【说在前面的话】
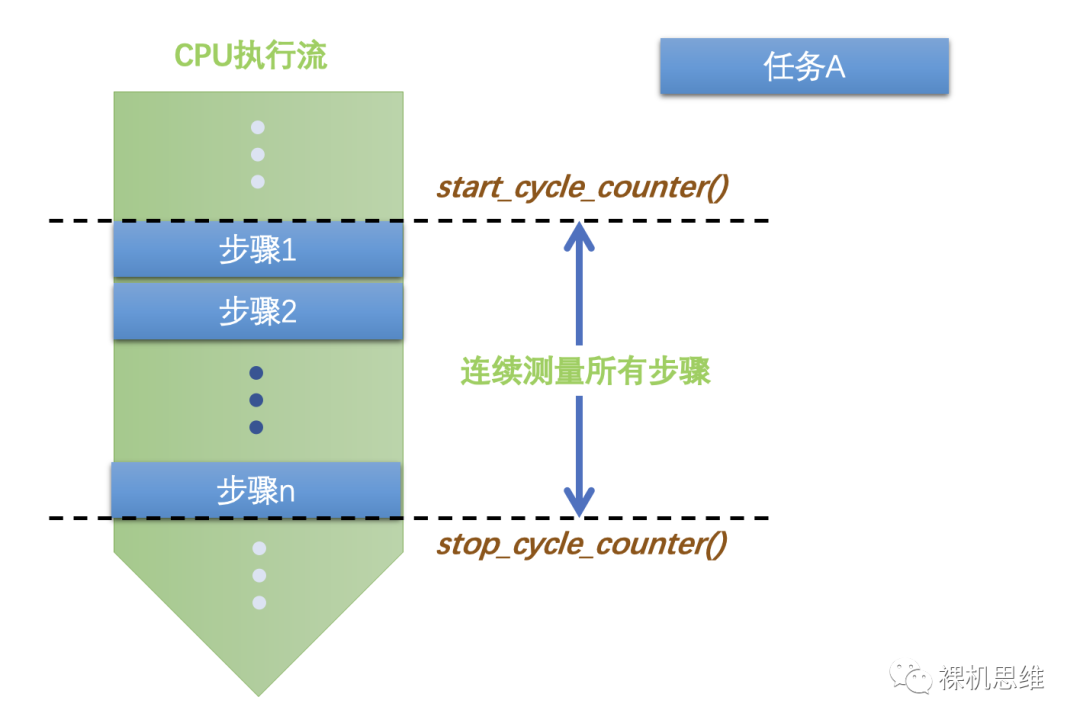
step_1();step_2();...step_n();
如果这些步骤总是
“我们说好不分离~要一直一直在一起~”
那么测量起来就非常简单:
在裸机中,我们可以使用 __cycleof__():
__cycleof__() {step_1();step_2();...step_n();}
也可以简单的使用系统提供的API函数:
start_cycle_counter();do {step_1();step_2();...step_n();} while(0);int32_t iCycleUsed = stop_cycle_counter();
在RTOS环境下,我们可以使用上一篇文章介绍过的专用函数 start_task_cycle_counter() 和 stop_task_cycle_counter()来获取周期数信息:
void example_task (void *argument){init_task_cycle_counter();...start_task_cycle_counter();do {step_1();step_2();...step_n();} while(0);int64_t lCycleUsed = stop_task_cyclee_counter();...}
如果你还不清楚问题的全貌,不妨看下面几张图:
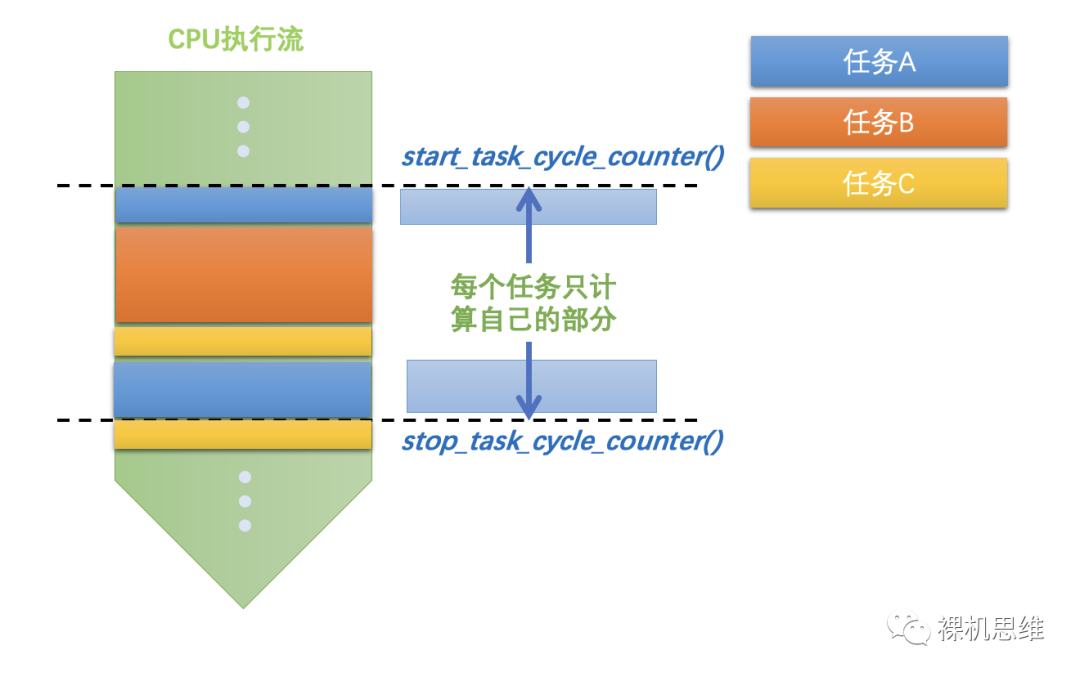
不同的步骤拥有不同的实时性要求
不同的步骤处于不同的模块中
不同的步骤处于不同的安全域中
考虑到未来扩展的需要,认为的需要将步骤拆散并放置到不同的任务中
不同的步骤处于数据流的不同位置
……

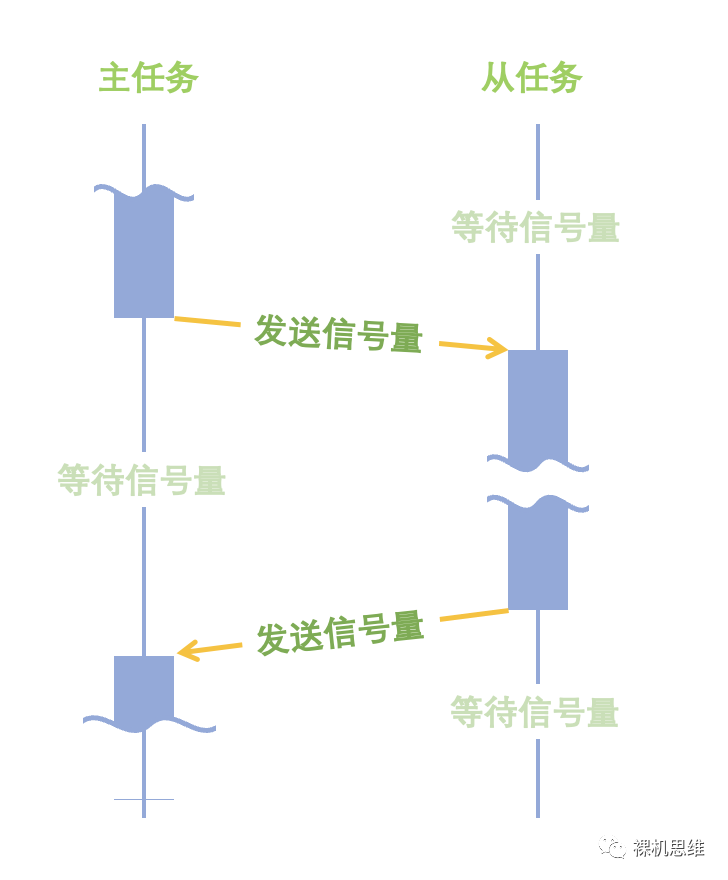
这里:
从任务的目的是从主任务那里分担一部分的工作;
从任务会在任务启动后完成必要的准备工作后就开始等候来自于主任务的信号量,此时,从任务是处于挂起状态;
一般来说,从任务应该在主任务发送信号量之前就完成所有的准备工作——否则,主任务就有“触发了个寂寞”的风险;
当从任务接收到来自主任务的信号量后,将从挂起状态中唤醒,开始正常工作;
当从任务完成本职工作后,会向主任务发送一个信号量——告诉它“你交代的事情我已经做完啦,我先睡会儿,有事您说话”——然后等待下一次主任务的信号量,并由此进入挂起状态。
主任务一般会在对应的阶段向从任务发送信号量,以启动异步处理,这就好比是对从任务说:“来活儿了,快醒醒,我先睡会儿”,然后就进入挂起状态——等待来自从任务的完成信号。
如果觉得上述步骤比较抽象,不妨来看一个实际的例子。假设一个数据处理可以被拆分成三个步骤——为了简化讨论,分别由三个函数 step_1()、step_2()和 step_3() 表示:
void step_1(void){delay_ms(1);}void step_2(void){delay_ms(2);}void step_3(void){delay_ms(3);}
这里,每个步骤都是用由 perf_counter提供的 delay_ms() 函数来模拟一个任务负载(注意:该 delay_ms() 函数不会引发RTOS的任务调度)。
假设三个步骤需要在一个任务中以10ms为间隔周期性的进行执行(以CMSIS-RTOS2的API为范例):
osThreadId_t s_tidTaskA;osThreadId_t s_tidTaskB;void task_a (void *argument){...while (1) {// 获取本次循环开始时的系统毫秒数uint32_t wTick = osKernelGetTickCount();step_1();step_2();step_3();//!< 100Hz 的周期性任务osDelayUntil(wTick + 10);}}
根据上一篇文章的内容,我们可以很容易的测量出三个步骤的CPU占用率:
osThreadId_t s_tidTaskA;osThreadId_t s_tidTaskB;void task_a (void *argument){init_task_cycle_counter();...__super_loop_monitor__(100) {// 获取本次循环开始时的系统毫秒数uint32_t wTick = osKernelGetTickCount();step_1();step_2();step_3();//!< 100Hz 的周期性任务osDelayUntil(wTick + 10);}}
由于三个步骤中负载所占用的时间分别为 1ms、2ms、3ms,因此在10ms的循环周期中,容易计算出这里的CPU占用率为60%,而perf_counter的测量结果也应征了这一结论(100次循环的平均结果):
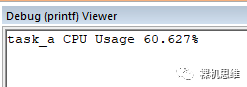
osThreadId_t s_tidTaskA;osThreadId_t s_tidTaskB;void task_a (void *argument){init_task_cycle_counter();...__super_loop_monitor__(100) {uint32_t wTick = osKernelGetTickCount();step_1();//! 向从任务发送信号量,催其起床osThreadFlagsSet(s_tidTaskB, 0x0001);//! 等待从任务完成,挂起当前任务osThreadFlagsWait(0x0002, osFlagsWaitAll, osWaitForever);step_3();//!< 100Hz 的周期性任务osDelayUntil(wTick + 10);}}void task_b (void *argument){init_task_cycle_counter();...while(1) {//! 等待来自主任务的信号量osThreadFlagsWait(0x0001, osFlagsWaitAll, osWaitForever);//! 干活step_2();//! 向主任务发送完成信号osThreadFlagsSet(s_tidTaskA, 0x0002);}}
这里有两点需要注意:
1、为了保证主任务不会“触发了个寂寞”,task_b()需要先于task_a()启动,(或者最保险的方式是将从任务的优先级设置的“大于等于”主任务。)比如:
int main (void) {// System InitializationSystemCoreClockUpdate();osKernelInitialize(); // Initialize CMSIS-RTOSinit_cycle_counter(true);s_tidTaskB = osThreadNew(task_b, NULL, NULL);s_tidTaskA = osThreadNew(task_a, NULL, NULL);...if (osKernelGetState() == osKernelReady) {osKernelStart(); // Start thread execution}while(1);}
2、别忘在两个任务的一开始使用 init_task_cycle_counter() 初始化对应任务的 cycle counter。
然而,经过上述修改后,我们发现实际测量到的 CPU 占用率为 40%:
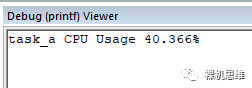
显然,该值由主任务中 step_1() 的 1ms 和 step_3() 的 3ms 构成,而从任务中 step_2() 所消耗的时间则没有比计算在内——这就是跨任务周期计数的问题所在。
为了应对这一问题,perf_counter 专门引入了可以跨越多个任务进行计数的计数器类 task_cycle_info_t,配合对应的方法(API函数)使用:
/*! \brief intialize a given task_cycle_info_t object and enable it*/externtask_cycle_info_t *init_task_cycle_info(task_cycle_info_t *ptInfo);
在“涉事”任务内使用的注册和反注册:register_task_cycle_agent() 和 unregister_task_cycle_agent():
/*! \brief register a global virtual cycle counter agent to the current task*!*! \note the ptAgent it is better to be allocated as a static variable, global*! variable or comes from heap or pool*/externtask_cycle_info_agent_t *register_task_cycle_agent(task_cycle_info_t *ptInfo,task_cycle_info_agent_t *ptAgent);/*! \brief remove a global virtual cycle counter agent from the current task*/externtask_cycle_info_agent_t *unregister_task_cycle_agent(task_cycle_info_agent_t *ptAgent);
在 perf_counter 的头文件中还能找到其它更为精细控制的方法,比如“使能开关相关的函数”等等,这里就不再赘述。
task_cycle_info_t 类的使用也非常简单:
static task_cycel_info_t s_tMyCycleInfo;2、在所有相关的任务启动前,对其进行初始化(完成构造):
int main (void){// System InitializationSystemCoreClockUpdate();osKernelInitialize(); // Initialize CMSIS-RTOSinit_cycle_counter(true);init_task_cycle_info(&s_tMyCycleInfo);s_tidTaskB = osThreadNew(task_b, NULL, NULL);s_tidTaskA = osThreadNew(task_a, NULL, NULL);if (osKernelGetState() == osKernelReady) {osKernelStart(); // Start thread execution}while(1);}
3、在所有“涉事”任务中,调用函数 register_task_cycle_agent() 注册我们的计数器实例,比如:
void task_a (void *argument){int64_t lTimeElapsed;init_task_cycle_counter();task_cycle_info_agent_t tCycleInfoAgent;register_task_cycle_agent(&s_tMyCycleInfo, &tCycleInfoAgent);start_task_cycle_counter(&s_tMyCycleInfo);...}void task_b (void *argument){init_task_cycle_counter();task_cycle_info_agent_t tCycleInfoAgent;register_task_cycle_agent(&s_tMyCycleInfo, &tCycleInfoAgent);while(1) {osThreadFlagsWait(0x0001, osFlagsWaitAll, osWaitForever);step_2();osThreadFlagsSet(s_tidTaskA, 0x0002);}}
这里需要注意:
前面的例子中,涉事的任务是 task_a() 和 task_b() 因此,这两个任务函数在完成了 init_task_cycle_counter() 后,都要调用 register_task_cycle_agent() 函数来注册 s_tMyCycleInfo;
注册时,需要借助一个 task_cycle_info_agent_t 的链表容器,帮助我们将 task_cycle_info_t 的实例加入到 每个任务自己的计数器链表中。这实际上也告诉我们,一个任务可以同时挂载多个不同的 task_cycle_info_t 实例——换句话说:每个任务都能同时服务多个不同目的的跨任务计数器,是不是很强大?
task_cycle_info_agent_t tCycleInfoAgent;register_task_cycle_agent(&s_tMyCycleInfo, &tCycleInfoAgent);
4、在开始计数时,通过 start_task_cycle_counter() 来启动我们的计数器:
start_task_cycle_counter(&s_tMyCycleInfo);同理,在需要获得计数结果的时候,调用 stop_task_cycle_counter() 来获取计数结果:
int64_t lCycleUsed = stop_task_cycle_counter(&s_tMyCycleInfo);这里,细心的小伙伴多半会注意到:这两个函数之前使用的时候不是不需要传递参数么?为什么又可以传递 task_cycle_info_t 类型的指针作为参数呢?其实这里使用了一个此前介绍过的技巧,还不太了解的小伙伴,可以参考这篇文章《【为宏正名】99%人都不知道的"##"里用法》,这里就不再赘述:
externvoid __start_task_cycle_counter(task_cycle_info_t *ptInfo);externint64_t __stop_task_cycle_counter(task_cycle_info_t *ptInfo);__start_task_cycle_counter((NULL,##__VA_ARGS__))__stop_task_cycle_counter((NULL,##__VA_ARGS__))
对应前面的例子,一个完整的示例代码如下:
void step_1(void){delay_ms(1);}void step_2(void){delay_ms(2);}void step_3(void){delay_ms(3);}osThreadId_t s_tidTaskA;osThreadId_t s_tidTaskB;task_cycle_info_t s_tMyCycleInfo;void task_a (void *argument){int64_t lTimeElapsed;init_task_cycle_counter();task_cycle_info_agent_t tCycleInfoAgent;register_task_cycle_agent(&s_tMyCycleInfo, &tCycleInfoAgent);start_task_cycle_counter(&s_tMyCycleInfo);__super_loop_monitor__(100,{lTimeElapsed = __cpu_usage__.lTimeElapsed;int64_t lCycleUsed = stop_task_cycle_counter(&s_tMyCycleInfo);printf("s_tMyCycleInfo CPU Usage %2.3f%%\r\n",(float)((double)lCycleUsed* 100.0 /(double)__cpu_usage__.lTimeElapsed));start_task_cycle_counter(&s_tMyCycleInfo);}) {uint32_t wTick = osKernelGetTickCount();step_1();//! 向从任务发送信号量,催其起床osThreadFlagsSet(s_tidTaskB, 0x0001);//! 等待从任务完成,挂起当前任务osThreadFlagsWait(0x0002, osFlagsWaitAll, osWaitForever);step_3();osDelayUntil(wTick + 10); //!< 50Hz}}void task_b (void *argument){init_task_cycle_counter();task_cycle_info_agent_t tCycleInfoAgent;register_task_cycle_agent(&s_tMyCycleInfo, &tCycleInfoAgent);while(1) {//! 等待来自主任务的信号量osThreadFlagsWait(0x0001, osFlagsWaitAll, osWaitForever);//! 干活step_2();//! 向主任务发送完成信号osThreadFlagsSet(s_tidTaskA, 0x0002);}}int main (void){// System InitializationSystemCoreClockUpdate();osKernelInitialize(); // Initialize CMSIS-RTOSinit_cycle_counter(true);init_task_cycle_info(&s_tMyCycleInfo);s_tidTaskB = osThreadNew(task_b, NULL, NULL);s_tidTaskA = osThreadNew(task_a, NULL, NULL);if (osKernelGetState() == osKernelReady) {osKernelStart(); // Start thread execution}while(1);}
运行结果如下:
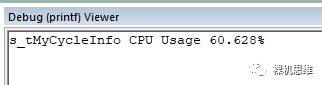
可以看到,三个步骤的任务负载(1+2+3=6ms)都被计算在内。

除了前面介绍的简单“主从”模式外,多任务环境下往往还存在另外一种类似流水线的多任务“接力”模式:

这种任务模式在“数据流图”上往往呈现“百川汇海”模式,有时候,我们需要沿着其中一条线索完成从源头到末端的性能分析,而它的“事件触发图”大体如下:
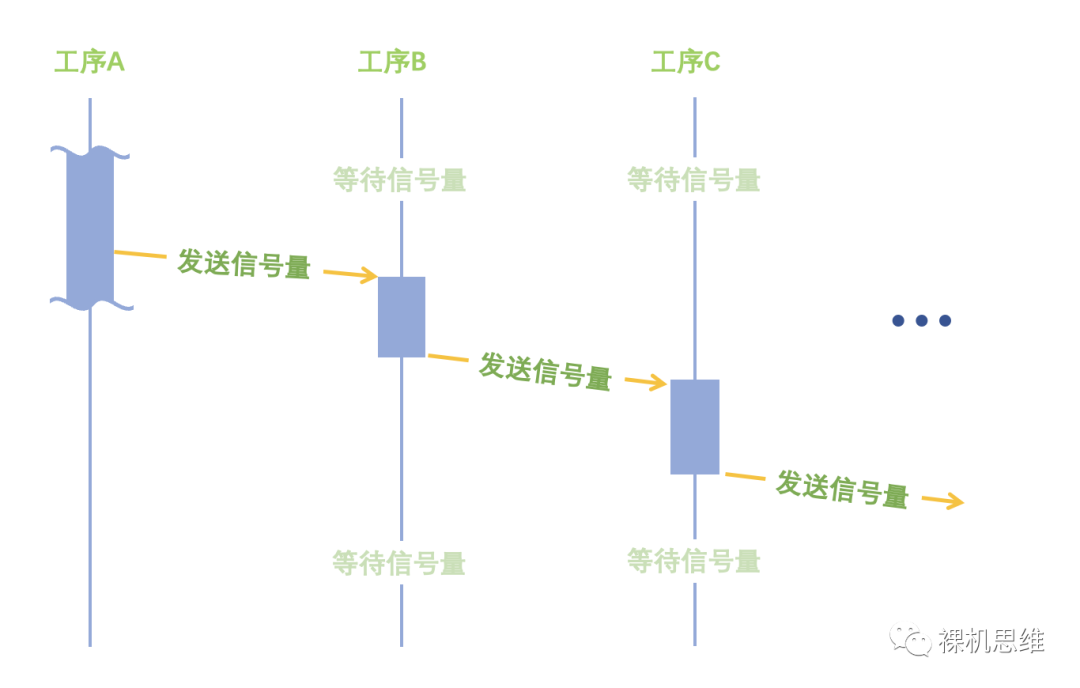
这种情况下,我们仍然可以使用 task_cycle_info_t 来测量整个工序的耗时(周期数),只不过需要注意的是:
我们要在工序开始的地方调用 start_task_cycle_counter()来开始计数;在工序结束的地方调用 stop_task_cycle_counter() 来获取测量结果。
由于 start_task_cycle_counter() 会清零计数器,因此要在源头处作必要的保护——防止在一次完整的测量结束前,过早的调用 start_task_cycle_counter()。利用RTOS所提供的互斥量,我们可以轻松的实现这一功能,这里就不再赘述。
测量的结果可以通过 SystemCoreClock 中保存的CPU工作频率换算成物理时间(ms或者us):
int64_t lCycleUsed = stop_task_cycle_counter(&s_tMyCycleInfo);printf("Pipeline used %d ms", lCycleUsed / (SystemCoreClock / 1000) );
有时候,进行性能分析需要暂时性的(或者有条件的)关闭某一计数器,此时灵活使用 使能开关函数 对 task_cycle_info_t 对象进行操作就成为了关键。
【说在后面的话】
谢谢啦。
如果你喜欢我的思维、觉得我的文章对你有所启发,
请务必 “点赞、收藏、转发” 三连,这对我很重要!谢谢!
欢迎订阅 裸机思维
‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧ END ‧‧‧‧‧‧‧‧‧‧‧‧‧‧‧
点击下面图片,有星球具体介绍,新用户有新人优惠券,老用户半价优惠,期待大家一起学习一起进步。
点击“阅读原文”查看更多分享,欢迎点分享、收藏、点赞、在看。