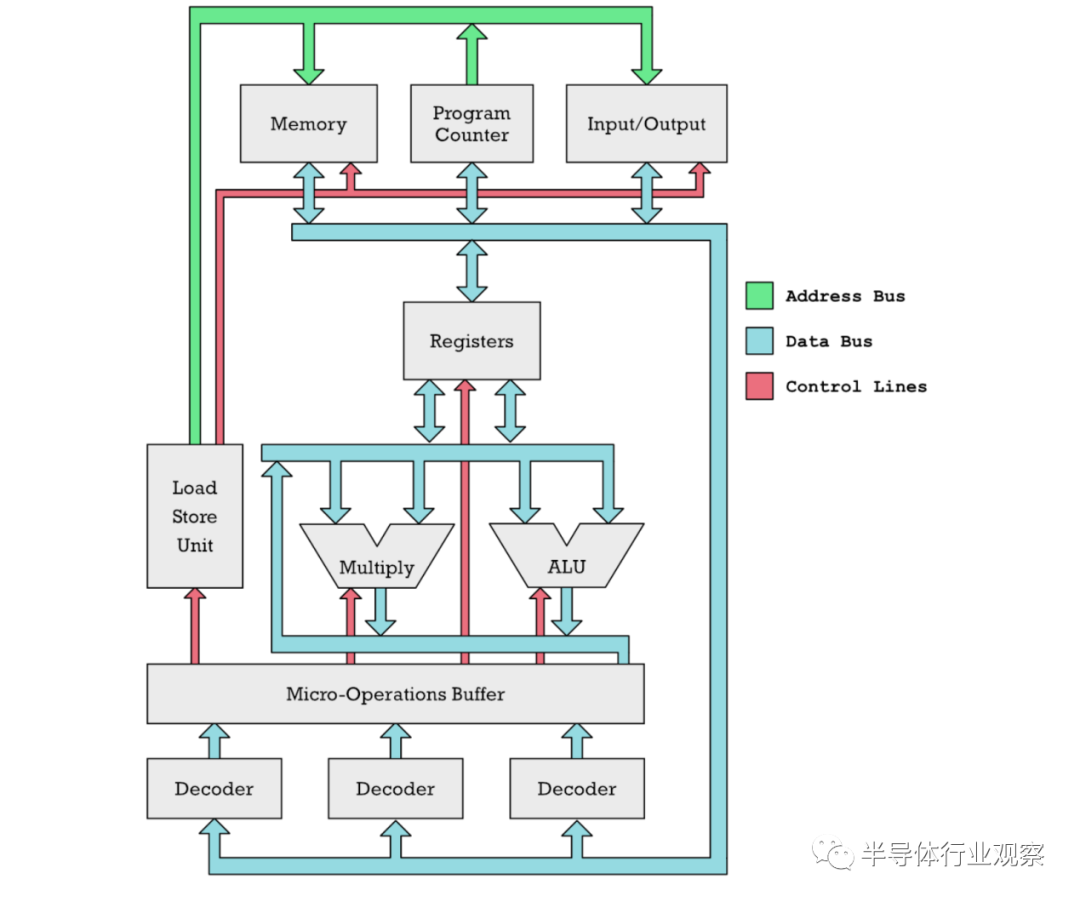
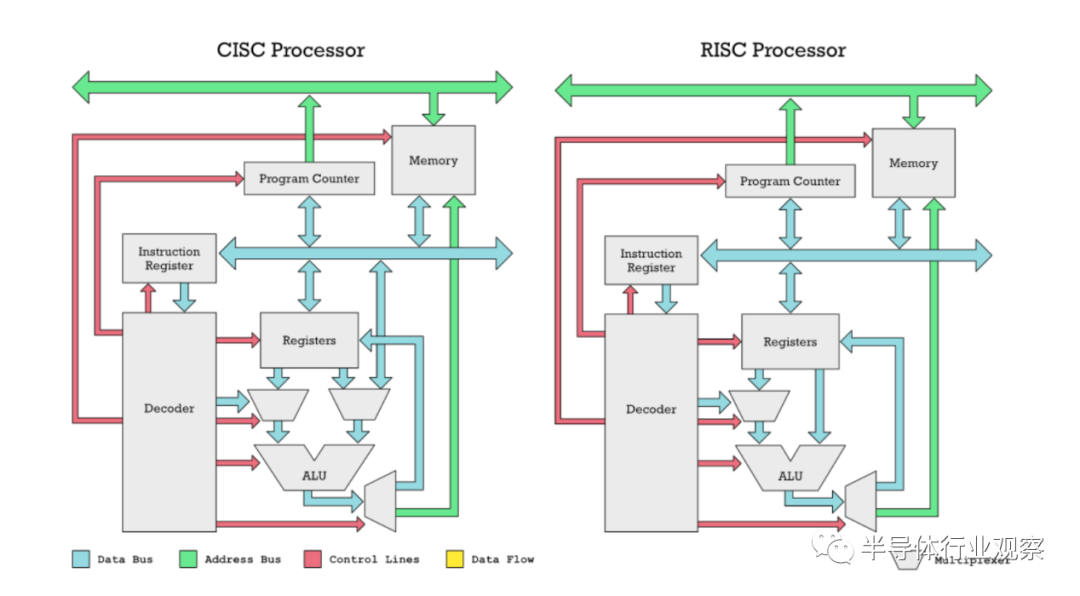
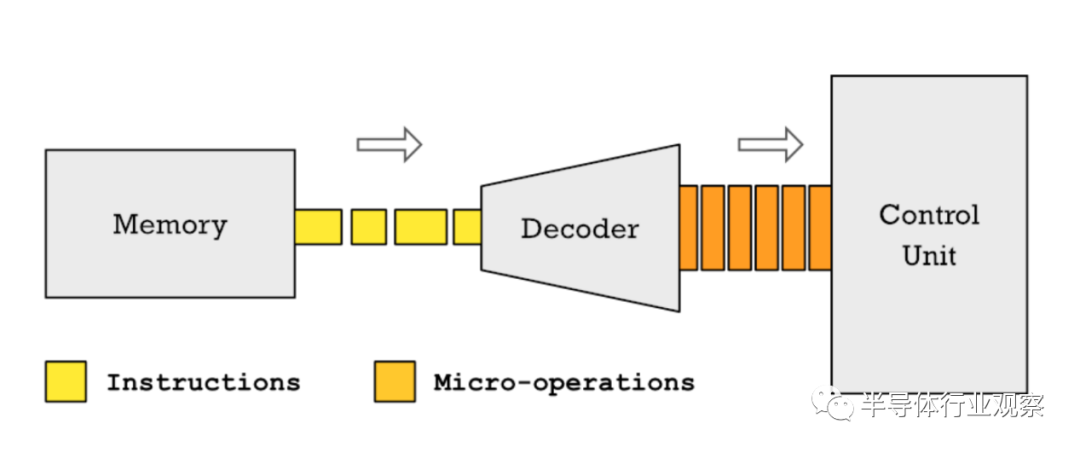
MOVE.B (A1), (A2) ; mem[A1] → mem[A2]这样的指令使CPU易于编程,但这意味着没有办法将支持的每条指令都放在32位内,因为表示完整的源地址和目的地址将只消耗64位。因此,通过使用变长指令,我们可以很容易地在任何指令中包含完整的32位内存地址。然而,这种便利是有代价的。变长指令更难以流水线处理,如果你想让一个超标标量处理器并行解码两条或多条指令,你很难做到这一点,因为你不知道每条指令在哪里开始和结束,直到你解码它们。RISC处理器倾向于避免使用可变长度指令,因为这不符合RISC不添加指令的理念,这也使得添加更高级的微架构优化变得更加困难。固定长度的指令会造成不便。您不能将内存地址放入任何操作中,只能放入特定的操作,如加载和存储指令。在RISC处理器中的算术逻辑单元(ALU)只能从寄存器而不是内存中获取输入。机器代码指令必须对正在执行的信息进行编码,例如它是在执行ADD、SUB还是MUL。它还必须对输入的信息进行编码。输入寄存器和输出寄存器是什么。一些指令需要对要加载数据的地址进行编码。在RISC-V指令中是这样编码的:上图显示了如何使用32位字中的每一位为RISC-V指令集编码一条指令
我们执行的特定指令称为操作码(上图黄色),它消耗7位。我们指定的每个寄存器输入或输出都需要5位。从这里应该很清楚,挤入一个32位地址是不可能的。即使是一个较短的地址也是困难的,因为你需要位来指定在操作中使用的寄存器。对于CISC处理器,这不是一个问题,因为您可以自由地使用超过32位的指令。这种紧凑的空间要求使得RISC处理器具有我们所说的加载/存储架构。只有专用的加载和存储指令,如RISC-V上的LW和SW,才能用于访问内存。对于CISC处理器,如68k,几乎任何操作,如ADD、SUB、AND和OR,都可以使用内存地址作为操作数(参数)。在下面的例子中,4(A2)计算到一个内存地址,我们使用它来读取一个操作数(参数)到ADD指令。最终的结果也存储在那里(在68k上destination是右参数)。; 68k assembly
ADD.L D3, 4(A2) ; D3 + mem[4 + A2] → mem[4 + A2]典型的RISC处理器(如基于RISC- v指令集的处理器)需要将加载(LW)和存储(SW)作为单独的指令进行存储。# RISC-V assembly
LW x4, 4(x2) # x4 ← mem[x2+4]
ADD x3, x4, x3 # x3 ← x4 + x3
SW x3, 4(x2) # x3 → mem[x2+4]你不需要通过结合地址寄存器(A0到A7)来计算地址。你可以直接指定一个内存地址,比如400:; 68k assembly
ADD.L 400, D4 ; mem[400] + D4 → D4但即使是这样一个看似简单的操作也需要多个RISC指令。# RISC-V assembly
LW x2, 400(x0) # x3 ← mem[x0 + 400]
ADD x4, x4, x3 # x4 ← x4 + x3在很多RISC设计中,x0寄存器总是0,这意味着即使你只对绝对内存地址感兴趣,你也可以始终使用偏移加基寄存器的形式。虽然这些偏移量看起来与您在68k上所做的非常相似,但它们的限制要大得多,因为您总是需要适合一个32位字。使用68k,可以给ADD.L一个完整的32位地址。你不能用RISC-V LW和SW。获得完整的32位地址是相当麻烦的。假设您希望从32位地址:0x00042012加载数据,则必须分别加载上面的20位和下面的12位,以形成一个32位地址。# RISC-V assembly
LUI x3, 0x42 # x3[31:12] ← 0x42 put in upper 20-bits
ADDI x3, x3, 0x12 # x3 ← x3 + x3 + 0x12
LW x4, 0(x3) # x4 ← mem[x3+0]实际上这可以简化为:LUI x3, 0x42 LW x4, 0x12(x3)我记得当我从68k组装转到PowerPC(苹果以前使用的RISC处理器)时,这让我很恼火。当时我认为RISC意味着一切都将变得更容易。我发现x86很麻烦,很难处理。然而,对于汇编编码员来说,RISC不像68k那样方便地使用CISC指令集。幸运的是,有一些简单的技巧可以使这个过程在RISC处理器上变得更容易。RISC-V定义了一些伪指令,以简化汇编代码的编写。使用LA (load address)伪指令,我们可以像这样编写前面的代码:# RISC-V assembly with pseudo instructions
LI x3, 0x00042012 # Expands to a LUI and ADDI
LW x4, 0(x3)总而言之:虽然加载/存储体系结构使编写汇编代码变得更麻烦,但它允许我们保持每个指令为32位长。这意味着创建一个可以并行解码多个指令的超标标量微体系结构需要更少的晶体管来实现。流水线化每条指令变得更容易,因为它们中的大多数可以适合经典的5步RISC流水线。使用像68k这样的高级CISC处理器,您可以用一条指令做很多事情。假设您想将数字从一个数组复制到另一个数组。下面是一个使用指针的C语言例子:// C code
int data[4] = {4, 8, 1, 2, -1};
int *src = data;
while (*xs > 0)
*dst++ = *src++;如果你在68k处理器上将指针src存储在地址寄存器A0中,将指针dst存储在地址寄存器A1中,你可以在一条指令中复制并向前移动每个指针4个字节:; 68k assembly
MOVE.L (A0)+,(A1)+ ; mem[A1++] → mem[A2++]这只是一个例子,但是一般来说,您可以使用CISC指令做更多的事情。这意味着您需要更少的代码。因此,RISC设计者意识到他们的代码会变得臃肿。因此,RISC的设计者们分析了真实的代码,提出了一种方案,可以在不使用复杂指令的情况下减少代码的大小。他们发现很多代码只是用来加载和存储内存中的数据。通过添加大量寄存器,可以将临时结果保存在寄存器中,而无需将它们写入内存。这将减少需要执行的加载和存储指令的数量,从而减少代码的RISC代码大小。因此,MIPS、SPARC、Arm(64位)和RISC-V处理器有32个通用寄存器。我们可以对比一下原来的x86,它只有8个通用寄存器。我在这个故事中想要说明的是,RISC处理器并不比CISC处理器差。区别在于RISC和CISC的设计者选择增加复杂性。CISC设计人员将复杂性放在指令集体系结构(ISA)中,而RISC设计人员宁愿将复杂性添加到他们的微体系结构中,但正如我一直强调的,他们不希望指令集在微架构中强加复杂性。让我来比较一下MIPS R4000,摩托罗拉68040和英特尔486,以强调理念上的差异。它们都有大约120万个晶体管,几乎同时发布(1989年至1991年)。RISC处理器(R4000)是64位的,其他是32位的。R4000有8级pipeline ,允许比6级pipeline 的68040和5级pipeline 的486更高的时钟频率。更长的pipeline 给R4000从100-200 Mhz远远超过68040的40Mhz和486DX2得到66Mhz (100Mhz在一个更晚的模型)。最终在1993/1994年出现了速度更快的CISC处理器,如68060和Pentium。但与此同时出现了MIPS R8000,它是一种可以并行解码4条指令的超标量结构。奔腾处理器每个时钟周期只能解码2条指令。所以我们可以看到RISC的设计者们是如何喜欢花哨的微架构而不是花哨的指令的。您可能会抗议说,今天的CISC处理器有复杂的微架构。他们所做的。一个现代的Intel或AMD处理器有多个解码器、微操作缓存、高级分支预测器、无序(OoO)执行引擎。然而,这并不奇怪。记住我关于晶体管预算理念的关键点:今天每个人都有很多晶体管可以使用,所以所有高端芯片都将有很多先进的微架构功能。他们可以负担得起他们的预算。关键在于:这些复杂的微体系结构特性中的许多都是由复杂的CISC指令集强加的。例如,为了使pipelines 工作,x86处理器将其冗长复杂的指令分解成微操作。微操作很简单,行为更像RISC操作,因此它们可以更容易地流水线化。问题是把CISC指令分解成更简单的微观操作并不容易。因此,许多现代的超标标量x86处理器对简单指令有3个指令解码器,对复杂指令有1个解码器。由于您不知道每条指令从哪里开始和结束,CISC处理器不得不进行一场涉及许多晶体管的复杂的猜谜游戏。RISC处理器避免了这种复杂性,可以将所有浪费的晶体管用于添加更多的解码器或进行其他优化,如使用压缩指令或宏操作融合(将非常简单的指令组合成更复杂的指令)。在不同的CPU设计中,指令可以以不同的方式组合或分割。如果你将苹果的M1处理器(这是一个基于RISC的处理器)与AMD和英特尔的处理器做比较,你会注意到它有更多的指令解码器。CISC的设计人员试图通过添加微操作缓存来缓解这个问题。有了微操作缓存,CISC处理器就不必克服障碍,也不必一遍又一遍地解码相同的复杂指令。然而,增加这一功能显然会消耗晶体管的成本。它不是免费的。因此,你正在把你的晶体管预算浪费在微架构的复杂性上,这只是因为ISA的复杂性。比较现代RISC和CISC处理器的一个问题是,RISC基本上赢了。没有人再从头开始设计CISC处理器了。Intel和AMD的x86处理器今天之所以流行,主要是因为向后兼容。如果你今天让一个设计团队坐下来,告诉他们从头开始设计一个高性能处理器,那么你最终不会得到传统的CISC设计。然而,这并不意味着在RISC社区中,有多少设计师倾向于CISC或RISC的方向上没有差异。现代的Arm处理器和基于RISC-V的处理器就是这种对比的有趣例子。Arm的设计者更愿意添加复杂的指令来提高性能。请记住,不是Arm不是RISC设计。当你的晶体管预算增长,增加更复杂的指令是公平的。。RISC-V的设计者更热衷于将ISA的复杂性保持在最低程度,而不是增加微架构的复杂性,从而通过使用压缩指令和宏操作融合等技巧来提高性能。我在这里讨论这些设计选择:RISC-V微处理器的天才。Arm和RISC-V的不同选择不是随意的,而是受到非常不同的目标和市场的很大影响。Arm越来越多地进入高端市场。请记住,苹果的Arm芯片正在与x86芯片展开正面竞争,不久,英伟达也会这样做。RISC-V的目标是成为一个更广泛的架构,用于从键盘到人工智能加速器、从gGPU到专门的超级计算机的任何东西。这意味着RISC-V意味着灵活性,您添加的指令越复杂,您施加的复杂性就越小,从而减少了为特定用例定制芯片的自由。------------ END ------------
●专栏《嵌入式工具》
●专栏《嵌入式开发》
●专栏《Keil教程》
●嵌入式专栏精选教程
关注公众号回复“加群”按规则加入技术交流群,回复“1024”查看更多内容。

点击“阅读原文”查看更多分享。