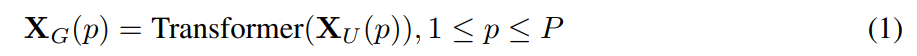点击上方↑↑↑“OpenCV学堂”关注我
来源:公众号 机器之心 授权
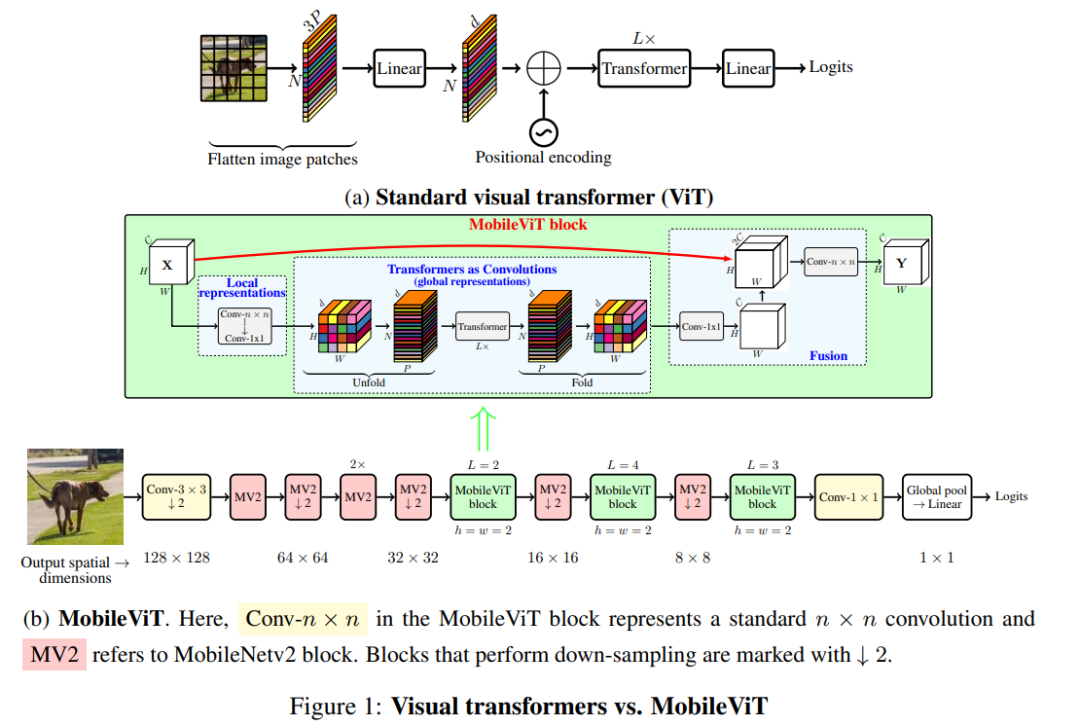
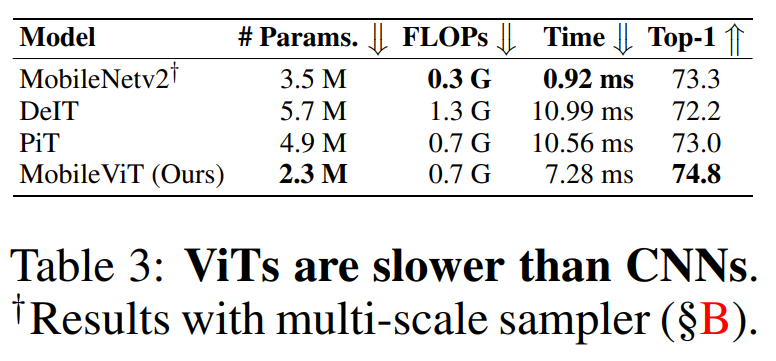
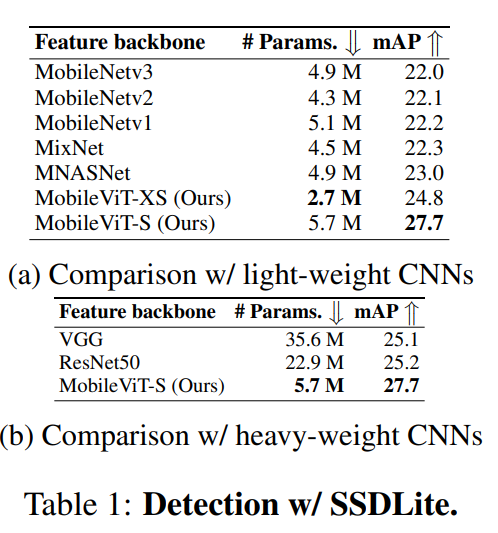
在这篇论文中,来自苹果的研究者提出了一种用于移动设备的轻量级通用视觉 transformer——MobileViT。该网络在 ImageNet-1k 数据集上实现了 78.4% 的最佳精度,比 MobileNetv3 还要高 3.2%,而且训练方法简单。目前,该论文已被 ICLR 2022 接收。

论文链接:https://arxiv.org/pdf/2110.02178.pdf
代码链接:https://github.com/apple/ml-cvnets