本文的作者是Altera(现已被英特尔收购)一位员工,文中观点虽不免偏颇,但非常有助于对整个FPGA技术有个全面的了解。
CPLD的时代
我在12年前,偶然接触PLD,没有想到自己居然就在这个行当里安身下来。可是这个行业也的确是个飞速发展的行业,十多年过去后,从当初的接近十家主要供应商,到今天已经激烈搏杀后,只有差不多如文章题目一样,成为了今天三足鼎立的局面。想来想去,决定以这个名字文章主题。同时也和大家分享我多年来的一些经历和感受。
全局布线,ISP,PLD,宏单元机构,成为PLD市场必备的武器。
CPLD时代,进入我国最早的供应商是Lattice,那个时候,也不是每个行业都用的了这种产品。首先,软件是需要收费的。这个和今天你可以轻松下载到免费的版本有很大的不同。另外,不同的授权,也决定你能使用不同的产品规模和设计语言。
90年代中,是电信行业大发展的年代。同时也是专用应用领域大发展的时代。当时pld是解决一个逻辑粘连的功能。同时由于Lattice很早进入市场,推广很成功。全局布线池的结构,对于布局布线要求不高。一度时间,很多大的通信企业,研究所,都很快成为Lattice的用户。但是,有句话说得好。“长江后浪推前浪,前浪死在沙滩上。”太早的成功也孕育着。安则危!
94年Altera已经有了一些用户。但是相对来说。还是很有局限性。另外过去的信息远远不可以与今天同日而语. 但是用过altera的工程师,已经为他的界面和功能留下了深刻的印象。96年是ALTERA在中国发力追赶的开始。当然,乱世出英雄。当时的代理商是一家香港的公司。他们很快找出这种集成电路最好的销售和支持模式。并且这种从大洋那边继承过来的方式,经过适当的改良,的确收到很好的效果。代理商有专门负责的现场应用工程师。这种方式极大方便了设计者与供应商之间的信息交流。在推广初期是否有技术支持,变得非常重要。这个时期在整个中国市场上涌现出很多非常优秀的现场技术工程师。今天已经有很多人成为这个行业的领军人物。
Lattice首开ISP技术先河,也就是今天常说的在线可编程,给所有设计者带来很大的方便。芯片在电路板上,可以直接编程调试。不用每次拔插芯片,再通过紫外线来擦写要方便得多。这个时候,Lattice还是明显占有上风的。毕竟先入为主嘛。当时主要的型号集中在Lattice ispLSI1032, 1016, Altera的EPM7128E,不过Altera已经做好了准备,因为,Altera毕竟是pld的发明者。而且也是最早采用Windows平台的开发工具。在美国市场上占有先机。他不会轻易放弃这样一个市场
当时的应用在电信领域主要是将之前的74系列的一些单元进行集成。同时加入一些控制功能。不过这个时期的产品结构都是采用mc单元结构。每个mc实际上就是相当于32到36个与非门,以Altera EPM3032为例就是认为有32*30到256*30,大致就是7000门左右,因此产品命名为MAX7000,但是当时的设计很多还在大量应用异步设计。因此,电路的结构如果能导致利用率的上升,将是更加有竞争力的表现。MC的结构就是采用先组合,后时序多个时钟输入结构。Lattice是用4个宏单元一组。altera采用8个一组。而且,altera在利用率上,稍微占有上风。同时Altera当时的maxplusII的良好界面。在97,98年的两年时间里,已经奠定在中国的基础。更深层次,Altera已经看到未来市场的需求,前面说到,成功太早有时候也不是好事。在MAX7000的铺垫下,Altera已经有了进攻Xilinx的武器,可Altera一致宣称那不是FPGA,换以一个更加中性的名字---CPLD(复杂可编程逻辑器件)。那什么是Altera的武器呢。FLEX8000!他的出现是Altera奠定今天可以和xilinx平分秋色的基础。
在1996,97年,成都,西安多家做专业领域的公司和研究单位,也使用了一些Actel,Actel的产品和那个时候的Quicklogic来说,都是属于Antifuse的技术。使用他的最大好处在当时就是有防止辐射,就是说在航空产品中可以用。但是需要你认真的仿真。如果你烧入进去设计,就只能换下一片了。而且为了烧断里面的熔丝,第三方的编程器支持的也不多。但是他们有些军用温度的产品。还是在这个领域有不错的口碑。
Actel当时的策略结构是,基本上和他们现在的论调也非常一致,就是精细颗粒,所有的DFF,还是可以靠独立的门来搭建。这个在他早先的A1020等产品系列上可以看到。而且芯片上有一部分是组合逻辑区,有一部分是时序逻辑区。另外他们的软件也是多家EDA工具的组合。特别是库的一致性不是特别通用。
Quicklogic的产品是FPGA公司中最早嵌入Synplify的商家,而且他们的LE结构是基于Mux的,底层的layout也可以清晰看到路由,资源消耗。输入法和库的建立很特别。但是也存在上面的问题。产品好像是QLxxx的,我还去应聘过一次这家公司,因为他们最早采用Synplify。而且,当时我已经感觉Synplify和雷昂纳多(拼写忘记了),以及exzampler??这个拼写也有问题。我在做FAE的时候,总是用这3个工具都综合一次,看他们哪个强。后来证明是对的。Sy是最平均的,而且简单的优点傻瓜。遗憾他也在今年被Synopsys收购了。现在Quicklogic也专注一些细分市场。
为什么要这样的结构-先组合,后时序多个时钟输入
随着科技的进步,有很多人已经忘记了很多细节,当然,我们也要遵循一个原则。难事做易,大事做细!就像朱熹说的--“问渠哪得清如许,为有源头活水来“,如果你不知道原理,碰到重要的问题,或者是设计的时候,即使成功,也是不知不觉成功,同样呢,也是不知不觉失败。
拉回话题,当你设计一个扫描电路的时候,例如,你可以采用一个时钟,输入一个计数器,然后计数器的输出,再驱动一个译码器,这样你的电路就出来了。当然事情完成了一半。功能实现了,但是,有没有更好的办法。后者换句话说。有没有适合PLD的方法。实际上用另外一个角度看,这个设计是典型的,先时序模块,才是组合电路。这个实际上,不是很和PLD本身的结构相符。还有一个问题时,随着电路速度的提高,每个译码输出之间的抖动也成为问题。就是输出的不一样的。从资源的角度来说,一个计数器,要3各单元。一个译码器,由于有8个输出,还是需要8各单元。但是如果用一个移位寄存器的方式,可以只需要8个单元。或者用状态机的方式实现,也是消耗同样的资源。可是,输出都是由于同一个时钟锁定,每个输出的延迟也比较一致。另外,当时对总线数据的译码是经常有的事情,因此,每个单元的扇入数量都是很高的。都有30个以上。因此,你设计的时候,要有两个思想:用同步设计模式,用先组合后时序的模式。后来的Xilinx的95系列更是将扇入系数扩大到90个。也是这个原因。当时PLD厂商比较的也是这些指标。
Xilinx , FPGA的发明者
Xilinx实际上成立的日期,比altera还晚了一年。但是他走的道路,从开始就注定了有今天的成就。在1996-1998,pld的高端市场,也就是FPGA市场,都是Xilinx把持,主要是xc3000/4000,当然Xilinx开创了一个新的结构,不过这种结构还是能够找到一些共同点,也是先组合,后时序。不过很重要的闪亮点是:
细颗粒查找表结构,丰富的寄存器资源,以及分段式路由布线结构,电路上电加载。当然如果这个也算是的话,那就是,他的内部甚至直接集成了三态门。这个特点是那个时代Xilinx拥趸攻击Altera,Lattice的重要工具。甚至有人说,没有这个不能实现某些电路设计的障碍。当然了,Altera, Lattice的pld也是具有三态门,不过是在输入输出管脚上。的确是不如Xilinx的来的强大和直接。有的人问了,这种结构有何好处。
电路的规模得到空前的提高。
适合做加加减减的,counter,comparter密集的设计。
无限制的更新电路。
在那个时代,衡量一个PLD很重要的指标,就是比谁的规模更大。从这个角度来看。
Xilinx无疑走到了最前面。当然,也有人说,这样的设计不可靠。这样的设计指标难以预测。还有地说这样的设计无法保密。但是市场的成功,应用需求的推动,证明这些都是杂音。
我们可以从当时xc3000的选型指南上看到。最大规模的产品,也就是今天xilinx最小的xc3s50a规模相当的东西。可是这个和当时PLD流行的规模,实在是一个飞跃。
Xilinx FPGA的架构。
Xilinx的成功,激励了Altera的新产品的推出。同时也有了革命性的突破。世界就是这么奇怪。中国古语。塞翁失马,焉知非福。实际上,如下所言,这款产品因该8282,具有282个逻辑单元的。但是在中国基本上只是在1995年有个别公司使用。

我本人经历我们开始在1997年开始大规模推广Flex10K,同年5月,位于西安的邮电部4所,是第一个采用EPF10K50的用户,当时电子杂志的广告,也有表明,Altera最先推出最大的FPGA.

实际上,这个时间就是Lattice噩梦的开始,由于设计规模的迅速攀升,规模已经是决定一个产品的关键因素。但是Lattice一直没有代表作。市场份额已经开始逐步被Xilinx,Altera蚕食。Altera的结构到底是什么革新呢?
Altera FPGA粗颗粒结构,嵌入式存储器,长联线结构.
Flex10K,他的推出,已经表明,altera的思维已经非常清晰,大规模的fpga将会是将来的王道!而且,高速的嵌入式块RAM是一个开创新的思维。当时,Xilinx凭借分布式RAM以及内置三态的结构,的确大有横扫千军的架势。但是Flex10K的出现,有效提升了Altera的FPGA产品的竞争力。在RAM需求应用不断上升的市场中。Altera迎来了市场的春天。
采用多选一,或者一对多的MUX结构,Altera推出应用指南。直到用户有效利用这种方式,实现了三态门的功能。
ESB的memory结构,是构建FIFO, DPRAM,大型查找表,都非常方便,
布线资源相对来说,以长联线资源为主。编译速度快。
Xilinx的分布式RAM尽管很灵活,但是随着RAM容量的增加,访问的速度也是递减。同时也要消耗大量的逻辑资源。这个时候,应该说Xilinx和Altera的产品已经是势均力敌。因为中国是新兴的市场。这一点表现得很明显。
规模制胜的产物
世界是运动的,粗颗粒,也是好结构!
这里又回到了我们的主题,产品的内在结构。先说细颗粒结构。当时,Xilinx的3000是以CLB为基本机构。
实际上,这个输入的个数是很有讲究的。当时,也有一种激烈的争论,就是5输入的好,还是4输入的好。在实际应用中,应该说,最小的逻辑单元是这样的规模是合理的。但是要注意一点。Xilinx和Lattice后面推出的fpga一样,两个寄存器是具有同一个时钟输入的。
粗颗粒结构,Altera还是依托自己以前在PLD的经验的积累,他的fpga有很多他的pld产品的血统。世界是基于以权制利的。因为这个时候如果已经有了Wintel的名字一样。数字电路以及CPU的发展,都和8以及8的倍数有关系。因此。这种大颗粒的结构确保:
8个逻辑单元LE为一组LAB。
每个LAB内部有独立的布线资源。确保可以实现8bit adder, shift reg, 8bit counter.
ESB,实现了存储器的资源和速度同时提高的可能。
布局布线算法比细颗粒机构的算法简单。
采用了非对称的结构,实现速度需求和控制需求的折衷。
Cyclone,Stratix,Vertex
Cyclone 的出现和FPGA的市场定位和产品定位
好的技术是需要,但是有效的市场定位和销售策略也要跟上。在2002年左右,为了更好服务各种不同市场的需要。而且当时的DSP市场仍然不太明朗,有的观望,也有大力投入。而且也有两种不同的策略。
一种是同一个器件平台,但是不同的应用区隔,例如Vertex和Spartan,有一段时间,他们可能是同一个产品平台,只是Spartan的东西就是Vertex屏蔽了一部分高级的性能,对于不使用的地方,也不需要检测,同时依靠同一个平台来维持成本优势。
另外一种,就是Altera的策略,完全依赖客人市场的需要,简化不需要的特性,推出简化的结构,面向主要的逻辑集成和LVDS信号链集成。推出Cyclone,市场反响非常强力,是Altera有史以来,市场响应最快的产品。
Altera FPGA的速度没有Xilinx的速度快,错!当然这种非对称的结构,你必须有一定的了解,才可以更好的利用。也就是要遵循:大的数据吞吐通道应该采用横向放置规划和控制通路采用纵向放置规划。
Altera至此以后,一直沿袭这种结构规划.因此,如果你想有效利用好Altera的产品,就应该遵守这个规则.但是要说明的,真正能体现性能的东西,也许就是你意识不到的一种小东西,就是简单的就是最好的.Altera正是凭借这个简单而高效的布局结构实现了今天的王道!昨天说到这里今天继续开始.又有很多时候没有提Lattice,在1998年的时候,Lattice和Altera同时都有成为PLD霸主地位的意图.什么可以证明呢,那就是谁最先推出可以ISP的宏单元超过1000个的PLD.当然在这个游戏过程中,Altera有一些变化,他有效的将他的Flex8000的布局结构和他的MAX7000进行结合.从而实现了在PLD规模扩大的同时可以实现:
规模的迅速扩大,可以比肩Xilinx的FPGA。局部的快速布线,和ISP,使其在获得规模优势的同时,保持布线延迟的稳定,沿用过去MAX7000的适配结构和FPGA的路由,实现两者有效的统一。Altera在推出他的最大的9560,具有560个宏单元的PLD,登上了无可争议的PLD冠军奖台。
当然有的人要说,Lattice有推出1000个左右,怎么不提呢。正是因为这点,导致Lattice步入歧途.实际上,FPGA世界的游戏规则已经改变了。
MAX9000的成功得益于以下的细微结构.这个时候Altera又一次将自己的颗粒度进行了扩容.有16个宏聚集在一起,在实现更多位的加法,控制,超前进位,大的多选一的应用中,可以将这些模块一次性放入一个LAB,同时在LAB内完成路由.现在已经露出一种迹象.大的规模要有,但是速度的需求已经开始了.所以在FPGA,CPLD的应用中,又有了新的裁判规则,你不仅要够大,还有够快
这个时候的异步设计还是非常的多,而且板子上芯片间信号的互联也多起来了,能够有效缩短Tsu已经成为一个重要的话题.实际上,就是在IOC上要有DFF,来进行快速锁存,同时也为所有进入CPLD的总线信号进行第一次整理.怎么实现很多的异步设计,看了下面,你就明白了.第1点,就可以用所有信号的函数输出作为clk,第2点,有效的将没有用完的资源很好借用给其他的宏,来用对称的结构实现非对称的应用!用简单的结构,应变不断的变化。
纵观当时其他的PLD,在结构上就落后很多了.你想,让你和姚明来争篮板球,如果你没有人家的身材,赢他恐怕也是嘴上的功夫了。这个时代的强者就是---谁有最多的逻辑资源,或者memory,谁就是老大。
上面说到Lattice已经在极力扩大自己的身材,但是他不是靠结构上的改变,而是Lattice收购了Vantis,也就是AMD的一个做PLD的小部门.当然在当时,AMD的Mach就这样并入了Lattice的家族.新的问题就出现了.好比我们现在有人用什么大灵通,小灵通,GSM,CDMA,是有百花齐放的感觉,但是Lattice就像变成了解放前的蒋介石,没有办法很好的用一套工具来统一使用不同的器件.而且本身Lattice自己当时的工具也是3个独立的工具拼凑在一起的.那个年代,用过Tango,后者Orcad的人都知道,他们的图形输入是第一名的,但是和MaxplusII比起来,自动识别对象链接,以及和Office 95类似的快捷键,用过Maxplusii的人,让他们转用Viewlogic等workoffice等,简直简直就是抹他们的脖子.还有当时Lattice的销售团队,总是宣扬他们是最好的PLD,有些人竟然有 "我认为64KROM,就可以应付未来所有的软件需求"这样的论调,认为PLD必将击败FPGA,事实上,市场的残酷,告诉他们那是个很冷的冬天.于是他们又一次在2000年左右,如同水淹七军一样的结局,又急忙掉转船头,收购了ORCA,可惜了ORCA是出自Lucent的一条好汉,由于没有良好的软件支撑,使得每个工程师必须像哪吒一样.对了,怎么会像哪吒?因为你必须有三头六臂,如果你公司有些产品需要从32个宏单元到2000个LE的FPGA的应用,你就必须学习3种工具来适应它.你想想,你是不是一定要像哪吒呢!
再次谈结构以及方法学。
这里开始讲些看来与我们主题有点不搭界的东西。
1--两个人相遇,只握1次手
2--三个人相遇,每人都握一次,握3次手
3--4个呢?就是2的结果加3次,6次手
4--5个呢? 10次手.
5--16个呢,.......天,不少于...
PLD就是这样的产物,当逻辑……你会发现,路由的面积都超过了有效的逻辑面积.而且,越大越糟糕.可以下载这个简单的PPT来发现一些小问题!
什么样的数目比较好,对于PLD的宏单元数目。
实践是检验真理的唯一标准.有人说了,256个是最好的结构,为什么呢,不然怎么那么多厂商都是在这个范围呢.实际上,他是由经济规律决定的,就是当时用256个的宏单元结构的芯片的面积,和他们卖出的价钱,比较符合当时这些上市公司的利润要求,所以.....就以这个最流行了.
但是Altera进行了很好的变通.中国有句话叫"玄之又玄,妙之又妙",什么是玄?玄就是变通的意思,也是变得意思.实际上万事万物都是相通的.那Altera就像我们的学校一样,每个年级分不同楼层,每个楼层分不同班级,每个班级上不同的课.但是用行列块的方式,达到既有规模,也有位置相关性.而且路由的面积也不会大到赚不到钱.实际上你自己观察,近10年 ,Altera的FPGA的主要框架是没有变化的!
Xilinx 的FPGA结构,实际上,有一个5200系列,很向Altera的Flex6000,但是没有多久这个东西就不见了.总之,Xilinx的结构属于称为 "孤岛式"结构,就是CLB在中间,路由围着这个孤岛.在一定的密度的时候 ,这种结构也还是不错的,当然有一个很重要的结构就是,他是全对称的.就是Xilinx的芯片的逻辑上资源的密集度是上小左右对称的.这个有好处,但是也有坏处.Altera的呢,是横向资源丰富,纵向资源相对较少,但是,在局部的横向上,又可以进行级联LE,DSP,Carry chain 等等. 好了,给大家举个简单的例子。
孤岛式的结构
Altera 的类似的结构,但是颗粒度大,从这张图,应该可以看出altera在横向资源是很丰富的.就是同一行的资源远多于同一列的.输入输出就更是了.当然,这个和管脚的封装脚的出位不是绝对一一对应的.
Stratix的出现
在2001年,Altera推出了他们最伟大的产品,Stratix.当时FPGA的竞争规则又发生了改变
Altera用TRAM的形式和Xilinx的分布式RAM和blockRAM竞争
Altera的PLL性能超越对手,布通率、利用率、表现突出。
但是上面这三点,都不是决定性的.这个时候,数据通信对背板走线和背板总线要求已经很高了.实际上FPGA也摇身变为系统级芯片了。
你不仅要有大的逻辑规模,合理的memory尺寸,相对丰富的时钟资源,还有就是要有高速的Serdes,缺少一项,你都会在系统级的应用中只能是亚军。
刚才说了系统级的应用,已经成了FPGA最残酷的竞争市场.那么PLD呢,怎么样了,实际上自然总是物竞天择!PLD已经变为这样的几种应用了。
就像一个国家的海军一样,PLD已经成为一些简单的驱逐舰,驰骋大洋的,可以跨海作战的,绝对不是这样的产品可以涵盖的.所以,你今天喝可乐的时候,不会有太多的选择.偶尔的一些牌子如同过眼烟云,很快就弹出你的视线了。
是的,十年前我的很多朋友,有在Quicklogic,有在Cypress,现在还有一些在不断出产品的公司,当然,只能是剑走偏锋.做些细分市场还是可以继续的.但是三国鼎立的形式已经是不可撼动的事实了。
北京和深圳的差别?
你到过我们的首都北京吗?到过我们的特区深圳吗?这样打比喻是因为我在深圳和北京都旅游或者工作过.实际上我也只是想借用这两个城市的布局来做个比喻。
北京是比较对称的城市,有东直门,西直门.有东单,西单等等.总之,他的布局就像Xilinx,无数个胡同就是像Xilinx围绕在CLB的路由线.这些资源在Xilinx的数据手册中有:
但是这些胡同间的联线并不是十分充足.特别是到了规模很大的时候.Altera的呢?在深圳的人,如果你不认路,很简单,只要你走到"深南大道,滨河大道,北环大道"上的任意一条,你就可以再从这些大道到你要去的地方.但是前提是 ,这3条大道的宽度要够.提示一点,这三条大道也是东西走向比较平行的.而且整个深圳也是一个东西走向的城市,地下再有一条地铁,在同样资源的情况下,布通率,和平均车速是非常好的.而北京的地铁,是环形的。资源上不如深圳的利用率高,这里无意于评价城市规划和道路设计,只是比喻。
Altera的FPGA就是如同深圳的道路,他可以让你从列上很自如的转到宽阔的行上,然后再到达你的目的地.所以,可以告诉你一个经验。Altera FPGA,布通率基本在95%左右,没有太大问题,Stratix最大的产品,有人有99%的布通率。
经常有这样的情况,大家选择FPGA的时候,就开始翻看每种FPGA的选型手册,然后对资源表.有的甚至直接说:我这个是10万门的.你的那个是6万门的,实际上,这些都不是很正确的评估.如同有人说,我家的房子4室两厅,你家的房子3室1厅双卫生间.到底哪个更大呢?到底哪个更节能呢. 厨房热水器之间离得很远又是问题.
所以说,学会正确的评价资源是很重要的.这个时候还要参照他的结构!!板式的,还是砖混的!!!
可能你还听说过一个使用面积的问题.实际上,有的房子看起来大,走道,不规则的布局,导致很多的地方都不能用!下面看个例子:
左边的Hops代表跨一步的意思,就是路由转换一次的意思.这个表什么意思呢.就是说在S3的路由过程中,每个路由在第一次,就可以覆盖850LEs中的一个,V5是132.如果你的逻辑,经过4跨,同样的路径覆盖的区域A的是X的2倍.代表什么呢?
布通率更高
速度更快!为什么,90nm以后,LE内部延迟已经不如路由延迟的时间长了. 所以经过的路由多,就会严重降低系统速度.
当然还有一些好事者,例如 (http://www.opencores.org)有很多公开的opencore,大家可以将它们同时尝试放在A,X,L,看谁放的多,放的快,系统延迟更小.这方便数据就不多说了,可能都成为一门学科都不一定,因为不同的比对都有benchmark的不同标准.最终我们应该很清楚的看到。
结构真的是很重要,我们能干,也要看是否站在巨人...
不过呢,很多时候,我们的朋友基本上都说:结构和我无关,我要学好VHDL,我要....codingstyle.这个设计属于系统工程!
FPGA的真正命门和Know How实际上,能做FPGA的公司太多了,但是能将我们的设计通过算法成功放到这个芯片上,而且算出正确的时间和你的仿真要求的.就不多了,说的难听点.有些领域甚至是没有亚军的竞争!选择小规模PLD,那些,不是太重要的问题.本身就不够养活一票人的产品。
Cyclone III 与 Spartan3的对决--苹果对苹果?
目前,很多人都基本上对于新的中档设计都会集中在这个系列的竞争中,换言之,在中国目前以成本为导向的第一要求下,实际上中小公司的产品选用80%是集中在这里.
经常有人说,为什么你们的LEs数目相同,价格很不同。做些解释,一家之言。
在今天,尽管是可以编程的器件,还是有不灵活的地方. 例如,你的应用决定你对什么资源敏感
不同市场也有不同的关注. 没有哪个东西绝对适合,只能是系列之间互相交叉来完成.
有一点要说,那些所谓我的是多少系统门的比较方式,是典型的大忽悠模式
比较产品有很多benchmark.这里列举一些.不全的地方,可以大家补充。
工艺
Cyclone III,65nm
Spartan3,90nm
眼前看,90nm是主流工艺,但是未来降价空间在2009年中达到轨点,另外,65nm的功耗不用说,35%的优势轻轻松松。
设计学
CycloneIII ---LP工艺,有很多人不理解这个,同样的设计采用LP和不采用就很大不同。
Spartan3--没有采用。
规模
Spartan3,3e,3a,3an,覆盖区域不同,从1K到40KLE左右
CycloneIII: 典型长中长焦距镜头,5K到120K,40K 以上,基本上Spartan3没有产品,可以用V5,V5定义为Highend,S3定义为Lowercost无线,DSLAM,医疗,平均规模在25KLE到80KLEs为最多,CycloneIII解决了有无问题。
Memory
这个是CycloneIII的幸运之处,当时可能设计上没有这么大吧。9K块,总容量绝对平均高出S为30%,块数也同样. Sp3dsp例外,但是他只有两个孩子.定焦镜头.要符合你的品味.
memory多影响到: CPU速度的提高,DSP应用,DUC,DDC,FIR等,级数上可以做更多. 速度高,还可以提高复用.
乘法器,一个18x18的乘法器,相当于350-450个LEs,当然流水的话要另外算。
PLL: Altera是模拟的,X是数字的. 恢复性和收敛速度那毫无疑问,地球人都知道模拟的好. A的时钟树更是多
布局: 从左到有,基本符合多时钟域交叉,如: LVDS入,经过第一级FIFO,进行时钟域交叉,或者数据交叉,第一次处理,然后经过中间逻辑加工,参数重加载等,然后进入乘法器,可以级联,然后有通过通用逻辑池进行加工,再次通过FIFO或者RAM来对接下一级。
其他行可以独立构成NiosII等,布局收敛性一流. 我尽量找个照片来显示。
所以不是简单说我的苹果和你的苹果一样. S3只有销价处理才是真正的出路.
如果你知道了结构,你会发现什么呢?
实际上,Altera一直在横向布线资源上浓墨重彩,因此,在Cyclone一代系列的时候,如果你的设计模块放在一个比较长的区域就更加容易跑出好性能.
如: 5行,5列的一个资源放置,不如在一个4行7列的区域中更好发挥性能.
到了CycloneII,可能就是接近1:1.2的样子。Statix,基本上接近正方形。
其他的你可能需要实验一下.毕竟这个是动手的科学。而且,每家FPGA厂商,在关键布线资源方面,都是秘而不宣.这个也是为什么Synplicity要另嫁豪门的原因!因为自己没有办法得到这些资源.而综合技术已经被FPGA厂商步步紧逼了!
Cyclone III的巧合
Cyclone III的诞生,可以说也是有划时代意义的.但是赢得偶然,其中已有些必然.下面来说说这个东西.
前面有人说过Xilinx的V5不错,但是如果说V5和StatixIII带有Serdes(串行器/解串器)的产品同时间面世的话.作为设计者,可能问题就来了。太多选择就是难以选择。
StratixIII速度快,布线好,但是没有SerdesV5速度布线都不错,出来的早,快人一步也是卖点。
但是呢?这两个产品都很贵。
由于Xilinx很重视高端用户,因此他们也认为Spartan3可以解决目前很多需要,这个也对,因此他们计划在45nm左右推出Spartan的升级产品。
Cyclone III,正好赶上高端DSP处理市场的繁荣,以前Xilinx的website上面也有这方面的迹象.号称Xilinx也是一个DSP的公司.这个也要得益于其他生态链软件系统的发展,Matlab的simulink。
另外,目前的有线系统中对Memory的需求也非常高,作为有效的缓冲也需要更多的空间。
举例来说,一个Video的应用。需要一些滤波或者其他的应用,那需要的FIR的Tap数目实际上是可大可小的.但是以前他们认为逻辑资源的比例太多于DSP的建立资源.导致很多设计用30万个LE的资源的FPGA,实际上,Logic资源利用在30%左右,而Memory仍旧显得很局促.还有一个就是用DDR2的设计也有增多的趋势。
还有就是中型设计的比重已经上升很快,就是在3年前,大家很多集中在6000个LE左右的资源.而紧接着的趋势是200个500个左右的资源和10000个LE资源的迅速两级化.另外一个增长就是50000个LE左右的区间,而这部分长期以来都是Stratix和v4,v5的传统空间.可是现在由于memory,mulitiplier的增加,导致系统性能也可以用CycloneIII实现资源换取速度和效率的方案.因此CycloneIII的资源也能利用低价格来和高端FPGA分一杯羹。
但是CycloneIII尽管有价格优势,逻辑和memory的优势,可是在Serdes的应用上,还是一片空白.这也是大家觉得他的缺憾所在。
总之,CycloneIII和Spartan3 DSPA系列的推广,已经有一个暗示的信号,就是以多块,大容量memory,Serdes可选的特点将成为新的中级FPGA市场的标杆了。
为什么Cyclone,或者说Altera的粗颗粒有一定的好处?
大家都知道,Altera的结构可以说看起来是大开大合,实际上是粗中有细。
以前一个LAB有8个LE,大家都可以理解,后来又发展成有10个LE,有16个LEs
如果你有一个计数器,假定在Cyclone里和Spartan里面跑,Cyclone和Spartan在做8位计数器方面应该是不相上下,但是,当在16位计数器还要跑同样的速度,而且保证路由资源最简单的时候,Cyclone的优势,或者说A家的优势就来了。
大家都知道,计数器就是进位翻转的传递链路是他性能的关键路径,换句话说,16位的计数器,就是两个8位计数器的级联,唯一区别的复杂度就是8位的传递时间如果是8x,那16位的就是16x了.用另外一种方式来思考:8位的计数器,在到达FE这个数字的时候,就用一个DFF进行一次隔离,提前一个时钟节拍将进位准备好,这样就将一个16位的计数器的复杂度降低到了8位一个样子.可是原本Cyclone的LAB就有10个LE,因此为了防止毛刺的问题以及刚才需要一个插入的DFF(D触发器),就刚好放在一个LAB里面,LAB(可配置逻辑模块(CLB))里面的路由是最快的,而且编译基本不太花时间.同时也为设计流水线的译码技术,提供两级的DFF延迟,但是这些全部做到了放在一个LAB。
大家回顾一下我们的设计,不就是计数器,加多选一,什么FSM就是那几个玩意来回的组合.然后中间加流水,再平衡流水寄存器之间的路由.没有新的发明,只有新的组合.但是Altera这样的结构就相对来说..哈哈又要吹一下牛皮了。
过去10年FPGA产业的发展和FPGA厂商的挑战?过去10年。FPGA产业发生了些重要变化?简要回答:逻辑数量超过10年前50倍,存储容量超过100倍,Serdes速度接近10G(Xilinx6.5G),消耗功耗只提高10倍多些。
FPGA三国志第三篇
SOPC篇
PLD的重新定义PLD是什么,Programmable LogicDevice.当然今天应该换个称呼了:Processor+ Logic+DSP了,世界就是这样不停的变化来维持他的稳定。
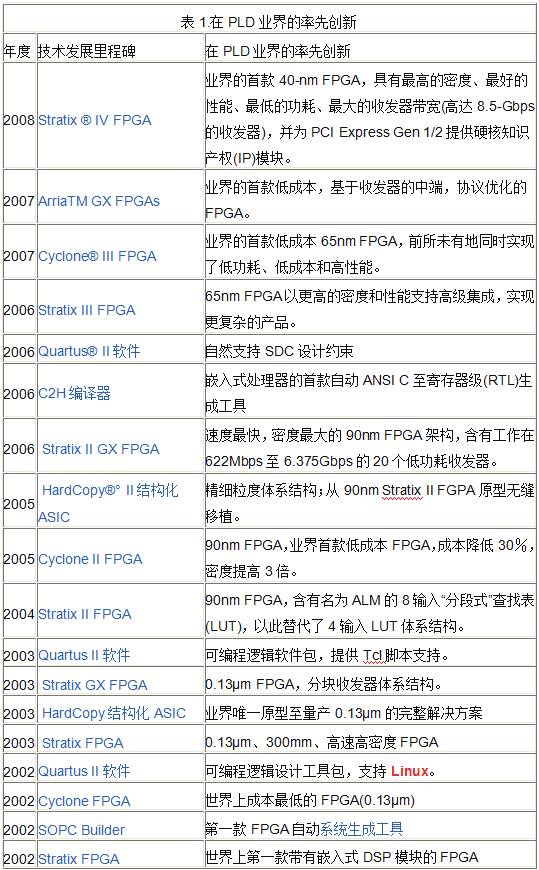
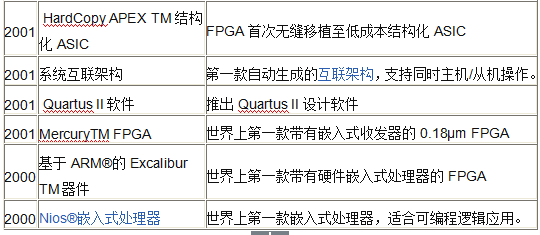
表1列出了Altera®可编程解决方案的主要历史创新发展过程。,可以看到在2000年的时候,FPGA的厂商已经开始在嵌入式微处理器方面开始崭露头脚。当然起初引来的也有一片哗然。说效率低下,难以开发。新鲜事物的诞生总是要经过这样的阵痛期。
在2002年,就有众多厂家出来声称都支持嵌入式软核CPU。甚至也和当时流行的8051 turbo以及一些ARM进行比较。
处理器嵌入在FPGA中,需要什么样的温床?
的确,在推出Nios soft processor两年之后,在我们周边也开始陆续有开始吃螃蟹的了。但是,还是回到结构的老话题上,来谈论一下为什么这个时候出现了由FPGA制造商推出的CPU,实际上在1997年,就已经有什么FPGACPU的说法甚嚣尘上。而且也有人在Xilinx和Altera上面分别实现了原形。
开始在FPGA嵌入大块RAM的时候,很多人抨击这种结构,只是一个动物园里面的老虎,实际上就是和猫差不多的杀伤力。不可以否认,它不如分布式RAM来的灵活,但是它可以作为一些Cache(高速缓冲存储器),或者是紧耦合的RAM,还有就是它的规模在容量增加的时候,仍旧有很好的速度,那就可以作为CPU的Cache了。Altera的RAM都是做在同一列的,很方便级联。另外总线宽度也很容易更改。
还有就是CPU里面总是有很多总线,内部总线。由于丰富的行联线的存在,在几列行资源里,就可以轻松集成RAM,CPU要的逻辑资源,以及总线的结构。这样,CPU也就顺利的在FPGA的世界里粉墨登场了。虽然起初只是16bit的。
2002年,Altera的开发软件已经趋于稳定,可以说已经很适合自己产品的结构,而且布线效率非常高。同时Altera的Nios也上升为NiosII,这个时候NiosII已经蜕变为美丽蝴蝶---一个32bit的RISC CPU(精简指令集计算机)。而且Altera又采用了非对称的机构实现了革命性的Avlon互联体系。关于这个体系的由非对称可以覆盖对称的,或不对称性的应用,我们以后详细聊。总而言之。如果再有一款更好结构的低成本的FPGA,那无异于在FPGA市场上刮起一场飓风!
Xilinx有Microblaze,其他的有ARM的核,实际上FPGA上实现的CPU,不是由一个CPU的内核来决定他的应用,而是谁有最好的互联体系,能和外围设备,和FPGA中的RAM,乘法器,以及其他定制逻辑更好桥接,粘合成一个SOPC,那才是真正意思上的软核。那究竟什么样子才好呢?
可以增加多个核来弥补自己速度上的缺陷,提高更多的并行处理,灵活的总线结构,可以连接高速,慢速,master,salve的模块,可以将客制化的逻辑,有效集成到CPU的指令体系。
有面向不同应用,可以进行裁剪的CPU core方便片上调试的环境。
可以快速自动实现外设资源冲突仲裁的机制,可以实现以软代硬,或者以硬代软,在软硬间转化速度与资源的偏重,如果有以上的特性,那相信留给设计者的只有是无限的遐想空间。
FPGA上的CPU,有太多的元素,你知道吗?
我们从哪里开始讲呢,准备从算盘开始讲CPU,很多人说,我是不是太无聊了呢?听我明天说给你听!看似简单的算盘,绝对孕育着无比的大智慧。看是简单的Avalon,也同样有很多玄机。那就是变变变。
来自Xilinx的消息,关于CPU在FPGA设计中的一些预测。
神奇的算盘
上回说到算盘。实际上大家应该都见过这个了不起的发明,只是他出现在你的记忆中的次数越来越少,就忘记了,实际上,很多伟大之处在很早就有历史可以证明的。看看你平时见到的算盘。
算盘的妙处和Altera的LE排列布局非常相似,或许是巧合吧。
但是这里的偶然也有些必然。或许我们有一天说,FPGA的结构最早是源于我国的。哈哈,玩笑啊。
可以增加多个核来弥补自己速度上的缺陷,提高更多的并行处理
一个算盘是算盘,级联起来还是算盘,可以横向,也可以纵向
灵活的总线结构,可以连接高速,慢速,master,salve的模块
算盘是平行也是并行结构,上面的有两个珠子,下面5个,2也可以代表10,5也可以代表10,同时,进位时也可以暂时存储在高档位,也可以留在本档。进位链和Altera LE的进位布局也是一样。
看一个更久的照片,当然这个也可以代表Cyclone的layout了。
Avalon的奥秘
全交叉,部分交叉型(适合FPGA中的嵌入总线!)
Xilinx的是共享总线型。仍旧属于传统型设计,只是将其搬移到了FPGA中。
处理器接口主要抽象为:
共享寄存器
RAMs
FIFOs
回头看Avalon,上面看起来,这两个softcore都差不多。
总线结构是SOPC的最重要的战场,也是区分SOPC是否高效的关键因素!
1--说到SOPC,最基本的集成首先是CPU的内置,但是CPU的有下列因素决定总线结构。
CPU---冯诺依曼结构,CISC体系多采用这种方式,特点,就是指令功能强大,总线结构复杂,堆栈结构设计庞大。因为要解决所有Master和Salve之间的运算和重写,另外寻址模式非常丰富。缺点是酒?峁垢丛樱?面积偏大,面积偏大导致这类CPU的频率不能太高!
CPU--哈佛结构,总线独立,能够提高并行,基本上以数据流加工为主。所以DSP,以及一些RISC的体系也很多 。
这里声明,RISC,CISC和CPU结构无必然联系。
简单说来:RISC是以总线结构越少越好,通络尽可能简单。例如大部分指令面向寄存器,然后数据操作多数在寄存器完成。有很多甚至基于堆栈。
共享总线的速度设计与性能总结:
完成相对高的总线频率
相对低廉的成本
不能并行!(这个是缺点)
共用的仲裁结构(缺点,反应速度慢)
所有主设备对从设备的存取都存在竞争关系(同时访问时候)
当然在FPGA中,双向三态的实现是依靠多选一和DFF的隔离来实现的,而且,多数为同步设计。当然在现代分离系统的设计中,已经很早有这样的先例。
例如一个ARM和TI的DSP进行协同的系统,TI DSP中有对总线进行释放的功能机制,释放的时候,可以由ARM来对DSP中的数据结果进行交换,或者是操作参数的更新。然后再将总线控制权返回给主控的ARM.在FPGA中,也是同样的道理。
NIOS II的总线结构Avalon是具有全数字交叉的总线结构,支持多主并发的结构。
FPGA中,由于FPGA中丰富的互联结构,以及FPGA中本身的逻辑胶合的本身设计定位,决定了在FPGA中的SOPC的总线结构:全数字交叉的互联结构是SOPC在FPGA中性能发挥的调节棒!
很多人对此有以下担忧:
仲裁结构复杂,
规模过于庞大
对设计工具要求高(每次互联设计,可能要修改太多东西)
Altera采用了一个折中的方式就是部分数字交叉结构。
而且将仲裁机制放在了从端,这样做的好处,就是有冲突访问可能的从设备,就对他增加仲裁,好处:
降低了总线规模
提高并行性
仲裁效率高
没有优良的总线结构,一切都是空谈,有效的机制,可以弥补CPU的性能的低能化!
总线接口的抽象!Xilinx和Altera志同道合,尽管总线接口的抽象不同,但是,不代表总线结构一致。X是总线共享型,A是数字交叉型。
例如Avalon-MM,Avalon-SM,Xilinx是PBv,和Fastlink来对应,MM是意思采用存储地址映射抽象,就是将所有端口定义为可以用内存地址来寻址操作。而SM是代表流媒体数据型,也就是一般和DMA都有一定的联系,当然,也是一种要不就是不断接收数据流,要不就是发送数据流的接口。例如,VGA的数据缓冲,DSP信号数据的输入和输出,例如AD数据的输入,以及DA的输出,同时具有FIFO功能。
并行,并行,再并行。
FPGA中用的设计语言,VHDL,Verilog HDL等,这些都是并行的,FPGA之所以能在很多DSP领域进行大显身手,也是因为他良好的并行扩展性。那同样。在SOPC中,要提高系统的整体性能,还是要并行,并行再并行!
上面就结构已经进行了简单的说明。那么在数据处理的单元上如何设置呢。
1---动态总线宽度的适应。
当你要将32bitNIOS和8bit,或者16bit的系统进行连接的时候,他应该能自动适应!
2--增加多个主控单元,对一些控制进行有效并发。
归纳为三点:
多增加CPU的个数,SOPC支持多CPU,而且现在很多CPU也在发展多核。商用PC已经很成熟了。
多增加DMA的通道个数,这样CPU可以干别的事情,至少数据吞吐加大
增加PCI-e的设备,这样,NIOS,FPGA不方便处理的,可以通过这样的接口进行功能上的折中。当然以后也可以增加RapidIO来和TIDSP进行数据的互换。
3--创建分离的数据通路
4--用多DMA进行辅助。例如
没有新的发明,只是新的组合!
实际上今天很多所谓的创新,也就是一些不同设计元素的合并和组合。TSMC,在20年前开始代工的时候,有很多人质疑这种方式,实际上这个是一种商业模式的创新。
Altera是前期一些Fabless的厂商之一,很多人也怀疑没有自己的工厂?怎么可以做好产品。但是回顾今天,大家不都是走这样的路吗。当然也有一些自己领域的佼佼者,内存,CPU还是自己开灶。
话题拉回,当你一个系统已经不方便的时候,或者是某种功能要求有很突出表现的时候,两个或者多个CPU的系统,或者是拆解再增加必要的子系统。也是一种创新。
分割为多个子系统的好处:
由于分割后,从设备可以分在不同的有限个主设备中,提供并行,降低冲突。
从系统之间耦合较松,就是说可以依靠共享内存,消息传递,信号灯互锁,FIFO等机制进行同步和信息交换。
一生二,二生三,三生万物.....
现在的工具都很方便复制和例化多个功能单元。当你设计好一个上面的系统的时候,你也可以将他们又构成一个模块,然后复制这些模块来达到更大的系统。这种在DSLAM的设计,或者是多路以太网复用到光设备等经常应用。
因此,
一生二,二生三……
当然这种思想是建立在大批量复制功能单元的策略。另外,还有一种大家熟悉的方式,就是提高局部的流水动作以提高系统吞吐。你不仅要有火尖枪,同时也要有混天绫。互相配合才是自然之道。
流水的数据操作分为两类:
读流水
写流水
读流水和写流水主要是针对目前的一些存储外设来设计的,就是一个主设备可以在第一读的动作发生,但是没有数据返回的前提下,连续发出多个读的动作,然后在适当的时钟延迟后,连续得到由连续发出读的指令而产生的返回数据序列。好处是,用个图来表达就明白了。
当然了,你可能说,这个说易行难,设计经验不足。没有关系,SOPCbuilder的master和Slave接口,已经将这些都做好了。如果你想自己设计一个,实际知道这样的时序,你也可以的。不外乎就是要做一个读和返回地址的计数器,计数器的差值是在Readdatavalid的返回时候发出的地址数目,当然你也要设计好数据的宽度
ARM Vs Nios II
大家对ARM和NiosII喜欢比较,今天就说上几句。
最快的NiosII (250Mhz)比ARM7快,
最小的NiosII比最小的ARM7要小
另外NiosII已经有了MMU,而且对Linux进行了支持
ARM7是把西瓜刀
NiosII是把瑞士军刀。NiosII做一个分型算法借助C2H,速度是ARM7的400倍,不算慢。但是ARM7的生态资源广,这两个应用实际上是相辅相成。
FPGA的公司实际上换而言之,也可以成为EDA的公司了,只是他们在这方面的能力是否强大而已.这3家公司中,拥有自己HDL的公司只有Altera.可能很多人不太清楚,就是AHDL,当然这种语言的辉煌期已经过去了.这里说这个,绝对不是鼓励大家用这个语言.
这3家主要的开发软件大家都知道,在中国应该以Quartus II用的最广.ISE次之.但是现在这两大软件的外观都已经有些一致的地方了.但是他们近乎同样外观的软件,却还是有很多地方非常不同.
Altera 在2000年前,在日本市场独领风骚.大家知道日本是漫画的国度,他们总是喜欢用图形表达,这可以证明Altera的图形输入做的是炉火纯青.但是,现在都是语言输入为主导了,因此Altera的这个优势才渐渐淡化.但是其他图形界面仍旧有其鲜明的特色,简单容易.
Altera的软件像Canon的相机,很傻瓜,对着景物按个快门.当然也有些地方,你也可以仔细微调.
Xilinx的软件洋洋洒洒,很专业,像部哈苏相机,你在照相前,先成为相机的专家,才能成为设计的专家.有人开玩笑了,这是拿东西来说事.那在这里引用Altera公司一些思想,给大家介绍一下.实际上,这个特点非常容易记忆.大家都知道TIPS这个单词吧,就是提示的意思.那在这里就给你一些提示,让你可以过目不忘!
TIPS---提高设计效能的秘方!
这几天准备一下,尽快让大家看到下面的章节!
从TIPS中的T开始说,FPGA的趋势如下
1--首先说一下眼前的大环境是怎么影响你的设计的.过去的设计规模应该是比较小,一个FPGA工程师,写个状态机,写个好的代码,这个就是相对来说的高手了.但是你要知道这种高手都是关起门来自称老大的.实际出门走多远很难说.因为现在器件的发展速度是很快的.
2---规模的变化
1998---一位当时的PLD的厂商说世界上有1000个宏单元的PLD就可以应付95%的设计了.今天你认为怎样?
1998---最大的FPGA内含10000LEs,今天的CycloneIII的第二小的家伙就是这个身段.
2008年---现今最大的FPGA内含530,000LEs,比1998年增大50倍!你还能用以前的设计方式来应付今天这个庞然大物吗?
3---规模的变化,带来复杂度的提高,调试也成为关键?
芯片规模大的时候,你就会要有些测试工程师的需求.因为人自己总是看不清自己的缺点.
4---一个模块跑个固定的速度,是否可以和其他模块都配合起来,还能保持性能?
目前EDA厂商众口一辞的话:20KLEs规模以上的设计,时序收敛是第一目标
当有问道Xilinx的软件设计者时候 ,他们也承认了这样的事实:
好了,第一个题目诞生了.T-IPS 中的T就是TimeQuest,以前FPGA的规模和设计ASIC不能相比,今天已经可以了.在FPGA中集成很多IP已经不是什么难题了.TimeQuest是依照SDC来进行工作的,SDC,是ASIC中设置约束的工具,换言之,也算是你如何指挥你的软件,将你设计的模块让他们统一协调好时间,然后保证最终的结构是你想要的.你不仅要看到设计,还要跑到那样的速度的时候,他还是你要的功能 ,有人说了,以前没有这样的工具吗?有,但是那不是针对大的设计的.当然大也是相对的,到了一定的规模,就必须使用另外的标准了!什么能帮助你达到时序收敛,什么可以加速你找到哪些地方不满足,TimeQuest!
目前支持这个SDC的有以下工具,当然Quartus支持的最完整.潜在的秘密是,Altera的器件的规模也是最大的了.
Altera -TimeQuest à SDC based Timing analysis
Actel – Offers preliminary SDC support
Xilinx & Lattice – No SDC support
可能你会问,能不能详细点说一下:
TimeQuest是Altera第二代的时序分析工具
你不需要记忆什么语法,完全的GUI界面,而且也支持模板输入功能.
他生成的约束是基于Synopsys的工业标准的.
TIPS中的I是指"递增编译",就是英文"Incremantalcompile"的第一个字母是I。
刚才说了,当你有时候改动了一部分设计的时候,你以前好不容易调好的时序,可能因为重新改动的影响,而在编译路由后,将没有改动的设计在布局和速度上发生了不期望的改变.那这个递增编译就是干这个的.他可以向制导武器一样,让你指哪里,打哪里.同时缩短编译时间,提高你的工作效率!当然这里绝非这么一句话就可以涵盖了.你也要有设计分离,规划布局等工作。
现在经常有提到我的产品是最好的Price,但是,现在由于系统规模增大,Power也是一个很重要的制约,功耗在某些设计中甚至是第一位的.Quartus中有关于根据Power的要求来智能编译设计的约束.就是TIPS中的P,也就是PowerPlay。
最后一个TIPS中的S就是指Systemlevel,或者是SOPC,因为你的设计可能要有各种接口,外部的,内部的,系统的互联.总线的对接,时钟域的交叉,这些,都可以用SOPC的工具SOPC builder来实现.不用内置处理器也可以.同时要求你在系统级的高度进行设计,这样就提高设计速度.在第三篇中有详细讲.
生产力发展的标志-生产工具,你现在和15年前设计方式的根本改变!
不管A,X,L,哪一家FPGA玩家,这三年来都在开发工具上投入了重兵.此前有网友争论--
Lattice用的是Synplify进行的综合,效果如何如何高.这个论调10年前是天经地义,颠覆不破的真理,但是今天再这样说,绝对偏颇!
Synplicity公司不少人后来都转投Altera门下.当时Sy最先得到Xilinx的结构的时候,大力发展所谓物理综合等一系列亮点,但是却对Altera提及甚少,大家都知道Sy的发家史,失去了FPGA厂商的支持,基本上也就失去温床.在2004年QuartusII4以后,Quartus的综合能力就已经与S家的不相伯仲了.Xilinx在10年前收购多家EDA厂商,例如StateCAD,当时用流程图生成状态机的VHDL和其他的一些厂商的时候,Quartus都是建立在自己的固有体系下.如果单独从产品器件上,只有工艺和功耗是未来需要争斗的地方,那么,综合能力和相关路由(就是紧耦合的模块放在一起)能力,以及EDA工具的全面性才是真正FPGA厂商的绝对命门.S家一共有250个软件开发人员.A家可能就远远不止了。
另外Cadence,Synopsys,Magma,Mentor等大哥,也就是卖个综合和核对工具,价值点相信大家已经悟到几分吧.
QuartusII 在今天,作为FPGA摄影大师的工具来说,不仅是精密的哈苏,更是Canon门下Eos MarkII的便捷傻瓜的代表。QuartusII就是今天FPGA的第一生产力。
-end-
来源:FPGA之家。如有问题,请联系我们,谢谢!
【1】I2C和SPI总线,嵌入式工程师爱用哪个?
【2】单片机软件抗干扰的这几种办法,以后不能说不知道了
【3】终于整理齐了,电子工程师“设计锦囊”,你值得拥有!
【4】半导体行业的人都在关注这几个公众号



