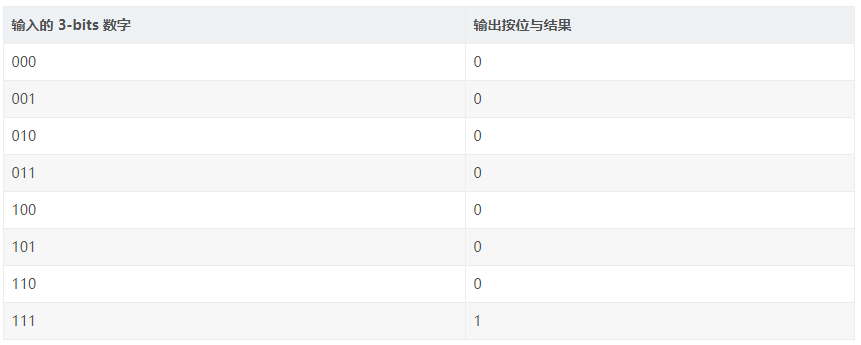

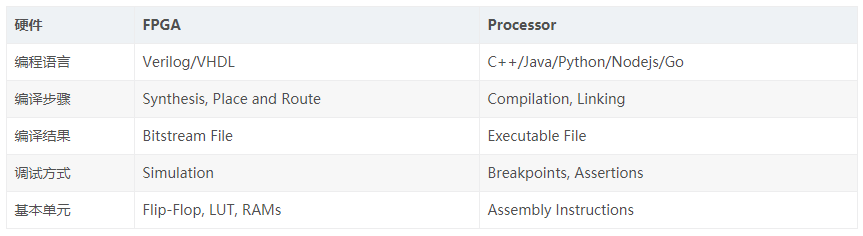



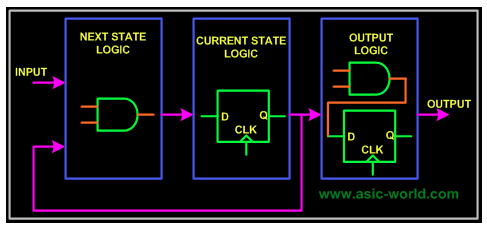
module fsm_using_single_always (clock , // clockreset , // Active high, syn resetreq_0 , // Request 0req_1 , // Request 1gnt_0 , // Grant 0gnt_1);//=============Input Ports=============================input clock,reset,req_0,req_1; //=============Output Ports===========================output gnt_0,gnt_1;//=============Input ports Data Type===================wire clock,reset,req_0,req_1;//=============Output Ports Data Type==================reg gnt_0,gnt_1;//=============Internal Constants======================parameter SIZE = 3 ;parameter IDLE = 3'b001,GNT0 = 3'b010,GNT1 = 3'b100 ;//=============Internal Variables======================reg [SIZE-1:0] state ;// Seq part of the FSMreg [SIZE-1:0] next_state ;// combo part of FSM//==========Code startes Here==========================always @ (posedge clock)begin : FSMif (reset == 1'b1) beginstate <= #1 IDLE;gnt_0 <= 0;gnt_1 <= 0;end elsecase(state)IDLE : if (req_0 == 1'b1) beginstate <= #1 GNT0;gnt_0 <= 1; end else if (req_1 == 1'b1) begingnt_1 <= 1;state <= #1 GNT1; end else beginstate <= #1 IDLE; endGNT0 : if (req_0 == 1'b1) beginstate <= #1 GNT0; end else begingnt_0 <= 0;state <= #1 IDLE; endGNT1 : if (req_1 == 1'b1) beginstate <= #1 GNT1; end else begingnt_1 <= 0;state <= #1 IDLE; enddefault : state <= #1 IDLE;endcaseendendmodule // End of Module arbiter
.|-- common| |-- inc| | `-- AOCLUtils| | |-- aocl_utils.h| | |-- opencl.h| | |-- options.h| | `-- scoped_ptrs.h| |-- readme.css| `-- src| `-- AOCLUtils| |-- opencl.cpp| `-- options.cpp`-- matrix_mult|-- Makefile|-- README.html|-- device| `-- matrix_mult.cl`-- host|-- inc| `-- matrixMult.h`-- src`-- main.cpp
__kernel__attribute((reqd_work_group_size(BLOCK_SIZE,BLOCK_SIZE,1)))__attribute((num_simd_work_items(SIMD_WORK_ITEMS)))void matrixMult( __global float *restrict C,__global float *A,__global float *B,int A_width,int B_width)
// 声明本地存储,暂存数组的某一个 BLOCK__local float A_local[BLOCK_SIZE][BLOCK_SIZE];__local float B_local[BLOCK_SIZE][BLOCK_SIZE];// Block indexint block_x = get_group_id(0);int block_y = get_group_id(1);// Local ID index (offset within a block)int local_x = get_local_id(0);int local_y = get_local_id(1);// Compute loop boundsint a_start = A_width * BLOCK_SIZE * block_y;int a_end = a_start + A_width - 1;int b_start = BLOCK_SIZE * block_x;float running_sum = 0.0f;for (int a = a_start, b = b_start; a <= a_end; a += BLOCK_SIZE, b += (BLOCK_SIZE * B_width)){ // 从 global memory 读取相应 BLOCK 数据到 local memoryA_local[local_y][local_x] = A[a + A_width * local_y + local_x];B_local[local_x][local_y] = B[b + B_width * local_y + local_x]; // Wait for the entire block to be loaded.barrier(CLK_LOCAL_MEM_FENCE); // 计算部分,将计算单元并行展开,形成乘法加法树#pragma unrollfor (int k = 0; k < BLOCK_SIZE; ++k){running_sum += A_local[local_y][k] * B_local[local_x][k];} // Wait for the block to be fully consumed before loading the next block.barrier(CLK_LOCAL_MEM_FENCE);}// Store result in matrix CC[get_global_id(1) * get_global_size(0) + get_global_id(0)] = running_sum;
# To generate a .aocx file for debugging that targets a specific accelerator board$ aoc -march=emulator device/matrix_mult.cl -o bin/matrix_mult.aocx --fp-relaxed --fpc --no-interleaving default --board <your-board># Generate Host exe.$ make# To run the application$ env CL_CONTEXT_EMULATOR_DEVICE_ALTERA=8 ./bin/host -ah=512 -aw=512 -bw=512 aocl program <your-board> matrix_mult.aocx./host -ah=512 -aw=512 -bw=512Matrix sizes:A: 512 x 512B: 512 x 512C: 512 x 512Initializing OpenCLPlatform: Altera SDK for OpenCLUsing 1 device(s): Altera OpenCL QPI FPGAUsing AOCX: matrix_mult.aocxGenerating input matricesLaunching for device 0 (global size: 512, 512)Time: 2.253 msKernel time (device 0): 2.191 msThroughput: 119.13 GFLOPSComputing reference outputVerifyingVerification: PASS
-END-
推荐阅读
