

特斯拉的纯视觉方案
Tesla在2021年的AI Day上展示了一个纯视觉的FSD(Full Self Driving)系统。虽然说只能算是L2级别(驾驶员必须做好随时接管车辆的准备),但如果只是横向对比L2级的自动驾驶系统,FSD的表现还是不错的。此外,这个纯视觉的方案集成了近年来深度学习领域的很多成功经验,在多摄像头融合方面很有特点,个人觉得至少在技术方面还是值得研究一下。
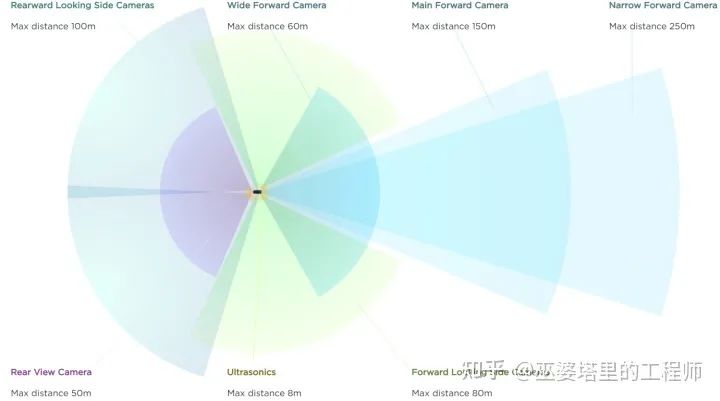 Tesla FSD系统的多摄像头配置
Tesla FSD系统的多摄像头配置
这里再稍微跑个题,说一下Tesla AI和Vision方向的负责人,Andrej Karpathy。这位小哥1986年出生,2015年在斯坦福大学获得博士学位,师从计算机视觉和机器学习界的大牛李飞飞教授,研究方向是自然语言处理和计算机视觉的交叉任务以及深度神经网络在其中的应用。马斯克2016年将这位青年才俊召入麾下,之后让其负责Tesla的AI部门,是FSD这个纯视觉系统在算法方面的总设计师。
Andrej在AI Day上的报告中首先提到,五年前Tesla的视觉系统是先获得单张图像上的检测结果,然后将其映射到向量空间(Vector Space)。这个“向量空间”是报告中的核心概念之一,我理解其实它就是环境中的各种目标在世界坐标系中的表示空间。比如对于物体检测任务,目标在3D空间中的位置,大小,朝向,速度等描述特性组成了一个向量,所有目标的描述向量组成的空间就是向量空间。视觉感知系统的任务就是将图像空间中的信息转化为向量空间中的信息。这可以通过两种方法来实现:一是先在图像空间中完成所有的感知任务,然后将结果映射到向量空间,最后融合多摄像头的结果;二是先将图像特征转换到向量空间,然后融合来自多个摄像头的特征,最后在向量空间中完成所有的感知任务。
Andrej举了两个例子,说明为什么第一种方法是不合适的。首先,由于透视投影,图像中看起来不错的感知结果在向量空间中精度很差,尤其是远距离的区域。如下图所示,车道线(蓝色)和道路边缘(红色)在投影到向量空间后位置非常不准,无法用支持自动驾驶的应用。
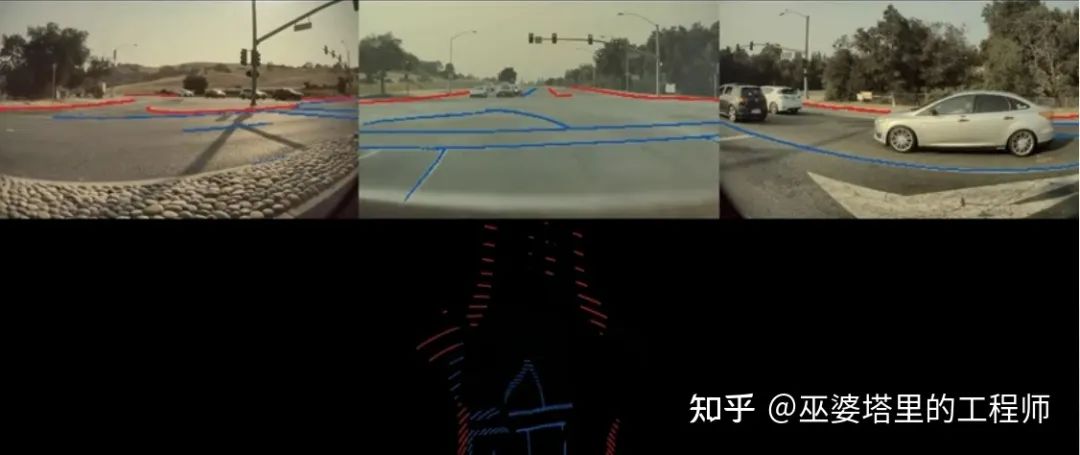 图像空间的感知结果(上)及其在向量空间中的投影(下)
图像空间的感知结果(上)及其在向量空间中的投影(下)
其次,在多目系统中,由于视野的限制,单个摄像头可能无法看到完整的目标。比如在下图的例子中,一辆大货车出现在了一些摄像头的视野中,但是很多摄像头都只看到了目标的一部分,因此无法根据残缺的信息做出正确的检测,因此后续的融合效果也就无法保证。这其实是多传感器决策层融合的一个一般性问题。
 单摄像头受限的视野
单摄像头受限的视野
综合以上分析,图像空间感知+决策层融合并不是一个很好的方案。直接在向量空间中完成融合和感知可以有效地解决以上问题,这也是FSD感知系统的核心思路。为了实现这个思路,需要解决两个重要的问题:一个是如何将特征从图像空间变换到特征空间,另一个是如何得到向量空间中的标注数据。
特征的空间变换
对于特征的空间变换问题,一般性的做法就是利用摄像头的标定信息将图像像素映射到世界坐标系。但这是个病态问题,需要有一定的约束,自动驾驶应用中通常采用的是地平面约束,也就是目标位于地面,而且地面是水平的。这个约束太强了,在很多场景下无法满足。
Tesla的解决方案中核心的有三点。首先,通过Transformer和Self-Attention的方式建立图像空间到向量空间的对应关系,这里向量空间的位置编码起到了很重要的作用。具体实现细节这里就不展开说了,以后有时间再单开一篇文章详细的介绍。简单来理解的话,向量空间中每一个位置的特征都可以看作图像所有位置特征的加权组合,当然对应位置的权重肯定大一些。但是这个加权组合的过程通过Self-Attention和空间编码来自动的实现,不需要手工设计,完全根据需要完成的任务来进行端对端的学习。
其次,在量产应用中,每一辆车上摄像头的标定信息都不尽相同,导致输入数据与预训练的模型不一致。因此这些标定信息需要作为额外的输入提供给神经网络。简单的做法可以将每个摄像头的标定信息拼接起来,通过MLP编码后再输入给神经网络。但是,一个更好的做法是将来自不同摄像头的图像通过标定信息进行校正,使不同车辆上对应的摄像头都输出一致的图像。
最后,视频(多帧)输入被用来提取时序信息,以增加输出结果的稳定性,更好的处理遮挡场景,并且预测目标的运动。这部分还有一个额外的输入就是车辆自身的运动信息(可以通过IMU获得),以支持神经网络对齐不同时间点的特征图。时序信息的处理可以采用3D卷积,Transformer或者RNN。FSD的方案中采用的是RNN,以我个人的经验来看,这确实也是目前在准确度和计算量之间平衡度最好的方案。
通过以上这些算法上的改进,FSD在向量空间中的输出质量有了很大的提升。在下面的对比图中,下方左侧是来自图像空间感知+决策层融合方案的输出,而下方右侧上述特征空间变换+向量空间感知融合的方案。
 图像空间感知(左下) vs. 向量空间感知(右下)
图像空间感知(左下) vs. 向量空间感知(右下)
向量空间中的标注
既然是深度学习算法,那么数据和标注自然就是关键环节。图像空间中的标注非常直观,但是系统最终需要的是在向量空间中的标注。Tesla的做法是利用来自多个摄像头的图像重建3D场景,并在3D场景下进行标注。标注者只需要在3D场景中进行一次标注,就可以实时的看到标注结果在各个图像中的映射,从而进行相应的调整。

3D空间中的标注
人工标注只是整个标注系统的一部分,为了更快更好的获得标注,还需要借助自动标注和模拟器。自动标注系统首先基于单摄像头的图像生成标注结果,然后通过各种空间和时间的线索将这些结果整合起来。形象来说就是各个摄像头凑在一起讨论出一个一致的标注结果。除了多个摄像头的配合,在路上行驶的多台Tesla车辆也可以对同一个场景的标注进行融合改进。当然这里还需要GPS和IMU传感器来获得车辆的位置和姿态,从而将不同车辆的输出结果进行空间对齐。自动标注可以解决标注的效率问题,但是对于一些罕见的场景,比如报告中所演示的在高速公路上奔跑的行人,还需要借助模拟器来生成虚拟数据。以上所有这些技术组合起来,才构成了Tesla完整的数据收集和标注系统。
视觉+激光雷达方案
几乎是在同期,毫末智行也提出将Transformer引入到其数据智能体系MANA中,并逐步应用到实际的道路感知问题,比如障碍物检测、车道线检测、可行驶区域分割、交通标志检测等等。从这一点上就可以看出,量产车企在有了超大数据集作为支撑以后,其技术路线的趋同性。在自动驾驶技术百花齐放的时代,选择一条正确的赛道,确立自身技术的优势,无论对于特斯拉还是毫末智行来说都是极其重要的。
在自动驾驶技术的发展中,一直就对采用何种传感器存在争论。目前争论的焦点在于是走纯视觉路线还是激光雷达路线。根据第一性原则,特斯拉采用纯视觉方案,这也是基于其百万量级的车队和百亿公里级别的真实路况数据做出的选择。采用激光雷达,主要有两方面的考虑。第一,数据规模方面的差距其他自动驾驶公司很难填补,要获得竞争优势就必须增加传感器的感知能力。目前半固态的激光雷达成本已经降低到几百美元的级别,基本可以满足量产车型的需求。第二,从目前的技术发展来看,基于纯视觉的技术可以满足L2/L2+级别的应用,但是对L3/4级的应用(比如RoboTaxi)来说,激光雷达还是必不可少的。
在这种背景下,谁能够既拥有海量数据,又能同时支持视觉和激光雷达两种传感器,那么无疑会在竞争中占据先发的优势。根据毫末智行CEO顾维灏的在AI Day上的介绍,MANA系统采用Transformer在底层融合视觉和激光雷达数据,进而实现空间,时间,传感器三位一体的深层次感知。
视觉感知模块
相机获取原始数据之后,要经过ISP(Image Signal Process)数字处理过程后,才能提供给后端的神经网络使用。ISP的功能一般来说是为了获得更好的视觉效果,但是神经网络其实并不需要真正的”看到”数据,视觉效果只是为人类设计的。因此,将ISP作为神经网络的一层,让神经网络根据后端的任务来决定ISP的参数,并对相机进行校准,这有利于最大程度上保留原始的图像信息,也保证采集到的图像与神经网络的训练图像在参数上尽可能的一致。
处理过后的图像数据被送入主干网络(Backbone)。毫末采用的DarkNet类似于多层的卷积残差网络(ResNet),这也是业界最常用的主干网络结构。主干网络输出的特征再送到不同的头(Head)来完成不同的任务。这里的任务分为三大类:全局任务(Global Task),道路任务(Road Tasks)和目标任务(Object Tasks)。不同的任务共用主干网络的特征,每个任务自己拥有独立的Neck网络,用来提取针对不同任务的特征。这与特斯拉HydraNet的思路是基本一致的。但是,MANA感知系统的特点在于为全局任务设计了一个提取全局信息的Neck网络(Global Context Pooling)。这一点其实是非常重要的,因为全局任务(比如可行驶道路的检测)非常依赖于对场景的理解,而对场景的理解又依赖于全局信息的提取。
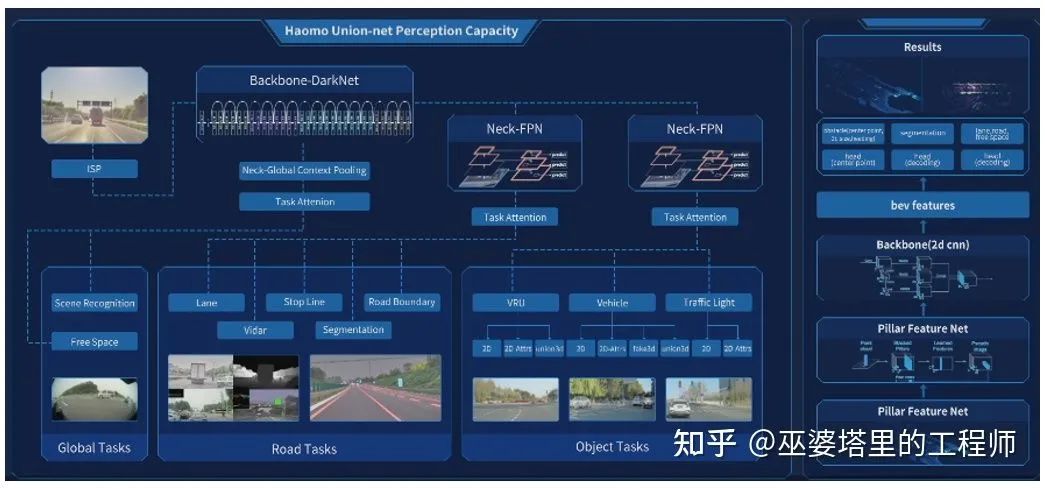
MANA系统的视觉和激光雷达感知模块
激光雷达感知模块
激光雷达感知采用的是PointPillar算法,这也是业界常用的一个基于点云的三维物体检测算法。这个算法的特点在于将三维信息投影到二维(俯视视图),在二维数据上进行类似于视觉任务中的特征提取和物体检测。这种做法的优点在于避免了计算量非常大的三维卷积操作,因此算法的整体速度非常快。PointPillar也是在点云物体检测领域第一个能够达到实时处理要求的算法。
在MANA之前的版本中,视觉数据和激光雷达数据是分别处理的,融合过程在各自输出结果的层面上完成,也就是后融合。这样做可以尽可能的保证两个系统之间的独立性,并为彼此提供安全冗余。但是,后融合也导致神经网络无法充分利用两个异构传感器之间数据的互补性,来学习最有价值的特征。
融合感知模块
前文提到了一个三位一体融合的概念,这也是MANA感知系统区别于其他感知系统的关键之处。正如顾维灏在AI Day上所介绍的,目前大部分的感知系统都存在“时间上的感知不连续、空间上的感知碎片化“问题。
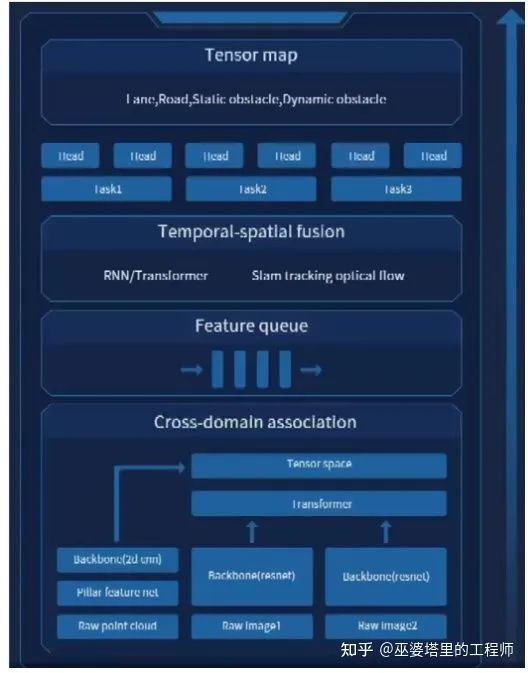
MANA系统的融合感知模块
空间上的不连续是由多个同构或异构传感器所在的不同空间坐标系导致的。对于同构传感器(比如多个摄像头)来说,由于安装位置和角度不同,导致其可视范围(FOV)也不尽相同。每个传感器的FOV都是有限的,需要把多个传感器的数据融合在一起,才可以得到车身周围360度的感知能力,这对于L2以上级别的自动驾驶系统来说是非常重要的。异构传感器(比如摄像头和激光雷达),由于数据采集的方式不同,不同传感器得到的数据信息和形式都有很大差别。摄像头采集到的是图像数据,具有丰富的纹理和语义信息,适合用于物体分类和场景理解;而激光雷达采集到的是点云数据,其空间位置信息非常精确,适合用于感知物体的三维信息和检测障碍物。如果系统对每个传感器进行单独处理,并在处理结果上进行后融合,那么就无法利用多个传感器的数据中包含的互补信息。
时间上的不连续是由于系统按照帧为单位进行处理,而两帧之间的时间间隔可能会有几十毫秒。系统更多地关注单帧的处理结果,将时间上的融合作为后处理的步骤,比如采用单独的物体跟踪模块来单帧的物体检测结果串联起来。这也是一种后融合策略,因此无法充分利用时序上的有用信息。
那么如何解决这两个问题呢?答案是用Transformer做空间和时间上的前融合。
先说空间前融合。与Transformer在一般的视觉任务(比如图像分类和物体检测)中扮演的角色不同,Transformer在空间前融合中的主要作用并不是提取特征,而是进行坐标系的变换。这与特斯拉做采用的技术有异曲同工之处,但是毫末进一步增加了激光雷达,进行多传感器(跨模态)的前融合,也就是Cross-Domain Association模块。前文介绍了Transformer的基本工作原理,简单来说就是计算输入数据各个元素之间的相关性,利用该相关性进行特征提取。坐标系转换也可以形式化为类似的流程。比如说需要将来自多个摄像头的图像转换到与激光雷达点云一致的三维空间坐标系,那么系统需要做的是找到三维坐标系中每个点与图像像素的对应关系。传统的基于几何变换的方法会将三维坐标系中的一个点映射到图像坐标系中的一个点,并利用该图像点周围一个小的邻域(比如3x3像素)来计算三维点的像素值。而Transformer则会建立三维点到每个图像点的联系,并通过自注意力机制(也就是相关性计算)来决定哪些图像点会被用来进行三维点的像素值。如下图所示,Transformer首先编码图像特征,然后将其解码到三维空间,而坐标系变换已经被嵌入到了自注意力的计算过程中。这种思路打破的传统方法中对邻域的约束,算法可以看到场景中更大的范围,通过对场景的理解来进行坐标变换。同时,坐标变换的过程在神经网络中进行,可以由后端所接的具体任务来自动调整变换的参数。因此,这个变换过程是完全由数据驱动的,也是任务相关的。在拥有超大数据集的前提下,基于Transformer来进行空间坐标系变换是完全可行的。
 采用Transformer进行图像坐标系到三维空间坐标系的转换
采用Transformer进行图像坐标系到三维空间坐标系的转换
再来说一下时间上的前融合。这个比空间上的前融合更容易理解一些,因为Transformer在设计之初就是为了处理时序数据的。Feature Queue就是空间融合模块在时序上的输出,可以理解为一个句子中的多个单词,这样就可以自然的采用Transformer来提取时序特征。相比特斯拉采用RNN来进行时序融合的方案,Transformer的方案特征提取能力更强,但是在运行效率上会低一些。毫末的方案中也提到了RNN,相信目前也在进行两种方案的对比,甚至是进行某种程度的结合,以充分利用两者的优势。除此之外,由于激光雷达的加持,毫末采用了SLAM跟踪以及光流算法,可以快速的完成自身定位和场景感知,更好的保证时序上的连贯性。
认知模块
除了感知模块以外,毫末在认知模块,也就是路径规划部分也有一些特别的设计。顾维灏在AI Day上介绍到,认知模块与感知模块最大的不同在于,认知模块没有确定的“尺子“来衡量其性能的优劣,而且认知模块需要考虑的因素比较多,比如安全,舒适和高效,这无疑也增加了认知模块设计的难度。针对这些问题,毫末的解决方案是场景数字化和大规模强化学习。
场景数字化,就是将行驶道路上的不同场景进行参数化的表示。参数化的好处在于可以对场景进行有效地分类,从而进行差异化的处理。按照不同的粒度,场景参数分为宏观和微观两种。宏观的场景参数包括天气,光照,路况等,而微观的场景参数则刻画了自车的行驶速度,与周围障碍物的关系等等。
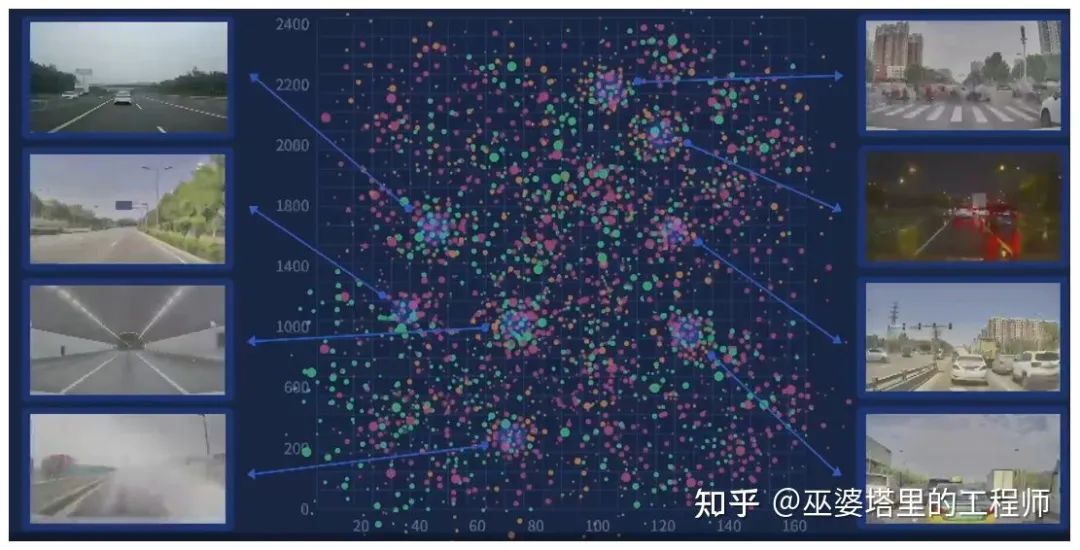 MANA系统中的宏观场景聚类
MANA系统中的宏观场景聚类
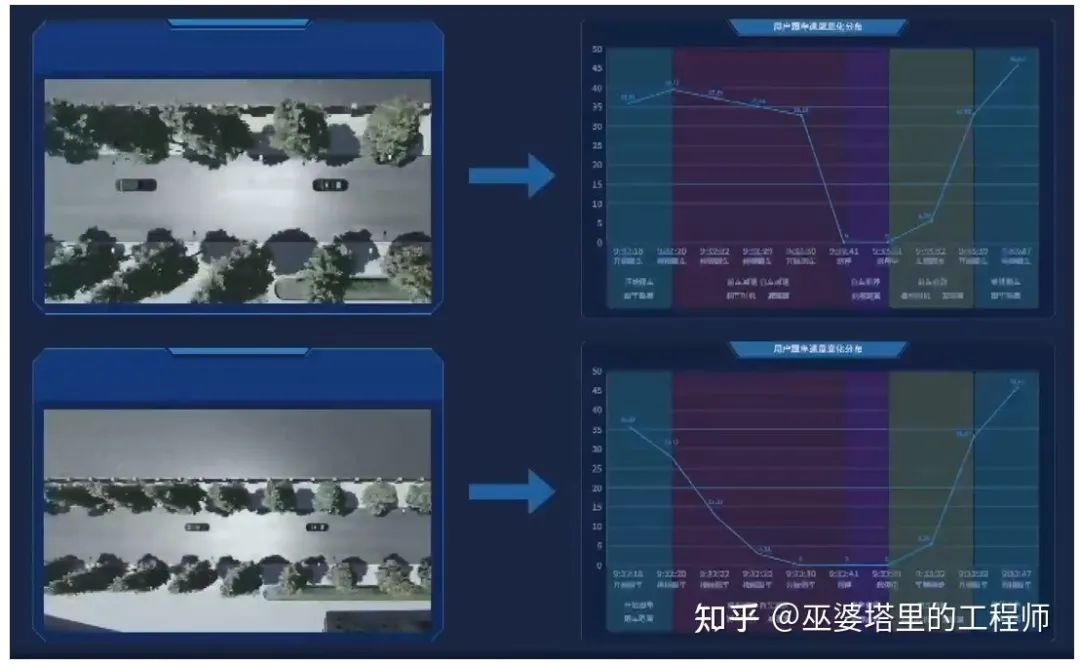 MANA系统中的微观场景(例子是跟车场景)
MANA系统中的微观场景(例子是跟车场景)
在将各种场景数字化了以后,就可以采用人工智能的算法来进行学习。一般情况下,强化学习是完成这个任务的一个比较好的选择。强化学习就是著名的AlphaGo中采用的方法。但是与围棋不同,自动驾驶任务的评价标准不是输和赢,而是驾驶的合理性和安全性。如何对每一次的驾驶行为进行正确的评价,是认知系统中强化学习算法设计的关键。毫末采取的策略是模拟人类司机的行为,这也是最快速有效的方法。当然,只有几个司机的数据是远远不够的,采用这种策略的基础也是海量的人工驾驶数据。
阅读原文,关注作者知乎!
